
基于变量重要性评分-随机森林的溶解氧预测模型——以深圳湾为例
2022-08-23 13:55杨明悦毛献忠
中国环境科学 2022年8期
杨明悦,毛献忠
基于变量重要性评分-随机森林的溶解氧预测模型——以深圳湾为例
杨明悦,毛献忠*
(清华大学深圳国际研究生院海洋工程研究院,广东 深圳 518055)
运用Pearson相关性分析,变量重要性评分和随机森林方法构建了溶解氧(DO)实时预测模型,并以深圳湾为例采用浮标资料预测1,3,6和12h的溶解氧.模型预测结果表明,模型最优的输入条件为pH值,水温,叶绿素a,氧化还原电位和蓝绿藻5个水质指标,1h预报的相关系数在0.9以上,6h预报结果一定程度上可以满足工程要求,但对低溶解氧事件的预报必须在3h以内.
溶解氧;预测模型;变量重要性评分;随机森林
随着社会经济发展,污染不断增加导致水环境恶化,并对全球水生生态系统构成严重威胁[1].溶解氧(DO)水平对水生生物的多样化至关重要,是评估水环境质量的重要指标之一[2],及时准确地预报DO具有重要意义.水体DO建模可追溯到20世纪20年代,DO模型主要是基于Streeter-Phelps方程,其机理是包含DO相互作用过程的质量平衡理论[3].随着环境在线监测技术的普及,数据驱动建模成为环境质量管理和预测的重要手段.比如,人工神经网络方法预测水库[4],湿地[5]和河流[6]中的DO;支持向量机[7]以及基于模糊逻辑和深度学习方法[8]等用于DO建模.Tung等[9]综述了209项人工智能模型的研究成果,表明2000~2020年数据驱动建模已成为重要的研究方法之一.
随机森林方法[10]对输入数据的质量要求相对较低,对异常值不敏感,可处理大量高维数组,计算密集程度也较低.这些优点使得模型可采用环境水质数据集作为模型输入,用于回归和分类问题,以开发特定的预测模型.该方法在水文和环境领域中有成功的应用案例,如水质预警模型[11],使用卫星图像进行全球降水分析[12],长江径流预报[13],近地面NO2浓度估算[14],海湾环境容量评价[15]和水华预警[16]等.然而目前预测模型建模复杂,预报时间短,较少结合在线监测数据实时预测DO.本文采用Pearson相关性分析,变量重要性评分和随机森林方法构建了DO实时预测模型,并以深圳湾浮标监测资料为例,对模型结果进行分析,对海湾溶解氧的预报具有重要意义.
1 材料和方法
1.1 研究区域和数据收集
深圳湾位于珠江口伶仃洋东侧,是一个半封闭型浅水海湾,属亚热带季风气候,年均气温22℃,年均降雨量1830mm,受珠江口和陆源污染的影响,水质严重富营养化[17].深圳市海洋监测预报中心在深圳湾布设浮标自动监测仪,位置如图1所示.本文采用该浮标在线监测资料(2014年11月1日~2017年9月6日,每0.5h一个数据),以DO作为目标变量,其它8项水质指标包括水温,pH值,叶绿素a,氧化还原电位,蓝绿藻,电导率,盐度和浑浊度作为输入因子,建立最优化的DO预测模型.
