
CLPNet:基于深度学习大规模MIMO的CSI反馈网络
2022-09-09 01:59:58刘为波丁宇舟
无线电工程 2022年9期
刘为波,颜 彪,沈 麟,丁宇舟
(扬州大学 信息工程学院,江苏 扬州225009)
0 引言
大规模多输入多输出(Multiple-Input Multiple-Output,MIMO)技术是下一代通信系统的核心技术之一。基站(Base Station,BS)端配置大量天线后,可以利用分集及并行接收技术极大地提升信道容量。尽管普遍采用的是时分双工(Time Division Duplexing,TDD)操作模式,但已经证明,频分双工(Frequency Division Duplexing,FDD)大规模MIMO能够处理由标准化带来的低延迟需求,可能比TDD解决方案要好得多。这一特性激发并鼓励了一些旨在减少或消除下行链路信道状态信息(Channel State Information,CSI)捕获开销的研究。在FDD模式下,由于信道之间不存在互易性,为了在BS上实现预编码的设计,设备端(User Equipment,UE)必须精确地把下行CSI反馈给BS端。然而,下行链路利用导频训练进行信道估计时,其开销会随着天线数量的增加呈指数性增长。因此,需要在反馈前进行CSI压缩来减少开销。
传统的压缩感知方法(LASSO,BM3DA-MP和TVAL3)[1-2]存在一些致命缺点,如严重依赖信道稀疏性假设、迭代重构信号效率低和没有充分利用信道结构等。深度学习(Deep Learning,DL)技术的快速发展为FDD大规模MIMO系统中CSI的有效反馈提供了另一种可能的解决方案。CsiNet[3]首先利用机器学习方法证明了DL在CSI反馈中的有效性,这是一种新颖的CSI感知和恢复机制,可以有效地从训练样本中学习通道结构。CsiNet学习从CSI到接近最优的表示(或码字)数量的变换,以及从码字到CSI的反变换,自然地克服了信道稀疏性前提和重构效率的局限性。在不同的压缩率下,CsiNet的性能显著优于传统压缩感知(CS)方法。后续基于DL的方法大多利用了CsiNet的思想来实现更好的性能。Liu等[4]和Yang等[5]采用上行和下行CSI关联,这可以被视为带有额外条件或假设的新场景。CsiNet-LSTM[6]和Attention-CSI[7]引入了长短时记忆网络(Long Short-Term Memory,LSTM),显著增加了计算开销。CsiNet+[8]通过更新卷积核,在不增加额外信息的情况下提高了网络性能,但CsiNet+的复杂性提高了很多倍。JCNet[9]和BcsiNet[10]降低了复杂度但性能也做了取舍。DN-Net[11]考虑到了实际的噪声,提出了一种用于码字去噪的噪声提取单元。CRNet[12]在不增加计算复杂度的情况下优于CsiNet。Wang等[13]提出了压缩采样CSI与神经网络结合,并使用了3D卷积层,其效果优于无采样方法。Ji等[14]提出了伪复值网络CLNet,将实值神经网络模型中的实部和虚部结合起来,并采用了空间注意力模块和通道注意力模块。MRFNet[15]开发了一种具体多感受野和大卷积通道的神经网络。以上大多数研究没有考虑到编译码器与图像算法的深层次结合,仿真性能和复杂度未达到理想的状态。
