
基于并行混合网络与注意力机制的文本情感分析模型
2022-08-12 02:30田乔鑫孔韦韦滕金保王照乾
计算机工程 2022年8期
田乔鑫,孔韦韦,2,滕金保,王照乾
(1.西安邮电大学 计算机学院,西安 710121;2.广西可信软件重点实验室,广西 桂林 541004)
0 概述
随着互联网和社交媒体的快速发展,越来越多的用户参与到内容生产和信息发布的流程中,逐渐从信息获取者转变为信息创造者。用户在社交媒体上发表个人主观性言论,针对这些主观性言论进行情感分析可以获得极具价值的信息,然而通过人工方式对其进行分析需要消耗大量人力与财力,因此文本情感分析技术成为自然语言处理领域的热门研究方向。
文本情感分析是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程[1]。传统的文本情感分析方法主要包括基于情感词典[2]和基于有监督机器学习[3]的方法,这类方法在处理小数据文本情感分析任务时有着不错的表现,同时也有较强的可解释性,但传统方法主要存在文本表示稀疏性且泛化能力较弱的问题。HINTON[4]提出的分布式表示概念以及MIKOLOV 等[5]提出的Word2vec 词向量训练工具解决了词向量的表示稀疏性问题,使得文本的向量表示可以包含一定的语义信息。KIM[6]将卷积神经网络(Convolutional Neural Network,CNN)用于句子分类任务中,采用3 种不同大小的卷积核来采集文本的N-grams 特征,再进行特征融合,取得了很好的分类效果,但是循环神经网络(Recurrent Neural Network,RNN)不能采集到文本的上下文信息。XIAO 等[7]使用双向长短期 记忆(Long Short-Term Memory,LSTM)网络处理文本情感分析任务,通过两个方向神经元的循环计算提取文本的上下文信息。LAI 等[8]为了进一步提升分类效果,将LSTM 与CNN 相结合,提出一种循环卷积神经网络(Recurrent Convolutional Neural Network,RCNN)模型,先使用双向LSTM 提取文本的上下文信息,再通过最大池化层提取主要特征进行文本分类。ABID等[9]构建CNN 与RNN 联合体系结构,提高了推特情感语料库的分析效果。
基于神经网络的文本情感分析方法相比传统方法获得了更好的文本表示以及更强的特征提取能力,但却没有考虑关键信息对文本情感倾向的影响。BAHDANAU 等[10]将注意力机制应用到自然语言处理领域,通过注意力机制识别出文本中的关键信息,有效提高了神经翻译模型的效果。YANG 等[11]提出一种分层注意力机制,在词语和句子两个层次分别使用注意力机制,同时考虑文本中关键词和关键句的重要性,适用于长文本的分类和处理。VASWANI等[12]舍弃了传统的注意力机制依赖于神经网络的固有模式,提出了基于多头注意力的Transformer 模型。为了取得更好的文本情感分析效果,研究人员开始将注意力机制融入RNN 与CNN 的混合模型。赵亚南等[13]提出融合多头自注意力与CNN 的文本情感分析模型,在金融新闻文本上进行情感分析且取得了不错的效果。袁和金等[14]提出的文本情感分析模型先用多通道的卷积神经网络提取文本特征信息,再将特征信息送入双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)并结合注意力机制获得上下文情感特征,同时引入Maxout 神经元避免训练过程中的梯度弥散问题。郭宝震等[15]提出的句子分类模型先对词向量使用注意力机制,再使用双路卷积神经网络对句子进行分类。WANG 等[16]针对在线评论中特定方面的情感极性进行更细粒度的情感分析,提出一种关系图注意力网络,更好地建立了方面词和观点词之间的联系。
基于分布式词向量和深度学习的文本情感分析方法要优于传统基于统计学习的文本情感分析方法,基于神经网络和融入注意力机制的文本情感分析模型由于具有更强的特征提取能力和对关键信息的加强处理,取得了更好的情感分析结果。本文在以上研究的基础上,提出一种基于并行混合网络与双路注意力机制的文本情感分析模型GCDA。针对不同网络的特点采用两种不同的词向量作为并行混合网络的输入,获得更丰富的文本信息。利用两种神经网络并行混合分别提取文本的全局特征和局部特征。使用双路注意力机制加强处理两种特征中的关键信息,提升模型的分类效果。
1 GCDA 文本情感分析模型
GCDA 文本情感分析模型结构如图1 所示,包括如下组成部分:

