
基于自适应图学习的半监督特征选择
2022-08-13 08:22:36江兵兵何文达吴兴宇项俊浩洪立斌盛伟国
电子学报 2022年7期
江兵兵,何文达,吴兴宇,项俊浩,洪立斌,盛伟国
(1.杭州师范大学信息科学与技术学院,浙江杭州 311121;2.中国科学技术大学计算机科学与技术学院,安徽合肥 230027)
1 引言
随着信息技术的发展,实际应用中产生的数据具有很高的特征维数.这些高维数据中包含大量冗余和噪声特征,直接使用这些高维数据不仅需要消耗大量的计算资源和存储空间,还可能导致算法性能的下降.通过特征抽取或特征选择技术,可以实现高维数据的降维.其中特征抽取[1]是把数据从原始特征空间映射到一个低维特征空间;而特征选择[2]能够根据特定的规则从原始特征中挑选出少量的相关特征.由于没有改变数据的原始特征空间,特征选择对高维数据具有更好的可解释性,已广泛应用于图像分类[3]、人脸识别[4]等机器学习应用中.
根据训练样本中是否包含标签信息,可将现有特征选择算法分成3 类:监督特征选择、半监督特征选择和无监督特征选择.监督特征选择算法利用特征与标签之间的联系来评估特征的重要性.无监督特征选择算法通过数据中蕴含的特定信息(如数据的方差、分布结构等)来评估特征的相关性.监督特征选择的性能主要依赖充足的有标签训练样本[5];而无监督特征选择由于缺少标签信息的指导,其性能通常不理想[6].值得注意的是,实际应用中产生的数据往往包含大量的无标签样本和少量的有标签样本.因此,研究能够同时利用有标签样本和无标签样本的半监督特征选择算法具有重要的意义.半监督特征选择的主要思想是:充分利用训练样本的标签信息和分布结构去评估特征的相关性,进而选出具有判别性的特征.
基于半监督学习框架[7],研究者们相继提出了许多半监督特征选择算法.这些研究中,早期的方法主要以基于图的过滤式算法为主,此类算法基于特征保持数据分布结构的能力或特定信息准则来选择相关特征.例如,文献[8]提出了局部敏感的半监督特征选择(Locality Sensitive Discriminant Feature,LSDF)算法,其利用标签信息最大化有标签样本间的类间距,并基于训练样本的局部结构进行特征选择.文献[9]提出了基于迹比准则的半监督特征选择(Trace Ratio Criterion for Feature Selection,TRCFS)算法.TRCFS 首先通过标签传播计算出无标签样本的临时标签,然后根据这些临时标签在训练样本上构建类内矩阵和类间矩阵,最后基于迹比准则选择相关特征子集.然而,上述过滤式算法没有充分考虑特征间的相关性,同时也忽略了选择特征和训练分类器之间的相互作用[5].最近,研究者们将特征选择作为训练分类器的一部分,提出了能够在训练过程中自动进行特征选择的嵌入式半监督特征选择算法.例如,Chang 等人提出的半监督特征选择(Convex Semi-supervised Feature Selection,CSFS)算法通过最小化预测标签与样本投影的损失来训练特征投影矩阵,并利用特征投影矩阵上的稀疏约束实现特征选择[10].Chen等人提出了重新调节线性回归半监督特征选择算法,其利用标度因子调节回归系数,最后选择相应特征子集[11].
值得注意的是,上述嵌入式半监督特征选择算法直接利用训练样本的预测标签去训练特征选择模型,同时忽略了样本的局部结构信息[4].然而,半监督场景下预测标签中包含的真实标签信息非常有限,直接基于预测标签训练得到的特征选择模型很难选出完全有效的特征子集.为了充分利用样本中蕴含的局部结构信息,Ma 等人将流形正则化[12]和L2,1稀疏约束结合起来,提出了一种基于图嵌入的半监督结构化稀疏特征选择(Structural Feature Selection with Sparsity,SFSS)算法[13].Luo 等人使用代替L2,1约束,提出基于稀疏回归的半监督特征选择算法[14].此外,在SFSS算法的基础上,文献[15]将约束同时应用到投影损失函数和特征投影矩阵上.上述基于图嵌入的半监督特征选择算法在一些实际应用中取得了较好的性能,但是它们忽略了特征选择与局部结构学习之间的相互作用,难以有效地利用数据的局部结构信息,进而影响所选特征子集的有效性[16].具体来说,这些算法直接基于原始特征空间中数据间的欧式距离去构建用于刻画数据局部分布结构的近邻图,并在特征选择的过程中使用固定不变的近邻图.然而,原始特征空间中通常包含大量的噪声和冗余特征,这会使构建的近邻图陷入局部最优.因此,学习高质量的近邻图对获取数据的局部结构及提升所选特征子集的有效性具有重要作用.
为解决上述问题,本文提出了一种基于自适应图学习的半监督特征选择(Semi-supervised Feature Selection with Adaptive Graph learning,SFSAG)算法.SFSAG首先通过学习样本间的近邻结构,有效利用训练样本中蕴含的局部分布信息;其次,充分利用样本在投影特征空间中的近邻关系;最后,通过稀疏投影学习和标签传播[17]有效地预测无标签样本的标签,并将学习到的特征投影矩阵用于选择判别性强的特征.本文的主要贡献总结如下:
(1)所提算法能够充分利用样本在投影特征空间中的近邻信息,从而有效地学习样本的局部分布结构,并提高所选特征的有效性和算法的性能;
(2)所提算法在选择相关特征的同时还能自适应地学习样本的局部近邻结构,并通过两者间的信息交互来降低噪声特征对算法的不利影响;
(3)提出了一种有效的优化方法来求解目标函数,并通过合成数据集和高维数据集上的实验验证了所提算法的有效性及其相对其他算法的优越性.
2 自适应图学习的半监督特征选择
本文所提基于自适应图学习的半监督特征选择(SFSAG)算法包含稀疏特征投影学习、自适应图学习和标签传播.在描述算法模型之前,首先给出算法中的符号说明.令X=表示训练样本,其中,xi∈Rd表示第i个样本,n为训练样本数,d为特征数.Y=[YlYu]Τ∈Rn×c为标签矩阵,c表示样本的类别标签数,Yl表示有标签样本的标签,如果样本xi属于第j类,那么对应类标签Yij=1,否则Yij=0;Yu表示无标签样本的真实标签.由于在训练过程中无标签样本的真实标签Yu是未知的,所以在训练时将其设置为0矩阵[14].
2.1 算法描述
SFSAG 算法首先在半监督框架下进行稀疏特征投影学习,其公式定义如下

