
基于聚类站点客流公共特征的轨道交通车站精细分类
2022-08-30 02:40蒋阳升俞高赏胡路李衍
交通运输系统工程与信息 2022年4期
蒋阳升,俞高赏,胡路*,李衍
(西南交通大学,a.交通运输与物流学院,b.综合交通大数据应用技术国家工程实验室,成都 611756)
0 引言
城市轨道交通是公共交通的重要组成部分,站点分类本质上是对该站点所在区域的土地利用特征、区位属性、人群属性进行分类。因此,通过对站点的精细分类可以对该地区的空间特征与轨道交通的利用情况有更深刻的认知,为城市规划以及站点周边土地开发提供参考。
目前,国内外关于轨道交通站点的分类已有很多研究,主要集中在以下几个方面:①以站点与周围站点或枢纽的连接情况进行分类。邵滢宇等[1]基于站点与中心区域距离、接驳公交线路条数、站点建筑强度等对哈尔滨地铁进行聚类分析,能有效划分地铁吸引范围。②以站点周边建筑的土地利用特征情况进行分类。段德罡等[2]考虑站点周边能影响到的区域的土地功能特征以及用地均匀度为依据,对站点进行分类,并提出周边土地利用类型的优化方案;傅搏峰等[3]考虑地铁站点本身的交通功能以及周边的场所特征,采用定性与定量相结合的方式提出面对郊区轨道交通站点的分类方案。③以站点的进站客流量(简称客流量)波动特征情况进行分类。Zhang等[4]将客流量建模为时间序列曲线,仅考虑曲线特征,使用两阶段法对曲线进行聚类,考虑了曲线波动本身的特征;Li等[5]考虑客流量波动中波峰波谷数量以及偏度等特征数据,将其作为依据,将站点聚类6个大类。
以上几种方法均能在一定程度上对轨道交通站点进行合理分类。第①种方法优点在于分类标准清晰,考虑到站点之间的空间布局情况,有利于轨道交通线路的整体规划布局;缺点在于未考虑到周边土地利用情况,无法根据其布局调整周边的土地建设。第②种方法优点在于充分考虑土地利用对轨道交通站点的影响,有利于指导后期土地利用建设;缺点在于需要海量POI(Point of Interest)数据对其分类进行支撑,并且由于周边土地利用的变化,站点的分类结果也会改变,时效性较强。第③种方法优点在于无需采集复杂的土地利用数据或者POI 数据,以客流量变化特征进行分类,标准明晰且非常直观;缺点在于分类效果粗糙,无法体现大类组内的差异性。
本文结合前两种分类方法的优点,对第③种分类方法进行改进,提出一种轨道交通站点精细分类方法,在仅使用AFC数据的前提下,将各站点聚类为几个大类站点,找出其大类站点的客流量波动与土地利用之间的关系,获得大类站点的客流公共特征;进一步,充分考虑同属一个大类的每个站点的客流细分特性,提出利用客流量公共特征比重组合,对每个站点进行精细分类描述。
