
基于改进粒子群算法的电动机器人全局路径规划
2022-09-09 01:41陈玲玲张占奎钟元辰张忠瑞
东北电力技术 2022年8期
陈玲玲,张占奎,钟元辰,张忠瑞
(1.吉林化工学院信息与控制工程学院,吉林 吉林 132000;2.国网盘锦供电公司,辽宁 盘锦 124000;3.国网辽宁省电力有限公司,辽宁 沈阳 110006)
自主导航的电动机器人应用范围包括工业、军事、救援、太空、农业和家庭[1],在这些实际应用中,电动机器人的智能能力决定其能否在碰撞移动下顺利完成任务。在这些智能能力中,地图建模和路径规划是最智慧、最重要的特征。路径规划是智能机器人和车辆自主运行的关键要素,是指在一个有障碍物的运动环境中,机器人参考传感器扫描到的环境信息,寻找1条不触碰障碍物的几何路径,按照这条路径能够安全移动到目标位置,其要素包括:①存在能够移动到终点的安全路线;②路径不碰到障碍物且长度尽可能小;③耗时少;④无碰撞。路径规划算法一般包括环境建模和路径搜索,每次规划任务都会有多条到达目标点的路径,但是最佳路径的计算取决于一些决策标准,例如路径长度、航行时间或能量最小化。除了避免碰撞的安全性和效率之外,评估路径的标准还可以是其平滑性和可行性、计算路径所需的计算资源。许多优化算法已被用于路径规划问题[2-3]。这些算法分为经典方法、元启发式方法2种。通常,由于计算花费时间较长且无法处理环境中偶然性情况,经典方法不常用于实时移动路径规划。与不能很好解决复杂环境问题的经典算法相比,元启发式算法易于实现,具有处理环境中存在的不确定性的能力[4-5]。
为了有效解决这个问题,学者们提出了不同的方法和思路。Mohanata提出了一种新颖的基于Petri-Net模型与遗传算法(genetic algorithm, GA)相结合的方法,构成了集成导航控制器[6]。Oleiwi开发了一种将蚁群优化算法与GA相结合的混合方法,使用蚁群优化算法获得无障碍的次优路径,然后作为GA的初始路径[7]。ZHANG B提出了一种受鸽子启发的算法来规划UCAV的三维路径[8]。李志锟等[9]对信息素分配和信息素含量的方法进行优化,并在引入权重参数改进转移概率公式。
粒子群优化算法(particle swarm optimization,PSO)是由Kenned博士和Eberhart教授通过观察群体动物捕食行为发明的一个进化计算方法[10],灵感来自于自然生物的运动表征,研究员发现个体之间通过某些简单的交互方式能够完成整个群体的繁杂活动,局部最优通过某种搜索规则和个体之间相互作用产生全局最优解。PSO最初用于解决非线性连续优化问题,主要应用之一是机器人的路径规划[11-12]。由于PSO需要配置的参数较少,并且数学模型较为简单,不涉及比较复杂的数学计算等优点,吸引了很多学者的关注并对其进行研究和改进,以方便实际应用。