
基于深度文本摘要的开源软件缺陷挖掘研究
2022-08-15 07:10汶东震张帆TADESSEMichaelMesfin徐博林鸿飞杨亮林原
山西大学学报(自然科学版) 2022年4期
汶东震,张帆,TADESSE Michael Mesfin,徐博,林鸿飞,杨亮,林原
(1.大连理工大学 计算机科学与技术系,辽宁 大连 116024;2.大连理工大学 人文与社会科学学部,辽宁 大连 116024;3.大连理工大学 软件学院,辽宁 大连 116024)
0 引言
自软件系统产生伊始,软件缺陷(Software Defeat/Bug)始终伴随在各类软件开发与使用过程中。轻微的软件缺陷会导致用户体验不佳、系统效率降低等问题;而严重的软件缺陷则会对社会经济安全稳定产生重大影响(如:千年虫问题、北美电网控制系统问题、苏联核预警系统误报等)。因此针对软件缺陷的识别和修复逐渐成为软件工程研究的重要内容。
典型的软件开发过程可以分为两个严密组织的重要阶段:软件开发与软件维护。如图1所示,软件工程的核心是为用户提供良好稳定的软件系统,在软件开发过程中经历用户需求分析、软件设计和软件编码开发三个环节不断迭代。当软件系统具备一定规模时,测试人员针对性地对软件系统进行测试并反馈软件缺陷问题,再交由开发者进行修复。在测试—修复迭代过程中逐渐形成稳定可用的软件系统最终交付用户。在此过程中,软件测试环节负责尽可能多地发现软件缺陷从而针对性地进行解决。测试过程包括:单元测试、回归测试、功能性测试、安全性测试等多个方面。而受限于软件交付期限与测试人员人力成本,交付后的软件系统仍可能存在大量缺陷。
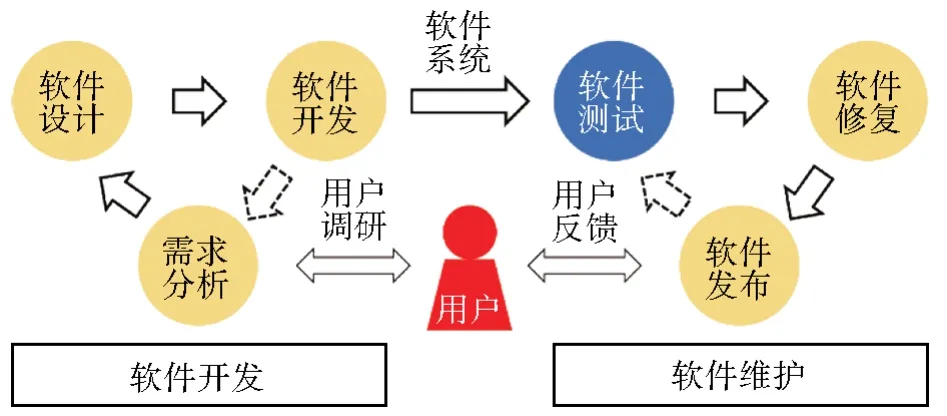
图1 软件工程整体流程Fig.1 A workflow of software engineering
而开源软件(Open Source Software)运动的兴起则为软件开发和维护提供了全新的理论指导。以Linux系统为代表的一系列成功且优秀的开源软件表明,基于少数核心开发者主导、部分贡献者助力、大量外部人员参与的“集市”式开发流程也能够产生极为精密并且稳定可用的软件系统。其中Linux系统的开发者Linus针对开源软件维护提出了Lnius定律:“足够多的眼睛关注,就可让所有问题浮现”(Given enough eyeballs,all bugs are shallow)。这一软件维护原则除了基于开放源代码的代码审查之外,开源软件的大量用户主动地或被动地参与到软件测试维护过程中来。
如图2所示,以开源软件协作平台Github为例,平台中每个开源项目均设有“问题”(Issue)板块,以便于开发者与使用者针对开源软件项目中包含的问题进行讨论交流。这种社区对话式的讨论交流一定程度上取代了传统软件开发过程中专业测试人员的工作。对话交流的文本也成为开源软件缺陷的报告文本。软件缺陷以用户需求而非测试需求为导向被曝光并加以解决,这也是开源软件项目具有良好用户可用性前提。但“众包”(Crowdsourcing)式的软件缺陷曝光方法也存在着信息过载(Information over⁃load)等问题。

图2 Github平台中的问题讨论区Fig.2 Discussion community of Github platform
