
人类动作识别的特征提取方法综述
2022-09-06 13:16甘臣权张祖凡
计算机应用与软件 2022年8期
彭 月 甘臣权 张祖凡
(重庆邮电大学通信与信息工程学院 重庆 400065)
0 引 言
近年来随着数码相机、智能手机等视频拍摄设备的普及以及视频应用软件的大幅推广,网络视频业务呈现出指数级增长的发展趋势,视频载体已经成为人们日常生产生活中传播信息的重要媒介。视频中隐藏着巨大的信息,网络视频市场庞大的用户量、高速增长的市场规模给网络视频的管理、存储、识别带来了极大的挑战,因此网络视频业务日益受到各方的重视[1]。在以人为焦点的计算机视觉(Computer Vision,CV)研究领域中,如手势识别[2](Hand Gesture Recognition)、人体姿态估计[3](Human Pose Estimation)、步态识别[4](Gait Recognition)等任务,人类动作识别(Human Action Recognition,HAR)任务因其在人机交互、智能家居、自动驾驶、虚拟现实等诸多领域中应用广泛,日益成为计算机视觉领域中一个重要的研究课题。视频中的人类动作识别的主要任务是帮助计算机自主识别出视频中的人体动作,通过解析视频内容来推理人体的运动模式,从而建立视频信息和人体动作类别之间的映射关系。准确地识别出视频中的人体动作,有利于互联网平台对海量相关视频数据进行统一分类管理,有助于营造和谐的网络环境。此外,HAR技术的发展也促使了视频异常监控业务的成熟,在公共场合中能辅助社会治安管理人员迅速对危机事件做出预测,在家庭生活中能及时监控用户的异常行为(如晕倒、摔跤等)以便及时就医[5]。因此,对视频中的人类动作识别这一任务进行深入研究,具有重要的学术意义和应用价值。
动作识别任务的实现过程一般可分为两个步骤:动作表示和动作分类,动作表示又被称为特征提取,被认为是动作识别的最主要任务。本文主要将人类动作识别相关特征提取算法分为基于传统手工特征的方法和基于深度学习的方法,分别从视频中提取手工设计的特征和可训练的特征[6]。传统的特征提取方法依赖于相关领域的专业知识,往往需要根据不同的任务进行特定的特征设计,识别算法的性能严重依赖于数据库本身,增加了不同数据集上处理过程的复杂度,泛化能力和通用性较差。并且,在现如今信息爆炸的时代背景下,视频数据的爆炸式增长无疑给手工特征的制作带来了巨大的挑战,因此人们更倾向于采用非人工的方法提取更具有一般性的特征表示以满足现实任务需求。深度学习(Deep Learning,DP)在语音、图像识别等领域中的重大突破鼓励了其在计算机视觉领域中的应用。随着海量数据的爆发与GPU等硬件设备的快速发展,深度学习更能契合时代特点,提升了从大规模视频数据中迅速挖掘出有用信息的可能性,在HAR任务中逐渐成为一种不可或缺的研究方法。基于深度学习的方法通过构建一个层级的学习训练模式,借助模型与标签在输入与输出数据之间建立层层递进的学习机制,自主获取原始视频数据的动作表征,从而克服了手工特征设计的缺陷,是一种更为高效且泛化性能更好的特征提取方式。
本文从基于传统手工特征的方法和基于深度学习的特征提取方法两方面对人类动作识别领域中的特征提取方法进行了分类与总结,如图1所示,最后概括了动作识别领域中所面临的困难和挑战,并总结了未来可能的研究方向。
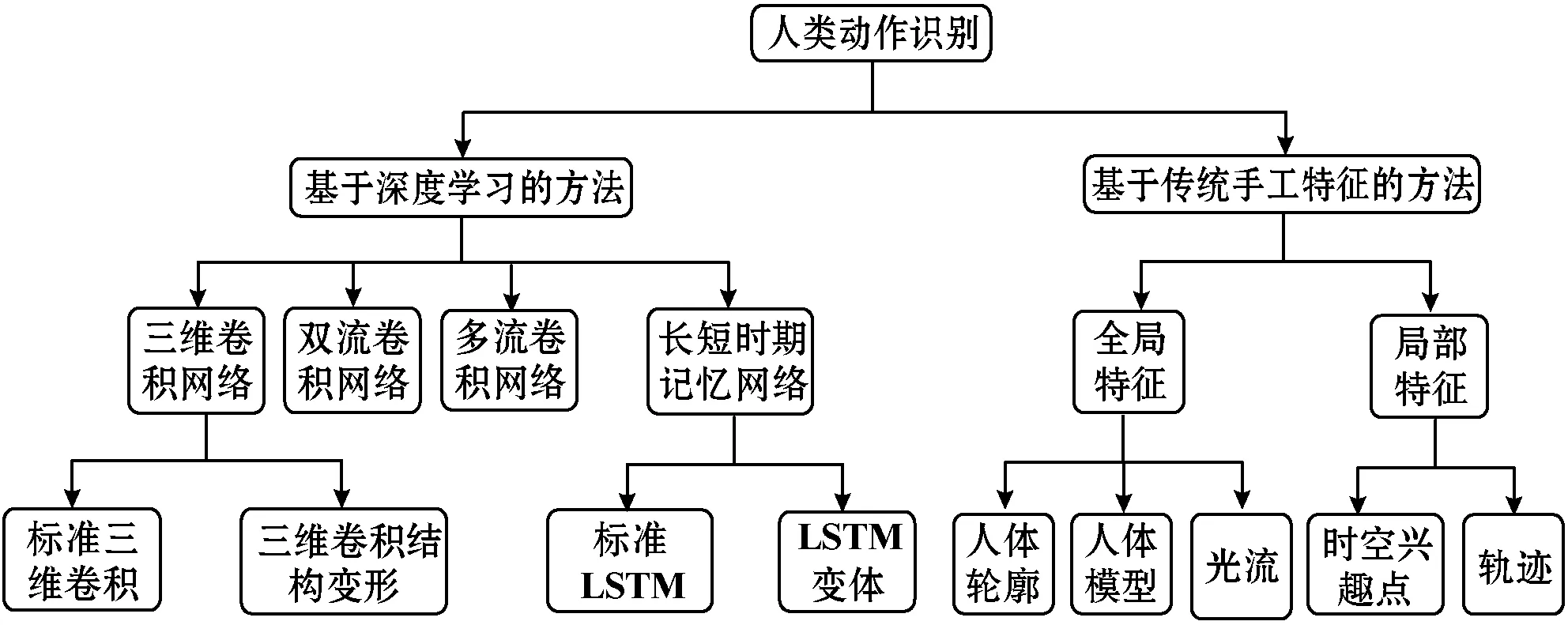
图1 人类动作识别特征提取方法总结
1 传统手工特征提取方法
大多数传统动作识别算法都依赖于人工设计特征的方法,其目的是从原始视频输入中剖析人体的运动模式并提取对应的底层特征,将视频数据信息转化为可以被分类模型所理解的特征向量,以便将原始的视频数据映射为相应的动作类别标签。视频数据不仅包括了静态的场景信息,还蕴含了丰富的动态变化,因此针对视频分类,稳健的视频特征表示除满足区分性与有效性两个基本特性之外,还需要包含大量的时间信息和空间信息,增加了手工设计特征的难度。传统的手工特征主要分为全局特征和局部特征,其对应特征提取算法优缺点总结如表1所示,接下来将从这两方面出发对相关算法进行总结与对比。
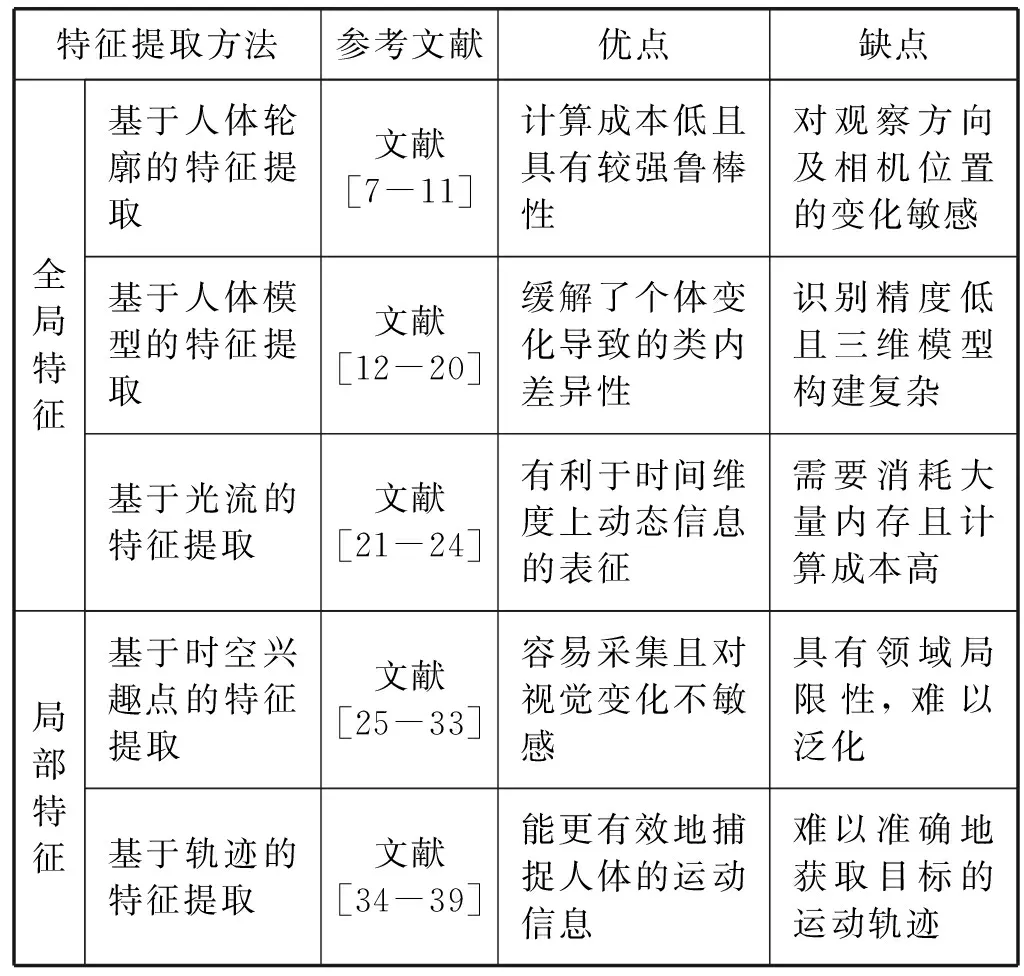
表1 传统手工特征提取方法总结
1.1 全局特征提取
动作的全局特征表示是出于对运动目标的整体描述,通常需要先用背景相减法或目标跟踪法将视频中的人体分割出来,再进行全局特征的提取。常用的全局特征包括基于人体轮廓的特征、基于骨架的特征与基于光流的特征。
(1) 基于人体轮廓的特征。早期的动作识别研究大多数都依赖于人体轮廓特征,通过特定的算法设计在时域中反映出人类动作序列的排列组合情况,通常需要预先建立各个动作类别的样本模板,在分类过程中将待测动作模板与所建立的标准模板进行比对,然后选择相似性最大的模板作为其最终分类结果。较为常见的人体轮廓特征有运动能量图[7](Motion Energy Images,MEI)和运动历史图[8](Motion History Images,MHI),通过从特定的方向来观察与给定动作相关联的粗粒度图像运动,从而保存人体动作信息。其中,MEI通过描述人体在空间中的位置移动及其能量的空间分布情况,反映了运动的轮廓以及动作发生强度;MHI通过观测视频帧中人体在某一时间段内同一位置的图像亮度变化情况,反映了运动发生的时间及其在时域上的变化情况。文献[9]在捕捉到运动片段的MEI的基础上提取其增强的Gabor张量特征,最后进行子空间投影得到有效的运动描述符。文献[10]在图像序列的MHI特征的基础上利用不同的几何矩对其进行特征编码,在不损失信息量的前提下提升了计算效率。基于人体轮廓的特征提取方法计算成本低且具有较强的鲁棒性,得到了广泛使用[11]。
