
基于反向影响采样的积极影响力最大化
2022-08-24 06:30:52杨书新许景峰
计算机应用 2022年8期
杨书新,许景峰
(江西理工大学信息工程学院,江西赣州 341000)
0 引言
随着互联网的蓬勃发展和信息技术的日益普及,大型社交网络(如Twitter、Facebook 和微博等)已经成为人们在日常生活中交流和互动的重要平台。通过对社交网络进行分析和数据挖掘,企业可以制定出更加有效的社会化营销体系,从而提升品牌的影响力。2001 年,Domingos 等[1]提出了影响力最大化问题,主要思想是:给定一个建模为图G的社交网络,在其中找到k个用户作为种子节点,使信息在特定的传播模型下,通过这k个初始用户的传播后能在社交网络中达到最大的影响范围。随后,影响力最大化问题逐渐成为社交网络分析领域的一个研究热点,广泛应用在病毒营销、谣言控制和个性化推荐等方面,有重要的现实意义。
目前,大部分的研究工作主要集中在无符号网络上,即默认社交网络用户之间传递的都是积极的关系。然而在实际生活中,人与人之间有积极的关系,亦有敌对的关系。如果仅仅考虑个体之间的积极友好关系,忽视了敌对的关系,会造成信息影响范围不准确的问题。例如,某个商家想要推广一种产品,如果商家找到的初始推广用户与很多人是敌对关系,那么,这些人大概率会对这款产品持负面意见,最终的宣传效果就不尽如人意。因此,在一些实际场景中,计算信息的传播范围需要同时考虑人们之间的积极和敌对关系,以防止所需的影响范围被过度估计,可以通过研究符号网络[2]中的积极影响力最大化来解决。
然而,针对符号网络的积极影响力最大化研究较少,并且其中大部分工作集中在使用传统的贪心(Greedy)算法或启发式算法在符号网络中进行研究。贪心算法计算影响范围时精度高,但时间开销巨大;启发式算法所需的时间消耗少,但计算结果精度较低。面对日益庞大的社交网络,两种算法都有各自难以克服的缺点。
为了更好地解决符号网络中的积极影响力最大化问题,本文提出了一种符号网络中基于反向影响采样(Reverse Influence Sampling in Signed network,RIS-S)的算法。该算法可以在符号网络中进行反向影响采样,找到的种子节点准确度较高,时间复杂度低,能够高效地解决符号网络中的积极影响力最大化问题,适用于大规模的社交网络。
本文的主要工作如下:
1)将反向影响采样的方法引入到符号网络中,以解决积极影响力最大化的问题,该方法能够在时间消耗和结果准确度上取得较好的平衡,与同类型算法IMM(Influence Maximization via Martingales)相比,运行时间更短,准确度更高。
2)在生成反向可达集阶段,考虑了节点之间的极性关系,从而可以获得更加准确的积极影响范围;为了减少反向可达集的重叠,限制了采样深度,提高了反向可达集的有效性。
1 相关工作
2001 年,Domingos 等[1]提出使用马尔可夫随机场(Markov Random Field)模拟信息的传播过程,首次提出了影响力最大化问题。Kempe 等[3]将该问题定义为一种离散优化问题,并提出了两种基本的传播模型:独立级联模型(Independent Cascade Model)和线性阈值模型(Linear Threshold Model)。基于这两种传播模型,Kempe 等[3]证明了影响力最大化亦是NP-Hard 问题,并提出了一种近似比为(1 -1/e -ε)的贪心算法,可以获得影响力最大化问题最优解63%的近似解。通过研究目标函数的子模特性,Leskovec等[4]对贪心算法进行了优化,提出了CELF(Cost-Effective Lazy-Forward)算法,该算法在时间效率上比传统的贪心算法快了近700 倍。