
基于随机森林算法的改性水润滑轴承摩擦性能预测*
2022-08-26 03:22徐起秀郭智威袁成清
润滑与密封 2022年8期
王 裕 徐起秀 郭智威 袁成清
(武汉理工大学,国家水运安全工程技术研究中心,可靠性工程研究所 湖北武汉 430063)
船舶尾轴承是船舶轴系中用于支撑螺旋桨轴的关键部件[1]。随着绿色航运的发展,水润滑轴承已逐步替代油润滑轴承。但水润滑轴承使用水作为润滑介质,由于水的黏度低,对材料的摩擦磨损性能提出更高的要求,因而提高水润滑尾轴承在船舶使用过程中的摩擦磨损性能已成为研究重点[2]。
针对船舶尾轴承的相关实验研究很多,已累积了大量数据。以水润滑尾轴承为例,目前已建立其相关摩擦性能数据集。因此,基于大数据理论,通过对原数据集进行算法建模,寻找数据间的关联性,对于预测水润滑尾轴承在不同工况条件下的摩擦性能,指导水润滑尾轴承的开发具有重要意义。
随机森林算法[3]是一种集成学习算法,该算法是在决策树算法基础之上进一步优化的一种算法模型,其原理是以原始数据为模型的训练集,进行算法的创建,然后再通过创建的算法模型预测数据的变化趋势。随着随机森林算法的参数的不断优化,其性能也更加准确,可以较为精确地模拟数据中存在的未知关系并用于预测未知数据或者趋势,通过构建随机森林学习算法模型可以用来实现数据的分类或者预测回归[4]。
本文作者运用随机森林算法挖掘水润滑尾轴承大量实验数据中的隐藏信息,建立一种多模型思维的随机森林算法,可准确地预测改性水润滑尾轴承的摩擦磨损性能。
1 改性水润滑轴承摩擦性能参数处理
水润滑尾轴承的摩擦磨损性能对保障船舶的航行安全具有重要作用。本文作者所在的课题组,已针对该改性水润滑轴承的摩擦磨损性能做了相关的实验对比,获得了相关的初始实验数据。文中首先基于原始数据集进行建模前的数据预处理。
1.1 材料组成
文中研究的改性水润滑尾轴承为质量分数10%聚乙烯蜡改性聚氨酯轴承,该轴承由聚乙烯蜡与聚氨酯聚合而成。首先将聚氨酯加热至90 ℃,投入聚乙烯蜡后加热至120 ℃共混,在共混过程中加入消泡剂(M-CDEA),然后加热至110 ℃,最后定性,得到如图1所示的实验样品。文中将其命名为PU- PEW10[5]。

图1 PU- PEW10试样
1.2 数据处理
在PU- PEW10试样摩擦磨损实验的数据集中,原始数据集的特征属性分别为温度、压力、扭矩、转速、功率,以及经过实验得出的摩擦因数。温度控制由型号为HH-21-4的恒温水箱控制。考虑到试样磨合期数据存在波动,用于建模的原始数据取试样磨合期后的稳定实验数据;考虑到恒温水箱控制水温时温度会有一定的波动,文中针对温度特征采用正态分布方法,补足数据集。HUANG等[5]的研究表明,在摩擦磨损实验过程中,影响PU- PEW10试样摩擦因数的外部因素主要为温度、压力和转速。因此将对数据集整理后,得到如表1所示的可用于随机森林算法建模的原始数据。
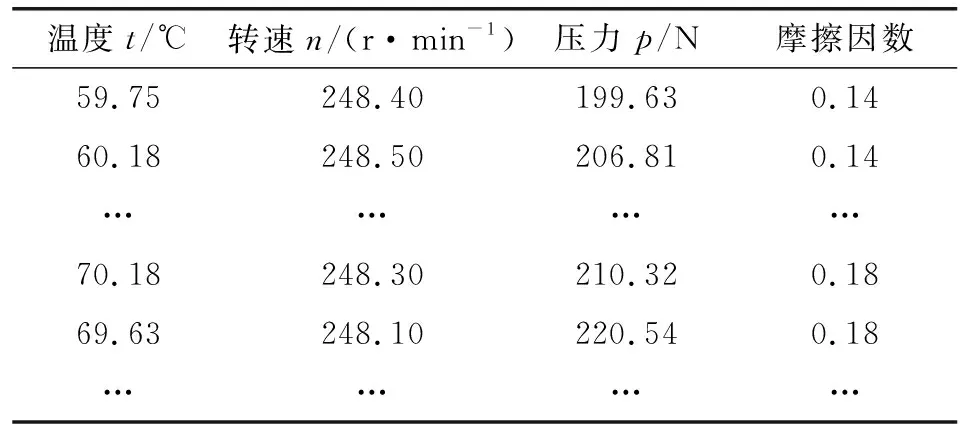
表1 处理后的影响因素数据和摩擦因数结果集