其中,W∈Rd×c表示特征投影矩阵,b∈Rc为偏置向量,F=[Fl Fu]Τ∈Rn×c表示训练样本的预测标签矩阵,γ是正则化参数.式(1)将L2,1稀疏约束施加在线性投影损失和投影矩阵W上,不仅可以使模型更加鲁棒,还能够使学习到的W具有行稀疏的特点.将有标签和无标签样本输入到线性回归模型中,然后通过最小化特征投影子空间与预测标签F之间的损失简化特征空间,从而实现特征选择.基于式(1),研究者们相继提出了一些嵌入式半监督特征选择算法,如文献[10,11].然而预测标签F中包含的真实标签信息相对有限,完全基于F训练的特征选择模型很难选出判别性强的特征子集.研究表明,在样本标签信息较少时,训练样本(主要是无标签样本)中蕴含的局部分布信息对提升特征选择效力非常重要[18].
为了充分利用无标签样本,研究者们通过构建样本间的近邻图来获取样本的分布信息(主要是局部结构信息).传统的方法[19]使用高斯核函数去构造样本间的近邻图S,这种方式主要存在两个问题:首先,直接通过高斯核构建的近邻图没有考虑原始特征空间中存在冗余和噪声特征,容易产生不可靠的近邻图,进而影响所选特征保持数据分布结构的能力及特征选择性能.其次,需要提前设定高斯核宽度参数,影响算法的实用性和通用性.最近,Nie 等人提出了一种自适应近邻图构造方法[20]:
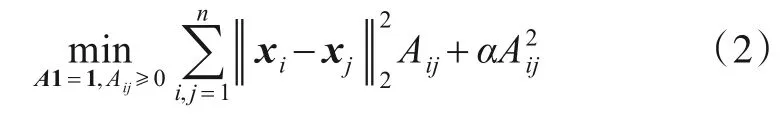
其中,Aij度量了第i个样本xi和第j个样本xj在原始特征空间中的相似性,正则化参数α能够避免学习到的相似性矩阵A出现平凡解和均匀分布.具体来说,如果α→0,样本将选择最近邻的样本作为其邻居;如果α→+∞,任意样本间的相似性由于A中的每一行Ai(i=1,···,n)相互独立,可单独求解行向量Ai.因此式(2)简化为