Goyal 等[5]优化了CELF 算法,提出了CELF++算法,进一步提高了时间效率。上述贪心算法时间开销巨大,难以扩展到现实场景中,有一定的局限性。2009 年,针对传统度估计算法的影响范围重叠问题,Chen 等[6]提出了DgreeeDiscount 算法,这是一种启发式算法,它的主要思想是:如果节点u的邻居节点中存在种子节点v,那么将u选为种子节点时,需要将u的度数进行一定的折扣,最终再选出度数最大的前k个节点作为种子节点。尽管DgreeDiscount在时间效率上比贪心算法提升明显,但是该算法求解的精度较低。2014 年,Borgs 等[7]将反向影响采样的思想引入影响力最大化问题中,提出了反向影响采样(Reverse Influence Sampling,RIS)算法。他们发现在寻找k个所需的种子节点的过程中,没有必要对整个图进行计算,并提出了反向可达集(Reverse Reachable Set)的概念。根据RIS 的思想,如果一个节点高频率地出现在采样图g所生成的反向可达集中,那么它有较高的可能性是种子节点的良好候选者。该算法得到的时间复杂度接近线性,能以不小于1-n-1的概率得到近似比(1 -1/e -ε)。RIS 算法为影响力最大化问题研究提供了一种新颖的思路,此后,学者们对此类算法进行了更加深入的研究。为了进一步提高算法的效率,Tang 等[8]提出了两阶段影响力最大化(Two-phase Influence Maximization,TIM)算法。相较于RIS 算法,TIM 算法减少了采样的数量,降低了时间复杂度,并且支持触发模型。通过对参数估计的改进,Tang 等[8]还提出了TIM+算法。TIM+与TIM 具有相同的最坏情况复杂度,但能表现出更加优秀的经验性能。尽管如此,TIM 和TIM+在计算成本方面仍然有很大的改进空间。2015年,Tang 等[9]基于鞅(Martingale)的估计技术提出了IMM 算法,该算法利用折半猜测的方法估计影响力扩展度的下界,实验结果表明,IMM 比TIM/TIM+性能更好。
大量的影响力最大化研究聚集在无符号网络上,也为解决符号网络下的积极影响力最大化问题指明了道路。Li等[10]首次研究了符号网络中的影响力最大化问题,他们利用“敌人的朋友就是我的敌人,敌人的敌人就是我的朋友”的社会原则,将IC(Independent Cascade)模型扩展到了符号网络中,提出了极性相关的独立级联(Polarity-related Independent Cascade,IC-P)模型。在此模型下,他们使用了贪心算法解决积极影响力最大化问题,在每次迭代中选择一个节点,以提供总影响的最大边际收益。IC-P 贪心算法与无符号网络中的贪心算法一样有着计算开销过于庞大的缺点。之后,Li 等[11]又在IC-P 模型中使用了模拟退火算法解决积极影响力最大化问题,该方法在精度(积极影响范围)方面与IC-P 贪心表现相似,但在效率方面更优。Wang 等[12]在符号网络中推广了LT(Linear Threshold)模型,提出了解决积极影响力最大化的LT-A 模型,然而,在进行求解时,使用的是贪心算法,效率偏低,不适用于大型社交网络。Hosseini-Pozveh等[13]提出了一种符号感知级联模型,并证明了在该模型中积极影响力最大化是NP-Hard 问题,最后使用了一种基于粒子群优化的启发式算法求解积极影响力最大化。Ju 等[14]使用独立路径计算符号网络中节点间的正激活概率,为了避免在估计传播范围时进行蒙特卡洛模拟,提出了一种传播函数以估计种子集的正影响传播。Qiu 等[15]针对符号网络提出了一种改进的级联模型ICWNP(Independent Cascade With the Negative and Polarity),并在该模型下使用了贪心算法解决极性关系的影响力最大化问题,该方法准确度较高但运行时间较长。
