
Amodified YOLOv4 detection method for a vision-based underwater garbage cleaning robot*&
2022-08-24 08:46:54ManjunTIANXialiLIShihanKONGLichengWUJunzhiYU
Manjun TIAN,Xiali LI,Shihan KONG,Licheng WU,Junzhi YU,4
1First Research Institute of the Ministry of Public Security of PRC,Beijing 100048,China
2School of Information Engineering,Minzu University of China,Beijing 100081,China
3Department of Advanced Manufacturing and Robotics,College of Engineering,Peking University,Beijing 100871,China
4State Key Laboratory of Management and Control for Complex Systems,Institute of Automation,Chinese Academy of Sciences,Beijing 100190,China
E-mail:tianmanjun2018@163.com;xiaer_li@163.com;kongshihan@pku.edu.cn;wulicheng@tsinghua.edu.cn;junzhi.yu@ia.ac.cn
Abstract:To tackle the problem of aquatic environment pollution,a vision-based autonomous underwater garbage cleaning robot has been developed in our laboratory.We propose a garbage detection method based on a modified YOLOv4,allowing high-speed and high-precision object detection.Specifically,the YOLOv4 algorithm is chosen as a basic neural network framework to perform object detection.With the purpose of further improvement on the detection accuracy,YOLOv4 is transformed into a four-scale detection method.To improve the detection speed,model pruning is applied to the new model.By virtue of the improved detection methods,the robot can collect garbage autonomously.The detection speed is up to 66.67 frames/s with a mean average precision(mAP)of 95.099%,and experimental results demonstrate that both the detection speed and the accuracy of the improved YOLOv4 are excellent.
Key words:Object detection;Aquatic environment;Garbage cleaning robot;Modified YOLOv4
1 Introduction
Polluted water causes 1.7 million deaths from curable diseases every year.It is also conservatively estimated that a large amount of wetland will be lost every year,and that wetland loss is equivalent to the value created by 800 000 hectares of wetland.The poor state of the marine environment is directly or indirectly affecting about 275 million people’s access to cheap protein(i.e.,fish),and will also cause 3.1 billion people around the world to be unable to obtain 20%of their supply of animal protein.In addition,it will cause serious damage to the global tourism and fishing industries(Ekins and Gupta,2019).In particular,the pollution of plastic waste is quite severe.Due to the extremely slow degradation,plastics have become ubiquitous and have been associated with marine health impacts such as entanglement,ingestion,potential dispersal of invasive species and toxicity,and contamination through trophic levels(Ostle et al.,2019). The ocean is suffering from increasing pollution,especially from plastics;eight million tons of plastic products enter the ocean every year,equivalent to a truckload of plastic garbage being dumped into the ocean every minute(Jambeck et al.,2015).According to a recent research report released by the marine conservation organization Oceans Asia,due to the sudden coronavirus outbreak,at least 1.56 billion masks were discarded into the ocean in 2020.Most of the masks are disposable and take 400 to 500 years to degrade in the ocean.They may carry germs,and are“hotbeds”for germs to multiply,posing a potential threat to the survival of marine life.Therefore,it is urgent to protect water resources.
In recent years,with the gradual optimization of control technology and the continuous improvement in software and hardware performance,intelligent robot research has become a research hotspot,and the development of intelligent robots has advanced by leaps and bounds(Albitar et al.,2016;Laschi et al.,2016;Mahler et al.,2016,2017,2018,2019;Xu et al.,2017;Bai et al.,2018;Prabakaran et al.,2018;Kim et al.,2019;Li CY et al.,2019).In this context,an intelligent robotic platform has been developed in our laboratory to clean up underwater garbage.
Robotic garbage cleaning can improve work efficiency,reduce labor,maintain safety,and enhance reliability.The robot’s main task is to detect,capture,and collect objects.The detection algorithm is indispensable when the robot works to discover,approach,and collect targets.A superior detection method can provide the robot with real-time and reliable target information and assist the robot in completing various tasks.
Object detection includes two primary tasks,i.e.,the classification and positioning of targets,which are two most basic and challenging research topics in the field of computer vision. Recently,with the advancement and development of computer science and technology,object detection has been widely implemented in areas such as intelligent surveillance(Fu et al.,2019),intelligent transportation(Mhalla et al.,2019),intelligent agriculture(Horng et al.,2020),military(Astapov et al.,2014),and medical fields(Tschandl,2020).
