
医疗大数据环境下的疾病预测模型研究
2022-08-31 03:46刘晓燕
制造业自动化 2022年7期
王 星,刘晓燕
(1.昆明医科大学第一附属医院 昆明 650000;2.昆明理工大学 信息工程于自动化学院,昆明 650000)
0 引言
医疗诊断是就医过程中的一个重要环节,除通过仪器的检验、检查外,日常医疗诊断很大程度是一种基于经验的判定方法,通过长期对病例的症状分析和经验积累,得出常见疾病的诊断方法,再将该方法应用于新的病例中,根据新的病例表现出的既有症状信息,得到最初的疾病类型判断。大数据指无法使用传统工具或方法进行分析处理的、具有复杂关系的庞大数据集合,需要利用纵向信息对数据进行补充分析[1]。医疗大数据是医疗卫生机构产生的一切与生命科学相关的复杂大数据[2]。医疗大数据领域中运用的浅层机器学习算法模型有回归分析、决策树、基于内核的算法、降低维度算法等[3]。在医疗大数据的基础上,疾病诊断方法可以通过决策树模型进行表达,并且建模分析,得到数据分类模型,用于预测和判定未知数据的已知类型。
在机器学习理论中,决策树是一个预测模型,在一定现有数据结论基础上,基于特征值与对象概率分布规律,构建决策树对实例进行分类的方法。决策树模型很自然地还原了做决策的过程,将复杂的决策过程拆分成了一系列简单的选择,因而能直观地解释决策的整个过程[4]。它是一种常用的树形结构分析工具,其中各非叶子节点代表一个特征值的判定测试,每个叶子节点表示实例的类别,每个树形分支表示该类别所有值域上的输出。使用决策树进行决策分析时,待分类数据从根节点开始进行特征值判定,并根据判定值选择分支,一直到叶子节点,最终测试数据的决策类型就是这种节点的类别[5]。
医疗诊断分析中,可同样使用历史诊断病例,以此作为数据基础模型,通过病例中的检查项目数值作为疾病类型的特征值,对不同特征值的疾病类型概率分布进行分析,建立检查项目特征与疾病类型的概率预测模型。决策树在建立时,相关的步骤包括特征选择、决策树生成、修剪[6],以下具体论述。
1 决策树分析
1.1 特征选择
信息论是量化处理信息的分支科学,划分数据的原则是将无序数据变得更加有序,划分数据前后信息的变化等同于信息增益。基于各特征进行划分,确定出的信息增益最大特征就对应于最优判定选择[7]。所以特征选择必须先计算每个特征带来的信息增益,最优特征的信息增益最大。
特征选择目的在于建立起原始分析数据集,原始数据集包含特征值和分类结果,普通医疗检验就是特征选择的实际执行过程,每个检验指标可作为一个特征值,如:体温、体表症状、各类血液检验指标等,分类结果就是该病例的最终疾病诊断。当一类疾病在一个特征值上有明显分布规律时,可直接通过该特征值得到病情分类,该特征值就是区分该类疾病的最优特征。原始数据集数据越大,特征值划分越精细,得到的决策树就越茂密,分析结果也就越准确。
信息集合的度量方式称为香农熵,简称熵,可将其看作为信息的期望,如果对象可划分为很多类,则符号xi的信息熵可描述如下:

其中,p(xi)具体表示选择该类型的概率。
在进行熵值计算时,需要确定出全部类型所有特征值对应的信息期望值,可通过下面公式得到:

其中n为分类数目,熵值和对象的不确定性存在正相关关系。基于数据估计方法确定出的熵就是经验熵。若十个数据划分为两类:A、B类,A类含四个数据,则数据中A类出现的概率为4/10;另外6个数据属于B类,则出现B类的概率为6/10,这些概率基于已有数据统计确定出。定义样本数据中的数据就是训练集D,此集合的经验熵表示为H(D),|D|对应于其样本容量。为方便分析假设存在K个类CK,k=1,2,….K,|Ck|为属于类Ck的样本量,则可通过如下表达式计算出经验熵:

根据历史诊断病例描述,通过医疗数据选取出主要疾病的特征描述信息,设定数据集D如表1所示。

表1 特征描述信息
样例中共9个疾病特征,诊断类型有2类,13个病例中,8个诊断为咳嗽病,因此数据中咳嗽病出现的概率为8/13,感冒出现的概率为5/13,根据经验熵计算公式得到数据集D的经验熵为:

信息增益含义为特征x的信息确定后,类Y的信息确定性增加的程度。
条件熵H(Y|x)含义为变量x明确情况下,Y的概率值,H(Y|x)对应于x给定后Y的条件概率分布的熵对x的数学期望:

