
秸秆颗粒燃|络预测系统研究
2022-08-28 02:35焦国昌李奉跃赵康军张东谷志新
森林工程 2022年4期
焦国昌,李奉跃,赵康军,张东,谷志新
(1.东北林业大学 机电工程学院,哈尔滨 150040;2.临沭县工业和信息化局,山东 临沂 276700;3.东北林业大学 信息与计算机工程学院,哈尔滨 150040)
0 引言
在以“碳中和”为发展目标的背景下,秸秆资源的开发和利用迎来了新的发展机遇[1]。我国每年产生秸秆9亿多吨,传统的利用方式是粉碎还田或就地焚烧等[2-3]。秸秆成型燃料是将各种农作物秸秆压缩成型制成清洁燃料,代替传统的煤炭,是可再生能源开发的研究热点。
国内外学者在秸秆燃料成型研究方面取得了很多成果,尤其是秸秆燃料成型工艺参数的研究。Kaliyan等[4]以玉米穗轴为原料,得出最佳成型参数:成型燃料松弛密度为1 100~1 120 kg/cm3,耐久率为88.2%~92.3%。Lela等[5]以压力、木屑含量、干燥温度为输入,运用Design-Expert8对高位热值、含水率等参数进行回归分析,得到预测模型。陈树人等[6]采用多因素多水平二次回归正交实验方法,运用Design-Expert8.0.6进行回归分析和响应面分析研究含水率、主轴转速和模辊间隙等因素间的交互影响。有研究表明,当原料含水率为7%~14%、成型温度为60~200 ℃、成型套锥长17~74 mm、成型套锥角4°~20°、成型周期为7 s时,可实现生物质最佳成型效果[7]。段宇[8]通过最小二乘支持向量机,运用遗传算法对生物质成型过程做了寻优计算,实现预测功能。
目前,秸秆燃料成型过程的优化设计研究主要包括机械结构的优化和对生产中可控参数的控制优化[9]。机械结构的优化相对成熟,而由于影响因子的复杂性和成型参数的多变量耦合性,导致对成型过程控制优化问题的研究大多是通过实验数据分析而得到一组最优的生产参数,迫切需要建立成型燃料参数预测系统对生产参数进行控制优化[10]。本研究基于Matlab建立成型燃料的模糊神经网络预测模型,通过计算机模拟成型得到预测值,根据用户需求获取最佳生产参数,为用户预知成型燃料产品的性能,从而实现产前预测,解决成本过高、燃料产品质量不稳定等问题。为秸秆燃料成型工艺参数优化提供一种新的思路。
1 材料与方法
1.1 实验因子的确定
影响秸秆燃料成型的因素可以分为原料因素、设备因素及其他因素[11-12]。原料因素包括秸秆种类、粉碎粒度和原料含水率等;设备因素包括电机转速、压辊锥角、模辊间隙、平模开孔率、模孔长径比和模孔倒角等;其他因素包括成型压力、成型温度等。各因素间又相互耦合,体现出多变量、非线性等特点,考虑全部因素进行优化实验过于困难,所以在本研究中,选取了相对重要的参数进行优化。
假设摄取角内的物料可以被一次挤入模具,成型速率的计算公式为[13]
v0=2mr(1-cosθ0)BπDn。
(1)
式中:v0为成型速率,mm3/min;m为压辊个数;r为平模半径,mm;θ0为最大摄取角;B为压辊宽度,mm;D为模具排布直径,mm;n为电机转速,r/min。
生产率(Q)的计算公式[14]为
(2)
式中:m为压辊个数;ρ为物料在模密度,t/m3;D1为平模外径,m;D2为平模内径,m;h为物料摄取层厚度,m;n为电机转速,r/min。
