
基于树莓派及深度学习的柑橘识别系统设计*
2022-08-17 05:03陈品岚张小花朱立学李浩林
中国农机化学报 2022年9期
陈品岚,张小花,朱立学,李浩林
(1. 仲恺农业工程学院机电工程学院,广州市,510225; 2. 仲恺农业工程学院自动化学院,广州市,510225)
0 引言
近年来,随着社会经济的发展,水果的产量正在逐年增长,在2020年我国的果园面积为12 280 khm2,同年水果产量已经达到了289 620 kt。柑橘作为主产水果之一,其种植面积和产量每年都有小幅度增加,在2019年其占我国园林水果种植面积和产量的21.32%和24.08%[1]。柑橘测产是为产后服务、市场供求分析和项目实施等提供科学依据的一项具有重要意义的工作。因此设计一种轻便式的柑橘识别系统可为柑橘测产提供一定的设备支持,同时也可以为水果采摘机器人的识别系统提供一定的技术支撑。
水果外观的特征因生物学的特性而有很大的不同,另外,自然环境的复杂性和时间变化也会增加水果外观的变化。国内外众多学者对自然环境中的果实识别分割方法进行了多方面研究。Kurtulmus等[2]使用颜色和Gabor纹理的特征分析方法识别了未熟的柑橘,其识别正确率达到75.3%,但对枝叶覆盖的水果的识别效果较差。目前深度学习算法在复杂环境下对目标表现出良好的识别能力。Zhang等[3]提出一种改进型R-CNN(Regions-based Convolutional Neural Network)的苹果树枝条识别方法,使用深度和索引(Depth & Index,D & I)的融合检测,提高了苹果树枝条识别准确率。岳有军等[4]改进了Mask RCNN网络,对复杂环境下的苹果进行识别,增加加权损失函数来提高识别精度,其识别精度为92.26%。武星等[5]使用了轻量化网络Light YOLOv3(You Only Look Once v3)对复杂背景下的苹果进行检测,改进了卷积块和损失函数,并使用学习优化技术,最后其平均精度可达94.69%。赵德安等[6]也使用YOLOv3对苹果进行目标检测,平均精度为87.71%。彭红星等[7]提出改进型SSD(Single-shot Multibox Detector)深度学习水果检测模型,增加了网络层数和使用了迁移学习,对在不同环境内的多种水果的平均检测精度达88.4%。毕松等[8]提出基于Darknet19网络模型的柑橘果实识别方法,对自然环境中存在多重干扰的柑橘识别准确率达到86.9%。对于上述文献所使用的硬件设备相对于树莓派(Raspberry Pi)来说,其体积较大,在一些果园中穿梭存在一定的困难。