其中,pi=p(x=xi),在基于数据估计确定出熵和条件熵相关概率情况下,以上两种熵就是经验熵和经验条件熵,此时如果有概率为0,则令
信息增益和特征存在相关性,因而特征A对集D的信息增益g(D,A),可看作为此集合的经验熵H(D)与特征A明确时其经验条件熵H(D|A)的差值[8],具体表示如下所示:

此差值对应于互信息,而决策树学习中的信息增益可看作为训练集中类与特征的互信息。
在实际计算中,依据原始样本病例得出的经验熵H(D)=0.9612,我们分别计算每个特征所能得到的信息增益,去掉该特征值后的新数据集H(D|A)的经验熵,两者的差异量如表2所示。

表2 差异量
从上表数据可以看到,通过咯痰或咽痛两个特征进行疾病划分,能更快区别出病例为咳嗽病或是感冒,因此咯痰或咽痛可作为优先判定的特征值,此特征值判定应当作为决策树的根判定节点。
信息增益值的大小对于训练数据集而言,不存在绝对意义,在分类难度很大情况下,相应的信息增益值会偏大,相反情况下则偏小,可通过信息增益比而适当的校正,在特征选择时一般以此标准进行。
信息增益比:特征A对集D的信息增益比gR(D,A),
可通过益g(D,A)与集D的经验熵比值确定出,具体表达式如下所示:

1.2 决策树的生成
在得到原始数据集后,基于最优特征值对数据集进行划分,由于特征值可能为多个,这样在划分时,相应的数据集也可能超过二个。在初次划分后,需要将数据集传递至分叉树的下一个节点,然后在这一节点上,对数据进行再次划分,从而基于递归模式对数据集进行处理,满足相关应用要求。
在上一步中,将病例诊断信息分析为特征值集合和分类结果,构建出原始数据集,决策树的生成过程则是医疗诊断过程,通过医生对各个检验指标进行经验总结,得到分类结果。
ID3[9]算法生成决策树,ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树[10]。
输入:训练集D,特征集A;
输出:决策树T。
相应的生成流程如下:
1)若训练集合D中全部实例都被划分为类别CK,这种情况下设置T为单节点树,并将Ck当做此节点的类别,返回T;
2)如果A=Ф,则置T为单节点树,而此节点的类别对应于D中实例最大的类Ck,然后返回T;
3)相反情况下基于信息增益比表达式确定出A中各特征对D的信息增益比,对所得结果进行对比确定出此值最大的特征Ag;
4)对节点i,以Di为训练集,以A-Ag为特征集,基于以上方法进行递归分析,而确定出子树Ti,结束后返回Ti。
对全部划分数据集的属性进行遍历后,各分支对应的全部实例相关的分类相同,在全部的实例对应的分类都一致情况下,确定出一个叶子节点或终止块,任何达到叶子节点的数据必然属于叶子节点的分类[11]。
1.3 决策树的修剪
决策树生成算法递归确定出决策树,一直到满足结束递归条件,在此基础上确定出的树可更好的进行训练数据的划分,所得结果的精度高。不过对未知测试数据的分类所得结果的准确性相对有限,容易产生过拟合现象。这种现象的产生原因为,学习时过于侧重提高分类正确性,而导致建立的决策树过于复杂,处理方法是对建立的决策树适当的化简,降低其后的处理难度。
决策树修剪的意义在于减少需要判定的特征值复杂度,在医疗诊断中,存在着大量的检查指标,实际情况下对于一个疾病的诊断,并不需要检验所有的项目,通常先进行一些基本的检查,例如:体表表现、常规血液检验等,通过这些基础指标得到疾病的大致分类,再针对该分类下的指标进一步进行其他项目检验,直至得出诊断。通过决策树的剪枝,可以得到常规医疗检验的项目指标,减少不必要的检验项目和检验次数。
剪枝:对得到的决策树进行修剪,将其中的一些子树或叶子节点剪去,而新的子节点设置为根节点,这样可使得分类树结构简化。
可基于决策树的损失函数或代价函数最小来实现。
决策树学习的损失函数定义为:

其中T对应于此子树的叶子节点,Nt对应于此叶子相关的训练样本数,α对应于惩罚系数,Ht(T)则为第t个叶子熵,其计算公式为:

其中C(T)含义为对训练数据的预测误差,可看作为相应的拟合水平;
α表示,α≥0参数控制两者之间的影响,此参数较大情况下确定出的模型结构更简单,而相反情况下建立的决策树更复杂,如果其为零,则对应于单纯考虑拟合水平,决策树的复杂性不需要考虑。
剪枝对应于α确定情况下,得到损失函数最小的子树。
α确定后,训练数据的拟合效果和子树大小存在正相关关系,不过子树大,则对应的复杂度越高,相反情况下则拟合效果差,损失函数表达了两者间的平衡度。
决策树的剪枝对应于从叶子节点进行递归,全部子节点回缩后的子树记为Tb,而没有回缩的子树为Tb,如果存在如下关系式:

则可判断出回缩降低了损失函数,这样就需要进行回缩处理,进行递归一直到不能进一步回缩。这样就基于贪婪算法进行剪枝处理,而简化了决策树。
决策树建立的目的在于更好的拟合训练数据,而剪枝操作主要是基于优化损失函数而使决策树得以简化,也为其后的分类处理提供支持和便利。
1.4 使用决策树进行分类
决策树分类[12,13]是分类算法中的一种应用最广泛的技术,它通过寻找数据间的联系,描述数据的关系模型,从而能够作出预测。在决策树建立基础上,可基于其划分实际数据集合,通过数据分类过程中各属性值与决策树节点的数值进行比较,递归执行该节点及其子节点,最后到达的叶子节点即为分析预测的该数据分类。
医疗诊断分类的过程,则是根据医疗检验得到的项目指标,对各个指标进行判断,将疾病类型划分在历史病例中。
2 决策树应用
通过对实际医疗诊断过程结合决策树算法的分析,得出可将决策树应用于医疗诊断的应用过程,通过以下过程实施,可得到决策树模型。
2.1 构建原始数据集
在前面的决策树分析过程中,我们将病例中的检查项目指标作为特征值,构建分析原始数据集。
2.2 计算数据集经验熵
计算原始数据集的经验熵,其输出结果符合预计计算。
2.3 最优特征选择

图1 原始数据集的经验熵
在第一轮最优特征选择中,计算得出的经验熵符合预计结果,选取咯痰作为最优特征。
2.4 决策树生成
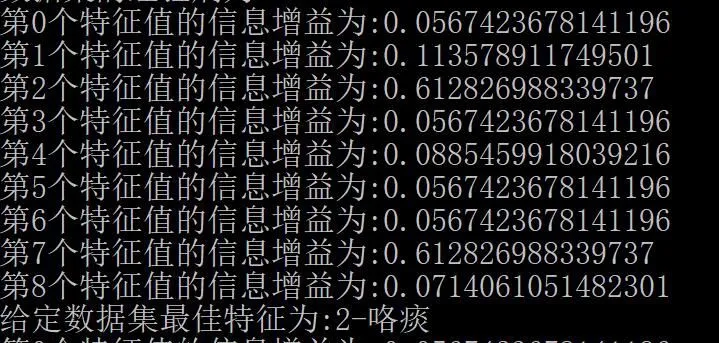
图2 最优特征选取
重复上面的最优特征值选择步骤,直到数据分类完毕或特征判定结束,获得最终的决策树。最终得到的决策树结构。
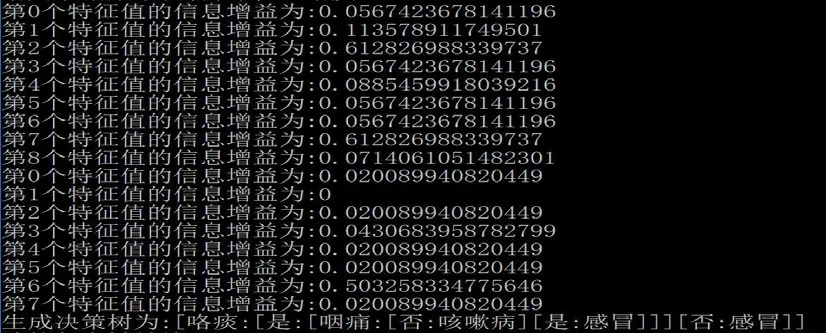
图3 最优特征判定结束
基于样本病例得到的决策树,判定逻辑如图4所示。

图4 最终决策树结构
决策树的最终特征值仅有:咯痰和咽痛,与原始数据集中采集的特征值有很大程度的减少,对原始数据的病例诊断结果保持不变,实际应用中,可根据决策树最终特征值进行检验指标进行采集,减少了无用或者与疾病关系不大的指标采集过程,可减少疾病诊断检验复杂度。
3 结语
医院大数据为分析病情提供了实现基础,在选取了部分样例进行实验过程中,通过算法的描述得到了较简化的区分感冒和咳嗽病的决策树模型,使用该模型对其历史病例进行测试,具有较高的准确率,基本达到诊断要求。通过医疗诊断分析模型的构建,可用于自动疾病初步预测、非医疗人员疾病诊断辅助信息手段、医疗检验项目指标制定,具有一定的可行性和指导意义。但是,如何寻找更好的数据预处理方法,如何发掘更好的优化决策树方法,如何更有效快速地完成决策树剪枝,如何将决策树与多种方法交叉结合等多种问题,都需要今后的学习中去研究[14]。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年6期)2021-07-20
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
电子制作(2019年19期)2019-11-23
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
课程教育研究·新教师教学(2016年18期)2017-04-12
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