2 问题定义和形式化描述
给定一个符号网络Gs=(V,E,P,S),其中V是节点的集合,V={v1,v2,…,vn},每一个节点v∈V代表社交网络中的一个用户;E={e1,e2,…,en}是有向边的集合,(u,v) ∈E表示节点u对节点v的影响关系;P(u,v) ∈[0,1]表示节点u对节点v的影响概率;S(u,v)表示节点u和v的极性关系(S(u,v) ∈{+1,-1}),S(u,v)为+1 表示节点u对节点v产生的是积极(友好)的关系,如果为-1 则是消极(敌对)的关系。P(u,v) ≠P(v,u)且S(u,v) ≠S(v,u),即两节点之间的影响概率和极性关系都是双向的,相互独立。图1 展示了符号网络的一个具体例子,每条有向边都有属性S(u,v) ·P(u,v)。
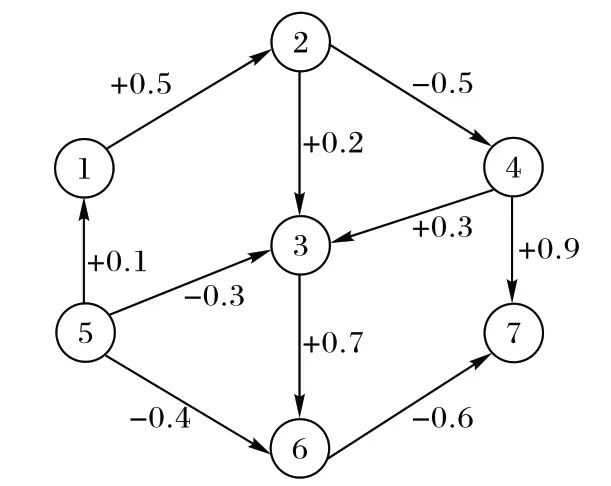
图1 符号网络Fig.1 Signed network
为了更加清楚地表述,表1 列出了本文常用的符号表示。
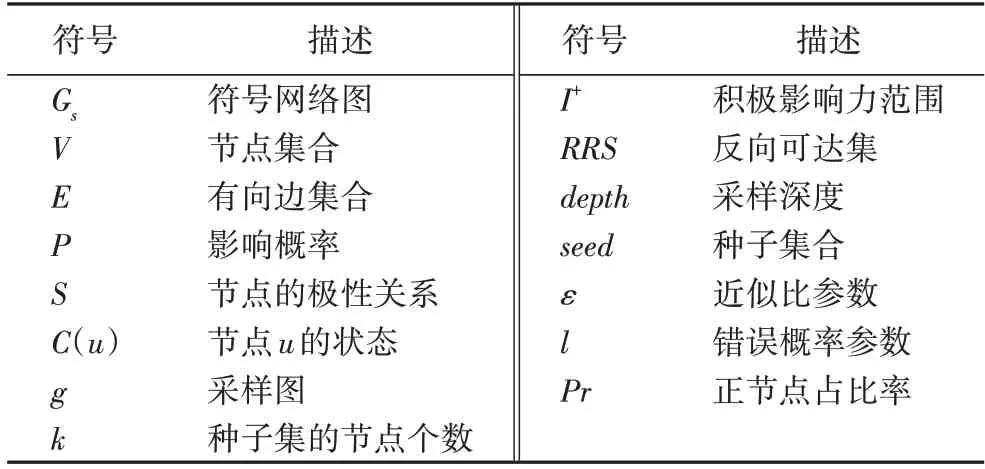
表1 常用符号表示Tab.1 Representation of frequently used symbols
2.1 IC-P模型传播规则
文献[10]针对符号网络扩展了IC 模型,提出了IC-P 模型,以解决符号网络中的影响力最大化问题。在该模型中,如果某个节点已经处于激活状态,那么它将有机会在下一轮信息传播中激活它的出度邻居节点(如果节点a有路径可以到达节点b且二者为邻居节点,则节点b为节点a的出度邻居节点,节点a为节点b的入度邻居节点)。被激活节点v的状态C(v)取决于激活它的节点u的状态C(u)和两节点之间的极性关系S(u,v),遵循如下规则:
其中:C(v)=+1 表明节点v处于积极状态,即节点v对传播的信息持正面意见;C(v)=-1 表明节点v处于消极状态,对传播的信息持负面意见。在积极影响力最大化问题中,种子节点的初始状态都为积极状态。以病毒式营销为例,商家想要推广某种产品,那么他找到的初始推广人应当是对产品持正面意见且影响力大的人物,只有这样营销才有实际意义。在图2 所示IC-P 模型信息传播的具体例子中,节点n1是种子节点,节点n1的初始状态C(n1)=+1。在第一轮信息传播中,节点n1激活了n2、n3、n4三个节点,但是依据式(1)中的规则,只有n3、n4节点处于积极状态。被激活的节点有且只有一次机会激活它们的邻居节点。在第二轮传播中,节点n2成功激活了节点n6,节点n3则激活了节点n5,节点n4尝试激活节点n7但并未成功;在第三轮传播中,节点n6激活了节点n7,此时网络中已经没有节点可以被激活了,整个传播过程结束。
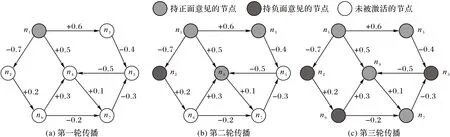
图2 IC-P模型传播示例Fig.2 Propagation examples of IC-P model
2.2 反向影响采样相关概念
定义1采样图。在图G=(V,E,P)中,对于图G中的每一条边e∈E,以1 -Pe的概率删除,最终得到的子图g是采样图。
定义2反向可达集。设v是图G中一个给定的节点,采样图g中可以到达节点v的节点集合为v在g中的反向可达集。
2.3 符号网络中的积极影响力最大化