相比于传统的构图方法(如高斯核方法),上述构图方法可以为每个样本选择k个近邻样本,并自适应地确定样本与近邻样本之间的相似性,且不需要使用额外的参数.虽然上述构图方法能够根据原始特征空间中样本间的近邻信息自适应地构建近邻图,但是在原始特征空间中样本间的近邻信息容易被冗余和噪声特征干扰.由于特征投影能够有效减轻冗余和噪声特征的不利影响[16],因此样本在投影特征空间中的近邻关系能够更加准确地描述样本的局部分布结构.因此,本文提出的自适应图学习模型将特征投影W直接引入式(2)中:

其中,第一项度量了样本在投影特征空间中的近邻结构.具体来说,假如xi和xj在投影特征空间中较接近,即较小,那么此时xi和xj的相似性Sij应该较大.
在算法优化的初始阶段,可令S等于A,这样可以使所提构图模型能够在原始特征空间中样本间近邻信息的辅助下,通过学习投影特征空间中的样本近邻关系,更加有效地获取数据的真实局部结构.正则化项能够避免S出现平凡解,其中参数θ和α类似,可根据邻居样本数k自动确定:

为了有效地结合所提自适应图学习模型和稀疏投影学习,实现在选择相关特征子集的同时还能自适应地学习样本在投影特征空间中的局部结构,SFSAG 算法通过标签传播对预测标签F进行平滑约束,其目标函数为

其中,第一项表示投影特征空间中的样本近邻结构对图的约束;第二项能够避免S出现平凡解,θ是正则化参数;第三项为定义在预测标签F上的平滑约束,使近邻样本具有相似的预测标签,LS表示定义在S上的拉普拉斯矩阵,λ是正则化参数;第四项能够使有标签样本的预测标签Fl与其真实标签Yl尽量保持一致,B为对角矩阵,通过将其前l个对角元素设置为一个较大的常数,充分发挥有标签样本对算法的引导作用.
2.2 算法优化
SFSAG 算法的目标函数中包含目标近邻图S、预测标签F、投影矩阵W和偏差向量b,以及投影矩阵W的L2,1范数约束,这导致无法直接优化目标函数及求解参数.因此,使用交替迭代优化方法来求解目标函数.
首先,固定F和W,目标函数可简化为
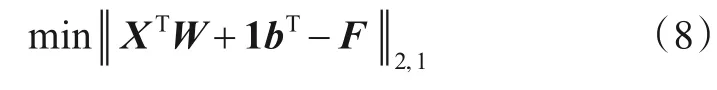
计算式(8)关于b的导数,并令导数等于0,可直接得到b的最优解

