
基于数据挖掘农田灌溉工程智能应用研究
2022-09-14 05:52:10吾古丽江斯特瓦地
水利科学与寒区工程 2022年8期
吾古丽江·斯特瓦地
(高昌区水管总站,新疆 吐鲁番 838000)
农田灌溉是在农业生产的环节,我国农业用水量占全国总水量的 十分之七以上[1]。与传统的灌溉技术相比,智能化农田灌溉系统为机井配置了远程智能监控设备,通过智能化建设挖掘数据,准确监测并显示地下水位变化、土壤墒情等各项信息,极大地改善了农业生产基础条件,提高水资源的合理利用率[2]。目前国内外对精准智能化农田灌溉工程进行了相关研究,主要分为无线传感网络技术、模糊控制技术、物联网技术以及专家系统控制技术[3-4],此外还有部分学者采用无线传感网络、BP神经网络预测模型以及智能灌溉专家决策系统等对智能灌溉进行了研究[5-11]。然而当前的研究,很少考虑数据来源的可靠性,因此做出来的灌溉优化设计与实际具有一定偏差。本文提出了REP数据前处理方法,先对比分析了基于参考蒸散量的预处理(REP)和等水量分布(EWD)方法在建立灌溉数据库中的优异性,之后采用人工神经网络、支持向量机、随机森林、逻辑回归、决策树对灌溉需水量的智能预测进行了分析,研究成果可为相关工程提供参考。
1 数据收集
为了建立训练数据集,从灌区收集了三种不同类别的数据。第一种提供了灌区作物不同生长季节的总用水量信息,第二种是研究区域内气象站监测的气象数据,第三种是两种类型的空间数据:(1)土地利用覆盖图像,提供有关作物种植的信息。(2)土壤类型图像,提供与研究区域相关的不同土壤类型的信息。本文选择对作物用水有重大影响的属性,以及在整个种植季节都可用的数据,例如,“种植期”与作物用水有着密切的关系。本文的训练集包含由各种天气参数属性组成的历史数据,如最高和最低温度、风速、湿度、降雨、太阳辐射,以及土壤类型、作物类型和作物用水,见表1。表1中的作物用水属性称为“类”属性,其他所有属性称为“非类”属性。数据集是一个二维表,其中列是属性(分类和数值),行是记录。每条记录保存一天内相应属性的每日平均值。土壤类型和作物类型等属性归类为类别属性,而所有其他非类别属性归类为数字属性。
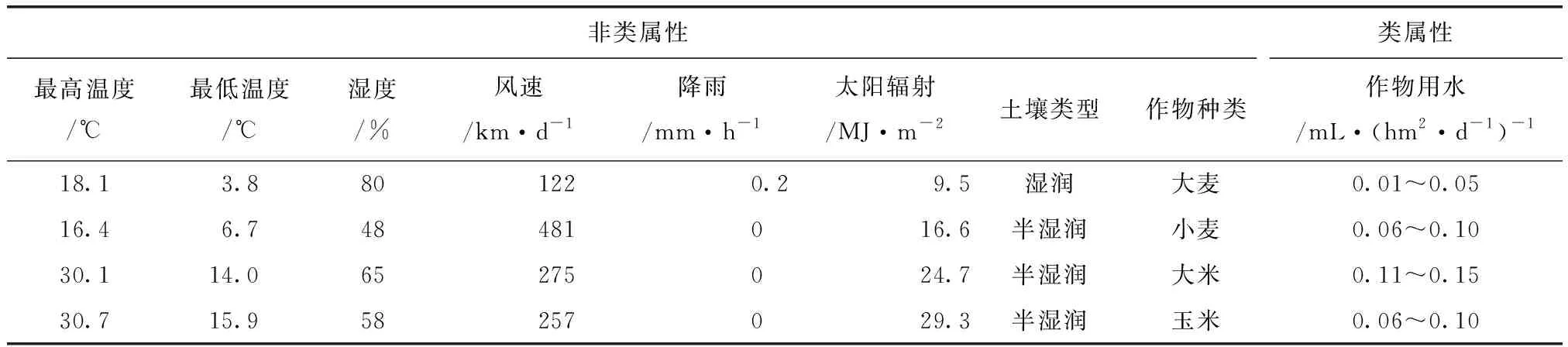
表1 各属性组成的训练集
2 基于REP数据预处理
第一种信息仅仅提供了灌区作物不同生长季节的总用水量信息,然而灌区并非每天供水,因此只能获得任何特定日期的供水量信息,而无法估计特定一天作物的确切用水量。然而,为了获得非类属性和类属性之间的精确关系,需要训练数据集记录每日作物用水量。因此,本文提出了一种数据预处理方法,称为基于参考蒸散量的预处理(REP),用于估算农场的日常作物用水量。此外,我们还将提出的REP技术与基于等水量分布的预处理(EWD)进行了比较。在等水量分配技术(EWD)中,我们将输送到灌区的水量除以两次连续输送之间的天数,可以得到每天的平均用水量。然而,如果平均分配用水,那么无论天气条件如何,每天的用水量都是一样的。由于实际作物用水量与天气条件有着密切的关系,因此需要在数据集中获得更准确的用水量数据,在精确数据集上应用分类模型来探索非类别属性和类别属性(作物用水)之间的精确关系。