人体轮廓特征是一种基于视觉的描述方法,在观察方向以及相机位置发生改变时容易受到影响,导致识别结果不准确。此外,该方法对分类过程中所需要的标准模板的精度要求较高,而模板的精确度高低依赖于数据库的样本容量大小以作为其计算的支撑。
(2) 基于人体模型的特征。由于人类的运动模式可以抽象成简单几何结构所表示的骨架的移动情况,基于人体模型的相关研究也成为了HAR领域中的一个重要方向,它通过视频帧之间人体关节点的变化来直观地描述人体动作,可以划分为二维表现形式[12]与三维表现形式[13-14]。二维模型利用二维几何形状(如:矩形、椭圆形、不规则形状)表征人体各部分,然后通过从图像中提取到的底层表观特征来估计相应模型参数与对应模型进行匹配,以区分头部、身躯与四肢等不同的身体区域,通过各几何图形的移动变形来描述具体的运动模式。文献[15]利用不规则的二维剪影图像来近似人体运动轮廓,并从中抽取图形节点的直方图以得到分类特征向量,该方法不需要精确定位人体关节信息,节省了计算开支。但二维模型不能表征运动过程中的人体距离信息,因此当运动过程中出现自遮挡、碰撞等情况时,估计到的运动模式会存在较大误差。为缓解上述问题,文献[16]利用深度相机估计不同人体骨骼关节的位置,并使用关节之间的夹角变化序列来刻画人体动作。文献[17]通过定位每一视频帧中人体的关节位置坐标来提取相应的姿态特征。文献[18]通过三维扫描设备获取静态的人体模型数据,然后利用蒙皮算法实现骨骼数据的绑定,从而重构实时运动模式。骨架特征精确地表征了静态人体姿态,但弱化了动作的时间演变,因此文献[19]将骨架特征与RGB数据相结合,基于RGB数据构造时间图像以表征动作的动态变化。当人体部位出现遮挡情况时,会严重影响基于骨骼数据的动作识别精度,而深度信息包含丰富的距离信息,缓解了骨骼数据的遮挡问题,因此文献[20]结合了深度信息与骨骼数据两种模态的优势,避免了单一输入模式的缺陷。三维模型利用圆柱或圆锥等几何模型来与人体构造模式相对应,通过结合人体运动学等先验信息与深度信息完成相关数据的估计,克服了二维模型在处理自遮挡与运动碰撞等问题时的缺陷。
基于人体模型的方法通过套用统一的人体模型来代表任意个体,一定程度上缓解了个体变化所导致的类内差异性,但是将复杂人体动作粗略地简化成一种僵化的几何模式,单纯地利用关节点变化来进行动作识别会产生较大误差。此外,三维模型所需的深度信息需要通过昂贵的摄像设备进行采集,模型的构建也将更加复杂。
(3) 基于光流的特征。光流一般由前景目标自身的运动、相机拍摄视角的移位或者两种现象同时发生的情况所产生,其计算依据建立于图像的亮度变化仅仅来源物体的移动这一假设之上,通过利用相邻帧上的像素点在时域上的亮度变化情况来反映人体的运动情况。文献[21]通过一个基于计算光流的描述符来描述远距离人类运动,通过追踪每个稳定的人类图像轨迹并计算其模糊形式的光流而非精确的像素位移来近似人类运动的平滑轨迹。文献[22]利用光流场中兴趣点的密集程度追踪运动过程的人体位置,并利用水平方向和垂直方向的平均差值与标准差值对其定位进行进一步的评估。文献[23]为减少光流提取过程中所需的计算量,利用光流的关键点轨迹在频域的多尺度表征来推理人体的运动情况。文献[24]将光流特征与MHI相结合以准确跟踪运动对象在某一段时间内的运动状态。光流特征因其在时间维度上良好的运动表征能力,在动作识别领域得到了大面积的应用,但光流特征易受到光照和遮挡的影响,且采用光流数据作为输入的模型内存需求大、计算成本高昂。
总体而言,基于全局特征的表示方法受限于相机运动、光照变化等因素,且需要去除背景、前景提取、人体定位与追踪等预处理操作,因此在复杂动态背景情况下对于运动的表征能力效果不佳。
1.2 局部特征提取
为避免预处理操作,局部特征表示方法侧重于视频中的感兴趣点的检测,并将人体动作局部表示进一步编码为用于分类阶段的特征向量,在特定的动作识别任务中分类效果良好。常见的局部特征包括基于时空兴趣点的特征和基于轨迹的特征。
(1) 基于时空兴趣点的特征。基于时空兴趣点的特征提取方法可分为兴趣点检测与特征点描述两部分。首先通过检测器检测出时空兴趣点,即时空中突然发生变化的点,利用时空兴趣点构成的点集来表示人体动作,然后利用描述子将兴趣点编码为分类器能理解的特征向量,从而描述动作信息,因其容易采集且对视觉变化不敏感等优点在复杂背景下的动作识别任务中备受推崇。Harris3D特征检测器[25]将空间域上的角点检测扩展到了时空域,通过融合梯度直方图(Histogram of Oriented Gradients,HOG)特征和光流直方图(Histogram of Optical Flow,HOF)特征以得到局部描述子,进而描述局部运动。在此基础上,文献[26]利用哈希方法和稀疏编码方法对最终的特征编码进行了改进,但是该方法产生的描述子对噪声、尺度和角度变化敏感。为克服上述缺点,文献[27]利用一种尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算法来检测帧序列中的关键点,但该方法仅考虑空间维度上的外观信息,忽略了人体动作在时间维度上的演变。因此3D SIFT算子[28]在时间维度上对SIFT算子进行了扩展,以期准确地描述视频数据的时空特性,得到了良好的局部时空特征描述符。但是对于模糊图像和边缘平滑的图像而言,其检测出的特征点较少,增加了动作识别的难度。为克服视觉变化敏感问题,文献[29]将时空兴趣点特征与局部光流特征结合起来,通过提取不同兴趣区域的光流直方图与视频片段词袋直方图来构成混合特征,缓解了遮挡问题。文献[30]将HOG与三维空间里的散射变换系数相结合,提出了一种鲁棒性更强的局部描述子。针对视觉范围的局限性问题,文献[31]将3D时空兴趣点扩展到了四维空间,以强调动作随时间的变化。为克服Harris兴趣点检测算法缺乏尺度信息的缺陷,文献[32]将其与Laplace尺度空间相结合,提出了改进的Harris-Laplace检测算法。但时空兴趣点的筛选条件较为苛刻从而导致选中的兴趣点个数较少,进而影响识别精度,因此文献[33]提出一种基于光流场旋度的兴趣点检测方法,降低了筛选难度。