With respect to object detection,accuracy and speed are the two most important indicators(Pu et al.,2021).Specifically,when the target is moving at a high speed or the application scene is complex and changeable,the speed and accuracy of the object detection method will face huge challenges.Among traditional object detection algorithms,histogram of oriented gradient(HOG)(Dalal and Triggs,2005)uses a histogram to count the edges of objects,and performs satisfactorily when expressing features.Local binary pattern(LBP)(Ojala et al.,2002)is good at expressing object texture information.Harr(Whitehill and Omlin,2006)can rapidly extract features,and is widely applied due to its strong ability to express object edge information.Scale invariant feature transform(SIFT)(Lowe,2004)is a local image feature that is unaffected by rotation,scaling,and brightness changes,and is robust in viewing angle changes,affine transformations,and noise.In 2001,Viola’s cascade+Harr scheme achieved outstanding results in face detection(Viola and Jones,2001).The deformable part module(DPM)is also a popular detector.However,the performance of DPM is ordinary,and it cannot adapt to images with sharp rotations.Thus,its stability and robustness are inadequate. In addition,the workload is relatively heavy(Felzenszwalb et al.,2008).Therefore,traditional methods have insufficient capability of feature extraction,which results in limited accuracy.Manual feature design is very troublesome and laborious.
The emergence of the convolutional neural network(CNN)solves the problems of the traditional object detection methods.It uses the convolution operation to extract target information characteristics,which significantly improves the accuracy of object detection.With the improvement of computing power in recent years,the development of graphics processing units(GPUs),and the maturity of big data technology,deep neural networks based on CNNs have been developed in many fields(Choi,2018;Hannun et al.,2019;Fei et al.,2020;Song et al.,2020;Hussain et al.,2021). For instance,in the ecotoxicology field,the deep learning method is used to train a predictive model that can support hazard assessment and eventually the design of safer engineered nanomaterials(ENMs)(Karatzas et al.,2020).In the field of astronomy,a class of advanced machine learning techniques has been applied to autonomously confirm and classify potential meteor tracks in video imagery.Deep learning has been shown to perform remarkably well,even surpassing the human.Note that it might supplant human visual inspection and review in meteor imagery collection tasks(Gural,2019).
Since 2014, the region-based CNN (RCNN)(Girshick et al.,2014;Girshick,2015;Ren et al.,2015)series of networks have achieved unprecedented results in speed and accuracy.All of them divide object detection into two stages called the region proposal network(RPN)and object classification.However,the RPN branch in the network causes the computation to be too large to meet the needs of high-speed detection.
To solve the problem of the two-stage network being relatively slow,researchers proposed single-stage networks,such as the YOLO series network(Redmon et al.,2016;Redmon and Farhadi,2017,2018;Bochkovskiy et al.,2020;Hsu and Lin,2020)and single shot multibox detector(SSD)(Liu W et al.,2016;Ming et al.,2022).The single-stage network merges the location problem and the classification problem into a regression problem.The target’s position information and category information can be directly obtained in the output layer,which significantly improves the detection speed.Notably,YOLOv3 was compared with Faster R-CNN and SSD(Benjdira et al.,2019;Park et al.,2019),and the results showed that YOLOv3 is superior in both speed and accuracy.YOLOv4 is improved especially with respect to speed and accuracy as compared to YOLOv3.Among the YOLO series networks,YOLOv4 is particularly outstanding in terms of speed and accuracy,and the YOLOv4 algorithm is therefore adopted in our work as the basic detection algorithm.As an extension of our previous work(Tian et al.,2021),this paper adds a new architecture of YOLOv4 with four scales to improve the detection accuracy,a more detailed analysis of the underwater object detection experiments,and a robotic grasping application case.
The primary contributions of this paper are as follows:
1.To better achieve high-precision target detection,YOLOv4 is converted into a four-scale detection network,from 13,26,and 52 to 13,26,52,and 104.Thanks to this improvement,targets in various sizes can be better considered.
2.Because the robot has higher requirements for real-time detection,the YOLOv4 model is pruned to reduce a lot of unnecessary calculations. Finally,because the weight file is only 9.455%of the original weight file,the frame rate can reach 66.67 frames/s and the mean average precision(mAP)is 95.099%.
2 Underwater garbage cleaning robot
Traditional underwater garbage cleanup relies mainly on manual salvage,which is time-consuming and labor-intensive.Workers need to return to the water surface to rest and change equipment regularly.Furthermore,due to the perilous underwater environment,workers may be attacked by aggressive marine organisms and may be hooked by corals.Working in water with chemical pollution or radioactive materials may affect workers’health.In this work,we design an underwater garbage collection robot that can independently identify and search for underwater garbage targets based on a vision system,accurately locate,and finally approach and capture targets.
In recent years,robots have become more and more mature,and their functions have been improved continuously.For example,a robot has been designed that efficiently and autonomously captures garbage on the water surface(Li XL et al.,2020;Kong et al.,2021).With the increasing awareness of environmental protection,target detection for underwater environments has also become a research hotspot(Valdenegro-Toro,2019;Hong et al.,2020).
