
体系作战下巡航导弹的动态隐身
2022-09-03 02:19:40马子杰谢拥军
系统工程与电子技术 2022年9期
马子杰, 谢拥军
(北京航空航天大学电子信息工程学院, 北京 100191)
0 引 言
巡航导弹是一种打击精度高、生存能力强、作战效费比高的战术打击装备,但近年来通过整合海陆空天防御武器装备形成体系化反导防御系统的构想得到验证和实现,如美军“海军综合防空火控”(Navy Integrated Fire Control and Control Air, NIFC-CA)系统,其预警探测范围和拦截打击能力较单个作战平台都有了巨大的提升,巡航导弹的作战能力受到挑战,没有隐身性能的巡航导弹将无法完成作战目标。传统的巡航导弹隐身方法是通过结构设计和材料选取来降低导弹雷达散射截面(radar cross section, RCS),现在巡航导弹的态势感知能力不断提升,可以将传统隐身手段与突防技术手段相结合,进一步提高隐身突防效能。动态隐身就是基于突防技术手段提出的隐身策略,巡航导弹通过自主感知战场威胁,利用规避飞行或背景隐藏,降低在航迹上的雷达探测概率和拦截概率,确保巡航导弹在体系作战中的作战能力,这就需要研究体系作战下巡航导弹的动态隐身航迹规划算法。
深度强化学习是人工智能领域深度学习和强化学习两大分支结合的成果,是目前动态规划领域的研究热点。近年来深度强化学习发展迅速,应用领域不断扩展,其开始被应用于武器装备智能航迹规划和导弹制导律的研究,用以解决航迹规划实时性问题。文献[23]和文献[24] 提出了基于深度强化学习的控制制导律,提升了制导的精度和鲁棒性。文献[25]探究了反导拦截系统的智能拦截策略,其算法能给出特定场景下是否发射拦截导弹、何时发射拦截导弹及发射后的最优导引律。文献[26]提出了一种能规避静态禁飞区和威胁区的无人机自主航迹规划方法。文献[27]在二维平面构建了静态威胁区,巡飞弹基于深度强化学习算法避开威胁飞行区打击目标,提升了巡飞弹的自主突防能力。
综上所述,目前巡航导弹动态航迹规划算法研究中针对预警雷达的威胁建模都属于静态建模,这难以适应对决策实时性要求较高的动态战场环境。因此,为了真实地反映动态战场环境,对体系作战全过程进行动态建模,搭建了一个体系仿真平台,利用该平台在深度确定性策略梯度(deep deterministic policy gradient, DDPG)算法奖励函数中同时引入了探测概率奖励和拦截脱靶量奖励,更全面地反映了巡航导弹突防时面临的体系作战威胁,能进行体系作战下的巡航导弹智能航迹规划。
1 体系作战及其仿真平台
1.1 体系作战
现代信息化战争是体系作战,作战时体系内各传感器和武器系统共享信息和对敌方威胁协同打击,其防空反导的作战范围和打击精度都大幅提升。为了评估体系作战下武器的真实突防效能,需要搭建相应的体系作战仿真平台。
1.2 体系仿真平台
图1是巡航导弹突防NIFC-CA作战体系的典型场景图。巡航导弹的攻击目标是舰船,期间有巡逻的预警机探测威胁和舰载拦截导弹的拦截威胁。

图1 巡航导弹突防场景示意图Fig.1 Schematic diagram of cruise missile penetration scenarios
图2是预警雷达仿真平台界面,采用E-2D预警机作为发射雷达平台,利用随机粗糙海面或地面数学模型模拟真实飞行环境,考虑地杂波和海杂波对低空飞行巡航导弹的影响,计算出巡航导弹在低空飞行时的RCS,模拟机载雷达进行必要的回波信号处理,设定巡航导弹被检测出的最大门限电压值,最终给出目标被探测概率。
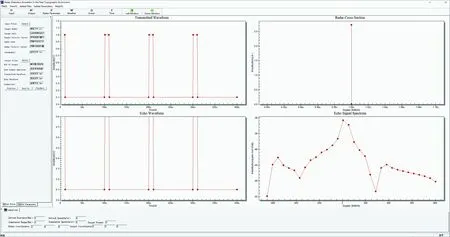
图2 预警雷达仿真平台界面Fig.2 Early warning radar simulation platform interface
舰载拦截导弹拦截仿真系统的界面如图3所示,仿真系统中可以导入巡航导弹和舰船的外形模型文件、运动轨迹文件和相应的速度矢量文件。根据预警雷达信号判断是否发射舰载拦截导弹进行截击。拦截导弹制导方式为比例导引法,最大法向过载为25 g,广义卡尔曼滤波模型阶数为5,比例系数为4,过载响应时间取为0.5 s。