基于时空兴趣点的特征检测得益于角点检测器的发展而容易提取且得到了普遍采用,但是它利用一些不关联的点的集合形式来描述人体动作信息,局限于现实场景中人体运动的复杂性,因此该技术很难得到实际应用。
(2) 基于轨迹的特征。人类的运动轨迹中蕴含着丰富的运动信息,且轨迹速度、方向的突变点的区别表征着不同类别运动,基于轨迹的特征提取方法主要包括对特征点进行密集采样与追踪、基于轨迹进行特征提取、特征编码三个步骤。为有效地捕获运动信息,文献[34]通过以不同的尺度来采样每一帧的局部模块的稠密点,并在密集光流场中对其进行追踪,以提取运动物体的稠密轨迹,同时从图像的底层特征入手,通过组合每个稠密点上的HOG和HOF等特征进一步提升了性能。文献[35]定义了轨迹运动相关性,以确定分类过程中不同轨迹的相应权值,用以权衡与目标动作更为相关的运动轨迹。为提取优质的轨迹特征,文献[36]通过补偿相机运动对稠密轨迹特征进行了改进,在追踪视频中的人体运动轨迹时,沿着光流场中的运动轨迹提取HOG、HOF、MBH和密集轨迹等特征,并采用特征词袋(Bag of Word,BoW)或费舍尔向量(Fisher Vector,FV)两种方法分别对特征进行编码,得到最终的视频特征表示,再使用支持向量机将提取到的特征表示编码到固定尺寸用于最终的分类识别。文献[37]结合显著性检测方法与改进稠密轨迹特征以期缓解相机运动对识别结果带来的影响。但无效的运动轨迹会影响模型判别能力,因此文献[38]在提取密集轨迹前利用运动边界策略进行采样以保存更有意义的轨迹特征。为减小相机运动的干扰,文献[39]利用动态高斯金字塔对快速鲁棒性特征进行了改进,并与IDT特征相结合从而减少了背景信息的干扰。为提高分类精度,需要确保人体的运动轨迹精确,但获取准确的轨迹本身就是一个研究难点。
与全局特征相比,局部特征不需要精确地定位出人体,对视角变化、复杂场景、遮挡等干扰不敏感,稳定性好,抗干扰能力强,且避免了预处理操作,但手工特征编码时需要的内存开销较大,而且局部特征缺乏外观上的细节信息,并需要额外的专业知识以进行特定领域的特征设计,具有领域局限性,难以泛化。
1.3 性能对比分析
为便于直观比较,表2给出了不同的传统手工特征提取方法在其对应数据集上的分类精确度对比,表2中数据直接来源于相应的原文献。由于多数传统方法并未采用统一的数据集进行实验分析,因此文中并未对涉及到的数据集进行详细介绍,仅在表2中给出了各数据集名称及其所包含的动作类别个数。
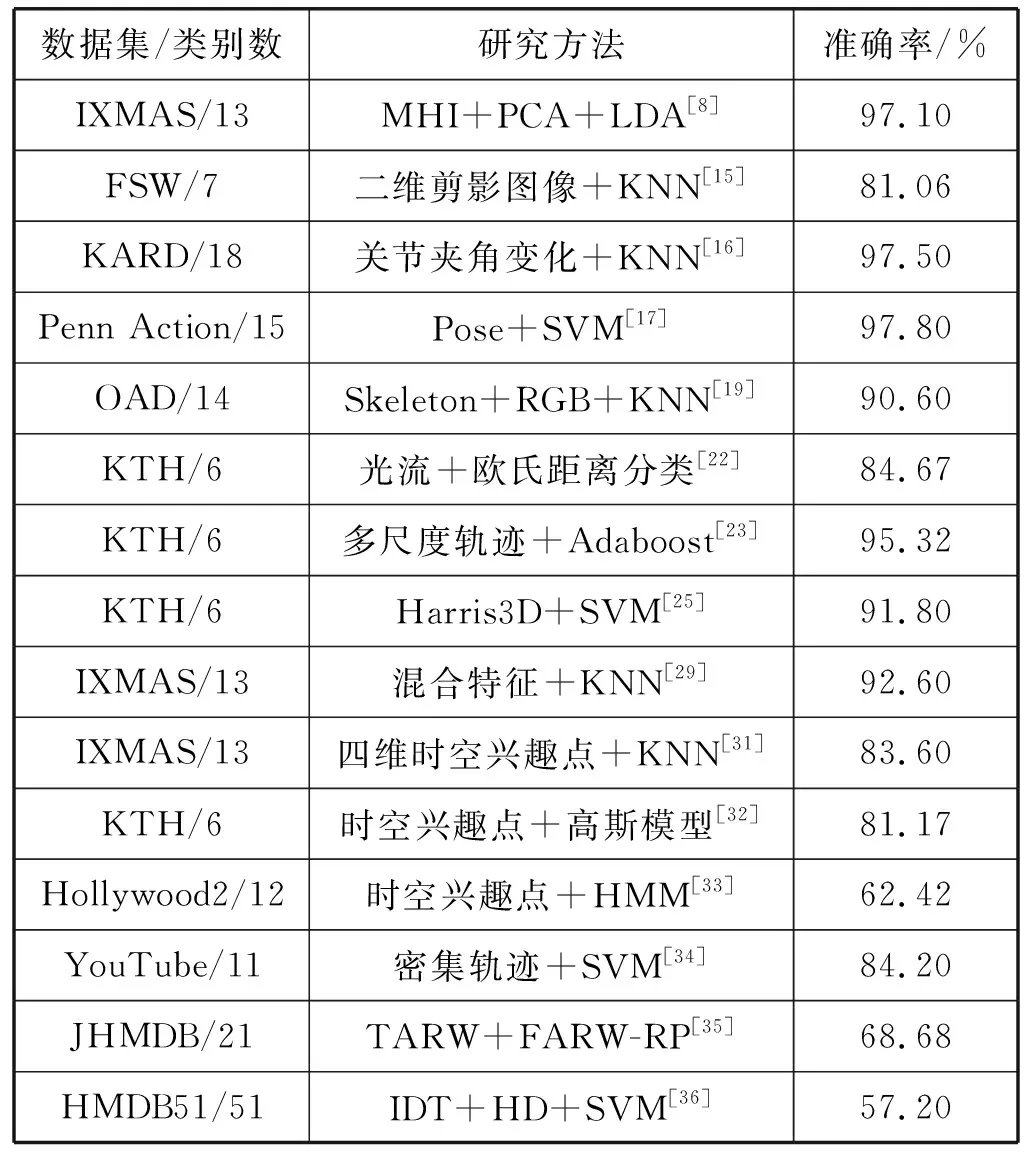
表2 传统手工特征提取方法的识别准确率对比
可以看出,多数传统的特征提取方法是在不同的数据集上进行实验,这是因为针对不同的分类任务需要进行特定的特征设计,从侧面印证了传统方法的领域局限性。而且利用传统的手工特征进行动作分类均需要分类器的参与(表2中LDA、KNN、SVM等均为常用的分类器模型),这种做法将特征提取与分类预测剥离为两个单独的步骤,得到的分类解不一定是全局最优结果。此外,大多数传统方法受限于计算复杂度,仅能对少数动作类别进行分类预测,表2中所涉及到的数据集多数都未超过20个类别,这并不满足实际应用需求。虽然文献[36]利用IDT等手工特征在HMDB51数据集上实现了对51个动作类别的识别,但其准确率较低,仅为57.2%,因此仅依赖传统的手工特征提取方法进行动作识别无疑是不现实的。
2 基于深度学习的特征提取方法
基于深度学习的特征提取方法从输入视频数据中自动学习可训练特征,克服了传统方法需要人工参与特征设计的缺陷,其识别性能更为高效,应用领域更加广泛,在HAR研究领域中掀起了一轮新的浪潮。根据神经网络结构设计的不同,基于深度学习的特征提取算法主要可分为:基于双流卷积网络的特征提取、基于多流卷积网络的特征提取、基于三维卷积网络的特征提取与基于长短时期记忆网络的特征提取。上述方法的优缺点总结如表3所示,接下来将从这四个方面对其相关工作进行讨论与总结。

表3 基于深度学习的特征提取方法总结
2.1 双流卷积网络
RGB数据具有丰富的外观信息,能直观地表示出人体形状与物体外观,补偿了传统方法中表观特征缺乏的不足,在动作识别领域中得到了大面积的应用。但仅采用单一视频帧作为模型输入只能表征单一时间节点的空间信息,因此为挖掘视频流的时间信息,文献[40]提出了基于RGB视频帧的后期融合(Late Fusion)、早期融合(Early Fusion)、缓慢融合(Slow Fusion)三种方法,但其识别效果与传统的手工模型相比还相差较远。为解决RGB单模态输入模型的识别性能受限于动态特征信息缺乏的问题,研究逐渐进入对多模态输入结构的探索。文献[41]将RGB与RGB-D两种模式共同作为模型输入,并探讨了不同数据类型的融合方式对分类器性能的影响。文献[42]将RGB与Depth Frames两种数据相结合用于连续手势的分割与识别任务中。由于骨骼信息可通过RGB-D数据进行快速准确的估计,因此也有文献尝试将RGB-D与人体骨骼信息相结合以表示动作[43],但RGB-D数据采集困难,且带有额外的噪声信息干扰识别效果。