国内各种识别系统被应用在树莓派上。牛犇等[9]使用树莓派为基础构成的实时人脸表情识别系统,检测采用Haar-like特征算法,分类器模型为深度学习卷积神经网络模型。江美玲等[10]使用树莓派为基础构成的实时服装识别系统,使用SSD检测框架。本文为设计轻便式的柑橘识别系统,采用了树莓派为系统硬件基础,基于深度学习SSD网络框架,对比不同训练次数的识别结果,并根据环境光照强度对图像使用直方图均衡化处理。同时,接收GPS(Global Positioning System)数据,确定区域柑橘密度,进行数据可视化。
1 系统总体方案
1.1 系统总体框架
本文系统由树莓派4B硬件平台、摄像头模块、光照强度传感器模块和GPS定位模块等硬件部分,同时包括树莓派操作系统、虚拟环境、TensorFlow2.2.0、labelimg、OpenCV4等软件部分共同构成。树莓派4B使用1.5 GHz四核ARM Cortex-A72处理器,4 G内存,并引入USB3.0接口,支持双频无线Wi-Fi,5 V/3 A的USB-C接口供电,具有良好的性能和丰富的接口。Python语言的可读性高而且面向对象的特性对于本系统的开发来说非常适合,故使用Python3编程语言进行柑橘识别系统的开发和设计,同时也是为了能更好地在树莓派上对系统进行测试和验证。系统总体框图如图1所示。
1.2 系统流程
系统整体的工作流程为启动树莓派并处于待机状态,从命令行窗口进入已经安装好TensorFlow的虚拟环境,运行柑橘识别函数,将树莓派摄像头采集到的柑橘图像传输至柑橘识别模块,在对柑橘进行检测之前,要测量环境光照情况和进行系统定位,再对图像进行预处理,通过图像预处理可以提高模型识别的准确率,尽量降低由于光照问题对图像识别质量的影响。然后在柑橘识别模块上使用已训练好的SSD神经网络模型进行柑橘识别,将识别的结果进行标识和计数,同时也将结果显示在显示屏上,以便查看,如图2所示。
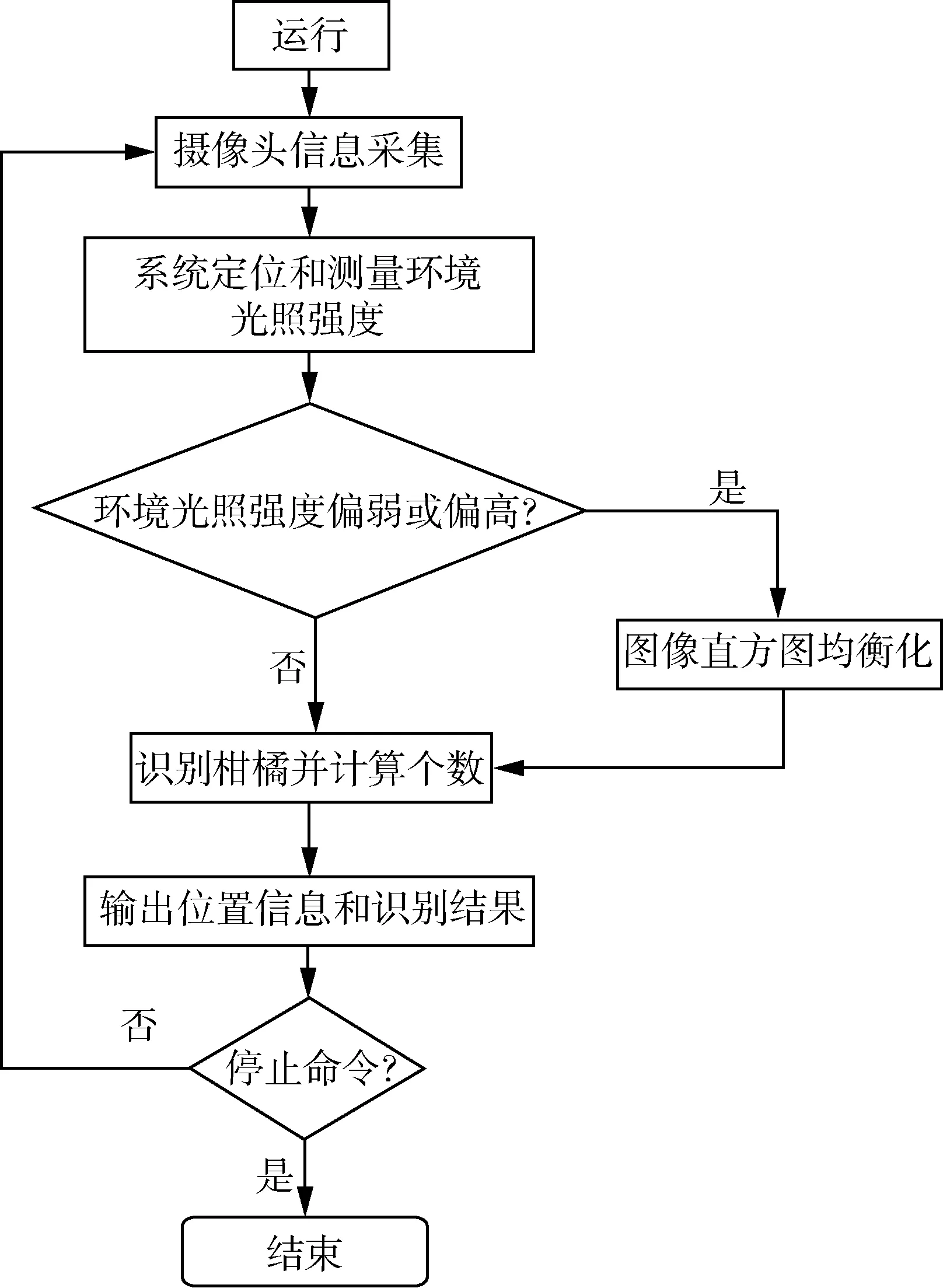
图2 系统工作流程图Fig. 2 System work flow chart
2 系统硬件模块设计
2.1 摄像头模块
在果园内对柑橘进行识别计数,为提高统计效率,所使用的摄像头视场角应尽可能大,且适合树莓派使用,因此,本系统选用的摄像头模组为树莓派专用的HBV-1509B-130型号模组,其对角视场角为130°,传感器像素为1 080 pixel,焦距可调,参数满足系统要求,且成本较低。HBV-1509B-130模组使用的接口为CSI(Camera Serial Interface)接口,树莓派有其对应的CSI接口,使用排针将两接口相连,配置树莓派内部参数,即可完成摄像头模块的调用。
2.2 GPS定位模块