然后,固定S和W,并将式(9)中的b代入到目标函数中,可得

将Q=BY+2βZXΤW代入到式(14)中,并计算式(14)关于W的导数,可得W的最优解:

其中,矩阵S的每一行都是相互独立的,因此,可以单独求解S中的行向量S:

式(18)可利用文献[22]中提到的方法直接求解.假设每个样本有k个近邻样本,那么参数θ的值可以通过式(6)自动确定.
综上所述,SFSAG 目标函数的迭代求解过程如下:首先,初始化S=A和F=Y;其次,利用式(9)和式(12)分别计算b和F;然后利用初始化的对角矩阵K和式(15)更新特征投影矩阵W,并基于当前的W更新K,通过式(18)自适应地更新近邻图S,重复上述优化过程,直到目标函数满足收敛条件.所提算法通过稀疏投影学习可以将特征投影矩阵W的行向量wi(i=1,···,d)与训练样本X的对应特征关联起来.因此,W的第i个行向量直接度量了样本X中第i个特征的重要程度[12]越大表明对应特征越重要).通过计算特征投影W的行向量模长,并将其从大到小排序,最终选择对应前r个特征作为特征选择的输出.
3 实验结果与分析
本节将在合成数据集和高维实际数据集上测试SFSAG 算法,并将其与一些先进的半监督特征选择算法进行对比,以验证SFSAG的有效性.
3.1 合成数据集上的实验
本实验参照文献[4]生成Two-Moon 数据集来验证SFSAG 算法获取样本局部结构的能力及其对噪声特征的鲁棒性.Two-Moon 数据集的原始数据分布如图1(a)所示:数据包含2 个类簇,每个类簇约有100 个样本点,分别是图中的红色和黑色样本点,其中蓝色圆圈表示有标签样本.使用式(2)构造的初始化近邻图A如图1(b).从中可以看出,虽然初始化图A能大致刻画数据的分布结构,但是2 类簇间仍存在一些相互连接的边,使类簇无法完全分离,这表明基于原始特征空间的样本间距离信息构建的近邻图A并不完全可靠.同时,当在Two-Moon 的特征空间中增加8 个随机噪声特征(范围在-0.3~0.3)时,此时构造的近邻图如图1(c)所示,可以看出,增加的噪声特征使不同类簇间连接边数增多,不仅降低了近邻图可靠性,还增加了分离不同类簇的难度.图1(d)展示了SFSAG 基于初始化图A和数据在投影特征空间中的近邻结构学习到的近邻图S,可以看出,在S中,两类簇间不存在相互连接的边,说明S不仅准确获取数据的分布结构,还能有效分离不同的类簇.实验结果表明:SFSAG 在进行特征选择的同时还能自适应地利用数据在投影特征空间中的近邻信息,进而降低噪声对数据局部分布结构的干扰,提高算法的性能.
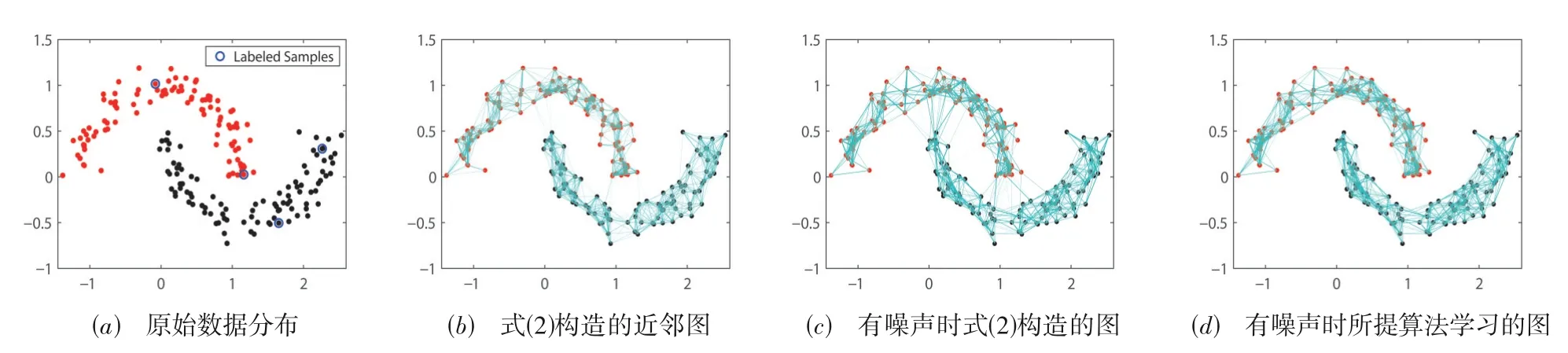
图1 公式(2)和所提算法在Two-Moon数据集上构建的近邻图
3.2 高维实际数据集上的实验
为了进一步验证SFSAG 算法在高维数据集上的性能,本节实验使用了8 个常用的高维实际数据集,其详细信息如表1所示.