Our underwater garbage cleaning robot is illustrated in Fig.1.The robot has a binocular camera to achieve object detection and position measurement.Four propellers are installed at its four bottom corners to assist the robot in moving forward,backward,left,and right.Two propellers installed on the left and right sides control the robot’s motion in heave,and depth-keeping movement can be achieved by controlling these two propellers.Control of these six propellers allows the robot to realize flexible movements.There is a manipulator at the front of the robot for grasping the target.

Fig.1 Illustration of the developed vision-based garbage capture robot
3 Underwater object detection
3.1 Underwater garbage dataset
A survey by the World Wildlife Fund(WWF)shows that nearly one million tons of worn-out fishing nets are discarded and left in the ocean every year.Almost all of these fishing nets are made of non-degradable plastic,and will remain in the ocean for hundreds of years.Marine organisms are often entwined in fishing nets,which makes it impossible to move freely for food,and eventually leads to entrapment and death.Every year,countless whales,sea turtles,and dolphins die from plastic bags or plastic fragments,and the number is increasing year by year.It is not uncommon for marine creatures to be killed by accidentally eating a large number of plastic bags.During dissection,a large amount of non-degradable plastic waste was found in the stomachs of dead marine life.As a result,the populations of many rare marine species are seriously threatened.
In our work,the main targets to be detected include plastic bags and damaged fishing nets underwater(Fig.2).Table 1 shows the specific confgiuration of the proposed dataset.Our work includes 6600 images:the training set consists of 6200 images and the other 400 pieces are used as the test set.The images in the dataset were taken mainly by a camera in a real underwater environment from different viewing angles and moments,taking into consideration different illumination conditions and relative orientations between the robot and targets.The brightness and clarity of some images have been adjusted to simulate different water quality environments.There are many obstacles in the underwater environment,and the reason for detecting stones in our work is to realize the obstacle avoidance operation of the robot. The images are labeled with LabelImg,and the target in the image is enclosed in a rectangular box.The coordinate information(the upper left and lower right corners)and object box category information are recorded in an XML file.

Fig.2 Dataset of underwater garbage:(a)from different times and clarity with various conditions of brightness,to better simulate real environments;(b)from different view angles,to imitate the robot approaching the target
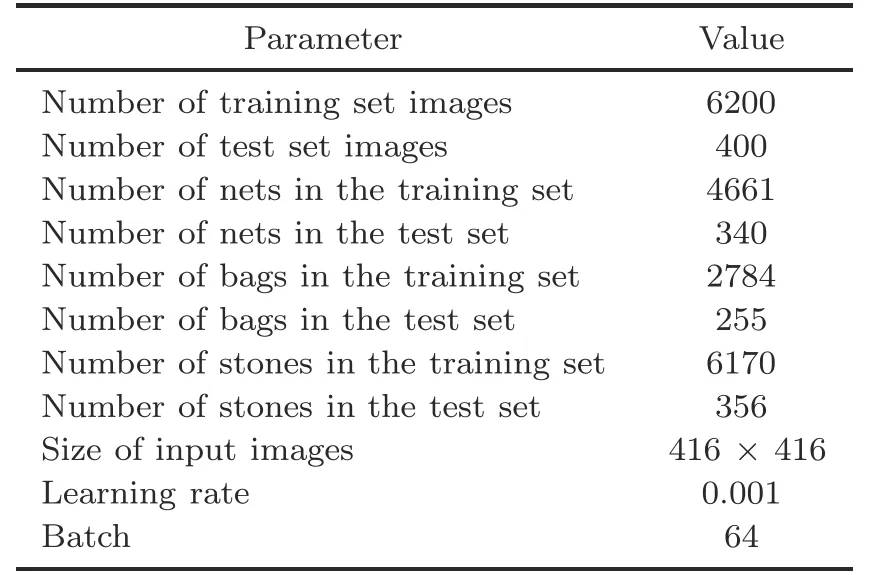
Table 1 Experimental parameters*
3.2 Underwater object detection based on YOLOv4
The YOLO series network is a typical singlestage detection algorithm.It extracts image features through a large number of CNN-based layers;the target’s position information and category information are directly returned eventually,which improves the detection accuracy and significantly increases the detection speed.
