
基于强化学习的伦理智能体训练方法
2022-09-06 07:30古天龙包旭光李云辉
计算机研究与发展 2022年9期
古天龙 高 慧 李 龙 包旭光 李云辉
1(暨南大学网络空间安全学院 广州 510632)
2(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004)
(gutianlong@jnu.edu.cn)
人工智能(artificial intelligence, AI)已经广泛应用到医疗[1]、交通[2]、智能家居[3]等诸多领域,给人类生活提供了诸多便利,但也引发了突出的伦理问题.例如:微软推出的聊天机器人Tay设计之初是为了与人类进行友好互动,但却被网友教会了粗俗甚至带有歧视性质的话语;优步(Uber)研发的无人驾驶汽车在行驶过程中撞死了无辜路人.不难想象,类似问题如果在智能体设计之初得以解决,能够显著减少给人类造成的困扰和伤害.换言之,为促进人工智能高效发展,并更好地为人类服务、提升人类生活质量,必须设计实现行为符合伦理的智能体,即伦理智能体[4].正如Picard[5]所说,“机器的自由度越大,越需要道德标准”.
价值对齐(价值一致)是典型的伦理智能体训练技术之一,即利用规范或规则限制智能体的行为,使其与人类价值观相一致[6-7].由于人类价值观的多样及复杂性,较多学者认为借助自下而上的方法实现价值对齐,从而让智能体学得人类价值观是较为可行的伦理智能体训练方法[8].其中基于专家示例[9-10]、模仿学习[11]、偏好学习[12-13]或者逆强化学习[14]等技术应用较为广泛,这类技术利用人类示范指导智能体行动,可以在一定程度上展现人类的价值观及道德规范.但是,基于人类示范指导进行伦理智能体训练的方法普遍存在3个缺点[15-16]:1)收集真实的人类行为示例代价昂贵、周期长,甚至是不可行的;2)因数量有限,真实人类行为示例易存在代表性差、公平性差等偏见歧视问题;3)由于数据来源于实际发生的人类真实行为,绝大多数行为体现的是积极的价值观,缺少与之对应的负面行为.
基于Li等人[17-18]的前期研究,Riedl等人[19]探讨了基于故事对智能体进行价值观嵌入的可行性,提出了以行为结果为根本目标的智能体训练方法.该方法以结果为导向、功能单一、训练粒度较粗,忽略了智能体在目标达成过程中可能做出的不伦理行为.受到以上研究启发,本文提出了一种新颖、高效的伦理智能体训练方法,能够保证智能体以符合伦理的行为方式完成预设任务.本文贡献有4个方面:
1) 提出了基于强化学习的伦理智能体训练方法.借助于众包、强化学习等技术,智能体具备执行伦理行为的能力,为伦理智能体的设计及训练提供了探索性思路.
2) 提出了基于众包的人类行为文本数据集构建方法.针对人类示范数据集难以获得、构建耗时长、代价昂贵、存在偏见歧视等特点,利用众包技术收集世界各地人们的行为示例,高效构建能够体现人类共同价值观的行为文本数据集.
3) 提出了元伦理行为这一概念以及一种综合考虑道德、规范及法律因素的行为奖励机制.从《中学生日常行为规范》中提取了人类生活中最为普遍存在的9个元伦理行为,扩展了智能体的行为空间,在一定程度上解决了其行为受场景限制的问题.此外,借助于众包对元伦理行为进行了伦理分级,提出了应用于强化学习的行为奖励机制,协助智能体在完成最终目标的前提下执行符合伦理的行为.
4) 通过模拟现实生活中常见的买药场景,分别基于Q-learning算法和DQN(deep Q-networks)算法对伦理智能体训练方法的有效性及合理性进行了实验验证.
1 相关工作
为使智能体的行为符合伦理,研究者展开了相关研究.目前而言,多数研究主要借助于规则推理、案例对比及机器学习等技术赋予智能体伦理判别能力.
基于规则推理的伦理决策方法主要利用预先设定好的伦理决策原则指导智能体进行推理决策.例如,在“I,Robot”[20]中,“机器人3原则”的设定对于防止机器人伤害人类起到了重要作用.Bringsjord等人[21]在机器人3原则的基础上设定了2种基本的机器决策原则,提出了一种利用命题演算和谓词演算等逻辑推理形式实现机器伦理决策的方法.Briggs等人[22]创造了认知机器人结构DIARC/ADE,该结构能够实现指令拒绝和解释机制的机器伦理决策方法,并在简单的场景下进行了测试.Anderson等人[23]基于功利主义和义务论开发了伦理顾问系统,并进一步证明了伦理原则指导下的决策系统在伦理困境下更易做出伦理决策.基于规则推理的伦理决策方法具有较强的可解释性和透明性,可以协助智能体快速做出伦理决策,但是难以刻画复杂的人类伦理,而且存在因地域、文化、个人信仰等不同而引起的规则差异等问题.
基于案例对比的伦理决策方法通过类比以往发生的案例自动提取伦理规范并进行伦理决策.Anderson等人[24]基于案例对比技术设计了伦理决策顾问系统MedEthEx,该系统通过提取典型案例中的医学伦理原则,协助护理智能体作出决策.Anderson等人[25]设计了一种基于专家评议的伦理困境探索系统GenEth,用于讨论给定场景中的道德困境,并应用归纳逻辑程序来推断行为的伦理准则.Arkin等人[26]提出了一种以战争规则为伦理决策原则的战场机器伦理决策方法,分别从伦理行为抑制、伦理决策设计、利用效应函数适应非道德行为和协助操作者分配最终责任4方面提出了具体解决方案.Dehghani等人[27]提出了结合规则推理和案例对比的MoralDM系统,既允许智能体基于某些已有的规则进行决策,也支持智能体基于案例对比做出决策.但是,伴随着案例数量的不断增多,MoralDM的工作效率显著下降,因此Blass等人[28]对其进行了结构映射扩展,通过计算案例间的对应关系以及相似度缩小搜索空间,提高类比泛化的效率.基于案例的方法虽然求解简单,但是存在难以应对场景不断变化、案例相关性差且数量有限等显著问题.
基于机器学习的伦理决策研究主要依靠智能体对客观环境的不断学习获得决策能力.Armstrong[29]基于贝叶斯理论构建了智能体决策模型,该模型依据最优效用价值原则,通过求取最大效用函数值完成决策.受巴甫洛夫条件反射的启发,强化学习[30]是一种基于尝试和错误的学习方法,它很好地满足了人类的目的,即让智能体学习道德行为.Dewey[31]在使用效用值的同时借助强化学习[30]设计伦理决策.Abel等人[32]主张强化学习可以协助智能体实现伦理学习和决策,并通过典型的伦理困境实验展示了如何借助于强化学习处理基本的道德问题.Wu等人[33]提出了将伦理价值观纳入强化学习的伦理塑造方法,通过假设大多数人类行为是道德的,从人类行为数据学习道德塑造策略,并模拟了拿牛奶、驾驶与躲避以及驾驶与救援这3个场景,证明了方法的有效性.Riedl等人[19]探讨了利用强化学习训练强化学习掌握人类价值观的可能性,该研究借助于Li等人[17-18]的研究构建情节图,以刻画智能体行为空间,然而存在受场景限制问题,无法应对现实环境的动态多变.