表1 实验数据集描述
本实验在每个数据集中随机选择70%的样本作为训练集,剩余样本为测试集.实验首先利用特征选择算法在训练集上选出相关的特征子集,然后在所选特征子集表示的有标签样本上训练线性SVM 分类器(正则化参数固定为0.1),最后通过计算分类器在由所选特征表示的测试样本上的分类准确率来验证特征选择算法的有效性.实验选择4 种半监督特征选择算法与SFSAG 算法进行对 比,分别是CSFS,LSDF,SFSS 和TRCFS.为了降低实验结果的统计误差,每组实验都会在不同的训练集和测试集分组上独立运行20 次,使用平均分类准确率作为实验结果.所有实验算法的正则化参数或平衡参数使用网格搜索法在{10-3,···,103}的范围内调整.所提算法希望有标签样本上的预测标签Fl能够充分接近它们的真实标签Yl,由于无标签样本的真实标签Yu未知,所以在算法训练过程中将其设置为0 矩阵,因此SFSAG 算法只考虑有标签样本的真实标签Yl和预测标签Fl的关系.于是将对角矩阵B的前l个对角元素设置成较大的常数(104);将B的后u个对角元素设置成较小的常数(10-4).实验从训练集中随机选择不同比率的有标签样本,并通过改变所选特征数量来分析特征选择算法的性能.图2、图3 分别展示了使用10%和30%有标样本时算法分类准确率与所选特征数量的变化曲线.
从图2、图3可以看出:(1)在实验数据集上,特征选择算法的分类性能随着选择特征数量的增加而提高,而且SFSAG 算法几乎在所有数据集上的分类准确率均高于对比算法,验证了所提算法在高维数据集上的有效性;(2)在大多数数据集上,基于图的过滤式算法(LSDF 和TRCFS)的性能表现均不及基于图嵌入式的SFSS 算法,且SFSS 算法的性能不如SFSAG 算法,这表明特征空间的稀疏投影学习和自适应的局部结构学习是影响特征选择的重要因素;(3)当标签样本的比率为10%时,CSFS 在所有实验数据集上的性能均不如基于图嵌入的算法,甚至在多个数据集(如Binalpha、Coil20和JAFFE)上的性能不如基于图的过滤式算法,这表明在有标签样本较少时,利用样本的局部结构信息对提升特征选择的性能具有重要的意义.

图2 使用10%的有标签样本,SFSAG和对比算法在实验数据集上的分类准确率与所选特征数量的变化曲线
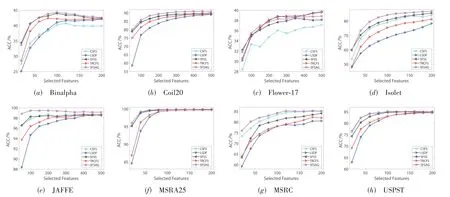
图3 使用30%的有标签样本,SFSAG和对比算法在实验数据集上的分类准确率与所选特征数量的变化曲线
为了进一步分析SFSAG 与现有半监督特征选择算法在不同有标签样本比率下的分类性能,下面实验将训练样本中有标签样本的比率设定在{10%,20%,30%,40%,50%}范围内,并将所选特征数量分别固定为{80,200,200,80,200,80,80,80}.实验结果如表2 所示,其中加粗项为相同标签比率下算法在对应数据集上的最优结果.从表2 中可以看出,特征选择算法的分类准确率随着样本标签比率的增加不断增长,这表明在有标签样本充足时,特征选择算法能够选择出判别性更强的特征子集.在不同的标签比率下,SFSAG 算法在实验数据集上都能够取得较好甚至最好的分类准确率.此外,在MSRC 数据集上,当有标签样本比率为10%和20%时,基于预测标签的CSFS 算法的性能明显低于LSDF、TRCFS 和SFSS 算法.当标签比率达到30%甚至更高时,CSFS 算法的性能仅仅低于SFSAG 算法,这表明在样本的标签比率较低时,SFSAG 算法能够更充分地利用样本的局部结构信息,在性能上较其他算法更具优势.值得注意的是,SFSAG算法在实验数据集上的分类准确率均高于SFSS 算法,进一步验证了SFSAG算法的有效性.

表2 使用不同比率的有标签样本,SFSAG以及其他半监督特征选择算法在测试集上的平均分类准确率(均值±标准差%)
3.3 算法的参数敏感性和收敛性分析
SFSAG 算法包含3 个正则化参数λ、β和γ.本实验分析参数在{10-3,···,103}范围内变化对SFSAG 性能的影响.图4 给出了β、γ和λ在Isolet 和Coil20 上 对SFSAG 性能的影响.实验结果表明:SFSAG 算法对较宽取值范围内的参数β、γ和λ的敏感程度不同.从图4可以看出,在给定所选特征数量时,参数β、γ和λ的变化对算法性能的影响较大.具体来说,在所选特征数量不变时,算法性能会随着β、γ和λ取值的变化而明显变化,表明SFSAG 算法性能对特征空间中的稀疏投影学习和预测标签上的平滑约束更敏感;同时当所选特征数量较少时,SFSAG 算法的性能对参数β、γ的变化更敏感.

图4 在Isolet和Coil20数据集上,参数β,γ和λ对算法性能的影响
本文使用交替迭代优化方法求解SFSAG 算法的目标函数.为了验证SFSAG 算法的收敛性,图5 展示了SFSAG 算法的目标函数与迭代次数的变化曲线,从图中可以看出:在实验数据集上,SFSAG 算法的目标函数只需迭代5次就能达到收敛状态,验证了交替迭代优化求解方法的快速性和有效性.

图5 在实验数据集上SFSAG算法的目标函数与迭代次数的变化曲线
4 结论
本文提出了一种基于自适应图学习的半监督特征选择(SFSAG)算法.首先,SFSAG 算法充分考虑了样本在投影特征空间中的近邻结构,能够自适应学习样本间的最优近邻图,从而充分利用样本中蕴含的数据分布信息.其次,SFSAG算法能够同时进行特征选择和样本的局部结构学习,并通过两者间的交互来提升模型对噪声特征的鲁棒性,从而有利于选择判别性更强的特征子集.然后,使用交替优化方法来求解参数的最优解,并通过实验验证了SFSAG 算法的收敛性.最后,合成数据集和高维实际数据集上的大量实验充分验证了所提构图方法的有效性以及SFSAG算法的优越性.
猜你喜欢
数学物理学报(2021年1期)2021-03-29 03:14:42
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
数学物理学报(2019年6期)2020-01-13 06:08:16
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
数学物理学报(2017年5期)2017-11-23 07:51:31
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
振动工程学报(2014年4期)2014-03-01 01:15:41