The overall network structure of YOLOv4 is very similar to that of YOLOv3.However,YOLOv4 includes some excellent technologies to strike a balance of detection speed and accuracy. The network structure is shown in Fig.3a.YOLOv4 can realize multi-scale and multi-size object detection.It will uniformly modify the size of any input image to an image of 416×416×3. After the image passes through the YOLOv4 network,feature maps will be generated in three sizes in the output layer:13×13×[3×(4+1+3)],26×26×[3×(4+1+3)],and 52×52×[3×(4+1+3)].Note that 13,26,and 52 are the width and height of the feature maps.The depth of the feature maps,[3×(4+1+3)],indicates that there are three anchor boxes with different sizes to predict objects of different sizes.The“4”represents the bounding box coordinate information and“1”is the object confidence information;if the bounding box contains the target,its value is close to 1;otherwise,it is close to 0.The last“3”is the category number of the target.The YOLOv4 extraction network is CSPDarknet53. Compared with Darknet53,CSPDarknet53 can extract more image features.The cross stage partial connections(CSP)(Wang et al.,2020)structure can reduce the amount of computation and enhance the gradient,strengthening the learning ability of the CNN and reducing the computational cost and memory consumption.In addition,it inserts the spatial pyramid pooling(SPP)(He et al.,2015)module between the main network and the final output layer,which effectively increases the feature acceptance range of the backbone network,significantly separates the most important context features,and greatly expands the receptive field.The network also introduces the feature pyramid network(FPN)(Lin et al.,2017)and pyramid attention network(PAN)(Li HP et al.,2018)structures. The FPN layer conveys strong semantic information by upsampling from top to bottom,while PAN conveys strong location features by downsampling from bottom to top.Consequently,feature fusion of different detection layers from different backbone layers is realized and further improves feature extraction capabilities. Furthermore,weighted residual connections(WRC),CSP,cross mini batch normalization(CmBN),and selfadversarial training(SAT)have been added to the network.
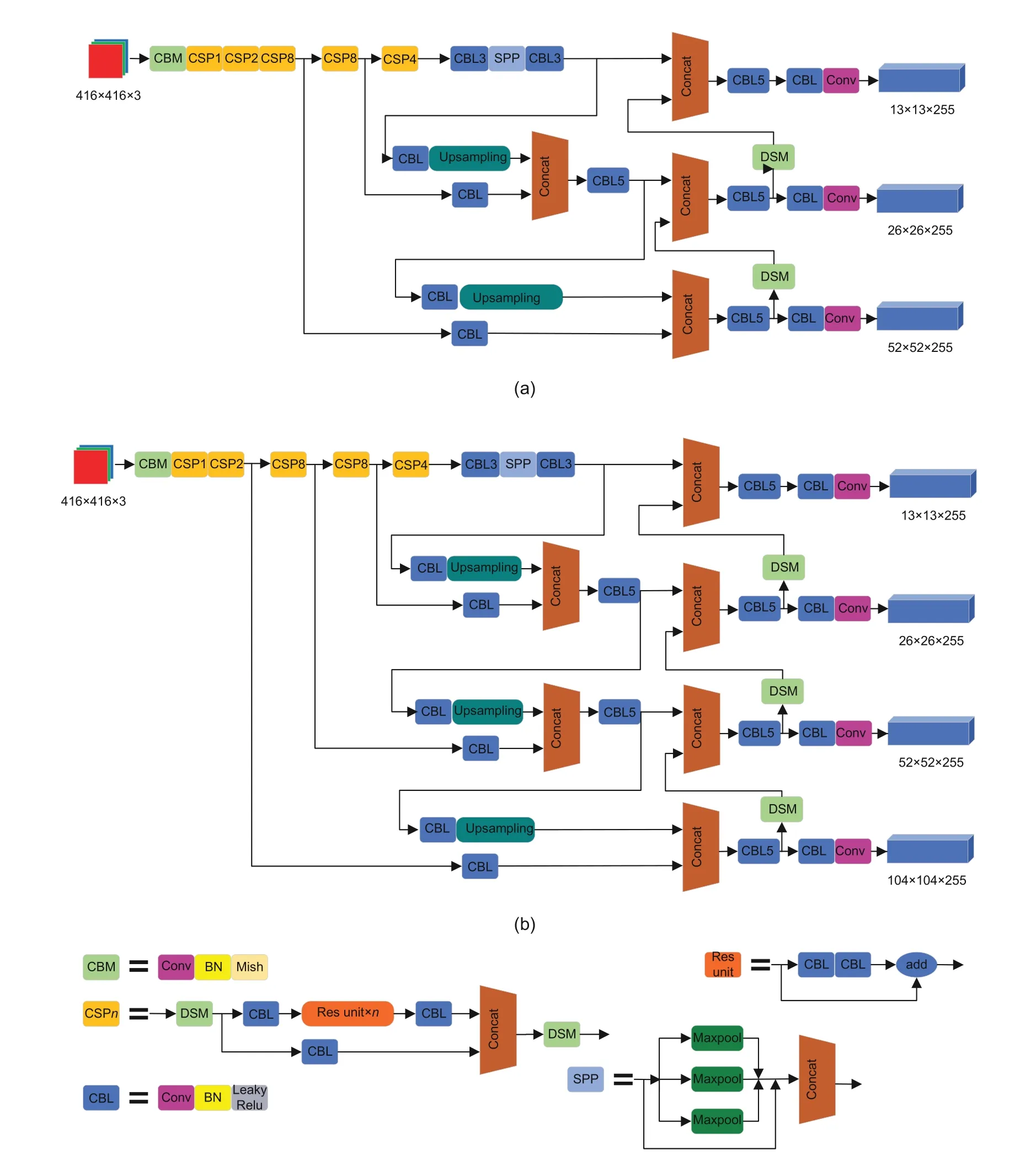
Fig.3 Network architecture:(a)original YOLOv4;(b)4S-YOLOv4
The activation function of YOLOv4 is also different from that of YOLOv3,that is,
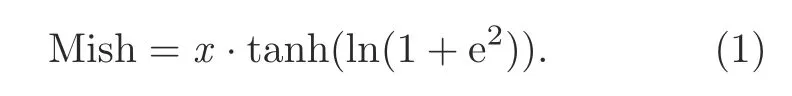