光流+RGB数据形式为使用范围最广的双流输入模式,文献[44]提出了著名的双流假设,即视觉信息可以被加工成两条路径:用于形状感知的腹侧流和用于运动感知的背侧流。源于此线索,文献[45]首次将双通道方法运用到动作识别领域中,将视频信息划分为空间信息与时间信息两个部分,其基本思路为先计算相邻视频帧之间的密集光流,然后将RGB视频帧与光流特征分别输入到Two-Stream结构中,分别训练双流CNN识别模型,最后融合两个网络的预测结果,其精度超过了传统动作识别方法,验证了光流信号对时间信息的补偿,证明了采取深度学习的特征提取方法替代传统手工设计特征的可能性。但该文献仅采用均值融合与线性SVM融合两种简单的方式来融合双流网络的识别结果,未考虑到两个卷积流之间的信息交互。为更好地融合双流网络的两路特征,文献[46]利用残差连接方式在时空卷积流之间建立起信息连接,以促进其信息交互。此外,文献[47]基于远程时间结构建模的思想构造了时域分割网络(Temporal Segment Networks,TSN),以RGB+光流两种输入模式分别作为不同网络流的输入,提出一种稀疏采样策略从给定视频中稀疏地采样一系列视频剪辑,不同于原始的双流网络结构采用相对较浅的网络,ClarifaiNet[48]作为卷积流的基础模型,该文献采取BN-Inception[49]网络分别进行特征提取,以实现准确率与模型效率之间的良好折中,然后对每一片段进行初步推断,通过各预测结果的“共识”来确定其最终所属类别,而且作者还提出了一种加权融合方法,让深度模型自适应地分配时间流特征与空间流特征在最终识别结果中所占的不同权重。为捕捉长时动态信息,文献[50]将双流网络与LSTM网络相结合以捕捉全局时空信息。文献[51]利用分段采样策略进行采样,并构建了时空异构双流网络,以实现长范围时序建模。文献[52]将TSN网络与时间金字塔池化方式相结合,通过构建多尺度时间特征建模长距离视频帧之间的依赖性。文献[53]构建了一种深度残差LSTM网络,并与双流网络相结合以提取全局信息。不同于传统时空双流网络采用并行排列的方式,文献[54]利用串行连接结合时空流网络,节省了硬件资源。为避免手动计算光流特征,文献[55]提出了一种多任务学习模型ActionFlowNet,从原始像素点出发,分别训练两个卷积流网络,在模型自动估计光流值的同时进行动作识别,模型不需要额外地进行手工设计,而是在带有真实光流值标签的数据集上训练模型使其自适应地学习连续视频帧之间的光流信息,在提取运动信息的同时降低了计算量。
双流模型利用两个卷积网络分别对时间信息和空间信息进行建模,一定程度上缓解了基于RGB数据的单流识别网络所面临的动态特征缺乏问题,但是以光流为代表的动态特征仅能表示部分时间信息,并且在视频中准确有效地提取光流本身就是一个亟待解决的难题。
2.2 多流卷积网络
为提高模型的描述能力,部分研究者丰富了模型的输入模式,将双流网络模型扩展到三流网络甚至多流网络,对不同的输入模式分别进行处理后再加以融合,用于后续的分类识别以期得到更具判别力的人体动作表征。
文献[47]在光流+RGB输入模式的基础上提出了扭曲光流(Warped Optical Flow)作为额外的输入模式,将这三种模式分别输入到TSN网络中,以探索多输入模式对模型判别力的影响。文献[56]将骨架序列特征按照不同的方向映射为RGB图像特征,并将其分别作为三流网络的输入,实现了多特征之间的信息交互。文献[57]提出了一个三流卷积网络,在光流+RGB数据的基础上提出了堆叠的运动差分图像(Motion Stacked Difference Image,MSDI)构成三模式输入,MSDI通过融合每个局部动作特征来建立用以表征全局动作的时间特征,将三种数据形式分别通过相同设置的卷积神经网络(即五个卷积层与两个全连接层的顺序堆叠)进行特征学习,以捕捉空间表观信息、局部时间特征、全局时间表示。文献[58]提出了动态图像的概念,使用排序池化和近似排序池化对RGB图像和光流进行编码,经训练后得到RGB动态图像流网络和动态光流网络,结合原始RGB网络和光流网络形成四流网络结构,利用其输出得分的均值来预测动作类。文献[59]利用RGB数据、光流和深度信息的多模态输入形式结合了多种特征类型的优势以提升模型识别效果。为提高有限训练样本情况下模型的学习能力,文献[60]在水平与垂直两个方向上提取原始视频帧的光流与梯度信息分别送入多流卷积网络通道,增加了训练样本数量。与上述文献对于不同的输入模式均采用相同设计的卷积流做法不同,文献[61]将深度MHI、骨架数据分别输入ResNet101与ST-GCN中提取对应的全局运动与局部运动信息,并结合RGB图像构成了三模态输入,考虑了目标与动作之间的依赖关系。文献[62]从特征级的光流正交空间出发,通过直接计算深度特征图的时空梯度,定义了光流引导特征(Optical Flow Guided Feature,OFF),该方法设计了三种子网络:特征生成子网络、OFF子网络与分类子网络,其中特征生成子网络由BN-Inception网络构成,并以RGB视频帧与堆叠的光流作为模型输入,分别提取对应特征,然后将其分别送入OFF子网络,得到OFF(RGB)与OFF(Optical Flow)两种新的输入模式,分别表征经OFF子网络处理后的两种数据类型,OFF子网络得到的特征通过堆叠的残差块进行细化,最后对四种模式输入到分类子网络分别进行分类预测,将融合结果作为最终的判别依据,获得了明显的性能增益。
基于多流卷积网络的动作识别方法虽然能够有效捕捉图像的空间特征,且更全面地补偿了单一视频帧所缺乏的时间信息,但输入模式种类越多意味着深度模型所需训练的参数量越多,这使模型的有效性大打折扣。此外,输入模式的增多也意味着对特征融合模块设计的要求也更高,增加了多流模型的复杂性。
2.3 三维卷积网络