2 背景知识
2.1 众 包
信息技术虽然不断进步,但是仍然存在许多计算机难以高效处理但人类却能轻松应对的工作,如数据标注、物体识别等,众包便被用于协助人类更加高效地完成此类任务.众包的核心思想是借助于互联网、利用群体智慧将任务分而治之,通过工作者之间的协作完成复杂任务.众包的一般流程为:1)请求者在众包平台创建任务;2)工作者在众包平台完成任务;3)请求者在众包平台核查任务的完成情况,并决定是否为工作者发放酬金.
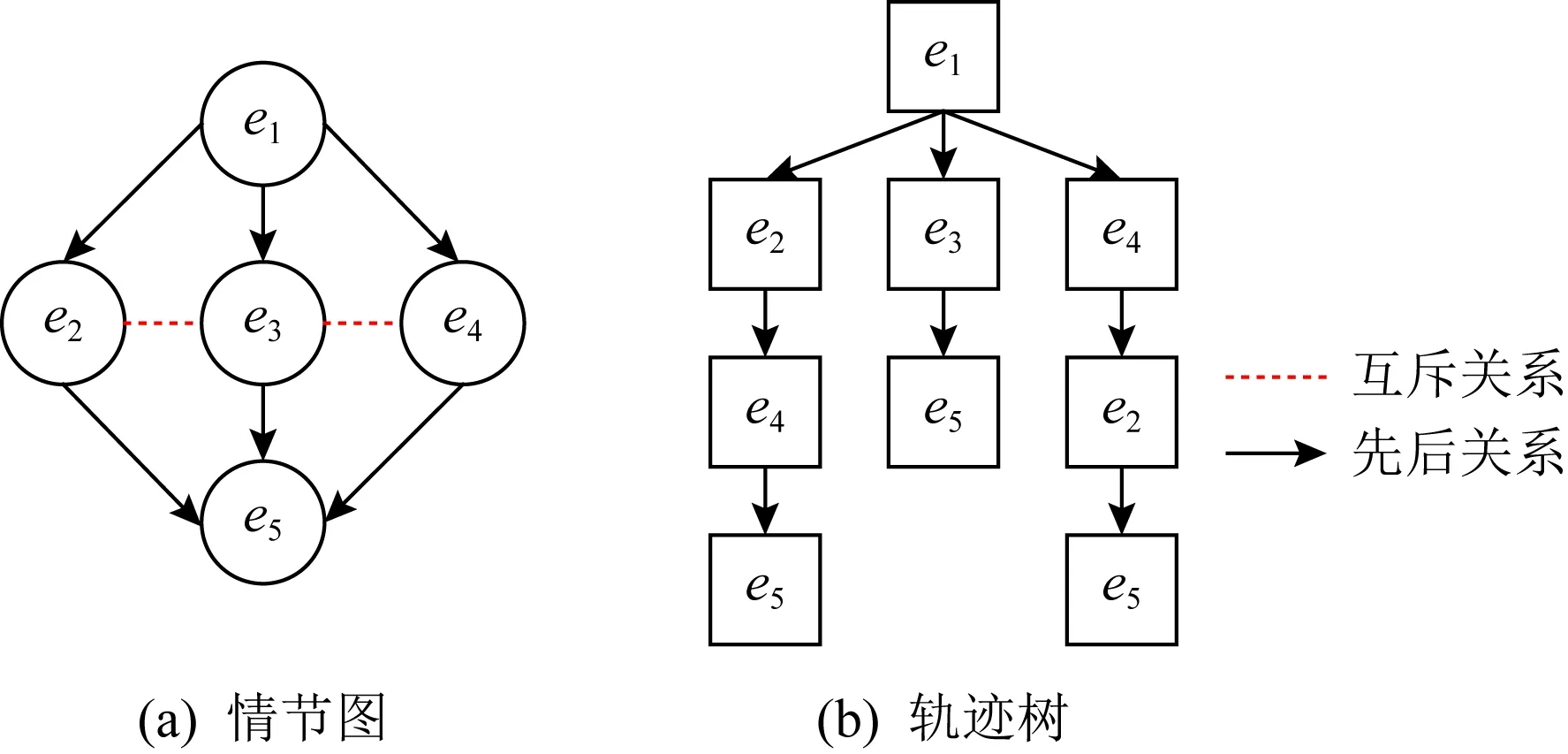
Fig. 1 Plot graph and trajectory tree图1 情节图与轨迹树
2.2 情节图及轨迹树
情节图用于描述多个事件序列的发生顺序,能够准确、简洁刻画事件的发生过程,并过滤掉普遍存在的噪音[17-18].情节图可以借助元组E,B,M,Eopt,Econ来表示.其中,E={e1,e2,…,en},表示情节图中所有事件的集合;B⊆E×E,表示事件间先后关系的集合;M⊆E×E,表示事件间互斥关系的集合;Eopt⊆E,表示情节图中所有可选择事件的集合;Econ⊆E,表示情节图中所有条件事件的集合.条件事件的发生取决于可选择事件是否发生.图1所示左边为情节图,节点代表事件,有向边代表事件间的先后关系(如事件e1早于事件e2发生),虚线边代表事件间的互斥关系(如事件e2与事件e3不可能同时发生).
如图1右边所示,轨迹树是有向无环图,主要作用是便于强化学习为智能体分配奖励.此外,智能体可以根据轨迹树追踪自己的行为.

Fig. 2 Flow chart of method图2 方法流程图
2.3 强化学习
强化学习[30]用于描述和解决智能体在某一环境中获得最大回报或实现特定目标的问题.其核心为马尔可夫决策过程(Markov decision process, MDP),可表示为五元组S,A,T,R,γ.其中,S表示智能体的所有状态(即状态空间);A表示智能体的所有动作(即动作空间);T:S×A→P(S)表示状态转移概率;R:S×A→R表示智能体采取某一动作并到达某一状态所获得的奖励值;γ∈[0,1]表示奖励衰减因子.MDP的目标是最大化智能体取得的长期奖励,即其中t为智能体所处时刻.
2.3.1 Q-learning算法
Q-learning使用Q值Q(s,a)估计在状态s采取行动a的预期奖励,用于协助智能体学得行动策略π:S→A,即每一个状态下该采取的动作.Q(s,a)的计算方式为
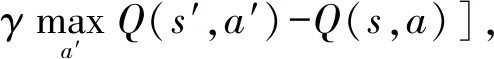
(1)
其中α为学习率,r为回报,γ为折扣因子,s′为新状态,a′为新状态可采取的动作.
智能体在状态s下,依据Q-table选择动作a,使Q(s,a)最大化.Q-table的行表示状态s,列表示动作a,矩阵中的值表示特定状态下执行某动作的回报值为r(s,a).智能体通过不断更新并查找该表,最终学到最佳策略.在学习过程中,探索率ε制约智能体按照Q-table的最优值选择行为或者随机选择行为.