以著名深度学习框架Tensorflow在Github上的讨论区为例,从2015年至今(2020),已有36 096个问题得到解决,在项目迭代过程中仍有3 680问题等待解决。海量的开源软件缺陷报告为开发者带来了巨大负担,少数开发者无法短时间对大量的项目反馈进行识别、理解和解决答复。一方面阅读这类报告并分析定位软件缺陷位置会消耗大量精力;另一方面待解决的软件缺陷优先度各有不同,进行优先度识别也较为困难。
针对这些问题,研究者提出开源软件缺陷的自动挖掘研究以提高软件开发测试效率。在自然语言处理研究中,文本摘要技术能够很好解决信息过载问题。文本摘要相关算法能够从新闻、文学等篇章文本中抽取核心观点和重要内容。因此结合文本摘要技术,针对软件缺陷报告能够很好地进行分析和挖掘,并以更为清晰明了的方式展现软件缺陷类型、位置、可能原因以及严重性情况,以减轻开发者负担并提高开发效率。
基于以上问题,本文设计了一系列实验对上述问题进行研究。并在问题研究基础上,结合自然语言预训练模型和深度学习技术,提出一种基于预训练自然语言模型的深度文本摘要模型,应用于开源软件缺陷报告挖掘中。相关对比实验表明,本文提出深度文本摘要模型针对性地提高了开源软件缺陷报告中缺陷识别挖掘的效果。
1 相关研究工作
开源软件运动(Open Source Software move⁃ment)始于20世纪80年代美国,标志项目是由Richard Stallman发起的GNU(Gnu is Not Unix)项目。而随着国内互联网产业在规模和质量上的不断进步和软件市场的不断扩展,诸如百度、腾讯、华为、阿里巴巴等公司和个人开发者也积极拥抱开源,开源软件仓库挖掘研究也逐步被国内研究者所重视。
尹刚等[1]针对面向开源软件生态的数据挖掘研究做了细致的综述。将开源软件仓库挖掘研究划分为三大类:软件资源挖掘研究,包括开源软件资源定位和开源软件可信评估等内容;软件开发任务挖掘研究包括缺陷挖掘和优先级预测、自动化开发任务指派以及领域专家识别与合作者推荐等任务;软件知识挖掘研究包含问答知识挖掘、API(Application Program⁃ming Interface)用例挖掘以及开发环境的软件知识集成等任务。各子任务之间关系如图3所示,可以看到开源软件挖掘研究重点在于结合数据挖掘技术针对开源软件项目以及软件社区内容进行知识挖掘,以更好地服务于开发者。而软件缺陷挖掘在开发任务挖掘研究处于基础地位,具有较大的研究价值。

图3 开源软件挖掘任务关系Fig.3 Relationship among software mining tasks
软件缺陷识别主要结合软件测试报告、软件缺陷报告等文本,利用文本挖掘技术从中定位软件缺陷,这也是本文主要研究内容。现有研究主要结合从监督学习和非监督学习角度均做了一定尝试。为了便于理解,本文将从软件缺陷报告挖掘和文本摘要技术两个方面对相关工作进行介绍。
(1)软件缺陷报告挖掘
Rastkar等[2]为软件缺陷报告摘要任务提供了一个合适的语料库,作者从University of Brit⁃ish Colunbia计算机科学系招募了10名研究生来注释一组bug报告。构建的语料库共有36个bug报告,2 361个句子。Wang等[3]针对开源软件缺陷报告中同一问题存在大量相似表述和相似术语的问题,结合复述获取(Paraphrase Ac⁃quisition)技术对缺陷报告中的相关性词语进行整合对齐,提高了缺陷挖掘的准确性。Jiang等[4]将有关报告贡献者的身份特征及其一系列属性特点融入bug报告摘要任务中,可以有效改进目前的摘要方法。