本文受CLNet和MRFNet的启发,把MRFNet中编码器部分提到的大卷积通道以及多感受野和CLNet的注意力机制进行了结合,提出了CLPNet。在译码器部分对大卷积核进行因子分解变为多个小卷积核,减少参数和复杂度。仿真证明,在复杂度提高很少的情况下,其性能有显著增加。
1 系统模型
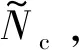
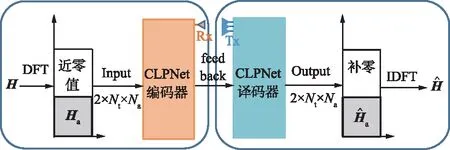
图1 CLPNet工作流程Fig.1 Workflow of CLPNet
因此,在频域中第n个子载波的接收信号可以表为:
(1)
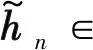
(2)
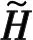
(3)
式中,Fa∈和Fd∈Nt×Nt是DFT矩阵。对于信道延迟矩阵H,每个元素都对应一定的路径延迟和到达角(Angle of Arrival,AOA)。在时间延迟域中,多径到达之间的时间延迟是在有限的时间内,所以只有前几行有非零值,其余行表示传播延迟较大的路径由接近零的值组成。因此,可以取前行得到矩阵Ha,不会造成太多的信息损失。接下来可以利用CSI矩阵的稀疏性来进一步压缩。当Nt→∞时,基于CS的方法具有足够的稀疏性,然而Nt在实际系统中的应用受到一定的限制,尤其是在压缩比较大的情况下,其稀疏性不足。在本文中,考虑下行CSI反馈的编解码网络,将CSI矩阵Ha输入到网络中,UE端的编码器部分根据给定的压缩比η将Ha压缩成一个长度为M的短特征向量c,然后BS端的解码器接收码字并将其重构为定义为CR=M/N,N即Ha的大小,本文取32×32×2=2 048。最后,通过反变换和零填充来恢复最终的H。整个反馈方案可以归结为:
(4)
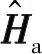
(5)
本工作只关注反馈方案,下行信道估计和上行反馈假设是理想的。此外,采用COST2100[16]模型来模拟FDD大规模MIMO系统的信道矩阵。
2 网络设计
2.1 研究动机
卷积通道是一个很重要的超参数,每个通道都可以认为是一个滤波器,其参数是可学习的。卷积通道的大小和特征图的数量紧密相连。计算机视觉[17]证明了更多的卷积通道可以捕获更多的特征。MRFNet[15]证实了在CsiNet中压缩比为1/4的情况下,随着卷积通道数量的增加,室内室外环境下的性能均有提升。CRNet中证明了并行卷积层在CSI反馈中的有效性。MRFNet的实验结果表明,大卷积核可以获得更多的全局信息,性能有进一步的提升。CLNet编码器端设计添加了伪复值网络和CBAM模块,其最后的复杂度和性能均优于CRNet。CLNet主要是对编码器部分进行了改进。综合上述内容,提出了MRFNet和CLNet的优化结构网络——CLPNet。
