
基于FM度量的自适应K-Means聚类的工业生产运行基准挖掘
2022-09-02 01:45李华,贾雪
长春大学学报 2022年4期
李 华,贾 雪
(长春大学 理学院,长春 130022)
运行基准是应用于工业生产的一种具有指导意义的工业生产运行参数,运行人员可以通过对照和对比不同参数条件下的运行基准,调整可控的运行参数,使得机组运行具有更高的安全性、经济性和高效性。因此,运行基准对工业生产具有重大意义。在提取运行基准方面,目前已有一些提取基准的方法,包括基于遗传算法和支持向量机方法计算不同工况下汽轮机主蒸汽压力的基准值[4];采用神经网络技术,根据锅炉燃烧调整试验和机组运行历史数据,建立了燃烧优化RBF神经网络模型,并采用遗传算法对锅炉可调燃烧运行参数进行了优化[5]。基于FM度量和稳定性算法进行自适应的聚类系数k值选择,并使用K-Means算法进行聚类,选取煤耗最低的聚类中心作为运行基准。
1 数据筛选
在大型工业生产运行机组实际运行中,设备运行状态会受到多种条件影响而随时发生改变,运行过程存在稳态工况和非稳态工况。非稳态工况相比于稳态工况,输入参数和输出参数之间没有较强的关联性,且非稳态工况中参数波动较大,不能准确反应机组当前的运行性能。因此,为了提高数据分析的准确性,需要对初始数据进行稳态筛选。
根据目前已有的一些稳态工况判别方法,包括基于权重的遍历算法并利用改进的置信区间筛选出稳态离群点[6];采用滑动窗口法对大样本数据进行稳态工况筛选[7];基于滑动窗口法的特征变量一阶差分稳态判别法[8]。
选择基于方差的稳态数据筛选法。在t时刻,计算连续s时间段的方差,如果该方差小于某个规定的阈值,则t时刻是稳态数据,否则为非稳态数据。
另外,在稳态数据筛选后,由于数据的特征众多,可能会出现某些特征不在其控制范围之内的情况,对此,我们有两种解决方法。第一,在仅有少量特征超限的情况下,采用填补法对其进行填补,以保证数据的可用性,填补法可以使用均值填补法、回归填补法等;第二,在大部分特征都超限的情况下,我们认为该数据样本不具有可用性,可以将其删掉,仅保留优质的数据样本。
2 特征选择