本系统的运行环境一般情况为果园等一些户外地带,而且对于GPS模块的启动时间要求并不高。因此,本系统的GPS模块可以使用的芯片为GY-GPS6MV2。它使用陶瓷片的尺寸相对于其他的模块来说较大,对GPS信号接收较好。同时它有3种不同启动方式,分别为冷启动、温启动和热启动。
树莓派与GY-GPS6MV2芯片之间的数据传输方式为串口传输,而树莓派4B内存在两个串口,分别是硬件串口、mini串口,本系统使用硬件串口与GPS模块进行通信。使用硬件串口之前,需要在树莓派内将硬件串口和mini串口的内部映射关系进行调换。GY-GPS6MV2芯片有4个引脚,将GY-GPS6MV2芯片的VCC接到树莓派5 V的引脚,GND接GND,RX接TX,TX接RX,即分别接到树莓派4B的4、6、8、10引脚,即可通过串口读取GPS信息。
2.3 光照强度传感器模块
环境光照的强弱,会对识别的结果产生影响,为提高识别率和识别速度,故模块对环境的光照检测要快速。本系统的光照检测模块选择为GY2561模块芯片,其核心采用TSL2561芯片。它可以快速地将环境的光照强度检测出来,并输出数字信号。其芯片参数如表1所示。

表1 TSL2561芯片参数Tab. 1 TSL2561 chip parameters
此芯片能使用I2C或SMBus对数字信号进行传输,本系统使用的通信方式为I2C通信。通过命令寄存器控制要访问的寄存器地址,控制寄存器芯片的启动或停止,读取数据寄存器,经过位运算和加法运算之后,便可生成对应ADC通道内的采样值,采样值经过转换计算即可得到检测到的光照强度。GY2561模块芯片有5个引脚,将它的VCC接到树莓派3.3 V的引脚,GND接GND,SDA接SDA0,SCL接SCL0,即分别接到树莓派4B的1、9、3、5引脚。由于在检测过程中并不需要使用到中断信号,所以INT不需要连接到树莓派的引脚上。
3 柑橘识别模型构建
本文使用的目标识别算法为SSD,以树莓派作为硬件平台,应用的软件平台为TensorFlow2.2.0+Python3.7+OpenCV4。SSD算法是基于多框预测,网络结构主要包含了基础网络(Base Network)、辅助卷积层(Auxiliary Convolutions)和预测卷积层(Predicton Convolutions)。它结合了YOLO和Faster R-CNN的优点,达到了速度快并且准确度高。其网络结构采用VGG16卷积神经网络架构,但在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络架构如图3所示。
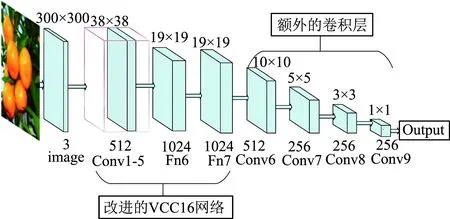
图3 SSD网络架构Fig. 3 SSD network architecture