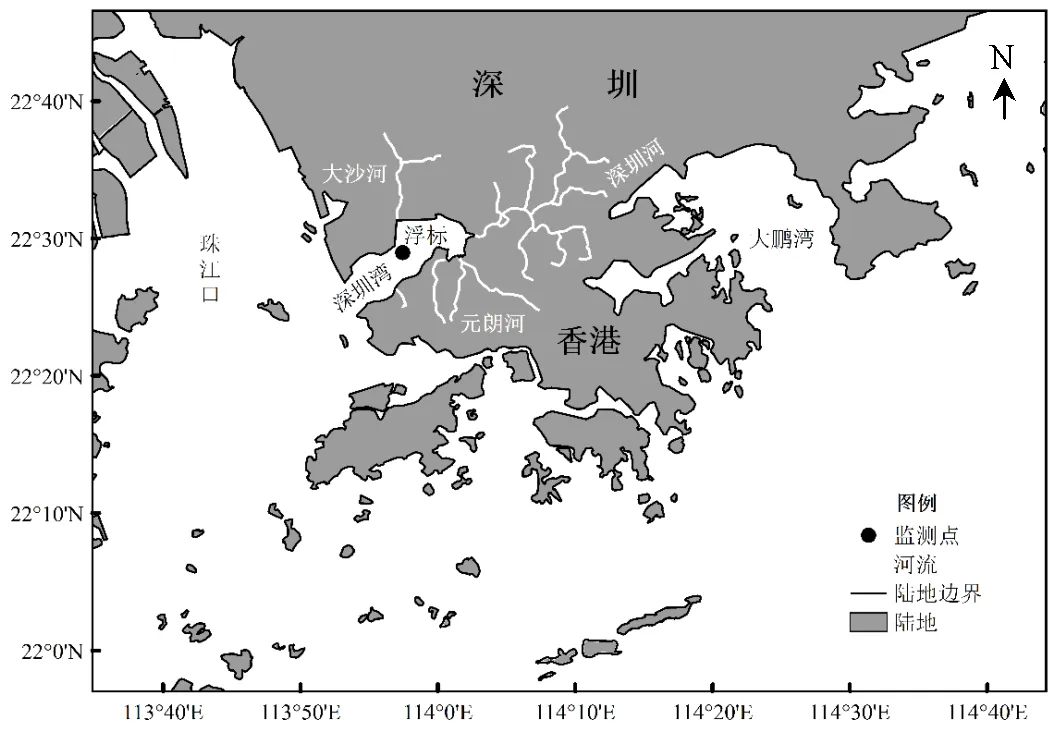
图1 研究区域及浮标监测点
审图号:GS(2016)2556号
经过适当数据清洗与插值处理后,表1统计了各项水质参数特征.深圳湾平均水温为30.07℃,平均叶绿素a含量为15.50µg/L,最高能够达到89.30µg/L.平均DO为5.36mg/L,最低为2.03mg/L,DO低于3mg/L的频率为2.2%,低于4mg/L的频率为11.5%,由此可见,深圳湾低氧现象频发,DO的预报对深圳湾水质管理非常重要.

表1 水质参数特征的统计
1.2 相关系数矩阵
相关系数是研究变量间相关程度的量,本文采用皮尔逊相关系数计算相关系数矩阵.通过计算2个相应变量之间的线性相关度得到矩阵的单元值,对于可能存在多重共线性的重要信息也可以通过相关系数矩阵来可视化.对于变量和,其相关系数矩阵为:
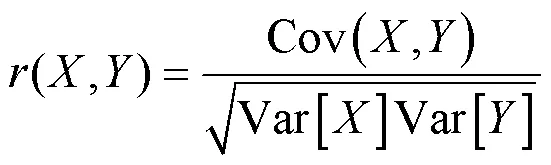
式中: Cov是方差,Var是协方差.采用显著性水平(值)来检验相关系数中样本统计值和假设的总体参数之间的显著性差异.若£0.01,检验高度显著; 0.01<£0.05,检验显著;>0.05,检验不显著.
1.3 基于变量重要性评分的预测变量组合
选择最佳数量的预测变量对数据驱动模型至关重要[18].变量重要性评分(VIM)主要评估每个特征在随机森林的每颗树上做了多大贡献,这个贡献通常可以用基尼系数或者袋外数据误差等作为评价指标来衡量,每个变量的得分可根据下列均方误差矩阵(MSE)估计.

通过误差矩阵确定第个特征变量的相对重要性,VIM的计算公式为:


为选择最有影响力的预测变量组合,并将其用于最终模型,本研究采用以下步骤进行筛选:
(1)使用VIM对预测变量的重要性进行排序.
(2)挑选排名靠前的预测变量创建第一个随机林,并计算评估模型性能.
(3)依次添加排名后一位的变量,重新创建随机林,并重新评估模型性能.
(4)重复上述过程,直到再次添加变量不会显著提高模型整体效率为止.
最终模型被称为“最优(简化)模型”[19],它包含一组最少的变量,并能够最大限度地提高预测模型的准确性.
