
轻量级自适应上采样立体匹配
2022-08-19 08:23宋嘉菲张浩东
计算机工程与应用 2022年16期
宋嘉菲,张浩东
1.中国科学院 上海微系统与信息技术研究所 仿生视觉系统实验室,上海 200050
2.上海科技大学 信息科学与技术学院,上海 201210
3.中国科学院大学,北京 100049
获取准确稠密的现实场景深度图对于自动驾驶、三维重建、机器人导航等人工智能视觉任务有着重要的意义。根据获取深度方式的不同,可分为主动式与被动式。具有代表性的主动测距方法有激光雷达。激光雷达具有抗电磁干扰能力强,检测精度高等优点,但获取的深度图稀疏并且在反光平面上的测距效果不佳。被动式测距则是利用场景在自然光照下的二维图像获取稠密深度信息,其中广泛使用的有双目立体相机。该双目相机采用立体匹配算法在左右两张经过校准的图像上,沿着极线寻找对应点的位置坐标,从而求得视差,继而通过三角化计算空间中对应点的深度信息。
随着深度学习的发展,MC-CNN(matching cost convolutional neural network)[1]首次采用卷积神经网络的方法学习左右图像的特征表达,来替代传统方法中手动设计的特征表达式(例如Census[2-4])进行代价体的计算;GC-Net(geometry and context net)[5]则是提出了第一个完全端到端的立体匹配模型。现阶段基于深度学习的立体匹配算法流程主要分为特征提取、代价计算、代价聚合、视差计算和视差优化五个阶段。为了减少立体匹配网络运行的计算量和显存消耗,PSMNet(pyramid stereo matching network)[6]选取特征提取阶段1/4 分辨率上的特征输出进行代价体的计算和聚合,在解码阶段通过三线性插值将1/4分辨率代价体上采样到原图尺寸进行视差计算。随着多分辨率层级网络在各大计算机视觉任务中的广泛应用,Yang等[7]将在低分辨率上得到的视差图通过双线性插值上采样到高分辨率,继而基于上采样后的视差进行仿射变换来进行更精细的视差预测。如今,端到端立体匹配模型更多地侧重实时性能,实时网络[8-10]为了更快的运行速度,选择在超小分辨率上(16x,8x)进行计算,并且采用层级线性插值上采样得到原图视差。
在端到端立体匹配算法的发展中,上采样逐渐成为其中的关键步骤。由于设备显存和算力的制约,在原图(例如1 280×960)上直接进行计算十分困难,因此在小分辨率尺寸上进行立体匹配计算成为主流做法。其中如何在上采样得到原图分辨率的同时尽可能还原下采样丢失的信息成为其中一个重点考虑的问题。除此之外,当算法应用在实际工程中时,模型的规模与计算量也是另一个重点考虑的问题。
常用无参数非深度学习上采样方案有最近邻插值和双线性插值方法,见图1,以图中红色点为例,红点的上采样使用了周围的4个点,但是其插值元素考虑的仅仅是像素的坐标位置值,并没有很好地考虑元素周围邻域的相关性和纹理、颜色信息。另一种上采样方案则是反卷积[11],见图1,其先通过补零扩大图像尺寸,接着进行卷积操作。该方案可以有权重地选择周边邻域进行插值,但同时也使得图像上每一个点都采用固定的同一个卷积核参数并且带来了大量的计算。