1 数据处理过程及站点聚类算法选取
1.1 数据处理
本文基于客流量特征对轨道交通站点进行分类,对数据格式要求较高,规范化数据处理过程如下:首先删除无关数据,冗余数据以及不在轨道交通运营时段内的数据,按照站点和时间将其归类。而后,选取合适的时间步,轨道交通站点进站客流量时间间隔一般选取5,10,30,60 min。时间间隔选取过短会导致客流量随机性波动过大,时间间隔选取过长会影响下文精细分类结果,本文考虑以上两个因素后选取10 min作为一个时间步,并对AFC数据按照10 min为间隔进行统计,生成站点时间序列数据。最后,做归一化处理,不同站点由于其地理区位等因素导致客流量总数差异较大,如不进行归一化,将会放大大站与小站之间的差异。因此为保证聚类效果,本文对每个车站进站客流量统一进行归一化处理,为使归一化对客流量波形的影响降到最小,本文使用Min-Max 标准化(Min-Max Normalization),其计算方法为
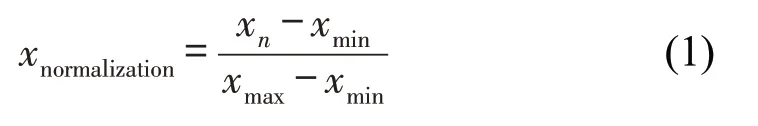
式中:xn为当日第n个时间段内的客流量(n=1,2,…,m),m为一天中运营时段包含的总时间间隔数;xmin、xmax分别为当天客流量最小值、最大值,保证归一化效果不被某些极端日期的巨大客流影响。
1.2 聚类算法选取以及评估方案
本文将站点进站客流量转化为时间序列数据,将站点客流聚类问题转换为时间序列聚类问题。一般来说时间序列聚类有3种主流方案:度量时间序列距离函数[6]、时间序列的特征提取[7]与机器学习聚类方案[8]。K-Means 算法属于第1 类聚类算法,具有计算简便,效率高等特点,适用于样本量大的分类情况。由于本文时间序列数据聚类特征过多,使用其他算法计算复杂,故采用K-Means++方法聚类。该算法在原算法的基础上改进了对初始聚类中心选取方案,使得聚类准确性较原算法有了进一步提高[9]。
此外,本文使用肘部法则(Elbow)对时间序列聚类效果进行评估。肘部法则将不同聚类数量的簇内误差平方和作为成本函数,随着聚类数量的增加,其簇内误差平方和会逐步减小,样本距离簇内中心点越近,但是同时每个类所包含的样本数量也会逐渐减少,使分类效果变差。肘部法则就是在其中寻找一个平衡点,将聚类数量增多过程中,簇内误差平方和下降幅度变化不明显的位置作为肘部,并选取为聚类数量[10]。
2 两阶段站点精细分类方法
2.1 基于客流公共特征聚类分析的站点大类判别