2.2 CLPNet网络
CLPNet总架构如图2所示,为了简单,省略了传统的卷积块。CLPNet整体来说是一个端到端的编解码框架,主要有4个模块,是为CSI反馈问题定制的。CSI反馈方案的性能在很大程度上取决于压缩部分,即编码器压缩的信息损失越小,解压精度越高。受UE端的计算能力和存储的限制,深度编码器网络设计是难以实现的。因此,CLPNet的编码器端对CLNet编码器进行了优化,只使用了空间注意力模块,另使用了一个1×1的卷积块。在2个定制块级联形式下,实现了一个复杂度较低但信息丰富的编码器。在过去,设计CSI反馈网络时CSI的实部和虚部是分开处理的,CSI矩阵是描述不同信号路径的信道系数的复值。在第一个模块,输入的CSI首先经过伪复数值输入层,该层将实部和虚部嵌入在一起,以保留CSI的物理信息。其次,不同的信号路径在角延迟域中具有不同的簇效果,对应于不同的AOA和不同的路径延迟。为了使神经网络更加关注这些簇并抑制不必要的部分,引入了CBAM块[18]中的空间注意力机制。
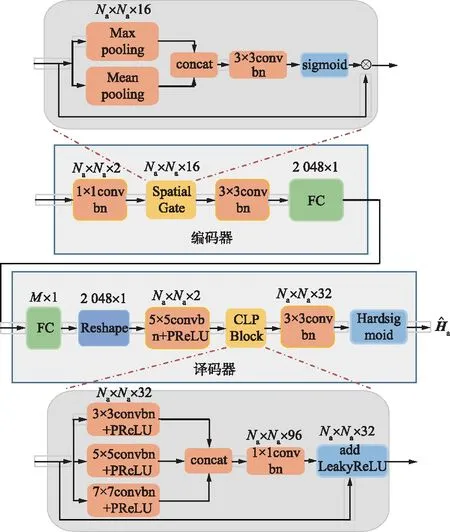
图2 CLPNet总架构Fig.2 Overall architecture of CLPNet
2.3 编码器
2.3.1 卷积操作
CSI矩阵是信道复系数,表示为:
(6)
式中,N为信号路径总数;an(t)和θn(t)为在t时刻第k条路径的衰减和相位变化。大多数的处理办法是虚实分开,会破坏复值信道的原始物理特性。
在Encoder端进行如下操作,首先,Ftr:Ha→ρ∈Na×Na×C是一个标准的卷积操作,其中C表示卷积核的数量。给定一个输入Fi,其通过一系列卷积变换后得到一个通道数为s2的特征。Ftr的输出为ρ=[ρ1,ρ2,…,ρC],ρC∈Na×Na,每个卷积核f都有可学习的权重wn。CLNet的操作是通过1×1卷积核逐点卷积,这样复系数的实部和虚部可以显示嵌入。
卷积操作可以表示为:
(7)
式中,vc表示第c个卷积核;xs表示第s个输入;uc表示第c个二维矩阵;下标c表示channel。
2.3.2 空间注意力块
在角延迟域,信道系数反映了在不同分辨率下的簇效应,对应着具有特定延迟和AoAs的可分辨路径。为了对这些簇给予更多的关注,CLPNet在编码器部分使用了一个空间注意力模块作为空间上的关注。如图2上半部分的编码器模块所示,首先,在输入Fi的通道C上采用平均池化和最大池化操作,生成2个2D特征映射图,Favg∈Na×Na×1,Fmax∈Na×Na×1。随后拼接2个特征映射图生成一个压缩的空间特性描述符Fcon∈Na×Na×2,将其与标准层卷积操作,生成2D空间注意力掩码Fmask∈Na×Na×1,利用sigmoid函数激活掩码,最后与原特征图Fi相乘得到具有空间注意力的Fo,为:
Fo=Fi(σ(fc(Favg;Fmax)))。
(8)
2.4 译码器