图1 双线性插值和反卷积过程Fig.1 Procedures of bilinear interpolation and deconvolution
针对上采样问题的研究在超分辨率(super-resolution)视觉任务中有着重点的探索。超分辨率问题在于研究如何使用低分辨率图像重建出相应的高分辨率图像。早期,SRCNN(super-resolution convolutional neural network)[12]网络使用三线性插值将低分辨率图像上采样到目标尺寸,接着使用三层卷积网络进行拟合得到高分辨率图像;ESPCN(efficient sub-pixel convolutional neural network)[13]网络采用Pixel Shuffle 的方案进行上采样,该操作使得大小为σ2×H×W特征图像被重新排列成大小为1×σH×σW的高分辨率图像;VSR(video super resolution)[14]网络通过在每个像素的时空邻域进行滤波上采样得到高分辨率图像。本文也将结合ESPCN中提出的Pixel Shuffle和VSR中提出的邻域滤波进行改进。
综上所述,本文的贡献点在于:(1)针对立体匹配算法中代价体上采样问题进行研究并改进;(2)提出了一个轻量级自适应上采样模块(lightweight adaptive upsampling module,LAUM),用以学习代价体中每一个像素的插值权重窗口,并且设计了多尺度窗口提高上采样能力,同时该模块具有大感受野和轻量化的特点;(3)在SceneFlow和KITTI2015数据集上的定性定量实验证明了LAUM模块的有效性。
1 算法描述
1.1 立体匹配算法描述
现有端到端立体匹配模型主要包含特征提取、代价体计算、代价滤波、视差计算、视差优化五个阶段,流程图如图2 所示。特征提取部分多基于ResNet[15]网络,选取其1/k分辨率(例如k=4)特征图作为下一阶段的输入;代价体计算阶段,则根据实现方法的不同,代价体结构可以分为两个大类,分别为3D([H,W,D])代价体和4D([H,W,D,C])代价体,前者通过相关操作[16-18]在通道维度上计算左图和变换右图的相关程度,后者的4D 代价体则是通过在通道维度(C)上叠加[5,19-20]或者特征相减[8]的操作来实现,本文基于3D 代价体展开,该代价体记作CV(cost volume):

其中,i=[0,1,…,Dmax],Fl、Fr依次为左右特征图。出于计算量的考虑,代价体计算和滤波阶段通常在1/4 原图甚至更低分辨率上进行,然后采用上述所提插值的方法将代价体上采样到原图尺寸。本文的主要研究方向就是针对这一阶段进行改进(图2 绿色部分,代价体上采样),通过轻量级的模块使得上采样的结果更为精准,减少信息损失,提高算法最终视差预测的精度。

图2 立体匹配流程图Fig.2 Procedure of stereo matching
1.2 上采样公式
为了得到输出特征图O∈ℝσH×σW×C中的每一个元素,在输入特征图I∈ℝH×W×C上使用上采样方程进行采样,其中σ表示上采样的倍数。更具体地,假设需要求得的目标输出像素点坐标为(xi,yi,ct),则上述上采样过程可以公式化地表示为:

其中,i⊂[0,H×W-1],t⊂[0,C],Ψ就是上述提到的上采样方程,σ则是上采样的倍数。
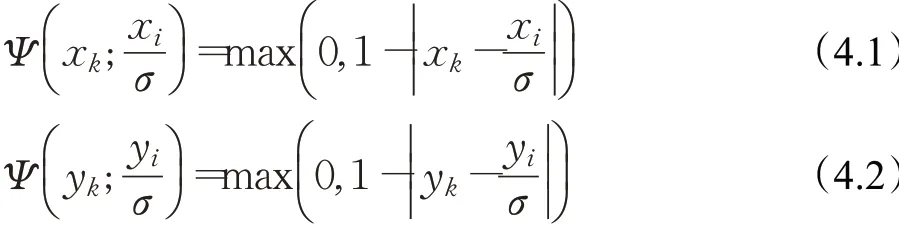
对于目标像素点(xi,yi,ct)∈O,其直接对应的源坐标为,如果直接使用对应源坐标点的值则是最近邻插值方法;当Ψ取方程为:则是常见的双线性插值方法。从该公式分析可见,双线性插值的参数只与对应像素点的横纵坐标有关,其取0至1之间的值作为权重参数进行插值,并没有很好地利用像素点周围的邻域纹理信息。例如处于边缘并且属于前景的像素点,在上采样过程中与背景的点坐标更近,则会产生一定的误差,如何选择正确的点进行插值十分重要。
本文提出的轻量级自适应上采样模块,就是为了解决这一问题。该模块不仅仅是根据坐标位置的远近来进行权重的确定,而是通过深度学习的方法为每一个像素点(xi,yi,ct)∈O寻找一组上采样参数,在输入特征图上采样从而提高整体的预测精度。该上采样方程可以记为:
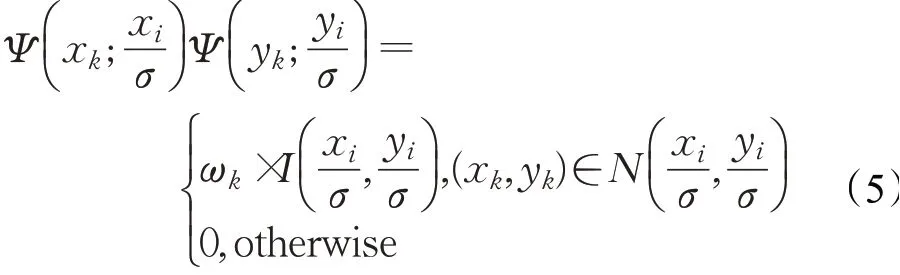
对比式(4.1)、(4.2)与式(5)分析可得,前者线性插值所使用的权重考虑的是坐标位置,后者本文提出的自适应上采样模块插值更多地考虑待插值像素周围的纹理信息。相比线性插值,本文提出模块更好地考虑了图像的RGB 纹理信息,为每一个像素点都学习了特定的上采样参数方程,同时也避免了物体边缘区域与内部区域使用相同上采样方案造成的误差。如此设计使得上采样模块有了更好的纹理感知能力。
1.3 轻量级自适应上采样模块
1.3.1 模块总览
所提的轻量级自适应上采样模块流程图如图3 所示。该模块的输入尺寸为H×W×C,首先经过纹理感知模块进行邻域信息的融合,并扩大每个点的感受野,此时代价体的通道数从C变为σ×σ×2×K×K(其中σ是上采样的倍数,K为卷积核尺寸)。随后,采用Pixel Shuffle 算法将代价体进行上采样,Pixel Shuffle 的具体做法则是使用通道(C)在空间维度(H×W)上进行顺序拼接,从而达到扩大的目的。上采样后代价体通道方向上代表的为每个像素点需要进行周边邻域采样所需的参数数量,以此来为每个像素点学习特定参数。

