
基于模糊C均值与主成分分析的故障检测研究
2022-08-15 09:33:34孙宏雨
自动化仪表 2022年7期
孙宏雨,李 元
(沈阳化工大学信息工程学院,辽宁 沈阳 110142)
0 引言
随着时代进步和科技发展,工业生产过程中的技术和产品不断更新,使人们对工业过程的安全性和可靠性要求越来越高。一旦在工业过程中发生故障,将会造成不可估计的财产损失和人员伤亡。因此,对故障检测与诊断方法的研究具有重要意义[1-2]。主成分分析(principal component analysis,PCA)作为一种基于多元统计的检测方法,历经多年发展,已经较为成熟并且被广泛应用[3]。PCA能够提取原始数据主要特征并建立统计模型,以T2和平方预测误差(squared prediction error,SPE)(也称Q统计量)作为统计量,对工业过程进行监控[4]。由于化工过程中产生的数据具有非线性、多模态等特性,PCA并不能很好地处理。针对非线性问题,Wang等[5]利用局部化方法提出非线性PCA模型。
针对数据存在的随机性以及噪声影响,Tipping等[6]提出了概率PCA模型。但当数据有多个模态时,概率PCA中使用的Z-score标准化方法就受到了限制。因为Z-score方法运用的是基于所有样本数据的均值和标准差,所以在处理多模态数据时,概率PCA不能准确地进行故障检测[7]。针对多模态问题,He[8]提出了一种基于K近邻的故障检测方法。该方法的故障检测指标为局部距离之和D2,有效降低了多模态的影响。但当模态间方差差异较大时,该方法检测能力较弱。李等[9]提出了基于K均值聚类与局部离群因子算法的故障检测研究。该研究通过K均值聚类方法将多模态数据中各个模态的数据单独分离出来,再按类别分别建立模型进行故障检测。但当多模态数据密度差异较大时,其聚类效果并不理想。
目前,聚类分析在图像处理[10]、医学科学[11]、汽车制造检测[12]等领域得到了广泛的应用。模糊C均值(fuzzy C-means,FCM)聚类算法于1973年由Bezdek[13]提出。相比于K均值的硬聚类方式,FCM引入了模糊理念,为计算过程提供了加权思想,使聚类结果更加灵活。而且在大部分情况下,数据集中的对象不能划分成为明显分离的类,指派一个对象到一个特定的类很容易出错。FCM算法的基本思想是通过将测试数据分成k类,计算每个样本的隶属度,并以隶属度使测试数据隶属于C个数据中心。FCM通过不断计算、更新隶属度矩阵和聚类中心达到动态聚类,以实现目标函数最小为目的。FCM可以把一个数据集合分解成若干个子集,根据判定规则使每个子集内部的数据具有一定的相似性,不同子集之间具有尽可能大的相异性。
根据以上分析,本文提出一种基于FCM-PCA的故障检测方法。首先,通过FCM,按模态对具有多模态特性的训练样本进行分类;然后,在每个模态子集下单独建立PCA模型。检测时,首先将待测样本通过FCM聚类进行模态划分,找到所属模态子集;然后应用该模态子集所建立的模型进行故障检测。
1 基本方法
1.1 模糊C均值聚类算法
假设数据集X={x1,x2,...,xn}。其中,n为样本个数。应用FCM将训练数据划分为k类,其中2≤k≤n。针对每个样本,建立隶属度矩阵U=(Uij)k×n和聚类中心矩阵C=(c1,c2,…,ck)。其中:c1,c2,...,ck为k个数据中心;Uij为第j个样本数据隶属于第i类的隶属度。
隶属度表示数据点属于每个类的可能性,取值范围为0~1。限制条件为:
0≤Uij≤1
(1)
(2)
式中:Uij为第j个样本数据隶属于第i类的隶属度;j为样本数。
FCM聚类算法目标函数为:
(3)