CLPBlock为解码器的主要部分。MRFNet中证明了大卷积通道的有效性,从复杂度(Flops)和性能方面综合比较,CLPBlock中的每个卷积层的卷积通道大小为32,并有一个批归一化(BN)函数和带参数的PReLU激活函数。CLPBlock包含了3个不同卷积核的并行路径,不同卷积核的大小分别为3×3,5×5,7×7。为了减少参数,5×5和7×7的卷积核通过卷积分解,分别分解为2个3×3和3个3×3卷积核的串联形式,每个3×3卷积核后增加了激活函数使整个模型的非线性拟合能力也变强。3个通道并行输出后进行拼接激活操作,最后通过1×1的卷积核拼接,将96的通道数减少到32并使用归一化函数输出,这是整个CLPBlock操作过程。卷积核的多尺度可以提取具有不同感受野下的特征,并行结构可以理解为从“复杂”输入中提取更多信息的再提取操作,1×1卷积操作是一种特征融合和增加非线性的方法。最后,根据残差学习的思想,添加带有参数的LeakyRelu激活函数的相同路径。
解码器的输入和输出大小分别为M×1,2Na×Nt,头部卷积层采用5×5卷积核性能最佳,CRNet已经证明了这一点。首先,压缩的码字通过FC层恢复,重塑大小为2Na×Nt,然后通过5×5卷积核串联到CLPBlock,把卷积通道同时扩展到32通道。最后,通过一个3×3的卷积核操作后经过Hardsigmoid函数激活。由于Hardsigmoid函数没有指数运算,因此可以减少一定的运算时间,即复杂度。
3 实验结果与分析
3.1 实验设置
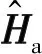
(9)
复杂度通过Flops(每秒计算的浮点数)来衡量,epoch为1 000,batch为200。激活函数使用了带有参数的PReLU函数、带有泄露的LeakyReLU函数和Hardsigmoid函数。通过无错误反馈这个假设是合理的,因为反馈链路通常使用纠错码来保护,因此有一个非常低的错误率[19]。
3.2 对比分析
本方法与其他几种只关注压缩和恢复的方法进行了比较。不同压缩比和在不同场景下的性能对比如表1所示。从表1可以看出,CLPNet在不同压缩比和不同场景下的NMSE均高于其他方法的NMSE,尤其是在高压缩比的情况下表现甚佳,这是因为网络有了一个更加细化的编码器,在空间上增加了注意力机制,即使在高压缩比的情况下也能很好地恢复出信道矩阵。
本文对编码器和解码器参数数量进行了对比,如表2所示,在参数数量方面CLPNet并没有明显增加。但从如图3所示的卷积通道数量与复杂度关系可以看出,随着卷积通道的增加其复杂度有了指数性的上升,选择32通道为一个折中情况,其复杂度并未增加太多。可以看出,整个网络的复杂度主要来源于解码器,如果牺牲复杂度选择64通道,性能将会进一步提升。由于进行了卷积分解,参数相对MRFNet也有了一定的减少,并且解码器是在BS端,可以正常部署提高性能。由表1和表2综合得出,CLPNet编码器复杂度增长并未太多,解码器部分复杂度Flops相比MRFNet小很多的情况下,CLPNet的性能均超过CLNet和MRFNet两种网络的性能。
CLPNet,CLNet和MRFNet在1 000次迭代、压缩比CR=1/4的室内情况下的性能曲线如图4所示。从图4可以看出,CLPNet网络其收敛速度要明显高于另外2种网络的收敛速度,并且随着epoch的增加,CLPNet性能依然提高。