在估计每日用水量时,考虑了参考蒸散ETo因子,作物用水量可以通过作物系数Kc和参考蒸散量ETo的乘积来计算。对于特定的生长阶段,每种作物都有一个恒定的作物系数值。计算特定一天的作物用水量如下:设n为灌区连续两次供水之间的天数,WT为n天开始时供水期间的供水量,nd中每一天的ETo值从气象站获得。在确定这些参数过后,计算第i天的系数xi,见式(1):
(1)

3 算法预测原理
3.1 人工神经网络(ANN)
人工神经网络是一种由生物启发的,用来构建可以学习并且独立解释数据中联系的计算机程序的方法。每个神经元以一组x变量(取值从1到n)的值作为输入,计算预测的y-hat值。假设训练集中含有m个样本,则向量x表示其中一个样本的各个特征的取值。此外,每个单元有自己的参数集需要学习,包括权重向量和偏差,分别用w和b表示。在每次迭代中,神经元基于本轮的权重向量计算向量x的加权平均值,再加上偏差。最后,将计算结果代入一个非线性激活函数g。其计算过程如式(2)~式(3):
(2)
yk=g(sk)
(3)
式中:角标k为第k个神经元;xj为输入参数向量,表示未知量个数;wj,k为各参数权重;bk为阈值;yk为输出值;g(sk)为非线性激活函数;sk为第一次进行权重分配后的输入值。
3.2 支持向量机(SVM)
支持向量机是一种基于统计学的最先进的神经网络方法。支持向量机算法的基础是最大间隔分类器,最大间隔分类器虽然很简单,但不能应用于大部分数据,因为大部分属是非线性数据,无法用线性分类器进行分类,解决方案是对特征空间进行核函数映射,然后再运行最大间隔分类器。支持向量机的核函数映射是一种扩展特征空间的方法,核函数的核心思想是计算两个数据点的相似度。
3.3 决策树(DT)
决策树是一中监督机器学习算法,该算法根据数据的特征进行逐层划分直到划分完所有的特征,这一过程类似于树叶生长过程。决策树算法可用于解决分类和回归问题,在实际数据分析中有着广泛的应用,比较经典的决策树算法有CART、ID3等等。
3.4 随机森林(RF)
随机森林由Leo Breiman(2001)提出的一种分类算法,他通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。
3.5 逻辑回归(LR)
逻辑回归模型的主要目标是基于训练数据集上提取的知识预测新给定数据的标签。逻辑回归可以分为两种类型:简单逻辑回归和多元逻辑回归。简单逻辑回归用于预测类别值,因为他是分类的,并且只有两种可能的结果,然而,多元逻辑回归可以用来预测由三个或更多可能结果组成的类值。
4 REP与EWD前处理方法对比分析
为了评估数据预处理技术的优异,构建了两个训练数据集D1和D2。数据集D1使用等水量分布(EWD)方法,D2使用基于参考蒸散量的预处理(REP)方法。本文在训练数据集上应用决策树算法(C4.5)来提取非类属性和类属性之间的关系,然后将其应用于测试数据集,以测试预测准确性。之后,在D1上使用带有反馈的三层前馈结构构建人工神经网络,将数据集分为三部分:70%、20%和10%用于训练、验证和测试。网络的训练使用两种不同的网络类型,第一种是使用8个节点,1个隐藏层,第二种是使用6个节点,1个隐藏层。两种网络都接受了30 000次、50 000次和70 000次学习迭代的训练。通过比较预测精度,对数据集D上的模型进行性能评估。计算时使用3折交叉验证方法进行预测精度分析,这是一种通过将数据集划分为三个相等部分(也称为a倍)来测试精度的方法,其中数据集的两部分用于训练,第三部分用于测试。该过程持续3次,以便数据集的每个部分都用于测试一次。D总共有6070条记录,其中2023条记录用于每次交叉验证中的测试。