对于聚类后的大类站点,本文希望能通过一定的方法求出每个大类站点客流量的公共特征作为该类站点的客流量波形代表。对此,本文提出的公共特征波形提取步骤如下。
Step 1 去除异常曲线。由于聚类方法的局限性,存在一些数据被错误的分类到这个大类中,本文通过求每条曲线与该类中其他所有曲线的平均欧式距离的方法筛选出误差最大的几条离群曲线并删除。
Step 2 初始特征曲线的确定。由于每条曲线代表一个站点在一天内客流量的变化值,将其视作散点值,使用SPSS 等分析软件利用曲线拟合找出大类站点的初始特征曲线。
Step 3 度量曲线相似性。Step 2 确定的初始特征曲线只是通过简单的拟合所得,并未考虑到每条曲线的整体性,故需要一个方法来度量两条曲线之间的相似性。本文所使用的客流量曲线由离散的数据点构成,两条客流量之间的相似性[11]计算方法如下:
设L1、L2分别为离散有序点串,,其中,M,N分别为L1、L2中包含的有序点数量。定义DF为L1、L2之间的相似度距离,求解公式为
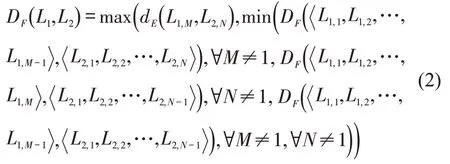
式中:dE(L1,M,L2,N)为点L1,M与L2,N之间的欧式距离,使用递归进行计算。当离散有序点串逐步缩减为一点时递归计算终止,此时有
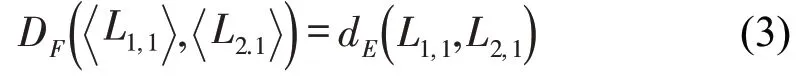
在递归计算中会产生两个计算矩阵,矩阵维度为M×N,其中一个矩阵为G矩阵,矩阵元素Gi,j的值为点L1,i与L2,j之间的欧式距离。另一个H矩阵的矩阵元素Hi,j为
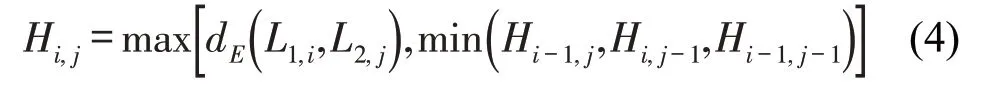
式中:Hi,j为DF的值。
计算完所有曲线与初始特征曲线的相似度后,在大类中删除与初始特征曲线相似度最低的一条曲线,再对剩余曲线重新进行拟合。
Step 4 更新特征曲线。重复Step 2 和Step 3,不断更新特征曲线,直至特征曲线不再出现明显变化,此时所得的特征曲线即能较好地代表该大类站点的公共特征。
2.2 基于客流公共特征比重的站点类型精细表达
轨道交通站点客流量主要由该站点所处区位的土地利用特征以及人口密度决定,虽然每个站点所处区位不同,不会出现处于完全相同土地利用类型区位的站点,但是每个站点的客流量都会体现出相似的特征(这也是时间序列聚类的核心)。在2.1节中,根据聚类结果求得每个大类站点的客流公共特征。接下来,通过精细分类找出每个站点所包含公共特征的比例,反映出该站点在每个大类站点中区别于其他站点的特异性。本文提出的站点精细分类原理如下:
Step 1 确定每个站点一天内客流量波动情况,为避免某一天内站点出现极端天气,大型集会造成的客流量不稳定情况,将每个站点按时间间隔对客流量求均值,将其作为每个站点特征客流量,记为Q。其中,Qi,j为第i个站点中第j个时间段的特征客流量。
Step 2 建立大类站点客流公共特征客流量矩阵与类型比例矩阵。

式中:xm,n为第n个大类中第m个时间段内归一化后的客流量值;ai,j为第i个站点中第j类别大类公共特征比例值,其值在0~1 范围内,并且∑ai,j=1;初始A矩阵的取值为ai,j=1,n为该站点所处的聚类大类的类别值,其余值取为0。
Step 3 计算精细分类拟合客流量值P,并将其重新归一化。

式中:Pm,i为在第i个站点第m个时间段内的归一化后的客流量拟合值。
Step 4 使用式(3)计算与站点特征客流量曲线之间的相似度距离值,以相似度距离值最小为优化目标,即minφ=DF(Pi,Qi),不断优化类型比例矩阵A。当相似度距离值最小时,此时精细分类拟合客流量曲线与原站点特征客流量曲线相似度最高,其类型比例矩阵即为本文所求的精细分类结果。
3 实例分析
3.1 站点初步聚类以及公共特征提取
本文选取成都轨道交通站点进站数据,通过上述流程对数据进行处理。由于休息日客流波动较大,与工作日客流特征明显不相符,故只选取工作日客流进行分析。为保证数据对分类的可解释性,所选取时段内不包含重大节假日、极端天气以及重大人群聚集活动,时间跨度为2017年7月1~31日,共有21 个工作日。所选取时段内共计4 条线路97座车站,共计4500万条信息,其中轨道交通运营时段为6:00-23:00,根据上文,将1 天分为102 个时间间隔。
对97 座站点的21 个工作日数据生成2037 条时间序列数据并打上站点标签,使用上文KMeans++算法进行聚类。K-Means++算法需要提前输入聚类数量,因此根据聚类数量肘部法则[10],生成聚类数量误差图如图1所示。
用空白血清制备低、中、高浓度的质控样品,每个浓度质控样品取6份测定作为日内精密度,连续检测3天获得的结果作为日间精密度。向空白血清中加入低、中、高浓度的标准品,每个浓度各取6份,通过计算检测值与加入的标准品的比值,取平均值得到回收率。结果表明,各药物的日内、日间精密度(RSD%)均小于15%;平均回收率在90%~110%。见表4。