图1 GCDA 模型结构Fig.1 GCDA model structure
1)词嵌入层:将文本通过GloVe 和Word2vec 嵌入为两种不同的词向量。
2)特征提取层:将GloVe 词向量输入到BiGRU中提取包含上下文语义信息的全局特征,对Word2vec 词向量采用CNN 提取局部特征。
3)双路注意力层:对上一层输出的全局特征和局部特征使用双路注意力机制加强其中的关键信息。
4)输出层:对双路注意力层输出的两种特征信息进行特征融合,并使用softmax 分类器进行分类。
GCDA 模型使用BiGRU 和CNN 神经网络。CNN 通过卷积操作提取卷积核范围内词语之间的局部特征,且受卷积核大小限制一般适合处理短文本信息。BiGRU 通过神经元之间的循环依赖可以提取到文本中词语之间的关联信息,即使文本的长度较长也不会遗漏,同时采用双向结构还可以采集到文本的上下文信息。但由于门控机制对信息的过滤,因此不会提取到较强的局部性特征,而是提取整个文本的全局性特征。GCDA 模型将BiGRU 和CNN 并行混合构成特征提取层,结合两个神经网络的特点进行特征提取上的互补,使得模型适用于长文本和短文本。同时由于文本情感分析本质上也是分类任务,因此该模型也可以应用于文本分类、意图识别、命名实体识别等任务。针对具体的任务使用特定数据集进行训练,并根据具体分类任务的类别数目对输出层参数进行微调,可以将模型推广应用至其他下游分类任务。
1.1 词嵌入层
词嵌入层将文本信息转换为向量作为模型的输入数据。根据不同网络的特点,采用Word2vec[5]和GloVe[17]两种词向量分别作为两个神经网络的输入。Word2vec 采用局部上下文窗口训练词向量,与CNN采用卷积核窗口提取特征类似,都只能关注到窗口范围之内的上下文信息,故作为CNN 的输入来提取更强的局部特征。GloVe 利用语料库的全局统计信息构建词的共现矩阵,再基于共现矩阵训练得到包含全局信息的词向量,将GloVe 训练得到的词向量作为BiGRU 的输入用来提取全局特征和上下文信息。
由于神经网络需要接收固定长度的输入,因此在词嵌入前需要先对不定长度的文本进行预处理。假设每个文本S固定长度为n,则每个文本可以表示为S={w1,w2,…,wn},长度超出n的部分信息舍弃,不足的部分采用
1.2 特征提取层
1.2.1 全局特征提取
由于文本信息的有序性特点,因此RNN 非常适合用来处理文本信息。RNN 每一个神经元的输出由当前时刻的输入和前一时刻的记忆共同决定,所以可以捕获文本之间的长期依赖关系,通常用来提取全局特征,但是传统的RNN 由于梯度爆炸和梯度消失问题导致在实际应用中难以训练。HOCHREITER 等[18]提出的LSTM 网络通过 在RNN神经元内部设置输入门、遗忘门和输出门3 个门控单元,解决了RNN 的梯度消失问题,使得LSTM 相比RNN 更容易训练。CHO 等[19]提出的门控循环单元(Gated Recurrent Unit,GRU)只设置了重置门和更新门,减少了网络中的相关参数,在保留LSTM 优点的同时提高了训练速度。因此本文采用双向GRU 网络来提取文本的全局特征和上下文信息,GRU 内部结构如图2 所示。

图2 GRU 内部结构Fig.2 GRU internal structure
在图2 中,xt表示当前时刻的输入,ht−1表示前一时刻的记忆信息,br、bz、b为偏置项,rt表示重置门,zt表示更新门,Wr与Wz分别表示重置门与更新门中的权重参数,ht表示当前时刻的输出,具体计算过程如式(1)~式(4)所示:

通过嵌入层GloVe 训练得到的文本向量矩阵A={x1,x2,…,xn},以词向量xi为例作为双向GRU 的输入,经过前向和后向GRU 编码得到的隐藏层表示分别包含了上文信息和下文信息,则词向量xi经过双向GRU 提取到的包含上下文信息的全局特征表示如下:
整个文本矩阵A经过双向GRU 提取到包含上下文语义信息的全局特征表示如下:

使用双向GRU 提取文本信息全局特征的过程如图3 所示,其中dim 表示文本矩阵维度。
图3 BiGRU 提取全局特征的过程Fig.3 Process of BiGRU extracting global features
1.2.2 局部特征提取
CNN 具有较强的特征提取能力,由于卷积核窗口大小有限,一次只能提取到局部范围内的信息,因此采用CNN 来提取文本的局部特征。本文采用3 个不同大小的卷积核来分别提取文本不同的N-grams局部特征。将经过Word2vec 训练得到的文本向量表示矩阵B={y1,y2,…,yn}作为CNN 的输入,使用卷积核在文本矩阵中自上向下滑动提取局部特征。对于窗口大小为r的卷积核通过第j次卷积操作提取到的局部特征cj表示如下:

其中:f为ReLU 非线性激活函数;w代表卷积核中的参 数;b为偏置 项;yj:j+r−1表示文 本矩阵的第j行到第j+r−1 行中卷积核一次共读取r行的词向量。卷积核在文本矩阵中自上向下滑动共进行n−r+1 次卷积操作,所提取到的局部特征矩阵C表示如下:

已有方法在卷积层提取到特征之后常常采用池化层来进一步提取特征,但池化操作会造成一定的信息丢失,且会破坏文本特征的时序性特点,所以本文方法在卷积层之后弃用池化层使用注意力层,该方法可以减少信息的损失并对文本中关键信息进行加强。使用CNN 对文本矩阵B进行局部特征提取的过程如图4 所示。
图4 CNN 提取局部特征的过程Fig.4 Process of CNN extracting local features
1.3 双路注意力层
在情感分析任务中,文本中常常包含表达强烈情感意向的情感词,这些词语会对整个文本的情感倾向产生至关重要的影响,使用注意力机制来捕获这些关键情感词并分配较大的概率权重对提高情感分析准确率有着极大的帮助。
对特征提取层提取到的全局特征和局部特征分别使用注意力机制加强其中的关键信息,先按照重要程度的不同对全局特征hi和局部特征cj分配不同的注意力权重,如式(9)、式(10)所示:

其中:wh和wc表示权重参数矩阵;bh和bc为偏置项;tanh 为非线性激活函数;vi和vj为经过激活函数激活后文本的权重向量。
在对注意力权重进行归一化处理后,得到关于全局特征hi和局部特征cj的注意力分数ai和aj,如式(11)、式(12)所示:

按照每个词不同的重要程度,引入经过归一化处理得到的注意力分数ai和aj,对提取到的每个特征hi和cj计算加权和,得到经过注意力加强关键信息的整个文本的全局特征zh和局部特征zc,如式(13)、式(14)所示:

本层使用双路注意力机制对BiGRU 和CNN 并行提取到的特征分别做加强处理,为关键信息分配更高的注意力权重,从而提高模型的分类效果。
1.4 输出层
输出层由全连接神经网络和softmax 激活函数构成。分类前首先对注意力层得到的两种特征信息进行特征融合,得到文本最终的特征表示t,如式(15)所示:

然后将融合得到的特征输入到全连接神经网络中,使用softmax 激活函数计算得到文本的情感概率p,最终进行情感分类处理,如式(16)所示:

其中:w为权重向量;b为偏置项。
最后根据情感概率值p确定整个文本的情感类别。
2 实验与结果分析
2.1 实验环境与数据集
实验在Windows10 系统下进行,CPU 为Intel®i5-6300HQ 2.3 GHz,编程语言采用Python 3.7.9,深度学习框架采用PyTorch 1.0.1。
数据集采用情感分类公开数据集IMDb[20]和SST-2。IMDb 数据集是从IMDb 电影评论网站收集的50 000 条电影评论,情感极性分为积极和消极两类,每类各占总评论数的一半,该数据集中训练集和测试集各包含25 000 条影评数据。SST-2 是斯坦福标准情感分析数据集的二分类版本,去除了中立情感的数据部分。两个数据集的具体信息如表1所示。

表1 数据集信息Table 1 Dataset information
2.2 实验评估指标
实验采用准确率(A)、精确率(P)、召回率(R)和F1 值(F)作为模型的评估指标。用于计算这些指标的分类混淆矩阵如表2 所示。