1.4 随机森林模型
随机森林聚合了许多决策树,其结果是由多个决策树输出的汇总.决策树是一种决策支持工具,它使用树状结构,由节点和链接组成.每个决策树都以一个父节点开始,该父节点表示一个审议和决策点,并创建分支,直到做出决策.本研究通过袋外误差法确定了决策树的最佳数量,具体步骤如下:
(1)原始训练集有个样本,且每个样本有维特征.从数据集中随机抽取个样本组成训练子集,一共进行次采样,即生成个训练子集.
(2)每个训练子集形成一棵决策树,一共形成棵决策树.
(3)针对单个决策树,树的每个节点处从个特征中随机挑选个特征,并根据结点不纯度最小原则进行分裂.每棵树都依照此方法分裂下去,直到该节点的所有训练样本均属于同一类,在此过程中不剪枝.
(4)根据生成的多个决策树分类器进行预测,统计每棵树的投票结果,利用平均值得到最终结果.
本研究使用随机森林构建的DO实时预测模型有以下3点前提假设与适用条件: (1)DO的变化具有一定的规律性,目标值与变量间存在一定的关联性,受其中一个或多个变量共同影响; (2)短期内DO的变化是连续的,不会突变; (3)当前DO状态受前一相邻时段的影响更大,即数据之间的间隔越远,其相关性越弱.
1.5 模型性能评估指标
选择4种性能指标评估模型性能,包括: 纳什效率系数(NSE),均方根误差(RMSE),平均绝对误差(MAE)以及均方根误差与标准偏差之比(RSR).计算公式为:




式中:是数据点数,Yo是观测真实值, Ym是建模预测值, Ymean是观测值的平均值.
NSE是广泛使用的统计评分指标之一,其范围从负无穷到1,接近1的值表示模型拟合完美,负NSE则表明拟合不良.RSR值为评估模型校准和验证提供了基础,并建议模型应该被接受还是被拒绝[20].采用RSR值评价模型拟合效果,分别以RSR值为0~0.5,0.5~0.6,0.6~0.7和>0.7范围分为完美模型,良好模型,一般模型和较差模型.此外,RMSE和MAE接近0表示模型和观测值完美拟合.
2 结果与讨论
2.1 预测因子的筛选
DO和其他8项水质指标的相关系数矩阵见图2.其中,DO与水温和pH值呈中度相关性(= 0.464~0.505),与叶绿素a呈弱相关性(=0.382).并具有统计学意义(£0.05).其他预测因子如氧化还原电位,蓝绿藻,电导率,盐度和浑浊度与DO的相关性非常弱(=-0.058~0.197),其中与蓝绿藻的相关性不显著(>0.05).此外,结果还显示各预测因子间存在中度至强多重共线性.例如,电导率和盐度具有强相关性(=0.997);蓝绿藻与叶绿素a具有中等相关性(= 0.444),与pH值和氧化还原电位均具有弱相关性(||=0.285~0.383); pH值与氧化还原电位,电导率和盐度表现出中度相关性(||=0.416~ 0.569).
随机森林的变量重要性评分结果如图3所示.pH值是预测DO最有影响力的因子,重要性为25.56%;而后依次是水温,叶绿素a,氧化还原电位等,重要性分数高于10%的有4个;浑浊度的影响力最弱,仅3.52%.对比图2和图3可知,基于VIM的预测因子重要性排序与Pearson相关矩阵结果不同,这种差异可能源于数据相关矩阵存在多重共线性.此外,DO动力学的非线性特性也无法从相关系数的线性分析中体现出来.因此,在数据驱动模型建模过程中,一般采用VIM而不是相关性来选择主要的预测变量,这可避免受到多重共线性效应的影响.
根据以上分析,按照各变量重要性相对排名顺序,可以产生8种不同的预测变量组合方案(表2)作为模型的输入条件.