由图1可知,当聚类数量大于5时,簇内误差平方和的减少已经不明显,故选取聚类数量为5重新聚类。由于每个站点有21 条时间序列数据,选取21 条数据在5 类大类中分布最多的一类作为该站点的聚类大类。所得聚类结果如表1 所示,其中,第1类站点数量最多有51个。
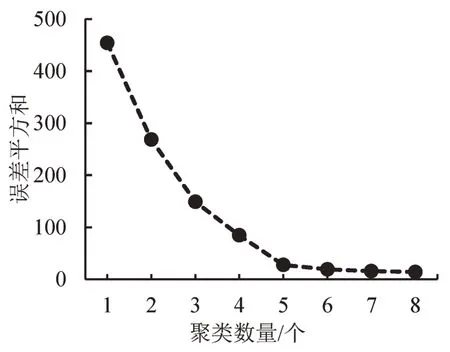
图1 聚类数量误差图Fig.1 Variation of classification error with number of clusters

表1 聚类结果表Table 1 Clustering results
本文对聚类所得五大类站点的客流量波形特征进行分析。考虑到客流量的实际意义,选择以下几类特征进行分析,并根据客流特征情况对五大类站点进行命名。特征包括:①高峰个数,该特征体现了站点中1天内会出现高峰客流的次数,能较好地体现客流量波动的差异;②高峰客流比值,高峰客流比值是指1 天中客流量最多的高峰小时内客流量与总客流量的比值,该特征体现了客流在1天中分布的均衡性;③高峰出现时间,该特征是指1天中出现客流量高峰的时间,能有效体现站点的客流属性。基于上述特征生成大类站点客流量特征表如表2所示。

表2 大类站点客流特征Table 2 Passenger flow characteristics of cluster stations
对于聚类后的大类站点,采用本文提出的公共特征提取方案,并用式(1)进行客流量归一化,生成每个大类站点的公共特征波形曲线如图2所示。
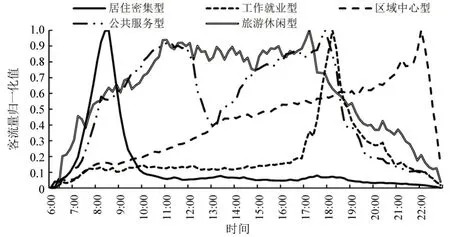
图2 大类站点公共特征曲线图Fig.2 Common feature curve of cluster stations
3.2 站点精细分类及结论分析
根据本文提出的站点精细分类方法,对成都97座地铁站点进行实证分析。几个大类站点中代表性站点的分类结果以及对应的结论分析如表3所示。
3.2.1 精细分类效果验证
取春熙路站为代表性站点,根据表3 可知,该站点由49%工作就业型特征以及51%的区域中心型特征叠加而成,将其与真实客流量对比,如图3所示。可见分类拟合结果能较好地表现出正常情况下春熙路站的客流波动,以常见的评价指标MAPE 作为评价其效果的指标,计算得出,春熙路站拟合值的误差在11%内。同时其他站点平均误差值都在14%左右,而客流预测模型在客流值拟合上的误差值约为12%[12],两者效果相差无几,故认为精细分类效果可以满足下文分析。
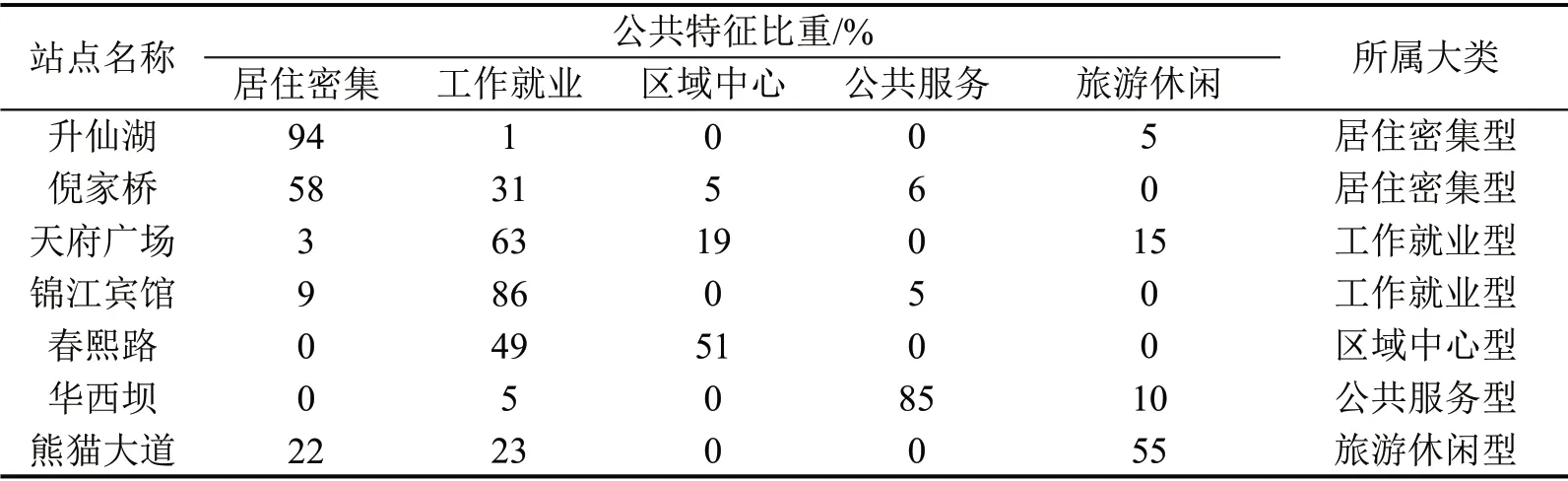