基于三维卷积网络的特征提取算法的一般做法为将少量连续的视频帧堆叠而成的时空立方体作为模型输入,然后在给定动作类别标签的监督下通过层级训练机制自适应地学习视频信息的时空表征。三维卷积网络在时空两个维度上直接从视频数据中同时捕获具有区分性的视频特征,无须刻意设计时空特征融合模块,能有效地处理短期时空信息的融合问题,更好地促进了时空特征在识别判断过程中的相互交互。
(1) 基于标准三维卷积的模型。文献[63]将二维卷积网络扩展到三维空间,同时从时空维度提取视频特征。在此基础上,提出了多种3DCNN的变形,如C3D[64]、I3D[65]、Res3D[66]等。得益于GPU的发展,基于3DCNN的方法逐渐成为视频动作识别领域的主流方法。文献[67]利用多视图学习提取多个局部形状描述符,然后与3DCNN相结合将多个视图描述符进行融合,以提高分类特征的描述能力。文献[68]在C3D网络之前添加了一个缓冲区,实现了模型在视频流输入的同时执行实时分类预测。针对C3D网络层数较浅不利于学习深度特征的问题,文献[69]将残差思想与深度C3D网络相结合,在其中引入短路连接,避免了深度C3D网络会导致其学习能力退化的缺陷。但3DCNN较之于2DCNN倍增的参数量使得其相应模型在小数据集上进行训练易导致过拟合效应,因此文献[70]将密集连接方式应用到3DCNN中,并结合空间金字塔池化方式,减小了模型的训练难度。此外,研究者们采用迁移学习方法,在公共大型数据集对模型进行预训练后,再利用小数据集对模型进行微调。文献[71]受2DCNN在ImageNet[72]数据集上进行预训练后极大地促进了通用特征表示的获取的启发,针对3DCNN的巨大参数量是否会引起训练过程中的过拟合问题进行了研究,首次提出在Kinetics[73]数据集上从零开始训练多种3DCNNs模型(ResNet[74]、Pre-activation ResNet[75]、Wide ResNet[76]、ResNeXt[77]、DenseNet[78]),通过由浅(18层)到深(200层)的网络结构研究了在不导致过拟合的情况下该数据集可训练的深层结构的层数上限,证明使用Kinetics数据集训练深度3D CNN将追溯2D CNN和Image Net的成功历史。预训练缓解了常用小数据集的过拟合效应,是一种有效的初始化方式,能够加快模型的收敛速度。但在大型视频数据集上进行预训练操作需要昂贵的时间成本,因此文献[79]利用在图像数据集ImageNet上进行预训练后的2DCNN模型来构建3DCNN,其沿着时间维度堆叠相同大小的二维卷积核来重构三维滤波器,并且通过在帧序列上同时进行二维卷积来模仿视频流中的三维卷积操作,避免了在大型视频数据集中进行繁琐的预训练过程。但是视频数据包含许多无用信息,若对所有特征同等对待,会导致特征提取过程中包含大量不必要的特征,从而干扰识别结果并增加多余的计算量。
文献[80]表明人类在观察周遭环境时并非关注全部内容,而是将注意力集中在环境的显著性区域。部分学者受此启发,在特征提取算法的设计中引入了注意力机制,帮助模型在特征学习的过程中为目标区域分配更多的注意力资源,进而抑制冗余信息,在复杂的视频内容中快速筛选出关键信息。文献[81]提出了一种卷积注意模块(Convolutional Block Attention Module,CBAM),在二维残差网络结构的基础上构建了层级双重注意机制,将通道注意力与空间注意力依序添加到每一残差块中,但该网络结构忽略了对动作识别任务来说至关重要的时间信息。文献[82]在其基础上将二维残差注意结构扩展到三维空间,提出了一种三维残差注意网络(3D Residual Attention Networks,3DRAN),根据信道和空间注意机制子模块在每个三维残差块中依次推断所提取到的特征的信道注意映射和空间注意映射,使中层卷积特征序列性地在通道域和空间域中学习关键线索。文献[83]以残差网络为基础构建了一种双流残差时空注意(Residual Spatial-Temporal Attention Network,R-STAN)网络,该网络分支由集成时空注意力的残差块(R-STAB)堆叠而成,从而使R-STAN具有沿时间维和空间维生成注意力感知特征的能力,引导网络更加注重为具有不同判别力的时空特征分配相应权重,大大减少了冗余信息。文献[84]为克服3×3×3卷积核在时空域上感受野较小未考虑到整个特征图以及整个帧序列中的全局信息,提出了一种带有注意力机制的时空可变形三维卷积模块(Spatio-Temporal Deformable 3D ConvNets with Attention,STDA),沿时空维度同时执行帧间变形操作和帧内变形操作,自主学习在时空维度上的偏移量以自适应拟合视频中发生的即时复杂动作,从而产生更具区分度的视频表征,补偿全局信息缺失问题,更好地捕捉时空领域内的长期依赖性和视频中不规则的运动信息。
基于标准三维卷积结构的模型因其固有的内在结构在提取局部时空融合特征时具有先天的优势,但同时也存在很多局限性。基于标准三维卷积结构的模型所需训练的模型参数量十分巨大,增加了模型的计算复杂度与存储开销且不利于模型的迭代优化,导致模型难以迅速收敛到最优解。
(2) 基于三维卷积结构变形的模型。为减少模型的训练参数、提升计算速度、减小内存消耗,多种基于标准三维卷积网络的结构变形被提出。在早期的相关研究中,研究者将一层卷积核大小为3×3×3的标准三维卷积层近似为三个级联的卷积层,它们的滤波器大小分别为1×3×1、1×1×3与3×1×1,提升了模型的有效性[85],但这种做法相当于将模型的深度加深了三倍,导致模型难以训练。为解决上述问题,文献[86]提出了一种非对称三维卷积来近似传统三维卷积以改进传统3D CNN的计算复杂问题,通过将两层卷积核大小为3×3×3卷积层近似为一层卷积核大小为1×5×1、1×1×5与3×1×1的非对称三维卷积层,然后再堆叠多个不同的微网来构建非对称3D卷积深层模型,提高了非对称三维卷积层的特征学习能力且不增加计算成本。