表1所展示的是将已知的5种工况下的数据整合成的一组数据。其中,5种工况参数分别为60 ℃、0.3 MPa,70 ℃、0.3 MPa,80 ℃、0.3 MPa,80 ℃、0.5 MPa以及60 ℃、0.7 MPa。温度、转速以及压力都是随机森林算法模型的特征属性,即输入值,摩擦因数是模型的输出值。
2 随机森林模型构建
随机森林算法是一种集成学习算法,该算法是基于决策树算法基础上集合而成的一种多模型分类算法,因此文中先介绍决策树算法原理。
2.1 决策树算法原理
决策树是一种最基本的模型分类回归算法,是针对不同结果集进行分类的树形结构算法。该算法通常包括3个学习步骤,分别为基于特征的选择、决策树的生成以及将构建的决策树通过数据集进行剪枝操作。决策树算法主要使用ID3算法、C4.5算法以及CART算法。决策树由节点和有向边组成,节点有2种类型:内部节点和叶节点。内部节点代表一个特征或一个属性,叶节点表示一个类[6]。文中的随机森林算法采用的是决策树算法中的CART原理建模[7],原理如下:
给定一个训练集(文中的数据集为表1中的数据)
D={(x1,y1),(x2,y2),…,(xn,yn)}
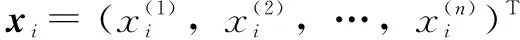
决策树学习是根据给定的训练数据集构建一个决策树模型,使它能够对实验实例进行正确地分类。
文中使用的决策树CART原理,是基于“基尼指数(Gini)”来选择划分特征属性[8]。基于CART原理的决策树模型用基尼系数最小化准则来进行特征选择,生成二叉树。数据集D的纯度可用基尼系数来度量:
(1)
(2)
ΔGini(A)=Gini(D)-GiniA(D)
(3)
公式(3)用于计算基尼系数的增益,针对回归问题应用最小平均误差准则来检验模型的优劣。文中构建模型的数据为经过预处理的摩擦因数数据集,将处理后的数据应用Python编写决策树算法模型,直接训练数据集,得到训练好的模型并对其进行准确性验证,即计算该模型的均方根误差(MSE),发现该值为0.0,说明该模型可精确预测每一组摩擦因数值。但根据算法模型应用可知,当模型预测的MSE达到0.0时,表示模型能够精准预测每一组数值,这种现象称为“过拟合现象”,在该情况下需要对原模型进行超参数的调整,使其泛化能力更好。
调整超参数的方法有很多,文中采用网格搜索的方法确定模型的超参数数值,即包括树的深度、节点数目等。网格搜索设置的参数为′max_depth′=[2, 3, 4, 5, 6, 7, 8, 9, 10], ′min_samples_split′=[4, 8, 12, 16, 20, 24, 28]。′max_depth′指定了决策树下钻的深度,′min_samples_split′指定了分裂一个内部节点(非叶子节点)需要的最小样本数。
决策树构建完成后,需对优化后的模型进行验证。文中采用偏差方差法对优化后的模型进行准确性验证,通过算法自行计算,其MSE值为0.143,偏差(Bias)的值为0.055,方差(Variance)的值为0.088。可见,通过调整超参数′max_depth′以及′min_samples_split′的数值,使得模型有了一定的改进。但是一棵决策树并不能很好地说明预测的准确性,最佳的处理方法是应用多棵决策树进行预测值投票,得到最佳的预测结果,此时需要引进随机森林算法来实现。