热值的计算公式[15]为
C=100%-(A+M+V)。
(3)
H=2.326(147.6C+144V)。
(4)
式中:C为固定碳百分比,%;V为挥发物百分比,%;A为灰分百分比,%;M为含水率百分比;H为低位发热量,MJ/kg。
秸秆成型燃料的评价指标主要是成品燃料的成型密度与热值[16]。根据公式可知电机转速与设备能耗、设备生产率相关;含水率对成品燃料热值有着直接影响;成型燃料密度与物料的成型速率、原料的密度和电机转速有直接关系,而原料密度则是受原料粉碎粒度和原料种类的影响,在粉碎粒度与种类确定不变的情况下,影响成型燃料密度和热值的因素主要有原料的含水率和电机转速[17]。经过上述分析,确定实验因子为含水率和电机转速,设计实验分别测试:含水率恒定,3种不同转速下的生产率、密度和热值;转速恒定,3种不同含水率下的生产率、密度和热值,该实验为二因素三水平正交实验,见表1。
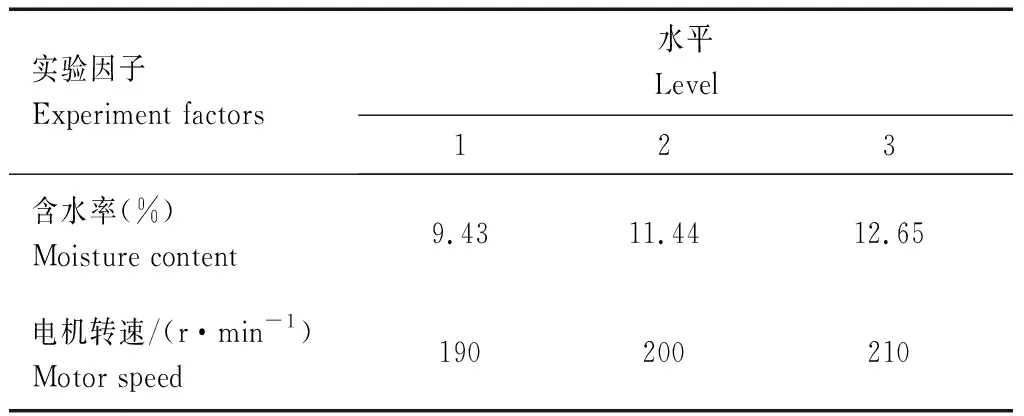
表1 正交实验设计Tab.1 Orthogonal experimental design
1.2 材料与设备
秸秆原料:采用哈尔滨郊区成熟玉米秸秆,去除根部,置于自然环境中,粒度大小为5~7 mm,调节物料含水率为10%~15%。
实验设备:游标卡尺、小型粉碎机、电子天平、台秤、秒表、MB25水分分析仪(奥豪斯仪器有限公司)、e2k燃烧量热仪(DDS Calorimeters)、YT900系列矢量通用型变频器、加装变频器的平模成型机。主要实验设备如图1所示。

图1 主要实验设备Fig.1 Experimental installation
颗粒成型机主电机参数:额定功率30 kW,电流58 A,电压380 V,额定工作频率50 Hz,额定转速960 r/min。
颗粒成型机主要参数:模孔直径10 mm;压辊直径19 cm;压辊厚度7.4 cm;平模直径16.5 cm。
1.3 实验方法
(1)生产率测定:生产过程中,每隔5 min取秸秆颗粒成型燃料成品一次,称质量后计算单位时间内的产量即为生产率。5组平行实验求取平均值。
(2)热值检测:实验中采用cal2k公司生产的e2k燃烧热量仪对成型颗粒燃料的热值进行测量[18],如图1所示。在容器充分冷却的前提下,放入适量颗粒燃料并放置好点火线,拧紧容器后,充入氧气,使容器内压强达到3 MPa,将容器放入燃烧量热仪中进行热值测量。
(3)密度检测:用天平称得秸秆颗粒成型燃料成品的质量,用游标卡尺测量其长度和直径。根据密度公式,计算10组燃料密度,取其平均值。
2 预测模型的构建
2.1 BP神经网络成型参数预测模型
2.1.1 BP神经网络预测模型的构建
以秸秆颗粒燃料成型过程中的工艺参数为模型输入,以其性能指标参数为模型输出,以实验记录数据为训练样本,建立基于BP神经网络的参数预测模型。
选择输入量对输出量影响相对较大的2个参数,分别为原料含水率与电机转速。隐层结构设计为1层,隐层节点数根据经验公式计算,其中调节常数α一般为1~10。改变m值,对比网络输出误差,从而确定输出误差最小时的隐层节点个数为5。输出量一般代表网络要实现的目标变量,确定成型燃料生产率为1个输出变量,目标误差为0.1。