给定一个数k∈N,代表种子节点的个数。在符号网络Gs=(V,E,P,S)中,节点有三种状态:积极状态、消极状态和未激活状态。积极状态下的节点表示其对传播的事物持正面意见,消极状态下的节点对传播的事物持负面意见。积极影响力最大化的目标是找到k个种子节点,使它们在特定传播模型下能够影响到的积极状态节点数达到最大,可以被形式化为式(2):
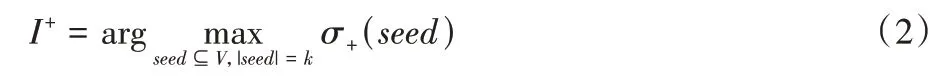
其中:seed表示的是种子节点集合;k是种子集合的大小,在病毒营销中可以理解为商家用于广告投放的成本;σ+(seed)表示的是被种子节点激活的最终具有积极状态的节点个数期望。
3 基于反向影响采样的积极影响力最大化
贪心算法在求解符号网络中的积极影响力最大化问题时虽然能保证精度,但随着社交网络规模愈加庞大,此类算法求解的时间成本呈指数型增长,难以满足现实需求;启发式算法利用直观上的经验,能在有限的搜索空间内较为迅速地得到结果,然而其求解精度却难以得到理论保证。基于反向影响采样思想的算法在解决影响力最大化问题时避免了上述问题,在影响力精度和运行效率上取得了较好的平衡,为了更好地解决符号网络中的积极影响力最大化问题,本文提出了基于反向影响采样思想的算法RIS-S,该算法在符号网络中进行反向影响采样,算法主要分为两阶段:1)在符号网络Gs的采样图g中生成一定数量的反向可达集。2)在生成的反向可达集中用贪心方法找到k个节点,使它们覆盖的反向可达集尽可能地多,这k个节点即是积极影响力最大化问题中所需的k个种子节点。
详细介绍如下:
1)生成一定数量的反向可达集。生成反向可达集的前提是需要构建符号网络G=(V,E,P,S)的采样图。依据定义1,采样图的生成只与图中每条边的传播概率Pe有关,所以在符号网络中获取采样图的方法与在无符号网络中一致。生成采样图g时,两节点间的传播概率越大,它们之间的连接关系在图g中更容易出现,这与信息在独立级联模型中的传播机制类似。在IC-P 模型中,种子节点的初始状态都为积极状态,依据式(1),如果节点v被节点u激活且节点u处于积极状态,那么当且仅当两节点间的极性关系S(u,v)等于+1时,被激活的节点v才能处于积极状态,所以在生成反向可达集时,可以先利用边上的极性关系信息剔除不可靠的候选种子用户。具体的做法是,在生成采样图中某一节点u的反向可达集时,只将可以到达节点u且路径中极性关系都为+1的节点纳入到节点u的反向可达集中,不仅可以将节点间的极性关系融入反向可达集中,还能避免状态为-1 的节点对最终积极影响范围造成干扰。
在以往的研究中,以IMM 及其优化算法(Stop-and-Stare Algorithm,SSA)[16]为代表的基于反向影响采样思想的算法都专注于研究反向可达集的数量,从而保证算法的精度,但却忽略了反向可达集之间的冗余现象。图3(a)是一个有8个节点和7 条连接边的社交网络图G,边上的数字代表节点间的传播概率,对每一条边以1 -Pe的概率进行移除操作后,可以获得采样图,再对采样图进行遍历可以获得不同节点的反向可达集。采样图的生成过程具有随机性,所以图G可以生成多个不同的采样图(如采样图g1 和g2),由此获得的反向可达集也不尽相同。在采样图g1 中,节点8 的反向可达集是{1,3,6,8},而在采样图g2 中,节点8 的反向可达集为{3,6,8}。每条边的传播概率P(u,v)相互独立,传播路径1→3→6→8 和3→6→8 出现在采样图中的概率可由式(3)计算:
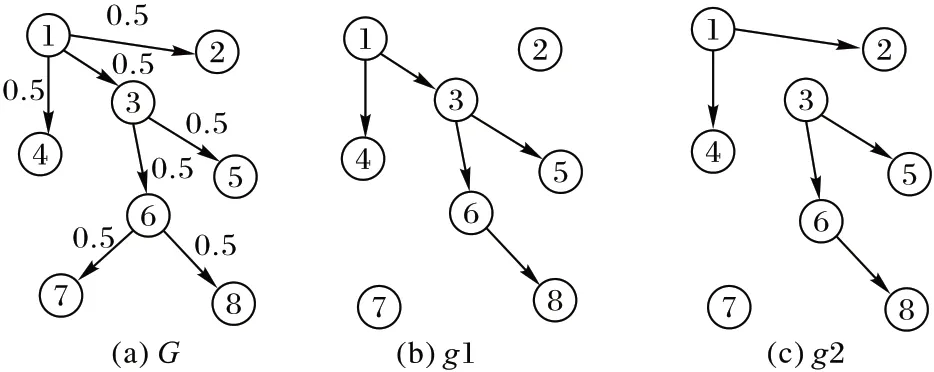
图3 采样图及反向可达集示例Fig.3 Examples of sampling graph and reverse reachable set