表2为基于EWD和REP方法模型的每折的预测精度。由表可知,对于EWD方法,随机森林方法相比其他算法预测精度都好,平均准确率为51%,而对于REP方法,在所有其他技术中,RF的预测性能仍然最好,其次是决策树和支持向量机。其中,RF的预测准确率为78%,而DT和SVM的预测准确率分别为74%和64%,ANN和LR回归的准确性较低,但ANN在数据集D1上的性能优于SVM。从上表还可看出,数值结果清楚地表明了基于灌溉工程和数据挖掘知识的数据预处理的有效性,REP方法处理数据的优势明显大于EWD方法。

表2 基于EWD和REP方法模型的每折的预测精度
5 灌溉量预测分析
本文将6个模型均应用于灌区的每个灌溉子区域,以获得整个种植季节的需水量,其中5个机器学习模型,1个传统的ETo预测方法。通过将每个灌溉子区域预测需水量相加,计算每个总的需水量。为节约篇幅,只将采用RF方法的预测需水量与实际需水量之间的值给出,如图1所示。由图可知,RF方法在一段预测区间内均表现出良好的预测精度,实际总灌水量与预测总灌水量均保持在较小的误差精度之内。其中,RF预测的需水量与实际耗水量更接近,准确率高达98.5%,表明该模型预测的贴近度较高。其次是DT和ANN,其准确率分别为94.0%和93.0%,这两个指标的预测度与RF方法相差不大。从结果分析来看,本文采用的机器学习方法可为灌区的需水量预测提供较好分析工具,大幅度提升灌区用水资源配置率。

图1 RF方法的预测需水量与实际需水量
6 结 论
本文为提高灌溉用水量预测精度,提出了一种REP数据前处理方法,先对比分析了基于参考REP和EWD方法在建立灌溉数据库中的优异性,之后采用人工神经网络、支持向量机、随机森林、逻辑回归、决策树对灌溉需水量的智能预测进行了分析,结果表明经过REP方法处理后的数据,对后续用水量预测精度具有大幅度提升,优势明显大于EWD方法。此外RF预测的需水量与实际耗水量更接近,准确率高达98.5%,其次是DT和ANN,其准确率分别为94.0%和93.0%。
猜你喜欢
小学科学(学生版)(2021年5期)2021-07-22 02:40:02
今日农业(2020年14期)2020-12-14 19:47:34
环境影响评价(2020年2期)2020-12-02 01:23:38
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
水利科技与经济(2017年4期)2017-04-22 02:37:58
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
水利科技与经济(2016年3期)2016-04-22 01:04:52
水利规划与设计(2016年7期)2016-02-28 15:06:27
建材与装饰(2015年41期)2015-04-17 00:38:21