在大型工业生产运行中,由于设备的多样性,采集的测点众多,同一时间的测点可能有几千甚至几万。而在数据分析中,测点过多,会导致计算效率极低,且有可能会影响到数据分析的质量,从而难以应用到实际中。因此,在进行数据分析之前,我们需要对初始样本进行特征选择。特征选择的方式分为两种,第一种可以通过工业生产运行人员提供的方式获得,他们在多年的工作经验中,对重要特征有更为专业的看法,这些特征往往是与建模目标高度相关的;第二种是根据大数据分析方法进行特征选择,比如逐步回归法、方差选择法、相关系数法等。
另外,机组运行的过程中,运行人员会根据不同的目标对可控参数进行不同程度的调整,在这种情况下,我们的基准要针对不同的参数条件来进行挖掘。在不同的参数条件下,运行基准是不同的,我们把不同的参数条件称为工况。因此,要对数据样本进行工况划分,可以采用滑动平移的方式来划分工况。
3 基准挖掘
在工业生产运行中,往往会根据机组设计值或者行业标准来优化生产目标。而在实际生产中可能会对设备进行部分改造,或者随着设备的磨损,导致设计值难以达到优化目标。另外,各工业生产企业对经济、节能、高效有着一定的要求。实践表明,基于历史数据进行基准挖掘能够良好的解决上述稳态。合理地运用基准也能够在保证机组安全运行的同时有效降低可控的能耗损失。因此,准确、合理的基准值对提高机组运行效率和节能降耗具有重要意义。
李打油嘴都笑歪了。真的歪,跟我父亲一样,平时看不出,浅笑也看不出,只有笑得特别开心时,笑过后要把笑容收回去的那一瞬间,才会发现,他俩嘴都有点歪。共祖宗嘛,也许家族遗传。估计我也是。可我好像没遇到什么特别开心的事。
利用大数据分析方法来进行基准挖掘已成为当前的主流方法,包括模糊C-均值聚类算法[9]、K-Means算法[10-11]等。聚类是将一个数据集分成由类似的数据样本组成的多个类的过程。由聚类所生成的簇是一组数据样本的集合,这些样本与同一个簇中的其他样本彼此相似,与其他簇中的样本相异。通过聚类,可以从数据集的大量样本中提取出具有代表性的几堆,有助于简化问题。因此,本研究也采用聚类的方式来进行基准挖掘。
聚类算法包括基于划分的聚类方法、基于层次的聚类方法、基于密度的聚类方法等。基于层次的聚类方法可解释性好,但时间复杂度高;基于划分的聚类方法,如K-Means算法,其对于大型数据集是简单有效的,时间和空间复杂度低,但需要预先设定K值;基于密度的聚类方法,如DBSCAN,能发现任意形状的聚类,但聚类的结果与参数有很大的关系。本研究结合了FM度量,通过稳定性算法确定聚类参数,再通过K-Means算法进行聚类分析,得到聚类结果,能对K-Means算法的缺陷进行一部分的补足。
