
面向图像语义分割的生成对抗网络模型
2022-08-24 11:18窦育民徐广伟黄晶晶蔡凡凡
无线互联科技 2022年12期
窦育民,徐广伟,黄晶晶,蔡凡凡
(1.新乡医学院 管理学院,河南 新乡 453000;2.中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引言
随着多媒体和网络技术的快速发展,越来越多的信息以图像的形式呈现并广泛应用于医学、通信、工农业生产、航天、教育、军事等多个领域。在智能空间视域下有效地组织、查询与浏览大规模的图像资源已成为迫切需要解决的问题。智能空间可看作是物理世界和信息空间的融合,目的是建立一个以人为中心的计算和通信能力的空间, 让计算机参与从未涉及的计算行为活动, 让用户能与计算机系统发生交互,随时随地获得人性化服务[1-3]。
图像语义标注是基于内容图像检索技术的关键环节[4],是一个将现代计算机和机器学习技术应用于传统人文研究的新型跨学科研究领域,基于图像的机器学习方法为传统人文社科研究提供新的研究思路[4-7]。其中大数据的科学发展对人文科学研究有积极的推动作用,现有统计模式识别方法可以发现海量数据中的潜在信息,在总结模式规律方面有出色表现。因此,近年来数字人文研究逐渐成为信息科学、人文社会科学、人工智能等众多学科的研究热点。
语义分割是当今计算机视觉领域的关键问题之一。宏观上,语义分割是一项高层次的任务,为实现场景的完整理解铺平道路。场景理解是一个核心的计算机视觉问题,其中包括自动驾驶、机器人的自动感知、智能监控、人机交互、增强现实等。近年来,随着深度学习的普及,许多语义分割问题采用深层次的结构解决,最常见的是卷积神经网络,在精度上远超其他方法。
语义分割是一项视觉场景理解任务,即一个密集的标记问题,目的是预测输入图像中每个像素所属的类别标签。卷积神经网络(CNN)方法是现今最流行的方法,在2009年和2013年,Grangier[9]等人与Farabet[10]等人分别利用CNN完成了这项任务。遵循不同的CNN卷积网络架构,其共同特点是把图像分割任务转化为像素标签变量的分类任务。
场景理解问题的关键是对图像进行自动语义标注。语义标注的实质是通过对图像视觉特征的分析提取高层语义用于表示图像的含义,从而在图像低层特征和高层语义之间建立联系,解决低层特征和高层语义间的“鸿沟”问题。其主要思想是从大量图像样本中自动学习语义概念模型,并以此标注新的图像。
1 GAN的基础架构的阐述
生成对抗网络(Generative Adversarial Networks,GAN)是一种生成式模型,模型学习的是联合概率分布P(X,Y) ,学习任务是得到属性为X且类别为Y时的联合概率。根据零和博弈原理,一方的收益必然意味着另一方的损失,博弈各方的收益和损失相加总和永远为“零”,双方不存在合作的可能。在零和博弈中,把目标设为让对方的最大收益最小化,以使己方达到最优解。
1.1 GAN的条件形式的分割框架
利用一个基于生成对抗网络的条件生成式模型[11-13],在原模型基础上,输入额外的数据作为条件,修改生成器和判别器。在图像分割数据集上,以分割掩模图类别标签为条件,用来场景区域的多类别学习,在输入图像相应区域生成图像场景理解的描述标签。