然而,标准的PSO存在着提前收敛和全局收敛缺乏保证的缺点,这限制了其在实际系统中的应用,于是很多学者对其进行了改进。文献[13]引入多个因子参数动态调整算法参数,并使用鱼群的跳跃机制增加粒子的多样性。XIE M将最大化采集数据量、路径安全性和最短行驶距离作为优化目标,并使用最小-最大归一化方法计算适应度[14]。Girija提出了将人工势场和粒子群结合的混合算法[15],该方法将PSO与有源滤波器相结合,提高了在高障碍物密度环境下确定可行且代价最小路径的速度,并且能够在较短的时间里,规划出安全的可行驶路径。本文提出了将粒子适应度差值作为算法的反馈信号来动态调节惯性权重和引入随机因子的改进粒子群算法(improved particle swarm optimization,I-PSO),为自主电动机器人或车辆在具有许多不同形状和大小的静态障碍物环境中找到从起点到目的地的无碰撞全局路径。
1 环境模型
对运动空间抽象出模型是执行路径规划算法的前提,其作用是将机器人的工作空间映射成路径规划算法可以使用的抽象空间。将工作空间抽象成合理的模型能够方便计算机存储和计算,并且可以缩短优化算法探索的时间。为了方便对空间环境建立数学模型,本文采用的是根据栅格法建立的二维地图模型。将周围环境看成二维平面,将平面进行等面积的栅格化处理,空间中无障碍物位置对应的单元格,用白色填充,障碍物位置对应的单元格,用黑色填充,栅格中的数字代表机器人通行该位置所需要的能量值。目标是在基于栅格的地图上找到1条能够使机器人安全通行并最终到达目标点的路径点集合,且这个集合组成的路径是所有能到达目标位置的路径中长度最短的。路径规划中需要考虑的重点是所选路径既不能在障碍物位置,也不能与障碍物位置交叉。地图模型如图1所示。
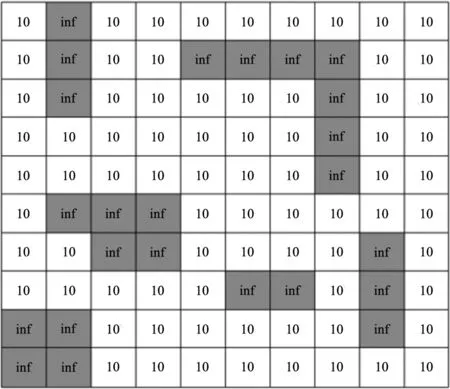
图1 地图模型
为了保证机器人不与障碍物发生碰撞,单元格的大小应综合考虑实际环境空间和机器人的尺寸大小,并且在构建栅格地图时需要对空间中的物体及机器人活动区域边界进行放大,障碍物的大小应向外延伸到机器人自身物理半径与安全距离之和,这样在路径规划时就可以把机器人看作质点。
2 路径规划数学模型
规划路径的目的是寻找1条满足多个约束条件的路径曲线。本文将最短路径和障碍物碰撞风险作为量化寻找路径的标准。
2.1 路径长度函数
在路径规划方向,最短路径意味着最小化出发位置到目标位置的路径长度,使用欧几里得距离计算2个位置坐标的长度。
(1)
式中:(xi(t),yi(t))代表粒子i在t时刻的坐标位置。
在迭代中,如果第i个粒子的位置与目标点和起点之间的距离最短,则被选为最佳点。路径规划算法计算出中间节点、起始位置和目标位置之间的连线长度的累加。
