
基于深度学习的眼底视网膜图像疾病分类研究
2022-08-19 01:29:02李果璟夏秋婷
传感技术学报 2022年5期
李果璟,夏秋婷,李 宏
(杭州电子科技大学自动化(人工智能)学院,浙江 杭州310018)
眼底是人体唯一能直接看到血液循环状况及微循环结构的部分[1]。 传统眼底检查的流程是患者前往医院拍摄眼底照片,眼科医生依据图像进行诊断。 但日益上升的患者人数造成专业眼科医生短缺,医生工作愈发繁重等问题逐渐显现。 并且,仅仅凭靠医生肉眼观察分析的传统诊断方法所带来的效率低下、误诊、漏诊等问题也不容忽视。 因而,利用计算机技术辅助眼底诊断,进行眼底健康筛查十分必要。
糖尿病(Diabetes Mellitus,DM)和眼底病变的发生存在一定的关联性,由胰岛素分泌缺陷或者胰岛素作用障碍造成的糖尿病会给患者带来血糖升高,血管性改变等后果[2]。 在全球范围内,糖尿病引发的眼底视网膜病变(Diabetic retinopathy,DR)是致盲的首要因素,是许多国家成年人失明的最主要病因之一[2-4]。
深度学习[5-10](Deep Learning) 是机器学习(Machine Learning)方法中的一种。 深度学习在眼科上的应用目前取得了很多成果。 Gulshan 等人[11]在2016年就利用Inception-v3 结构将深度学习技术应用在糖尿病眼底视网膜病变的诊断上,且实验结果十分成功;Muhammad 等人[12]设计了一种基于Alexnet 网络与随机森林方法混合的深度学习方法(HDLM),基于OCT 眼底图像对52 名青光眼患者眼底图像进行是否为青光眼的诊断;Felix 等人[13]设计的神经网络与随机神经结合的模型,对年龄相关性黄斑病变进行12 个等级的分类。
本文利用全局信息对整个眼底图像进行特征提取,随后进行分类。 其创新点在于,提出了一种针对眼底视网膜图像的多疾病多标签分类的解决方案;针对视网膜图像中多种疾病的多标签分类,提出了构建多分支模型多任务学习的解决方法;为增强模型对病灶学习能力,引入了注意力机制来提高疾病分类的精度;采用多模型融合技术,对不同结构的神经网络进行融合以提升模型效果。
1 材料与方法
1.1 数据和预处理
本文所用数据集来源于2019年北京大学“智慧之眼” 国际眼底图像智能识别竞赛(Peking University International Competition on Ocular Disease Intelligent Recognition,ODIR-2019),由北京上工医信科技有限公司提供。 数据来源于在上工医信合作医院及医疗机构进行眼健康检查的患者,数据提供了3500 组结构化脱敏信息作为训练集。 以下简称数据集为ODIR。
从医学角度上分析病灶特征,正常眼眼底图像中血管清晰,包括小血管在内的多个血管走行方向明确,视盘呈正常淡红色。 无絮状物或结节状物体出现。 而糖尿病视网膜病变的眼底图像上可能会存在微动脉瘤(Microaneurysms,MA),软性渗出(Soft Exudates,SE),硬性渗出(Hard exudates,EX)以及出血(Hemorrhages,HE)等症状。 微动脉瘤是由于毛细血管壁局部变薄而膨胀引起的,他们被认为是糖尿病视网膜病变发生时最早可见的体征。 渗出是由于毛细血管内血浆的渗漏,再根据颜色及边界是否明显区分为硬性或软性渗出。 浅层的出血通常呈火焰状,在视网膜深层的血管破裂将导致斑点状圆形病灶[14]。
1.2 基于深度学习的眼底多疾病分类器方法实现
1.2.1 实验环境
本文提出了新的眼底视网膜图像病变检测分类方法,并进行优化。 本实验设计多组对比实验,先确定了整体的分类器模型构建思路: 选择以Resnet50[7]为主干网络,在此基础上对结构进行修改,结合特征融合技术并采用多任务学习得到基准模型。
通过设计多组对比实验,实验环境配置表如表1 所示,所设计的深度学习方法实现是基于Pytorch1.1.0 以及torchvision0.3.0 框架。