其中:(u,v)表示路径path中的一条边;P(u,v)表示节点u对节点v的影响概率。由此可知,传播路径1→3→6→8 出现在采样图g1 中的概率为0.125,传播路径3→6→8 出现在采样图g2 中的概率为0.25,显然,传播路径3→6→8 更容易出现在采样图中。因此,当反向可达集的数量有限制时,{3,6,8}更可能是节点8 的反向可达集,而不是{1,3,6,8}。
针对上述例子所展现的情况以及基于三度影响力原则[17],本文提出的RIS-S 算法在生成反向可达集阶段控制了最大采样深度,以减少反向可达集的冗余,进一步提升了最终影响精度,生成反向可达集的方法如算法1 所示。

在算法1 中,首先生成符号网络Gs的采样图g,然后在Gs中随机选择一个要生成其反向可达集的节点v。new_nodes表示生成反向可达集时新增节点的集合;RSS0 表示上一轮遍历生成的反向可达集,其初始值为节点v;temp用于暂时存储新增的节点。第4)~5)行,令初始采样深度为1,并开始生成节点v的反向可达集;第6)~9)行,随机选择new_nodes中的某个节点u作为起始节点,依次搜寻与它极性关系为+1 的入度邻居节点,并加入到反向可达集RRS中,下一轮的new_nodes节点为本轮加入到RRS中的新增节点;第10)~13)行,如果某一次迭代中采样深度depth大于最大影响采样深度sample_depth,搜寻停止,否则开始新一轮搜寻;第15)行,返回最终的反向可达集RRS。
2)使用最大覆盖方法选取k个种子节点。在反向影响抽样的机制中,节点的影响力与它覆盖的反向可达集数量成正比,如果某个节点高频率出现在反向可达集中,那么它将被认为是具有高影响力的节点。选取k个种子节点的具体方法如下:

算法2 使用最大贪心覆盖方法在反向可达集中找出k个种子节点。第1)行,先初始化种子节点集seed;第2)~4)行,将出现在反向可达集中次数最多的节点选为种子节点,并将其添加到种子节点集seed中;第5)行,更新反向可达集,剔除包含本轮被选为种子节点的反向可达集。进行k轮循环,最后返回种子节点集seed。
3.1 个体化系统管理模式降低了新生儿出生缺陷率 本研究在孕前及孕早期开展了健康生活方式的教育[5-6],生殖遗传咨询门诊,建立了新生儿缺陷的三级预防体系[7]。结果显示,观察组新生儿出生缺陷(4.95‰)明显低于对照组(12.53‰),说明在孕前开展个体化的优生优育知识健康教育工作的必要性,观察组建立孕前—围产期档案、计划妊娠管理,从年龄、营养、遗传和环境因素进行孕前风险评估,做好优生优育的科普教育,减少遗传性畸形的出生。孕早期及时补充叶酸及少量维生素,开展实验室筛查、羊水检测等物理诊断,充分做好三级预防体系,将孕期保健时间节点前移,为孕产妇提供一体化的延伸服务措施。
RIS-S 算法的时间复杂度分析过程如下:在算法1 的第1)行中,获取采样图的时间复杂度为O(|E|);在第5)~7)行中,搜寻与new_nodes节点极性关系为+1 的入度邻居节点的时间复杂度为O(|new_nodes| · |new_nodes| · |E(g)|),其中|E(g)|表示采样图g的边数,其余行的代码时间复杂度为O(1)。算法2 使用最大贪心覆盖方法寻找k个种子节点的时间复杂度为O(k)。综上所述,RIS-S 算法的时间复杂度为O(|E|+|E(g)| · |new_nodes|2+k)。在采样图g中,边数|E(g)|小于整个符号网络Gs中的边数|E|,new_nodes中的节点数也远远小于采样图g中总节点数|V(g)|。贪心算法的时间复杂为O(k·|E|·|V|),|E|和|V|分别表示符号网络Gs的边数和节点个数。在大型社交网络中,|E|和|V|的数值往往很大,所以RIS-S 算法更适用于大型社交网络。
4 实验与结果分析
4.1 实验数据集与实验参数设置
为了验证RIS-S 算法求解符号网络中积极影响力最大化问题的有效性,本文选取了三个真实的符号网络数据集Bitcoinotc、Slashdot 和Epinions 进行了仿真实验。Bitcoinotc是一个比特币交易评估网络,用户可以以信任和不信任关系对其他人进行排名;Slashdot 是一个科技新闻网站,该网站的Slashdot Zoo 功能允许用户标记其他用户为朋友或敌人;Epinions 数据集来源于大众消费者点评网站Epinions.com,网站的用户可以通过查看某个用户的产品评分和评论决定是否信任该用户。这些数据集可以从斯坦福大型网络数据集网站(http://snap.stanford.edu/data)中找到。实验数据集相关参数如表2 所示。表2 中:|V|和|E|分别表示图的节点数、边数;d代表网络直径;E-/E+是负边占比率。
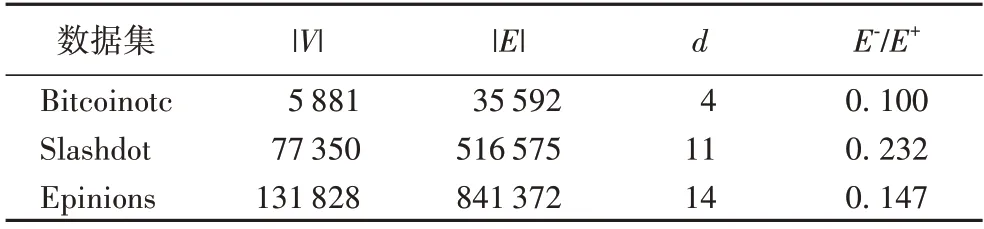
表2 实验数据集相关参数Tab.2 Relevant parameters of experimental datasets
贪心算法并不适用于较大规模的社交网络,所以在实验中,本文选取了Random 算法、POD(Positive Out-Degree)算法、Effective Degree 算法和IMM 算法与RIS-S 算法进行对比。Random 算法[18]是解决影响力最大化问题最常用的算法之一,它从图中随机地选取k个节点作为种子节点。POD 算法[19]是一种启发式算法,它选取图中正出度最大的前k个节点作为种子节点。Effective Degree 算法[20]是有效度算法,节点的正出度数量减去负出度数量为有效度,此算法选择k个有效度最大的节点作为种子节点。IMM 算法[9]是基于反向影响采样思想的代表性算法之一,它在解决影响力最大化问题中有着较好的结果准确性与运行效率。
实验在操作系统为64 位的Windows 10 中进行,CPU 为AMD Ryzen5 2600@3.40 GHz 六核,内存为16 GB,硬盘大小为512 GB,编程环境为Python 3.6。
所有算法都是在IC-P 模型下进行积极影响力计算的,节点激活概率P设置为0.05。在模拟信息传播阶段,实验进行10 000 次蒙特卡洛模拟,取平均值作为各种子集最终的积极影响力范围。为了更符合信息在真实社交网络中的传播规律,最大影响采样深度sample_depth设置为各数据集的网络直径。RIS-S 算法中,近似比参数ε=0.5,错误概率参数l=1,与IMM 算法一致。
4.2 实验结果与分析
实验的对比指标有:积极影响力范围、算法的运行时间和正节点占比率。积极影响力范围和正节点占比率可以表明算法的准确度,而运行时间则可以反映出算法的运行效率。
4.2.1 积极影响力范围
图4 是各算法计算出的种子集在Bitcoinotc 数据集上的积极影响力范围。Bitcoinotc 是相对较小的数据集,由图4 可知,虽然RIS-S 算法在种子个数小于15 时积极影响力范围不如POD 算法和Effective Degree 算法;但当k≥15 时,RIS-S 算法是五种算法中表现最好的。
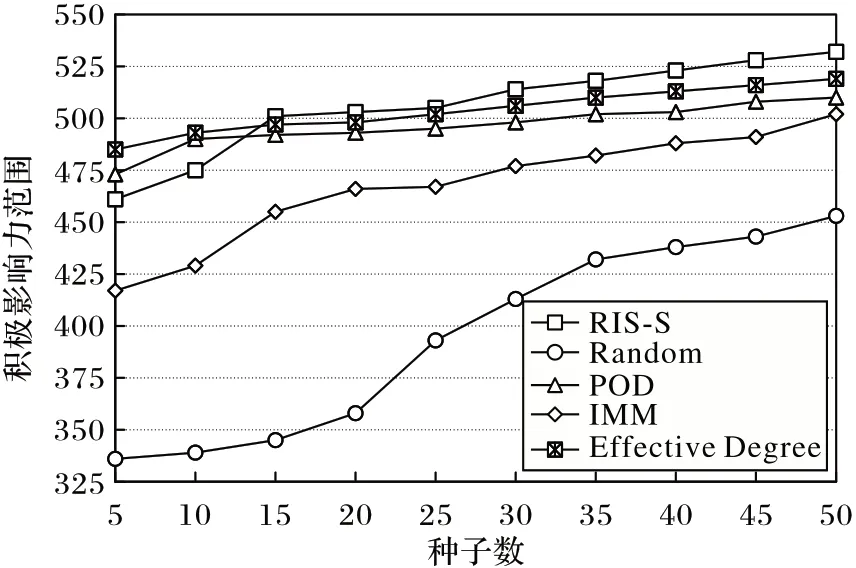
图4 Bitcoinotc数据集上的积极影响力范围Fig.4 Positive influence range on Bitcoinotc dataset