Lotufo等[5]根据开发人员经常快速浏览软件bug报告的习惯,提出了Hurried算法,利用了PageRank算法进行句子选择,并且考虑了句子与报告标题之间相似性等因素。Kim等[6]认为目前的bug报告摘要方法还没有充分利用其固有特性,他们提出了一种使用加权PageRank算法的软件bug报告摘要方法,并利用了bug报告之间的“重复(duplicates)”“块(blocks)”“依赖(depends on)”关系,通过实验说明该方法具有一定的有效性。
Jindal等[7]提出了一种无监督方法,该方法基于聚集方法提取报告中的关键单词或短语以构成领域知识集,从每个报告中提取出隶属度高于设定阈值的句子,经过去除冗余和重排序后形成摘要。李晓晨[8]提出了一种基于深度学习的无监督bug报告摘要算法,该算法使用了基于bug报告的无监督步进式自编码网络,考虑了报告中的多种特征,通过实验表明其方法具备更优效果。
(2)文本摘要技术
摘要技术能够从海量繁杂文本中抽取出目标信息,起到信息过滤和挖掘的作用。而当前文本摘要技术主要分为两类,生成式摘要和抽取式摘要,其中生成式摘要技术主要结合文本生成模型,在分析文本特征的基础上生成原始文本对应的摘要内容。而抽取式摘要则结合文本分类、序列标注等技术对原文中词、句子、段落进行打分,选择原始文本作为摘要内容。
软件缺陷报告文本具有较强的领域特性,尤其是涉及程序语言的关键词、变量名、API名称等,领域特定性较强。因此更适合使用抽取式摘要方法,直接从原始报告文本中抽取缺陷描述的关键性文本。
Kupiec等[9]最早在文本自动摘要领域使用机器学习技术,在抽取线索词、句子长度、句子与文章标题的相似性等特征基础上,作者使用朴素模型进行句子打分,从而实现抽取式摘要。随着文本表示技术的发展,词嵌入(Word Embedding)技术成为在多项文本领域任务上取得较好的效果,基于词嵌入技术,Nallapati等[10]使用两个双向的GRU(Gated Recurrent Unit)模型分别构建句子级特征与篇章级特征,其模型充分考虑了信息内容、显著度、新颖度对结果的贡献,并取得了当年最佳效果(State of the art)。
随着预训练语言模型(Pretrain language model)技术不断发展,结合预训练技术的下游任务模型不断刷新榜单。2018年BERT(Bidi⁃rectional Encoder Representations from Transform⁃ers)模型[11]发布,在众多子任务上同时取得了最好的效果,研究者越来越多的使用BERT应用于相应的下游任务。Liu等[12]在BERT模型基础上进行了微调。作者改进了模型输入文本的方式,构建基于BERT的抽取式文本摘要模型,最终在摘要任务上取得了2019年的最佳结果。Ahmad 等[13]提出了PLBART,它作为一个序列到序列模型,可以执行广泛的程序语言理解和生成任务。PLBART通过对大量的Java和Python函数去噪以及自动编码并进行了预训练,在代码摘要、代码生成等基于七种编程语言的任务上取得了SOTA的性能。