SSD网络算法输入图片为300像素×300像素,网络浅层主要用来提取图像中小目标特征,而深层网络主要提取图像中大目标特征。在自然环境下所采集的柑橘图像,柑橘目标在图像中多表现为小目标特征,故柑橘识别网络需在浅层网络对图像提取更多的目标特征。VGG16网络输入图片为224像素×224像素,共有13个卷积层和3个全连接层,其卷积层均是使用边长为3,步长为1的卷积框。而SSD对VGG16做了改进,把全连接层FC6和FC7转换成3×3卷积层和1×1卷积层,去除全连接层。此外,池化层的步长为2、边长也为2的卷积框换为步长为1、边长为3的卷积框,并增加网络卷积层数,加深网络结构,其目的是为了增加特征图的数量,提高检测精度。同时,此改进也有利于网络对浅层目标的特征提取,进而提高网络对柑橘的检测精度。
3.1 SSD算法先验框设置
在多尺度特征提取中,需要建立真实框与先验框的匹配关系,通过交互比例确定类别,计算位置偏差和置信度。因此,先验框的选择对于提高训练速度、降低目标偏差至关重要。先验框尺度
(1)
式中:m——特征层数;
smin——最低特征层尺度;
smax——最高特征层尺度。
SSD先验框是由每层的特征图经过卷积之后产生的,根据设定的特征层尺度smin和smax,得到各个特征图的先验框尺度sk。
3.2 数据集创建
本文所需要使用的数据集为柑橘数据集,在搜索COCO数据集官网后,发现COCO2017版柑橘数据集共有1 699张图片,其中标注框6 399个,平均每张图片3.77个,该数据集的图像多为高清、单角度、背景简单、水果少、标注识别难度小,而且它与柑橘在自然场景中的实际情况有很大的不同。因此,本系统的数据集采用的柑橘图片分为两部分,一部分为fruit360数据集中背景简单、数目少、标注识别难度小的柑橘图片,另一部分为自然果园中背景复杂、数目多的柑橘图片,使用人工对数据集进行标注。
使用labelimg对图片中的训练目标进行标注,形成数据集,标注过程中只有一个类:orange。本文数据集共手动标注了约600张图片,整体的标注结果优于开源数据集,因此适合作为该模型的训练数据集来标注和生成XML格式文件。标注原则:标注所有可见的柑橘类水果,标注可见水果的明显部分,不标注只露出一小部分或者难以实现检测识别的水果剩余部分,尽量将标注框与果实边缘贴合,减少背景等不必要的干扰。将带注释的XML文件打包好,用于后面的训练模型[11-12]。
3.3 损失函数算法
损失函数是位置误差Lloc与置信度误差Lconf两者的加权和。即
(2)
式中:x——匹配orange类对应的先验框与真实框的权重参数;
c——先验框对背景、orange类别预测概率;
l——orange类先验框位置;
g——orange类真实框位置;
N——匹配到真实目标(Ground Truth)的先验框数正样本量,如果N=0,则将损失设为0;
α——用于调整confidence loss和location loss之间的比例参数,默认α=1。