图3 轻量级自适应上采样模块Fig.3 Lightweight adaptive upsampling module
1.3.2 纹理感知模块
如图4首先采用一个1×1卷积层来将输入的通道数从C压缩到32,采用该卷积能很好地压缩后续步骤的计算量和参数,使得模块更加轻量化。然后,设计了连续的3个残差模块,每个残差模块首先经过3×3卷积、批归一化、ReLU 激活函数,为了获得更大的感受野,并且不增加网络的模型大小,设置每个模块的卷积空洞率依次为1、2、1,得到的结果再使用一个3×3卷积(不使用批归一化和激活函数)进行进一步信息融合。其中,每个残差模块的输入输出通道数都为32,使得整体模块的参数不随着输入通道数的增加而大量增加。经过3 个残差模块后,继续使用1×1 卷积将通道数从C压缩到σ×σ×2×K×K(其中σ是上采样的倍数,K为卷积核尺寸)来为后续做准备。
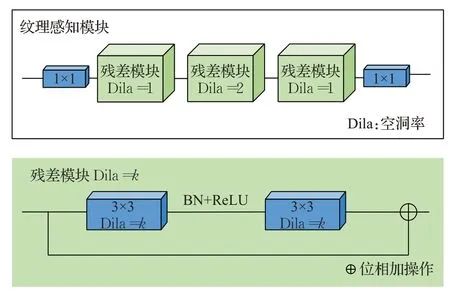
图4 纹理感知模块Fig.4 Context-aware module
1.3.3 多尺度窗口
传统上采样方法(例如双线性插值、最近邻插值)等使用的都是3×3邻域窗口进行插值,对应像素点周围的信息固然重要,但是大的感受野窗口,更多的点能够更好地辅助该点的上采样。因此,本文同时使用两种窗口进行插值,如图3 多尺度窗口所示,第一种记作K×K(例如3×3,5×5)窗口,另外一种则是空洞率为σ(上采样的倍数),参数量依旧是K×K的空洞窗口,因此总共的采样窗口数量(参数量)为K×K×2。K的值在实验部分具体分析和介绍。
1.4 轻量级分析
使用反卷积方案进行上采样同样可以为每个像素学习固定的上采样参数,但是会带来大量的计算。假设上采样模块的输入尺寸为H×W×C,输出尺寸为σH×σW×σC,采用反卷积上采样σ(上采样倍数)倍,则卷积所需的步长为σ,卷积核尺寸为2×σ×2×σ,则其理论计算所需要的参数量为C×(2σ×2σ)×(σC)。本文提出的自适应上采样模块参数主要集中在纹理感知模块和通道升维两部分,在纹理感知模块中,通道数固定为32,两个1×1 卷积层参数量为C×32+32×(σ×σ×2×K×K)(其中σ为上采样倍数,K为多尺度窗口),3个残差模块参数量为3×2×32×(k×k)×32(其中k为卷积核尺寸),因其固定输入输出尺寸为32,所以该部分参数量为固定值,也同时保证该部分计算量不随着上采样倍数的增加而大量增加,在通道升维部分,其参数量为C×(k×k)×(σC)。以K为3,k为3,σ为4,C为48为例,本文提出的自适应上采样模块参数量为反卷积上采样参数量的1/4。
2 实验结果
2.1 数据集
本文在两个主流双目数据集(SceneFlow[21]和KITTI2015[22])上进行了大量的实验,验证模块的有效性。
SceneFlow 数据集是虚拟合成的数据集,并且提供了稠密的真值视差,该数据集包含了35 454张双目训练集以及4 370张测试集。EPE误差(end-point-end error)是这个数据集使用的指标,该指标描述了像素点的平均预测误差。EPE误差以小为优。
KITTI2015 数据集是真实的室外场景,该数据集提供了稀疏的真值视差(车载激光雷达获取),其包含了200 张训练集以及200 张测试集双目图像。D1-all 是该数据集主要使用的指标,它表示在所有像素点中,预测值与真实值误差大于3 个像素的点占总像素点的比例。D1-all误差以小为优。
2.2 实验平台和方法
实验代码基于PyTorch 框架编写,实验平台使用的是NVIDIA 2080ti显卡。在整个训练过程中,全程使用Adam[23](β1=0.9,β2=0.999)作为神经网络的优化器,采取在SceneFlow 数据集上预训练,再在KITTI2015 上使用SceneFlow 训练得到的模型进行调优训练的策略。本文提出的轻量级自适应上采样模块(LAUM)将在PSMNet[5]和AANet[8]网络上通过替换其中三线性插值为本文的自适应上采样模块来进行验证。
基于PSMNet 网络:在两个数据集上将输入左右图随机切分成256×512 分辨率。在SceneFlow 数据集上,总训练轮数为20,并使用固定的学习率0.001;在KITII2015 数据集上,总训练轮数为500,初始学习率为0.001,200轮后学习率设为0.000 1。
基于AANet网络:在两个数据集上将输入左右图随机切分成288×576 分辨率。在SceneFlow 数据集上,总训练轮数为128,初始学习率为0.001,在第[40,60,80,100,120]轮时,学习率依次衰减一半。
对于所有数据集和网络,最大视差都被设定为192。除此之外,与所使用的PSMNet和AAnet保持一致,使用ImageNet 数据集的均值和方差来对输入图像进行正则化操作,并进行随机的颜色增强,翻折进行数据增强。
2.3 上采样方法分析
为了验证提出的轻量级自适应上采样模块LAUM的有效性,本文基于PSMNet 网络,在SceneFlow(EPE误差)和KITTI2015(D1-all 误差)数据集上对比了线性插值、反卷积以及LAUM模块的效果。其中线性插值是原文中所使用的上采样方案,LAUM模块具有很好的移植性,可以直接替换三线性插值方法进行实验。实验结果如表1所示,可以发现采用反卷积方式进行上采样所需参数量(#Params)和计算量(GFLOPs,Giga floating point operations)最多,但是误差也是最大的;反观本文的自适应上采样模块LAUM,在线性插值的基础上增加少量的参数(6.2%),在SceneFlow数据集上EPE误差降低26.4%,在KITTI验证集上D1-all误差降低17.81%,足以证明LAUM 模块设计的有效性和轻量化,更适合实际工程。
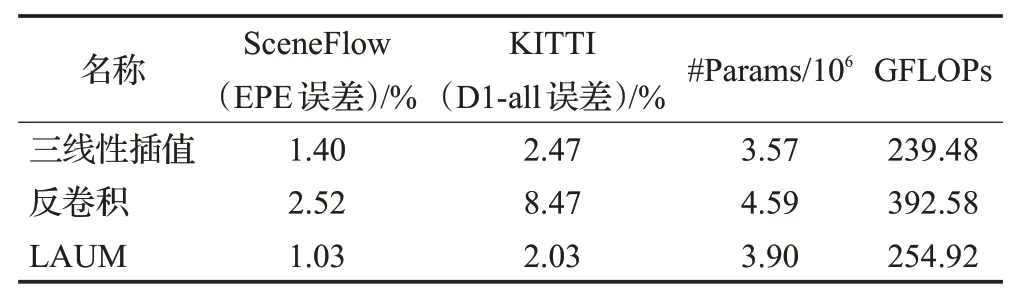
表1 基于PSMNet上采样模块分析Table 1 Analysis of upsampling methods on PSMNet
2.4 SceneFlow数据集结果
如表2 所示,在SceneFlow 测试集上对比了搭载LAUM 上采样模块网络与其他主流网络的结果。本文选取了两个代表性的网络PSMNet 和AANet 作为基础网络,直接替换其中的三线性插值上采样方法为本文的轻量级自适应上采样模块(名称后缀为-LAUM),前者是提升预测精度的代表网络,后者是提升速度立体匹配网络中的代表。