聚类依据某些标准对数据集分类。具有较高相似性的数据在同一簇内。簇之间具有较高差异性。采用拉格朗日乘子法求取目标函数J的极值。
(4)
当目标函数最小时,隶属度函数Uij以及聚类中心ci的表达式为:
(5)
(6)
FCM算法的步骤如下。
①初始化满足约束条件(2)的隶属度矩阵,根据式(6)计算聚类中心矩阵。
②将得到的聚类中心矩阵作为输入,根据式(5)计算隶属度矩阵,并根据式(4)计算目标函数J的值,如此循环迭代。
③当迭代次数达到所设定的次数或连续前后两次差值小于所设定的阈值时,目标函数达到极小值,迭代终止;否则,重复步骤②。
1.2 基于PCA的故障检测方法
PCA能够使原本数据结构分布得到最大限度的保留,并在最小均方条件下将原始特征向具有最大投影信息量的维度上投影,从而在特征空间中实现数据特征提取。PCA主要算法原理如下。
假设数据集X有m个样本。每个样本存在n个变量。数据X如下所示:
(7)
对数据进行标准化处理。PCA所采用的标准化方式为Z-score标准化方法:
(8)
求协方差矩阵:
(9)

对式(8)求出的协方差矩阵进行特征分解,得到特征值和相对应的特征向量。将特征值从大到小排列,λ1≥λ2≥...≥λn≥0。其所对应的特征向量分别为[u1,u2,…,un]。
计算主成分:
Zk=(uk)Txmean
(10)
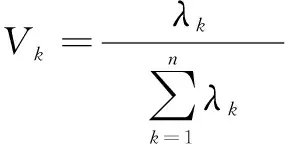
(11)
式中:Zk为第k个主成分;Vk为第i个主成分的方差贡献率。
本文中,主元个数的选取为:将特征值从大到小排序后,根据累计方差贡献率确定前k列作为主元,并组成矩阵P。
降维到k维后的数据为:
Y=P×X
(12)
计算统计量T2和Q:
(13)
(14)
2 基于FCM-PCA的故障检测方法
PCA方法要求数据服从单一模态高斯分布。但很多化工过程中都存在着多工况的情况,导致采集到的数据是具有多模态特性的。在这种情况下,PCA方法就不能很好地处理具有多模态特性的数据。
FCM-PCA可以有效地处理数据具有多模态特性的问题。首先,使用FCM按模态划分多模态数据,使每个模态子集服从高斯分布;然后,在每个模态下运用PCA进行故障检测。这种方法可以有效减小多模态特性的影响,提高检测准确率。FCM-PCA故障检测方法主要由建立模型和故障检测两部分组成,步骤如下。
2.1 建立模型
使用正常样本数据经过处理后,建立PCA模型并计算统计量和控制限。具体步骤如下。
①采集正常运行下的样本数据集X。
②选择聚类数目K与隶属度权重因子m。
③利用FCM聚类对数据集进行聚类,并为每一类贴上标签。数据集由此分成n个子集,即M1,M2,...,Mn。
④构建PCA模型。
⑥使用核密度估计法计算出每个子集下的控制限。
2.2 故障检测
测试样本xnew经过处理后,使用已经建立的PCA模型对其进行故障检测,以判断其是否为故障样本。故障检测具体步骤如下。
①对测试数据进行FCM聚类。根据聚类后的聚类中心与训练数据聚类中心之间的距离对比结果,将分类后所贴标签与训练集所贴标签一一对应,找到所属类别。
②按数据标签将数据分成多个子集,并提取每个子集数据。
③通过已经建立的PCA模型,对每个子集中的数据进行故障检测。
3 数值例子
本文将基于FCM-PCA的故障检测方法应用于多元线性数值例子,说明该方法的优点,并将其结果与基于PCA的故障检测方法的结果进行对比。数值例子如下。
(15)
式中:e1~e5为满足均值为0、方差为0.1的正态分布的独立噪声;S1、S2为系统控制变量,可通过设置S1、S2不同分布来产生多模态数据。
S1、S2两模态分布如下。

(16)

(17)
通过仿真生成的1 000个样本组成训练集进行建模。每个模态各存在500个样本,同时各生成200个正常样本和300个故障样本作为测试集。故障为在x2的第201~500个样本上发生0.13(i-200)的斜坡故障,在x5第701~1 000个样本上发生幅值为45%的阶跃故障。本文通过使用PCA和FCM-PCA对上述数值例子进行故障检测,通过85%贡献率确定两种方法的主元个数均为1。
本文提出的方法首先将数据聚类,并在每一类下单独建立模型。原始数据聚类前后以及测试数据聚类前后的散点图分别如图1、图2所示。