此外,分解的时空卷积网络[87](Factorized spatio-temporal Convolutional Networks,FstCN)与伪三维网络[88](Pseudo-3D network,P3D)也被提出用于缓解三维卷积网络计算复杂的问题。文献[89]提出了一种基于三维残差网络的时空分解方法,将标准三维卷积操作解耦为级联的二维空间卷积与一维时间卷积,以更为紧凑的结构取得了良好的结果。随后,该团队又基于分组卷积从通道分离这一全新视角提出了一种通道分离卷积网络(Channel-Separated Convolutional Networks,CSN),将标准三维卷积分解为通道交互层(滤波器大小为1×1×1)与局部时空信息交互层(滤波器大小为3×3×3),前者通过减少或增加通道维度以加强不同通道之间的信息交流,后者利用深度可分离卷积的思想,摒弃了通道之间的信息传输而着重于局部时空信息之间的交互,降低了模型的计算量[90]。文献[91]将二维空间卷积核与一维时间卷积核按照三种不同的方式进行连接,然后将三种网络串接起来构造伪三维残差网络,降低了模型训练难度。文献[92]利用张量低秩分解理论提出了Fake-3D模块,选取C3D网络作为其基础架构并结合残差连接的思想,降低了C3D模型的参数规模且提升了识别性能。文献[93]证明了I3D较之于I2D的性能增益,同时对该模型中全3D卷积模块的冗余度提出了疑问,进而提出一种轻量级模型S3D-G,在底层网络中采用2DCNN提取空间特征,在顶层3DCNN模块中利用深度可分卷积构造分离的3D时空卷积,结合了2DCNN与分解的3DCNN以实现在计算速度以及识别精度上的更好折中。但上述模型受限于输入数据的时间维度仅能表征局部时空信息。
计算复杂度与内存消耗量限制了输入视频数据的长度,因此基于三维卷积网络的特征提取模型仅能表征短期时间范围内的人体动作,很难处理具有长时间跨度的视频数据信息,从而影响模型性能,因此长期时空序列信息能否获得充分的分析是提升视频动作分类准确性的关键。
2.4 长短时期记忆网络
为捕捉具有长时间跨度的动作信息,文献[94]设计了具有长期时间卷积核(Long-term Temporal Convolutions,LTC)的神经网络,通过同时卷积更多的视频帧获取更长的时间特征,但其参数量巨大,训练十分困难。文献[95]提出了一种Timeception模块,利用深度可分卷积构造temporal-only卷积核(T×1×1×1),通过堆叠多个Timeception模块以对视频进行长时序建模,但该模块选择牺牲空间信息来交换时序信息,在长期时序建模过程中可能会导致上下文语义信息被压缩,甚至丢失。基于长短时期记忆网络(Long Short-Term Memory,LSTM)的模型具体指在卷积神经网络的末端添加LSTM或者与之对应的变体结构,得益于其强大的序列建模能力,该方法也逐渐成为动作识别领域中的一个研究热点。
(1) 基于标准LSTM的模型。LSTM的引入不仅解放了输入长度,而且能更好地捕获长期视频数据之间的依赖性,文献[96]先使用卷积神经网络捕捉各个独立视频帧的特征,然后将CNN的特征按视频中的时间顺序依次送入LSTM中以获得时间相关性特征,以补偿CNN所缺乏的时间动态。除了探索视频帧之间的关联,LSTM还可用于建模不同视频片段之间的语义关系,文献[97]在经过kinetics数据集上预训练的I3D模型上引入了LSTM,利用I3D网络提取不同时刻的输入视频剪辑的局部时空特征,然后使用LSTM建模不同剪辑片段之间的时序依赖性,实现了高级时间特征与局部时空融合特征的结合。与上述方法类似,文献[98]将视频帧和光流两种模式送入3DCNN网络与特征融合模块,得到两种模式的融合特征,最后利用深层LSTM对序列性的融合特征进行时序建模,以强调模型表征连贯性动作的能力。文献[99]在3DCNN与LSTM网络的基础上引入了多任务学习,在建模视频帧之间的时序关系的同时强调了相关任务中所包含的丰富信息。为解决随着LSTM网络层数加深所引起的过拟合问题,文献[100]在递归网络中引入了残差连接构建伪递归残差神经网络用以提取时空特征。LSTM除了用于时序建模,还可用作编码-解码网络,文献[101]提出一种基于3DCNN的运动图网络结构(Motion Map Network,MMN),通过迭代的方式将整个视频所包含的运动信息集成到运动图中,然后LSTM编码网络将提取到的特征图编码为对应的隐藏激活形式,再通过输入层的解码网络重构近似输出,以探索视频序列之间的隐藏模式。
尽管LSTM具有强大的序列建模能力,但依然存有各种不足。标准LSTM仅考虑了单一方向上的序列信息,且采用向量化后的一维数据作为模型输入,易导致关键信息的丢失问题,因此CNN与LSTM变体结构的组合也开始受到研究者的青睐。
(2) 基于LSTM变体结构的模型。单向LSTM仅考虑了过去的序列信息,利用其对相似性较大的动作(例如跑步与三级跳)进行分类识别易产生混淆,所以预知运动的结果信息也至关重要。受此启发,研究者们采用Bi-LSTM网络对时间信息进行建模[102-103]。双向LSTM由两个不同方向的标准LSTM网络堆叠而成,具有前向、后向两条通路,将卷积神经网络所提取的特征送入后续的深层Bi-LSTM网络中进行依赖性探索,能帮助模型有效地提取动作发生的过去与未来的上下文语义信息,从而更有效地区分相似运动。文献[104]将双流3DCNN网络与双向LSTM相结合以期在视频流前后两个方向上对长期依赖性进行建模。但是将卷积层特征向量化后直接输入到LSTM中会破坏特征平面之间固有的空间位置相关性,从而干扰识别效果。