(2)
式中:f1是最短路径的目标函数;(xs,ys)是规划任务的起点坐标;(xg,yg)是规划任务的终点坐标。
2.2 碰撞风险
机器人最重要的目标是不能与工作环境中的障碍物接触并保持一定的安全距离。因此,需要判断得到的路线是否与障碍物有交点,或者与障碍物之间的距离太近。为了判断路径是否可靠,本文采用下式计算路径的碰撞风险。
(3)
(4)
(5)
式中:(xi,yi)是第i个粒子搜索到的路径节点;(xod(k),yod(k))是地图中第k个障碍物的中心坐标。
基于以上2个数学模型,构造包含避免与其路径上的障碍物碰撞和最小化机器人规划出的路径欧氏距离的目标函数。函数是通过2个目标函数的加权获得。
F=λ1f1+λ2f2
(6)
式中:λ1、λ2分别是最短路径权重和碰撞风险权重。
3 I-PSO的路径规划
PSO的消息分享方式可以看成一种协作共生的行为,也就是每个粒子都不断探寻搜索空间,在其探寻过程中,种群中其他粒子对它的动作也会有不同程度的影响,同时粒子还会记录过往的最优答案,即其探寻最佳答案的过程会同时受其他粒子影响和自身经验的指引。假设在1个D维搜索空间中,存在N个粒子,每个粒子都会根据下式来迭代更新自身的坐标和速度。
vi(t+1)=ωiυi(t)+c1r1(t)[pi(t)-xi(t)]+c2r2(t)[pg(t)-xi(t)]
(7)
xi(t+1)=xi(t)+vi(t+1)
(8)
式中:ωi是粒子i的惯性权重;pi(t)是粒子i在t时刻搜索到的最优位置;pg(t)是t时刻搜索到的全局最优位置;c1是设置粒子向个体最优方向每次运动长度的群体学习因子;c2是设置粒子向群体最优方向每次运动长度的群体学习因子;r1和r2为[0,1]范围内的均匀随机数;vi∈[-vmax,vmax],vmax是粒子的最大速度。
粒子的个体极值pi更新函数定义为式(9)。
(9)
式中:f(xi,(t))是适应度值。
整个群体的全局极值pg的更新函数见式(10)。
pg(t)=min{f(p1(t)),f(p2(t)),…,f(pD(t))}
(10)
式中:f(p1(t))是个体极值。
3.1 惯性权重的调整
为了权衡粒子的全局探索和开发特性,可以改变每个粒子移动速度的惯性权重因子,而且惯性权重ω的值越大,种群的全局探索能力就会较好,当ω的值越小时,粒子群的局部搜索能力会较强。因此可以通过灵活地调整ω的方式,决定种群在搜索过程中何时增大全局搜索或者加强局部搜索。
(11)
(12)
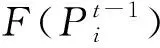
3.2 学习因子的调整