表2 SceneFlow数据集不同网络对比Table 2 Comparison with other networks on SceneFlow
基于PSMet 网络改进:首先分析基于PSMNet 网络的改进。PSMNet 网络具有两个版本,basic(基础)和hourglass(高精度),本文是基于basic 版本进行改进,目的是为了证明误差的降低并不是因为网络参数的增加,而是因为LAUM 模块设计的有效性。对比发现,本文的轻量级自适应上采样模块LAUM在basic的基础上带来了26.4%的误差降低,甚至超越了PSMNet 的高精度版本(-hourglass),但参数量仅仅为高精度版本的74.71%,计算量是其75.74%。与GWC-Net的对比可以发现降低8.8% EPE误差的同时,降低了42.8%的参数量和25%的计算量。和原网络以及其他网络的对比都证明了LAUM模块轻量化设计的有效性。
基于AANet网络改进:同样的结果也在基于AANet的改进上有所体现。本文的模块带来了10.3%的误差降低,值得注意的是在和GA-Net网络进行对比的时候,本文网络的参数量大于GA-Net,但是GFLOPS 远小于该网络,主要是因为GA-Net大量使用了3D卷积进行代价滤波。本文在表格中同时罗列了参数量和计算量进行对比。实验结果也证明了模块的有效性。
可视化结果:图5 可视化地展示了PSMNet-basic、PSMNet-LAUM、AANet、AANet-LAUM在SceneFlow测试集上的效果,并展示了各自网络的EPE 误差和误差图。误差图是通过预测图和真值相减得出。分析发现,基于LAUM 模块的网络有着更低的误差,同时在物体边缘处(SceneFlow数据集物体多且复杂)有着更好的预测结果,尤其在栅栏区域(PSMNet 和AANet 在这些区域都有大量错误),采用了LAUM模块后使得两个基础网络都在此区域有了明显的精度提升。