图2 水质预测因子间的Pearson相关系数

图3 各种变量重要性评分

表2 不同预测变量组合的8种方案
2.2 随机森林模型验证
选取80%的观测数据用于不同预测变量组合的随机森林决策树模型建模,剩余20%的观测数据用于验证评估模型的精度.如图4所示,当仅使用pH值作为唯一变量输入时,NSE为0.25,RSR为0.909,表明此时模型拟合不良,效果较差; 随着输入模型变量数量增加,NSE呈现上升趋势,RMSE,MAE和RSR也随之降低,表明模型的精度逐渐提高,拟合效果也越来越好.从方案5开始(即5个及以上的输入变量),NSE>0.8,RSR<0.5,表明模型可解释>80%的数据方差,达到较好的拟合效果.

图4 8种变量组合输入方案的模型性能

图5 方案5模型的DO验证
但值得注意的是,并非输入的变量越多,模型的性能就会越好.本模型试验表明,6个以上输入变量模型精度趋于稳定,输入变量继续增加,NSE值不升反降,说明模型性能在下降.造成这一现象的原因是排名较后的预测因子重要性较低,且与其他因子间还存在中度至强多重共线性,相当于为训练集增加了“噪声”.因此,合理选择输入预测因子的种类和数量是建模的基础.
根据模型的精度和简约原则,选择方案5(即pH值,水温,叶绿素a,氧化还原电位,蓝绿藻5个模型输入变量)作为最终模型的输入方案,用于预测DO,此时的NSE,RMSE,MAE和RSR分别为0.873,0.398,0.285和0.383.方案5的模型验证结果如图5所示,散点均沿=直线两侧分布,位于95%置信区间内占比94.4%,表明应用VIM-随机森林模型的DO预测精度较高,模型的拟合效果较好.
2.3 不同预测期的模型精度
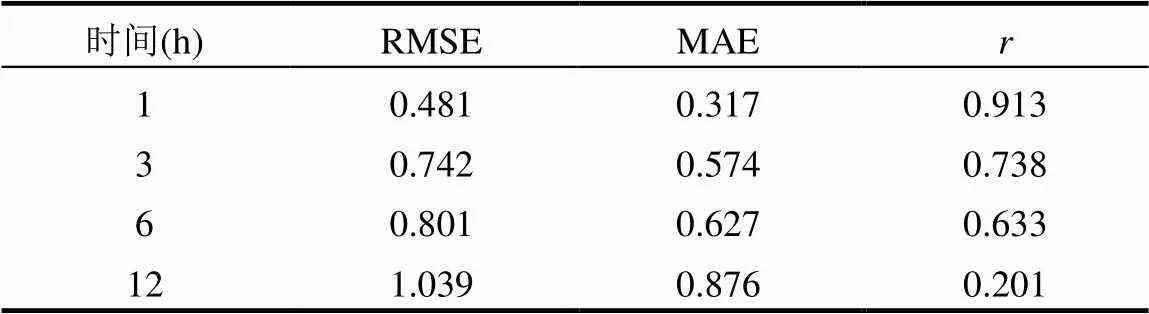
表3 不同预测期的误差与相关系数

图6 不同预测期模型预测值和实测值对比
目前大部分DO预测模型在1~2h的短期预测效果较好[21-22],但是对于预测模型来说,在满足精度的基础上预测期越长说明功能越强大.参考文献[23]将预测期分为短期(1,3h),中期(6h)和长期(12h),测试模型的有效性.采用随机森林模型在不同时段的预测误差与相关系数如表3所示,模型预测值和实测值对比见图6.模型的精度随着预测时长的增加而降低,预测期为1h预测效果最好,此时RMSE,MAE和相关系数分别为0.481,0.317和0.913.
从相关系数和精度看,随机森林模型预测6h后的RMSE,MAE和相关系数分别为0.801,0.627和0.633,表明预测结果在一定程度能满足工程实践要求.但是预测低氧过程,比如DO浓度小于4mg/L时,1和3h预测的效果更好,几乎与实测值同步变化(图6),说明模型能够预报极端值从而达到及时预警的效果.
在观测数据的时间序列中,数据之间的间隔越远,相关性越弱,随着预报时长的增加,模型误差也会逐步积累,从而影响预报精度[24];同时,在预测过程中模型提取信息随时间的推移越来越困难,因为随时间的推移,信息的不确定性越大.这些都是数据驱动模型的局限性.当预测期为12h时,RMSE值大于1,相关系数仅为0.201,说明构建的DO模型对于长期预测的表现仍有待提高.
