
基于提交排序和预测模型的测试套件选择方法
2022-08-24 06:30:36刘美英杨秋辉王潇蔡创
计算机应用 2022年8期
刘美英,杨秋辉,王潇,蔡创
(四川大学计算机学院,成都 610065)
0 引言
持续集成(Continuous Integration,CI)是一种软件开发实践,每次集成都通过自动化的构建和测试进行验证,保证频繁变更的代码快速安全地集成到主线代码库,而随着版本的快速变更所需要的测试资源也在不断增长[1]。例如在Google 中,平均每秒触发的测试执行次数多达1.5 亿[2]。因此,提升CI 环境中的回归测试效率是至关重要的。
CI 环境中的回归测试,主要问题是大量提交导致的频繁构建和测试导致的测试资源过于庞大、反馈周期较长[3]。为此,Liang 等[4]提出对CI 环境中的提交进行优先级排序,可以提高故障检测率,但不能降低测试成本。另外Machalica 等[5]采用人工智能领域技术对测试进行选择以加快测试反馈。该方法虽然能降低测试成本,但没有考虑CI 中大量提交到达的情况,忽略了密集提交的顺序对排序质量的影响。
在CI 中,为了对不断到达的变更提交进行回归测试,在保证故障检测率的同时降低测试成本,满足持续集成的质量和速度需求。综合考虑故障检测路和测试成本,提出CI 中一种新的回归测试选择方法:基于提交排序和预测模型的测试套件选择方法。本文方法包含提交排序和测试套件选择两个阶段。首先根据各个提交的历史失败率和执行率进行排序;之后对提交包含的测试套件采用XGboost 算法构建失败率预测模型,选择高失败率测试套件执行。在Google 的共享数据集上进行评估,在开销感知平均故障检测率(Average Percentage of Faults Detected per cost,APFDc)、选择率(SelectionRate)、测试召回(TestRecall)、变更召回(ChangeRecall)四个指标上本文方法比文献[4-5]方法有更好的表现。
1 相关工作
文献[6-11]基于历史执行信息,研究了历史测试数据对优先级技术效率的影响,证实了历史执行数据对测试用例优先级(Test Case Priorization,TCP)排序技术研究的重要性。文献[12]基于历史日志信息设计了回归测试优先级排序算法,优化了持续集成测试流程。Do 等[13]评估了时间限制对TCP 技术的成本和收益的影响,从经济有效的回归测试角度给予了测试工程师启示。Liang 等[4]提出基于提交的排序技术(Continuous,Commit-Based Prioritization,CCBP),该方法使用测试套件失败和执行信息对CI 中持续到达的提交进行优先级排序;但该方法仍然需要执行提交中的全部测试套件,测试成本并未得到有效降低。
文献[14-18]根据回归测试历史信息提出了一系列测试选择技术,证实了执行历史对回归测试选择(Regression Test Selection,RTS)技术研究的重要性。Machalica 等[5]提出一种新的预测测试选择策略,基于历史执行信息对测试套件进行失败率预测和选择。但该方法并没考虑到密集提交环境中多个提交间的序列对故障检测率的影响。
另外,现有研究也包含TCP 和RTS 混合优化技术。Elbaum 等[19]提出在测试预提交阶段使用RTS 技术选择测试套件的子集,在提交后的测试阶段使用TCP 技术确保故障快速反馈。Spieker 等[20]介绍了Rerecs,一种能自动学习CI 中TCP 和RTS 的新方法,旨在最大限度减少反馈时间。Najafi等[21]根据先验的TCP 和RTS 方法,确认了测试执行历史中失败信息的价值。本文参考以上文献,提出基于提交排序和预测模型相结合的回归测试选择方法,是一种历史数据驱动的回归测试优化方法。
2 本文方法
本文提出了一种提交排序和测试套件选择相结合的持续集成回归测试优化方法,可以提高故障检测率,同时降低测试成本。本文方法的流程如图1 所示。

图1 本文方法的流程Fig.1 Flowchart of the proposed method