表2 分类混淆矩阵Table 2 Classification confusion matrix
在表2 中,TP表示将样本正确分类为积极情感的个数,FP表示将样本错误分类为积极情感的个数,TN表示将样本正确分类为消极情感的个数,FN表示将样本错误分类为消极情感的个数。评价指标中准确率表示所有预测正确的结果占总结果的比率;精确率是针对结果,表示所有预测为正例的结果中预测正确的比率;召回率是针对样本,表示样本中的正例被正确识别的比率;F1 值是召回率和精确率的调和平均值,可以综合衡量模型的分类效果。计算公式如式(17)~式(20)所示:

2.3 实验参数设置
除模型本身的结构设计以外,参数设置也会影响模型的特征提取能力以及训练效果,从而对最终的实验效果造成影响,所以参数调优是实验中的重要步骤。采用控制变量法经过反复实验确定模型的最佳参数,以对结果影响较大的随机失活率(Dropout)、BiGRU 隐藏层参数维度(Hidden_Size)、卷积核通道数(Nums_Channels)3 个参数为例进行分析,在IMDb 数据集上参数的调整对准确率的影响实验结果如表3 所示。由于模型中卷积核尺寸(3,4,5)表示采用大小分别为3、4、5 的卷积核,因此(32,32,32)表示3 个卷积核对应的通道数均为32。
表3 参数设置对准确率的影响Table 3 Effect of parameter settings on the accuracy
Dropout 是按照概率对一些神经元的激活值进行随机失活处理,用来避免过拟合现象。当其值设置的较小时几乎不能避免过拟合,当其值设置的较大时失活的值太多会造成特征丢失,GCDA 模型Dropout 取0.4 时效果较好。BiGRU 的隐藏层参数维度即提取到的特征维度,若维度太小则不足以进行特征表示,若维度太大则会增加模型的训练时间,且更容易发生过拟合。卷积核采用多通道的方式进行局部特征的提取,由于有BiGRU 提取的全局特征作为补充,因此卷积核通道数设置为32 时便可以取得较好的效果。经过实验确定模型参数后,在IMDb 数据集上对模型进行训练,平均每个Epoch 所需的时间为249.45 s,模型中的参数迭代至最优并且趋于平稳所需的运行时间成本约为10 个Epoch。模型整体的参数设置如表4 所示。

表4 模型参数设置Table 4 Model parameter setting
2.4 对比实验与结果分析
2.4.1 情感分析模型对比实验与结果分析
为验证GCDA 模型的有效性,将其在IMDb 和SST-2 两个公开数据集上与经典模型和最新模型进行对比实验,具体对比模型如下:
1)TextCNN[6]:该模型采用3 种大小的多通道卷积核,提取文本不同的N-grams 特征。
2)BiLSTM[7]:该模 型采用双向长短 期记忆网络,提取文本的上下文信息。
3)BiLSTM+EMB_Att[21]:该模型采用词向量注意力机制先识别关键信息,再使用双向长短期记忆网络提取文本的上下文信息。
4)Att-DouCNN[15]:该模型使用词向量注意力机制提取关键词信息,并使用双路卷积神经网络提取句子特征。
5)Att-C_MGU[22]:该模型结合卷积神经网络和最小门控单元,并融合注意力机制,提取文本的深层特征,并且参数更少,收敛速度较快。
6)Att-MCNN-BGRUM[14]:该模型先使用多通道卷积神经网络提取特征信息,再将特征信息送入双向GRU 中,结合注意力机制得到文本的上下文情感特征。
7)Bi-SGRU-Att[23]:该模型采用双向切片GRU对文本序列进行切片实现并行处理,减少了模型训练所需的时间,并融入注意力机制提取关键信息。
经过对比实验,以上模型和本文GCDA 模型的实验结果分别如表5 和表6 所示。通过表5 和表6 的实验数据可知,在两个数据集上GCDA 模型相比其他模型分类效果均有一定的提升。GCDA 模型在IMDb 和SST-2 两个数据集上的准确率分别达到了91.73%和91.16%,相比经典的TextCNN 与BiLSTM模型在准确率和F1 值上约提升了3 个百分点。GCDA 模型相比IMDb 和SST-2 两个数据集上的对照组最优模型准确率分别提高了0.87 和0.66 个百分点。GCDA 模型在IMDb 数据集上相比BiLSTM+EMB_Att 模型和Bi-SGRU-Att 模型准确率分别提高了2.70 和0.87 个百分点。GCDA 模型在SST-2 数据集上相比Att-DouCNN 模型准确率提高了2.56 个百分点,这是由于使用BiGRU 与CNN 组成的并行混合网络可以同时提取到文本的长期依赖信息和局部信息,组成更丰富的文本特征表示从而提升分类效果。GCDA 模型相比Att-C_MGU 模型和Att-MCNNBGRUM 模型在IMDb 数据集上准确率分别提高了3.57 和0.93 个百分点,说明采用双路注意力机制可以更全面地捕获文本中的关键信息,进一步提高分类准确率。