建立基于BP神经网络的秸秆颗粒成型燃料生产率(y1)预测模型
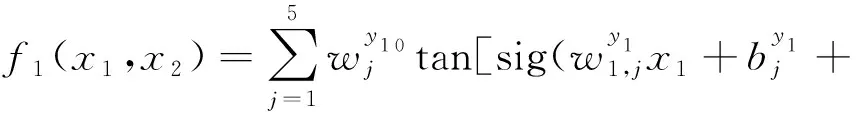
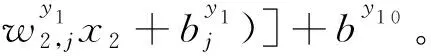
(5)

对比仿真预测值和真实值,判断模型性能,仿真结果得出生产率仿真误差最大值为18.996 2,其对应相对误差为1.68%。
同理,建立基于BP神经网络的秸秆颗粒成型燃料密度(y2)预测模型,确定2个输入变量:原料含水率与电机转速;确定成品燃料密度为1个输出变量;隐层神经元8个,目标误差为0.01。
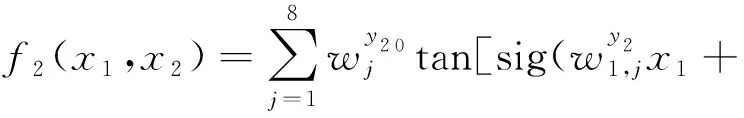
(6)
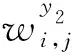
对比仿真预测值和实验值,得出密度仿真误差最大值为-0.097 2,其对应相对误差为6.89%。
同理,建立基于BP神经网络的秸秆颗粒成型燃料热值(y3)预测模型,确定原料含水率与电机转速为2个输入变量,成品燃料热值为1个输出变量,隐层神经元9个,目标误差为0.1。
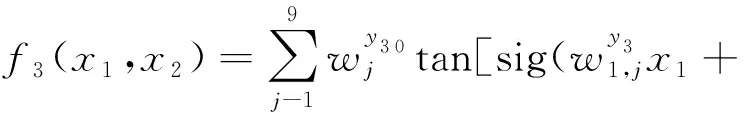
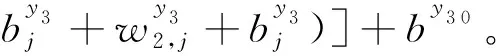
(7)
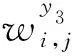
对比仿真预测值和实验值,得出热值仿真误差最大值为0.697 0,其对应相对误差为4.72%。
2.1.2 BP神经网络模型训练函数的确定
在使用Matlab中神经网络工具箱对函数进行拟合时,需要对不同训练函数分别进行尝试,根据训练效果最终确定合适的训练函数。对trainlm函数、traingdm函数、traingd函数、traingda函数进行了尝试,根据不同的训练结果,得出trainlm函数收敛速度最快,平均误差最小。
2.2 模糊神经网络成型参数预测模型
对于n输入单输出系统采用Takagi-Sugeno模型,其模糊规则的形式为
If(x1isAj1)and(x2isAj2)and…(xnisAjm)
Thenyj=aj0+aj1x1+…+ajnxn。
式中:x=[x1,x2,…xn]T;A为模糊集合,A=[Aj1,Aj2,…,Ajm](j=1,2,…,m);y为系统输出,y=[y1,y2,…,ym]T。
模糊神经网络预测模型由多个BP神经网络组成,而网络的输入层具有相同的输入神经元,但隐层个数及每个隐层上的神经元个数可自适应进行改变。使用K最近邻(KNN)分类算法对实验测得的92组生产率数据、97组密度数据和49组热值数据进行分类。将生产率分为4类,密度、热值样本数据分别分为3类,作为模糊规则。见表2。

表2 热值样本模糊规则Tab.2 Fuzzy rules of calorific value
根据公式得到生产率(y1)模型,密度(y2)和热值(y3)预测模型可同理可得。生产率计算公式为
(8)
式中:ui为第i条模糊规则的隶属制度;di第i条规则的模糊神经网络的输出。
3 秸秆颗粒成型燃料工艺参数预测系统验证
