
一种基于卷积神经网络的谱聚类算法
2022-09-06 05:52苏常保龚世才
安徽大学学报(自然科学版) 2022年5期
苏常保,龚世才
(浙江科技学院 理学院,曙光大数据学院,浙江 杭州 310000)
图像分割是计算机视觉中一个重要研究方向,目前图像分割已经成为计算机视觉领域的研究热点[1-2].所谓图像分割是指根据图像的一些特征如图像的色彩、空间纹理、几何形状等,把图像分割成若干个互不相交的区域,使得同一区域表现某种相似性,而不同区域则表现明显不同.从算法演进历程上看,目前的图像分割算法大致可以分为两大类:传统的和深度学习的图像分割算法.传统图像分割算法利用数字图像处理、拓扑学、数学等方面的知识来进行图像分割.而深度学习则是通过神经网络对图像提取特征,再对像素点进行预测达到对图像分割的效果.相比之下,深度学习图像分割效果更好,但是由于深度学习的图像分割算法训练的时候通常耗时又耗力,所以一些学者还是致力于考虑如何将两者有机结合起来.由于经典的k-means只能在凸球型数据集得到良好的聚类效果,而谱聚类则能在任意形状的样本空间执行并收敛于全局最优[3].谱聚类作为一种传统的图像分割算法,它结合了图论和聚类的思想,弥补了k-means聚类容易陷入局部最优解的缺陷[4],使得其可以适用于高纬度、非常规分布的数据集.人们发现基于图论的谱聚类算法在图像分割中具有良好的特性,所以谱聚类已经成为图像分割中一个新的研究热点.
关于谱聚类在图像分割中的应用,早在文献[4]中,作者就已经将谱聚类应用到图形分割当中了,不过主要是采用二分法在特征向量中分割.传统的谱聚类应用到图像分割中一般分为两步:根据图像构造相似度矩阵和在谱空间将图像信息进行聚类,由于相似度矩阵的分解容易对计算机造成内存溢出,并且时间上的消耗也是非常大的,所以许多学者对谱聚类进行改进.Inkaya 等[5]提出构建一种无参数相似图,即密度自适应邻域,它结合了距离、密度和连通性信息,反映了数据集的局部特征.Duan等[6]提出通过深度自动编码器生成深度嵌入,将数据降到适合聚类的维度,使用暹罗网络从嵌入中学习距离度量,进而构建更好的相似度矩阵.Luo等[7]提出了一种基于Pareto集成框架的分而治之的策略,采用多目标优化算法,进而确定相似度矩阵中的非零项和非零项的值.针对谱聚类在图像分割中相似度矩阵分解复杂度过高的问题,Fowlkes等[8]提出Nystrom近似方法作为一种低秩逼近的方法,对相似度矩阵进行特征分解并应用到图像分割中,大大提升了图像分割的速度.Boutsidis等[9]对少数幂次迭代能够获得近乎最佳的相似度矩阵的特征空间提供了一个严格的理论依据.Shaham等[10]结合深度学习,使用神经网络将原始数据映射到相似度矩阵的特征空间,避免了直接采用相似度矩阵求解原始数据的特征空间.这些改进的共同思想都是为了更好地构建原始数据的相似度矩阵,提高谱聚类分割的精度和降低在图形分割中的时间消耗和内存消耗.针对以上这些问题,论文基于谱聚类算法进行改进,并应用于图像分割当中.
1 基于卷积神经网络的谱聚类算法
传统的谱聚类算法随着深度学习理论被提出后,卷积神经网络的表征学习能力得到了学者们的广泛关注.Krizhevsky等[11]推出了AlexNet卷积神经网络,并在大规模视觉识别竞赛中一举夺冠,引爆了深度学习.自此,各种卷积神经网络被不断推出,其中具有代表性的网络架构有VGGNet[12],GoogLeNet[13],ResNet[14],DenseNet[15],Inception[16],Xception[17],MobileNet[18]和EfficientNet[19]等.学者们基于这些在图像处理方面得到认可的卷积网络,使用它们作为主干网络进行特征提取,通过上采样和反卷积操作还原图像,进而达到对图像的分割,其中最具开创性的一个经典的网络为全卷积神经网络FCN(fully convolutional neural network)[20].论文受到FCN的启发,采用训练好的VGG-19卷积神经网络对图像进行特征提取,某种程度上减轻了图像信息的表示对相似度矩阵的依赖,将其和谱聚类算法结合,应用到图像分割当中.