图1 原始数据聚类前后散点图
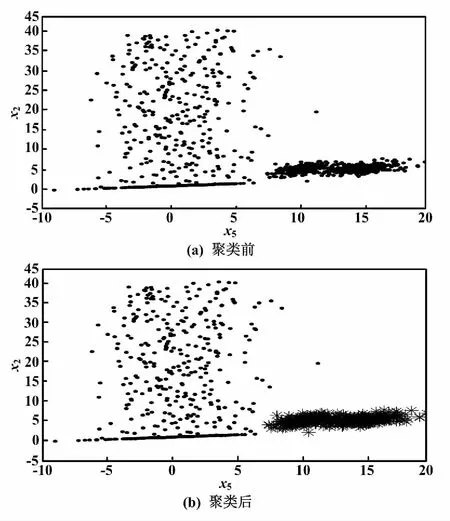
图2 测试数据聚类前后散点图
由图1、图2可知,FCM可以很好地对多模态数据进行聚类,并且具有很高的准确率。通过FCM对模态的划分,可以有效帮助PCA在每个模态下进行故障检测。
PCA与FCM-PCA两种方法对数值例子的故障检测结果如图3所示。

图3 两种方法对数值例子的故障检测结果
PCA对多模态数据整体建立模型时,在高维空间中T2控制限近似于超椭球面,而Q控制限近似于超球面。这导致球面内错误的包含了一部分故障区域。由于模态1发生的是斜坡故障,故障样本远离多模态数据中心且持续时间较长,所以PCA可以有效地进行检测。模态2中发生的是阶跃故障,且故障幅度较小,因此PCA模型会错误地将故障点包裹在内,从而无法有效地进行检测。FCM-PCA方法通过将样本聚类为若干个子集,并对每个子集建立独立的PCA模型,将故障样本排除在超椭球面外部,具有良好的检测能力。对数值例子的故障检测说明PCA不能很好地处理多模态问题,而FCM-PCA先对数据进行模态划分再进行故障检测,可以有效地解决数据的多模态特性。因此,FCM-PCA具有较高的检测率。
4 工业案例
田纳西-伊斯曼(Tennessee East-man,TE)过程是典型的复杂多变量化工过程。近年来,TE过程已经在故障检测研究领域得到了广泛的应用[14]。本节应用试验中的所有数据均来源于TE过程。
TE过程有1组正常过程数据和21组故障数据。故障数据分为4种类型[15]。每组数据集都包括52个观测变量,分为41个过程变量和11个操纵变量。具体故障数据类型的描述如下。
故障1~7均为阶跃变化类型:故障1和故障2分别为物料A/C进料比改变、物料B含量不变和物料A/C进料比不变、物料B含量改变;故障3为物料D进料温度改变;故障4、故障5分别为反应器、冷凝器冷却入口温度改变;故障6、故障7分别为物料A进料损失、物料C压力损失。故障8~故障12为随机变量变化类型:故障8为物料A、B、C的组成比例改变;故障9和故障10分别为物料D、物料C进料温度改变;故障11和故障12分别为反应器、冷凝器冷却水入口温度改变。故障13为反应动力学参数改变,属于慢偏移变化类型。故障14和故障15为粘住变化类型,分别为反应器、冷凝器冷却阀门粘住。故障16~故障20为未知故障。故障21为物料4阀门固定在恒定位置,属于恒定位置变化类型。
本文应用试验使用的为 TE 过程生产模式1和模式3,分别代表模态1和模态3。不同模式的生产过程需要使用不同的生产物G/H的比例。
将两个模态混合使用,即训练数据和测试数据的样本数各为1 922个。其中:训练数据为系统正常运行情况下的所有正常样本,包含各模态的961个正常数据;测试数据包含各个模态的160个正常数据和对应的801个故障数据样本[16]。
TE过程生产模式如表1所示。