The function image is shown in Fig.4.It is not completely cut offwhen the value is negative,but allows a relatively small negative gradient to flow in,which ensures the flow of information.Additionally,because the activation function has no boundaries,the problem of gradient saturation is avoided.The Mish function can also ensure the smoothness of each point,which improves the gradient descent effect.
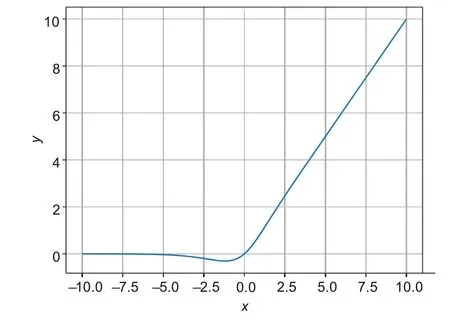
Fig.4 Mish function image
YOLOv4 adopts mosaic data enhancement.Its main steps are:(1)read four images at a time;(2)flip them,zoom them,or change color gamut;(3)arrange them in four directions;(4)calculate the data of four original images at one time.The process is shown in Fig.5.This process greatly enriches the image background information and the diversity

Fig.5 Mosaic data augmentation
of the dataset even when there is insufficient data,ensuring better training results.
YOLOv4 uses the complete intersection over union(CIoU)loss function.The IoU loss function does not consider the distance between the two boxes when the two boxes do not intersect.The generalized intersection over union(GIoU)solves this problem,but when the predicted bounding box is within the ground truth box,it cannot distinguish the relative position relationship.The emergence of the distance intersection over union(DIoU)resolves the drawbacks of GIoU,but DIoU does not take the widthto-height ratio between the predicted box and the ground truth box into account.CIoU solves all the above problems.It takes the overlapping area,center point distance,and width-to-height ratio between the predicted box and the ground truth box into consideration;the formula is as follows:
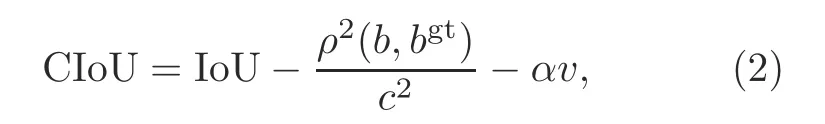
whereρ2(b,bgt)is the distance of central points of two boxes,cis the diagonal length of the smallest enclosing box covering two boxes,αis a positive trade-offparameter,andvmeasures the aspect ratio consistency as follows:
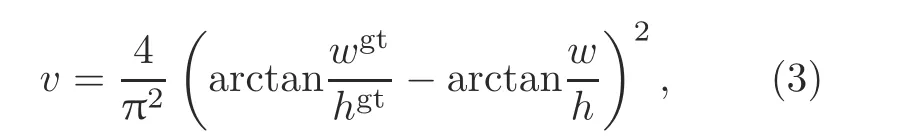
wherewandhare the width and height,respectively.Then the loss function can be defined as
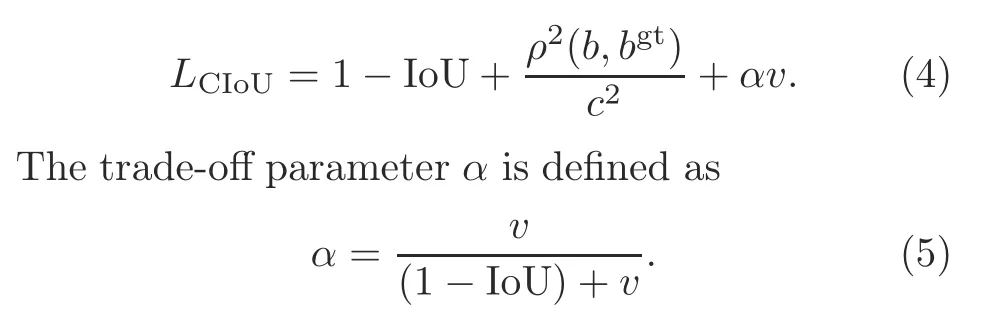
4 Improvements in YOLOv4
4.1 4S-YOLOv4
In the robot’s actual working area,when the robot gradually approaches the target object,the object’s image is gradually enlarged.In other words,there is plenty of size information about the target object.To better consider target objects of various sizes,and to further improve the accuracy of the detection network,our work adds a detection scale to the original YOLOv4,which is transformed from the original 13×13,26×26,and 52×52.It becomes 13×13,26×26,52×52,and 104×104,and is called 4S-YOLOv4.Fig.3b shows a schematic of its network structure.
