
计及空间相关性的轻量级风电功率预测方法
2022-08-26 00:49崔昊杨孙昊宇许永鹏
智慧电力 2022年8期
崔昊杨,孙昊宇,杨 程,王 茺,许永鹏,刘 诚
(1.上海电力大学电子与信息工程学院,上海 201306;2.云南大学材料与能源学院,云南昆明 650031;3.上海交通大学电子信息与电气工程学院,上海 200052;4.长沙市泓泽电力技术有限公司,湖南长沙 410015)
0 引言
风电能源是实现“双碳”战略的重要可再生能源[1]。为解决电网供需平衡难题,需要对具有强随机性、波动性和间歇性的风力发电进行预测。国内外研究学者通常采用深度学习方法提高风电功率预测准确度[2]。然而,用于风电功率预测的数据逐渐向高维化发展,造成维数灾难[3]。若仅考虑使用云计算,系统将面临高时延和高带宽的压力,仅考虑使用边端计算,部分高复杂计算任务将难以实现[4]。因此,克服风电功率预测数据高维灾难以及边端算力有限的问题,并满足能源调度对预测结果准确性的要求成为当前风电预测领域研究热点。
早期研究通过小波变换(WaveletTransform,WT)[5-6]、变分模态分解(Variational Mode Decomposition,VMD)[7]、小波包分解(Wavelet Packet Decomposition,WPD)[8]和奇异谱分析(Singular Spectrum Analysis,SSA)[9]等特征提取方法有效降低输入数据维度。WT,VMD,WPD 及SSA 等特征提取方法缺乏对风机空间关联性的考虑机制。目前,考虑空间相关性的风电功率预测已有大量的研究,主要分为物理方法和统计方法。物理模型[10-12]依赖于丰富的天气预报数据,成本相对较高,因此更多研究选择线性相关分析、人工神经网络等统计方法[13-15]。大多数研究未关注预测残差序列与风机风速序列之间的相关性,为进一步提升预测准确性,文献[16]利用长短期记忆网络(Long Short-Term Memory,LSTM)及Copula 函数建立残差序列与风电场中其他风机的风速序列之间的相关性,进一步提升预测准确性。
考虑空间相关性会增加预测模型中的输入特征,冗余的输入特征会占用非必要的计算资源。为此,ZHU 等人提出时空注意网络(Spatiotemporal Attention Networks,STAN)降维方法[17],将自注意力机制用于提取不同风机之间的空间相关性以及序列本身的时间相关性,基于风机之间空间相关性的分析,对空间多维风速等特征序列进行降维,可有效缓解边端设备通信线路面对维数灾难的压力。FU 等人采用预测时空网络(Predictive Spatiotemporal Network,PSTN)方法[18],引入卷积神经网络(Convolutional Neural Networks,CNN)并结合LSTM网络,替代自注意力机制对空间相关性的提取,预测结果的准确性优于STAN,通过改变预处理与预测方法减少预测模型需要训练的参数量,提高边端计算资源的利用率。LI 等人提出一种深度风电功率时空预测方法[19],提出使用空间位置距离量化空间相关性的思想,采用K 邻近算法(K-nearest Neighbor,KNN)提取风机原始风速时间序列特征维度,并对循环神经网络(Recurrent Neural Network,RNN)和多层感知器(Multilayer Perceptron,MLP)进行适当组合实现风电功率的准确预测。文献[19]由于采用人为设置的固定参数,尚未满足电力系统边端计算平台精准预测风电功率的需求。
为降低输入数据维度以及提升边端计算资源的利用效率,本文提出一种属地边端的轻量级风电功率预测方法。采用KNN 算法搜寻目标风机的邻近风机,同时引入轮廓系数自适应地确定k值,并将k台邻近风机的历史风速数据作为预测模型的输入;有效降低输入数据冗余维度。引入嵌入单元学习数据特征,为风机进行编码。门控循环单元(Gate Recurrent Unit,GRU)含有较少的参数量,通过GRU-MLP 组合预测网络替代序列到序列结构(Sequence to Sequence,Seq2Seq)中编码器和译码器单元的传统RNN 方法,轻量化预测模型。仿真实验表明,本方法降低风电预测输入维度与提升边端设备风电功率预测的有效性。
1 风电场原始风速数据分析及空间多维风速数据降维
1.1 风电场原始风速数据特征分析
为直观地表达邻近风机风速数据的变化特征相似度,以及风速随时间的变化规律利用某风电场各风机所处位置地理信息及其某天历史风速数据,分别绘制如图1 和图2 所示30 台风机坐标图和风速变化3D 图及其投影。
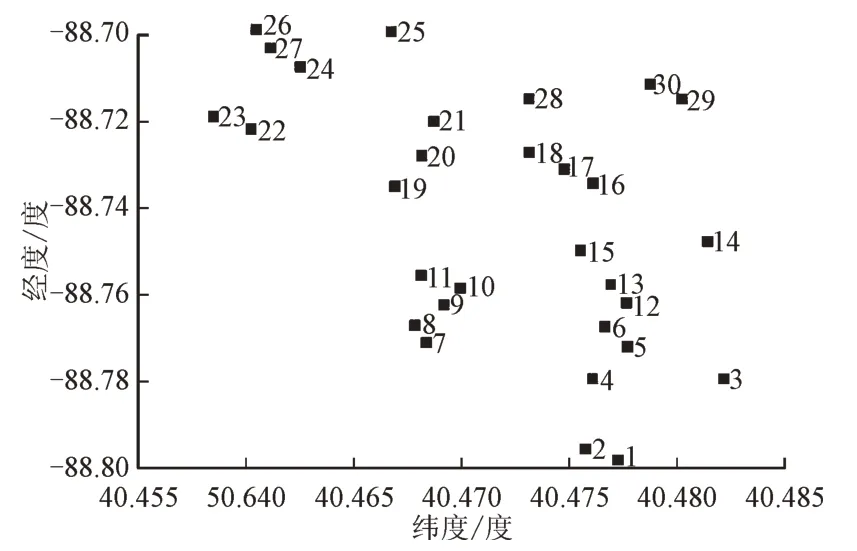
图1 风电场风机坐标Fig.1 Wind farm fan coordinates

图2 24小时风速变化3D图Fig.2 3D diagram of 24-hour wind speed change
从图2 投影图时间轴来看,风速波动呈现与时间强相关的特性;沿风机轴看,同一时间下,邻近站点的风速信息往往具有相似的风速波动性。
1.2 基于轮廓系数的KNN空间多维风速数据降维
根据风电场数据的时空特性分析结果得出,通过考虑邻近区域的风速信息,可以有效提取风电场各风机之间的空间相关性,为提升风电功率预测的准确性提供数据支撑。KNN 算法常通过计算数据点间的距离寻找与目标点最相似的m个最近的数据点[20]。基于KNN 算法的思想,本文通过计算风机间的空间位置的欧几里得距离,搜索与目标预测风机距离最近的k台风机,将k台风机的风速数据作为预测模型的输入特征,风机间距离计算公式定义如下:
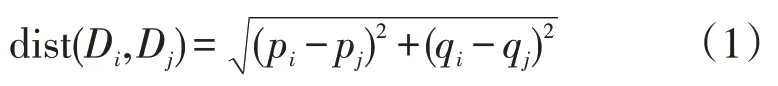
式中:Di,Dj分别为风机i和风机j的地理位置;pi,pj与qi,qj分别为目标风机i,j的所处位置的经度和纬度。
将目标风机与其他各风机的距离进行排序,选出与目标风机距离最近的k台风机。此聚类方法中k值需要人为拟定,若k值取值过大,会导致输入数据中存在冗余维度。为此引入轮廓系数作为评估标准自适应地确定k值,以降低输入数据的冗余维度。
轮廓系数的主要思想是量化数据集中的待测风机与其他风机以及其他风机间的相似度。这2种相似度的计算公式为:
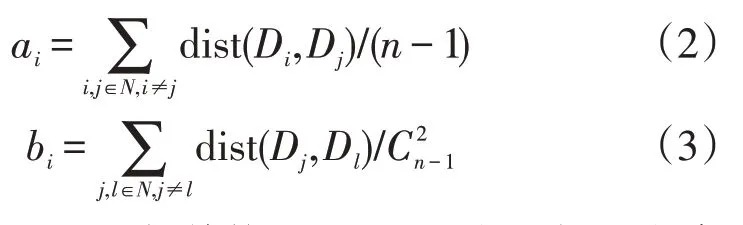
式中:ai为目标风机i与其他风机j的平均距离;n为待预测风机总数;bi为其他风机j相互之间的平均距离。
ai的值越小,表示目标风机与其他风机距离越近。ai被称为风机i的簇内相异性。当bi远大于ai时实现最佳聚类。
个体轮廓系数si的计算方式如式(4)所示:

si∈[-1,1],si越接近1,聚类效果越好。平均轮廓系数S定义为:

式中:k为目标风机i最佳的近邻数量。
平均轮廓系数值越大,表示k值的可信度越高,最终取平均轮廓系数最大时的k值作为该待测风机的近邻风机数。
根据上述确定的k值,由距离量化风机之间的空间相关性,对邻近风机与周围风机的距离进行排序,将与目标风机最近的k台风机作为目标风机的输入特征。
2 轻量级风电功率预测
2.1 预测流程
本文提出的计及空间相关性的轻量级风电功率预测方法步骤如下:
1)对数据进行预处理。将各风机的地理位置坐标输入到基于轮廓系数的KNN 算法中,寻找距离每台风机最近的ki台风机。
2)将ki台风机的风速数据输入嵌入单元,输出风机的嵌入向量。
3)将ki台风机的历史风速数据以及嵌入向量输入到基于Seq2Seq 的预测模型中预测未来时刻的风电功率值。
图3 为本文方法的预测流程。

图3 计及空间相关性的轻量级风电功率预测方法流程Fig.3 Lightweight wind power prediction method process considering spatial correlation
2.2 风速序列嵌入编码单元
为完成特定于每台风机的预测,同时允许模型在风机之间共享参数,需要通过增加输入向量便于模型识别风机的身份。采用热编码向量是识别风机的传统方法[21],为了克服预测模型在没有编码向量的情况下风机身份识别效率较低的问题,通过在模型中添加嵌入层学习风机的数据特征为风机进行编码。嵌入单元结构如图4 所示。

图4 风速序列嵌入编码单元结构图Fig.4 Structure diagram of wind speed sequence embedded coding unit
其工作原理是将聚类所得ki台风机风速数据Xtk(i)作为嵌入矩阵,再使用风机的热编码向量对嵌入矩阵进行降维。嵌入向量g(i)如式(6)所示:
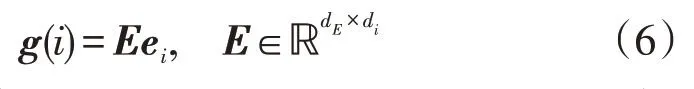
式中:E为嵌入矩阵;dE为嵌入向量的维数;di为风机的数量;ei为风机i的热编码向量;为嵌入矩阵集合。
2.3 基于Seq2Seq结构的GRU-MLP风电功率预测网络
2.3.1 Seq2Seq模型
预测模型需由风速序列实现风电功率预测,由Google 提出的Seq2Seq 结构则可以捕捉输出序列与输入序列的序列依赖性[22]。因此,预测模型采用Seq2Seq 为基础架构预测风电功率。
Seq2Seq 模型由编码器和解码器组成,模型结构如图5所示。编码器将输入序列风速值xt编码为固定长度的向量c输出到解码器,h0为初始隐藏状态,ht与h′t+τ分别为编码器与解码器中每个时间步的隐藏状态,由解码器解码为另一个目标序列风电功率输出。
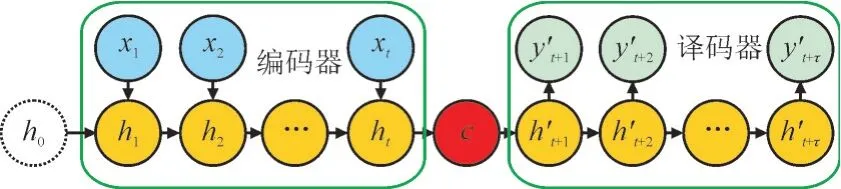
图5 风电功率预测Seq2Seq模型结构图Fig.5 Structure diagram of Seq2Seq model for wind power prediction
编码器和解码器通常使用RNN、LSTM 网络或GRU 网络。LSTM 和GRU 广泛应用于循环单元,与LSTM 网络相比,GRU 网络的参数更少,且训练速度更快[23]。因此在本文的模型中选择GRU 网络作为编码器和解码器。
2.3.2 GRU-MLP网络
风速时间序列呈现时间强相关的特性[24],循环神经网络是一种用于处理时间序列的神经网络模型,故可以使用循环神经网络来分析风速时间序列的变化趋势。GRU 网络具有循环和内部记忆单元,用于捕获顺序信息。将GRU 网络作为编码器的基本结构如图6 所示。

图6 风电功率预测模型编码器GRU基本结构Fig.6 Basic structure of encoder GRU of wind power prediction model
以KNN 聚类输出的邻近风机历史风速作为编码器GRU 的输入,假设在t时刻可以获取与之相关的时间范围内的风速值,捕捉尺度为m的时间窗口[t-m+1,……,t-1,t]风速数据的时间特征。对于风机i,利用编码器中的GRU 网络提取相应的隐藏变量ht,根据GRU 的前向传播公式可以得出t时刻的隐藏变量。前向传播公式如式(7)所示:

式中:xt为t时刻风速值;ht为t时刻编码器输出的隐藏状态为候选隐藏状态;rt为GRU的更新门;zt为GRU 的重置门;Wz,Wr,Wh,Uz,Ur,Uh均为不同的权重参数矩阵;br,bz,bh均为不同的偏置参数矩阵,σ为激活函数。
为了进一步捕获风电功率与风速的关系,将编码器中最后时间步的隐藏状态ht及t时刻风机i的风电功率分别作为解码器的初始隐藏状态和输入,由于MLP 层与层之间是全连接的[25],在解码器中附加MLP,可直接生成风电功率预测。进行多步预测直到满足给定的预测范围。基于GRU-MLP 的解码器基本结构如图7 所示。

图7 基于GRU-MLP解码器网络结构图Fig.7 Network structure diagram of decoder based on GRU-MLP
3 算例分析
3.1 数据集和评估标准
应用美国国家可再生能源实验室的公开数据集进行验证。该数据集风机的地理坐标为西经88.7954—88.5099°W,北纬40.4605—40.481421°N,数据发生时间为2010 年9 月1 日至2011 年8 月31 日,所用风速数据为100 m 高度处数据,功率数据与风速数据的分辨率统一为1 h。将全年数据集按照季节划分为4 类,每类数据集取前2 个月为训练集,后1 个月为测试集。即每类训练集和测试集分别包含1 680 个和480 个样本。样本组成形式为其中30 个风机的风速、风电功率及对应的地理位置坐标。风速数据及地理坐标作为预测模型的输入,风电功率作为模型的输出。预测窗口大小为12 h。
本文模型同时输出风电场内多个风机的风电功率预测值,选取平均绝对误差(Mean Absolute Error,MAE)作为风电功率预测的评价指标,其量值为EMA用于评估预测期内的实时偏差。MAE 值越小,表明所提方法的性能越高:
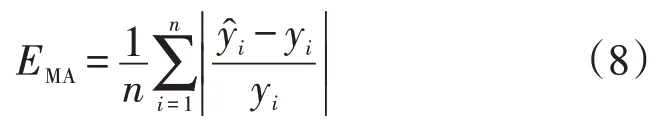
式中:yi为实际值;为预测值;n为待预测风机总数。
3.2 实验平台及超参数设置
本文中所有实验在Windows 环境下执行,编程语言为python3.9,深度学习框架为Pytorch。实验硬件配置为IntelCore i5-7200 CPU,4GB RAM。
输入数据的尺寸:通道数为3,即风机地理位置信息、风速、风电功率。
风机近邻数ki值:ki值的确定方法参照第2节,不同的k值的平均轮廓系数不同,进而近邻风机的聚类效果也不同。根据第2 节ki值的确定方法,通过设置不同的k值(k∈[2,10])寻找目标风机的邻近风机并计算出平均轮廓系数,结果如图8 所示。由图8 可以得出当k=3 时,聚类效果最好,因此将目标风机的近邻数k设置为3。
风电功率预测模型超参数设置:由于数据集样本的批处理尺寸、Python 优化器的选择以及GRU 网络隐藏层节点数等超参数的设置情况与网络模型的复杂程度和计算时长直接相关,进而影响预测效果。本文算例测试基于文献[19],根据轮廓系数的计算结果,如图8 所示,在k=3 时,平均轮廓系数最大,因此将人为设置的邻近风机数5 更改为3;其次,为了减少风电功率预测网络参数量,本文将其预测模型中的LSTM 网络改变为GRU 网络;风电功率预测模型超参数设置如表1 所示。

图8 风机不同k值的平均轮廓系数Fig.8 Average contour coefficient of fan with different k values

表1 风电功率预测模型超参数设置Table 1 Super parameter setting of wind power prediction model
3.3 基准模型
为了验证本文所提计及空间相关性的轻量级风电功率预测方法的有效性,选取ARMA-Copula[14],BP-Copula[15],LSTM-Copula[16],STAN[17],PSTN[18]作 为对比实验的基准模型。ARMA-Copula,BP-Copula,LSTM-Copula 模型是三种将深度学习方法与Copula理论相结合的风电功率预测方法,目前广泛应用于风电场或风电场群。STAN,PSTN 模型是当前考虑空间相关性的风电功率预测方法的先进算法代表。STAN 是采用多头自注意力机制来提取风电场之间的空间相关性。然后,通过具有全局注意机制的Seq2Seq 模型捕获时间依赖性;PSTN 是是一个集成CNN 和LSTM 的统一框架。首先,通过CNN 从空间风速矩阵中提取空间特征。然后,由LSTM 捕获从连续时间点提取的空间特征之间的时间序列特征。最后,由LSTM 顶层的最后状态输出预测的风速值。为了保证对比准确性,将基准模型中的CNN 与LSTM 的超参数控制在相似水平。
3.4 轻量级风电功率预测方法准确性验证
将本文模型与基准模型进行比较。风电功率预测的MAE 对比曲线如图9 所示,MAE 的统计值如表2 所示。由表2 统计结果显示,总体上,本文方法的预测误差的最大值、最小值以及平均值较基准模型方法均有所下降。由图9 曲线对比可看出,本文方法在预测的前6 h,预测效果与其它方法近似,在预测的后6 h 预测偏差均小于其它考虑空间相关性的风电功率预测方法。与基准模型方法相比,本文在计入邻近风机空间相关性时仅考虑了邻近风机的风速,未考虑其他气象因素,因此,本文所提方法在短期预测时与其他方法的预测效果近似,有时预测误差略高于其他两种方法。由于Seq2Seq结构可有效捕获序列长期依赖关系,本文预测方法在长期预测时效果优于其它方法。

图9 风电功率预测EAM对比Fig.9 EAM comparison of wind power prediction

表2 风电功率预测EAM统计值对比Table 2 Comparison of EAM statistical values of wind power prediction
3.5 基于轮廓系数的KNN算法有效性验证
为了验证轮廓系数对近邻风机数量确定的精准性,以图1 中18 号风机为例,分别采用固定k值(k=5)和引入轮廓系数后自适应的ki值进行聚类,实验结果分别如图10 和图11 所示。