图3 舰载拦截导弹拦截仿真平台界面Fig.3 Interface of shipborne interceptor missile interception simulation platform
2 基于Markov决策过程的突防决策模型
Markov决策过程(Markov decision process, MDP)是一种求解在可描述场景下智能体获得最大回报策略的方法,常被应用于自动控制、动态规划等问题。马尔可夫过程一个重要的性质就是马尔可夫过程的下一状态仅与当前时刻的状态有关,而与过去时刻的状态没有关系。在MDP中,智能体下一时刻的动作也只与当前的状态有关。巡航导弹突防过程为一个MDP,需要对导弹运动模型、状态空间、动作空间、奖励函数进行建模。
为了反映巡航导弹和NIFC-CA作战体系的对抗过程,在奖励函数中引入了探测概率降低奖励和巡航导弹与拦截导弹相对距离奖励:
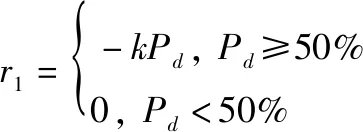
(1)
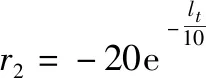
(2)
式中:为预警雷达探测概率,当探测概率小于50%时认为雷达未能探测到目标,将其奖励设为0;为比例系数;为巡航导弹和拦截导弹的距离。
3 基于深度强化学习算法的突防决策过程求解
DDPG算法是DeepMind公司将确定性策略梯度算法与Actor-Critic 网络结构结合提出的一种用以解决复杂连续控制问题的算法,这一算法具有良好的扩展性与适应性,基于该算法可以使用相同的网络参数解决一类连续控制问题。
DDPG算法求解流程图如图4所示。其中Actor 网络输入状态、输出动作,Critic网络输入状态和动作,输出在这一状态下采取这个动作的评估值。由于巡航导弹、目标、预警机和拦截弹的状态和动作信息在时间上均是连续的,故其状态空间中各样本不是独立的,只使用单个神经网络结构学习过程很不稳定,为解决这个问题,DDPG算法引入了经验回放机制,引入目标Actor网络和目标Critic网络,与现实网络独立训练。首先现实Actor网络与环境进行交互训练,得到状态、动作、奖励及下一时刻状态,将这4个数据放入经验池中,得到一定的样本空间后,现实Critic网络从经验池中提取样本进行训练,得到值;目标网络也进行同样的训练,每间隔一定时间就利用现实网络参数更新目标网络。训练完成后通过Actor网络输出高维的具体动作。
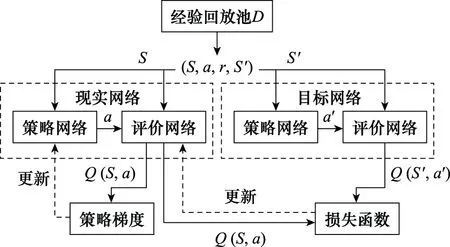
图4 DDPG算法求解流程图Fig.4 DDPG algorithm solving flowchart
神经网络的作用是为了建立状态到动作以及状态动作到评估值的映射。本文所采用的神经网络结构如图5所示,包含输入层、隐藏层和输出层。Actor网络包含两层隐藏层,均为256个单元数,权重均初始化为0.5,隐藏层使用selu激活函数,输出层使用tanh激活函数。Critic网络同时将状态和动作作为输入,输入层和输出层间有两层隐藏层,均为512个单元数,使用selu激活函数,输出层只有一个单元,因为动作-价值函数无边界故不使用激活函数。

图5 神经网络结构Fig.5 Neural network structure
体系作战下的巡航导弹智能航迹规划算法程序主要包含参数和数据输入模块、动作和动作评价网络、样本储存模块、模型训练模块、模型测试模块。其中,模型测试模块可以评估神经网络和强化学习训练参数的好坏,其流程图如图6所示,其中的初始参数为巡航弹、拦截弹、目标、预警机起始位置及其机动性能数据,以及目标和预警机的运动轨迹、巡航导弹RCS库。

图6 模型测试流程图Fig.6 Model test flowchart
4 仿真结果与分析
4.1 仿真场景及武器性能参数
仿真场景示意图见图1,本文设定的巡航导弹突防场景中包括巡航导弹、预警机、舰船目标及拦截导弹等武器装备。预警机在7 000 m高空以“跑道型”航线巡逻,其航线中心点距目标舰船的水平距离为60 km,巡航导弹发射时和目标舰船相距300 km,发射后贴近海面飞行,拦截导弹的发射点位于目标舰船上。其中巡航导弹的最大巡航速度为300 m/s,拦截导弹的最大速度为1 000 m/s。本文仿真时将其转化到空间直角坐标系中进行,并且进行了1 000倍的缩放。
4.2 软硬件环境及参数设置
本算法基于Windows操作系统开发,使用了Python编程语言和Tensorflow架构,计算硬件为64G DDR4内存和GTX2060显卡。深度强化学习超参数优化设计后设置如下:策略网络学习率为0.001,动作网络学习率为0.000 5,折扣因子为0.95,目标网络更新系数为0.005,经验回放池容量为10 000。
4.3 仿真结果分析
本文首先探究了仅考虑预警威胁下的动态隐身航迹规划问题。首先基于该场景对DDPG算法进行训练,图7为训练完成后输出的航迹规划模型的一个测试结果,该测试对抗场景中预警机以跑道型航迹巡逻,目标舰船贴近海面直线航行,巡航导弹以一条低可探测性航迹成功击中目标。

图7 预警威胁下的动态隐身航迹规划Fig.7 Dynamic stealth track planning under early warning threat
本文以训练每回合奖励值为指标判断策略是否不再显著提升,训练每回合奖励值趋于平缓时认为训练达到收敛。如果巡航导弹发射时就引入巡航导弹和拦截导弹相对距离奖励,由于训练目标不明确,收敛周期更长,训练20个回合,模型还没有收敛;故对于巡航导弹和拦截导弹相对距离奖励引入一个判断,当巡航导弹和拦截导弹相对距离小于3 km时才考虑拦截导弹的威胁,其训练每回合奖励值如图8所示,训练第11个回合即可收敛。
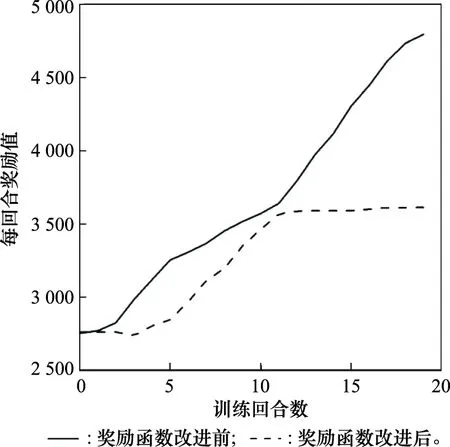
图8 奖励函数改进前后不同训练回合数下的奖励值Fig.8 Reward value under different numbers of training rounds before and after the reward function is improved
典型体系作战场景下训练后攻防轨迹图如图9所示,航迹生成时间为0.21 s。由于将仿真缩放1 000倍到空间直角坐标系,不使用深度强化学习下拦截弹脱靶量为0.039 m,使用深度强化学习后,拦截导弹脱靶量为0.58 m,引入深度强化学习后可以提高巡航导弹在典型体系作战场景下的生存能力,进而提高突防概率。
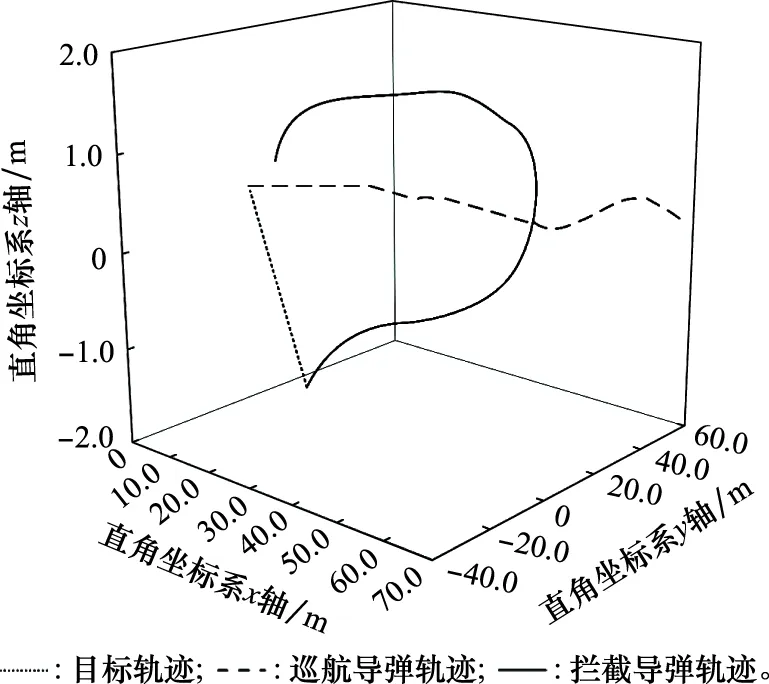
图9 体系作战下的动态隐身航迹规划Fig.9 Dynamic stealth track planning in system combat
5 结 论
现代信息化战争是体系作战,本课题组搭建了一个体系仿真平台用以评估体系作战效能。体系作战背景下,仅采用传统隐身策略的巡航导弹突防能力大幅降低,本文采用深度强化学习算法实时调整巡航导弹航迹,降低在航迹上的雷达探测概率和提高被拦截脱靶量,进而提高战场生存能力,实现面对敌方传感器的动态隐身。该算法训练完成后可实时生成突防机动指令,其求解时间远低于传统航迹规划算法;而且具备良好的扩展性与迁移性,可用于不同的突防对抗场景中。
猜你喜欢
环球时报(2022-08-18)2022-08-18 17:15:05
军民两用技术与产品(2021年9期)2021-11-27 06:29:31
军事文摘(2020年24期)2020-02-06 05:56:36
青年歌声(2019年12期)2019-12-17 06:32:32
北京航空航天大学学报(2017年7期)2017-11-24 05:27:33
北京航空航天大学学报(2016年6期)2016-11-16 01:50:52
西北工业大学学报(2015年4期)2016-01-19 03:31:42
舰船科学技术(2015年8期)2015-02-27 15:38:47