α可以衡量模型预测的好坏,用来表现预测与实际数据的差距程度。
3.4 训练过程
在训练的时候,首先要确定训练图片中的真实目标对应哪些先验框。在每张训练图片中每个真实目标都会存在一个准确程度最大的先验框进行匹配。与真实目标匹配的先验框为正样本,与背景匹配的先验框为负样本。若存在一些先验框没有真实目标与之匹配,但其准确程度大于识别置信度(本系统设定的识别置信度为0.5),那么这些先验框也与对应的真实目标进行匹配,故代表着一个真实目标可能会和多个先验框进行匹配。但是一个先验框不可以和多个真实目标进行匹配,如果多个真实目标和一个先验框准确程度大于识别置信度,那么先验框只和准确程度值最大的那个真实目标进行匹配。
在训练过程中,真实目标能对应多个先验框,而由于真实目标比先验框少很多,即背景会比orange类多很多。为确保orange类和背景样本保持在一定的比例,SSD会对背景进行抽样,抽样时按照置信度误差,进行从大到小排列,选择误差相对比较大的n个背景来训练,确保orange类和背景样本比例在1∶3左右,同时也减少了运算量。
3.5 预测过程
在预测过程中,首先要确定预测框中的是否为orange类,根据预测框对应的置信度值去判断。预测框对应的置信度值小于设定值则判断为背景类,同时去除掉此类的预测框。对应每一个预测目标都会存在多个置信度值大于设定值预测框与之对应,因此需要对这些预测框根据置信度值从大到小进行排序,同时也要注意预测框的位置,防止预测框的位置不在图片之中,然后选取n个置信度值最大的预测框。最后,把这些预测框用非极大值抑制算法(Non-Maximum Suppression,简称NMS算法)进行筛选,得到预测结果。
4 基于树莓派的柑橘识别试验
本文SSD网络训练在Ubuntu18.04操作系统下进行,系统硬件配置为Intel E5 2640V3处理器和英特尔RTX2080显卡,显存为8 G。网络训练使用TensorFlow2.2.0深度学习框架并配置CUDA10.1及CUDNN7.6.5进行加速。将训练好的SSD网络模型搭载在树莓派上运行,树莓派所安装的系统为Linux系统,使用的TF卡内存为16 GB。系统的操作方式为远程登录操作,使用VNC服务可以通过VNC viewer软件在计算机上对树莓派进行远程登录操作进入可视化操作界面,有利于识别系统的使用和操作。
4.1 不同训练次数的识别对比
在训练过程中,将数据集分成9∶1的训练集与测试集,训练次数为100次。随着训练次数增多模型的训练集损失值和测试集损失值最终会保持稳定,变化较小。为测试该算法在不同训练次数模型下的识别性能,选用了训练次数为5、40、70、100次进行性能测试,其模型的训练集损失值、测试集损失值和准确率如表2所示。从表2中可以看出,对数据集进行优化和训练次数增多,准确率也会有所改善,当网络训练100次后,其柑橘识别准确率最高,约为92.4%。但由于树莓派硬件条件的限制,识别速度约为0.22 fps。