提交排序阶段,对等待队列中的所有提交,根据其相关测试套件在版本控制储存库中的执行历史,进行失败率和执行率计算,然后对当前版本的提交进行排序。测试套件选择阶段,对于已排序的各个提交作如下处理:对当前提交所包含的测试套件,使用预先构建好的模型进行测试套件选择。而测试套件选择模型是在执行回归测试前,使用版本控制数据库中的历史信息构建的。为了提高效率,测试套件失败率预测和选择模型的构建可以周期性地,每一周或者几天更新,其构建过程包括收集版本控制库中的历史提交和执行数据,然后进行数据预处理,最后建模。
2.1 提交排序
CI 环境下存在多个开发人员持续发起提交,每次测试结果也随之更新,此时优先级排序方法要求必须是轻量级并且能快速持续进行。一段时间内可能对相同队列进行多次排序,导致传统的代码插装和变更分析技术不再适用。文献[4]认为在提交级别针对多个提交进行优先级排序后的测试表现更符合CI 环境的测试特点。本文根据动态的提交和测试结果信息采用基于提交的排序方法。
该过程涉及三类数据:1)提交本身,包含该提交到达的时间及相关联的测试套件集。另外还需人为计算一组属性,包括提交的预期故障率(基于提交的测试套件失败的概率)和执行率(提交的测试套件最近未执行的概率),分别用于优先级排序;2)待执行的提交(commitQ)队列。到达的提交会添加到commitQ 中,执行中的提交会从commitQ 中移除,当资源可用,就对commitQ 进行优先级排序;3)失败窗口的大小(failWindowSize)和执行窗口的大小(exeWindowSize),可根据提交的数量衡量,在本次实验中设定为固定值,实际环境中也可根据不同条件进行调整。
提交排序的基本思想是,当新的提交到达时先加入等待队列,只有当队列不为空且测试资源可用时,才对等待队列中的所有提交分别计算所包含的测试套件的历史失败率和执行率,历史失败率指在最近历史中该提交的失败测试套件数占测试套件总数的比例,执行率指在最近历史中该提交执行过的测试套件数占测试套件总数的比例。最近历史由失败窗口和执行窗口限制,例如失败窗口和执行窗口大小为5,最近历史为距本次提交最近的5 次提交的测试套件的失败和执行历史。首先比较提交的失败率,失败率更高则优先级更高;失败率相同则比较执行率,执行率低的测试套件对应的提交优先级更高,以此得到最高优先级提交,将其移出等待队列并释放资源。提交优先级排序算法的伪代码如下。
算法1 提交排序算法。
输入按时间先后到达的提交集合commitQueue,包含多个commit,每个commit 的测试套件集testSuites,包含多个测试套件。
输出最高优先级提交。

2.2 基于预测模型的测试套件选择
CI 中记录了项目中受变更影响的测试套件的执行结果,因此可以通过历史结果信息构建预测模型,对测试套件进行失败率预测,从而选择失败可能性较高的测试套件。
2.2.1 数据收集和预处理
为收集CI 中的项目数据,可从版本控制库和CI 服务器中通过提交日志和构建日志获取相关的提交和测试数据。如提交的执行结果、提交包含的测试套件集、各测试套件执行结果,最后将关联信息通过进行人工或统计程序分析得到各测试套件失败次数、执行次数,合并数据得到样本数据集。数据预处理部分采用基于包装器Wrapper[22]的特征选择方法。使用XGboost 作为特征选择的基模型,通过枚举法进行特征子集遍历,将去掉该特征的特征集与全特征集的选择率selectionRate的比值作为分类度量,数量阈值numberThreshold作为排名度量,探索去掉某一特征集对模型的影响。分类度量、排名度量大于1 则表示有积极影响,选择该类特征作为最终特征子集。
2.2.2 预测模型构建
使用XGboost 算法[23]构造测试套件失败率预测模型学习器,变更提交c和与之相关的测试套件集作为输入,失败的测试套件标记为正例,反之为负例。XGboost 学习器相当于一个函数,根据输入返回一个区间在[0,1]的分数score(c,t),表示测试套件t在提交c中的失败概率。测试套件选择策略由预先定义的分数阈值scoreThreshold和数量阈值numberThreshold控制。两个参数阈值的确定方法基于文献[5]中通过反复评估模型性能不断调整得到,模型评估时先定义需要达到的测试召回和变更召回标准,再调整两个参数的值。模型构建的流程如图2 所示。