图5 KITTI2015和SceneFlow数据集效果图Fig.5 Visualization of 2 datasets(KITTI2015 and SceneFlow)
2.5 KITTI2015数据集结果
在KITTI 数据集上,本文仅在PSMNet 与AANet 上比较设计的自适应上采样模块(LAUM)和原文的效果。从表3中可以发现,采用本文设计的轻量级自适应上采样模块(LAUM),D1-all误差降低了15.4%和18.9%。正如之前提到的,LAUM模块设计的初衷是为每个像素寻找上采样窗口,其中也包括边缘像素点,边缘处的效果提升更能反映模块的有效性。因此,本文采用了Sobel边缘检测算子得到左图的边缘区域并且采取一定程度的边缘膨胀(见图6),从而验证在这些边缘区域的误差。可以发现,本文提出的LAUM 模块在提升整体精度的同时也能很好地提升边缘处像素点,各自在边缘处有了15.0%、16.7%的精度提升。图5也分别展示了两个基础网络PSMNet 和AANet 以及加入LAUM 模块后各自网络在KITTI数据集上的可视化效果,并展示了各自的误差。可以发现,尽管原本数据集(KITTI 数据集的视差真值稀疏)的误差值已经很小,但是LAUM依旧可以提升整体的预测精度。
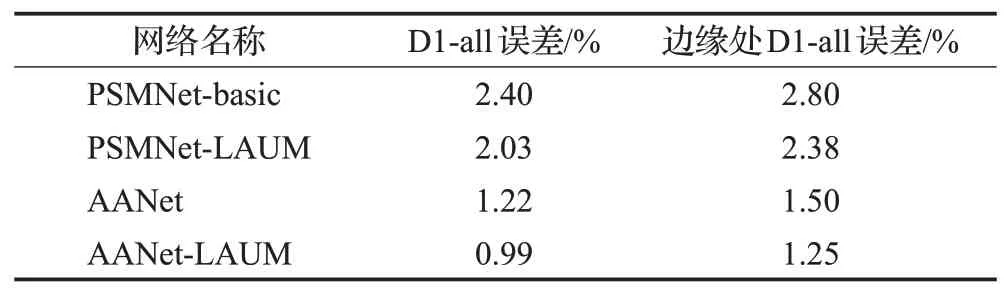
表3 KITTI验证集D1-all误差对比Table 3 Comparison of D1-all error on KITTI validation dataset

