
基于DOM树与模板的自适应网络信息抽取方法
2022-09-06 13:16柏志安曾剑平
计算机应用与软件 2022年8期
柏志安 廖 健 曾剑平
(上海交通大学医学院附属瑞金医院信息中心 上海 200025)2(复旦大学计算机科学技术学院 上海 200433)
0 引 言
基于HTML Web页面的网络信息表示方法是当前的主流,在微博、论坛、传统网站、公众号等不同类型应用中广泛使用。由于Web页面中通常包含大量与真正内容无关的其他信息,因此,从中抽取有用信息一直是研究和应用的重要基础。Web信息抽取主要用于从网页中提取符合要求的信息内容,这些信息通常是以一定的HTML标签标注的,对提取出来的信息内容可以以一定的方式进行组织和存储,方便后续的分析或利用。
论坛型网站页面结构复杂,包含了主帖列表、回帖列表、帖子中的各种用户信息和帖子内容等众多信息。针对这些信息的抽取,目前还是倾向于使用基于模版的信息抽取技术为特定的页面结构生成特定抽取规则。然而这种类型页面经常进行改版,包括结构组织和页面内容的调整等,这就导致抽取规则需要重新设计。其原因在于,目前信息抽取技术缺乏对网页本身特性的利用,整体自动化水平不高。因此,对于Web页面信息抽取而言,具有很大的挑战性,研究具有普适性且能够应对网页结构变化的自适应信息抽取算法是非常有必要的。
1 相关工作
Web信息抽取的技术根据不同的归类方法有不同的分类。从自动化的程度来说,可以分为非自动化、半自动化和全自动化三类。从技术方法分类,可以分为基于视觉特征的方法、基于本体的方法、基于机器学习的方法、基于DOM树结构的方法和基于模版的方法[1]。
基于视觉特征的算法利用视觉上的距离进行分块来区分不同主题的数据,所使用的视觉特征有字体的大小和颜色、页面背景颜色、间隔距离等。孙璐等[2]提出了一种基于视觉特征的Deep Web信息抽取方法,利用经典的VIPS算法对页面结构进行语义分块,基于基准视觉块进行信息抽取。
基于本体的信息抽取方法通常先对Web页面进行预处理,包括网页分块。然后对网页文本进行词性和语法分析,需要设计合理完善的知识库并构建领域本体,最后解析文本生成抽取规则。文献[3-4]提出了利用本体的方法抽取信息,或通过建立完整的本体得到抽取规则或是在Web信息抽取中利用领域本体知识。刘丽娟等[5]采用向量空间模型结合特征词权值,利用本体思想分析并计算主题相关度,从而达到提高特定主题网页信息抽取质量的目的。