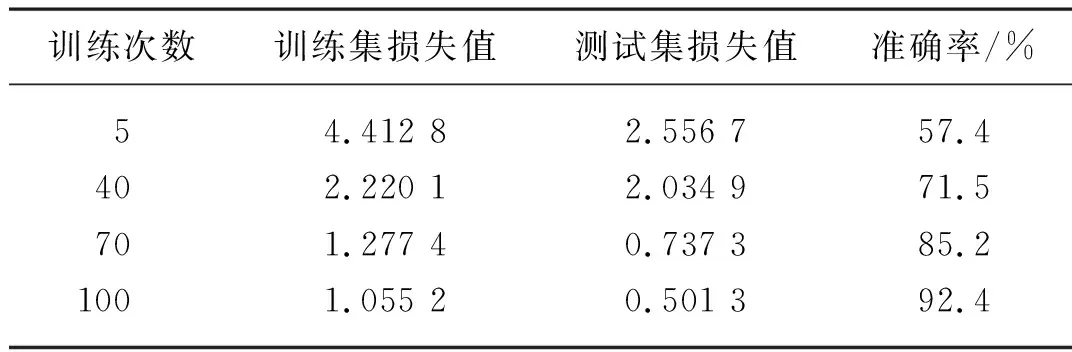
表2 模型训练次数与损失值关系Tab. 2 Relationship between model training times and loss value
在本网络训练中,每次模型训练都可以得到一个权重文件,为观察不同训练次数对果园柑橘的识别情况,使用训练次数为5、40、70、100次的权重文件对柑橘进行目标识别预测,得到的识别结果如图4所示。不同的训练次数对柑橘的识别结果存在较大差异,训练次数越高,识别准确率越高,即模型越好。训练次数为100次时权重文件的模型可以将大部分的柑橘目标识别出来,只有小部分应遮挡严重未能准确识别。

(a) 训练5次

(b) 训练40次

(c) 训练70次

(d) 训练100次 图4 训练次数结果对比Fig. 4 Comparison of training times and results
4.2 直方图均衡化前后的识别对比
在图像采集过程中,常常因为光线因素的影响,会造成采集的一些图像较亮或较暗,较亮会使得识别的目标区域高光,较暗会使得识别的目标区域模糊。对于光线的过亮或过暗都会对识别的准确率产生一定的影响,导致一些真实柑橘目标无法被正确检测识别。当环境光照过弱或过强时,需要升高或降低识别图像的对比度,即使用直方图均衡化。使用直方图均衡化,图片整体亮度会发生变化,较暗区域对比度升高,较亮区域对比度降低更均匀地分布在直方图上。在一般情况下,晴天室外的光照度约为30 000~130 000 Lux,阴天室外的光照度约为50~500 Lux,日出日落的光照度约为300 Lux。本系统所用的摄像头中,在果园内当光照度小于100 Lux时,拍摄的画面亮度过低,当光照度大于15 000 Lux时,拍摄的画面亮度过强。故当光照度小于100 Lux或大于15 000 Lux时,系统识别图像需要使用直方图均衡化。
对图像进行全局直方图均衡化会导致柑橘特征上的一些细节变模糊,为更好保留目标特征,故使用局部的自适应直方图均衡化。此方法在不影响图像目标特征的前提下,还能很好地减少光照对识别结果的影响。通过对光照不足的图像和经过直方图均衡化的图像进行识别,可以看到直方图均衡化后的图像识别效果更佳,对比前后的柑橘识别数目,直方图均衡化后的识别结果能更好地反映区域内的柑橘密度,如图5所示。

(a) 原始图像

(b) 图像直方图均衡化 图5 图像直方图均衡化后识别对比Fig. 5 Recognition and comparison after image histogram equalization
