
基于多层感知卷积和通道加权的图像隐写检测
2022-08-19 02:56叶学义郭文风曾懋胜张珂绅赵知劲
电子与信息学报 2022年8期
叶学义 郭文风 曾懋胜 张珂绅 赵知劲
(杭州电子科技大学通信工程学院 杭州 310018)
1 引 言
数字图像隐写检测阻止非法隐写通信活动、保障通信安全[1],是信息安全领域的重要研究方向,得到了广泛的研究并且发展迅速,它通过对数字图像进行分析,从而判断图像是否嵌入了秘密信息。传统图像隐写检测方法主要通过提取基于相邻像素相关性的高阶统计特征和训练分类器完成载体/载秘图像的分类,如减法像素邻接矩阵(Subtractive Pixel Adjacency Matrix, SPAM)[2]和空域富模型(Spatial Rich Model, SRM)[3]。但是这些方法所提取的检测特征需要人工设计,特征提取耗费极高,而且随着隐写术的不断发展[4–6],人工设计隐写检测特征的难度越来越大。
随着深度学习的兴起,研究者开始将深度学习引入图像隐写检测[7]。2014年,Tan等人[8]从一堆自动编码器中使用无监督学习来训练卷积神经网络(Convolutional Neural Networks, CNN)。2015年Qian等人[9]提出了一个基于监督的5层CNN模型Qian-Net进行隐写检测,其检测准确率与SRM[3]相似。2016年Xu等人[10]构建了一个不同的5层CNN检测模型Xu-Net,不同点在于Xu等人借鉴了其他应用领域中取得成功的卷积神经网络结构单元,如绝对值激活层(ABSolute activation layer, ABS)和批归一化层(Batch Normalization, BN)。卷积层之后使用ABS层的目的是使模型学习残差图像的符号对称性;BN层的使用则避免模型在训练过程中出现梯度消失问题,且允许更大的学习率,大幅提高训练速度,实验结果表明,其模型的检测准确率稍优于SRM[3]。2017年,Ye等人[11]设计了一个10层的CNN图像隐写检测模型Ye-Net,该模型首次在预处理层使用了SRM[3]中使用到的30个高通滤波器进行滤波,有助于抑制图像内容和提取隐写信息;使用截断线性单元(Truncated linear unit, Trunc)作为第1个卷积层的激活函数,增加了模型的非线性因素,使模型可以拟合更复杂的特征,实验结果表明,其模型检测准确率远超于SRM[3]。Yedroudj等人[12]在2018年提出了一个新的5层CNN图像隐写检测模型Yedroudj-Net,其模型结合了Xu-Net[10]和Ye-Net[11]的优点,取得了更好的检测结果。同年,Zhang等人[13]提出了一个利用可分离卷积和空间金字塔池的CNN检测模型Zhang-Net,明显地提高了检测准确率。