2.2 随机森林算法
随机森林算法是决策树的集成,是以决策树为基学习器基础上构建bagging的方法,该方法在训练数据时,通过每棵决策树的CART方法,对数据中特征属性随机选择最优作为分类的基础。采样时,通过有放回的方法,构建多棵决策树,每棵决策树基于一定的精度进行分类。在此基础上,每一棵树再对预测或者分类的结果进行投票筛选,使得分类或预测的结果精度提高。
文中的随机森林算法相对每个决策树设置有同一个根节点,该节点的选择由随机森林算法随机选取。从该节点中随机选择一个包含m个特征属性的子集,再通过筛选的子集择优选择一个特征属性用来划分,直到获得最优深度及节点数。其中m的含义为控制模型随机性[9]的程度:当m与特征属性数量相同时,那么构建的基决策树与直接应用决策树建模一致;如果m取1,则是通过算法选择一个特征属性来划分;通常使用推荐值,即取m为log2d,其中d为特征属性数量[6]。文中的特征属性数量有3个,所以d取3,m取log23。
与决策树算法一样,将处理后的数据集直接用于随机森林算法构建模型,模拟数据后计算该初始模型的MSE值,得出结果为0.027。鉴于数据量较少,文中采用了K折交叉验证的方法,将数据重新进行构建模型。交叉验证的方法是一种常用的模型选择方法,该方法的提出是为了解决数据不充足问题,其基本思想为重复使用原始数据集。K折交叉验证[10]是应用最多的一种交叉验证方法,文中K取值为5,为一个较为适中的参数。
交叉验证方法的原理[11]如下:将处理后的数据集进行数据切分,切分的原则是随机性,保证数据的可信度;将切分后的数据集按照一定比例(文中按照8∶2的比例)分为训练集与测试集,对数据集进行训练并优化。通过交叉验证方法得到的不同训练模型并用于投票选择,然后通过测试集对每个模型进行误差计算,并最终选出误差最小的模型。
以K=5为例,K折交叉验证的过程是:将处理后的数据集切分成5份互不相交、大小一致的数据子集;随机选取其中的4份数据子集训练模型,利用剩下的1份数据子集作为测试集验证模型;每进行一次交叉验证就将原始数据打乱并重新按照8∶2的比例将数据重新选择并拆分为5份;将上述过程执行5次,最终算法会选取其中平均测试误差最小的模型用于改性水润滑聚氨酯材料摩擦性能的预测。
基于上述方法,计算了优化后模型MSE,其值为0.189。MSE值偏大,为此再将模型进行网格搜索[12]寻找随机森林模型的最佳参数。首先尝试12种(3×4)超参数组合,分别为′n_estimators′= [3, 10, 30], ′max_features′=[2, 4, 6, 8]。其中n_estimators为随机森林决策树的数目,max_features为用来控制特征子集的数量,其值越小,随机森林算法中的树形结构差异越大,文中默认使用bootstrap重采样方法,即有放回的可重复的抽取样本;然后尝试6种(2×3)boosting方法进行网格搜索最优参数,即不放回的进行样本建模,参数设置为′bootstrap′=[False], ′n_estimators′=[3, 10], ′max_features′=[1, 2, 3],之后通过算法寻找最优的参数组合。将′bootstrap′设置为True,即将数据集有放回的可重复的进行建模;′max_features′= 2,′n_estimators′= 30,即选取特征子集中的2个特征属性组合,建立30棵树模型。计算得到优化后的模型的MSE值为0.178,可见优化后的模型较之前的模型有了更好的泛化能力。