4.2 Pruned 4S-YOLOv4
In recent years,with the improvement in computing power,CNNs have gradually become the main method in the field of computer vision.More and more types of excellent deep neural networks have been proposed,such as VGGNet(Simonyan and Zisserman,2015),GoogleNet(Szegedy et al.,2015),ResNets(He et al.,2016),and AlexNet(Krizhevsky et al.,2017).Researchers try to improve network performance by optimizing the network structure,adjusting the loss function,and improving the training method,to continuously optimize the accuracy and speed of the network.When the depth of the neural network increases,the number of parameters inevitably increases.Although a larger and deeper neural network can more fully extract the target’s feature information,which is of great help in improving the detection accuracy,the requirements for the network’s hardware performance are also increasing.A ResNet network with 152 layers will have more than 60 million parameters,and it will require more than 20 gigabit floating point operations when inferring an image with a resolution of 224×224(Liu Z et al.,2017).This may not be possible on a platform with low-level hardware,so it will not be able to perform optimally.
To achieve high-speed and high-precision detection,we prune the 4S-YOLOv4 network,and thus greatly reduce the number of parameters and calculation of the model,as well as the resource occupation of the model.Therefore,it enormously improves the inference speed of the model.
The core of the channel pruning algorithm is to delete the channel with the smallest contribution and its input-output relationship by calculating the channel in the network(Molchanov et al.,2019).This enhances the channel-level sparsity of the convolutional layer by applyingL1regularization on the channel scaling factor.Therefore,pruning feature channels leads to a slim object detector.The main formula is
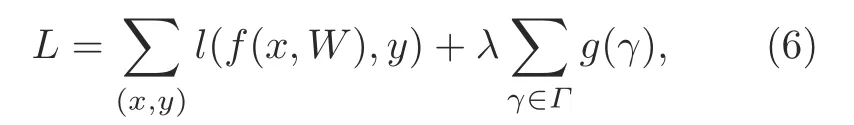
wherexandydenote the training input and the target respectively,Wdenotes the trainable weight,g(·)is a sparsity-induced penalty on the scaling factors,Γis the scaling factor of the batch normalization layer,andλbalances the two terms.The schematic is shown in Fig.6.
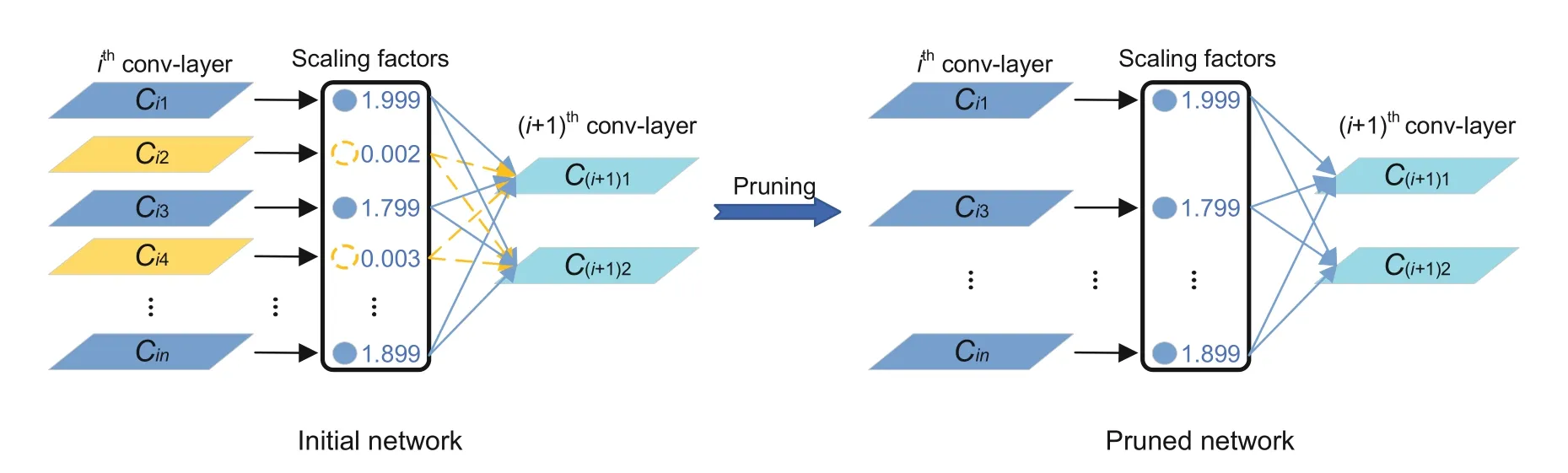
Fig.6 Channel pruning diagram
5 Experiments and results
5.1 Testing results
