
改进半监督GAN及在糖网病分级上的应用
2022-08-16 03:11岳丹阳罗健旭
计算机工程与设计 2022年8期
岳丹阳,罗健旭
(华东理工大学 信息科学与工程学院,上海 200237)
0 引 言
基于深度学习的人工智能医学图像分析[1,2]需要大量标注样本,医学标注成本较高,很难获取大量标注样本。针对糖网病标注样本少的问题,本文进行基于深度学习的半监督学习算法研究,并将其应用到糖网病场景下的小样本分类中。
在深度半监督算法中,深度生成模型获得了最广泛的应用[3]。常见的生成模型主要有自编码模型[4]、深度卷积神经网络[5]和生成对抗网络(generative adversarial network,GAN)[6]等。由于GAN强大的概率拟合能力,在半监督分类领域中获得了许多进展。Salimans等对判别器网络输出进行调整[7],同时进行分类和真假判别。Ali-Gombe等提出多任务判别器[8],对标签数据进行监督学习,对无标签数据进行无监督学习。Fu等提出编码生成对抗网络用于半监督分类[9],在GAN中添加一个编码器提取图像特征用于分类。基于GAN的半监督方法在医学领域也取得了许多应用,Li等结合DCGAN和FCM提出一种用于肺结节良恶性分类的半监督学习方法[10],Li等提出基于GAN的半监督学习模型用于乳腺彩超图像的良恶性分类[11]。现存的基于GAN的半监督分类方法主要对判别器结构调整,使其共同学习标签和无标签数据的分布,但是判别器同时分类和判别真假预测可能不相兼容,分类性能易受GAN稳定性的影响。另外,未考虑GAN生成的数据对分类性能的辅助,也未考虑提升生成性能以提高模型的概率拟合能力。本文基于Triple-GAN[12]算法,使分类网络与GAN既独立又对抗训练,在标签少的情况下,利用大量无标签数据和生成数据共同提升分类器的泛化能力。
1 半监督生成对抗网络Triple-GAN
Triple-GAN算法提出一种引入分类器与生成器和判别器三者共同对抗训练的方法进行半监督学习。Triple-GAN的模型结构如图1所示,由3部分组成:分类器C、生成器G、判别器D。C为输入数据提供标签信息,主要是从生成配对 (xG,yG)、 真实配对 (xL,yL) 和仅有图片xC这3种数据中学习数据分布生成标签信息y,C表征着条件概率分布pC(y|x), 产生的图像标签对 (xC,yC) 服从pC(x,y) 分布。G表征着条件分布pG(y|x), 负责为输入一对条件yG和先验分布z生成图像标签对(xG,yG), 服从pG(x,y) 分布。D唯一作用是判断图像标签对 (x,y) 是否来自于真实数据分布p(x,y)。