图5 是各种子集在Slashdot 数据集上的积极影响力范围。由图5 可知,Random 算法积极影响力范围在数据集Slashdot 中远远小于其他三种算法;RIS-S 算法积极影响力范围最广,POD 算法次之;Effective Degree 算法与POD 算法表现较为接近;IMM 算法在积极影响力范围上表现不如Effective Degree 算法、POD 算法和RIS-S 算法,但大幅领先于Random 算法。Random 算法在寻找种子时随机性过强,找到的种子质量较差,所以在五种算法中表现出了最糟糕的积极影响力范围。IMM 算法在寻找种子时没有考虑节点间的极性关系,由式(1)可知,在符号网络中,高影响力的节点并不一定拥有较高的积极影响力范围,因此IMM 算法在解决积极影响力问题上与Effective Degree 算法、POD 算法和RIS-S算法有一定的准确度差距。在Slashdot 数据集中,IMM 算法的积极影响力范围比POD 算法平均低23.3%,与RIS-S 算法的平均差距有27.3%。Effective Degree 算法在k=5,10,15 时与POD 算法表现几乎一致,二者总体的积极影响力范围差异较小。RIS-S 算法从种子数k=5 到k=50 时积极影响力范围都优于POD 算法,并且在k=30 时逐步拉开两者之间的积极影响力范围差距,在k=50 时RIS-S 算法比POD 算法高出5.5%的积极影响力范围。
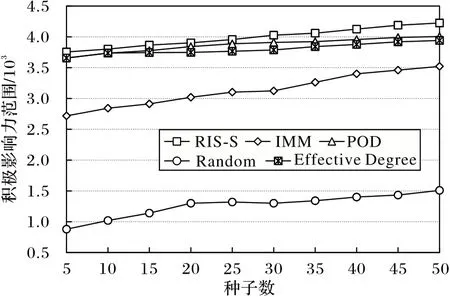
图5 Slashdot数据集上的积极影响力范围Fig.5 Positive influence range on Slashdot dataset
图6 是各种子集在Epinions 数据集上的积极影响力范围。从图6 可看出:面对更加庞大的符号网络,RIS-S 算法在k=50 时积极影响力范围比POD 算法高7.2%,比IMM 算法高20.5%,表现出色,而Random 算法的积极影响力范围最低。Effective Degree 算法依然与POD 算法表现相似。由图5~6 可得知:在Slashdot 和Epinions 中,正出度最大的前15 个节点拥有较少的负边。POD 算法选择正出度最大的节点作为种子节点,仅能保证在第一轮影响传播中被激活的节点处于积极状态,无法保证后续影响传播激活的节点处于积极状态;RIS-S 算法通过考虑符号的反向影响采样技术,生成的反向可达集全部为处于积极状态的节点,所以RIS-S 算法拥有更加优异的积极影响力范围。
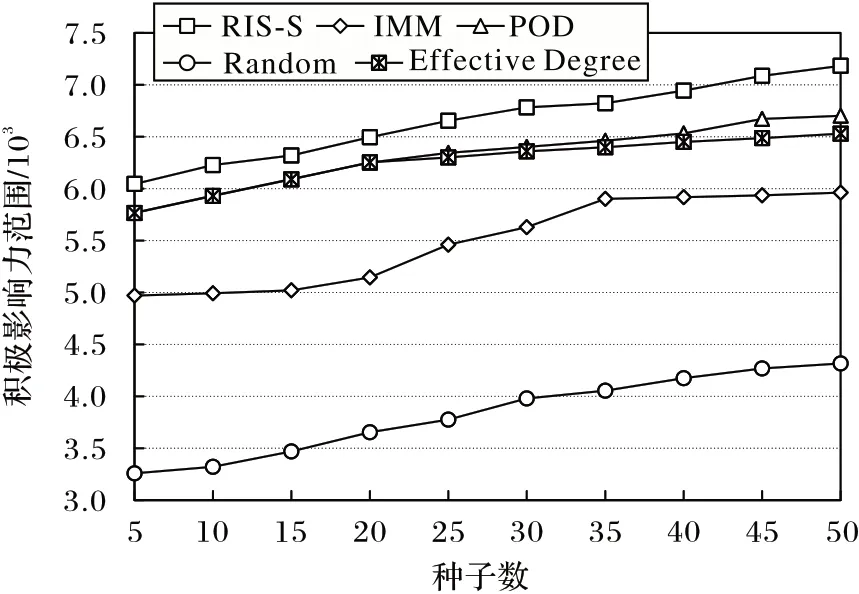
图6 Epinions数据集上的积极影响力范围Fig.6 Positive influence range on Epinions dataset
4.2.2 运行时间
算法的运行时间也是一个重要的性能衡量指标。图7是RIS-S 算法与IMM 算法在Bitcoinotc 数据集上的运行时间。整体上,RIS-S 算法的运行时间比IMM 算法的更短,并且随着种子个数的增加,RIS-S 算法的运行时间优势愈加明显。图8是RIS-S 算法与IMM 算法在Slashdot 数据集中的运行时间。从图8 可看出:RIS-S 算法在拥有更高积极影响力范围的情况下,算法运行时间比IMM 算法更低,在种子个数k=50 时,RIS-S 算法的运行时间比IMM 少35%。RIS-S 算法在生成反向可达集阶段控制了采样的深度,一定程度上减少了反向可达集的冗余,由文献[9]可知,IMM 算法的时间复杂度为O((k+l)(|E|+|V|)lb(|V|/ε2)),而RIS-S 算法的时间复杂度为O(|E|+|E(g)| · |new_nodes|2+k),|E(g)|小于|E|,|new_nodes|也远小于|V|,所以RIS-S 算法相较于IMM 算法更快。图9 是RIS-S 算法与IMM 算法在Epinions 数据集中的时间对比。在k=40,45,50 时,RIS-S 算法的运行时间接近IMM 算法,原因在于Epinions 数据集比Slashdot 数据集网络直径更长,负边占比更低,但总体上,RIS-S 算法的运行效率更加优异。