In this experiment,a detection task involving three types of target objects-fishing nets,plastic bags,and stones-was implemented on the GTX 1080Ti×3.Then,the frame rate,mAP,and average precision(AP)for each category of the proposed 4SP-YOLOv4(Pruned 4S-YOLOv4),YOLOv4,4SYOLOv4,YOLOv3,SSD,and Faster R-CNN were calculated for quantitative analysis.The weight file sizes of these networks were also compared,and the comparison results are shown in Fig.7.The final quantitative results are listed in Table 2,and the detection performance of 4SP-YOLOv4 is shown in Fig.8.
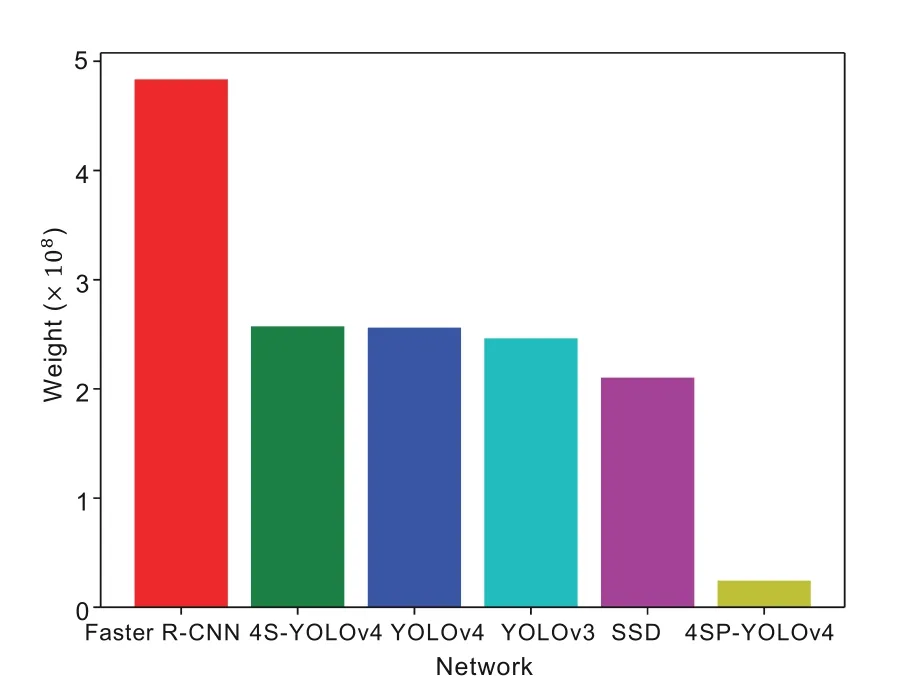
Fig.7 Weight comparison chart

Table 2 Detection results on the dataset
We also conducted a robot underwater target capturing experiment to verify whether the robot can adapt to different environments with the help of vision algorithms,and observed its state in a complex environment to determine whether the robot has the ability to solve practical problems.Underwater experiments are shown in Figs.9 and 10.This robot carried a binocular camera,responsible for obtaining the objects’position information using the stereo principle.Note that due to the soft texture of broken plastic bags and nets,it is not necessary to measure their specific orientation to accomplish grasping.In the real underwater environment,the robot can detect objects in time and accurately.Then,according to the detected object information,the robot is able to approach the object and successfully grasp it.
5.2 Discussion
The detection effect of 4SP-YOLOv4 is shown in Fig.8,and the results of comparison with other detection methods are listed in Table 2.We compared the weight file sizes of different network models,and the results are shown in Fig.7.The results showed that 4SP-YOLOv4 was remarkable in all aspects in this experimental scenario.After the conversion to 4S-YOLOv4,the accuracy was improved,which proves the correctness of this improvement.However,due to the addition of a scale of calculation,its speed dropped a little.Obviously,4S-YOLOv4 cannot cope with high-speed application scenarios,so it prunes the model channels that contribute little to classification and positioning to minimize the loss of model accuracy.It also reduces a lot of unnecessary calculations and improves the inference speed of the model,so it can realize high precision and achieve high speed.