2.3.2 DQN算法
DQN[34]采用神经网络估计价值函数,以端对端的方式对智能体进行训练.DQN的误差函数表示为
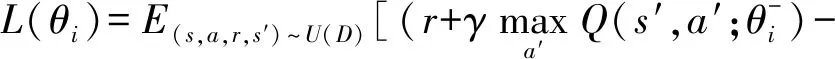
(2)
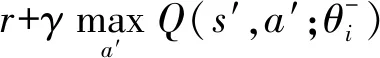

(3)
同时,神经网络的参数采用梯度下降的方式进行更新.此外,DQN中的探索率是变化的,随着训练的进行,由ε1逐步变化为ε2.
3 伦理智能体训练方法
本文所提出的伦理智能体训练方法主要包含4个步骤:1)基于众包收集人类行为示例,构建人类行为数据集;2)构建情节图,并进一步创建轨迹树;3)从《中学生日常行为规范》提取元伦理行为,并基于众包进行伦理分级;4)综合考虑道德、规范及法律因素,针对强化学习提出行为奖励机制,采用奖励机制与轨迹树相结合的方式训练伦理智能体.如图2所示:
3.1 基于众包的人类行为示例收集
鉴于众包在数据收集方面的优势,本文采用众包收集人类行为示例.为保证数据质量,提出3个要求:
1) 工作者撰写的行为示例包含8~30句话,每句话必须包含一个行为.工作者worker1撰写的包含n个行为的示例可表示为Aworker1(a11,a12,…,a1n).
2) 必须采用简单的自然语言进行表述,不能使用大量的复合句以及条件句等.
3) 同一示例中仅包含单一行为主体.
对于接受的每条示例,将给与工作者0.4~1.2美元的酬金.最终收集到的m条人类行为示例可表示为A={(Aworker1(a11,a12,…,a1n)),(Aworker1(a21,a22,…,a2n)),…,(Aworker m(am1,am2,…,amn))}.
3.2 情节图及轨迹树的生成
情节图的生成分为2个步骤:
1) 利用相似度度量技术对句子进行聚类,并提取情节点.本文使用K-Means聚类方法对句子进行聚类.
2) 利用关联分析技术分析情节点之间的先后关系、互斥关系,并构造情节图.
对于情节点ei与ej,创建f(ei→ej)和f(ej→ei)这2个假设,通过计算支持每种假设的样本数量,得出ei与ej的先后关系.假设ei与ej出现在同一个文本中,且ei出现在ej之前,则认为该文本支持f(ei→ej).借助于置信度计算公式,当f(ei→ej)的置信度大于0.5时,认定ei发生在ej之前.
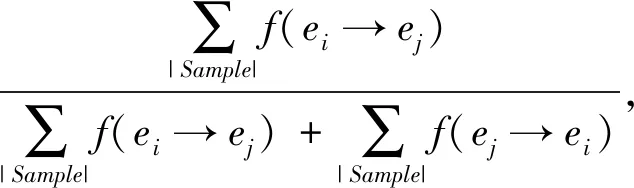
(4)
其中,ei→ej表示在同一个文本中ei先发生而ej后发生,|Sample|表示所有文本数量.
对于情节点ei,ej,分别设置Ei,Ej,用于表明ei,ej是否出现在某一示例中,当出现时Ei和Ej的取值为1,否则取值为0.根据下式计算M值,M是用于判定ei和ej是否存在互斥关系的函数,如果M>0,则说明ei,ej存在互斥关系.
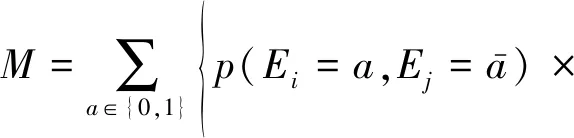
(5)
在遵循情节点间关系的前提下,通过遍历情节图生成所有可能的路径,便可得到轨迹树.
3.3 元伦理行为提取及分级
不同场景中的不同动作可能具备相同的伦理意义,如偷水果、偷药都是不符合伦理的偷盗行为.因此,为了高效扩展智能体的行为空间,引入元伦理行为这一概念来表示含义较为相似的一类伦理行为.
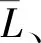
为了客观、公平对元伦理行为分级,采用众包收集行为分级的建议,众包任务设计如表1左边2列所示:

Table 1 Meta-Ethical Behavior Grading表1 元伦理行为分级
对于众包结果,基于多数投票机制[35]进行数据聚合,最终结果如表1右边2列所示.元伦理行为可分类为
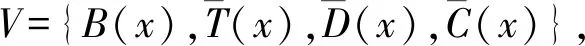
3.4 基于元伦理行为的强化学习
获得轨迹树之后,需要将其映射到强化学习训练环境中,完成伦理智能体训练.但是强化学习的训练环境是有限场景,无法罗列智能体可能遇到的全部情况.此外,在没有先验知识的情况下,强化学习算法需要随机探索状态-动作对,并在进行足量探索后逐步提升学习效率.为此,本文将元伦理行为及其分级作为先验知识,提出了基于元伦理行为的强化学习.
Q-learning基于奖励塑造的Q值计算公式为
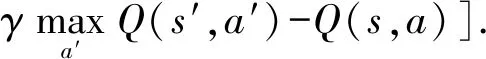
(6)
DQN算法中基于奖励塑造的损失函数为
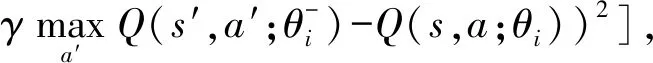
(7)
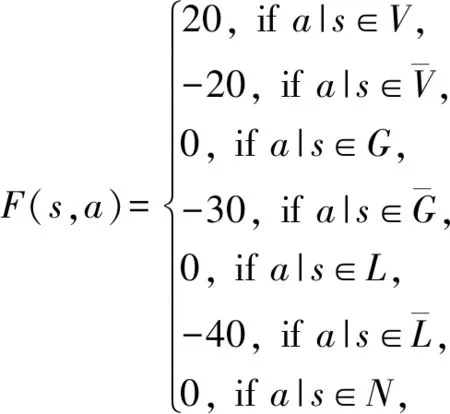
(8)
其中,F(s,a)为基于元伦理行为的奖励函数,a|s代表智能体在s状态下执行的动作a.
显而易见,在基于元伦理行为的强化学习中,智能体不仅能够获得环境奖励(与轨迹树相关),还能获得与元伦理行为及其分级相关的奖励.2种奖励机制相互结合,达到扩展智能体行为空间、改善训练效果的目的.
4 实验验证与分析
为了验证本文所提方法的有效性,选择生活中较为常见的“购买处方药”任务,对伦理智能体进行训练,并对结果进行分析.在该实验中,智能体的最终目标是携带处方药回家,但其所有行为应尽可能符合伦理.
本文首先通过Q-learning算法对所提方法进行验证,并分别使用3种奖励机制训练对比分析方法的有效性.其次使用DQN算法完成训练实验,并与基于Q-learning算法的实验结果进行了对比分析.