在种群搜索过程中,让c1维持较大的值能不断扩大种群的探索区域,但是这样会导致算法过慢收敛。让c2维持比较大的值能使粒子尽可能的获取邻近粒子的信息,从而加快算法的寻优速度,但是得到的解可能不是最优的。因此加速度的取值方法对是否能够找到最优解有很大作用。为了让粒子在算法初期尽量多的执行全局搜索,在算法后期拥有显著的收敛速度,应在算法前期适当增大c1且减小c2,在算法后期适当减小c1,同时增大c2。加速因子的更新公式设计见式(13)和式(14)。
(13)
(14)
式中:c1b,c1e,c2b,c2e分别是粒子自身和群体学习因子的初始值和最终值。
为了降低掉入局部陷阱的概率,本文在更新粒子位置时,引入一个随机因子,以增加粒子探索的随机性。
Li(t)=Li(t)(1+r)
(15)
式中:Li(t)是第i个粒子在第t次的位置;r是[-0.1, 0.1]的随机值。
3.3 PSO流程
PSO流程如图2所示。
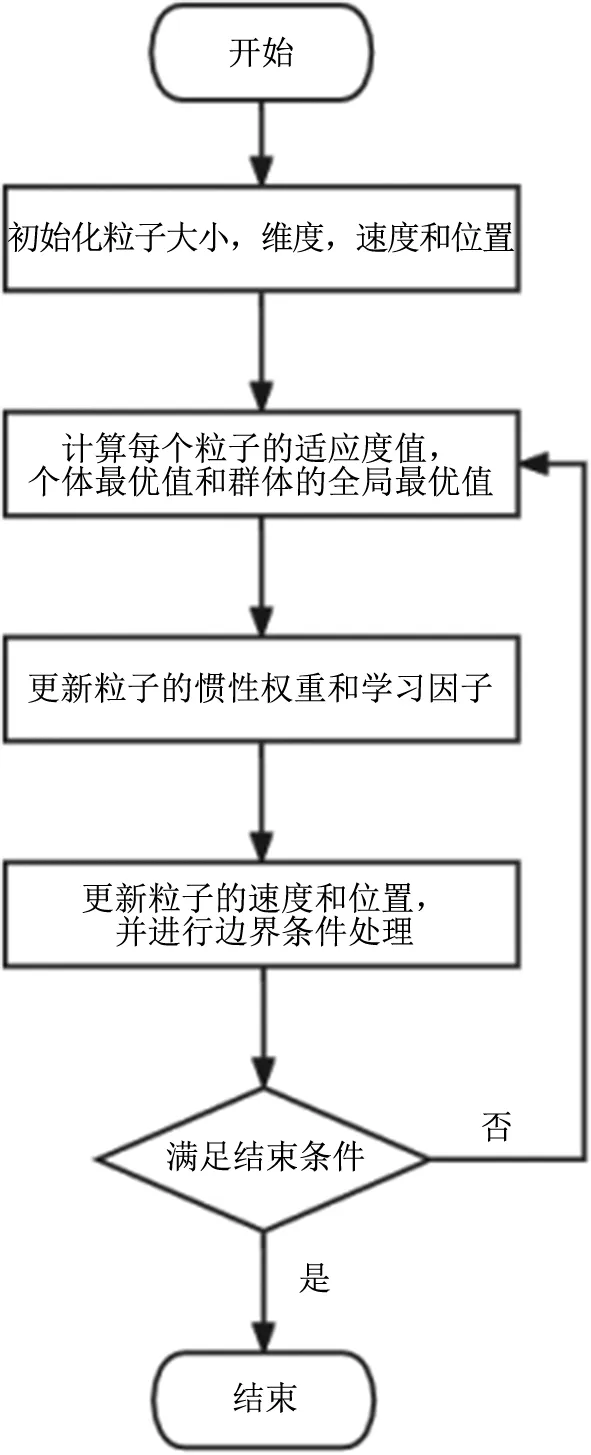
图2 路径规划流程图
a.设置N、D、tmax、Vmax,并初始化ω、c1b、c1e、c2b、c2e、v和x;
b.根据式(9)和式(10)计算粒子的F、p,并选出种群的pg;
c.根据式(11)—(14),动态调整每个粒子的ω、c1和c2。
d.根据式(7)和式(8),计算下一次迭代粒子的v和x。
e.判断是否达到规划任务的终止要求。若达到,结束迭代,否则转到步骤b。
4 仿真试验
使用MATLAB模拟二维栅格地图,使用I-PSO和标准PSO规划路径,结果如图3所示。为满足PSO的收敛和稳定条件[18],参数设置为:ωmax=0.8,ωmin=0.01,c1b=1.5,c1e=1,c2b=1,c2e=1.5,tmax=100,N=100,D=1,环境中设置较少的障碍物。
图3中,蓝色曲线是基于标准PSO规划的路径,红色曲线是I-PSO规划的路径,从图3可看出在障碍物较少时,2个算法找到的路径基本相同,都规划出了较优的路径。
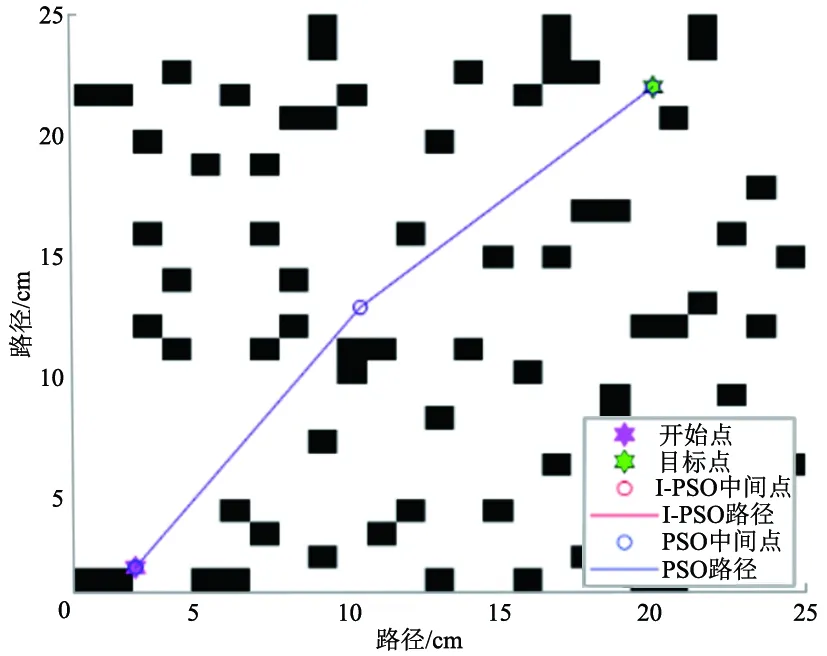
图3 规划的路径1
图4是2种PSO在迭代搜索最优路径时函数适应度值变化图形。I-PSO的适应度值迭代曲线,在迭代开始阶段,其值明显小于标准PSO的适应度值。在迭代中期,I-PSO的适应度值已经趋近于稳定。可以看出I-PSO较标准PSO在收敛速度和收敛效果上都更有优势,在简单的环境下能更快的规划出较优的全局路径。

图4 适应度值1
为了进一步验证算法的可行性,增加地图中障碍物的数量,以测试I-PSO在面对不同环境下规划路径的能力。搜索空间维度D=2,其他参数不变,然后进行仿真试验,得到规划路径如图5所示。
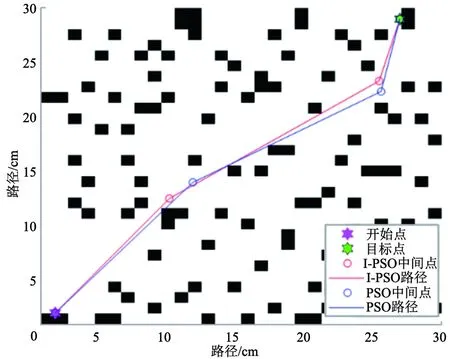