尽管本文构建的DO模型在短、中期预测上表现良好,但长期预测的准确性仍有待提高.尽早预测低氧事件可以为紧急预案处置提供充分的反应时间,其重要性不言而喻.因此,如何提高模型长期预测能力将是今后的研究重点.
3 结论
3.1 采用变量重要性评分和随机森林相结合的方法构建了DO预测模型,并以深圳湾为例通过变量重要性评分方法筛选了pH值,水温,叶绿素a,氧化还原电位,蓝绿藻5个模型输入变量,建立了性能评价最优模型,其中NSE,RMSE,MAE和RSR分别为0.873,0.398,0.285和0.383.
3.2 模型预测结果表明,在深圳湾采用随机森林模型预测6h内的DO在一定程度上能满足工程要求;但是如果要精准预测低氧过程及极端缺氧事故,预报时长应该小于3h.
[1] Ji X,Shang X,Dahlgren R A,et al. Prediction of dissolved oxygen concentration in hypoxic river systems using support vector machine: A case study of Wen-Rui Tang River,China [J]. Environmental Science and Pollution Research,2017,24(19):16062-16076.
[2] Wen X,Fang J,Diao M,et al. Artificial neural network modeling of dissolved oxygen in the Heihe River,Northwestern China [J]. Environmental Monitoring and Assessment,2013,185(5):4361-4371.
[3] Li G.Stream temperature and dissolved oxygen modeling in the lower Flint River basin,GA [D]. University of Georgia,2006.
[4] Antanasijević D,Pocajt V,Perić-Grujić A,et al. Modelling of dissolved oxygen in the Danube River using artificial neural networks and Monte Carlo Simulation uncertainty analysis [J]. Journal of Hydrology,2014,519:1895-1907.
[5] 江春波,张明武,杨晓蕾.华北衡水湖湿地的水质评价 [J]. 清华大学学报(自然科学版),2010,50(6):848-851.
Jiang C B,Zhang M W,Yang X L. Water quality evaluation for the Hengshui Lake wetland in northern China [J]. Journal of Tsinghua University (Science and Technology),2010,50(6):848-851.
[6] Ahmed A A M. Prediction of dissolved oxygen in Surma River by biochemical oxygen demand and chemical oxygen demand using the artificial neural networks (ANNs) [J]. Journal of King Saud University-Engineering Sciences,2017,29(2):151-158.
[7] Heddam S,Kisi O. Modelling daily dissolved oxygen concentration using least square support vector machine,multivariate adaptive regression splines and M5model tree [J]. Journal of Hydrology,2018,559:499-509.
[8] Ay M,Kişi Ö. Estimation of dissolved oxygen by using neural networks and neuro fuzzy computing techniques [J]. KSCE Journal of Civil Engineering,2017,21(5):1631-1639.
[9] Tung T M,Yaseen Z M. A survey on river water quality modelling using artificial intelligence models: 2000~2020 [J]. Journal of Hydrology,2020,585:124670.
[10] 姚登举,杨 静,詹晓娟.基于随机森林的特征选择算法 [J]. 吉林大学学报(工学版),2014,44(1):137-141.
Yao D J,Yang J,Zhan X J. Feature selection algorithm based on random forest [J]. Journal of Jilin University (Engineering and Technology Edition),2014,44(1):137-141.
[11] 李若楠,王 琦,刘书明.基于典型相关系数和随机森林的水质预警方法 [J]. 中国环境科学,2021,41(9):4457-4464.
Li R N,Wang Q,Liu S M. Water quality warning method based on canonical correlation coefficient and random forest [J]. China Environmental Science,2021,41(9):4457-4464.
[12] Bhuiyan M A E,Nikolopoulos E I,Anagnostou E N,et al. A nonparametric statistical technique for combining global precipitation datasets: development and hydrological evaluation over the Iberian Peninsula [J]. Hydrology and Earth System Sciences,2018,22(2): 1371-1389.
[13] 赵铜铁钢,杨大文,蔡喜明,等.基于随机森林模型的长江上游枯水期径流预报研究 [J]. 水力发电学报,2012,31(3):18-24,38.