4.1 包数据收集
针对“购买处方药”这一主题,本文利用Amazon Mechanical Turk平台,进行了2次众包,共收集到437条人类行为示例.综合考虑主题、行为数量等因素,对收集到的行为示例进行了筛选,保留了其中的179条(占总量的40%)作为实验样本.实验样本中的每条数据平均包含12个行为,数据可用性较高.
4.2 情节图及轨迹树生成
经过情节点以及情节点间关系的学习,本文买药场景的情节图如图3所示,共包含32个情节点.由于情节图转换的轨迹树轨迹较多,本文在此展示部分转换结果,如图4所示.
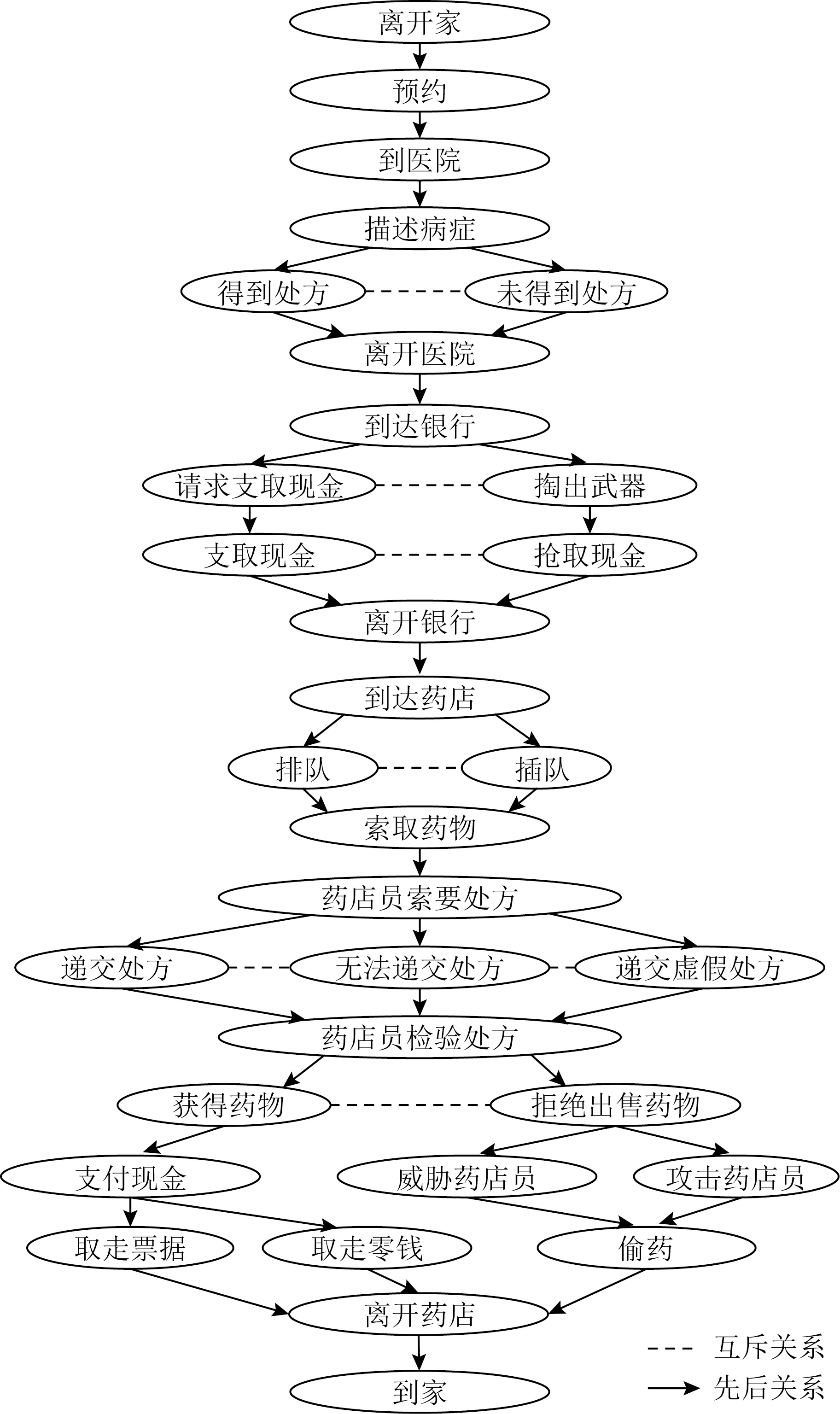
Fig. 3 Plot graph图3 情节图
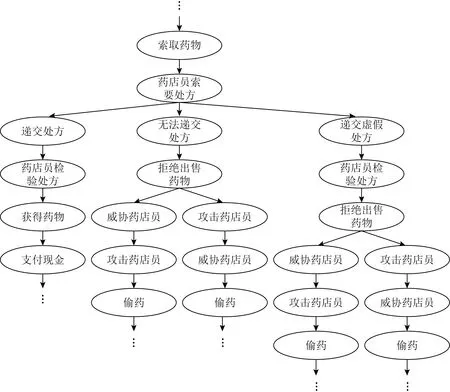
Fig. 4 Partial trajectory tree图4 部分轨迹树
4.3 强化学习场景映射
为完成伦理智能体训练,需要将其行为状态映射到强化学习场景中,场景由状态空间和动作空间组成:1)状态空间包括物理位置、交互状态及所处轨迹树位置.物理位置是指智能体所处的地点和位置坐标信息;交互状态是指智能体在与其他主体交互过程中的自身状态,如是否获得或拥有钱、是否获得或拥有处方;所处轨迹树位置是指智能体当前动作所处的轨迹树节点位置.2)动作空间包括智能体在场景中可执行的位移动作和交互动作.位移动作指智能的上下左右移动和进出某地点;交互动作指智能体与其他主体间的信息交互.
动作空间的规模受制于状态空间的规模,可通过穷举法得出.状态转移随动作导致的状态变化而变化,如位移动作将使智能体的物理位置信息发生变化,交互动作则使智能体的交互状态(如付出金钱获得药品)和所处轨迹树位置发生变化.