3.1 FM度量
FM度量是一种对聚类的质量和优度进行评价的指标。其通过对样本点的划分标签和分簇标签进行分析,度量聚类的精度,其最大值为1,聚类质量越高,FM度量值越接近1。
式中,prec是聚类的成对精度,其衡量了正确聚类的点对占同一个簇中所有点对的比例;recall是聚类的成对召回,其衡量了正确标记的点对占同一个划分中所有点对的比例。
3.2 K-Means聚类算法
K-Means算法采用一种贪心的迭代方法来找到使得SSE目标函数值最小的聚类。K-Means聚类算法的基本原理与步骤如下。首先从数据空间中随机生成k个点作为初始的聚类中心;其次,计算并比较其他的数据样本到k个聚类中心的距离;再对距离大小进行排序后,将数据样本划分到最近聚类中心所在的那一簇;划分结束后,重新计算每一簇中样本数据的平均值,将其作为新的聚类中心。不断重复上述过程,直到目标函数值收敛。
式中,SSE表示所有样本点的平方误差总和;xj代表第i个簇内第j个样本点;μi代表第i个簇的中心。
K-Means聚类算法的聚类效果依赖于聚类参数k的选择,聚类中心数过少,则样本的特征不能够全面体现;聚类中心数过多,同一簇中的数据可能会被分隔开。
3.3 分簇稳定性
分簇稳定性的主要思想是,从与D相同的分布中抽样得到的若干数据集生成的聚类应当是相似或“稳定”的。分簇稳定性的方法可用于找出一个给定聚类算法的合适参数值。分簇稳定性算法的基本原理与步骤如下。首先通过从D中抽样,生成t个大小为n的样本,然后对每一个样本Di,分别用不同的参数值运行相同的聚类算法。然后通过计算在每一个参数上的每一对数据集的聚类之间的距离。最后,计算期望成对距离,选择使得期望成对距离最小的参数作为最佳参数。

分簇稳定性算法流程:step1:输入聚类算法A,抽样数量t,分簇最大数目K,数据集D;step2:通过有放回抽样,从数据集D中抽取与之数据量相同的样本,记作D1,D2,...,Dt;step3:对每一个数据集D1,D2,...,Dt,分别使用聚类算法A,将Di聚类分为k个簇 ;step4:为了计算分簇间的距离,需要先对数据集对去交集,记作D(1_2)1,D(1_3)1,...,D(t-1_t)1;step5:对每一个k,计算不同数据对间的分簇距离,记作dk i_j,本研究选择FM度量(相似度);step6:对每一个k,计算期望成对距离,记作μk d;step7:选择使得成对距离最小(相似度最大)的k作为该数据集D的最佳k值。