图10 固定k值聚类效果Fig.10 Fixed k-value clustering effect

图11 自适应k值聚类效果Fig.11 Adaptive k-value clustering effect
聚类结果显示,当取固定值k=5 时,所取近邻风机包含与目标风机相对距离较远的20 号与21 号风机,引入轮廓系数后,自适应地确定出近邻数ki=3,与采用固定参数k的KNN 聚类方法相比,剔除了与目标风机距离较远的风机,进而降低了输入数据的特征维度。
为进一步验证基于轮廓系数的KNN 算法在本文模型中的作用效果,在本节中分别使用2 种不同的方式预测12 h 后的风电功率。第1 种方法为仅使用原始数据进行预测,第2 种方法为采用人为设定的固定参数k确定的近邻风机风速数据进行预测。第3 种方法为引入轮廓系数后,采用由轮廓系数所得k值确定的近邻风机风速数据进行预测。实验结果对比曲线如图12 所示,预测误差MAE 的统计值如表3 所示。

图12 聚类前后风电功率预测EAM对比Fig.12 EAM comparison of wind power prediction before and after clustering

表3 聚类前后风电功率预测EAM统计值对比Table 3 EAM statistical values comparison of wind power prediction before and after clustering
由图12 中对比结果及表3 中MAE 统计值可以看出,通过考虑风机空间相关性以及引入轮廓系数自适应确定k值,风电功率预测的准确性均有所提升。这表明通过考虑空间相关性,使用邻近风机的数据可以有效改善风电功率预测的准确度;在引入轮廓系数后,剔除了距离较远的风机,从而降低了输入数据的冗余维度,可适当减少预测误差。
3.6 基于Seq2Seq结构的GRU-MLP预测网络轻量性验证
为验证本文所提预测算法的轻量性,将本文所提算法的参数量与先进方法进行了比较。本文方法所需参数量为94.19 K,而ARMA-Copula,BPCopula,LSTM-Copula 所需参数量分别为799.65K、30.71 M、12.59 M。本文方法所需参数量分别为ARMA-Copula、BP-Copula,LSTM-Copula 3 种方法的11.78%,0.29%,0.73%。PSTN 方法与STAN 方法所需的参数量分别为2.20 M、225.23 M。本文方法所需参数量分别为PSTN 方法与STAN 方法的4.18%,0.04%。
根据网络轻量性验证实验结果得出,本文方法所需的参数量远小于其它方法。由此可见不需要过大的参数量,对深度学习方法的适当组合可以满足一定的预测需求。
4 结论
本文提出了一种计及空间相关性的轻量级风电功率预测方法,在电力系统云边协同领域具有应用潜力。不仅考虑了相邻风机间的空间相关性,并通过参数较少的风电功率预测模型达到了一定的准确性要求。本文所提方法有如下特征:
1)基于轮廓系数的KNN 算法降低了输入数据的维度,并提升了风电功率预测的准确性;
2)基于Seq2Seq 的GRU-MLP 风电功率预测网络的参数与其它考虑空间相关性功率预测方法相比大幅减少。为边端设备计算资源的高效利用提供技术方案。
本文方法在考虑空间相关性的风电功率预测方法上表现良好。但是电力系统的稳定运行往往需要考虑更多的环境因素。因此,对于未来的工作,将考虑引入物理影响因素对预测模型进行修正,提高模型预测的准确性。
猜你喜欢
学校教育研究(2020年12期)2020-06-27
时代英语·高一(2019年5期)2019-09-03
现代农业科技(2018年11期)2018-08-14
吉林农业(2018年10期)2018-06-07
中学生数理化·中考版(2017年4期)2017-07-08
科学家(2016年3期)2016-12-30
中学生数理化·中考版(2016年2期)2016-09-10
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
大灰狼(2009年7期)2009-08-26
数理化学习·初中版(2009年1期)2009-03-19