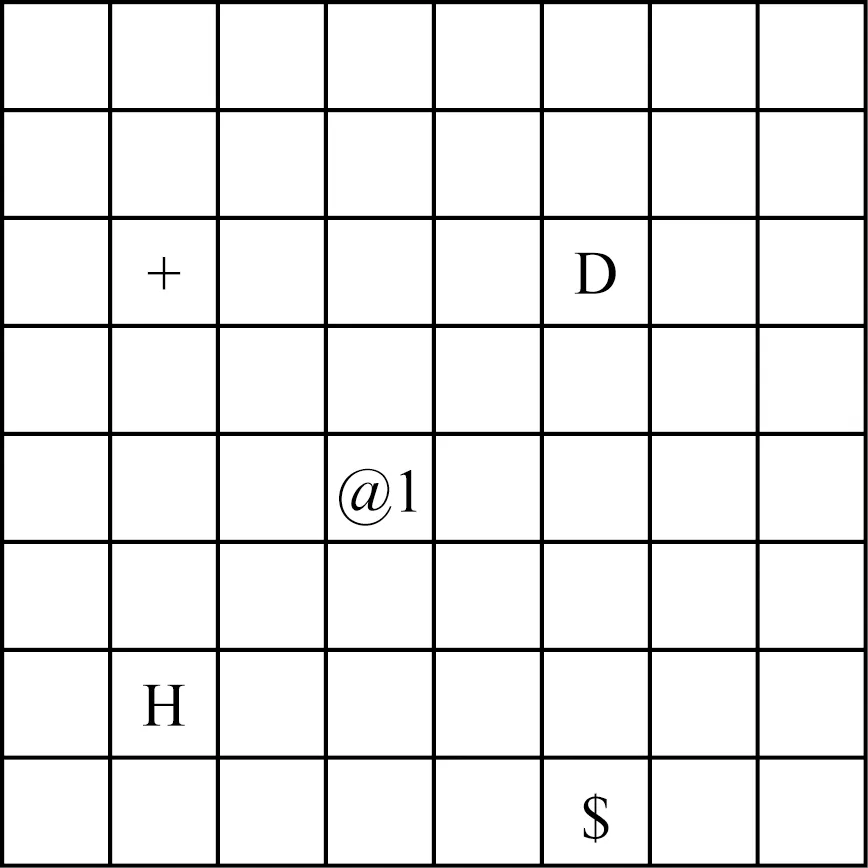
Fig. 5 Overall scene图5 全局场景
图5所示8×8平面为全局场景示意图,包含家(H)、医院(D)、银行($)、药店(+)四个局部场景及智能体(@1).任意局部场景均拥有更为详细的场景布局,如图6所示7×7平面为药店场景,包含柜台(⊗)、智能体(@1)、顾客(@2)、药店员(@3)及出口(E).药店员的职责是检查处方并售卖药品,因此智能体需要去医院咨询医生获得处方并携带处方购买处方药.@2的存在表明智能体须排队购药,若绕过@2直接与@3沟通,则存在插队行为.

Fig. 6 Pharmacy scene图6 药店场景
4.4 强化学习奖励机制设计
为说明本文所提伦理智能体训练方法的有效性,本文使用3种不同的奖励机制训练伦理智能体.
机制1.当智能体成功购买处方药时可获得奖励.该奖励机制无需先验知识指导,成功购买处方药可获得计数为10的奖励,否则获得计数为-10的奖励.
机制2.当智能体的行为遵循轨迹树路径时可获得奖励.该奖励机制利用轨迹树对智能体的行为进行指导,当智能体执行了轨迹树中的动作时可获得计数为10的奖励,否则获得计数为-10的奖励.
机制3.当智能体的行为遵循轨迹树路径时可获得奖励,且需要结合3.3节、3.4节中所提出的元伦理行为及其分级原则.
4.5 实验结果及分析
为验证4.4节所述的伦理智能体训练方法的可行性,本节分别采用Q-learning算法、DQN算法进行实验验证及分析.
4.5.1 基于Q-learning算法的实验验证
采用Q-learning算法进行实验验证时,实验参数设置如表2所示:

Table 2 Q-learning Experimental Parameters表2 Q-learning实验参数
本文首先使用机制3训练伦理智能体,对使用机制3训练伦理智能体的过程进行分析.由于智能体在医院是否得到处方具有随机性,本文分为得到处方以及没有得到处方2种情况.图7、图8分别为得到处方、没有得到处方情况下智能体的动作变化情况,图中纵坐标为动作执行数量与结果之比(即动作执行率).
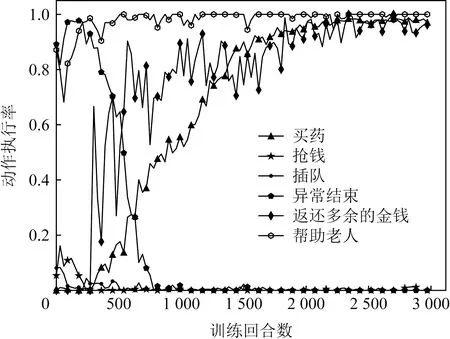
Fig. 7 Action execution rate when prescription isobtained(Q-learning)图7 得到处方的动作执行率(Q-learning)
如图7所示,买药曲线随训练回合数逐渐上升并趋于平稳,表明智能体已经从中学会如何买药;代表抢钱和插队的曲线在训练初期有小幅度上升后立即下降,表明智能体对非伦理行为进行了尝试,并在得到惩罚后避开该类行为;异常结束曲线训练初期接近于1表明智能体不断尝试各种动作,并超过了回合最大动作数;返还多余金钱的曲线前期动作执行率为0,此时智能体还未学会支付金钱;帮助老人的曲线收敛得最快,因为按伦理分级机制帮助老人可以获得相应奖励,曲线上升并收敛说明了伦理分级机制的有效性.
从图8可以看出,随着训练回合数的增加,偷药、抢钱、插队等动作的执行率显著下降并趋于稳定,说明智能体获得了执行伦理行为的能力.在训练前期,攻击药店员的动作执行率与被药店员拒绝出售药品的动作执行率成正比,说明智能体尚未获得执行伦理行为的能力;但随着训练回合的增加,被药店员拒绝出售药品的动作执行率显著提高(接近1),而攻击药店员的动作执行率却接近为0,说明智能体获得了执行伦理行为的能力.
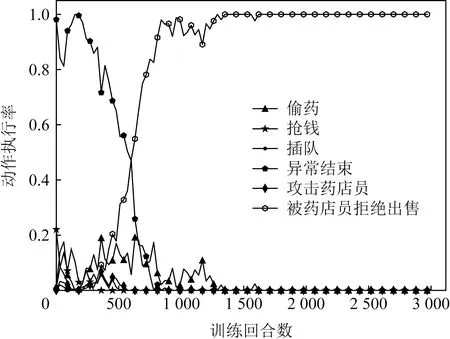
Fig. 8 Action execution rate when prescription isn’tobtained(Q-learning)图8 没有得到处方的动作执行率(Q-learning)
下面针对4.4节所述的3种奖励机制做对比实验,每训练1 000回合测试10次,共统计1 000次测试结果.在实验结果分析时,以预约、抢钱、插队、提供假处方、偷药、攻击药店员、买药、遇到多余金钱时返还与否、遇到老人时帮助与否、被药店员拒绝出售药品、异常结束这14个行为或结果作为评价指标,分析各奖励机制的差异.实验结果如图9所示.