表5 IMDb 数据集上不同模型的实验结果Table 5 Experimental results of different models on the IMDb dataset %
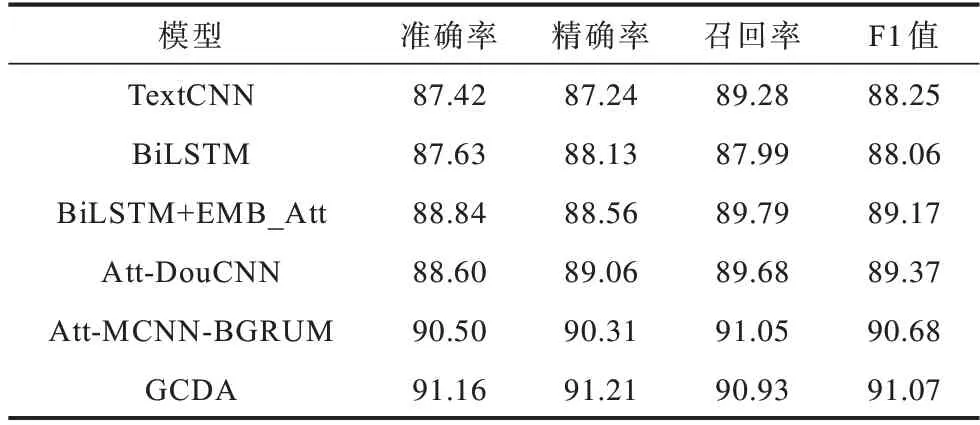
表6 SST-2 数据集上不同模型的实验结果Table 6 Experimental results of different models on the SST-2 dataset %
2.4.2 双路注意力机制对分类效果的影响
为了进一步验证双路注意力机制对模型分类效果的影响,在原模型的基础上进行修改得到单路注意力机制和无注意力机制的两组模型作为对照进行对比实验,具体对照模型如下:
1)无注意力机制模型:BiGRU+CNN,去掉原模型的双路注意力机制,采用CNN 与BiGRU 的并行混合。
2)单路注意力机制模型:(1)BiGRU+CNN-Att,去掉原模型中BiGRU 部分的注意力机制,采用BiGRU 与CNN-Att 的并行混合;(2)BiGRU-Att+CNN,去掉原模型中CNN 部分的注意力机制,采用BiGRU-Att 与CNN 的并行混合。
以上模型的参数设置与GCDA 模型相同,在IMDb 和SST-2 数据集上进行实验,共训练10 个Epoch,每次迭代的结果如图5 和图6 所示。

图5 4 种模型在IMDb 数据集上的准确率变化趋势Fig.5 Accuracy variation trend of four models on IMDb dataset