Ez~pz(z)[log(1-D(G(z|y)))]
(1)
其中,D:判别器;G:生成器;z:随机噪声;data:训练数据;y:条件输入。
条件GAN[12-13]在GAN的基础上增加条件进行的对抗模型。条件GAN的模型结构包括两个神经网络,分别是生成器Generator和判别器Discriminator,Discriminator通过对Generator的评判提升模型的鉴别能力,Generator通过对Discriminator的欺骗提升模型的生成能力。其中生成器的目标是学习样本的数据分布,从而具备生成欺骗判别器样本的能力;判别器的目标是判断输入样本真伪的概率。这里使用生成器和判别器都由多层感知机实现,整个网络可以用交替优化生成器和判别器的方式优化目标函数,通过反向传播算法获得目标函数更新梯度。
1.2 模型总览
在生成器和判别器中分别输入相同条件y,CGAN的网络相对于原始GAN网络没有变化。随机变量通过输入生成器网络产生分布,利用判别器与真实分布进行不断比较,最终得到与真实分布相似的分布[11-13]。
1.2.1 生成器网络
U-net 网络结构最早由 Ronneberger[10]等发表于2015年的MICCAI,逐渐成为大多数医疗影像语义分割的研究基础。U-net网络使用全卷积网络,是一个端到端的分割网络,包括收缩路径和扩张路径两部分,并且为了防止梯度消失和梯度爆炸引入了跳跃连接的方法(见图1)。卷积过程中为了减少输出的离群点,卷积后还加入了BatchNormal,并激活ReLU。整个过程通过图像特征编码和解码完成像素级图像分割任务。
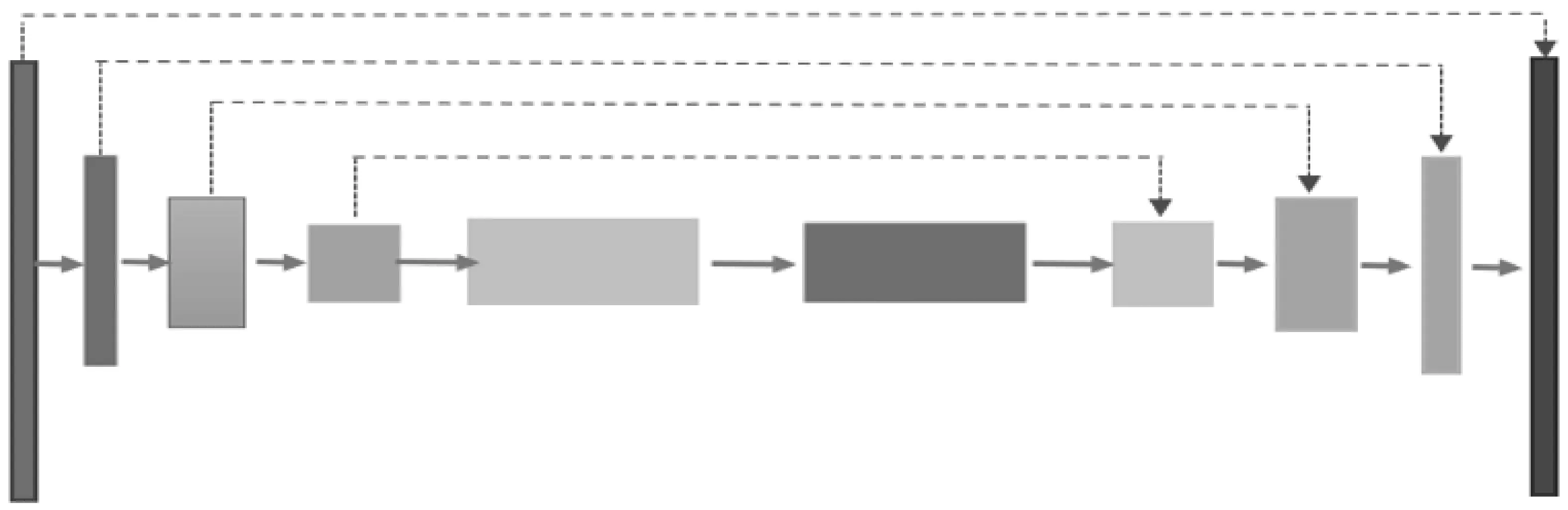
图1 Unet网络
在模型收缩路径的编码模块中,使用可分离卷积和点卷积结构替换两层卷积层[11],由于该结构采用的双分支结构,融合了不同深度的特征信息,因此提取特征比简单地叠加卷积层更有效。在下采样阶段采用步长为2的卷积层代替池化层,减少了下采样过程中信息的损失。在模型对编码后的特征图扩张路径进行的解码模块中,上采样操作使用反卷积,结合跳跃连接的特征图可有效减少上采样过程中的信息损失。
生成器是U型网络,扩张路径通过跳跃连接串联对应层进行,通过随机噪声作为输入训练成生成器模型。
1.2.2 判别器网络
判别器使用深度神经网络,可根据需要设计网络深度,这里设置为5次卷积(见图2)。第1层输入图像为自然图像和掩膜图像,分别为3通道,叠加送入网络;前4次卷积每一层步长stride设置为 2,padding 为1,第5次卷积前再在特征图左面和上面分别增加一行和一列,再进行一次卷积。除了第1层没进行规范化外,后面每层对特征数据进行了规范化操作(见表1),实例规范化函数处理过后,再用LeakyRelu激活函数[12-13]。

表1 判别器网络模型参数
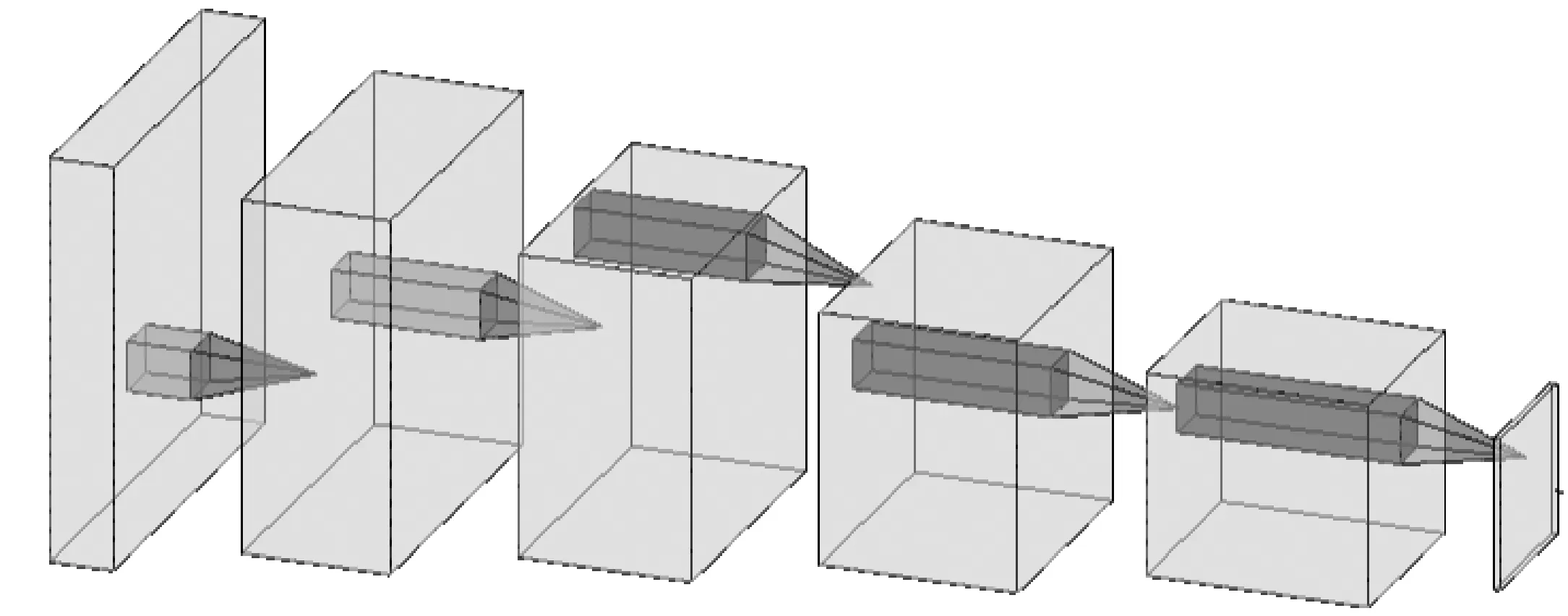
图2 判别器网络
由于条件GAN捕获的是图像的结构信息,在目标函数后增加正则项L1函数捕获图像的低频信息进行补充。
L1(G)=Ex,y,z[‖y-G(x,z)‖1]
(2)
前4次卷积每一层步长stride设置为 2,padding 为1,第5次卷积前再在特征图左面和上面分别增加1行和1列,然后再进行1次卷积。