可以看到,开源软件缺陷挖掘任务研究中,以开源软件缺陷报告为对象,结合抽取式文本摘要技术是一种可行的技术路线。本文重点针对开源软件缺陷报告与抽取式文本摘要技术之间的适应性进行研究,在此基础上提出一种基于预训练自然语言模型的软件缺陷报告摘要模型。相关数据集上的对比实验表明本文提出的模型有着较好的效果。
2 模型
针对软件缺陷报告的句子特征提取问题,本文结合Bert提出了一种基于句子向量特征的软件缺陷报告摘要模型。整体模型结构如图4所示。
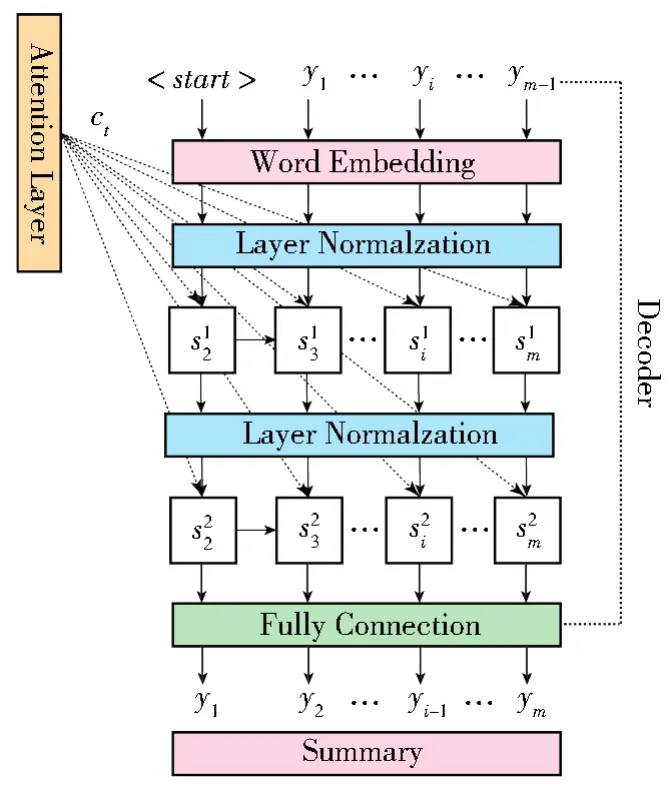
图4 基于预训练模型的深度文本摘要模型Fig.4 Text summarization model based on pretrain language-model
在整个框架的上半部分,使用了一个用于单文本分类的Bert模型,[CLS]代表文本序列的开始符号,[SEP]作为每个句子文本的结束标志。对输入的文本修改成一个向量序列X=[w1,w2,…,wn],其中n为序列长度,每一个wi为三种向量的简单相加,即词嵌入(Token Em⁃bedding)、分隔嵌入(Segment Embedding)和位置嵌入(Position Embedding),分别用来表示词的含义、句子区分以及词在句中的位置。随后将相加之后的向量X输入至多层的双向转换器结构(Transformer)中,即:

其中,h0为模型的输入向量X,LN为归一化(Normalization Operation)操作,MHAtt为多头注意力机制(Multi-Head Attention)操作,l代表Transformer的层数。实验中的Bert,选用了“bert-base”预训练模型,因此其输出维度为768。
模型以单个句子文本为单位,输入主要分为两个部分,第一部分需要在句子文本的开头添加[CLS]符号,在句子的结尾添加[SEP]符号,将其转为Bert模型的Token Embedding序列,并对每个不满足最大长度的序列使用[PAD]符号进行填补。第二部分为由[0,1]序列组成的MASK掩码列表,也就是通过0和1指明PAD的部分。取Bert模型输出的最后一层的全部向量接入一个分类层,最终使用Sig⁃moid函数进行激活。
在本方法中使用了双向GRU模型作为分类层,同时在实验中对比了使用双向LSTM(Long Short-Term Memory)以及普通的线性分类器的性能。
GRU修改了循环神经网络中的隐藏状态的计算方式,加入了重置门(Reset Gate)和更新门(Update Gate)机制,其计算方式如下:

σ为Sigmoid函数,Ht−1为上一时间步的隐藏状态,Xt为当前时间步的输入。
接下来通过重置门Rt来选择丢弃无关信息来计算候选隐藏状态:

而当前时间步的隐藏状态的计算与更新门Zt、上一时间步的隐藏状态Ht−1以及当前时间步的候选隐藏状态有关:
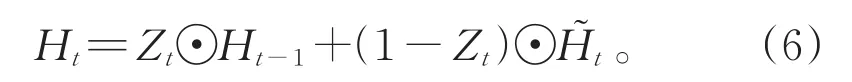
由于单向的GRU模型只能获取到文本序列的前向信息,为了获取到上下文信息,采用了双向的GRU模型,一个是以原单向GRU为顺序训练,另一个以原模型反转后的序列顺序进行训练。最后双向GRU的输出为两个序列输出拼接而成。设前向GRU的隐藏层输出为,反转后的GRU的隐藏层输出为,双向GRU的隐藏层输出为Ht,隐藏层单元数为m,

Ht的向量维度为(n,2m),取双向GRU层的最后一个时间步的隐藏状态Hn作为输出,输入至全连接层并以Sigmoid作为激活函数,得到该句是否为摘要句的概率值:
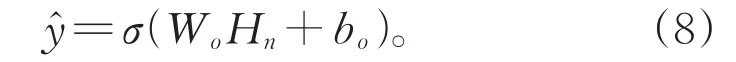
训练时的损失函数采用二值交叉熵函数(Binary Cross Entropy Loss),模型最终预测目标为当前输入的句子是否为软件缺陷关键描述句。

3 实验
开源软件缺陷报告属于专业性较强的领域特定文本,类似的如医学文本、法律文书等。与一般文本不同,这种类型文本中包含着大量在通用领域文本上很少出现的领域特定词语,并且部分常见词语会因为文本领域的不同发生词义、语义的偏移。这使得在通用文本任务上成熟的方法不能直接用于此类文本任务之上。
一份典型的开源软件缺陷报告的格式,如表1所示(注:已翻译为中文描述,开源软件缺陷报告一般为英文文本数据)。这类报告数据往往来源于开发者们的邮件列表、开发者论坛、开源社区讨论版等位置,是一种对话形式的数据集。其中标注为蓝色的为软件领域一些常见实体的名称(如tensorflow、conda);标注为黄色的部分为讨论者添加的代码引用(如tf.model);标注绿色的部分为程序运行编译器或者集成开发环境(IDE(Integrated Development Environment))反馈的错误信息。可以看到,开源软件缺陷报告是一种掺杂自然语言、程序语言以及通过模版生成的告知类信息等多种形式文本的杂合体。

表1 开源软件缺陷报告格式示例Table 1 Example of reporting format for open source software defect
针对软件缺陷挖掘任务,本文设计不同方面的实验在开源软件缺陷报告数据上进行测试,以寻找软件缺陷报告分析的较好实践。
三种实验针对结合文本摘要技术的开源软件缺陷挖掘任务进行探究,针对自然语言处理技术与软件缺陷文本的结合进行探讨,并引出本文方法。
实验组1:预训练语言模型对自然语言处理任务提升显著,本文首先针对开源软件缺陷报告对比了常见的预训练词向量技术。在此基础上针对基于开源软件缺陷报告的挖掘任务特点进行研究。
实验组2:在使用预训练的自然语言模型对开源软件缺陷报告文本进行表示的基础上,本文对比了基于单句的关键句分类模型、基于上下文句子关系的关键句分类模型、基于主题相关度的关键句分类模型以及结合篇章文本的信息检索模型,对比实验表明本文模型最优。
实验组3:在前两种实验的对比验证基础上,本文针对不同神经网络结构针对关键句的分类能力在软件缺陷报告数据集上进行了验证,证实本文模型的有效性。
3.1 数据集和评价方法
本文使用两个软件缺陷报告数据集作为进行对比实验验证。
SDS(Summary DataSet)[2]:该数据集 由Rastkar首次提出,数据集共包含从4个开源项目(Eclipse、Mozilla、KDE、Gnome)收集的 36个软件缺陷报告,2 361个句子。每个句子由三名注释者投票决定是否为摘要句,若一个句子至少获得两人赞同,则为摘要句。
ADS(Authorship DataSet)[4]:由Jiang 等首次提出,数据集包含从4个开源项目(Eclipse、Mozilla、KDE、Gnome)收集的 96个软件缺陷报告,每个项目各24个缺陷报告。雇用了7个大连理工大学软件学院的研究生对数据集进行注释。每个报告首先由三个注释者用自己的语言进行人工摘要(最多不超过250个单词),之后注释者需要将人工摘要的每个句子链接到原文中的一个或多个句子,原文中不少于2票的句子被标注为摘要句。
实验采用准确率(Accuracy)、精确率(Preci⁃sion)、召回率(Recall)、F1值(F1-Measure)作为评价指标,分别计算如下:
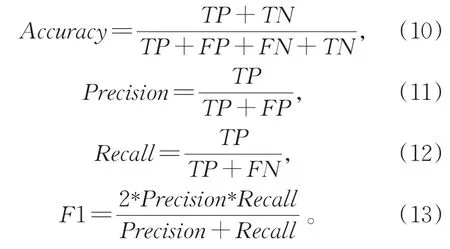
TP为模型判断为摘要句且数据集中也被标记为摘要句的数量,TN为模型判断为非摘要句且数据集中被标记为非摘要句的数量,FP为模型判断为摘要句但数据集中被标记为非摘要句的数量,FN为模型判断为非摘要句但数据集中被标记为摘要句的数量。
此处针对数据标注的一致性进行了检测,选取组内相关系数(ICC)和Kappa检验方法进行了验证,如表2所示,二者值越接近于1越好。可以看到,数据标注一致性尚可,在目前软件缺陷报告挖掘任务数据集属于不错的结果。

表2 数据标注一致性分数Table 2 Data annotation consistency score
摘要句的选取数量设有限制,每个报告的摘要句数量为其总句子数的30%。
实验采取六折交叉验证的方式,对于SDS数据集,即每轮选取30个报告作为训练集,6个报告作为测试集,共进行6轮。评价结果时按每个报告为单位进行计算,一轮的6个报告取平均值,最后6轮结果再取平均值,即是最终结果。
3.2 对比实验和训练方案
本文选择较为经典的摘要抽取算法Tex⁃tRank[14],以及经典的文本分类模型TextCNN[15]作为基础对比实验。
针对词向量对比实验(实验1部分),本文使用基于双向长短时记忆网络的文本分类模型(Bi-LSTM)[16]作为基础,将分类器文本表示部分所用的词嵌入矩阵分别替换为经典的word2vector[17]方法 、Glove[18]方6法以及Fast⁃text[19]方法进行对比。
针对软件缺陷挖掘对比方案(实验2部分),本文结合BERT模型提出三种对比方案,基于单句表示的关键句分类模型、基于上下文句子关系的关键句分类模型、基于主题相关度的关键句分类模型以及基于篇章表示的信息检索模型。其中BERT进行文本表示的方案如图5所示。
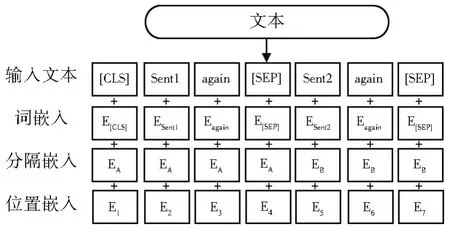
图5 BERT文本表示方案Fig.5 Text representation scheme of BERT
基于单句表示的关键句分类模型:即本文所用方法。
基于上下文句子关系的关键句分类模型:每次训练时将待判定的句作为句子1,待判定句子之后的一句作为句子2,二者使用[SEP]特殊字符进行连接,并在拼接后句子收尾加入[CLS]和[SEP]字符,通过BERT模型获得到两个句子的联合表示后针对句子1是否为关键句进行句子分类判定。
基于主题相关度的关键句分类模型:句子嵌入表示方案与上面相似,此处将句子2替换为当前开源软件缺陷报告的标题。将标题作为当前报告主题,计算待判定句与主题进行相关度计算。
基于篇章表示的信息检索模型:受Nogueira等[20]工作启发,本文还对比了基于信息检索方案的关键句抽取模型。将待判定的目标句作为“查询句”,以目标句为中心设定一个局部篇章采样窗口,取一共W个词作为当前摘要句所在的局部篇章(包含当前句子)。将待判定句与局部篇章使用[SEP]进行拼接并输入BERT模型中得到二者联合表示后针对“查询句”是否为关键句进行判定。
上述方案中,未进行特殊注明的,其文本表示部分均使用BERT进行表示,后端分类模型均使用全连接层配合Sigmoid函数进行分类。
最后,在基于BERT的单句表示基础上,对比了句子表示后:直接使用全连接层(Fullyconnected)、双向长短时记忆网络(Bi-LSTM)和双向门控循环单元(Bi-GRU)在开源软件缺陷报告分类上的效果,验证了本文提出模型在当前任务上的合理性。
3.3 实验结果对比
表3为实验组1的实验结果。其中基础分类模型为双向长短时记忆网络(Bi-LSTM),通过替换不同的预训练词嵌入语言模型,研究不同自然语言词嵌入模型在软件缺陷报告挖掘任务上的适应性。表3中以“自”开头的项目表示结合当前词向量方法,在软件缺陷报告数据上进行训练得到的词向量结果;而以“预”开头的则为在自然语言语料上训练完成的词向量结果。其中w2v表示经典的word2vec词向量训练方法(skip-gram和cbow模型);fastT为fastText词向量模型。是否参与训练则是在进行模型训练时指定词嵌入矩阵是否进一步参与到具体任务上的训练。
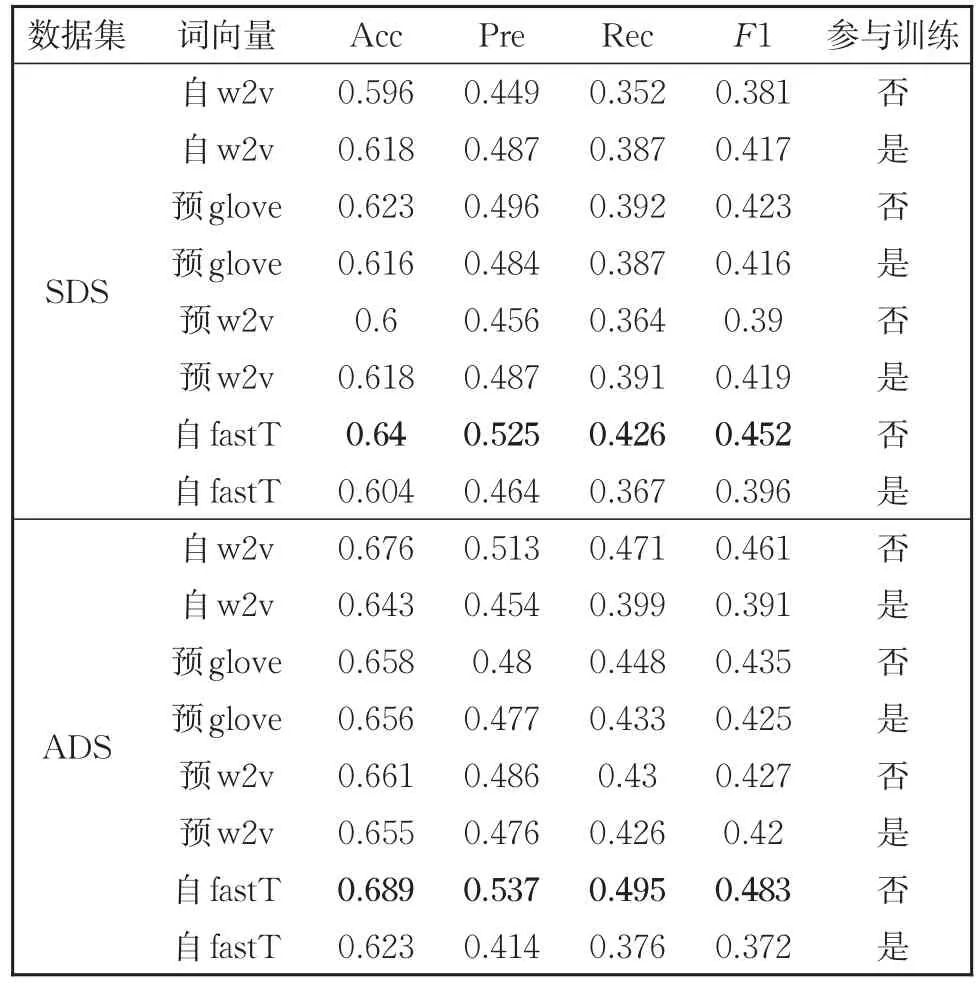
表3 不同词向量对比结果Table 3 Comparison among different word vectors
从表中可以看到在两个数据集上自行训练word2vec词向量效果较直接使用预训练结果相对较弱。而在模型训练过程中将训练好的词嵌入矩阵也一并参与训练时,模型结果也会有一定程度的降低。而综合三种词向量在该任务上的效果,可以看到使用fastText词向量针对软件缺陷报告进行表示相对取得了最优的效果。
综合上述实验对比的结果可以看到,软件缺陷报告文本作为一种领域特定的文本,其内部包含程序语言、自然语言等多种成分,容易产生未登录词的情况(Out Of Vocabulary,OOV)。直接使用在自然语言语料上预训练的word2vector词向量效果相对较差。而fastText方法使用词根词缀模式对词嵌入内容进行训练,针对软件缺陷报告中出现的代码文本、特殊的软件实体、API名称等复合新词有很好的效果。因此,针对开源软件缺陷报告挖掘的重点还是在于如何解决成分掺杂所带来的未登录词的问题,以获得更好的语义表示。进一步的BERT模型相对能够更好解决这一问题。
不同实验方案对比结果如表4所示,其中文本表示部分均使用BERT模型,表中“单句”表示直接基于单句的方案,此单句表示后直接使用全连接层进行输出分类;“前后句”表示输入待判定句子和其后句进行联合表示建模的方案;“主题”表示输入带判定句和文档标题进行联合建模的方案;而IR方案则代表基于篇章的信息检索模型;而“单句+G”表示单句表示后使用Bi-GRU进行再编码输出,即本文模型。

表4 不同实验方案对比结果Table 4 Comparison among different experimental schemes
可以看到基于前后句上下文关系判断的方案以及基于局部篇章的信息检索方案效果相对较差,而基于主题判定的效果相对直接使用单句有一定提升。在文本表示BERT基础上通过Bi-GRU进行进一步语义编码能较大地提升模型的预测能力。综合实验结果来看,相比于通用语料上的文本摘要任务,软件缺陷报告中关键句的挖掘相对更加独立,即与上下文关系较小,句子本身信息以及与问题主题的相关性相对更加重要。而改进分类后端为Bi-GRU之后获得的提升也可以看出进一步语义编码对于任务的贡献。相应的,表5中对比了使用全连接层、使用Bi-GRU以及使用Bi-LSTM(表5中“单句+L”方案)进行关键句分类的结果。可以看到,进一步编码的方案相比于全连接层整体有一定的提升。
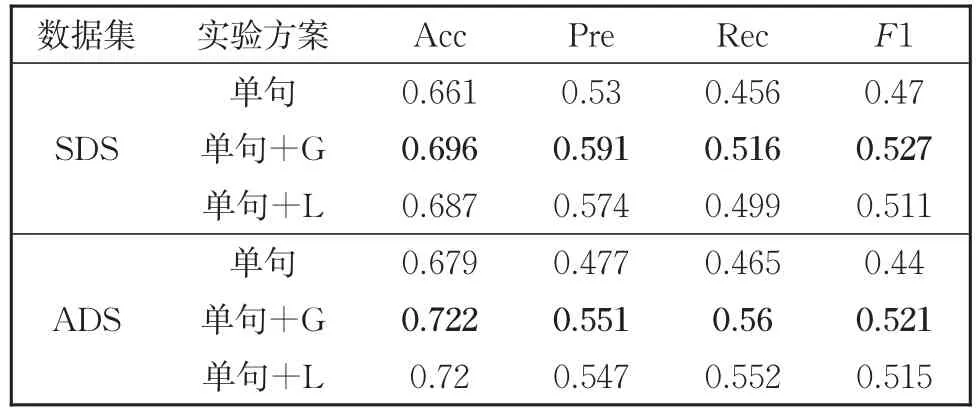
表5 不同分类后端结果对比Table 5 Comparison among different classifiers
上述结果表明结合通用的自然语言预训练模型进行软件缺陷报告表示后,仍需要进行进一步语义编码,才能对软件相关文本进行更好的挖掘。相比于LSTM方案,GRU结果相对略高,主要是由于数据集规模限制LSTM的进一步训练,可以推测在更大数据集上,序列编码分类方案会有更好的效果。
表6为本次实验选取的基线模型结果。其中TR表示textRank文本摘要模型,而TC表示textCNN句子分类模型。两种模型所使用的词向量均为在自然语言文本上已经预训练好的glove词向量。可以看到本文方案相比于基线实验在性能上有很大的提升。
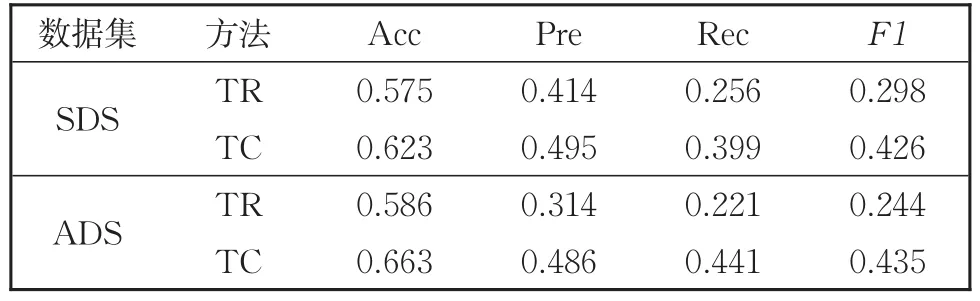
表6 基线对比实验Table 6 Comparison among differect baselines
4 结论
本文通过实验对软件缺陷挖掘任务进行了较为详实的研究,并在此基础上提出一种基于预训练模型的深度文本摘要模型。相关实验表明,软件缺陷报告数据具备更多领域特定内容(程序语言、领域特定实体名称、模板化生成内容等),在处理时不能直接应用通用领域自然语言模型,需要针对领域特定词语进行处理。同时,在结合较强的预训练自然语言模型表示之后,使用循环神经网络再次进行语义编码后结果会有进一步提升。说明软件缺陷报告这类包含程序语言的自然语言文本在通用领域语言模型表示基础上还需进一步尽心语义挖掘,才能更好地服务于后续任务。
本文仅仅针对软件缺陷挖掘任务结合自然语言预训练模型在两个规模较小的数据集上进行了探索。从实验也可以看到,在数据集上训练词向量效果略微有所降低,其中原因可能与数据量较小有一定关系。文中两个数据集均来源于开源项目,后续研究中会在大量数据集上进行相关探索,对开源软件缺陷报告文本挖掘相关理论进行进一步完善。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
体育师友(2022年1期)2022-04-17
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
软件和集成电路(2020年8期)2020-11-28
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
南风窗(2016年26期)2016-12-24
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南风窗(2015年22期)2015-09-10