4 案例分析
4.1 数据介绍
为了验证模型的有效性,选用某实际运行的双抽式汽轮发电机组作为案例。从DCS集散控制系统 (Distributed control system)中采集历史运行数据,采样间隔为1 min。因为该机组纯凝期和供热期的数据有较大差距,故选取纯凝期2020年—8月的机组平稳运行数据记录作为案例的训练样本,共计165 016组,选取2021年6月的数据作为案例的测试样本。其中,训练样本中主蒸汽流量波动如图1所示。从图1可以看出,当主蒸汽流量从一个稳定状态切换到另一个新的稳定状态时会经历短暂且快速的非稳态过程。在运行数据中存在着大量的非稳态工况。因此,有必要先将机组的非稳态工况与稳态工况区分开,对165 016组机组原始运行数据样本进行稳态判别。
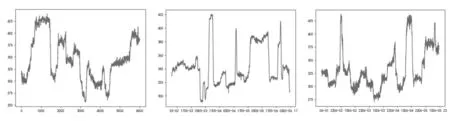
图1 主蒸汽流量波动
4.2 稳态筛选
采用机组运行人员提供的几个重要指标的波动性对原始数据进行稳态筛选,共有79 831组样本被划分成稳态工况,其余样本则被划分成非稳态工况。分别绘制稳态工况和全数据情况下主蒸汽流量的波动曲线,如图2所示。从图2可以看出,稳态工况下主蒸汽流量的分布呈现明显的稳定性。
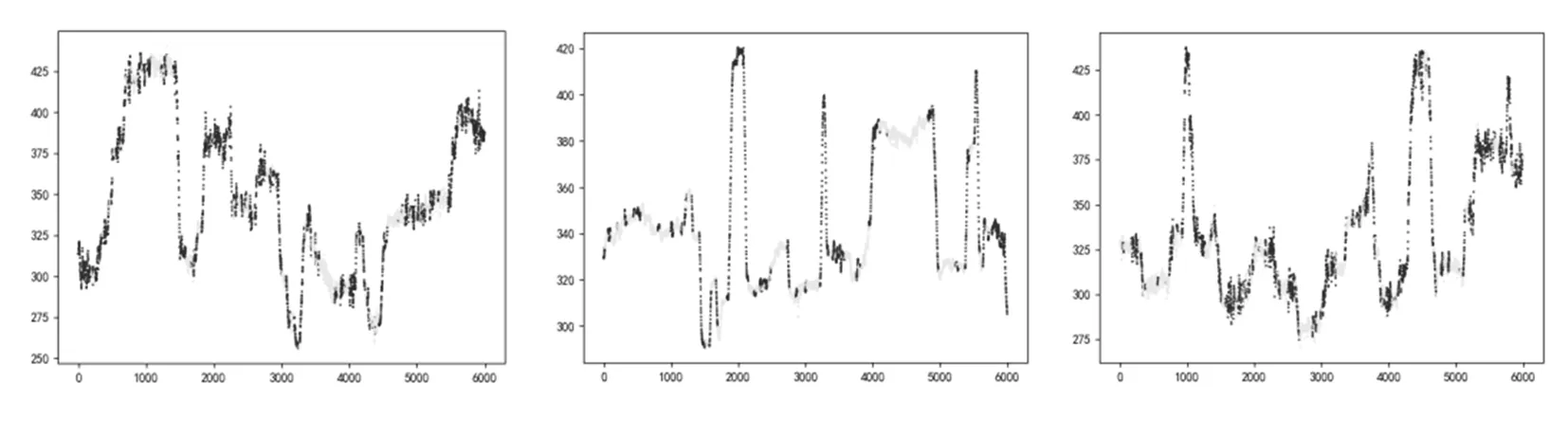
图2 全数据与稳态数据对比
4.3 特征选择
在稳态工况被筛选出的基础上,我们以工业生产运行人员提供的特征作为重要特征,针对稳态工况中的异常数据进行了异常值处理,分别进行了均值填补和删除,使得数据质量进一步提高,有助于基准挖掘的准确性和实用性。并且,我们根据参数条件的不同,将数据样本进行划分,以参数从小到大的顺序将其划分为37个工况,记作工况1、工况2、...、工况37。如图3所示。相同的工况下,参数条件相对一致,因此,在细分的工况中进行基准挖掘能够更好的覆盖机组运行的实际条件,准确性也会随之提升。
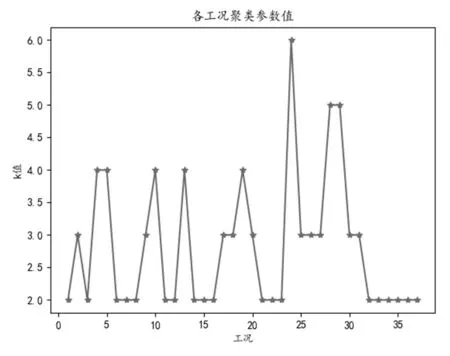
图3 各工况聚类参数k值
4.4 聚类分析
为了从运行工况中提取出最具指导意义的运行基准,采用FM度量通过稳定性算法自适应的生成k值,各工况k值如下图所示。然后使用K-Means聚类算法对工况内的样本进行聚类。
对比同一工况的不同聚类簇,从图4可以看出,不同的聚类簇可以很好的将工况中的数据样本区分开来,聚类效果良好。然后,为了更好地节能降耗,我们选取簇中心煤耗最低的簇作为基准簇。

图4 同一工况的不同聚类簇
4.5 基准提取
选择同一工况下使得煤耗最低的簇中心,作为该工况的基准,如表1所示。
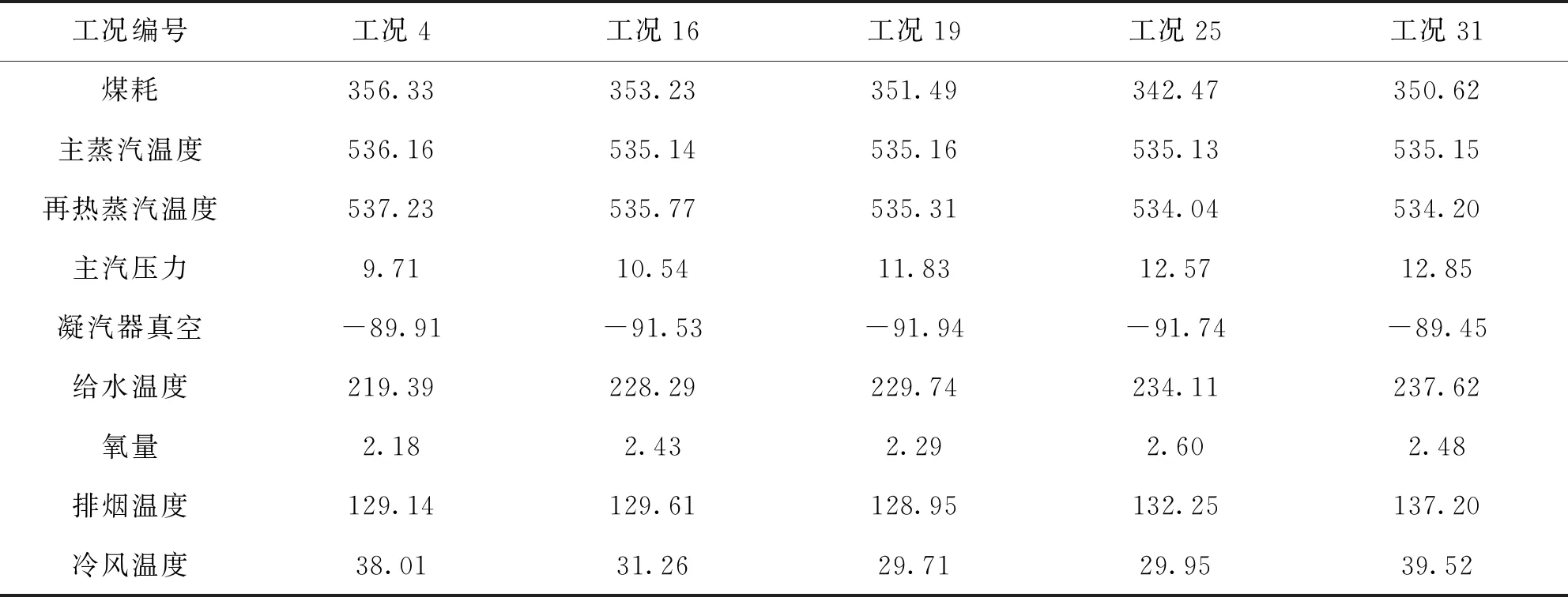
表1 各工况基准值
4.6 结果分析
为了测试基准是否能够优化运行,选用2021年6月1日—2021年7月1日的实际运行数据,并根据其工况推送出对应的基准,如图5所示。
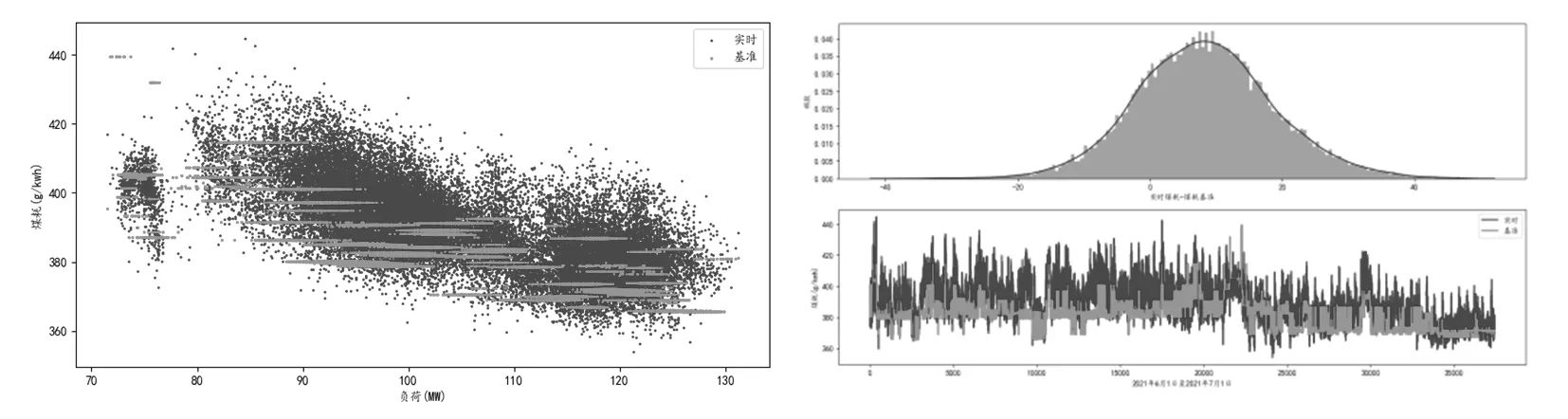
图5
我们能看到基准煤耗普遍是低于实际运行的煤耗的,其中,煤耗的基准值与实际运行值相比,基准值比实际值低了8 g/(kW·h),也就是说每发电1 kW·h则可节省煤量8 g。因此,运行基准挖掘对于实际运行生产具有高效经济的作用。
5 结语
针对大型工业生产运行机组基准挖掘稳态展开研究,以重要特征为出发点,利用机组大量运行数据,采用基于FM度量的自适应K-Means聚类算法,确定影响机组运行效率和节能降耗的参数基准值。并通过案例分析,首先通过对数据进行稳态工况筛选,并对异常值进行处理,然后利用基于FM度量的自适应K-Means聚类算法进行聚类,并选择使得煤耗最低的聚类簇中心作为参数基准。通过基准煤耗 与实际煤耗进行比较,验证了所提方法的有效性。
猜你喜欢
中国生物化学与分子生物学报(2022年6期)2022-09-06
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年10期)2022-08-22
上海师范大学学报·自然科学版(2022年3期)2022-07-11
上海师范大学学报·自然科学版(2022年3期)2022-07-11
汽车实用技术(2022年4期)2022-03-07
好日子(下旬)(2020年6期)2020-08-04
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
读者·校园版(2015年7期)2015-05-14
克拉玛依学刊(2011年3期)2011-04-16