2 实验设计与分析
本实验平台为windows10+pytorch3.5,CPU:Intel®(R)i7-6700HQ@2.60 GHz;内存大 小: 16 GB;GPU:NVIDIA GeForce GTX960M;显存大小:4 GB。本实验对图像语义分割公共数据集ICCV2009[16]进行实验验证,包括715张自然图像,分别取自LabelMe,MSRC,PASCALVOC,and Geometric Context,与自然图像匹配的标签文本文件在对应区域的划分种类标签。通过图像像素矩阵形式表示语义类,包括天空、树、公路、水、建筑、山,前景目标用自然数分别表示,如人、动物、汽车等,负数表示未知。
本实验使用其中的*.regions.txt类文件,文件内数字表示图像中语义类每个像素的矩阵分割掩膜图。模型整体训练模型分为判别器和生成器,训练学习中,这里把*.regions.txt转换为.img进行。
数据准备:因为数据集的标签掩膜文件以.txt形式存在,利用以下算法把将其转换为图像文件。
转换算法如下:
im = Image.new("RGB",(x,y)) # 新建图像文件缓冲区
file = open(files[k])# 打开标签文本文件
for i in range(0,x):
读取文件第i行像素数字元素
for j in range(0,y):
根据第j列像素值,赋予对应的颜色
写入文件缓冲区,保存生成一张标签掩膜图像文件。
为了增强模型的泛化性能,减少模型训练学习中的过拟合问题,同时提升训练数据的数据量和多样性,采用常规方法对输入模型的批量训练数据进行数据增强。其中有随机裁剪图像,同时以图像x轴和y轴的 0.2倍大小、0.7和0.3比率进行随机平移、缩放图像。因需输入图像使用相同的数据增强方式,所以对标签也需做相同的数据增强。
参数设置:训练使用256×256的自然场景图像和标签掩膜图,设置120个 epochs,平滑系数lr为0.000 2。在训练开始时,G性能较差,D(G(z))接近0,此时:log(1-D(G(z)))的梯度值较小,log(D(G(z)))的梯度值较大,把G的目标改为最大化logD(G(z)),在早期学习中能提供更强的梯度。
如图3所示,第1和第4行为自然场景图像,第2和5行为GAN方法预测的语义分割图,不同颜色代表不同的对象类,第3和第6行为样本给出的真值掩膜图。可看出,预测图基本能给出图像场景的区域位置和语义类别,可应用在一些有类似样本图像的语义标注中。

图3 第1,4行实景,第2,5行语义分割预测,第3,6行掩膜
3 结语
现代的影像应用需自动推理相关知识或语义。语义分割作为人工智能感知系统的核心问题,对场景理解的重要性日渐突出。自然场景手工标注相当费时,商业成本高。因此,利用CGAN方法进行自动化的语义分割具有广阔的应用前景。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
制造技术与机床(2017年10期)2017-11-28
科技资讯(2016年21期)2016-05-30
现代语文(2016年21期)2016-05-25
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