为保留特征图的空间拓扑结构,文献[105]结合了3DCNN和ConvLSTM,并将这两个网络所捕获到的二维特征送入2DCNN用于学习更深层次的特征,以实现任意长视频序列的动作识别。文献[106]结合多层密集双向Conv-LSTM后产生具有丰富时空信息的相应采样帧的特征图,然后与原始采样帧一起送入3D DenseNet网络,在考虑不同视频剪辑相关性的同时保留了卷积层特征平面的空间拓扑结构。文献[107]设计了一种仅使用RGB图像数据的轻量级架构,通过ConvLSTM和FC-LSTM在不同视觉感知层分别建模时序信息,有利于更好地融合局部空间细节特征与全局语义特征,增强了模型的综合表征能力。但是ConvLSTM结构在输入-状态以及状态-状态转换过程中利用其内部卷积结构显式地编码输入空间位置的相关关系与长期时间依赖性关系,其参数量较大,在小数据集上难以得到充分训练从而导致模型过拟合。针对上述问题,文献[108]提出了一种结合3DCNN和ConvGRU结构的深度自编码网络用于学习视频的时空维度特征,其性能与ConvLSTM相当,但前者参数量更少且更容易训练。文献[109]借助计算分解以及稀疏连接的思想,利用深度可分离卷积、分组卷积与混叠卷积替换ConvLSTM中的传统卷积结构,以获取冗余性分析。
基于CNN与LSTM网络相结合的动作识别算法能最大程度地利用两种模型的优点,在不均匀的时间跨度内将表观信息、运动信息和长短期时空信息关联起来,为后续的分类判别阶段提供了一个较为全面的时空表征,但是上述模型仍然需要大量的视频数据用于模型训练,这对用于训练的数据集要求较高,且训练过程中的时间成本较大,增加了模型的训练难度。
2.5 性能对比分析
在基于深度学习的特征提取方法的相关实验中,UCF101与HMDB51是使用范围最为广泛的数据集。UCF101是收集自YouTube的真实动作视频数据集,囊括101个动作类别,共13 320个视频,包罗了人与物的交互运动、身体运动、人与人的交互运动、弹奏乐器和各类运动五种动作类型。HMDB51数据集包括从各种电影片段以及公共数据库中收集的大量真实视频剪辑的集合。该数据集包含6 849个剪辑,涵盖51个动作类别。动作类别可分为五种类型:一般面部动作、含对象交互的面部动作、一般肢体动作、人物交互肢体动作和人与人交互肢体动作。该数据集来源于现实场景,含有复杂的背景信息且在不同类别的运动中含相似场景,因此相较于UCF101更具挑战性。表4罗列出了不同的深度学习特征提取方法在上述数据集上的识别准确率对比。为便于描述,光流(Optical Flow)、扭曲光流(Warped Optical Flow)、堆叠的运动差分图像(Motion Stacked Difference Image)、动态图像(Dynamic Image)、动态光流(Dynamic Optical Flow)等输入数据类型分别简化为OF、WOF、MSDI、DI、DOF。此外,OFF(RGB)与OFF(OF)分别表示经OFF子网络处理后的RGB和光流数据。
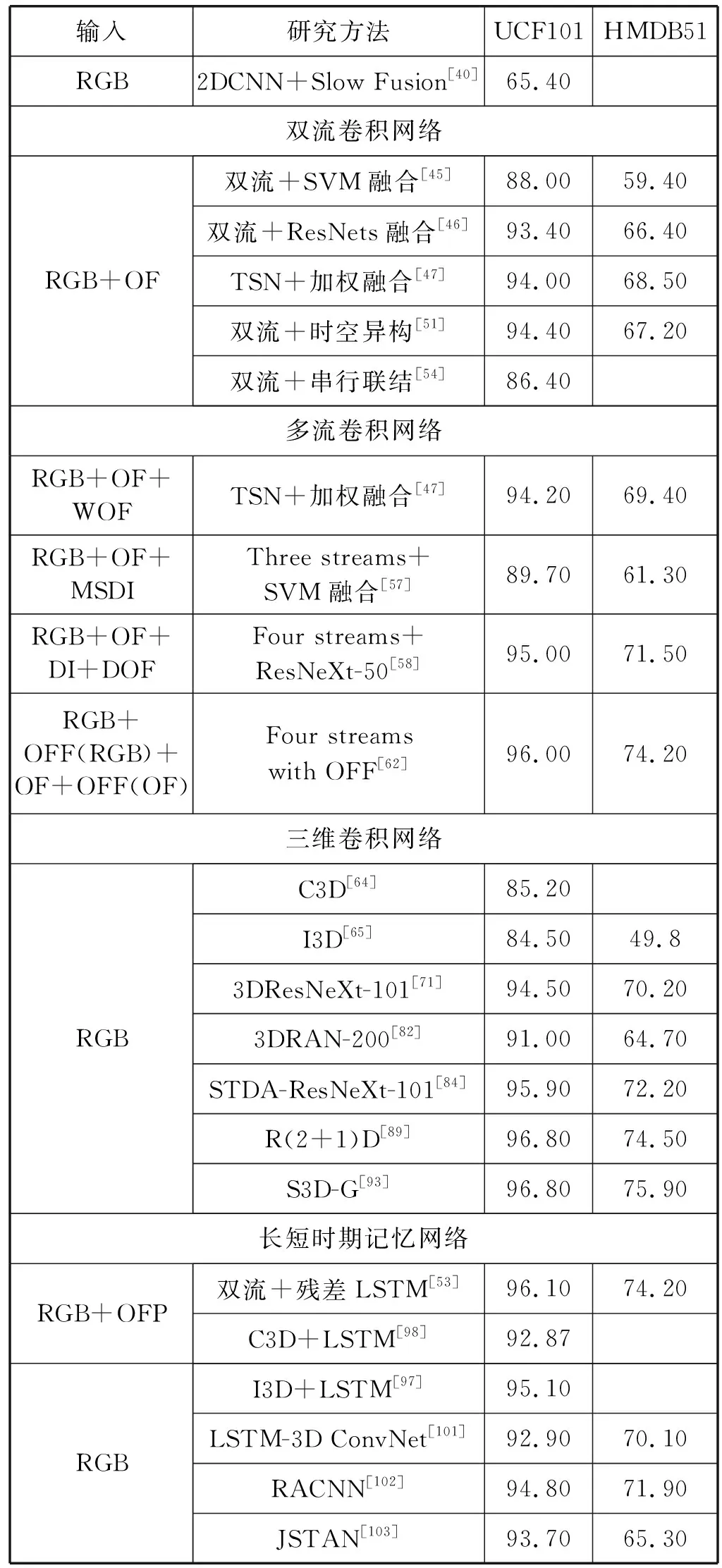
表4 基于深度学习的特征提取方法识别准确率对比(%)
可以看出,相较于文献[40]利用2DCNN与单一RGB输入模式相结合的方式,双流网络得益于光流数据在时间流信息上的补偿,其平均识别精确度相较于单流网络在UCF101数据集上提升了25.84百分点,证明了双流卷积网络的有效性。在基于双流卷积网络的特征提取方法中,文献[51]利用时空异构双流网络在UCF101数据集上达到了94.40%的准确率,文献[47]利用加权法融合TSN双流网络,在HMDB51数据集上达到了68.50%的准确率,实现了最优的识别结果。
在基于多流卷积网络的特征提取方法中,文献[57]利用三流卷积网络结合SVM模型,在UCF101和HMDB51数据集上达到了89.70%与61.30%的准确率,与文献[45]中利用双流网络结合SVM模型的方法相比较,分别提升了1.7百分点与1.9百分点。文献[62]利用OFF子网络构建四流卷积网络,在两个数据集上均取得了最优结果,在UCF101和HMDB51数据集上分别实现了96.00%与74.20%的准确率。与单流网络相比,其平均准确率在UCF101数据集上增加了28.33百分点,但是多流卷积网络中精确度的提升需要以巨大的计算量为代价。
在基于三维卷积网络的特征提取方法中,仅采用RGB输入模式也能达到与双流甚至多流卷积网络相当的识别效果,避免了复杂的预处理过程。与其他模型相比,C3D[64]与I3D[65]模型并未在大型数据集上进行预训练,因此识别效果不是很理想,证明了3DCNN在小数据集上容易引起过拟合的问题。在UCF101和HMDB51数据集中,文献[71]利用3DResNeXt-101分别实现了94.50%与70.20%的准确率,文献[89]利用三维卷积的结构变形构造R(2+1)D网络,分别实现了96.80%与74.50%的准确率。与文献[71]相比,文献[89]利用更少的卷积层(34 vs 101)实现了更高的精确度,证明了基于三维卷积结构变型模型的有效性。文献[93]利用S3D-G模型取得了96.80%与75.90%的准确率,在表4所有方法中识别精度最高,但是该方法在Kinetics与ImageNet数据集上同时进行了预训练,训练过程中的时间成本十分高昂。
在基于LSTM的特征提取方法中,文献[97]与文献[98]通过LSTM模型的引入,明显提升了C3D[64]与I3D[65]模型的识别效果。此外,文献[53]通过在双流网络中引入LSTM变体模型,在UCF101和HMDB51数据集上取得了良好的识别效果,分别实现了96.10%与74.20%的准确率,证明了LSTM强大的序列建模能力在特征提取过程中的性能增益。该方法适用于任意长度的视频帧输入,在复杂度与精确度之间取得了良好折中,但是仍然要求昂贵的训练成本。
3 未来可能的研究方向
基于传统手工特征提取的方法需要巨大的内存开销与计算成本,且依赖于领域专家的先验知识,具有较强的主观性,在很多情况下基于深度学习的方法表现更为优越。基于深度学习的特征提取方法得益于神经网络的层级训练模式,通过层层递进的特征提取机制自动从原始视频数据中抽取高维特征,充分捕获视频数据的上下文语义信息,从而增加了模型的描述能力,有利于最后的识别判断。特征提取直接关系到视频内容是否能够得到准确且充分的表达,进而影响分类结果。但面对爆炸式增长的视频数据量,日趋复杂的视频内容以及实时性分析的现实需求,视频特征提取方法也对有效性、鲁棒性与时效性提出了更高的要求。现将视频特征提取方法中存在的挑战及未来可能的研究方向总结如下:
1) 多特征融合。不同形式的输入通过特征提取模型处理后会得到不同类别的特征,从不同方面描述了视频中的人体运动模式。各特征侧重点不同,仅利用单一特征进行后续的识别判断容易导致错误的分类结果。很多模型直接基于RGB数据进行特征提取,随着摄像设备的应用与发展,RGB数据具有便于采集且细粒度信息丰富的优点,其对应特征能直观地反映物体表观与细节纹理信息。但由于视频采集过程中摄像头的抖动、环境光照与遮挡等因素,RGB数据通常会带有大量的背景噪声,造成视频数据时空维度上的复杂性与多变性,从而导致不同个体的相同动作之间会出现较大的类内差距,进而影响分类特征的视频表征能力。融合不同类别的特征能结合各特征的优势,以规避单特征分类任务的缺陷。目前部分研究者通过结合视频数据中的深度信息来克服RGB数据对背景噪声敏感的缺陷[110],但深度信息的采集成本较高且识别精度不理想。因此设计更为简单有效的额外的输入模式以产生不同类型的特征,通过多种特征相融合的方式来表征人体的运动模式更加值得讨论,利用不同特征之间的互补性实现对多种特征的优势进行综合。
2) 动态信息的表征。动态的运动信息是视频数据中的多帧差分所包含的内容,用以描述运动历史,如何设计特征提取机制以期准确地描述人体动作在时间维度上的动态演变,对视频中人体动作的正确区分而言意义重大。部分研究者利用视频中的光流特征表征人体动态信息,在补偿时间信息的同时消除了无关背景因素的影响,虽然带来了精度提升,但光流计算的复杂度较高且内存开销较大,极大地降低了模型的有效性与实用性。此外,光流特征往往需要预先计算,且光流视频的生成需要耗费大量时间成本,不能达到实时分类预测的效果。因此,为满足实用性要求,寻求一种简单高效的动态表征以代替复杂的光流计算从而减小内存消耗,具有重要的现实意义;为满足实时性要求,将动态特征提取过程融入到动作识别网络中以便进行实时预测分析,也是一个亟待解决的问题。
3) 特征筛选。视频数据包含许多冗余信息,若对所有特征同等对待,会导致特征提取过程中包含大量不必要的特征,从而干扰识别结果并增加多余的计算量。注意力机制能够模仿人类观察世界时所采用的视觉注意机制,着重观察空间区域中的核心目标以及时间维度上的动作发生片段。近年来,研究者们设计了不同的时空注意力机制,趋向于将目光集中在帧级时空注意力的相关研究上,以辅助模型自动筛选重要的视频帧以及其对应的突出空间区域,然而相邻帧所包含的动作信息几乎等同以至于难以区分其重要性,部分学者试图通过添加复杂的正则化来解决上述问题,但模型的计算量与复杂度也随之上升,因此将研究重点从帧级注意力转向剪辑级注意力,为不同的视频剪辑片段分配不同的重要性分数也是一个值得研究的方向。此外不同的卷积核对应着不同的通道以提取不同类别的特征,因此不同通道所对应的特征也应该被区别性对待。综上所述,如何调整注意力机制,以辅助模型灵活筛选关键性特征,是提升最终分类特征的判别能力的关键。
4) 多模态特征挖掘。目前大多数人类动作识别任务的研究仅考虑了视频中的视觉特征,基于直观感受到的视频画面进行人体动作的分类判别。然而现实生活中的视频数据不仅仅包含图像特征,还含有大量的语音信息与文本信息,对这些数据类型的充分利用能辅助模型进一步挖掘深层次特征,进而理解视频内容。如何结合视频中不同属性的数据类型,对各类数据所包含的信息进行显示挖掘,协同利用多模态特征之间的互补特性,是辅助模型确定动作类别以提升识别精度的关键。多模态数据的引入虽然增加了不同数据类型之间的联系,但是多模态特征的挖掘需要模型在不同数据集上进行训练,以及需要分别对各个模态分别进行特征提取与类别预测,这也意味着模型复杂度与模型训练成本的增加,因此设计一个易于训练优化的模型以生成简单有效的多模态表征也是一个值得探究的方向。
4 结 语
近年来,人类动作识别技术的应用领域愈加广泛,涵盖自动驾驶、机器人与智能监控等多个领域,具有重要的现实意义。本文对视频中的人类动作识别领域中所涉及到的特征提取方法进行了全面的概述,从传统的手工特征提取方法与基于深度学习的特征提取方法两方面对其研究现状进行了归纳并分析了各类方法的优点与不足,最后总结了人类动作识别领域中现存的挑战及未来可能的研究方向,以期帮助后续科研人员更加清晰明确地了解人类动作识别任务中的特征提取算法的相关研究现状。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
速读·下旬(2021年11期)2021-10-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
大东方(2019年12期)2019-10-20
电机与控制学报(2018年9期)2018-05-14
科学与财富(2017年22期)2017-09-10
计算机应用(2016年10期)2017-05-12
商情(2017年1期)2017-03-22