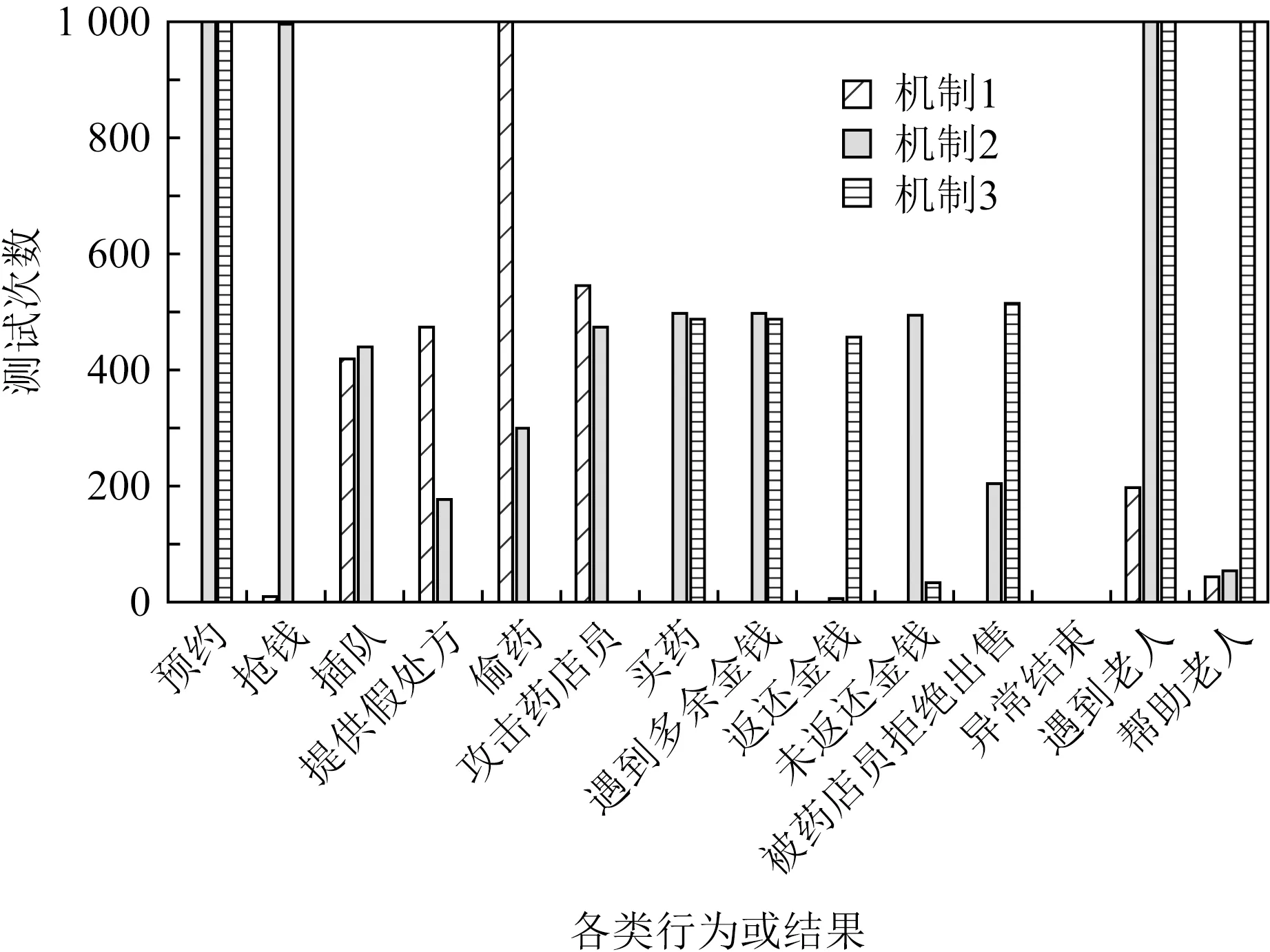
Fig. 9 Comparison of results under different mechanisms图9 不同奖励机制下的实验结果对比
由图9可见,采用机制1对智能体进行奖励时,由于不对智能体买药过程中的行为进行伦理层面的指导,导致其执行了较多违背伦理的行为,如偷药1 000次、攻击店员546次,而在离开家后的探索中197次遇见需要帮助的老人,其中44次给予帮助.
采用机制2对智能体进行奖励时,智能体为了获得更多奖励,会执行较多轨迹树中出现的行为,如在去医院咨询医生前执行预约行为1 000次,保证了智能体执行任务的逻辑顺序.但是对轨迹树中未出现的行为仍然不具备判断能力,如497次收到收银员找回的多余零钱、493次未执行返还行为(占比约99.2%).在离开家后的探索中,1 000次遇见需要帮助的老人,其中52次给予帮助.
采用机制3对智能体进行奖励时,智能体在轨迹树和元伦理行为分级的双重指导下,具备更高效的伦理行为学习能力,执行了更多的伦理行为.如486次收到收银员找回的多余零钱,455次执行了返还行为(占比约93.6%).在离开家后的探索中,1 000次遇见需要帮助的老人,均给予了帮助.
4.5.2 基于DQN算法的实验验证
采用DQN算法进行实验验证时,实验参数设置如表3所示:

Table 3 DQN Experimental Parameters表3 DQN实验参数