Fig.8 Detection results of 4SP-YOLOv4

Fig.9 Schematic of robot underwater detection

Fig.10 Schematic of robot underwater capturing
Because the single-stage structure of the YOLO series network allows them to achieve high speed and high precision,YOLOv3 has achieved a perfect balance between accuracy and speed.YOLOv4 is improved based on YOLOv3,and has made certain improvements in accuracy and speed.Compared with YOLOv3 and YOLOv4,the SSD feature extraction network was not as good as Darknet-53 for feature extraction.Darknet-53 achieved higher precision than ResNet-101 and was 1.5 times faster.The performance of Darknet-53 was similar to that of ResNet-152 and it was 2 times faster.Darknet-53 also achieved the highest measured number of floating-point operations per second(Redmon and Farhadi,2018).However,to further improve the accuracy,our work added a detection scale to YOLOv4.To improve the detection speed,the 4S-YOLOv4 model was pruned.Finally,compared with the original YOLOv4,the accuracy of 4SP-YOLOv4 was 4.162%higher,the frame rate was 53.335%larger,and the weight was only 9.499%of that of the original model.
The experimental results indicated that 4SPYOLOv4 can provide the robot with real-time and accurate object detection.High-speed detection can process the image in real time and provide the object position information for the robot in time,in response to the changeable and complex environment.Even though Faster R-CNN made a significant breakthrough in accuracy,it cannot achieve real-time detection due to the computational burden from the two-stage network.Briefly,4SP-YOLOv4 exhibits better performance than the others in both speed and accuracy,and can effectively improve the capability of autonomous cleaning robots.Based on the aforementioned results,the proposed algorithm outperforms those in previous studies and is suitable for autonomous cleaning robots.However,for better robustness in complex aquatic environments,a more adequate dataset is indispensable. Additionally,the core contribution of this work is about the pruning strategy,which is effective in datasets with a small number of classes,like the underwater dataset we have proposed.However,this method performs slightly worse when tested on datasets with a larger number of classes,such as COCO,because the pruning process reduces the scale of the network.When there are more categories of objects in the dataset,the pruned network will be insufficient.Further research is therefore needed to improve the performance.
6 Conclusions and future work
A good detection method is essential for intelligent cleaning robots,and accuracy and speed are critical for detection algorithms.Traditional methods cannot simultaneously meet the requirements of speed and accuracy.In this paper,we propose an improved YOLOv4 algorithm.First,we convert the original YOLOv4 to 4-scale YOLOv4;then we perform model pruning on 4S-YOLOv4.Compared with other detection algorithms,4SP-YOLOv4 can achieve 0.951 mAP in 15 ms at GTX 1080Ti×3,and the number of parameters is only 9.499%of that of the original model,ensuring high-precision and high-speed object detection.
With only 9.499%model parameters,the hardware configuration requirement of 4SP-YOLOv4 is not as high as that of the original YOLOv4 model.In other words,it is possible to achieve high-speed and high-precision detection on devices with low configurations.The core contribution of this work is about the pruning strategy,which is effective for datasets with a small number of classes like the underwater dataset that we have proposed.In the future,we will try to transfer the model to mobile devices,such as mobile phones and cameras.
Contributors
Manjun TIAN designed the research.Manjun TIAN,Xiali LI,and Shihan KONG proposed the methods.Manjun TIAN and Shihan KONG conducted the experiments.Licheng WU and Junzhi YU processed the data. Manjun TIAN and Shihan KONG drafted the paper.Xiali LI,Licheng WU,and Junzhi YU helped organize the paper.Shihan KONG and Junzhi YU revised and finalized the paper.
Compliance with ethics guidelines
Manjun TIAN,Xiali LI,Shihan KONG,Licheng WU,and Junzhi YU declare that they have no conflict of interest.
 Frontiers of Information Technology & Electronic Engineering2022年8期
Frontiers of Information Technology & Electronic Engineering2022年8期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Human-machine augmented intelligence:research and applications
- Causality fields in nonlinear causal effect analysis*
- Introducing scalable1-bit full adders for designing quantum-dotcellular automata arithmetic circuits
- Training time minimization for federated edge learning with optimized gradient quantization and bandwidth allocation*#
- Amatrix-based static approach to analysis of finite state machines*
- Adaptive neural network based boundary control of a flexible marine riser systemwith output constraints*#