谱聚类算法应用到图像分割是将图像通过某种相似度度量转化为一种无向加权图G(V,E,W),其中顶点V表示图像的区域块或者像素点,这里统称为图像的子类;边E表示图像子类之间的连接边;W表示这些边之间的关系,通常用具体的数值衡量.由于W包含了这些子类之间的信息,可以运用某种划分准则,实现对图像子类的划分.常见的划分准则有比例割集、规范割集、平均割集、最大最小割集、多路规范割集.根据划分准则可以将谱聚类算法分为迭代谱聚类和多路谱聚类两大类,其中迭代谱聚类的经典算法有PF(perona and freeman)[1],SM(Shi and Malik)[4],SLH(Scott and Longuet-Higgins)[21],KVV(Kannan, Vempalaand Vetta )算法等[22],这些算法一般通过迭代实现对样本数据的划分.多路谱划分的经典算法有MS(Meilaand Shi)算法[23]以及NJW(Ng, Jordan and Weiss)算法[24].论文采用多路规范割集准则对图像进行划分,以NJW算法为基本框架进行改进对图像分割.虽然不同的算法选择的划分准则函数和谱映射的方法可能不一样,但是基本框架都是一致的.以NJW算法为例,步骤如下:
(1) 构造相似度矩阵W;
(2) 求解矩阵W的前k个最大的特征值所对应的特征向量,构建谱映射空间;
(3) 利用某种聚类算法对特征向量空间中的特征向量进行聚类.
1.1 特征提取器
卷积神经网络的特征提取是一个从浅层到高层、从低维到高维的一个过程.基于浅层的卷积层往往包含更多纹理、形状,轮廓等特征,而高层的卷积层则包含图像中小物体更多的语义信息.随着网络层数的加深,提取到的特征可视化后就越抽象,并且特征图的维度也更高.研究表明,VGG-19网络对于图像的边缘特征的提取在浅层网络中表现比较良好,所以论文选取VGG-19网络作为图像边缘特征提取器.
1.2 特征融合
VGG-19的网络结构如图1中的左图所示:一共由16个卷积层、5个最大池化层和3个全连接层组成.VGG-19网络普遍采用3×3大小的卷积核做特征提取,如图1右图所示.当输入一个5×5的图像时,卷积核为3×3大小,卷积核在输入图像上开始依次扫描,将卷积核与输入图像中对应位置的数值逐个相乘,最后汇总求和,得到该位置的卷积结果.将此结果作为新的像素点对应到原图,通过不断移动卷积核,就可算出各个位置经过卷积操作后的新像素点.这样的操作,其实相当于一个卷积核把按照3×3排列的9个像素点通过线性变换聚合到一个新的像素点上,一次性分别捕捉了横、竖以及斜对角的3个像素.而VGG-19前两2个卷积层都设置了64个卷积核,即意味着每一层分别从64个维度对像素点进行聚合,通过小范围不断地聚合,加上有目标地训练卷积核中的参数,进而提取图像的边缘信息.为了与原图像素点一一对应,论文采用了conv1_2这一浅层网络的特征提取结果.这一层提取的特征图大小为224×224×64,224×224代表的是特征图的尺寸,64代表的是特征图的通道(像素点的维度).考虑到维度越高数据之间的相似度越难以区分,这里采用1∶1的比例将64个特征图叠加到一起,最终将得到一个224×224的单通道特征融合图.