基于机器学习的抽取方法中,一类是利用实现观察或分析结果定义若干能够反映预期信息与噪声信息差别的统计量,然后再进行信息抽取。吴共庆等[6]结合标签路径特征和文本块密度的统计特征,提出了Web新闻信息抽取模型CEDP。李志义等[7]基于一类具有重复模式的页面,提出了新的信息提取新方法,该方法利用聚类算法发现重复模式。另一类机器学习方法则引入一定的数学模型来描述抽取对象,刘志强等[8]将待抽取信息项视作为状态,将词汇作为待抽取观测项,从而提出基于改进的隐马尔可夫模型的网页信息抽取方法,对新闻报道中的关键信息进行抽取。深度学习方法也开始被用于Web信息抽取,赵朗[9]构建了一种基于双层循环神经网络的模型用于Web页面信息的抽取。
基于DOM树的信息抽取领域也有较多的算法和成型的系统[10]。基于分治方法,提出了在DOM上进行最长增量式序列的构建和模板检测算法[11]。马晓慧等[12]将DOM树标签路径与行块的分布密度相结合,利用视觉属性剪枝去噪防止正文内容误删,但对于短文本过多的网站,如论坛网页缺乏准确性。王海艳等[13]同样利用视觉特征,提出剪枝和融合算法并引入MapReduce计算框架,实现并行化抽取目标信息的效果。何云钢等[14]选取DOM树中每个节点及其子节点进行筛选,只保留文字类型的子节点,最后形成独立而完整的段落,并将其组成分段的网页文本内容。
基于模版的信息抽取针对的是通过读取数据库数据填充到统一模版生成的网页。李宝密[15]提出了自动生成模板的Web信息抽取方法,并将模板转换成为结构化形式。张方[16]提出了一种基于数据分块的Web数据抽取规则生成算法,自动生成基于Xpath和正则表达式的抽取规则模板。顾韵华等[17]结合DIV块模板和表格模板,在领域本体指导下训练决策树模型构建DIV块模板定位数据块。
综上所述,这五类Web页面信息抽取方法在各自不同的角度上提出了抽取技术,基于视觉特征的抽取方法并无法区分信息块中的有用信息,例如发帖人昵称、发帖时间等。基于本体的方法则存在构造本体的复杂问题,并且抽取质量与本体完整性有密切关系。基于模板的方法更偏向于人工分析的基础上定义模板,在面对页面改版时也会遇到很大问题。基于机器学习的方法试图解决自适应的问题,但引入了阈值这类难以确定的参数或需要大量的标注样本。基于DOM树具有直观的方式,是HTML页面表示的合适方法。
本文充分利用了DOM树和模板的优势,提出新的方法解决页面抽取的自适应问题。相对于现有Web信息抽取技术,本文的创新点主要是:
(1) 针对论坛型网页信息抽取,提出一种基于DOM树与模板的自适应信息抽取算法。算法以拥有共同父节点的邻近结构进行子树定位,通过文本长度、链接文本长度等特征对子树内各个节点进行进一步的细分,从而生成信息抽取规则。尽管DOM树、模板是Web信息抽取的常用方法,但是当前的方法不能充分利用这两者的优势,导致Web页面信息抽取时,难以解决页面改版带来的程序重写问题。
(2) 算法能够自动适应实际应用中的多种典型页面改版操作,包括HTML标签类型、属性和属性值的增删和修改,以及整个页面中信息单元的位置移动。本文方法能够很好地针对这些改版自动生成抽取规则并获得比现有方法更好的抽取性能。
2 论坛型网页特性
不同类型的网站由于功能与内容偏重不同,页面的布局往往相差很大。典型的新闻博客类网页的布局通常是标题位于上方,正文紧随其后,这能很清楚地引导用户关注标题及正文的内容。企业、学校等组织的官方网站则有导航和网站主体内容分成两个部分的页面布局。本文算法针对的目标是论坛型网页,不同论坛板块页或称目录页的布局大同小异,通常来说就是一个以帖子标题为主要元素的列表,而帖子内的布局可以分为主帖+回复楼层和只有回复楼层两种,如图1和图2所示。
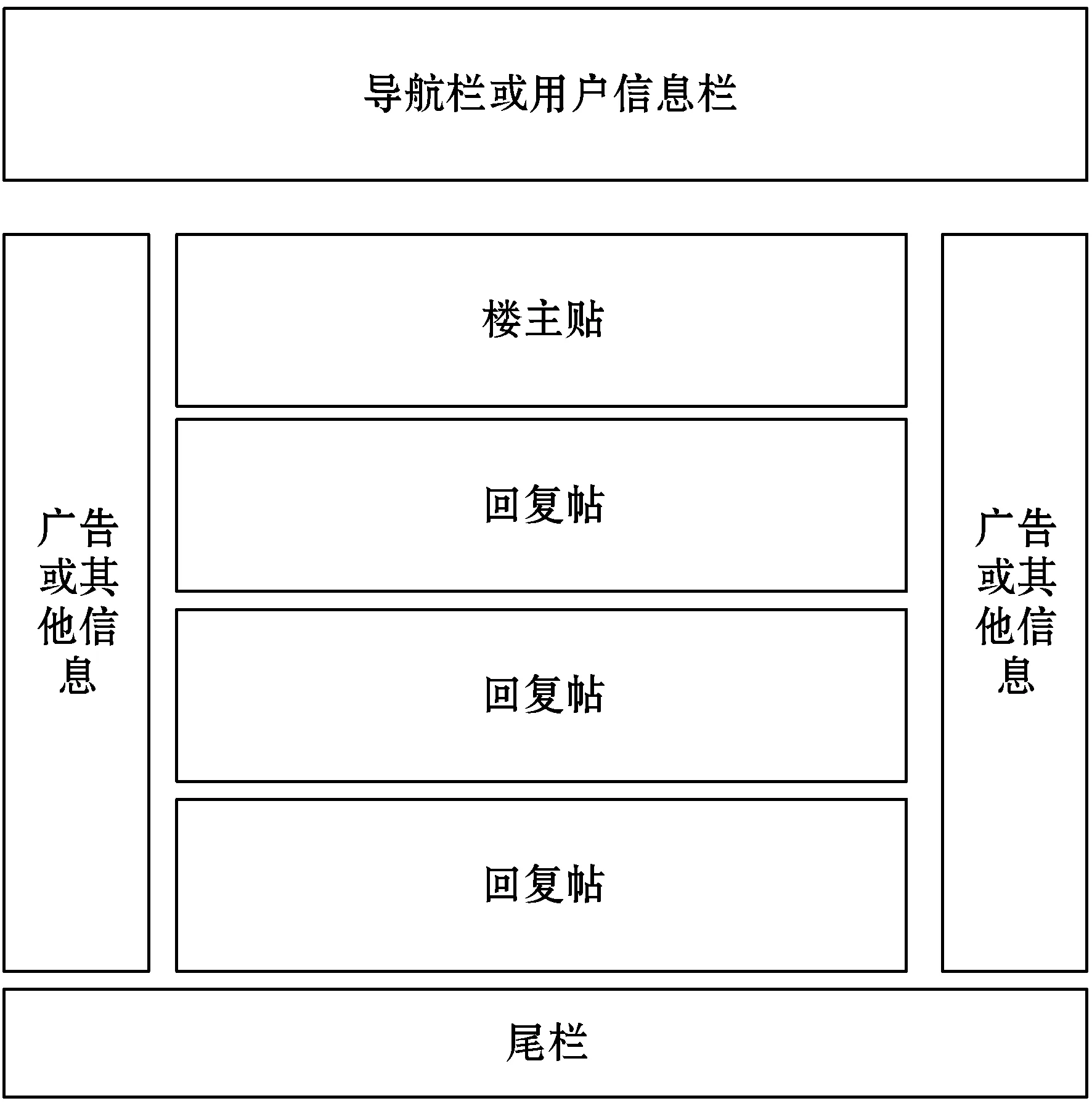
图1 主帖+回复楼层的帖内页面结构
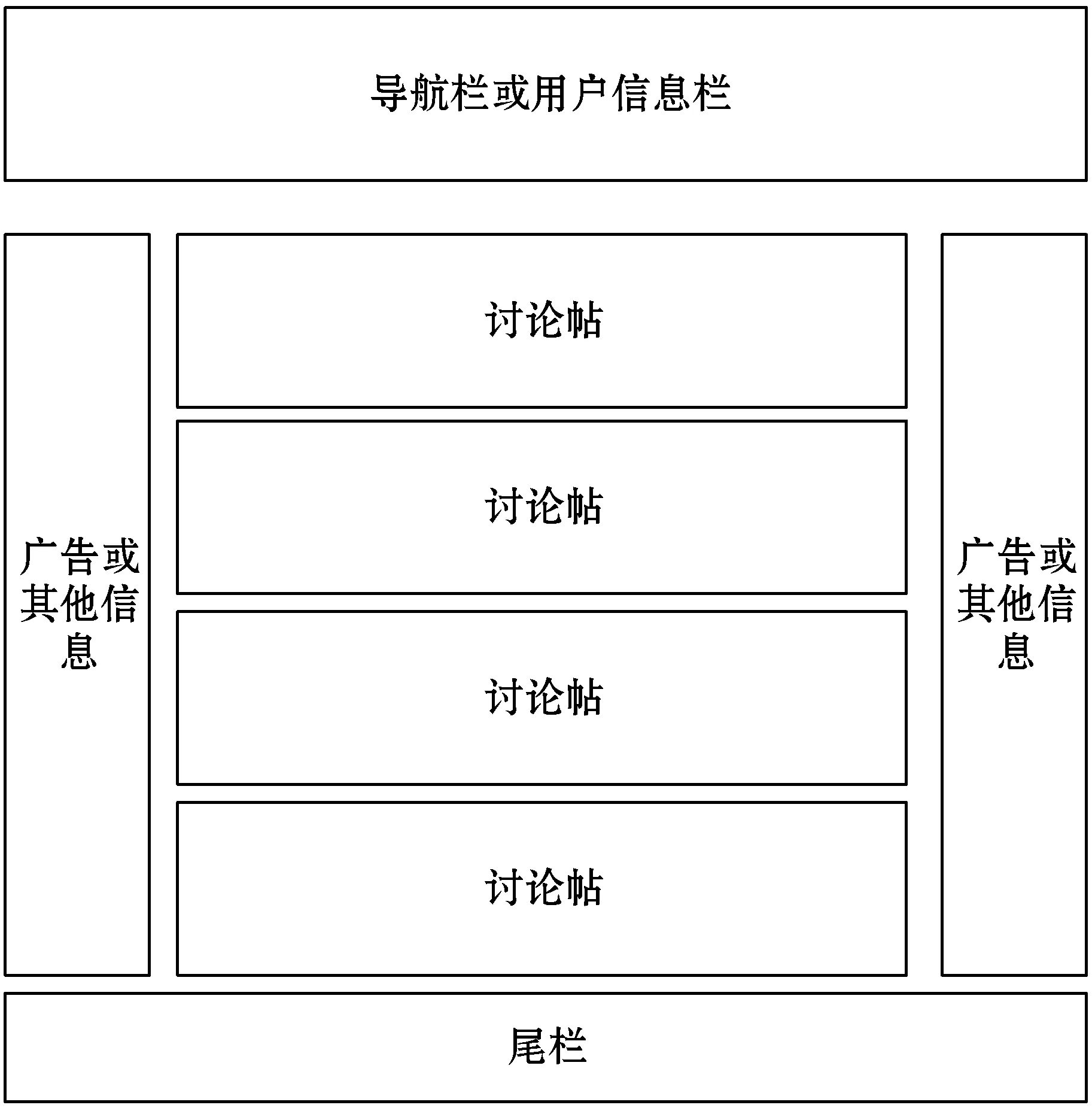
图2 只有回复楼层的帖内页面结构
对于图1,不管从外观还是从DOM树的角度看,其主帖和下方的评论楼层都分属不同的部分,可以容易地与评论楼层所在的区域区分开,因此,重点在于定位评论楼层所在的位置。
2.1 多变性
现代网页多使用CSS文件来控制页面布局外观,实现了与html的分离。在设计得当的情况下,只要修改几个CSS文件就可以同时对多个网页进行改版,在对应的html标签的class属性内表明其归属类即可。也正是这种易修改性,使得网站设计人员进行页面改版变得更加容易。
此外,部分网站由于反爬虫的需要,也会频繁对节点属性、节点标签,甚至是页面结构进行改动。对于通过xpath、css选择器等方式定位节点再抓取信息的爬虫采集方式,这种变动会导致抽取规则在改版后完全失效,需要根据变化情况对规则进行人工调整,耗时耗力。另外,通过嵌入html的JavaScript脚本,可以轻易增加、删除DOM树上的节点,修改已有节点的属性、文本等。
因此,考虑到上述多种原因产生的页面多变性,本文不关注特定节点本身,而是从DOM树整体结构入手。根据论坛型网页的特性,比较DOM树子树之间的相似性,自动化地分析并获取能够定位到所需节点的抽取模板。
2.2 子树结构的相似性