因为数据集中有5种分类状况,为了评估每一类的预测情况,文中又对原始数据集做了分类算法,然后针对该模型计算每一类的接受者操作特征(ROC)曲线值,结果如图2所示[11]。
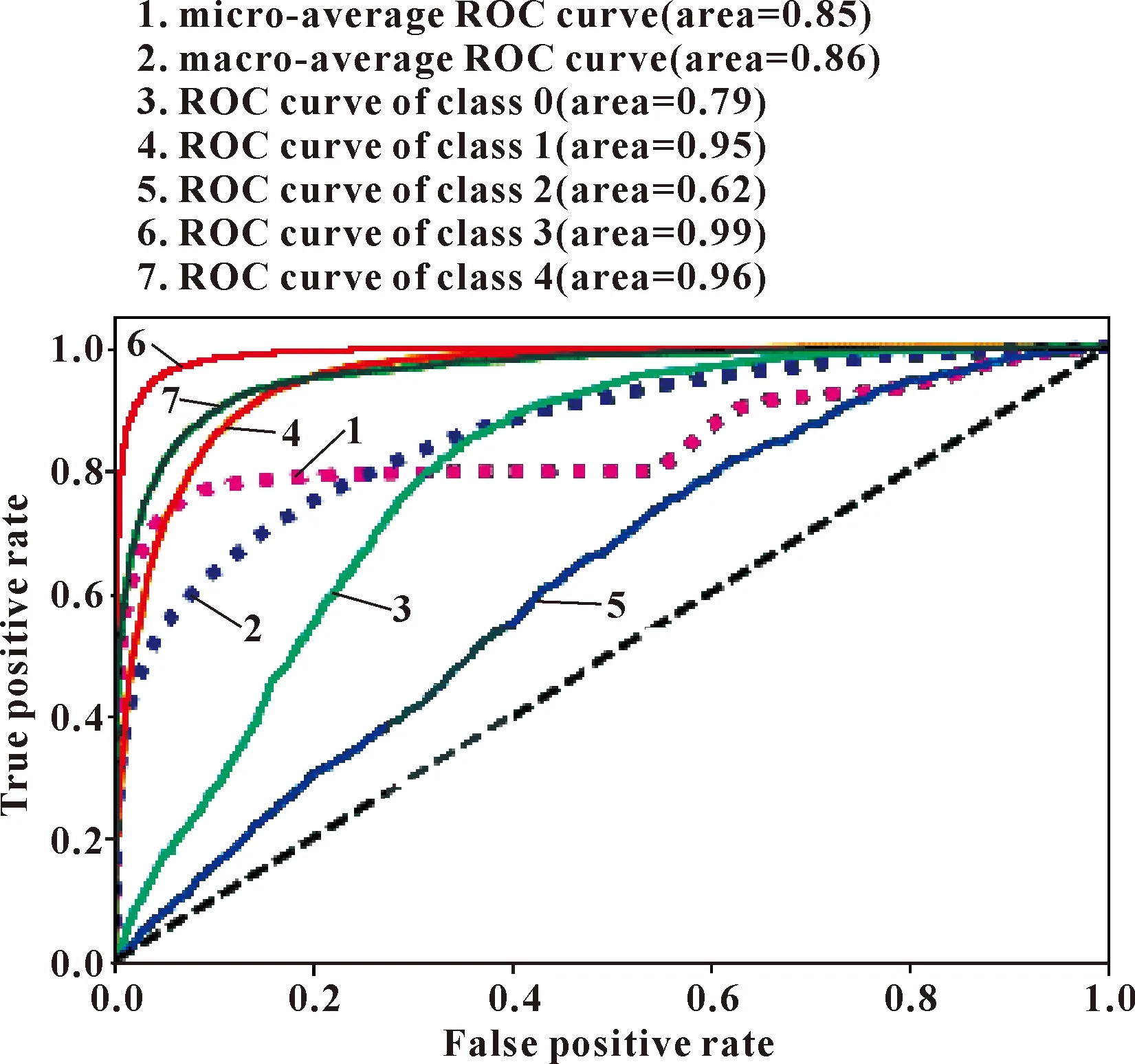
图2 改性水润滑轴承摩擦因数预测的ROC曲线
如图2所示,其中class0—class4分别对应上述的5种不同工况,发现class0类与class2类的面积较低,即得分较低。但是micro-average ROC curve与macro-average ROC curve的平均值分别为0.85与0.86,从整体来看,该算法调整参数优化后的模型分类较为准确,没有出现过拟合或者欠拟合的状态。所以优化后的模型能够较准确地预测出并分类改性水润滑轴承的摩擦学性能。
2.3 模型结果
将所建的模型的均方根误差(MSE)值进行对比,优化前后其值分别为0.03以及0.178。优化前MSE值不足0.1,即在预测每一个工况时均能够准确预测摩擦因数,这种现象属于过拟合现象[13],模型不能完全准确地预测水润滑轴承的摩擦性能。所以,优化后的模型比优化前的模型拥有更好的泛化性能[14]。随机森林算法相较于决策树算法,属于一种多模型的算法,从上述分析得知,随机森林是将数据集划分成多棵树来建立模型的一种集成算法,文中通过构建30棵决策树,然后对其优化并择优选择最佳的模型,构建一种较为准确的随机森林算法模型。
图3所示为优化后模型预测的不同工况下的摩擦因数。
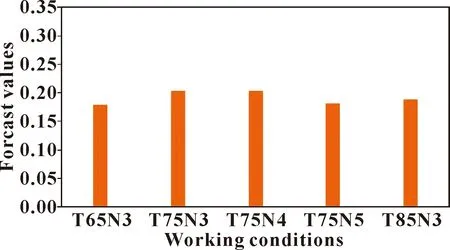
图3 随机森林算法预测的不同工况下的摩擦因数
图3中,T65N3、T75N3、T75N4、T75N5以及T85N3代表5种不同的工况,分别为65 ℃、0.3 MPa,75 ℃、0.3 MPa,75 ℃、0.4 MPa,75 ℃、0.5 MPa以及85 ℃、0.3 MPa,对应的摩擦因数预测值分别为0.18、0.20、0.20、0.18、0.18。
3 实验验证
3.1 摩擦因数实验结果
采用表2所示实验条件,通过实验测量了该改性水润滑轴承的摩擦因数及磨损量。

表2 实验条件
考虑到实验过程中改性水润滑尾轴承和摩擦件之间有一个磨合阶段,所以不同工况下材料的摩擦因数取磨合之后数据的平均值。图4所示为0.3 MPa下改性水润滑轴承不同温度下的平均摩擦因数。根据HUANG等[5]的研究结果,在60~80 ℃之间该种材料的摩擦因数不断增加,但是80 ℃后摩擦因数增加幅度开始下降。而文中实验在文献[5]的基础上将温度最大范围增加5 ℃,达到85 ℃的工况,实验发现,该材料的平均摩擦因数出现了下降的趋势,表明该材料在80~85 ℃之间可能取得负载0.3 MPa工况下的最大平均摩擦因数。

图4 0.3 MPa下改性水润滑轴承不同温度下的平均摩擦因数