虽然基于深度学习的图像隐写检测已经显著提高了检测准确率,但是现有模型所提取检测特征的表达能力仍然不能满足应用所需。为此本文构建了一个基于多层感知卷积和通道加权的图像隐写检测模型。在预处理层,对滤波器内核进行改进,使用SRM[3]中使用到的30个高通滤波器对预处理层进行初始化,按照尺寸大小,分别扩充为17个 3 ×3和13个5 ×5大小,优化局部特征;在模型中使用多层感知卷积层来代替传统的卷积层,增加模型的抽象能力;为了使模型学习到更有利于检测的特征,进一步提高模型的检测准确率,在模型中加入通道加权模块。将该模型与Xu-Net[10], Yedroudj-Net[12],Zhang-Net[13]进行比较,在相同的实验条件下,小波加权( Wavelet Obtained Weights, WOW)[14]、空域-通用小波相对失真(Spatial-UNIversal WAvelet Relative Distortion, S-UNIWARD)[15]两种不同隐写算法的不同嵌入率下的实验结果表明,本模型表现出更高的检测准确率。
2 基于CNN图像隐写检测的最近典型模型
2.1 Yedroudj-Net
图1显示了Yedroudj-Net[12]的整体架构,其包含1个预处理层、5个卷积层以及1个由3个全连接层和1个Softmax[16]组成的输出层,卷积层包含线性卷积层、批归一化层(BN)、非线性激活层和平均池化层。
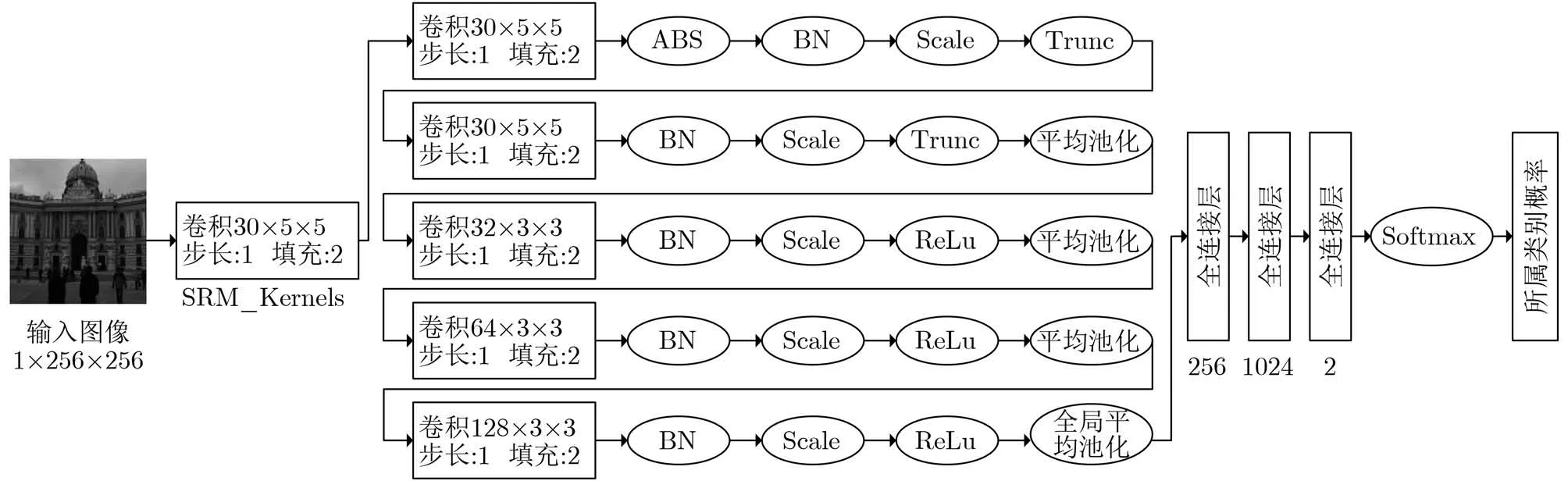
图1 Yedroudj-Net[12]CNN架构
基于数字图像的信息隐写过程可以看作在载体图像的高频区域添加少量信息,为了提取多样性的高频信息,预处理层采用与Ye-Net[11]相同的处理方案,使用SRM[3]中的30个高通滤波器对输入图像进行滤波。以往的研究证明[9],这种预处理很大程度上抑制了图像内容,暴露出隐写信息,如果没有这种预处理,模型很难收敛。鉴于ABS层和BN层在Xu-Net[10]模型中的良好表现,Yedroudj-Net[12]模型在搭建过程中同样使用了ABS层和BN层。
2.2 现有问题及分析
目前隐写算法的研究更趋向于将秘密信息嵌入载体图像的细节,尽可能小地改动载体图像,这导致检测模型必须提取更高阶的图像统计特性才能反映出载体图像在隐写前后的差异。因此,对于图像隐写检测而言,检测特征的表达对检测结果至关重要,但是现有的模型还存在以下问题:(1) 预处理层需要用SRM中30个高通滤波器进行初始化,现有的处理方式是将其统一扩充为5 ×5大小,则小尺寸的高通滤波器会被填充过多的0,抑制残差图像;(2) 卷积层的线性卷积运算对高阶特征的表达能力有限;(3) 卷积得到的所有特征图以同等的权重输入下一层,没有考虑其主要性和次要性。
由此提出了基于多层感知卷积和通道加权的隐写检测模型。首先在预处理层将30个高通滤波器按照尺寸大小,分别扩充为17个 3×3 和 13个5 ×5大小,避免过度补零对残差图像的抑制;其次引入Lin等人[17]提出的多层感知卷积层(Multi-layer perceptual convolution layer, Mlpconv),它将卷积核与多层感知器连接,利用多层神经元的全连接弥补对高阶特征的表达;最后采用挤压激励(Squeezeand-Excitation, SE)[18]模块,实现根据全局信息对不同的特征图通道分配不同的权重。
3 基于多层感知卷积和通道加权的隐写检测模型
3.1 模型结构
如第2节所述,本文构建了一个新的隐写检测模型,整体架构如图2所示。
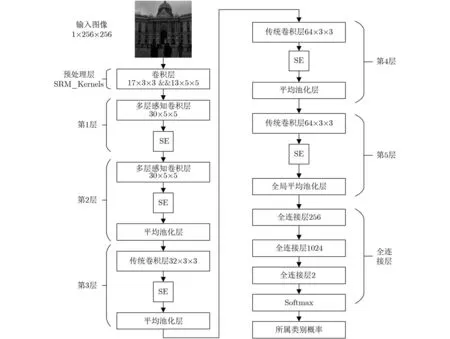
图2 本文检测模型
本模型由1个预处理层、2个多层感知卷积层(Mlpconv)、3个传统卷积层、通道加权模块SE[18]以及3层全连接层组成。
预处理层对输入图像进行滤波,滤波器采用的是SRM[3]中用到的30个高通滤波器,滤波器的值在训练过程中固定不变。滤波得到的残差图像输入多层感知卷积层,多层感知卷积层包含30个5×5大小的线性卷积核和1个多层感知器(MultiLayer Perceptron, MLP),多层感知器由具有非线性激活函数的两个完全连接的层组成,其中非线性激活函数选择线性整流单元(Rectified Linear Unit, ReLU),全连接层神经元的个数与线性卷积核的个数保持一致。每层卷积层的线性卷积之后都使用BN层,ABS层仅在第1个卷积层之后被使用。与Yedroudj-Net[12]相似,本模型在Mlpconv中的线性卷积之后应用Trunc激活函数,在传统卷积层应用ReLU激活函数。模型中第1层不做池化,2, 3, 4层使用平均池化,大小为5 ×5,步长为2,最后一层使用全局平均池化。通道加权模块SE[18]根据全局信息对不同通道特征图分配不同的权重,特征图完成权重重分配之后输入到下一层,SE[18]具体实现细节如3.4节所示。
3.2 改进预处理层

扩充完后首先对所有高通滤波器进行归一化处理,使得滤波器中心元素的值为1,这样每个滤波器的参数都分布于同一量级;然后将通过高通滤波器计算得到的两部分残差图像堆叠到一起,进行阈值T为3的截断操作,可以有效抑制无用的图像内容,防止模型对较大的值进行建模,提高模型对特征的表达能力。
3.3 Mlpconv
图3所示为传统线性卷积层的示意图,对于传统的卷积层来说,一般是通过一个单层线性滤波器对输入进行线性卷积运算,然后接非线性激活函数,最终生成特征图。以ReLU激活函数为例,传统卷积层的特征图的计算公式为


图3 线性卷积层
众所周知,CNN通过结合较低层的特征来生成高层特征,因此在将他们生成更高层次的特征之前,对每个局部感受野进行更好的抽象是有益的。所以在本文构建的模型的低层使用了如图4所示的多层感知卷积层(Mlpconv)结构来代替传统的卷积层。
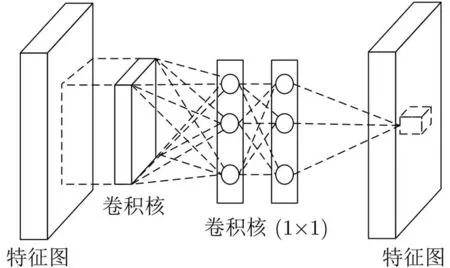
图4 Mlpconv层
Mlpconv相当于在卷积层中包含了一个由多层感知器构成的微型网络,通过微型网络对每个局部区域进行更复杂的运算,计算更抽象的特征。Mlpconv特征图的计算公式为

3.4 通道加权
通常在设计检测模型时,会用到多个卷积核,尽可能地提取检测所需要的特征,多个卷积核提取到的特征会包含主要特征,相应地也会包含次要特征,每个特征图通道对检测结果的重要性并不完全相同。为此在模型中引入了通道加权的机制,对特征进行重新校准。SE[18]模块利用全局信息对不同的特征图通道分配不同的权重,在图像分类比赛中表现出显著的性能,通过在每层卷积层后构建SE模块[18]来完成通道加权的过程,如图5所示。
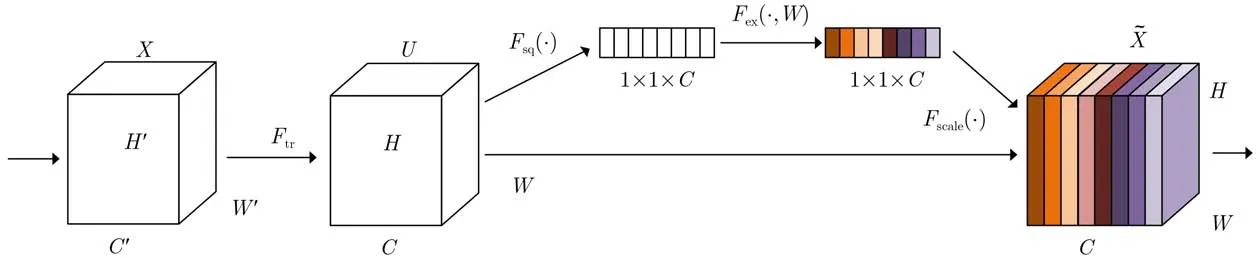
图5 SE模块结构图
卷积得到的特征图U首先通过挤压(Squeeze)操作,U的维度为H×W×C,C为卷积得到的特征图通道数。Squeeze操作通过对特征图使用全局平均池化得到输出为 1×1×C的特征图通道统计数据,采用全局平均池化是为了聚集全局信息,使得来自网络的全接收域的信息被它的所有层使用。计算公式为

4 实验及分析
4.1 实验设置及数据集
所有实验均采用深度学习框架 PyTorch,在Linux操作系统下实现,图形处理器(Graphics Processing Unit, GPU)采用英伟达(NVIDIA,GTX1080)。选用数据库为BOSSBase v1.0[19],其包含10000张大小为512×512的灰度图像,由于GPU显存限制,使用MATLAB将所有图片重采样为大小为2 56×256的图像。
实验使用了两种典型的自适应隐写算法小波加权(Wavelet Obtained Weights, WOW)[14]和空域-通用小波相对失真(Spatial-UNIversal WAvelet Relative Distortion, S-UNIWARD)[15]对载体图像进行秘密信息嵌入,由此得到10000对载体/载秘数据集,然后将10000对图像划分为两组,5000对图像分配给训练集,5000对分配给测试集,在5000对训练集中选择4000对进行训练,剩下的1000对留作验证,测试集在训练阶段保持不变。
实验中采用小批量随机梯度下降算法,权重衰减率设为0.0001,动量设置为0.95,所有层使用泽维尔 (Xavier)[20]方法初始化,训练中每一批次大小设置为16,学习率初始化为0.01,最大训练迭代数为300。实验中对比检测模型的数据直接来自对应的参考文献。
4.2 预处理层改进前后对比
对于隐写检测模型来说,特征提取模块的输入是预处理层所提取的残差图像,因此预处理层所提取的残差图像对于模型的检测结果至关重要。为了说明在3.2节所提对预处理层的改进对模型检测准确率的影响,用所提改进方案对Yedroudj-Net[12]预处理层进行修改,其他部分不变,与Yedroudj-Net[12]进行对比实验。在0.2 bpp和0.4 bpp两种嵌入率下,两种检测模型对WOW[14]和S-UNIWARD[15]两种隐写算法的检测准确率如表1所示。
从表1可以看出,按照3.2节提出的方案修改了预处理层之后Yedroudj-Net[12]相较原本的Yedroudj-Net[12]在两种隐写算法的两种不同的嵌入率下,检测准确率都有所提升,最高提升5.51%。由此可见,改进后的预处理层所提取的残差图像对模型的检测准确率有很大的影响,更加有利于隐写检测。
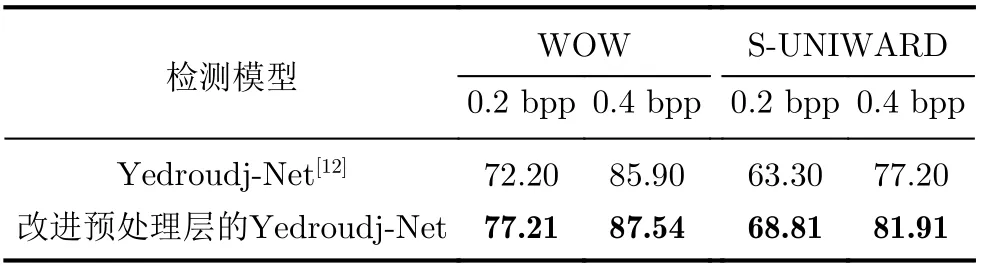
表1 Yedroudj-Net[12]修改预处理层前后准确率(%)
4.3 Mlpconv对检测准确率的提升
为了说明Mlpconv对检测准确率的影响,本节实验首先对Mlpconv的抽象能力进行了分析,然后研究了Mlpconv的层数对检测结果的影响,最后与3种比较著名的检测模型进行了对比,分别是Xu-Net[10], Yedroudj-Net[12]以及Zhang-Net[13]。
4.3.1 特征图可视化
特征图可以很好地描述特征提取过程,为了比较Mlpconv与传统卷积层的特征抽象能力,将经过第1层传统卷积层后的特征图与经过第1层Mlpconv之后的特征图进行了可视化处理。隐写检测模型都是使用S-UNIWARD[15]进行训练,嵌入率为0.4 bpp。选取数据集中任意一张载秘图像,模型所提取部分特征图对比如图6所示。其中图6(a)为载秘图像,图6(b)为经过第1层传统卷积层后所提取的部分特征图,图6(c)为经过第1层Mlpconv之后提取的部分特征图。实验结果表明,Mlpconv生成的特征图保留了较少的图像内容信息,并保持了较高的信噪比,在隐写检测模型中使用Mlpconv能提取出具有较强表达能力的特征。

图6 模型所提取部分特征图
4.3.2 Mlpconv层数对检测准确率的影响
使用Mlpconv代替传统的卷积层可以显著提高检测准确率,但过多地使用Mlpconv会带来参数量的增加,增大计算开销。为了合理使用Mlpconv,搭建性能良好的图像隐写检测模型,本节实验探究了Mlpconv层数对检测准确率的影响,分别使用1层Mlpconv、2层Mlpconv和3层Mlpconv替换传统的卷积层时,在S-UNIWARD[15]隐写算法的0.1 bpp,0.2 bpp, 0.3 bpp以及0.4 bpp 4个不同的嵌入率的情况下做了对比实验,实验结果如图7所示。
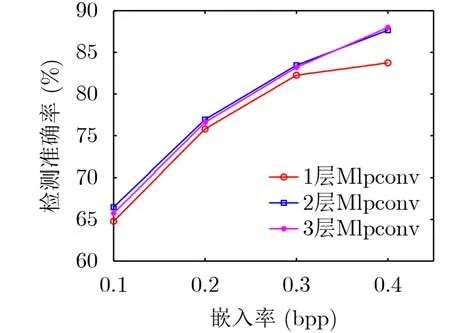
图7 不同Mlpconv层数实验结果图
实验结果表明,增加Mlpconv的层数并不能给模型带来检测准确率上的持续提升。当用2层Mlpconv代替传统的卷积层时,检测准确率最高,3层Mlpconv仅在0.4 bpp的嵌入率下表现较好,检测准确率为87.79%,相比较2层Mlpconv的准确率提升0.13%,并且当Mlpconv为3层时,模型所需学习的参数量相较于2层Mlpconv增长了0.6%。综合考虑,选择了使用2层Mlpconv代替传统的卷积层来搭建隐写检测模型,以达到良好的检测准确率。
4.3.3 不同方法的对比
在0.2 bpp, 0.4 bpp两种嵌入率下,Xu-Net[10],Yedroudj-Net[12], Zhang-Net[13]以及本文模型对WOW[14]和S-UNIWARD[15]两种隐写算法检测准确率如表2所示。