现代Web网页基本上都是采用div+css布局或table布局,前者因为拥有更好的可维护性和更佳的性能在近几年使用更多。然而不管使用什么格式的布局,正常的网页设计者为了保证网页的功能和后续可维护,对页面做出改版时都会遵循相似的原则。
网页中每个楼层内的元素和其排列顺序基本一致,主要变化在于用户ID、用户评论、评论时间对应节点的文本。查看网页的源代码,能够发现在帖内的不同楼层分别属于拥有相同class属性的独立的div容器,且都聚集在上一层的div容器内,楼层内含有各个标签在div容器内也是以同样的顺序排列。其下出现的标签、标签出现的次序、标签对应的内容,都是同样的。因此从DOM树的角度看,它们可以被视为挂在同一个父节点下的多棵结构极度相似的子树。
不管各个节点的文本内容或者DOM树整体结构发生什么样的改变,为了保证网页符合用户的使用习惯,用户评论或回复楼层在视觉上必然集中在一个区域内。为了实现这种设计,在DOM树上它们也必然是挂在同一个上层节点下。这也就是说,本文算法中定位有效信息所在子树的核心思想是:在DOM树上论坛帖内各楼层回帖,表现为拥有共同父节点的邻近的结构极度相似的子树。因此,可以认为对于论坛型网页来说,通过识别相邻的拥有相似结构的子树来选择有效信息子树,即使修改楼层的一些节点,只要它们多次重复出现且集中在相近区域内,就能正确识别。只要识别出这些代表楼层的有效信息子树的位置,就可以进一步地通过文本长度、链接文本长度等特征对子树内各个节点进行进一步的细分,判别它们各自的信息类别。
3 算法流程
本文算法重点在于定位有效内容对应的标签,生成抽取规则并提取文本,这需要遍历DOM树上所有节点。算法整体流程如图3所示,在遍历过程中,根据class属性对节点进行第一步的粗筛选生成候选集。因为html标签的class属性可以有多个值,为了方便操作,将其属性值拼合成以“.”连接的字符串的形式,并将这个字符串为称为节点的class属性串。接下来,获取候选集内所有class属性串对应节点的公共父节点,随后再根据候选集内的情况做下一步的细分。下面分阶段说明算法执行过程和原理。
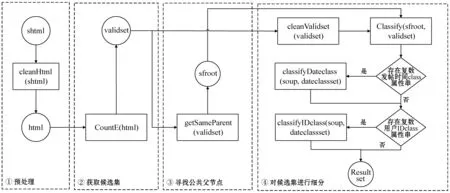
图3 算法的整体结构
3.1 生成候选集
要利用DOM树进行信息抽取,需要将HTML文档转换为对应的DOM树,之后,所需的回复楼层部分的信息变成了多棵结构相似的子树,且这些子树的父节点拥有相同的标签和属性。如果能得到这些子树在DOM树的位置,我们的问题就可以转换为对这些有效信息子树的直接处理。
在根据html构建DOM树前需要过滤掉不存储有效信息的html标签及其内部内容,这些标签包括: