
基于蝙蝠优化偏好矩阵的序列化数据推荐算法研究
2022-08-15 09:33丁勇
自动化仪表 2022年7期
丁 勇
(云南师范大学文理学院,云南 昆明 650228)
0 引言
随着信息网络的发展,大数据应用技术获得了越来越多的关注。各类用户与项目信息的快速增长对推荐系统负载能力提出了挑战,因此需要对系统扩展性开展更加深入的研究[1-4]。内容推荐算法和协同过滤算法存在明显的差异性。内容推荐算法无需根据用户评分行为信息进行分析,而是以用户与项目特征信息作为推荐的依据[5-7]。有学者[8]通过隐含狄利克雷分布(latent dirichlet allocation,LDA)主题模型与Word2Vec模型相结合的方式研究用户之前关注过的音乐。文献[9]重新构建了一种混合模型,实现了深度神经网络和矩阵分解模型相融合,可以在稀疏数据条件下对用户与项目信息进行深度挖掘。文献[10]则将增量更新协同过滤方法和语义分析算法相融合,构建得到了一种混合推荐算法。以传统形式的聚类算法处理用户与项目信息的过程中,较易引起错误并存在陷入局部最优的缺陷,因此不能发挥聚类的理想作用,难以准确获取最近邻居,导致最终推荐结果出现较大偏差[11-12]。
根据上述研究结果,本文设计了一种根据用户偏好进行优化聚类处理的协同过滤推荐算法,并对该算法进行了测试分析。
1 算法模型
1.1 用户类型偏好矩阵
本文进行数据建模的过程中设置了项目类型特征,可以准确反馈用户兴趣偏好并精确提供推荐内容。对于个性化推荐系统,各项目都存在多种类型特征。这使得项目类型比项目数量更少。此外,不同用户对各个项目类型也会产生不同的兴趣偏好。根据以上特征,本文选择项目-评分矩阵与项目-类型矩阵相结合的方法设计评分比例-项目编号(rating proportion-item preference,RP-IP)算法,以此预测用户对各类项目的偏好情况,构建得到细粒度用户-项目类型偏好矩阵。
评分比例(rating proportion,RP)代表某一用户u对类型e的项目评分总和Ru,i在项目总评分Ru中所占的比值。评分比例计算过程如式(1)所示。
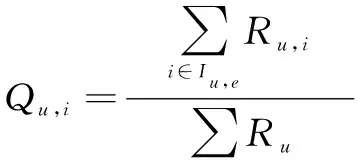
(1)
式中:Qu,i为评分比例;i为自评分变量。
项目偏好(item preference,IP)代表类型e的项目数量C(Ie)在项目总数C(I)中的占比,能够有效避免类型e的热门项目引起的用户偏好差异。通过式(2)计算项目编好矩阵Mi,e。为避免产生类型e的项目数量为0的问题,本文以1+C(Ie) 作为分母。
(2)
用户对项目类型的偏好程度Pu为:
(3)
利用式(3)计算得到用户对项目类型的偏好程度,同时构建细粒度用户-项目类型偏好矩阵。本文在分析计算过程中都是选择真实评价数据,对于评价数据为空的情况,把部分数据表示成0。
1.2 蝙蝠优化聚类控制流程
采用蝙蝠优化用户模糊聚类算法进行处理的过程为:首先,通过蝙蝠优化算法确定最优初始聚类中心;然后,对用户实施模糊C均值(fuzzy C-means,FCM)聚类。采用蝙蝠优化算法进行处理时,把每只蝙蝠都表示为一个聚类中心矩阵C。
输入:细粒度用户-项目类型偏好矩阵、蝙蝠种群大小h、聚类数、最大迭代次数T。
输出:包含W、c个用户簇的用户簇隶属度矩阵。
①以随机方式生成初始蝙蝠种群C,初始化种群的蝙蝠个体Ci速度vi、位置xi、脉冲发射率ri、响度Ai与频率fi。
②计算隶属度。
③计算种群内所有蝙蝠个体适应度值并排序,并挑选出适应度值最优的蝙蝠个体。
④修改蝙蝠个体位置和速度参数。
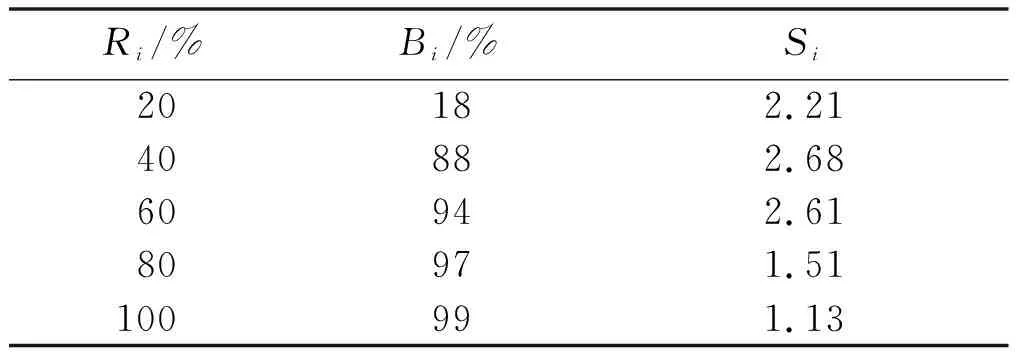
⑤生成随机数r0并对种群内的蝙蝠个体实施遍历。当满足条件r0 ⑥生成随机数r1并对种群内蝙蝠个体实施遍历,当r1 ⑦当迭代次数小于T或不满足聚类中心收敛条件时,则重新回到步骤②进行迭代;反之,输出最优适应度值条件下的蝙蝠个体xbest,将其作为最优初始聚类中心并实施聚类划分,生成用户簇隶属度矩阵W与c个用户簇。 本文在设计蝙蝠协同过滤推荐算法(bat collaborative filtering recommendation,B-CFR)时融入了用户偏好优化聚类方法。为克服聚类协同过滤算法处理系统可扩展性问题时面临的缺陷:首先,将用户行为分为类型矩阵和评分矩阵;然后,以B-CFR算法为基础,根据项目类型建立细粒度偏好模型,并利用蝙蝠优化算法达到改进聚类的效果,找出目标用户的最近邻居;最后,按照用户加权相似度结果预测评分,并输出推荐结果。 本文研究的数据来自美国GroupLens小组从MovieLens网站获取并经过预处理的数据集。为了对算法推荐性能进行验证,在试验开始前,把ML-100K内的所有数据量以5∶1的比例进行随机分类,从而得到训练集和测试集。试验完成后,通过五折交叉验证的方式把五次测试所得的结果均值作为最终评价指标。 为分析B-CFR算法的聚类数,通过加权相似度的方法预测评分。不同聚类数下测试系统平均绝对误差(mean absolute error,MAE)值和均方根误差(root mean square error,RMSE)值的分布如表1所示。 表1 不同聚类数下测试系统MAE值和RMSE值的分布 考虑到聚类数对最近邻居用户查找效率存在明显影响,需要合理选择聚类数值,以免发生聚类数过大或过小的问题。对表1进行分析可知,在聚类数为10的情况下,MAE值最小。因此,本文设计的算法将聚类数设置为10。 为确定本文设计的B-CFR算法的近邻数K,不同近邻数下测试系统MAE值和RMSE值的分布如表2所示。对表2进行分析可知,当K处于[10,40]区间内,随着K的增大,MAE值迅速减小。由此可以发现在该区间内,当K增加后,获得了更优的推荐效果。当K=40时,MAE值最小。当K处于[40,80]区间内,随着K的增大,MAE发生了缓慢升高的现象,但低于K为10、20情况下的MAE值。根据以上分析可知,本文算法的K取值为40时达到最优值。 表2 不同近邻数下测试系统MAE值和RMSE值的分布 为确定本文设计的B-CFR算法最优权重系数,验证了该因子对推荐结果产生的影响。按照上文优化的聚类数为10、K为40,对系统进行计算。不同权重系数下测试系统MAE值和RMSE值的分布如表3所示。对表3进行分析可知,当权重系数处于[0.1,0.5]区间内,不管聚类数量是多少,MAE值都发生了随权重系数增大而减小的现象。该结果表明,在设置了用户项目类型偏好相似度的情况下,通过B-CFR算法预测评级时能够满足用户真实评级状态评价,显著改善推荐效果。当权重系数处于0.5~0.9时,随着权重系数的增大,MAE值也随之提高。由此可以推断,此时用户项目类型偏好相似度已经获得较高比重,从而对推荐性能造成负面影响。 表3 不同权重系数下测试系统MAE值和RMSE值的分布 为验证本文设计的B-CFR算法具备比传统CFR算法更强的实时性,设定K为40,根据用户占比度Ri计算得到最近用户重复度Bi和搜索率Si。不同Ri下Bi和Si的分布结果如表4所示。 表4 不同Ri下Bi和Si的分布 对表4进行分析可知,Ri取值为40%的情况下,Bi为88%。Si在Ri为40%的条件下获得最大值。 由此可以获得以下结论。本文设计的B-CFR算法相对于CFR算法,一方面可以优化评分预测准确性,另一方面可以有效缩小最近邻居搜索范围,增强系统实时性,使系统获得更强的扩展能力。 本文在设计B-CFR算法时,融入了用户偏好优化聚类方法。首先,以B-CFR算法为基础,并根据项目类型建立了细粒度偏好模型。然后,利用蝙蝠优化算法,达到改进聚类的效果。最后,按照用户加权相似度结果预测评分。 本文所设计的算法在聚类数为10、K为40时是最优的。当权重系数处于[0.1,0.5]区间内时,通过B-CFR算法预测评级时能够满足用户真实评级状态评价,显著改善推荐效果。 相对于CFR算法,本文设计的B-CFR算法可以优化评分预测准确性、有效缩小最近邻居搜索范围、增强系统实时性,使系统获得更强的扩展能力。1.3 算法执行过程
2 试验结果与分析
2.1 数据集
2.2 参数结果分析



2.3 实时性的验证
3 结论
猜你喜欢
红外技术(2022年11期)2022-11-25安阳工学院学报(2020年2期)2020-06-05现代计算机(2018年27期)2018-10-25现代电子技术(2018年1期)2018-01-20电脑知识与技术(2017年26期)2017-11-20雷达学报(2017年6期)2017-03-26小溪流(画刊)(2016年12期)2017-02-04互联网天地(2016年1期)2016-05-04现代计算机(2016年17期)2016-02-28微型小说选刊(2015年5期)2015-06-05