表3 部分站点精细分类结果Table 3 Accurate classification results of some stations
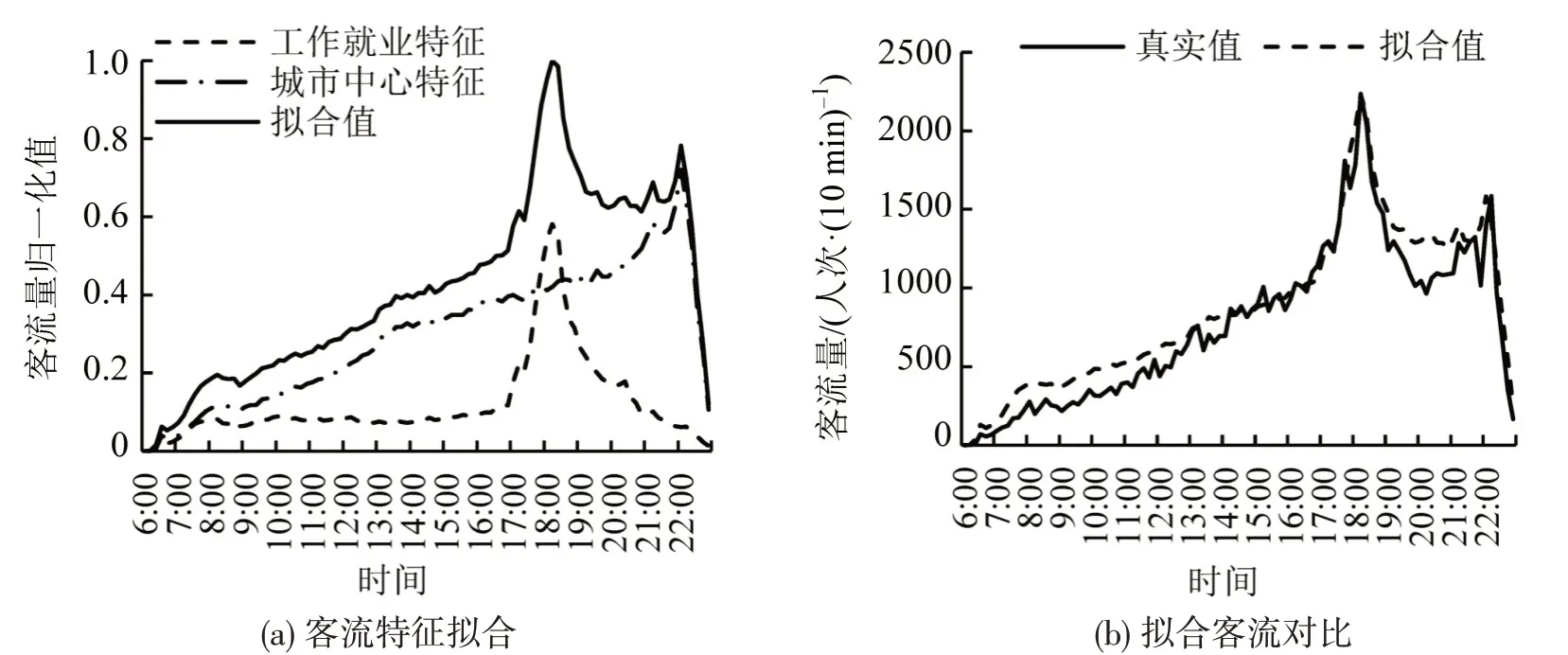
图3 春熙路站客流量拟合图Fig.3 Fitting diagram of passenger flow at Chunxi Road Station
3.2.2 从土地利用角度分析精细分类结果
选取表3 中同属居住密集型的两个站点进行分析。其真实客流量对比如图4所示,升仙湖站体现出94%的居住区特征,仅包含一个早高峰。与此相比,另一个站点倪家桥站虽然有很大一部分早高峰特征体现,但是其中晚高峰的特征同样不可忽视。部分文献将该类站点归类为职住交错区域[13],但并不能完全体现该类站点的特点。从表3 可以看出,该站点除了居住型特征达到58%,其工作就业型特征也达到31%。在聚类中虽然将两个站点分为一类,但两者不管是土地利用类型还是客流量波动仍具有较大差异。本文精细分类方案能有效体现出该类差异。
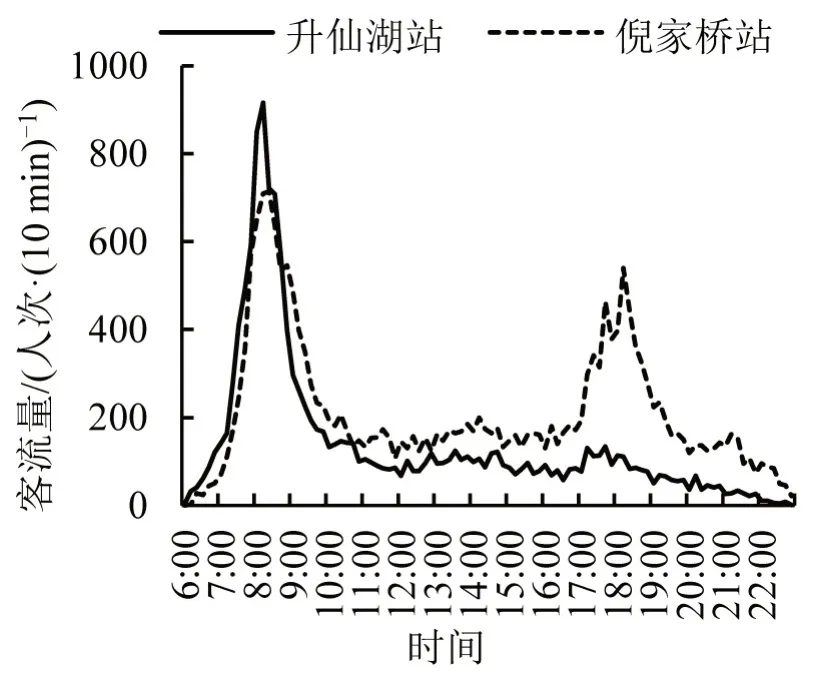
图4 聚类组间站点客流量对比图Fig.4 Comparison of station passenger flow between cluster groups
从另一个角度看,目前绝大部分文献对站点分类的研究集中于从POI 数据来体现土地利用特征[10],该类方法能精确表示当前站点的土地利用类型,但对数据质量要求很高,需要非常庞大的POI数据进行分析,并且随着社会发展,土地利用性质在不断地发生变化,因此对数据的时效性要求也非常高。本文提出的精细分类方案优势在于可以从客流量波动特征反推当前站点的土地利用性质。
以成都天府广场站为例,该站处于成都市中心,其周边有大量的工作就业型土地,并且根据表3中精细分类结果,还能看出天府广场站额外承载着部分区域中心区以及旅游休闲区的功能,其土地利用特征比例为63%工作就业类土地,19%区域中心类土地,15%的旅游休闲类土地以及3%居住类土地。为验证模型的有效性,本文使用百度地图开源平台获取天府广场站的POI 数据[9],与本文精细分类模型生成的结果进行对比。
以天府广场站点为中心,1 km 为半径,采取到POI 数据547 条,分为居住、写字楼、公司单位、美食、酒店、购物、教育、政府机构、景区游览、公共交通等小类。按其特征归类到本文生成的五大类公共特征中并生成POI结果如表4所示。

表4 POI结果Table 4 POI results
从表4 可以看到,其实际POI 数据与本文模型所得结果基本拟合,其平均绝对误差仅为4.72%。因此可以认为,本文模型生成的精细分类结果能较好地反映出该站点周边的土地利用性质。
4 结论
本文使用成都地铁AFC 数据,汇总站点客流量信息,将其处理为时间序列数据。使用基于KMeans++的时间序列聚类算法,对所选取的时间段内成都轨道交通97座车站进行分类。根据聚类结果的波形特征与实际用地属性,将站点分居住密集型、工作就业型、区域中心型、公共服务型以及旅游休闲型等五大类。其拟合值与真实客流之间的平均误差MAPE值仅为14%,与客流预测模型12%的误差值有相近的效果[12]。本文城市轨道交通站点精细分类研究结论如下:
(1)与现有研究中将站点归类为单一属性特征不同,本文研究结果证明,绝大部分地铁站点周边都呈现出两种及其以上的土地区位特征。以天府广场站为例,该方案将其归类为63%工作就业型,19%区域中心型,15%旅游休闲性和3%居住密集型,并且与实际POI数据结果高度吻合。本文使用五类站点公共特征的比例描述地铁站点的类型以及周边的土地利用特征,能有助于进一步分析城市内不同功能分区与轨道交通之间的联系以及整个城市空间的格局。
(2)使用客流量特征对地铁站点进行分类。本文引入站点公共特征这一概念,将每个地铁站点的客流与公共特征进行匹配,从而做出精细分类,有效体现出地铁站点间细微差距。以升仙湖和倪家桥站点为例,大部分研究将其分为同一类居住型站点,但本文的研究表明,升仙湖站有94%的居住型站点特征,而倪家桥站仅有58%的居住型特征,体现出精细分类的差异。
(3)案例结果表明,相较于使用POI数据方案,本文仅使用客流量数据对站点进行分类,生成了相似的结果。本文使用方案摆脱了POI 数据强时效性的影响,将客流量波动与土地利用特征连接起来,通过客流量数据直观反映出站点周边土地利用情况,是城市规划者对城市空间进行规划的全新视角。
猜你喜欢
环球时报(2022-12-12)2022-12-12
成都信息工程大学学报(2022年2期)2022-06-14
资源信息与工程(2021年5期)2022-01-15
现代电子技术(2021年15期)2021-08-06
农业资源与环境学报(2021年4期)2021-07-30
建材发展导向(2021年10期)2021-07-16
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
数学大王·中高年级(2019年5期)2019-06-09
智富时代(2018年7期)2018-09-03
