
基于深度学习的危险驾驶状态检测预警系统设计
2022-08-24 11:18马晨东罗紫琳
无线互联科技 2022年12期
许 旻,马晨东,罗紫琳
(苏州市职业大学 计算机工程学院,江苏 苏州 215104)
0 引言
随着社会生活水平的不断提高以及汽车数量大幅增加,汽车、公交车、中小型客车作为代步工具被越来越广泛应用于日常生活中,而伴随着交通事故频率也越来越高。交通事故调查统计结果表明,疲劳驾驶或分心驾驶是引发交通事故的主要因素。如果能对驾驶员的驾驶状态进行检测,并对其危险驾驶状态进行事故预警,能有效改善道路的安全性。研究如何提高对驾驶员疲劳或分心特征检测的准确率、快速判断驾驶行为是否处于危险状态,对于交通安全驾驶问题的改善有着重大意义,也是相关领域技术人员需要解决的技术问题。
1 国内外检测危险驾驶方法
目前,国内外检测危险驾驶的方法主要通过对目标特征进行实时检测,通过处理与计算检测数据判断出驾驶人是否处于疲劳或分心驾驶状态。根据检测目标特征不同可以分为3种不同的方案:基于驾驶员生理特征、基于驾驶员行为及面部特征和基于车辆运动特征。
基于驾驶员生理特征的检测方法,主要通过接触式设备与驾驶员身体接触,监测驾驶员的脑电信号、心电信号、肌电信号等生理特征参数,然后进行信号的特征提取与分析,最后将检测到的数据与非危险状态下的数据进行分析与对比,从而判断出驾驶人是否处于疲劳驾驶状态。徐礼胜[1]等提出基于短时心电信号疲劳驾驶检测算法,即采集时长为30 s的短时心电信号序列数据,然后对数据进行预处理,去除掉极端样本数据,利用该序列的时域/频域特征与卷积神经网络对ImageNet数据集训练的特征进行结合,对这些特征分类,用分类结果对驾驶人进行危险驾驶检测。该类于驾驶员生理特征的检测方法准确性、可靠性、精度性相对较高,但是因为要与驾驶人相接触,会给驾驶人带来不便,可能会干扰到驾驶人的正常操作。
基于驾驶人的行为及面部特征的检测方法主要是通过计算机视觉识别技术对获取的驾驶人图像进行处理,提取驾驶人的头部位置、眼睛眨眼频率以及嘴巴等特征,并对获得的这些特征信息进行处理,最后判断出驾驶人是否处于疲劳驾驶状态。通过Violla-Jones算法[2]检测面部表情和眼睛位置,再通过眼睛追踪技术,采集驾驶人的眼睛眨眼的持续时间、眨眼的频率等特征来完成检测;这类基于驾驶人的行为及面部特征的检测方法是利用摄像头或红外热成像技术来获取检测数据,然后再提取出目标特征,进而进行危险判断。这种检测方法易受到光线、姿态的影响,检测效率有待提高。
驾驶行为是影响汽车安全驾驶的主要因素,很大程度上也能体现驾驶员的精神状态。当驾驶人处于危险驾驶状态时,应激反应会有延迟,对车辆的控制能力降低,操作水平也会下降,因此危险驾驶状态时所驾驶车辆的行为特征与正常驾驶时的行为特征相比是有差异的。Wang[3]等提出的疲劳驾驶检测算法是对实车的方向盘操作特征进行提取、分析,提取实验数据在时域以及频域上的指标,最后对指标处理并设计SVM分类器,从而推导出疲劳驾驶检测算法。这类基于车辆行为特征的危险驾驶检测方法,通过非接触式的检测设备,对车辆的行为特征进行提取,所需成本低、性价比高,但检测需与车辆型号、道路实际情况以及个人驾驶习惯等因素相关联,因此准确率不够高。
综上所述,本文将针对人脸特征和驾驶状态识别与检测的相关算法模型,进行重新优化设计以及多技术配合,达到总体算法最优目的。
2 系统算法流程及功能模块
系统基于车载摄像头采集驾驶员脸部特征及人体行为,采用局部区域多特征和深度学习特征融合的算法进行分析,通过判断出来的驾驶员的疲劳或分心驾驶状态给予驾驶员相应的预警信息,并以语音提醒方式引导驾驶员停止危险行驶状态。算法中通过摄像头获取视频帧图片,根据视频流采集的数据,对人脸检测和定位后,对人脸关键点检测,再通过头部3D姿态估计、眼睛和嘴巴部位抠图,根据业务规则和状态分类网络设计来判定是否疲劳驾驶还是分心驾驶。算法流程如图1所示。
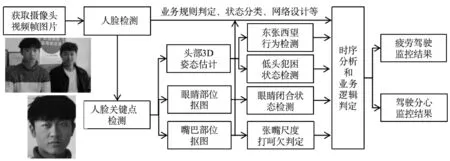
图1 危险驾驶检测算法流程
根据以上算法,系统基本实现对人眼闭合、东张西望、低头犯困、打哈欠4种驾驶状态的检测与识别功能。当发生疲劳和分心行为时,右边参数会有相应脉冲,可通过参数的变化检测到是否有疲劳和分心行为,当这些行为达到一定频率时,将语音预警。同时本系统可以实现本地化离线部署,更能按照驾驶员生理特征,对检测阈值提前做好参数调整,以更精准的方式检测驾驶过程中是否发生危险驾驶行为。调参界面如图2所示。

图2 调参界面
3 关键技术研究
危险驾驶状态检测预警系统主要包括以下模块:人脸检测、人脸关键点检测、人眼闭合状态识别、东张西望状态识别、低头犯困状态识别、驾驶行为判断、语音预警。涉及人脸对齐校正、头部姿态模拟、局部区域多特征和深度学习特征融合的人脸状态检测算法、增强学习决策器(分类和检测模型)以及各种深度学习算法小型化的加速和压缩算法等关键技术。
3.1 人脸检测模块
MTCNN算法是一种基于深度学习的完成人脸检测和人脸对齐的多任务神经网络模型,它是由一个3层网络(P-Net、R-Net、O-Net)组成的卷积网络结构[4]。在该模块中,使用改进的MTCNN算法[5]对IMG进行人脸检测:在预先训练好的人脸检测器中,输入待识别无深度信息图片IMG,若IMG中没有检测到人脸,则返回去输入下一幅待识别的图像;若从IMG中检测到人脸,则标记出其人脸框定位点的横纵坐标、人脸框的长宽,以及人脸关键特征点位置,将人脸框截取出来,最终得到人脸。通过改进MTCNN算法使得其脱离服务器端的卷积神经网络架构,重新设计的基于C++相关库和Armadillo矩阵加速库,可以更加快速有效且小型化地实现人脸关键点检测。另外,可以对阈值也进行了适当的提高,这将大幅度减少每一步中候选框的数量,减少大量计算量,同时不会引起过大的误差。
3.2 人脸关键点检测模块
级联回归方法是通过回归关键点位置处提取的特征逐步逼近真实关键点位置,可以很好地实现人脸对齐结果[6]。SDM(Supervised Descent Method[7])监督下降方法算法是基于关键点位置索引特征[8],使用级联线性回归来输出关键点位置,模型简单高效且易于理解,是众多级联回归方法中最有效的方法之一。
在该模块中,调用预先训练好的人脸关键点检测模型对所述人脸区域进行检测,得到人脸关键点数据,通过提取SIFT特征,使用SDM监督梯度下降的方法来求解非线性最小二乘问题,以提高人脸关键点检测的对齐误差校正。
3.3 人眼闭合状态识别模块
人眼闭合状态,很多时候受限于摄像头拍摄视频图片的质量,本模块自定义了某种小型N层设计的深度学习网络,使用经过多次测试和改进的损失函数在大量数据的训练下识别效果明显,不再受限于人脸关键点检测的比例判定以及摄像头拍摄视频图像的质量。
3.4 东张西望状态识别模块
本模块基于人脸检测、人脸关键点检测和三维透视变换技术,经过处理得到人脸平面和头部偏转的角度等头部姿态等信息,进而能够实时判断驾驶中东张西望等分心动作。
3.5 低头犯困状态识别模块
本模块在车载资源受限的环境下,对于低头行为检测这样的分类和检测深度学习网络的训练,设计和优化了一种针对近红外图像的特定模型,采用多分类深度学习训练的网络,构建局部区域多特征融合的目标检测和分类模型,使得在较小的模型规模下,获得更高的识别精度。构建的模型中主要使用深度学习模型的小型化技术,即压缩技术和加速技术;压缩的方法重点在于操作全连接层,加速的方法重点在于操作卷积层。模型压缩的主要思想是减少参数,减少比特数,一般模型压缩过程中也会加速模型,目标就是让模型在存储上变得更小、运算上速度更快。
3.6 驾驶行为判断模块
在该模块中,根据头部姿态估计模块,将所述人脸区域图像中的人脸进行对齐,基于头部姿态估计算法和所述人脸关键点数据计算对齐后的人脸区域图像中头部姿态角;根据人脸状态检测模块,调用预先构建的人脸状态检测模型对所述人脸区域图像进行分析,得到人眼闭合状态特征和嘴部动作特征,根据以上特征生成危险驾驶行为判决结果。使用局部区域多特征向量与深度学习特征融合的人脸状态检测方法,和基于Q-learning增强学习决策器对驾驶状态进行分类和检测,大大提高了识别的速度和准确率。
3.7 语音预警模块
本模块通过系统集成的语音模块,利用先进的自然语言处理技术、语音建模,使用大量的语音数据库训练,生成智能语音模型,对监控对象进行识别、判断,并在检测到有疲劳或分心驾驶的条件下,把系统发出的指令生成报警声提示驾驶员,实现车载设备和驾驶员之间的良好交互性。
4 结语
系统通过大量数据集(CEW 数据集、Yaw DD 数据集)训练,对人眼闭合、东张西望、低头犯困、打哈欠4种行为检测并不断调整阈值精度,对比现有的危险驾驶状态检测算法,识别精度高、检测速度快。未来将通过大数据获得更多的驾驶员行车状态,不断完善算法、强化算法,不断加强它的精准度来保持行业领先水平,为行车安全添加保障,使其满足更广阔的需求。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
今日农业(2021年8期)2021-11-28
少儿美术·书法版(2021年9期)2021-10-20
动漫星空(2018年9期)2018-10-26
公民与法治(2016年4期)2016-05-17
发明与创新(2015年33期)2015-02-27
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
军事历史(1985年2期)1985-01-18