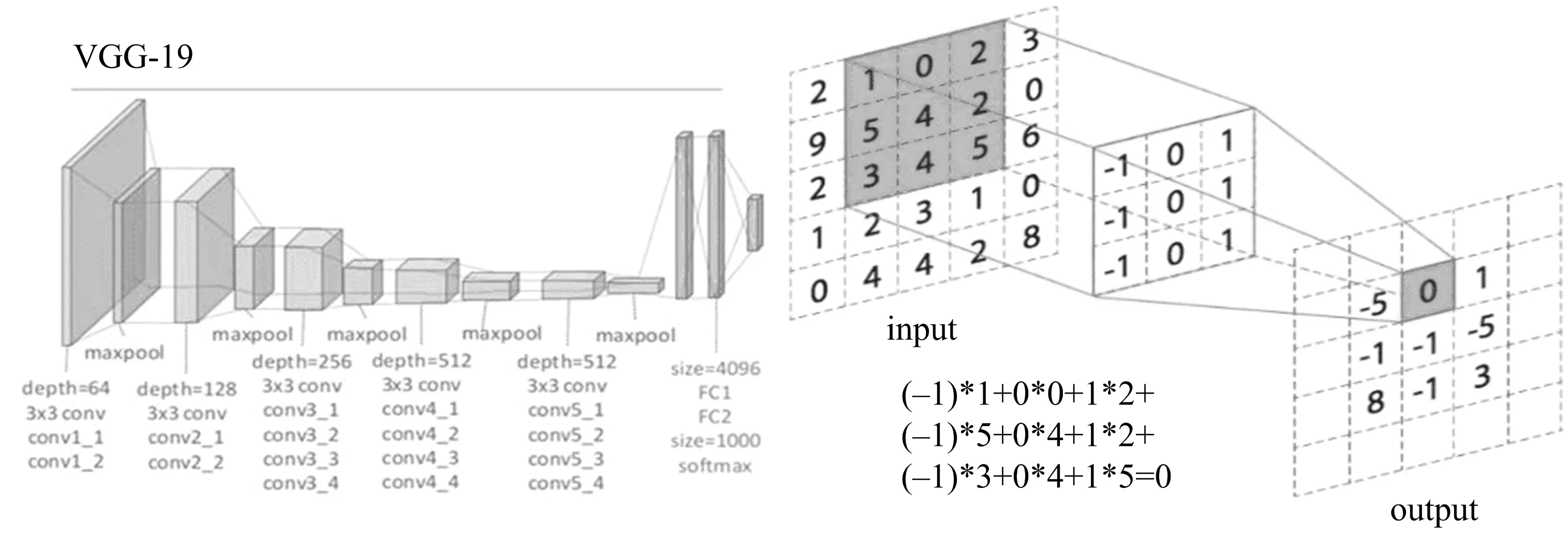
图1 VGG-19结构图
在谱聚类问题中,相似度矩阵的构造至关重要,因为它决定了样本信息的特征空间.许多研究人员使用深度学习中的卷积神经网络学习原始数据的深度特征,以便于后续更好地聚类[10,25-26].传统的谱聚类大多采用高斯核函数去定义相似度矩阵,即
wij=exp(-‖xi-xj‖2/2σ2),
其中:wij是相似度矩阵W的第i行第j列元素.由于高斯核函数中尺度因子σ往往是需要人工调参的,并且单一的尺度因子并不具有全局通用性,计算过程中难以调整到最优[27].而且经过高斯核函数计算相似度矩阵其计算消耗是非常大的,因为一次指数运算所消耗的时间是乘积运算的30多倍.而论文采用卷积网络对图片进行过特征提取和特征融合后,即认为图片的颜色、纹理、空间等信息已经大部分被提取到了,得到单通道的灰度图被认为是图像的特征表达.基于这些思想,在给定一张图片有n个像素点时,每一个像素点用xi表示,其中xi∈d,1≤i≤n,表示第i个像素点的特征有d个维度,论文算法中d=1.论文直接采用欧式距离构造加权连接图G(V,E,W),V表示像素点个数,E表示像素点之间的边,W=[wij]n×n表示相似度矩阵(权重矩阵),即
wij=‖xi-xj‖2.