表1 TE过程生产模式
本文通过85%累计方差贡献率确定主元个数。PCA方法所确定的主元个数为1;使用FCM-PCA方法对数据集进行了聚类处理,将两个模态分开确定主元个数,所确定的主元个数分别为31和32个。该方法在降维的同时可以较好地描述数据信息。两种方法的置信度设置为99%,经过先验知识及多次仿真试验确定聚类数K为2以及隶属度权重因子m为2。以下采用FCM-PCA对故障1~故障21进行故障检测。
训练集聚类结果以及测试数据聚类结果如图4所示。
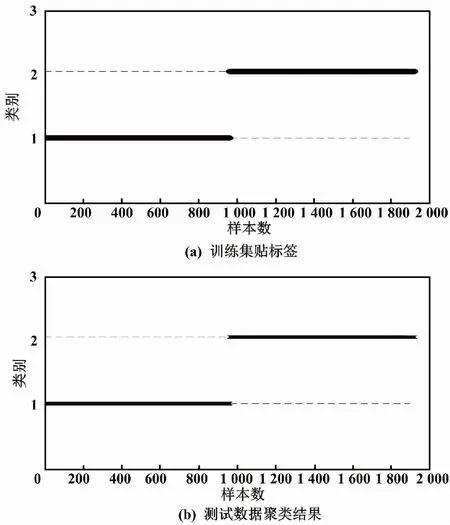
图4 训练集及测试数据聚类结果
由图4(a)可知,当目标函数收敛后聚类完成,可以很明显地看出前961个样本为一类、后961个样本为另一类。这说明模糊C均值方法可以将各个模态的数据准确贴标签。以故障1为例,图4(b)即不断更新隶属度矩阵和聚类中心后各样本的聚类结果。由图4(b)可知,前961个样本为一个类别、后961个为另一个类别,聚类结果与训练数据贴标签结果完全一致。
在训练集聚类以及测试样本按模态聚类后,分别在各个模态下建立PCA模型,确定控制限,并对测试数据进行故障检测。对全部21种故障类型待测数据检测,并且与只采用PCA算法进行检测的结果进行对比分析。两种方法的部分检测率如表2所示。

表2 两种方法部分故障检测率汇总表
由表2可知:FCM-PCA的检测率明显高于PCA检测方法。FCM-PCA与PCA针对故障1、故障4、故障6、故障8、故障11、故障13、故障20的检测率较高,均高于80%。而对于故障2、故障7、故障10、故障14、故障17、故障18、故障19,PCA的检测率都在80%以下,而FCM-PCA对于这7个故障的检测率均在85%以上。由此可知,FCM-PCA的检测率明显更高,检测能力优于PCA。
在故障7中,物料C压力损失,产生了一个阶跃性变化,导致物料C含量偏离正常状态,从而发生故障。两种方法对于故障7的检测结果如图5所示。由图5(a)、图5(b)可知,故障数据在第161个样本到第961个样本间大部分被检测出,后800个大部分未被检测出。图5(c)、图5(d)为聚类后在模态1、模态3下运用PCA的仿真结果,在第161个样本后和第1 122个样本后绝大部分故障数据都被检测出来,FCM-PCA检测率远大于PCA检测率。多模态数据在经过标准化后仍然具有多模态特性,因此PCA不能很好地建立模型。FCM-PCA会先将模态分开,再分别在每个模态下对数据进行标准化处理,消除了多个模态带来的方差差异的影响,大大提升了故障检测率。对比可知,FCM-PCA可以有效地处理具有多模态特性数据的故障检测,故障检测准确率高于PCA。

图5 两种方法对故障7的检测结果
两种方法对故障14的检测结果如图6所示。
故障14为反应器冷却阀门粘住,扰乱系统的正常运行。由图6(a)、图6(b)可知,由于数据具有多模态特性且模态间方差存在较大差异,而使用PCA算法会根据整个多模态数据建立模型导致错误地包含一些故障数据。经过聚类后,PCA算法在每一个分类后的子集中建立模型,消除了模态间方差差异,从而可以更好地进行故障检测。对比图6(c)、图6(d)可知,FCM-PCA将模态划分后,在每个模态下单独建立PCA模型,更准确地描述了每个模态的数据信息。其检测率远大于PCA方法的检测率。
5 结论
本文针对工业过程数据的多模态特性,提出了一种基于FCM-PCA的故障检测方法。首先,使用FCM聚类算法将多模态划分成各个模态子集;然后,使用PCA在每个子集下进行故障检测。本文将此方法应用于TE过程的多模态数据中,并与PCA算法进行比较。通过对多模态数据进行聚类,消除了数据的多模态特性,使PCA模型建立在各个子集,从而有效降低了模态间方差差异对PCA带来的影响,提高了检测能力。试验结果表明,FCM-PCA可以较好地处理多模态问题,实现多模态数据的准确分类,提取各模态有用的信息进行故障检测,使故障检测率明显提升。研究结果充分证明了FCM-PCA方法用于故障检测的有效性。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
电子测试(2017年15期)2017-12-18 07:19:27
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
智能系统学报(2015年4期)2015-12-27 09:38:39
都市丽人(2015年4期)2015-03-20 13:33:22
上海电机学院学报(2015年4期)2015-02-28 14:30:00
电子设计工程(2015年6期)2015-02-27 12:04:53
计算物理(2014年2期)2014-03-11 17:01:39