图6 KITTI数据集边缘图Fig.6 Edge map of KITTI dataset
图7可视化地展示了在边缘处的细节,可以发现采用了LAUM模块能够更好地保留物体(汽车)的形状轮廓,在边缘处有着更好的预测效果。车子表面是反光材质,反光区域对物体的整体性有着极大的影响,可视化结果表明,基于轻量级自适应上采样模块LAUM 的算法比线性插值方法能够更好地应对该情况。

图7 边缘预测细节可视化Fig.7 Visualization of details at edge area
2.6 消融实验-多尺度窗口
为了进一步验证本文提出的模块中多尺度窗口的有效性,设计了如下消融实验。该实验基于PSMNet网络进行,数据集使用SceneFlow,采用的测试指标是EPE误差。结果如图8 所示,其中K×K(例如3×3)表示使用单窗口进行插值,K×K×2 则表示使用本文提出的双窗口。图中所列参数量依次从9 到50 进行对比。比较3×3×2与3×3窗口,可以发现双窗口的设计可以有效降低14.2%的误差,与5×5 窗口的比较也可以证明误差的降低是因为模块设计,而不是更多的参数量带来的。当窗口参数量达到7×7 时,误差有了明显提升,这也是因为在纹理感知模块中通道数被设置成了32(出于轻量化目的),当窗口参数量大于这个值,会出现信息的冗余,因此会带来精度的降低。

图8 不同窗口对预测精度的影响Fig.8 Effect for prediction of different window sizes
2.7 上采样窗口参数可视化
为了验证LAUM 模块能够很好地感知周围邻域的纹理信息,本文通过可视化窗口权值来体现,具体实验设计如下:LAUM模块是为高分辨率输出的每一个像素学习一个上采样窗口权值,将每一个像素的权值全部在低分辨率对应的位置累加,则可以得到在低分辨率输入中每个像素对上采样的贡献度。图9 为上采样窗口权值可视化图,颜色越深,值越小。从图9 中可以发现车子边缘处的权重累加值接近零,意味着边缘处的点几乎不参与上采样的过程。边缘处具有歧义性,本文提出的LAUM模块学习到的参数更多地落在了非边缘区域,窗口权值的可视化结果以及在数据集上的精度提升都证明了设计模块的有效性。

图9 上采样窗口权值可视化Fig.9 Visualization of upsampling weights
3 结束语
本文针对端到端立体匹配网络中的关键步骤(代价体上采样),提出了轻量级自适应上采样模块LAUM,用以解决线性插值纹理信息使用不足和反卷积计算复杂的缺点,进而提升最终视差预测的准确度。在SceneFlow和KITTI 数据集上的结果也证明了本文模块设计的有效性。更重要地,提出的LAUM模块参数量极少,复杂度几乎可忽略不计。同时,可以十分便捷地替换到任何使用线性插值和反卷积的网络中。在接下来的工作中,将更多地侧重LAUM模块在实际场景中的泛化能力和低算力设备上的实际运行速度。
猜你喜欢
计算机工程(2022年3期)2022-03-12
小型微型计算机系统(2022年1期)2022-01-21
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
计算机与数字工程(2020年11期)2020-12-23
科教导刊·电子版(2016年23期)2016-10-31
现代计算机(2016年3期)2016-09-23
电脑知识与技术(2016年15期)2016-07-04
哈尔滨理工大学学报(2016年1期)2016-05-31
现代电子技术(2015年18期)2015-09-16