4.3 果园柑橘密度数据可视化
为测试本系统对柑橘的测产情况,在区域内均匀选取500个识别数据点,每个数据点的距离大于5 m,在识别过程中记录的数据主要有3个,分别是经度、纬度和柑橘数量。将识别结果的历史数据保存到.csv文件中,对GPS信息和识别的柑橘数量使用folium库在地图上做数据可视化,可以在地图上看到柑橘的区域密度,每一个数据点的识别距离约为5 m,如图6所示。图6中地图上柑橘区域密度与实际的柑橘区域密度较吻合,能较好地反映整体区域内的柑橘密度。
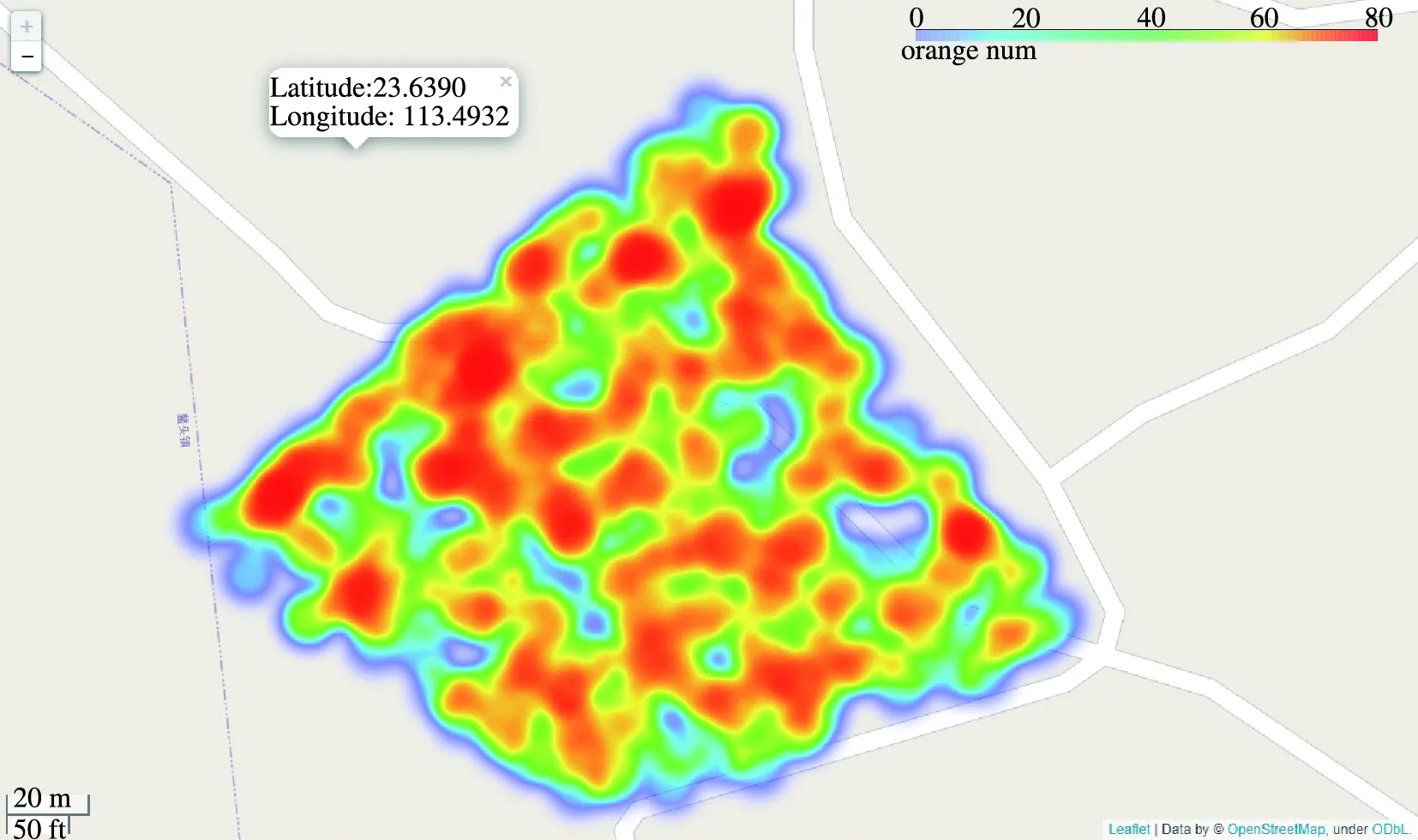
图6 柑橘密度数据可视化Fig. 6 Visualization of citrus density data
5 结论
1) 柑橘测产可为柑橘产后的果园智能化管理提供基础。针对目前一些识别设备体积大、成本高等问题,本文将树莓派与深度学习方法相结合,提出了一种基于树莓派及SSD的柑橘识别系统,搭建了一款轻便式的柑橘识别设备,实现对柑橘的准确识别。
2) 本文利用SSD实现对自然环境下柑橘果实的检测和识别,试验结果表明在训练次数为5、40、70、100次的情况下,其准确率分别为57.4%、71.5%、85.2%、92.4%。经过测试发现模型对果园中柑橘密集和稀疏等情况下的图像均有较好的检测识别准确率,但对于极少部分体积较小和枝叶遮挡较为严重的柑橘果实的检测识别准确率还有待提高。由于树莓派硬件条件的限制,本系统的识别速度差,约为0.22 fps,所以算法还有待改进。在光照影响的情况下,使用直方图均衡化其识别效果更佳。同时对识别所得数据进行可视化,能较好地反映果园内的生长状况,有助于果园的管理和生产。
3) 将基于树莓派的柑橘识别系统应用在采摘机器人的果实实时识别上,可以为采摘机器人的研制提供技术支撑,在未来具有良好前景和重要意义,并且随着软硬件和神经网络学习算法的不断发展,果园中的果实目标检测设备将会更加简便化,其识别算法的准确率会更高、速度会更快,采摘机器人技术也会继续发展升级,智能、精准、高效、经济、实用的采摘机器人将逐渐引用到果园中。
猜你喜欢
中国音乐学(2022年1期)2022-05-05
客联(2021年9期)2021-11-07
影像视觉(2018年12期)2018-11-29
成都理工大学学报·社会科学版(2017年4期)2017-09-08
中学生数理化·高一版(2017年2期)2017-04-25
初中生世界·八年级(2017年3期)2017-03-24
中小企业管理与科技·上旬刊(2016年12期)2017-01-05
岁月(2016年5期)2016-08-13
数码影像时代(2009年8期)2009-09-07