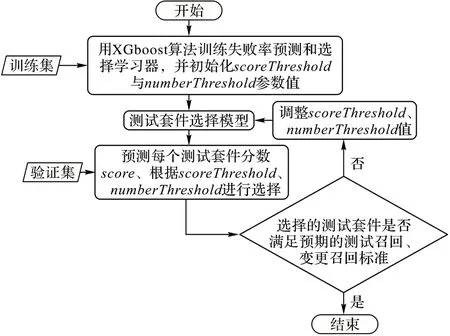
图2 测试套件失败率预测和选择模型构建流程Fig.2 Construction flowchart of test suite failure rate prediction and selection model
2.2.3 测试套件失败率预测和选择
用构建的模型进行测试套件失败率预测和选择。首先对提交的测试套件进行数据预处理,得到符合XGboost 学习器输入的特征值的集合作为待预测样本输入;然后学习器进行预测,预测后返回每个测试套件的分数score(c,t);最后选择score(c,t)≥scoreThreshold的测试套件t,且选择的测试套件总数量不超过numberThreshold。
3 实验验证
3.1 实验数据
本文使用Google 共享数据集[24],包含15 d 内收集的超过2 506 926 个测试套件的执行信息。原始数据集的相关统计信息如表1 所示。
3.2 评估指标
为综合考虑选择质量和故障检测率,故使用测试召回(TestRecall)、变更召回(ChangeRecall)、选择率(SelectionRate)、开销感知平均故障检测率APFDc四个指标评估本文方法。本文引用文献[5]中的三个度量标准来优化选择模型和评估质量。设C是一组变更提交,FC是更改c中失败测试套件集,,SelectedTests(c)是更改c中选择的测试套件集,AllTests(c)是更改c相关的所有测试套件。测试召回(TestRecall):表示选择的测试套件属于失败测试套件集的概率,其定义见式(1)。变更召回(ChangeRecall):表示选择的测试套件属于包含失败测试套件的变更提交的概率,其定义见式(2)。选择率(SelectionRate):表示选择的测试套件与提交包含的所有测试套件的比例,其定义见式(3)。其中TestRecall、ChangeRecall的值越高,SelectionRate越低,则回归测试选择的质量越好。

为评估故障检测率,使用了改进的APFDc度量标准[4]。APFDc是基于成本的平均故障率表示,与传统的基于测试用例级别的APFDc[25]不同,改进后的APFDc考虑的是测试套件的执行过程,对测试套件的故障检测率进行评估。APFDc的计算公式见式(4):

其中:T为有序的测试套件集;n为T中的测试套件总数;F为有故障的测试套件集;m为F中的测试套件数;TFi为首次检测到F中第i个有故障的测试套件在T中的次序;tj为第j个测试套件的执行开销。
3.3 构建失败率预测和选择模型
为在Google 开源数据集应用本文方法,首先根据文献[4]将窗口大小设为10,测试资源设为1,即最近历史限制为考虑最近的10 次提交的测试信息,且整个流程中测试资源只能被一个提交所使用即同一时间只考虑单个提交的测试执行。使用Java 多线程模拟提交的到达和优先级排序。
根据文献[5,26]使用的特征在原始数据集上增加了一些需计算得到的特征,其中包含提交触发的测试套件数(Test suite cardinality)、测试套件的历史失败率(History failure rate)、测试套件的历史执行率(History execution rate)。基于包装器Wrapper 方法,在TestRecall=0.9 时计算模型的分类度量和排名度量,最后选择分类度量和排名度量大于1 的特征得到构建模型的特征子集:History failure rate、History execution rate、Size 和Language。