前端开发工具采用Qt软件进行设计。以成型实验数据为基础,运用SQL Server 2005建立成型工艺参数数据库。通过Matlab神经网络工具箱对数据进行训练,实现预测功能。调用动态链接库的方法,实现Qt和Matlab的混合编程。其中,部分热值预测结果见表3。预测误差平均值为0.72%,能够满足实际预测要求。
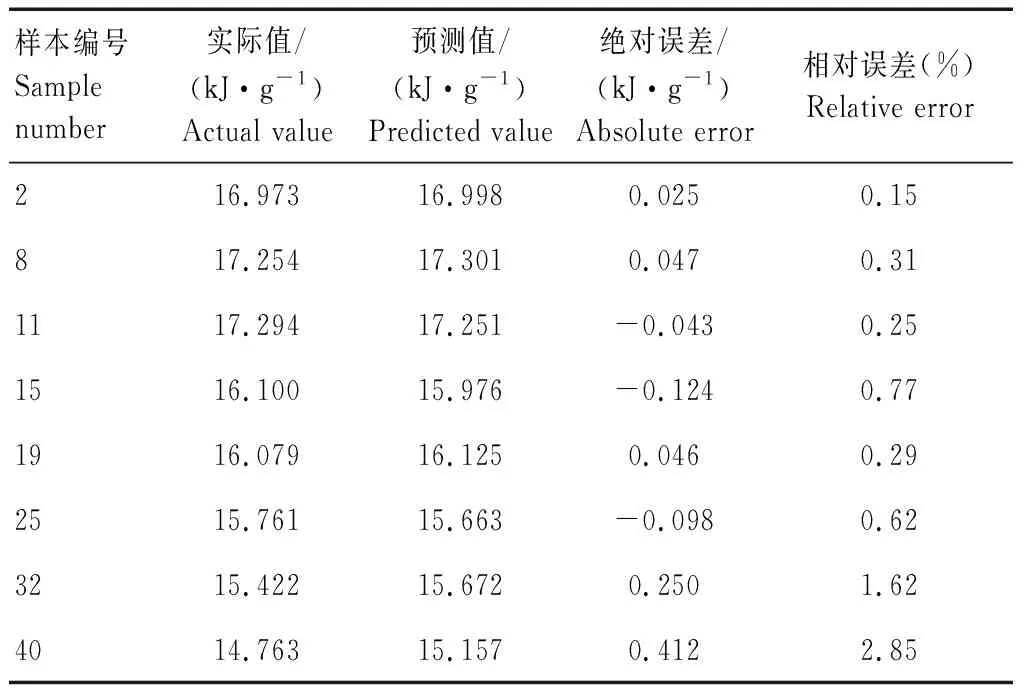
表3 热值预测结果Tab.3 Results of calorific value predictions
实验中,秸秆原料含水率为12.43%,电机转速分别设定为190、200、210 r/min。将实验结果与预测结果进行对比,见表4。根据国家标准中对于生物质颗粒状成型燃料的密度和热值的要求,成品燃料密度大于1 g/cm3,热值大于13.4 kJ/kg,所以结果符合国家标准。

表4 不同转速下实验与系统预测结果比较Tab.4 Comparison of experimental and prediction results at different speeds
秸秆颗粒成型燃料工艺参数预测系统的绝对误差与相对误差见表5,相对误差最大为2.08%,绝大部分预测值相对误差小于1%。所以该系统能够比较准确地对成型燃料效果进行预测,实现产前预测。在实际生产中可以结合预测结果,选择符合标准的热值和密度且生产率最大时对应的原料含水率和电机转速作为生产依据进行生产,从而提高生产效率。

表5 预测系统不同工艺参数的绝对误差和相对误差Tab.5 Absolute and relative errors of different process parameters in prediction system
4 结论
选择原料含水率、电机转速作为2个影响因素,松弛密度、单位时间产量、成品燃料热值作为成型评价指标进行正交实验,并建立成型工艺参数数据库。利用KNN 算法将实验测得的92组生产率数据、97组密度数据和49组热值数据进行分类。将生产率分为4类,密度、热值样本数据均分为3类,作为模糊规则。预测系统由多个BP神经网络组成,建立密度、热值、生产率的模糊神经网络预测模型,预测系统的相对误差平均值为0.72%,有较好的预测效果。
选择原料含水率为12.43%,电机转速分别为190、200、210 r/min,进行验证实验,对比预测系统的预测值与实验值,分析对比结果,预测系统的相对误差最大为2.08%,绝大部分预测值的相对误差小于1%,所以得出该模糊神经网络预测系统能够满足实际预测系统要求,可运用到实际生产预测中。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28
电力科技与环保(2022年3期)2022-07-15
昆钢科技(2022年2期)2022-07-08
林业机械与木工设备(2022年5期)2022-05-27
环境卫生工程(2021年1期)2021-03-19
竹子学报(2019年4期)2019-09-30
建材发展导向(2019年10期)2019-08-24
长江科学院院报(2018年12期)2018-12-19
制造技术与机床(2017年5期)2018-01-19
电子制作(2016年1期)2016-11-07