实验过程中测得的材料在0.3 MPa载荷及65、75和85 ℃下的摩擦因数变化曲线如图5所示。可得出,在相同的负载条件下,高介质温度对于该材料摩擦因数的稳定性和机械性能都产生了负面的影响[15-16],其摩擦稳定后的摩擦因数值均在0.15以上,说明高温对于该材料的摩擦性能影响较大。

图5 0.3 MPa及不同水润滑温度下的实时摩擦因数
图6所示为75 ℃温度及载荷0.3、0.4、0.5 MPa下的实时摩擦因数。在相同的水润滑温度条件下,随着压力增加,该材料的摩擦因数呈略微下降的趋势,且压力越大,摩擦因数越稳定。产生这种现象的原因可能是,随着压力的增加,改性水润滑聚氨酯与摩擦件之间接触面变大,贴合效果也越好[17]。通过图6也可以看出,在研究的载荷范围内,载荷的大小对于该材料摩擦因数的数值影响不大,但是对其稳定性影响较大。

图6 75 ℃及不同压力下的实时摩擦因数
3.2 仿真与实验结果对比
表3给出了实验和仿真得到的该改性水润滑轴承在不同工况下的摩擦因数及误差率。可见实验值和仿真值误差率均在5%左右。考虑到在实验过程中产生的振动等因素导致压力不稳的情况,会导致实验结果和预测结果有一定的偏差,但两者的偏差较小,所以可认为预测结果较为准确。

表3 不同工况下摩擦因数真实值与预测值对比
比较随机森林算法预测的摩擦因数值与实验得出的结果,可以发现:温度对于该改性水润滑轴承的平均摩擦因数有较大的影响,在75~85 ℃之间会产生一个峰值,此时该改性水润滑轴承的磨损会增加;负载对于该材料的平均摩擦因数的影响较小,但是对于轴承的运转稳定性影响较大。
4 结论及展望
(1)基于大量实验数据,建立了一种多模型思维的随机森林算法,作为一种基于决策树的集成算法,提高了计算精度。
(2)引入ROC曲线,基于构建的模型分类器进行了准确度评价,进一步证明了算法的准确性。随机森林算法引入了随机性的概念,使得模型不容易过拟合,模型的训练速度快,较为准确地预测了改性水润滑尾轴承的相关摩擦性能数据。
(3)比较随机森林算法预测结果与实验结果可以得出:温度对于该改性水润滑轴承的平均摩擦因数有较大的影响,在75~85 ℃之间会产生一个峰值,此时该改性水润滑轴承的磨损会增加;负载对于该材料的平均摩擦因数的影响较小,但是对于轴承的运转稳定性影响较大。
(4)文中研究尚有不足之处,即在进行摩擦性能预测时,只针对一种特定的改性水润滑轴承进行了预测,下一步研究将会针对不同的改性水润滑轴承的摩擦性能进行预测,使算法预测更具有普适性。
猜你喜欢
建材发展导向(2021年15期)2021-11-05
食品安全导刊(2021年21期)2021-08-30
能源工程(2021年1期)2021-04-13
小学生学习指导(中年级)(2021年3期)2021-04-06
小学生学习指导(低年级)(2020年9期)2020-11-09
科学与信息化(2019年28期)2019-10-21
小学生学习指导(高年级)(2018年3期)2018-11-29
小学生学习指导(中年级)(2018年9期)2018-11-29
科学与财富(2016年32期)2017-03-04
食品工业科技(2014年21期)2014-03-11