最后将原始数据集按6∶2∶2 划分为训练集、验证集和测试集。在训练集上构建初步模型观察得到学习率为0.05,故设置选择策略的参数scoreThreshold=0.05,numberThreshold=10。在验证集上评估模型调整两个参数值,在该过程中将模型标准定位测试召回设为0.9 以上,变更召回设为0.95 以上,分别计算测试召回在scoreThreshold和变更召回在numberThreshold的依赖性。最终得到在GooglePre 验证集上scoreThreshold≈0.35,numberThreshold≈362;在 GooglePost 验证集上scoreThreshold≈0.32,numberThreshold≈240。
3.4 对比实验及结果分析
本文方法先对提交进行优先级排序再选择测试套件执行,因此与同样采用提交排序的文献[4]方法、采用测试套件选择的文献[5]方法作对比实验验证方法的有效性。在Google 共享数据集上:对文献[4]方法进行重现并获得实验结果;对于文献[5],由于Google 开源数据集与文献[5]方法所使用的私有数据集相比缺少一些特征,如涉及到源代码的文件数、作者名及文件间的依赖性,导致模型在构建时的输入特征有差异,因此本文对文献[5]的核心算法进行实现。
1)故障检测率对比。为对比方法的故障检测速度,不限制测试成本,分别记录三种方法在Google 共享数据集上的测试执行时间和包含失败测试套件的提交执行比例,统计分别在执行时间到达25%、50%以及75%时执行的包含失败测试套件的提交比例,并计算各自的APFDc值。
GooglePre 数据集上的结果如表2 所示。由表2 可知,本文方法的包含失败测试套件提交的执行比例即揭错率在各时间节点的表现都优于另两种方法。其中本文方法比文献[4]方法的揭错率提高了17.9%~30.2%,比文献[5]方法的揭错率提高了4.8%~32.0%。
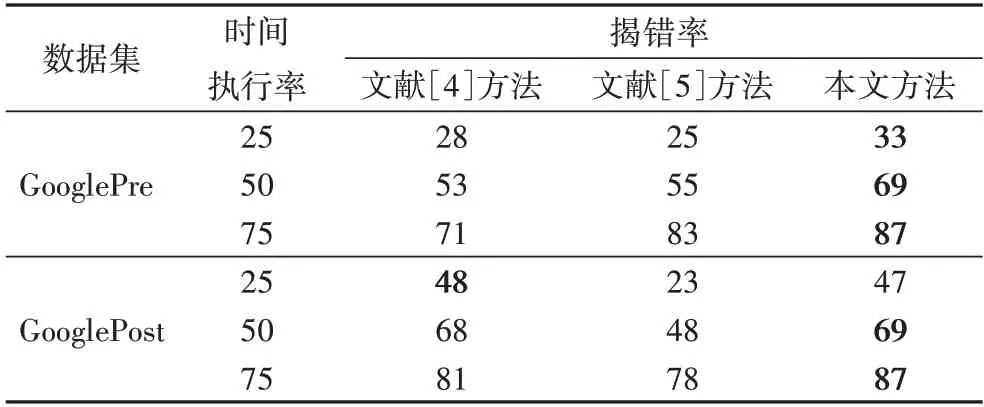
表2 不同时间执行率下不同方法的揭错率对比 单位:%Tab.2 Comparison of error revealing rate under different methods unit:%
GooglePost 数据集上结果如表2 所示。由表2 可知,本文方法的揭错率在各个时间节点的表现都优于文献[5]方法,其中本文方法比文献[5]方法揭错率提高了11.5%~104.4%。与文献[4]方法相比,虽然执行时间在25%节点时,本文方法表现略差,但随着时间的增加,本文方法的提交执行比例逐步超过文献[4]方法,执行时间在75%节点时揭错率提高了7.4%。从以上结果可知,经过提交优先级排序的测试选择技术能更早检测到更多的缺陷。
APFDc值对比结果如表3 所示。在GooglePre 数据集上,本文方法的APFDc值比文献[4]方法高0.126 2,比文献[5]方法高0.098 7。在GooglePost 数据集上,本文方法的APFDc值比文献[4]方法高0.005 6,比文献[5]方法高0.014 5。因此本文方法最高在现有方法的结果基础上提高了1%~27%。通过测试的揭错率和APFDc值的比较,本文的方法可以提高基于成本的故障检测率,更早地检测到更多的缺陷。

表3 不同方法的APFDc值对比Tab.3 APFDc value comparison
2)为评估选择的质量,限制测试成本。三种方法的测试成本为文献[4]方法>本文方法>文献[5]方法,以本文方法的测试成本为基准,三种方法在测试过程中时间到达则停止测试。统计三种方法选择的测试套件数、包含失败的测试套件数、包含失败测试套件的变更提交数,并计算各自的测试召回、变更召回和选择率。
由图3 可知与文献[4]方法相比,在GooglePre 数据集上,本文的TestRecall、ChangeRecall的值比文献[4]方法的值分别高38.16、15.67 个百分点,SelectionRate的值比文献[4]方法低6.2 个百分点。由图4 可知在GooglePost 数据集上,本文的TestRecall、ChangeRecall的值比文献[4]方法的值分别高33.33、24.52 个百分点。SelectionRate的值比文献[4]方法低6.33 个百分点。