从表2的实验结果可以看出,针对WOW[14]隐写算法,0.2 bpp和0.4 bbp嵌入率下,本文模型检测准确率与Yedroudj-Net[12]相比较提升8.52%和3.69%,与性能表现较好的Zhang-Net[13]相比,准确率提升4.02%和1.39%;隐写算法为S-UNIWARD[15]时,两种嵌入率下,所提模型与Yedroudj-Net[12]相比,准确率提升13.64%和10.46%,与Zhang-Net[13]相比,准确率提升5.44%和2.96%。实验结果表明,本模型在两种隐写算法不同嵌入率下,检测准确率均高于另外3种模型,这主要得益于Mlpconv的引入,在模型的前两层使用Mlpconv代替传统的卷积层,可以显著提升模型的检测准确率。
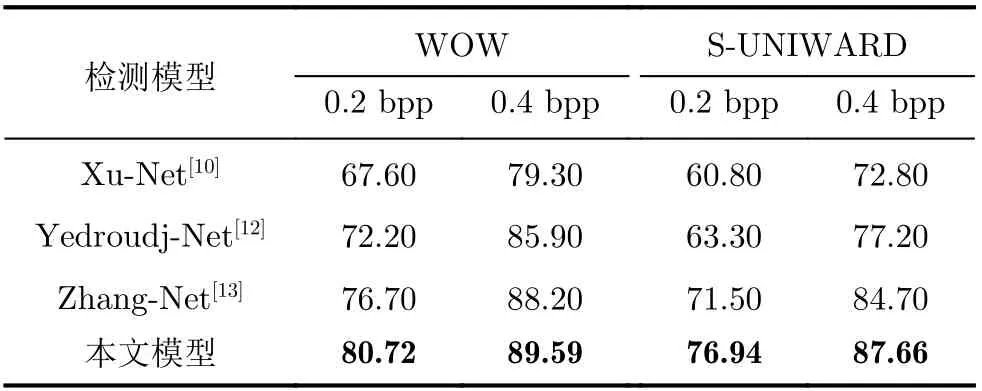
表2 本文模型与其他模型的对比结果(%)
4.4 通道加权对检测准确率的提升
该模型中加入了通道加权机制,通过SE模块使模型执行特征重校准。为了验证通道加权的有效性,将原本的模型与加入SE模块之后的模型进行了对比试验,其中SE模块涉及到一个缩减率r的参数设置,在不同的缩减率r下进行了实验,实验表明根据第1层全连接层的输入通道数对r进行调整,保证输出通道数缩减到2时模型检测准确率表现最好,即当输入通道分别为30, 32, 64, 128时,参数缩减率r相对应地设置为15, 16, 32, 64时可以在准确率和复杂性之间实现良好的平衡。在WOW[14]和S-UNIWARD[15]两种隐写算法的0.2 bpp, 0.4 bpp两种嵌入率下,所提模型进行通道加权前后的对比实验结果如表3所示。
从表3可以看出,所提模型在加入通道加权的机制后,相较通道加权之前,在不同隐写算法的不同嵌入率下,检测准确率可提升0.44%~0.71%。因此,在已经设计好的模型中加入所提通道加权机制,可以进一步提升隐写检测模型的检测准确率。
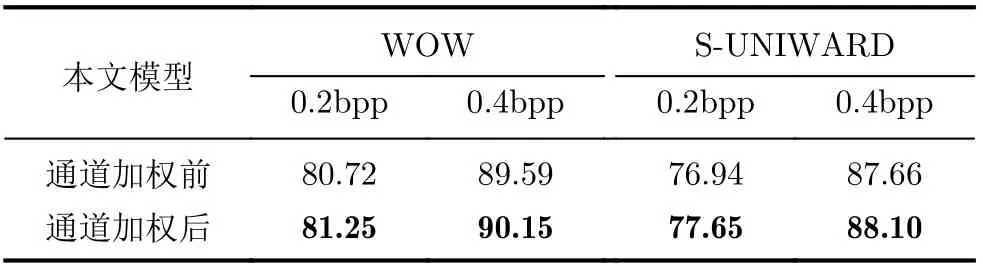
表3 通道加权前后模型的检测准确率(%)
5 结 论
基于多层感知卷积和通道加权的图像隐写检测模型,首先在预处理层中改进卷积核的扩充尺寸,将30个高通滤波器按照尺寸大小,分别扩充为17个3×3和 13个5 ×5大小,避免出现因填充过多的0而抑制残差图像;其次使用多层感知卷积层代替传统的线性卷积层,增强模型对高阶特征的表达能力,提高检测准确率;最后在模型中加入通道加权的模块,对不同的卷积通道赋予不同的权重,使模型选择性地强调对检测结果更有利的信息特征,进一步提高模型的检测准确率。通过在不同隐写算法、不同嵌入率下进行的实验结果表明,与现有的CNN检测模型相比,本文模型在检测准确率上有明显的提高。
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
潍坊学院学报(2020年2期)2021-01-18
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
电子制作(2018年1期)2018-04-04
制导与引信(2017年3期)2017-11-02