表1 实验环境配置
1.2.2 评价指标
本实验利用留出法进行模型选择和评估,选择所有数据中的90%左右为训练数据,10%为测试数据。 本实验为多标签分类问题,输入示例可以由多个标签进行标记且不互斥。 采用的评价策略分为两个部分,首先是对于所有类别评估模型整体的准确率(accuracy,acc)、基于标签的评价指标(f1-score)、受试者工作特征曲线下面积(Area of receiver operating characteristic curve,AUC)以及杰卡德指数(Jaccard Index);其次,针对每个类别,进行acc、f1-score、AUC、查准率、敏感性(Sensitivity)以及特异性(specificity)的评估。 通过综合指标的考量,更为全面地判断模型性能好坏。 上述指标大多借助混淆矩阵得分统计,如表2 所示。
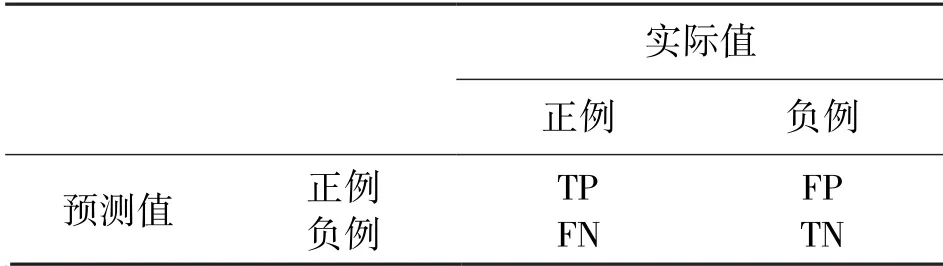
表2 混淆矩阵分析
准确率表示所有被预测正确的数据比例,计算公式为:

查准率(precision)表示预测值为正例时预测正确的比例,计算公式为:

敏感性表示真实值为正例的情况下,预测正确的比例,计算公式为:

特异性(Specifity)表示预测值为负例的情况下,预测正确的比例,计算公式为:

F1-score 事实上是查准率和敏感性的调和平均数Fβ的一种特殊情况,来评估样本不平衡情况下的模型总体表现。 其计算公式为:

分类过程中按照不同阈值设定,可得到一系列的横坐标为假阳性率(false positive rate,FPR)和纵坐标为真阳性率(true positive rate)即敏感性数值对,并按照假正例率进行排序。 然后将阈值设为最大值,那么所有的样本均为负例,再按照排列顺序将阈值设为每个预测值,可绘制得到曲线。 该曲线为受试者工作特征(Receiver Operating Characteristic,ROC)曲线。 该曲线右下方面积为AUC,AUC 越大表示性能越佳。
Jaccard 指标是预测值和真实值都为正例占预测为正例或者真实值为正例的比例,其所代表的含义是比较两个样本之间的差异程度,Jaccard 指数越大,说明差异性越小。 假设标签集合为T,预测结果为P,计算公式可以表示为:

1.2.3 特征融合与多任务学习
本实验中包含两组对比实验,分别为:
①用于选择输入模式,验证本实验中对输入进行特征融合是必要的。 ②不同的输出策略对结果的影响,设计适用于本实验的多任务学习方案。
同一位患者的左右眼存在一定相关性,从而进行猜想:训练模型同时参考左眼和右眼图像信息将提高实验结果。 为验证该猜想设计如下实验:
对ODIR 信息标签表中“Left-Diagnostic Keywords”和“Right-Diagnostic Keywords”采用正则匹配手段,依照关键词信息,提取并生成相应的左眼和右眼各个疾病的单眼级别的标签(image label)。 在预测的时候,根据同一患者的ID 选择出左右眼,然后利用训练好的模型分别针对其左眼和右眼进行预测,然后对双眼结果进行融合得到最终诊断结果。在预测诊断阶段,综合左眼和右眼结果进行融合,并整合成诊断意见,指出患者是否存在相应眼底疾病。
采用信息标签表中已有数据(双眼各疾病类别标签)。 相应采取的训练策略是先将左眼和右眼分别读入,然后将双眼图像做拼接处理后输入卷积神经网络进行训练。 输出结果即为患者诊断信息。
最终训练集和验证集中各类别数据分布如表3所示,其中训练集为9417 张,验证集为290 张。 其中,N 表示正常眼,D 表示糖尿病视网膜病变,G 表示青光眼,C 表示白内障,A 表示年龄相关性黄斑病变,H 表示高血压,M 表示近视。 在训练策略上,设置初始学习率为3×10-4,每8 次迭代完成后学习率衰减为原来的0.6;批量大小表示网络每一次输入的样例个数,本实验中设置为10。 实验所采用的优化器是SGD,动量设置为0.9,网络损失函数采用二元交叉熵。

表3 训练集与验证集各类别数量及比例统计
2 结果
如表4 所示,双眼级别多任务学习除AUC 指标外,在其他指标上均比单眼突出,验证了双眼级别预测模型效果比单眼级别效果更好。 在特异性、敏感性、查准率和F1-score 上,双眼级别模型结果比单眼级别更优。

表4 基于单/双眼级别不同输出分支模型结果统计
单眼与双眼级别多分支情况下每个类别的分类情况评价指标对比如图1 所示。 从准确度来讲对于正常眼(N)以及糖尿病视网膜病变(D)的分类效果最差。

图1 单眼或双眼级别多任务学习模型每个类别评价指标对比
实验2 中,同样参数条件下,对比双眼级别多任务学习模型及其分类效果。 分析loss 曲线及ROC曲线,如图2,双眼级别单分支模型未能成功收敛,效果十分不理想。 由此,模型训练结构为多眼级别多分支结构。

图2 双眼级别单分支模型训练
最终在迭代了总共32 次后,模型最佳结果各项指标如表5,将其定义为基准模型Resnet50_M。

表5 Resnet50_M 模型整体评估指标
2.1 超参数优化
针对当前所获得的基准模型Resnet50_M,进一步调整参数来优化,设计了以下方案:
①更改学习率衰减策略,将训练得到模型记为new_lr 观察Resnet50_M 模型loss 下降曲线。 仅调整学习率衰减策略,即始终保持3×10-4不变,Resnet50_M模型训练时其他超参数设置均不改变,重新训练模型。
②更改loss 函数为Focal Loss,将训练得到模型命名为focal_loss。 与方案(1)中其余超参数保持一致,进行训练,并且设置Focal Loss 中γ=1,α=1。
如表6,重新训练后,new_lr 模型的准确率、AUC、F1-score、Jaccard 有所提升。 但是再进一步采用Focal_Loss 方案后,部分指标略微有些下降。

表6 Resnet50_M/new_lr/focal_loss 模型评估指标
从单个类别的多项评估指标来看,如图3 所示,new_lr 以及focal_loss 效果均比Resnet50_M 优良。new_lr 以及focal_loss 模型查准率较优,表明模型正样本预测的准确率较高,也代表对正样本的“过滤能力”较佳。 对于不同类别在敏感性评估前三种模型各有所长。 使用Focal Loss 时,效果略微下降。

图3 Resnet50_M/new_lr/focal_loss 在单类别中评估指标
2.2 注意力机制
本实验中,将SE 模块添加至Resnet50 结构中,记为SE_Resnet50_M,并尝试更换zuiho 新的主干网络为Xception 及孪生网络。 训练数据集预处理方式都与其他设置与new_lr 模型基本相同,但由于内存有限,batch size 只能设为8。 将学习率初始化为3×10-4,每迭代32 次后衰减为原来的0.2,即在loss下降较为平稳时候,主动调整学习率继续训练。
由表7 可以发现,SE-Resnet50_M 使模型整体效果提升较大。 acc 和Jaccard 指数大幅度提升。 但Xception_M 模型中,acc 下降较大,更换孪生网络后模型未能拟合。
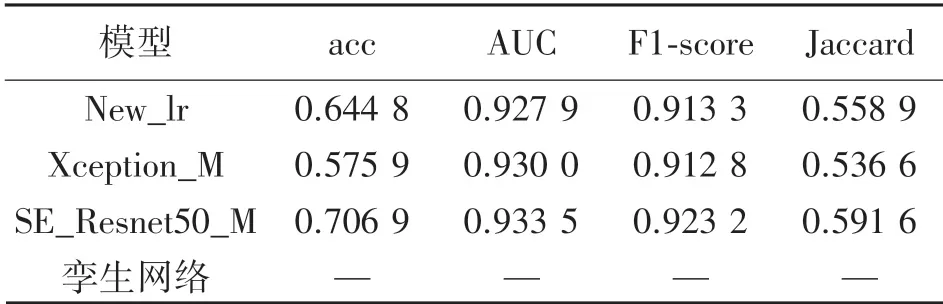
表7 Resnet50_M/SE-Resnet50_M/Xception_M评估指标
从图4 看,SE_Resnet50_M 在高血压(H)上的查准率、敏感性和f1-score 中出现了0 值,这说明高血压类别较难正确分类。
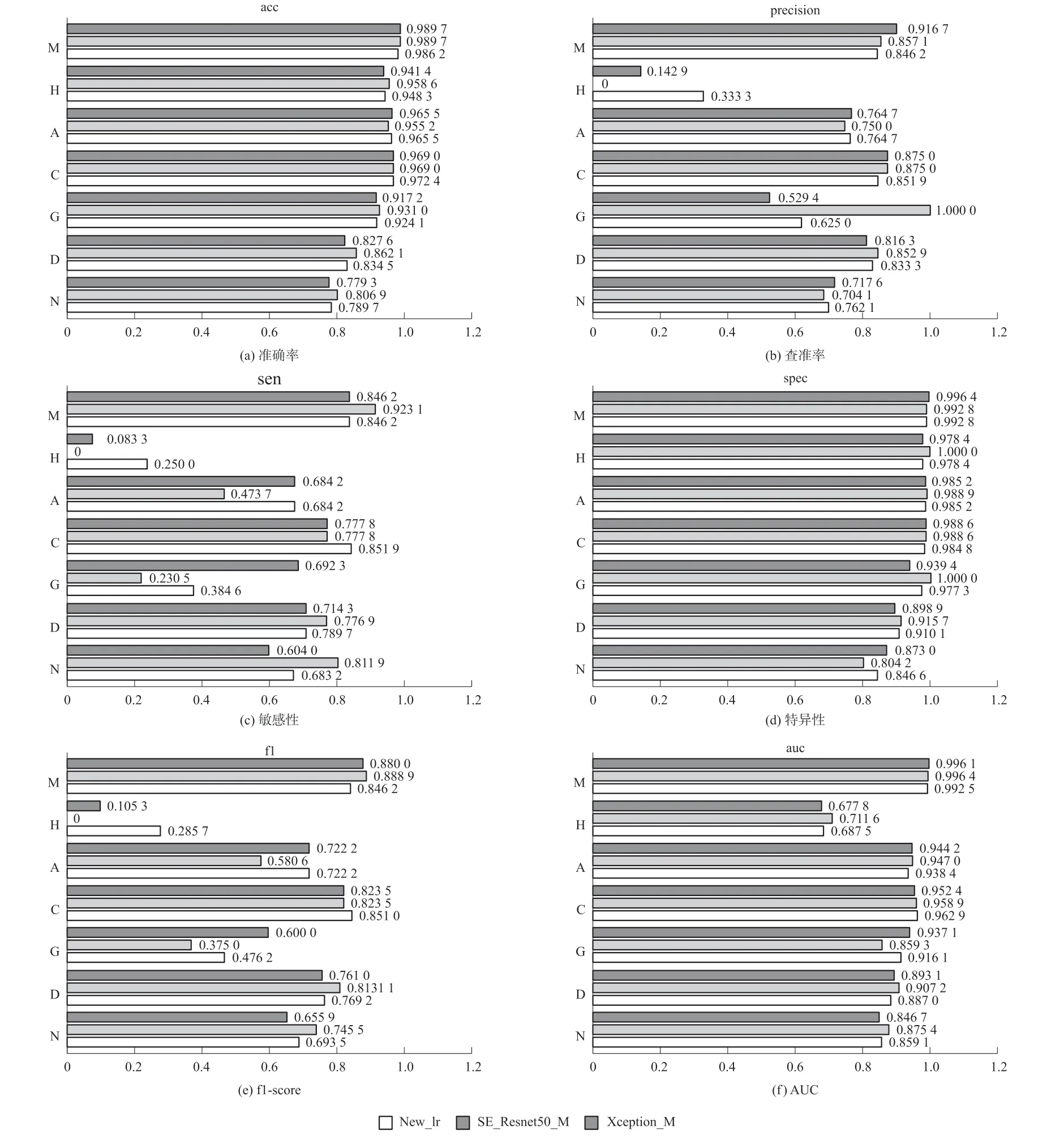
图4 Resnet50_M/SE-Resnet50_M/Xception_M 在单类别中评估指标
2.3 模型融合
将Resnet50_M 与SE_Resnet50_M 使用加权平均法实现模型融合,如表8 所示,其中,α表示Resnet50_M的权重,γ表示SE_Resnet50_M 的权重,两个模型在不同的权重比例下,得到结果为表8。

表8 不同权重比例下模型评估指标
因此,在α=0.5,γ=0.5 时候,模型融合效果为最佳。 对比基准网络Resnet50_M,最终结果在其基础上有所提升。
从单个类别的结果来看,最终得到结果如表9所示。 从准确度acc 来看,正常眼(N)和糖尿病(D)预测结果最差。 在本实验中,AUC 考虑了阈值变动情况,为二分类中最常用,评估价值最高的指标。Gulshan 等利用Inception-v3 结构在两个数据集上分别进行验证得到的AUC 分别为0.991 和0.990。

表9 多模型融合后单个类别下模型评估指标
3 结论
本实验针对左右眼之间的相关性,提出了一种左右眼拼接的特征融合方法;针对视网膜图像中的多种疾病多标签分类,提出了利用多任务学习构建多分支模型的解决方法;为增强模型对病灶学习能力,引入了注意力机制来提高对疾病分类的精度;采用多模型融合技术,对不同结构的神经网络进行融合提升模型效果。
在确定模型架构为“双眼级别输入-网络-多分支输出”的情况下,进行参数优化,得到基准模型Resnet50_M。 在对比实验中,发现注意力机制有利于特征的学习,并且准确率大幅度提升。 利用多模型融合技术,综合考量Resnet50_M 与SE_Resnet50_M 模型预测结果,准确率提升了21.17%达到0.7103,AUC 提升了10.07%达到0.9458,F1-score 提高了4.620%达到0.9261,Jaccard 指数提高了36.94%达到0.6042。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11 09:53:56
基层中医药(2021年8期)2021-11-02 06:25:02
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:28
中医眼耳鼻喉杂志(2021年2期)2021-07-21 08:53:34
车迷(2018年11期)2018-08-30 03:20:32
家庭影院技术(2018年5期)2018-06-29 07:42:10
海峡姐妹(2018年3期)2018-05-09 08:21:02
家庭影院技术(2018年3期)2018-05-09 07:06:12
中学生(2017年13期)2017-06-15 12:57:48
湖南中医药大学学报(2016年1期)2016-12-01 04:08:18