图3 GooglePre数据集上TestChange、ChangeRecall和SelectionRate的对比Fig.3 Comparison of TestChange,ChangeRecall and SelectionRate on GooglePre dataset
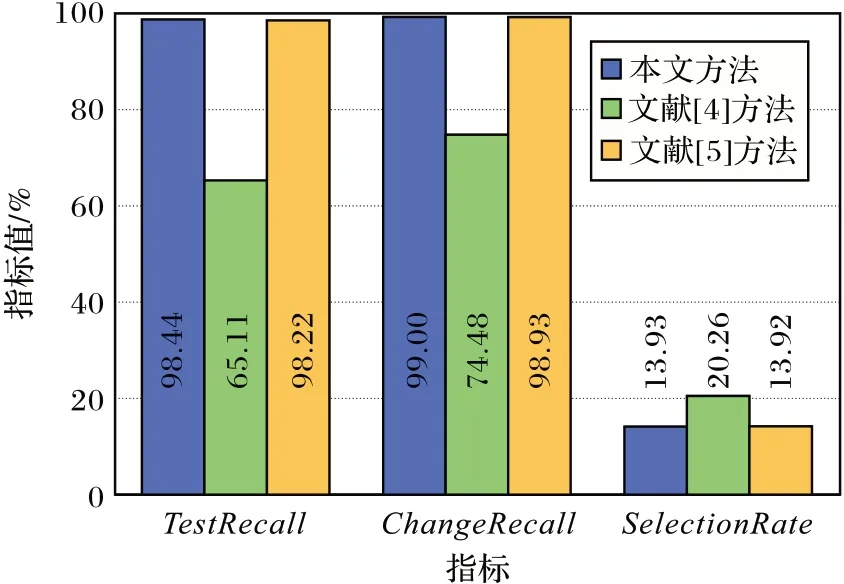
图4 GooglePost数据集上TestChange、ChangeRecall和SelectionRate的对比Fig.4 Comparison chart of TestChange,ChangeRecall and SelectionRate on GooglePost dataset
TestRecall和ChangeRecall高是因为受测试成本影响,文献[4]方法做实验时丢失了一部分失败测试套件。文献[4]方法选择率高是因为在同样的时间成本下执行的测试套件的数量更多。
与文献[5]方法相比,本文方法的TestRecall、ChangeRecall的值略高一些,由于经过提交排序后的一些测试套件集的特征值History failure rate 更高,失败率预测的分数更大使被选择的失败测试套件集更多。虽然本文方法与文献[5]方法构建模型的特征略有差异,导致选择的质量并不够理想,但本文综合使用提交排序和测试套件选择的方法比文献[5]方法只使用测试套件选择的方法效果更好。从构建模型的角度出发,更多有效的信息来源,如代码更改的历史,都能以附加特征的形式纳入测试选择模型中以提高选择的性能,这一点在未来工作中是值得探索的。总的来说,本文方法在给定的测试成本下,选择了相对较少的测试套件,提高了测试套件的测试召回和变更召回。
综合上述结果,在不限测试成本情况下,本文方法的APFDc值更高,即提高了故障检测率的速度;以本文测试成本为统一基准,本文方法的TestRecall和ChangeRecall值更高,SelectionRate值更低,即降低了测试成本。因此将提交优先级排序和测试选择套件选择相结合的方法提高了故障检测率,并降低了测试成本。
4 结语
为在持续集成环境中取得反馈速度和测试成本间的平衡,本文提出了一种结合提交优先级排序和测试套件选择的方法。该方法分两阶段:第一阶段对提交进行优先级排序,并对提交等待队列进行持续的优先级排序,提交排序方法作为只考虑失败率和执行率的轻量级方法,在CI 环境中能快速完成排序;第二阶段对前一阶段得到的最高优先级提交包含的测试套件采用构建的失败率预测模型预测,选择高失败率测试套件执行。通过对比实验,验证了本文方法的有效性。
本文综合考虑故障检测率和测试成本,解决在持续集成环境中测试成本过高、提交序列影响测试反馈速度的问题,但还存在不足之处。比如:在提交优先级排序技术中,没有关注提交之间的依赖关系,且只考虑了单个测试资源可用的情况,未来可研究基于上述情况动态调整排序算法,输出多个优先级较高的提交。构建测试套件选择模型中,对于特征集子集的选择未来可使用更多变更影响技术分析得到最具代表性的特征子集。对于一些新代码的提交,包含的历史信息较少,本文方法可能并不适用。
猜你喜欢
装备制造技术(2020年3期)2020-12-25 05:22:34
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
口腔医学(2020年6期)2020-07-08 06:11:00
山东陶瓷(2020年5期)2020-03-19 01:35:36
数学物理学报(2019年6期)2020-01-13 06:08:16
爱你(2019年21期)2019-11-14 12:37:32
爱你·健康读本(2019年6期)2019-07-08 06:28:03
数学物理学报(2017年5期)2017-11-23 07:51:31
中国照明(2016年5期)2016-06-15 20:30:13
思维与智慧·上半月(2014年8期)2014-09-10 07:22:44