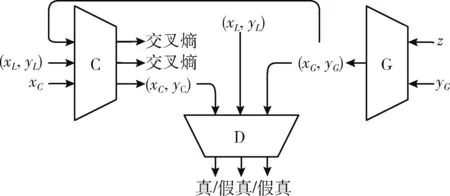
图1 Triple-GAN模型结构
Triple-GAN总的优化目标函数如式(1)所示
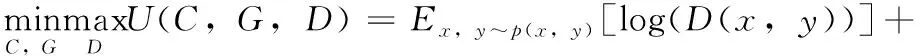
(1)
其中,α为常数,平衡C和G之间的相关重要程度,考虑平衡因素,一般设为1/2,E为分布期望。理想中平衡为p(x,y)=pG(x,y)=pC(x,y), 在实际训练中难以实现,故在分类器C上增加了一个标准监督损失函数RL和伪判别损失Rp, 如式(2)和式(3)所示
RL=Ex,y~p(x,y)[-logpC(y|x)]
(2)
Rp=EpG[-logpC(y|x)]
(3)
RL计算pC(x,y) 与p(x,y) 分布之间的差异,Rp计算pC(x,y) 与pG(x,y) 分布之间的差异,通过共同对抗训练使C、G和D互相博弈互相提升。
2 改进的Triple-GAN算法
Triple-GAN的生成性能和分类性能有限,网络结构比较单一,应用场景有限。本文对Triple-GAN的结构重新设计,提出改进的Triple-GAN算法,其中分类器使用适用性更好的多尺度分类网络。由于原Triple-GAN模型难以生成大尺度的图像,提出能够生成具有大范围关联性图像的生成对抗网络模型SEDA-GAN,即能提高生成质量,亦能应用在糖网病图像上。
2.1 多尺度分类网络
分类器使用残差网络ResNet-50作为主干网络,残差网络不仅深度较高,还具有优越的性能,解决了梯度消失和梯度爆炸的问题[13]。残差网络的结构如图2(a)所示,先经过7x7卷积网络、批归一化、ReLU和最大池化初步提取浅层特征,然后经过4个由瓶颈结构组成的layer层进行深层次特征提取,再使用平均池化和全连接层输出结果。
每经过一个layer层,获取的特征图包含着更深层次的语义特征,尺度缩小,但低层的特征所包含小目标信息也会随着下采样缺失。由于眼底图像上包含着许多小目标信息,本文提出多尺度分类网络(multi-scale classification network,MCN),引入多层特征做预测。MCN结构如图2(b)所示,去除原来的全连接层,layer2、layer3的特征经过3×3卷积和平均池化后与layer4层输出的特征进行融合,再经过两层全连接层进行预测,可以根据3种不同尺度的特征存在的有益信息进行类别预测。
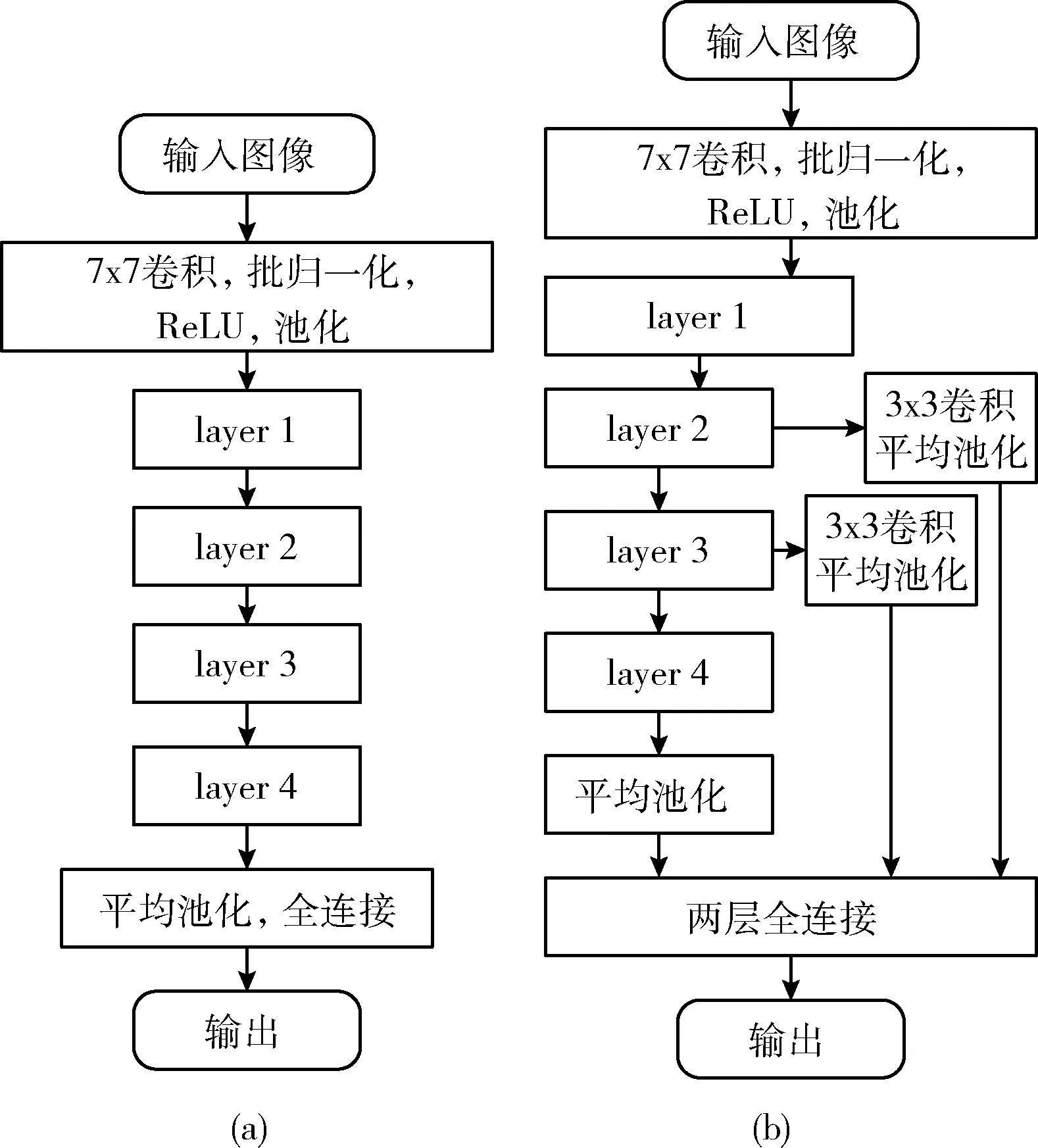
图2 残差网络结构
2.2 生成对抗网络
在Triple-GAN算法中生成图像质量越接近于目标数据,生成的图像标签对越有益于分类器的泛化能力。本文提出了一种压缩激活双注意力生成对抗网络(squeeze-and-excitation dual-attention generative adversarial network,SEDA-GAN),以BigGAN[14]模型为基础,从通道的角度提升GAN的生成性能。BigGAN在生成具有复杂结构的图像时还存在着一些困难,生成图像的目标结构分布不自然。SEDA-GAN从通道增强的角度做出两个方面的改进,详细如下:
第一,引入压缩激活[15](squeeze-and-excitation,SE)操作,对BigGAN中卷积块ResBlock提取的特征进行重校准,提出新的卷积模块SEResBlock。压缩激活操作从通道的方向上学习通道关联性信息,增强特征层中一些作用较强的特征层并削弱一些无用的特征层,使得网络的中间层特征更具表达能力,进而提升GAN的生成性能。
SEResBlock的结构如图3所示,图3(a)、图3(b)分别为生成网络和判别网络中的SEResBlock模块,SEResBlock模块在ResBlock结构中增加了压缩激活操作层SELayer,类别经过批归一化层共享嵌入到网络中。SELayer对上层经卷积块提取的特征M∈C×H×W进行平均池化,得到一个长度为C的压缩特征向量s。向量s经过由两个1×1卷积和激活函数ReLU、Sigmoid组成的两层非线性层学习得到一个长度为C的激活向量w∈(0,1)。 最后w经过通道倍乘对原来的特征M进行重校准得到新特征通道倍乘计算如下
(4)
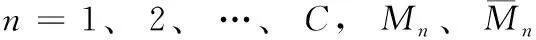
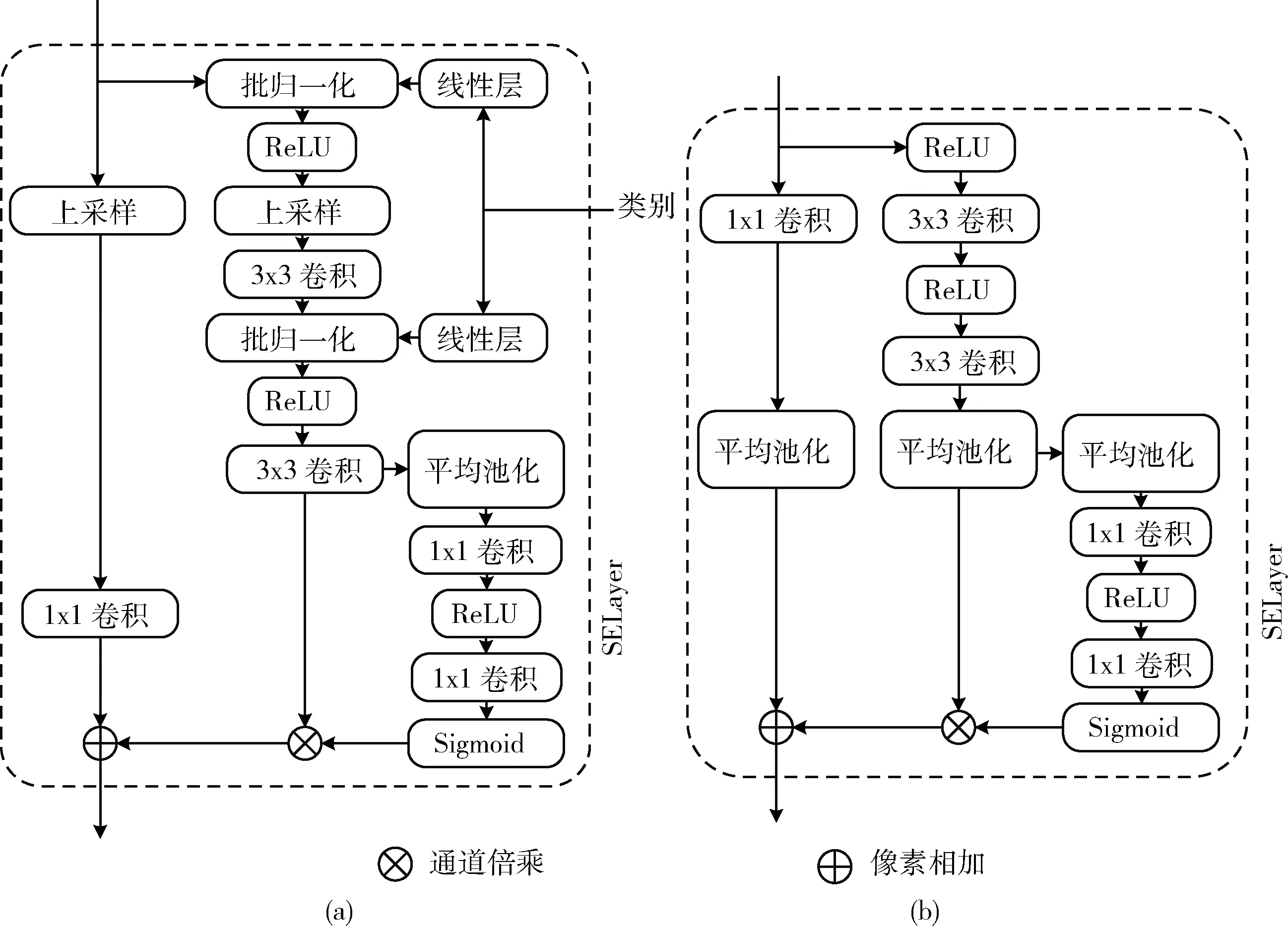
图3 SEResBlock模块结构
第二,引入了双注意力机制[16](dual-attention,DA),使GAN的特征能同时从特征的位置和通道空间上捕获大范围的结构关联信息,获取更加丰富广泛的上下文语义信息。BigGAN中的自注意力机制[17](也称位置注意力机制)建立的特征结构信息有限,难以生成复杂结构的图像。在网络的高级特征中,结构间的关联信息与特征通道也有关。DA结构如图4所示,由位置注意力和通道注意力两部分构成。其中特征A∈C×H×W同时进行计算得到位置注意力特征S∈C×H×W和通道注意力特征T∈C×H×W, 最后经过两个3×3卷积J(x) 和K(x) 进行融合,得到具有丰富结构信息的新特征U∈C×H×W, 如式(5)所示
U=J(S)+K(T)
(5)
位置注意力特征S的计算:如图4的Ⅰ部分所示,特征A经过3个1×1卷积提取,得到尺寸不变通道数为C/8、C/8、C的3个特征B、R、V,B和R重组成二维矩阵 [b1,b2,…,bN]、 [r1,r2,…,rN], 其中向量b和r长度为C,N为H×W。 重组后的B的转置与重组的R相乘并经过Softmax运算得到位置特征图P,P的每个元素值pji的计算如式(6)所示
(6)
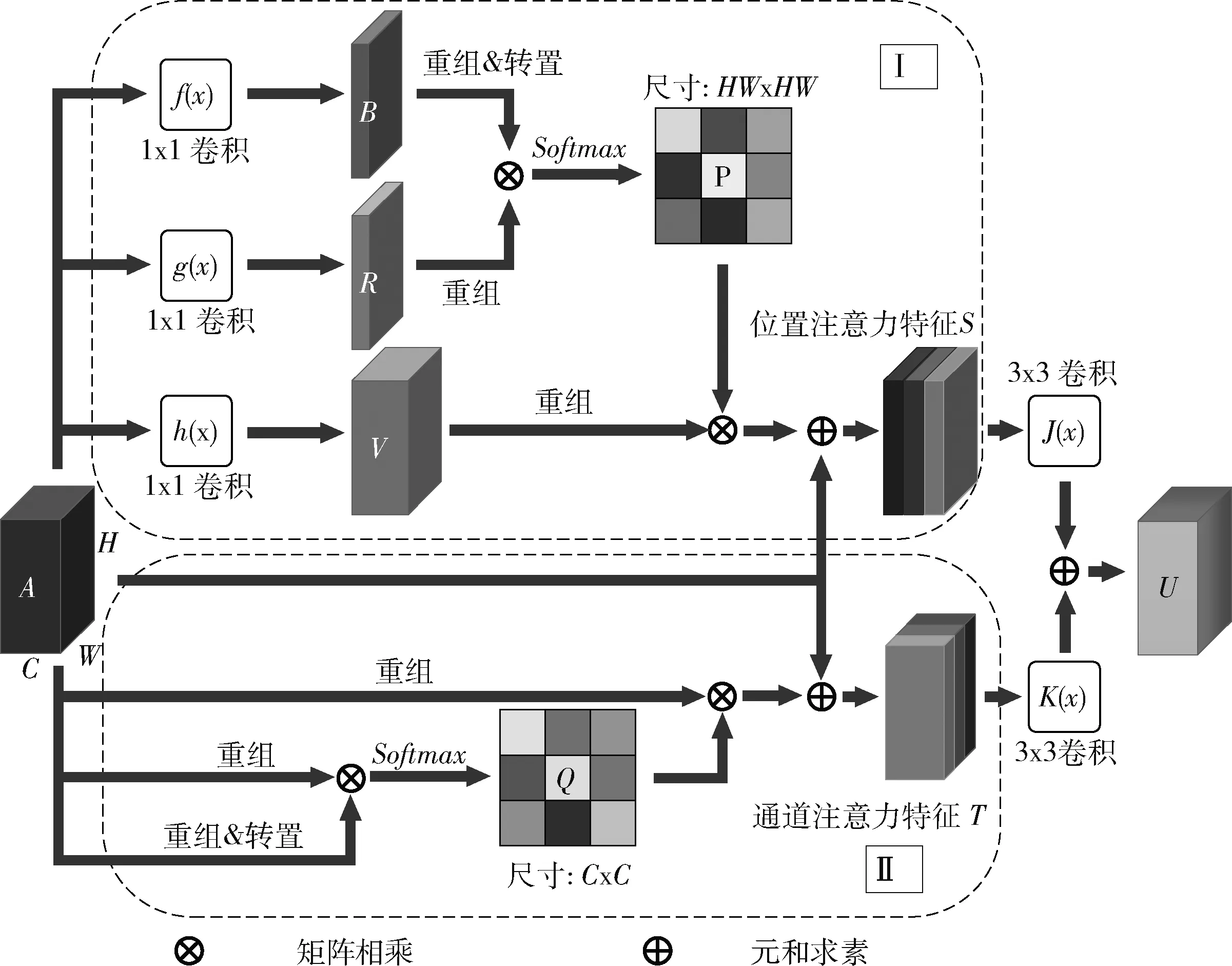
图4 双注意力机制结构
其中,i,j=1、 2、 …、N,pji建立了bi和rj位置间的关联信息。然后V重组后的特征 [v1,v2,…,vN] 与位置特征图P的像素点相乘后重组成维度为C×H×W的特征,再乘以一个学习权重λ与特征A相加便得到了位置注意力特征S,计算过程如式(7)所示
(7)
其中,j=1、 2、 …、N, 可以看出位置注意力特征S的每个位置包含着特征A所有位置间的关联信息。
通道注意力特征T的计算:如图4的Ⅱ部分所示,特征A直接进行重组得到二维矩阵A′=[a1,a2,…,aC], 向量a长度为N。然后A′与其转置相乘并经过Softmax运算得到通道特征图Q,Q的每个元素值qji的计算如式(8)所示
(8)
其中,i,j=1、 2、 …、C,qji建立了ai和aj通道间的关联信息。然后通道特征图Q的像素值与A′相乘后重组维度为C×H×W的特征,再乘以一个学习权重β与特征A相加便得到了通道注意力特征T,计算过程如式(9)所示
(9)
其中,j=1、 2、 …、C, 其中特征T的每个位置包含着特征A不同通道间的关联信息。
SEDA-GAN的网络框架如图5所示。图5(a)为生成
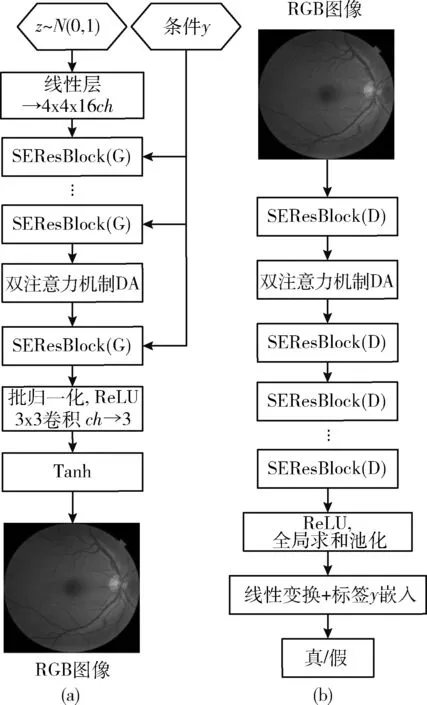
图5 SEDA-GAN网络框架
模型,输入为噪声向量z和类别y,z服从于标准正态分布,y嵌入到SEResBlock的批归一化层中,ch为64,双注意力机制DA放在网络的中后级特征间。图5(b)为判别模型,判别输入的RGB图像和标签y是否是真的,由SEResBlock和双注意力机制构成,结构与生成器对称,最终经过线性变换和标签y嵌入融合进行判断输入图像-标签的真假。
2.3 半监督网络的优化
GAN使用对数损失时, log(1-x) 在优化的后期梯度变化较大,不利于网络的平衡。使用铰链损失(Hinge Loss)时,梯度计算稳定,网络收敛速度也比较稳定[17]。改进Triple-GAN使用Hinge损失函数,如下所示:
判别器D的损失
LD=-Ex,y~p(x,y)[min(0,-1+D(x,y))]- (1-α)Ex,y~pG(x,y)[min(0,-1-D(G(z,y),y))]-αEx,y~pC(x,y)[min(0,-1-D(x,y))]
(10)
生成器G的损失
LG=-Ex,y~pG(x,y)D(G(z,y),y)
(11)
分类器C的损失
LC=-αREx,y~pC(x,y)pC(y|x)[min(0,-1-D(x,y))]-RL-αpRp
(12)
LD中α用于平衡生成数据与无标签数据,一般为0.5。LC中的pC(y|x)[min(0,-1-D(x,y))] 为无标签数据的离散损失函数,用于学习无标签数据的分布,源于强化学习算法的离散损失。αR和αp均为权重参数,可根据其对应损失对分类器性能的贡献调整参数的大小。整个半监督网络的优化分3个过程,如算法1所示。
算法1:使用最小批量随机梯度下降算法优化Triple-GAN的训练
fornumber of training iterationsdo
数据准备:
(1)采样mD个真实有标签的图像-标签对 (x,y)~p(x,y);
(2)从标准正态分布中采样mG个噪声z,使用G生成图像-标签 (x,y)~pG(x,y);
(3)采样mC个真实无标签数据,使用C生成图像-标签 (x,y)~pC(x,y)
优化D:使用梯度下降优化判别网络D,根据LD计算梯度更新参数θD
优化G:使用梯度下降优化生成网络G,根据LG计算梯度更新参数θG
优化C:使用梯度下降优化分类网络C,根据LC计算梯度更新参数θC
endfor
3 实 验
3.1 评价指标
改进Triple-GAN模型包含分类网络和生成对抗网络部分,因此需要衡量分类精度和GAN生成图像的质量。分类精度常用错误率(Error)评估,其计算如式(13)所示
(13)
GAN中常用Fréchet Inception Distance(FID)[18]指标衡量生成数据与目标数据分布之间的差异性来评价生成图像的质量。FID越小表示生成图像质量越接近真实图像质量,FID计算如式(14)所示,生成图像与真实图像通过Inception-v3网络提取得到特征向量,计算得到分布featx和featg, 然后再计算两种分布之间的Wasserstein-2距离,得到质量评估分数
(14)
3.2 CIFAR-10数据验证
CIFAR-10是一个用于普通物体识别的数据集,共有60 000张彩色图像,分辨率为32×32,分10个类,每类6000张图,50 000张用于训练,10 000张用于测试。为便于与Triple-GAN模型对比,在CIFAR-10上进行验证,验证MCN的分类性能、SEDA-GAN的生成性能和Triple-GAN半监督性能。
3.2.1 MCN性能的验证
为验证MCN的有效性,使用相同的数据处理和训练参数对改进前后的残差网络进行实验对比。在训练时对数据进行随机翻转、旋转,再标准化处理。训练的批量数为32,学习率初始为0.001,使用余弦退火学习率衰减策略调整学习率。
实验结果见表1,改进后的模型比改进前的模型错误率下降了2.33%,引入多尺度特征后对分类网络的性能有着一定的提升。
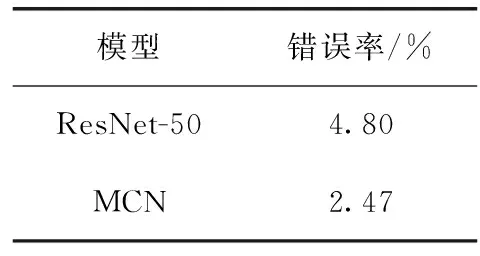
表1 ResNet-50改进前后分类错误率
3.2.2 SEDA-GAN的验证
为验证提出的SEDA-GAN的生成性能,与BigGAN在相同的实验参数下进行对比实验。SEDA-GAN使用了与BigGAN模型的相同的损失,生成器和判别器的学习率设为0.0002,总迭代1 000 000次,每1000次迭代学习率以0.999的比率衰减,使用了频谱归一化[19]稳定网络训练。
本部分设计了5组不同的实验在FID指标上评估,如图6所示,NA为未使用注意力机制的BigGAN模型,SA为使用自注意力机制的BigGAN模型,SE将SELayer层应用到NA组模型的ResBlock中,DA为应用双注意力机制的BigGAN模型,SE+DA为应用了SELayer和双注意力机制的模型SEDA-GAN。通过对比NA和SE组结果可以看出,应用SELayer后模型的收敛速度加快,说明SEResBlock的特征提取能力相比ResBlock更强;对比SA和DA组实验可以看出,使用了双注意力机制,模型可以得到更低的FID结果,DA建模的结构关联性更加丰富;应用了SELayer和双注意力机制的SEDA-GAN获得了更好的FID结果。经过多次实验取均值,结果见表2,提出的方法均带来了提升,SEDA-GAN模型的FID最低。
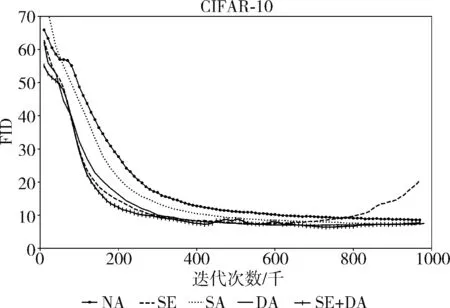
图6 生成对抗网络FID结果对比

表2 不同组实验的FID结果
3.2.3 改进Triple-GAN算法的验证
将改进的Triple-GAN在CIFAR-10上进行实验,验证改进模型的分类性能和生成性能。随机采样出N=2000和N=4000张数据作标签数据,剩余数据作无标签数据。
训练参数:标签数据、无标签数据、生成数据训练的批量数分别为32、128、128。分类器、生成器、判别器的学习率初始为0.0005、0.0002和0.0002,使用学习率衰减策略维持后期训练的稳定,衰减率为0.999,1000次迭代衰减一次。损失函数的参数αR和αp初始设为0,迭代10 000次时设为0.2和0.1。GAN训练的后期会出现模式崩塌,生成的数据质量变差会影响分类性能。为此在训练过程中增加了FID质量评估机制,使用最优模型的生成数据送入分类器中。
分类性能验证:在标签量N=2000和N=4000的情况下进行多次实验,测得平均错误率分别为10.65%和7.62%。原Triple-GAN算法在N=4000时错误率为16.99%,改进Triple-GAN的错误率降低了9.37%。同样在N=4000时,将αp一直设为0,去除生成数据的辅助,错误率仅为14.40%,可见生成数据的加入对分类网络的泛化作用较好,对分类性能的提升较高。为了对比改进的Triple-GAN算法在半监督算法中的优势,在N=2000和N=4000时与当前主流的半监督模型进行对比,结果见表3,改进Triple-GAN在标签量为2000和4000的情况下均取得最低的错误率。
另外,设置了不同标签量情况下的实验,见表4。随着标签量的增大错误率越低,标签量等于10 000时错误率已经比较接近ResNet-50的错误率,当使用25 000张标签数据时,分类的错误率比ResNet-50的错误率更低。
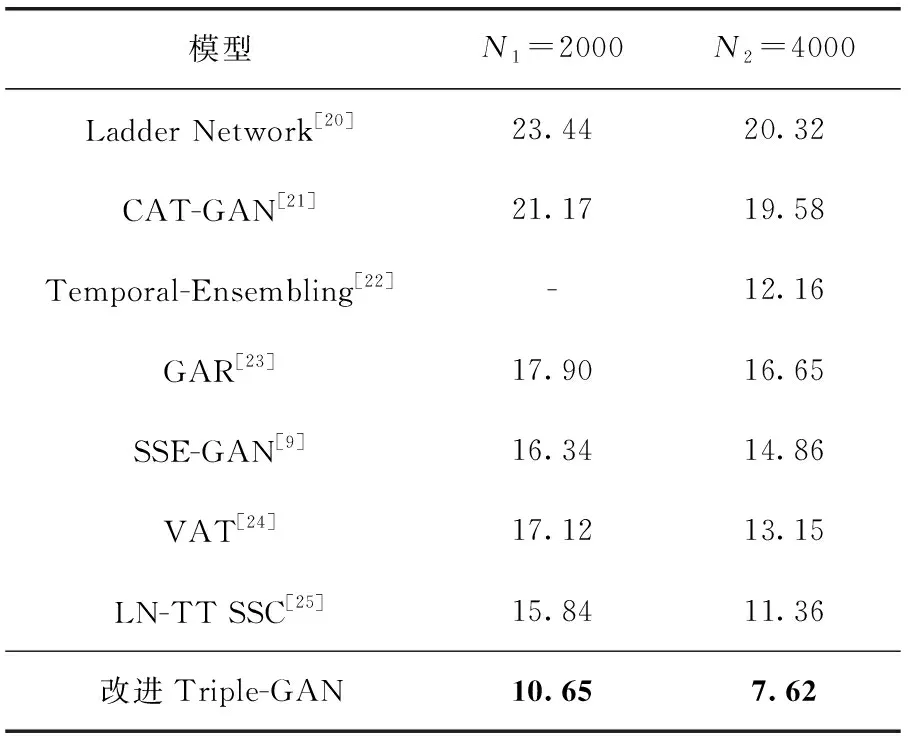
表3 CIFAR-10数据集上半监督模型分类错误率/%

表4 不同标签数据量下的分类错误率
生成性能验证:如图7所示,在标签量N=4000时与原Triple-GAN的生成图像对比,改进的Triple-GAN生成的图像更清晰,质量更好,更加具有多样性,且各类别间差异性比较明显。与目前一些常见的生成对抗网络模型进行对比,结果见表5,改进的Triple-GAN与提出的SEDA-GAN模型均获得较低的FID,改进后模型生成的数据分布与原数据分布更加相似。

图7 Triple-GAN改进前后生成图像对比
3.3 糖网病数据上的应用
糖网病,全称糖尿病视网膜病变,是比较常见的一种糖尿病引起的视网膜微血管并发症,严重可致人失明。国际标准中常将糖网病的严重程度分为5级:健康、轻度、中

表5 不同生成对抗网络FID评分
度、重度、增殖。本文实验数据由上海社区医院提供,共8000张图片,标注了2000张数据,分为dr0~dr4这5个等级。实验中随机选取800张作测试集,剩余1200张作训练集,其余6000例为无标签数据。
原始图像尺度规格不统一,进行预处理并截取感兴趣区域,调整尺寸为128×128,如图8所示,从左到右分别对应着dr0到dr4这5个等级的眼底图像。dr0级为健康的眼底图像;dr1级为轻度期,出现少量微血管瘤;dr2级为中度期,有一些眼底出血症状,视力衰退;dr3级为重度期,患者视力严重衰退,眼底出血较多;dr4级为增殖期,患者失明,有增殖血管形成,玻璃体出血。

图8 糖尿病视网膜眼底病变
由于数据总量较少,对数据随机水平垂直翻转进行增强。训练时标签、无标签、生成数据的批量数为16、32、32。分类器、生成器、判别器的初始学习率为0.0005、0.0001、0.0001。同时使用学习率衰减策略,衰减率0.99,每1000次迭代衰减一次。网络权重使用频谱归一化方法以稳定GAN训练,损失中的αR和αp初始为0,8000次迭代时设为0.2和0.1。