图6 4 种模型在SST-2 数据集上的F1 值变化趋势Fig.6 F1 value variation trend of four models on SST-2 dataset
通过对比无注意力机制模型和融入注意力机制模型的实验结果可知,使用注意力机制捕获文本序列中的关键信息可以明显提高模型的整体分类效果。在单路注意机制模型中,BiGRU+CNN-Att 模型使用注意力机制识别CNN 提取到的局部特征中的关键信息,BiGRU-Att+CNN 模型则识别BiGRU 提取到的全局特征中的关键信息,对比其结果可以发现使用注意力机制捕获全局特征中的关键信息能提升分类效果,并且在文本长度较长的IMDb 数据集上提升效果更明显。
通过对比GCDA 模型和单路注意力机制模型的实验结果可知,使用双路注意力机制同时关注全局特征和局部特征中的关键信息,可以捕获同一个词在局部文本和整篇文本中不同的情感程度,识别出更细微的情感倾向变化,从而提高最终的分类效果,验证了双路注意力机制的合理性与有效性。
2.4.3 不同词向量作为输入的实验与结果分析
为了验证GCDA 模型针对不同网络特点采用两种词向量并行输入模型的有效性,使用其他词向量输入模型作为对比实验验证,具体词向量如下:
1)Word2vec:使用单一的Word2vec 词向量作为模型输入。
2)GloVe:使用单一的GloVe 词向量 作为模 型输入。
3)GloVe_Word2vec:本文词向量,针对两种网络的特点,使用GloVe 词向量作为BiGRU 的输入,使用Word2vec 词向量作为CNN 的输入。
输入的词向量均为100 维,其他参数设置保持不变,在IMDb 和SST-2 数据集上分别进行实验,具体的实验结果如图7 所示。
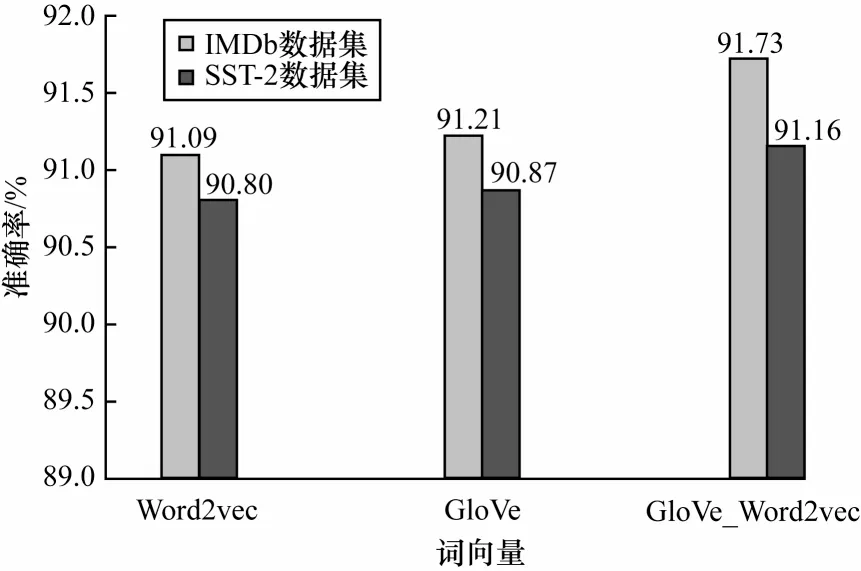
图7 不同词向量对准确率的影响Fig.7 Effect of different word vectors on the accuracy
通过图7 的实验数据可知:Word2vec 是使用词的局部上下文窗口来训练词向量,只能提取窗口大小内上下文的相关性信息;GloVe 是基于全局统计信息训练词向量,准确率略高于Word2vec;GloVe_Word2vec 同时使用两种词向量可以从不同的角度将文本向量化,从而获得更丰富的文本表示信息。可见,GloVe_Word2vec 针对BiGRU 使用循环单元提取全局特征的特点,利用基于全局统计信息的GloVe词向量作为输入;针对CNN 使用卷积窗口提取局部特征的特点,利用基于上下文窗口训练的Word2vec词向量作为输入,最终的分类准确率相比采用其他词向量得到了一定程度的提升。
3 结束语
本文提出一种基于并行混合网络和双路注意力机制的文本情感分析模型。该模型通过两种词向量输入从而得到更丰富的文本信息,再利用并行混合网络提取文本的上下文信息和局部特征,同时融入双路注意力机制,为两种特征中的关键信息分配更高的概率权重,使模型高度关注情感倾向明显的重要词汇。在公开数据集上与同类模型的对比实验结果证明了本文模型具有良好的分类效果。后续将针对融合位置编码信息的方面级情感分析任务展开研究,进一步扩展本文模型的适用范围。
猜你喜欢
广东通信技术(2022年4期)2022-05-12
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
汽车维修与保养(2021年5期)2021-09-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国科技纵横(2016年11期)2016-08-05
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