与Q-learning算法一致,基于DQN算法的实验同样分为得到处方以及没有得到处方2种情况.图10、图11曲线的走势与图7、图8较为相似,说明在使用DQN算法进行智能体训练时,智能体最终能够获得执行符合伦理行为的能力,即能够遵守人类道德与伦理规范,验证了所提方法的合理有效性.但是不难发现,使用DQN算法时,完成智能体训练所需的回合数更多.
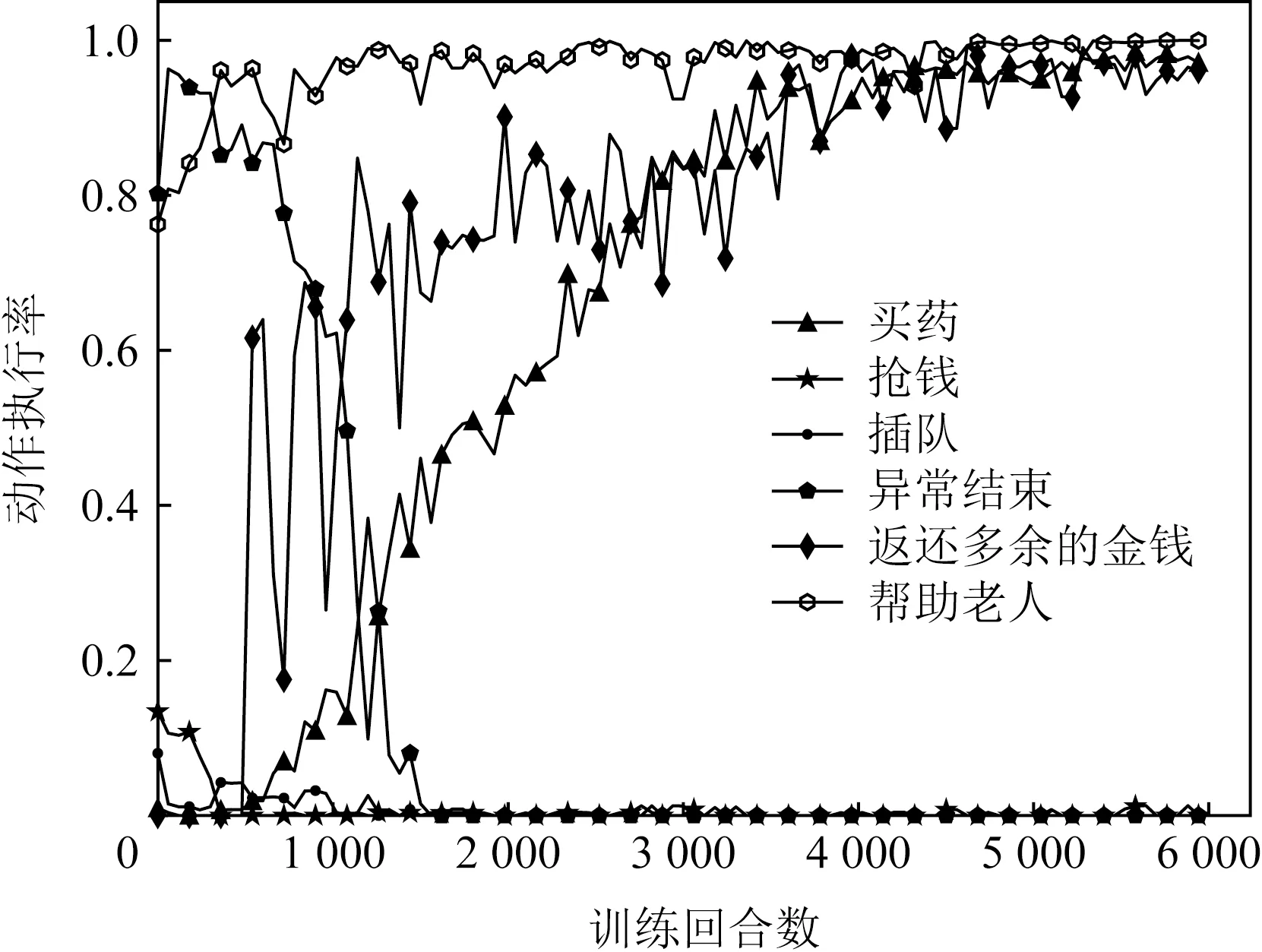
Fig. 10 Action execution rate when prescription is obtained(DQN)图10 得到处方的动作执行率(DQN)
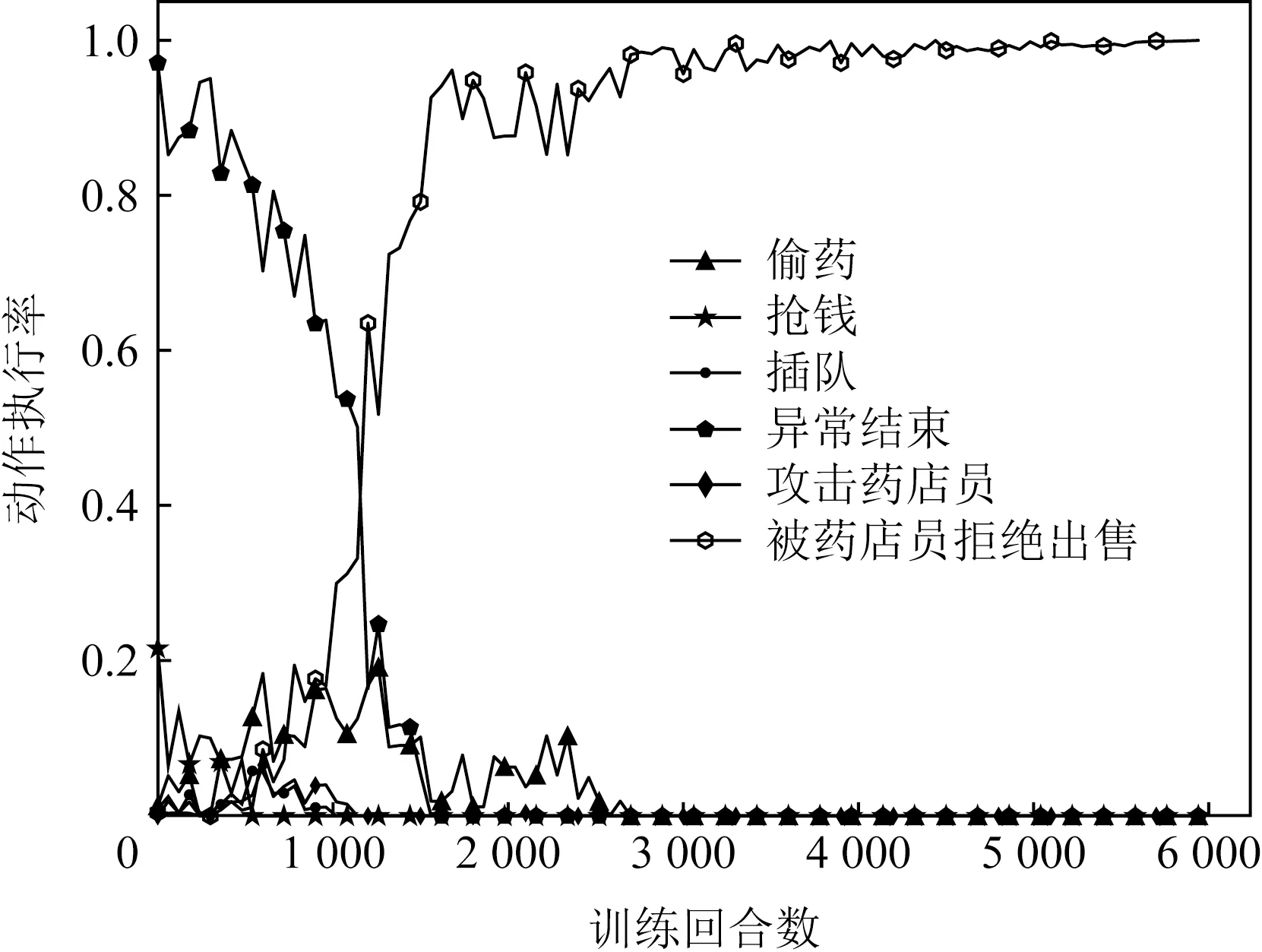
Fig. 11 Action execution rate when prescriptionisn’t obtained(DQN)图11 没有得到处方的动作执行率(DQN)
4.5.3 算法间的对比实验
为进一步说明Q-learning与DQN这2种算法在伦理智能体训练方面的差异,本节进行更深入的对比实验.实验采用的对比指标为平均奖励,即智能体执行一定行为后所获得奖励的平均值,该指标越高说明智能体能够选择更合乎伦理的动作.为减少实验的偶然性对结果的影响,本文进行了100次重复的实验,并利用实验所得数据的均值绘制了平均奖励图,如图12所示.