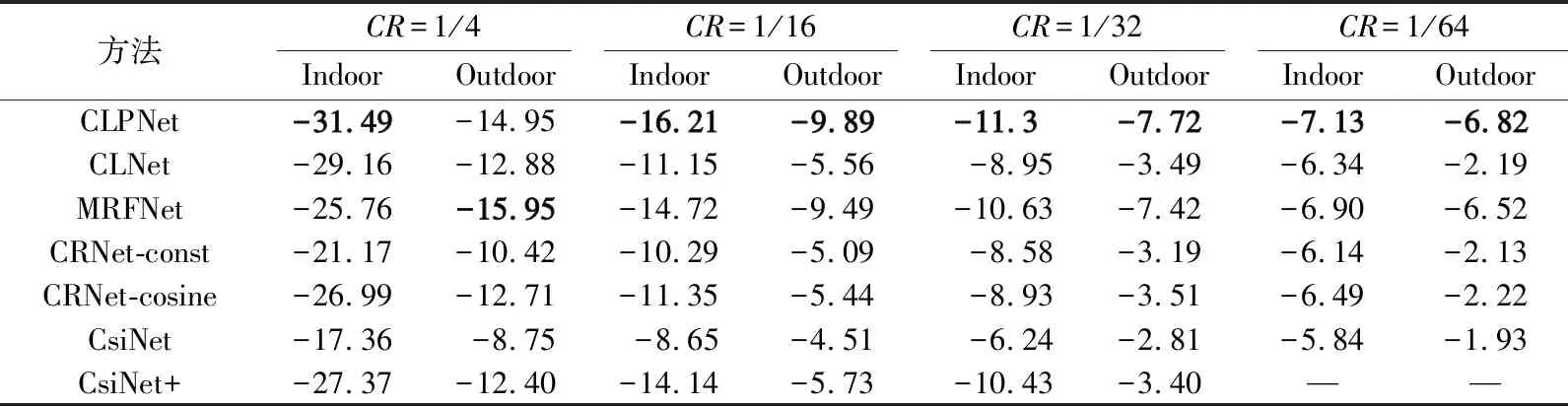
表1 不同环境下的基于DL方法的NMSE
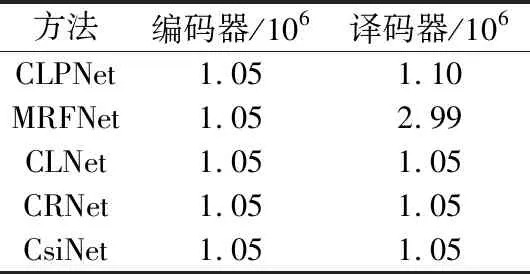
表2 编码器和解码器各自的参数数量
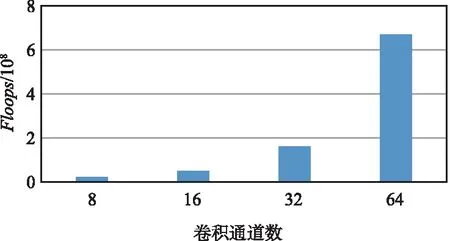
图3 卷积通道数量与复杂度关系Fig.3 Number of convolution channels vs complexity
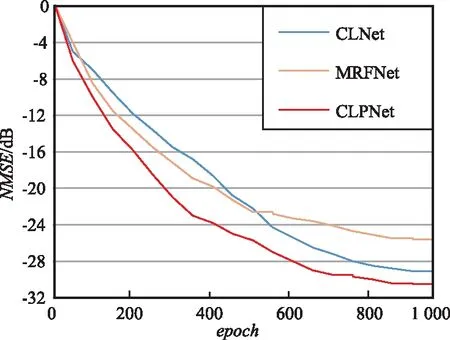
图4 不同网络训练曲线Fig.4 Different network loss curves
CLNet和MRFNet两种网络的曲线对比可以看出,大卷积通道的优势在初始情况下尤为明显,但随着迭代次数的增加,注意力机制的优势慢慢明显起来。MRFNet[15]验证了MRF块串联数量增加会有进一步性能的提升,说明CLPNet通过选择更大的卷积通道和串联更多的CLPBlock的情况下,即牺牲更多复杂度,性能会进一步提高,最后通过实验验证了此猜想。
最后,本文做了2项消融研究。第1,对CLNet[14]的编码器部分进行了消融研究,发现加入的SENet模块在放入CLPNet网络中进行训练时,仿真性能提升不到1%,原因可能是信道矩阵对空间维度更加敏感。
第2,比较了在CR=1/4的室内环境下不同激活函数的性能比较,仿真结果如图5所示。
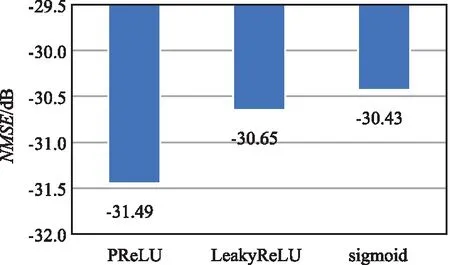
图5 不同激活函数性能对比Fig.5 Performance of different activation functions
可以看出,带有参数的PReLU函数相对LeakyReLU和sigmoid函数性能分别提高了2.6%和3.6%,说明带有参数的PReLU函数更有利于网络的训练,并且在实际训练记录中显示了其收敛速度也高于另外2种激活函数。这也证实了二值化量化聚合网络研究[20]中的结论。
4 结束语
本文研究了5G通信系统下的关键技术,即FDD模式下的大规模MIMO的CSI反馈问题,提出了一种基于DL的网络结构CLPNet。在整个网络中,编码器端的伪复值输入层考虑到了信号的相位信息,并通过空间注意力机制分配权重增强簇的关注度;而解码器端的网络具有多个不同大小的卷积核提取不同特征,并具有大量卷积通道以保持丰富的信息特征。通过多个感受野的融合,可以更好地提高恢复质量。仿真结果表明,在牺牲了较小复杂度的情况下,CLPNet在不同压缩比的情况下均得到了性能的提升。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
软件(2020年3期)2020-04-20 01:45:24
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
汽车与新动力(2014年6期)2014-02-27 12:10:55