Zhao T T G,Yang D W,Cai X M,et al. Predict seasonal low flows in the upper Yangtze River using random forests model [J]. Journal of Hydroelectric Engineering,2012,31(3):18-24,38.
[14] 游介文,邹 滨,赵秀阁,等.基于随机森林模型的中国近地面NO2浓度估算 [J]. 中国环境科学,2019,39(3):969-979.
You J W,Zou B,Zhao X G,et al. Estimating ground-level NO2concentrations across mainland China using random forests regression modeling [J]. China Environmental Science,2019,39(3):969-979.
[15] 邹佳奇,张亦飞,方 欣,等.基于随机森林的入海污染源对海湾环境容量的影响排序研究 [J]. 海洋环境科学,2021,40(5):675-682.
Zou J Q,Zhang Y F,Fang X,et al. Impact ranking of pollution source discharge on the bay environmental capacity based on the random forest algorithm [J]. Marine Environmental Science,2021,40(5):675-682.
[16] 刘云翔,吴 浩.基于随机森林算法的水华预警模型 [J]. 人民黄河,2018,40(8):75-77,90.
Liu Y X,Wu H. Water bloom early warning model based on random forest [J]. Yellow River,2018,40(8):75-77,90.
[17] Zhou Y,Wang L,Zhou Y,et al. Eutrophication control strategies for highly anthropogenic influenced coastal waters [J]. Science of the Total Environment,2020,705:135760.
[18] Asadollah S B H S,Sharafati A,Motta D,et al. River water quality index prediction and uncertainty analysis: A comparative study of machine learning models [J]. Journal of Environmental Chemical Engineering,2021,9(1):104599.
[19] Laird J. The law of parsimony [J]. The Monist,1919,29(3):321-344.
[20] Moriasi D N,Arnold J G,Van Liew M W,et al. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations [J]. Transactions of the ASABE,2007,50(3):885-900.
[21] Cao W,Huan J,Liu C,et al. A combined model of dissolved oxygen prediction in the pond based on multiple-factor analysis and multi-scale feature extraction [J]. Aquacultural Engineering,2019,84:50-59.
[22] Khan U T,Valeo C. Optimising fuzzy neural network architecture for dissolved oxygen prediction and risk analysis [J]. Water,2017,9(6):381.
[23] Liu Y,Zhang Q,Song L,et al. Attention-based recurrent neural networks for accurate short-term and long-term dissolved oxygen prediction [J]. Computers and Electronics in Agriculture,2019,165:104964.
[24] Kamranzad B,Etemad-Shahidi A,Kazeminezhad M H. Wave height forecasting in Dayyer,the Persian Gulf [J]. Ocean Engineering,2011,38(1):248-255.
Dissolved oxygen prediction model based on variable importance measures and random forest: A case study of Shenzhen Bay.
YANG Ming-yue,MAO Xian-zhong*
(Institute for Ocean Engineering,Shenzhen International Graduate School,Tsinghua University,Shenzhen 518055,China).,2022,42(8):3876~3881
A real-time prediction model for dissolved oxygen was established by using Pearson correlation analysis,variable importance measures and random forest method. Taking Shenzhen Bay as an example,the model was used to predict the dissolved oxygen in 1h,3h,6h and 12h based on the buoy data. The results showed that the optimal input conditions of the model were pH,water temperature,chlorophyll A,redox potential and blue-green algae. The correlation coefficient of 1h prediction results was more than 0.9,and the 6h prediction results could meet the engineering requirements to a certain extent. However,the prediction of low dissolved oxygen events might be within 3h.
dissolved oxygen;prediction model;variable importance measures;random forest
X832
A
1000-6923(2022)08-3876-06
2022-01-17
国家自然科学基金资助项目(42076150)
* 责任作者,副教授,maoxz@sz.tsinghua.edu.cn
杨明悦(1999-),男,安徽六安人,清华大学深圳国际研究生院硕士研究生,主要从事海洋环境预测研究.
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
中国报道(2020年12期)2020-01-08
电子制作(2018年17期)2018-09-28
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
决策与信息·下旬刊(2013年1期)2013-03-11