(1)
1.3 基于Nystrom近似方法
谱聚类算法基于像素点分割时,其样本数据量是十分庞大的,所以构造的相似度矩阵规模也很庞大.由于矩阵特征分解的时间复杂度是O(n∧3),空间复杂度O(n∧2),那么谱分解将造成计算机的时间消耗和空间消耗也很大.根据文献[8],采用Nystrom近似方法去逼近相似度矩阵的特征.该方法的基本思想是通过抽取原始数据的少量样本,用抽到的样本和未抽取的样本之间的相似性去逼近原始样本的特征空间.具体做法如下:从n个像素点中,抽取1%的像素点m,m≪n,剩余未抽到的样本个数为n-m,则相似度矩阵W可被分解为
(2)
其中:A∈m×m是由抽取的m个像素所构成的相似矩阵,B∈m×(n-m)是由抽取的m个像素和未抽取的(n-m)个像素所构成的相似矩阵,C∈(n-m)×(n-m)是由剩下未抽取的(n-m)个像素所构成的相似矩阵.可以看出矩阵C是一个大矩阵,计算起来很复杂,所以根据Nystrom近似方法,将矩阵A对角化为A=UΛUT,令为W矩阵的近似特征向量,有
(3)
则W矩阵的近似矩阵为
(4)
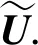
(5)
采用如下公式逼近D-1/2WD-1/2得
(6)
(7)
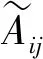
S=USΛSUST,
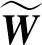
基于以上的思想,论文的算法步骤如下:
(1) 将输入的原始图片通过VGG-19卷积网络进行特征提取和特征融合;
(3) 通过Nystrom近似方法计算相似度矩阵W的特征向量V;
(4) 取S的对角化矩阵ΛS的前λ个最大的特征值对应的特征向量,构成矩阵X;
(5) 对X矩阵行向量进行归一化处理得到矩阵Y;
(6) 对矩阵Y的每一行采用k-means均值聚类,聚类的每一行的类别对应图像的每一个像素点;
(7) 根据像素点的类别,还原图像,完成图像分割.
2 对比实验与结果分析
论文所使用的数据集均来自BSD500[28]中的图像,图像大小在实验之前均被裁剪为224×224.算法实验代码在Windows10操作系统,CPU是intel(R)Core(TM)i5-5200U(2.20 GHz),内存为8 GB的计算机上通过python3.6实现.
为了验证论文算法的性能,论文将k-means聚类算法、基于Nystrom近似的谱聚类(快速谱聚类)算法与论文算法做了对比.由于论文实验的3种算法最终都要通过k-means算法聚类过程,故在实验时分别将聚类数目k设为2~8,通过反复实验,发现当k取3时,分割效果最好.为了从视觉上直观对比3种算法的分割结果,论文选取了部分实验图像做展示,如图2所示.

图2 算法分割图
图2第(a)~(e)行分别是原始图像、k-means算法分割效果图、快速谱聚类算法分割效果图、论文算法分割效果图、人工分割轮廓图.采用肉眼观察3种方法的分割结果,可以发现k-means分割出来的图最为模糊,主要体现在背景的噪声点太多,将图中的物体和背景混为一体.对比人工轮廓分割图,物体的轮廓分割不够明显.而快速谱聚类算法分割结果相比k-means分割结果图背景更加纯净,物体线条的分割越来越清晰,这是因为快速谱聚类是在谱聚类算法的基础上进行分割的.论文算法所分割的图像边缘轮廓非常清晰,和人工分割轮廓图基本一致,基本是将背景与图像中的物体完全分割开了.综上所述,论文算法的分割效果是最优的,证明了论文算法在性能上是优于k-means算法和快速谱聚类算法的.
通过肉眼评判图像的分割效果往往会受到主观因素的影响,为了进一步验证算法的有效性,论文采用精确率(precision,P)[29]、边缘召回率(boundary recall,R)[28]、F1值[22]3个常用的图像分割评价指标进行验证.
(8)
(9)
(10)
其中:P为精确率,R为召回率,TP表示真正例数量,FP表示假正例数量,FN表示假反例数量.用以定量分析论文图像分割的性能,衡量标准是以Berkeley大学的数据集给出的人工分割轮廓图,3种算法分割的指标如表1所示.