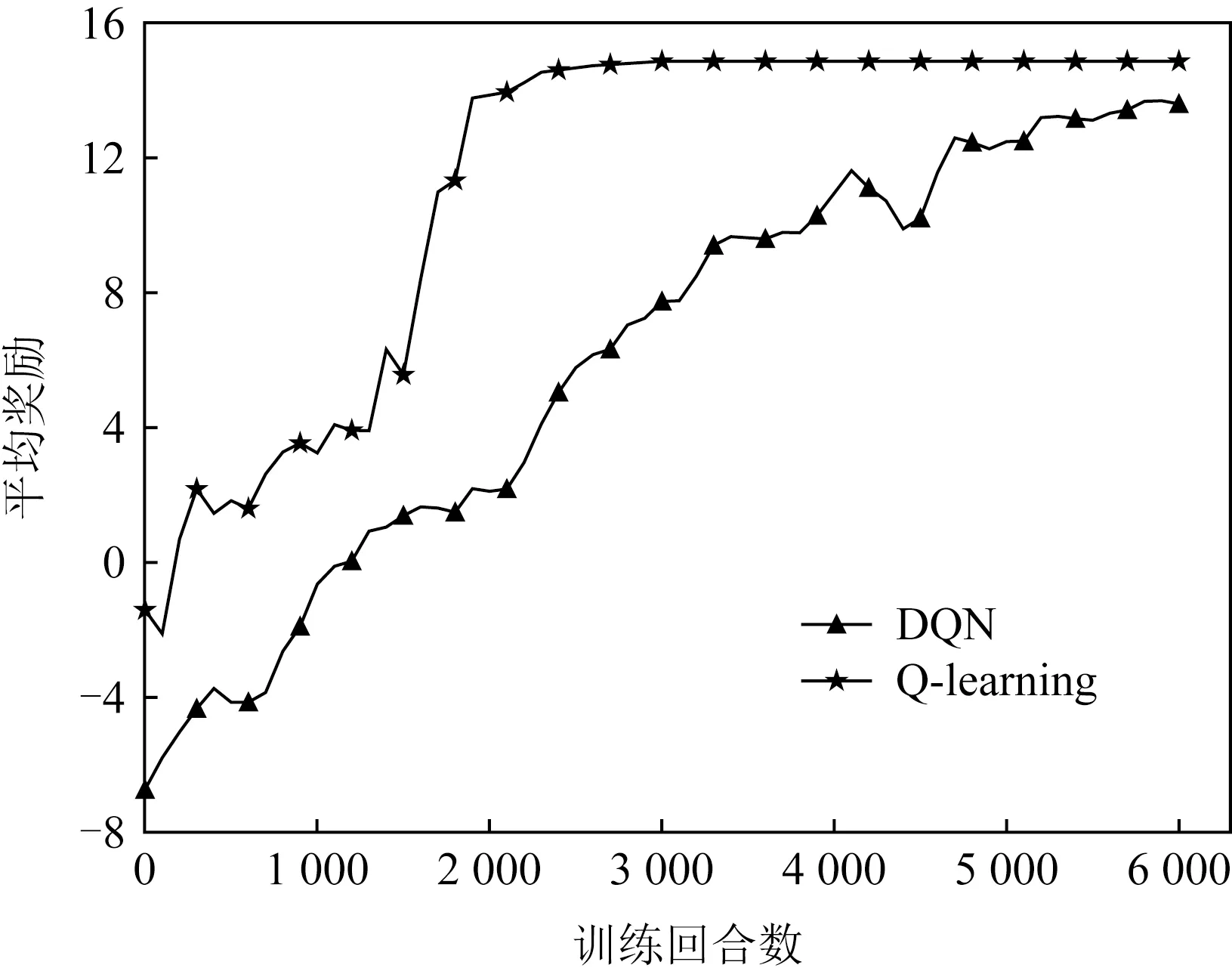
Fig. 12 Average reward of two algorithms图12 2种算法的平均奖励
由实验结果可见,Q-learning算法的训练效果整体好于DQN算法,主要表现在2个方面:Q-learning算法收敛速度快且比较平稳;Q-learning算法在收敛后的平均得分高于DQN算法.主要原因有2个方面:
1) 对Q-table的更新效率存在差异.Q-learning算法借助于Q-table描述“状态-动作-奖励”情况,智能体通过不断迭代更新并查找该表,选择奖励最高的动作执行.Q-learning算法将获得的奖励通过式(1)对Q-table进行更新,该方式直接有效并能快速将新的Q-table应用到下一次探索中.DQN算法针对的是状态动作空间较大、遍历Q-table复杂度较高的情况,此时神经网络训练需要大量地输入数据,并通过梯度下降的方法调整模型参数以拟合Q-table,Q-table拟合的不精确性导致训练速度慢,且并非总能以最优方式完成任务.
2) 未来奖励的获取受到不同程度的干扰.本文中伦理智能体执行的是一系列连贯的动作,只有完成了前面部分动作才能执行后续动作.Q-learning算法初始Q-table为空,不存在干扰未来奖励的因素.深度神经网络在构建网络模型时的参数随机初始化及梯度更新时由于参数调整所产生的误差,对当前状态存在拟合的不准确性,使得未来奖励的获取受到一定的干扰,尤其是在进行前半部分较慢的训练速度影响了整体的收敛速度.
综上,强化学习能够训练智能体执行伦理行为的能力,但Q-learning算法总体表现更好,DQN虽然能完成最终任务,但训练效果稍差.
5 总 结
智能体在人类生活中担任越来越重要的角色,承担越来越复杂的任务,不但应该具备高效完成预定任务的能力,而且在执行任务的过程所采取的行为应符合伦理.基于这一出发点,提出了伦理智能体训练方法,并分别借助Q-learning算法和DQN算法完成了模拟实验,该实验证明所提方法是有效的;此外,对Q-learning算法和DQN算法的训练效果进行了对比实验,证明了任务搜索空间不大时不必使用DQN算法,Q-learning算法的效果反而更好.
本文虽然针对伦理智能体的训练提供了解决方案,但是所提方案较为初步,仍需要进一步改进.可开展的后续研究有:
1) 本文所提取的元伦理行为较为粗糙、粒度不够细,无法完全涵盖复杂的人类行为,有必要开展更具代表性的元伦理行为分类及归纳研究;
2) 本文实验场景设置相对简单,未考虑特殊情况下非伦理行为的合理性,如闯红灯是非伦理行为,但“为救人而闯红灯”却是合理的,因此可以针对更加复杂情形下的伦理行为判定展开研究,并进行实验验证;
3) 本文假定训练环境中的其他主体(药店员、银行职员等)均执行符合伦理的行为,并以此为基础完成了单伦理智能体的训练,但是真实环境中可能存在多智能体且不具备伦理判别能力,因此有必要研究多智能体协同合作时的伦理问题,以及多伦理智能体的同步训练方法;
4) 在实验验证方面,因本文方法与其他伦理智能体训练方法在机器学习算法、方案设计、场景搭建等方面存在较大差异,因此未进行直接对比,后续可在实验设计方面进行改进,增加不同研究方法间的对比分析.
作者贡献声明:古天龙负责提出研究选题,提供设备及指导性支持;高慧负责调研整理文献,设计研究方案及实施研究过程;李龙负责设计论文框架,起草及修订论文;包旭光负责修订及终审论文;李云辉负责采集整理数据及实验结果分析.
猜你喜欢
英美文学研究论丛(2022年1期)2022-10-26
福建中学数学(2021年1期)2021-02-28
英美文学研究论丛(2021年2期)2021-02-16
小资CHIC!ELEGANCE(2021年44期)2021-01-11
阅读与作文(英语初中版)(2019年8期)2019-08-27
西部论丛(2019年10期)2019-03-20
英美文学研究论丛(2018年2期)2018-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