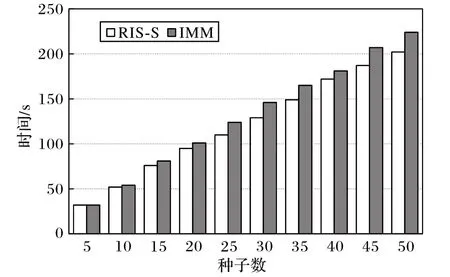
图7 Bitcoinotc数据集上的运行时间Fig.7 Running time on Bitcoinotc dataset
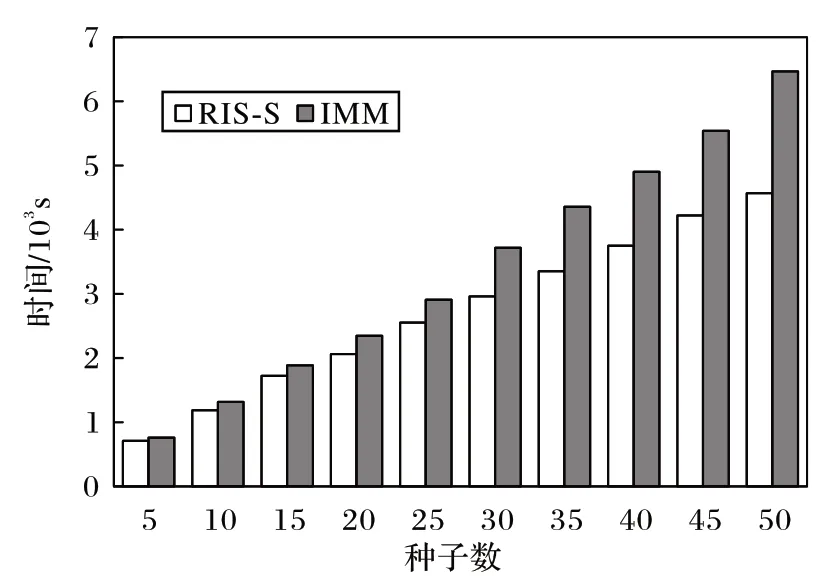
图8 Slashdot数据集上的运行时间Fig.8 Running time on Slashdot dataset
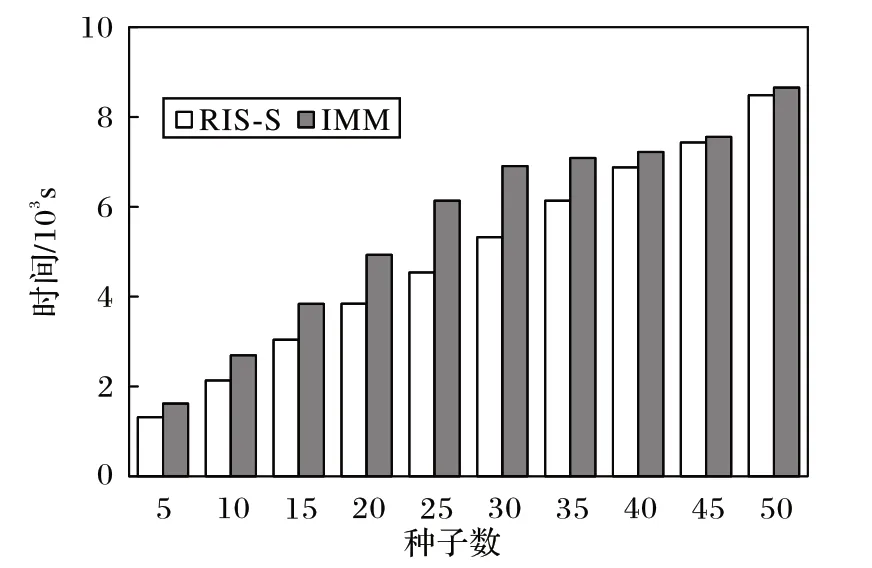
图9 Epinions数据集上的运行时间Fig.9 Running time on Epinions dataset
4.2.3 正节点占比率
正节点占比率可以进一步评估算法在解决积极影响力最大化问题时的准确度,其计算方式为:

其中:|V+|为被激活的正节点数;I(seed)表示最终被激活的节点数;Pr∈[0,1]为正节点占比率,值越接近1,说明此算法找到的种子更加准确。
表3 是各算法在种子数k=50 时的正节点占比率情况。

表3 k=50正节点占比率对比Tab.3 Comparison of positive ratio at k=50
从表3 可看出:RIS-S 算法在三个数据集中的正节点占比率都是五种算法中最高的。由于Bitcoinotc 数据集中正边占比率达到了90%,五种算法在Bitcoinotc 数据集中都有着较高的正节点占比率。在Slashdot 数据集中,RIS-S 的正节点占比率比POD 算法高5.5%,比Effective Degree 算法高6.9%,三者的正节点占比率都超过了70%;与IMM 算法和Random 算法相比,RIS-S 算法优势明显,正节点占比率分别高20.3%和48.1%。在Epinions 数据集中,RIS-S 算法的正节点占比率比表现第二好的POD 算法高9.5%,这说明在更大规模的符号网络中,RIS-S 算法在解决积极影响力最大化问题时更具优势。
5 结语
本文基于IC-P 模型,结合反向影响采样思想提出了一种解决符号网络积极影响力最大化问题的算法RIS-S。实验结果表明RIS-S 算法与基于反向采样思想的代表算法IMM 相比,具有更短的运行时间,在解决积极影响力最大化问题中有着更高的积极影响范围,在病毒式营销场景中有一定的应用价值。文献[21]的研究表明,回声室效应(Echo chamber)和过滤气泡(filter bubbles)问题会使社交网络用户处于相对封闭的社交环境,因此,未来的工作将在RIS-S 算法的基础上融入消极影响力,以解决信息暴露平衡问题。
猜你喜欢
幼儿园(2021年6期)2021-07-28 07:42:14
当代陕西(2021年1期)2021-02-01 07:18:12
考试与评价·高二版(2020年3期)2020-09-10 13:04:38
华人时刊(2019年15期)2019-11-26 00:55:44
小学生学习指导(低年级)(2019年11期)2019-11-25 07:31:48
NBA特刊(2018年14期)2018-08-13 08:51:40
小学生导刊(2017年13期)2017-06-15 20:29:38
人大建设(2017年11期)2017-04-20 08:22:49
中国卫生(2015年8期)2015-11-12 13:15:34
天津科技大学学报(2015年4期)2015-04-16 04:55:11