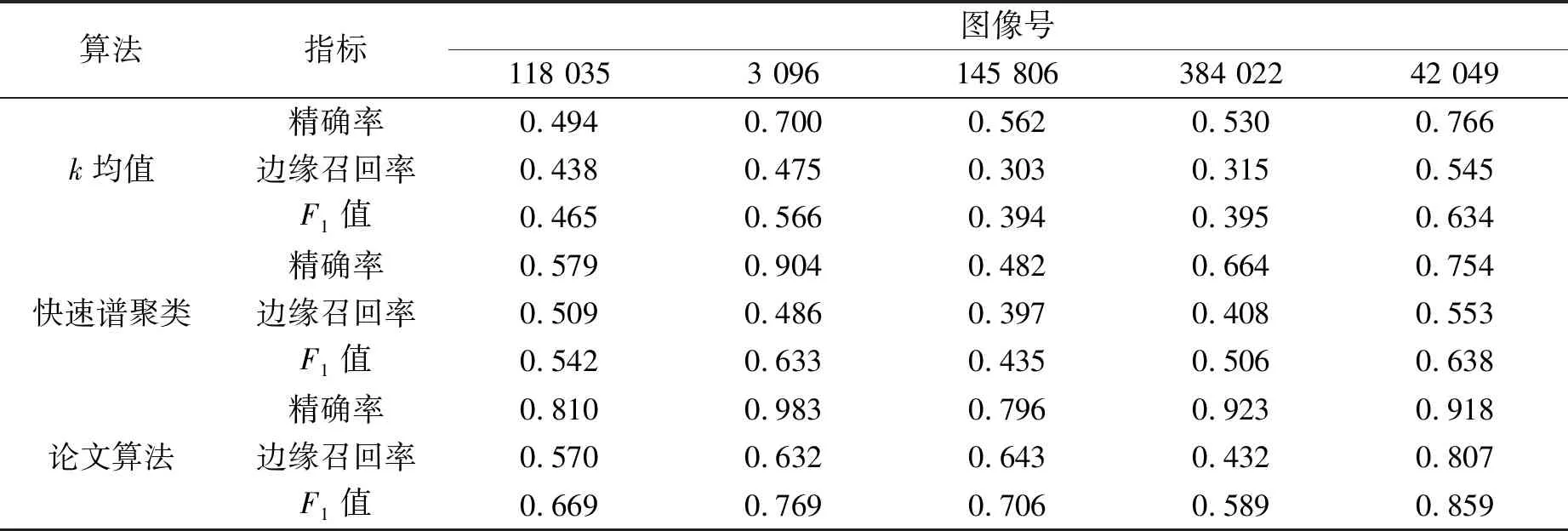
表1 3种算法的分割量化指标
从表1中可以看出,论文算法分割的图像在3个指标上均是最高的,因此客观上证明了论文算法在图像分割整体上是优于其他两种算法的.细看边缘召回率的值,发现论文算法的得分相比其他两种算法高,尤其是图像3 096,145 086,42 049,这也正是论文算法结合了VGG-19卷积网络的原因,使得在轮廓分割上处于绝对优势.
为了检验算法的时效性,论文将Berkeley大学测试数据中的200张图片分别用3种算法分割一遍,获得3种算法对一张图片的平均运算时间如表2所示.

表2 3种算法的运行时间对比
考虑到k-means算法的时间复杂度几乎是线性的[30],而基于谱聚类的算法时间复杂度是O(n∧3),所以k-means分割消耗的时间最短是可以理解的,但是论文算法相较于快速谱聚类算法时间消耗还是有所减少的,所以整体来看,论文算法在时效性上也取得了进步.
3 结束语
论文对传统谱聚类算法进行改进,结合当前学者的研究热点,使用深度学习模型中的卷积神经网络对图片单个像素点的邻近信息进行聚合,提高了原始数据的表征能力.为了减少传统谱聚类对计算机内存和时间的消耗,论文采用了Nystrom近似方法加速逼近相似度矩阵的特征空间,最终通过Berkeley大学数据集证明了算法的有效性和时效性.虽然论文算法的图像分割效果比传统谱聚类算法稍有提高,但是相较于深度学习的图像分割算法,在精度和时效性上还有待提高.
猜你喜欢
合肥工业大学学报(自然科学版)(2021年11期)2021-12-10
现代电子技术(2021年1期)2021-01-17
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
微型电脑应用(2019年1期)2019-01-23
电子制作(2018年19期)2018-11-14
现代计算机(2018年27期)2018-10-25
电脑知识与技术(2018年35期)2018-02-27
舰船电子对抗(2017年6期)2018-01-11