使用改进的Triple-GAN和MCN进行半监督和全监督实验,MCN的训练参数与章节3.2.1相同,多次实验的平均结果见表6。仅用标签数据进行全监督学习时,MCN的错误率为32.00%,改进Triple-GAN模型的错误率为12.75%。相比之下,半监督GAN方法利用无标签数据和生成数据可以大幅度提升分类器的泛化能力。同时在精确率、召回率和F1-score指标上对各类别进行测试,结果见表7,从中可知dr0和dr4级别的分类效果最好,dr2和dr3级的分类存在一些难度,分析病例图像,dr2和dr3级之间的部分眼底特征变化比较微小。

表6 糖网病数据分类错误率
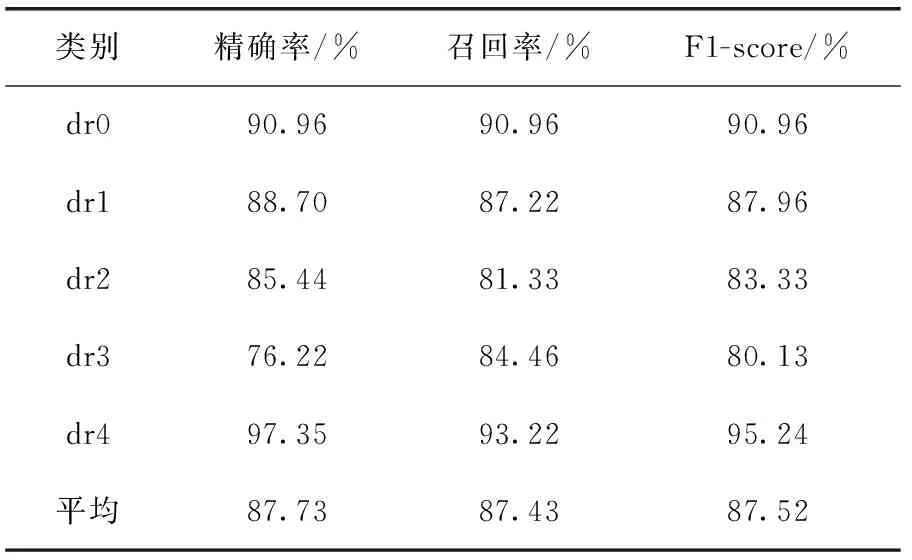
表7 糖网病数据各分类指标评估结果

图9 随机生成的眼底图像
另外,也对改进Triple-GAN生成的眼底图像质量进行评估,多次测试的FID均值为20.43。图9给出了随机生成的眼底图像,从左到右分别为dr0~dr5级,从中可以看出生成的眼底图像纹理也比较清晰,图像质量较好,与原图质量比较接近。
4 结束语
为提高半监督分类模型在糖网病分级上的精度,本文提出改进的Triple-GAN算法,重新设计网络结构与损失函数,将其应用到糖尿病眼底图像数据集上。改进点主要分为3点:①在残差网络中引入多尺度特征预测,提升网络分类性能,作为改进Triple-GAN的分类器;②提出压缩激活生成对抗网络SEDA-GAN,提高GAN的生成性能,作为改进Triple-GAN的生成对抗网络部分;③将对数损失函数换成铰链损失,提升网络训练的稳定性。在CIFAR-10上验证提出方法的有效性,并在糖网病分级上取得了较高的分类精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
计算机系统应用(2021年2期)2021-02-23
甘肃教育(2020年22期)2020-04-13
电子技术与软件工程(2019年18期)2019-11-18
新课程·上旬(2019年1期)2019-03-18
电子技术与软件工程(2017年14期)2017-09-08
教师·中(2017年3期)2017-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
试题与研究·教学论坛(2016年27期)2016-08-11
航天返回与遥感(2014年5期)2014-07-31