图5 规划的路径2
图5是改变工作环境内障碍物的密度后,2种算法在较为复杂环境下所规划的全局路径。图5中,I-PSO搜索到的安全路径相比于标准PSO规划的路径更趋近于直线,且轨迹长度更小。从图5可看出,当地图中的障碍物较多,环境较为复杂情况下,I-PSO相比标准PSO能找到更短的安全路径,且路径的拐点角度更小。
图6是障碍物较多时,2种算法在迭代寻找路径时的适应度值变化曲线。从图6可看出,当障碍物增多后,标准PSO在起始阶段收敛性较差,且算法的稳定性也不好,而I-PSO在起始阶段就能很快找到较好的解。
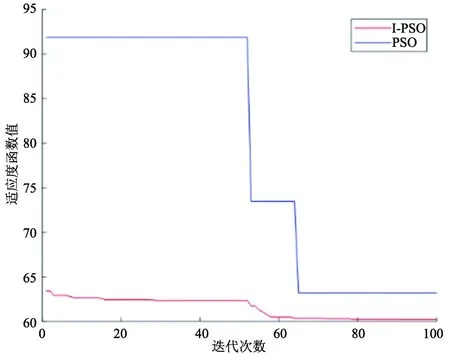
图6 适应度值2
图7和图8是在障碍物密度更大、活动空间更有局限性的环境下,2种算法规划的路径和对应的适应度值迭代变化图形。可以看出,I-PSO在更为复杂的环境下也能规划出安全、平滑和长度更短的全局路径。
由上述在3种环境下仿真得到的试验结果表明,本文提出的I-PSO较传统PSO能更快的规划出安全且距离更短的全局路径,并且在算法的收敛性和稳定性上都更优。
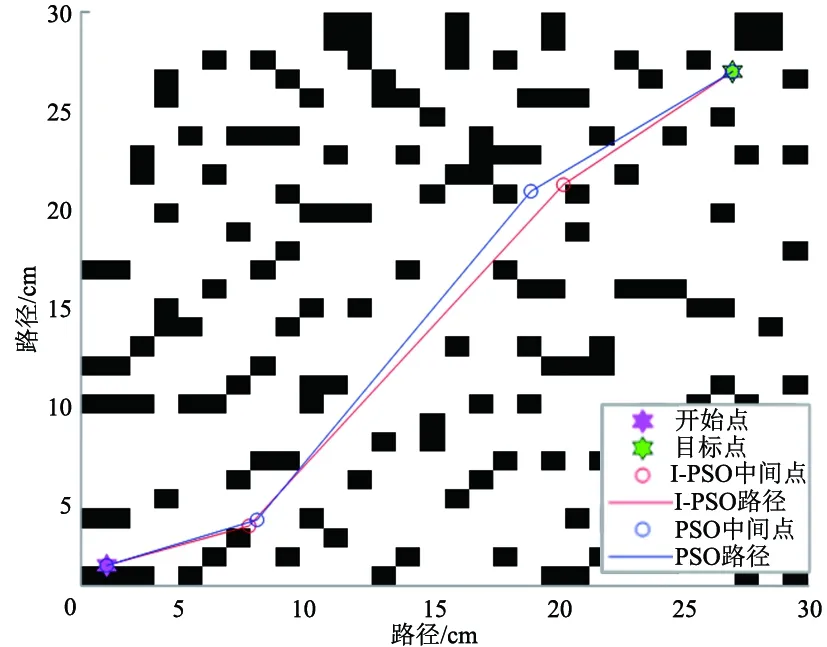
图7 规划的路径3
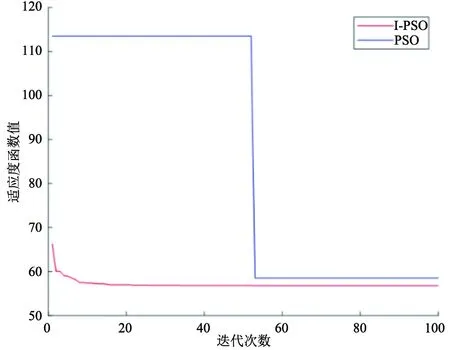
图8 适应度值3
5 结语
本文使用栅格法对机器人移动空间进行环境建模,为了使规划的路径更加安全、更适合机器人移动,建立了考虑路径长度、碰撞风险的路径规划数学模型。对于传统PSO在规划路径时存在易陷入局部最优以及收敛速度慢的问题,本文采用将粒子适应度差值作为算法的反馈信号来动态调整惯性权重的方式调节种群对搜索空间的整体或部分区域的搜索需求,并且引入随机因子尽可能避开局部陷阱,这种方法在处理PSO过早收敛和最优解质量较差的问题。MATLAB试验结果表明,提出的I-PSO具避障性能优越、规划的移动路径长度更短、路径更平滑等优点。
然而,本文主要解决的是在静态空间环境下的路径规划问题,缺少对动态障碍物的处理。在之后的研究中将对存在障碍物移动的环境进行数学建模,并将本文的算法进行改进,使其能在动态工作空间中进行规划路径。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
动漫界·幼教365(中班)(2020年3期)2020-04-20
创新作文(1-2年级)(2019年4期)2019-10-15
好孩子画报(2019年10期)2019-01-10
金桥(2018年4期)2018-09-26
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
当代贵州(2014年13期)2014-09-21
