
改进的RetinaNet 目标检测算法
2022-08-12 02:30司念文
计算机工程 2022年8期
于 敏,屈 丹,司念文
(1.郑州大学 软件学院,郑州 450000;2.战略支援部队信息工程大学 信息系统工程学院,郑州 450000)
0 概述
目前,基于深度学习的目标检测算法主要分为一阶段目标检测算法和两阶段目标检测算法两大类。一阶段目标检测算法是基于回归的目标检测方法,能同时对图像进行分类和候选框参数的回归,摒弃了多次回归的步骤;两阶段目标检测算法是基于候选区域的目标检测方法,该算法使用先选取候选区域,后对候选区域进行分类和回归的策略。相比于两阶段目标检测算法,一阶段目标检测算法无需候选区域分类回归步骤即可直接对目标进行分类预测。因此,一阶段目标检测算法不仅降低了计算复杂性,提高了时间效率,而且对实时目标检测具有更大的适用性,应用范围更加广泛。
在一阶段目标检测算法中,RetinaNet[1]是一种基于Focal损失函数的经典网络,其继承了之前一阶段目标检测算法检测速度快的特点[2],且基本克服了训练过程中类别不平衡问题。到目前为止,RetinaNet 仍被作为基础网络进行改进[3-4],或者作为主流基线网络与目前最新方法进行比较[5],被广泛用于计算机视觉领域[6-7]。然而,RetinaNet仅关注分类损失函数来解决类别不平衡问题,忽略了网络本身和边界框回归也是训练过程优化的重点,依旧存在难以充分提取与融合不同阶段特征,以及边界框回归不够准确的问题。传统的RetinaNet 算法通过深度卷积网络后会输出不同阶段尺度大小不一致的特征图,深层特征对应的下采样率通常比较大,容易造成小目标在特征图上的有效信息较少,不利于小目标的检测。而浅层特征分辨率较高,往往学习到的是细节特征,不利于大目标的检测。同时,RetinaNet 算法中的特征金字塔(Feature Pyramid Networks,FPN)[8]虽然试图通过横向连接进行特征集成,但FPN 中的顺序方式使集成特征更多地关注相邻层特征,而较少关注其他层特征。上述问题均可归结为不能充分提取与融合不同阶段特征的问题。此外,在边界框回归过程中,RetinaNet 算法中的边界框回归损失函数无法判断预测框和目标框是如何相交的,如果预测框和目标框没有重叠,那么损失函数将不起作用。上述问题归结为边界框回归不够准确的问题。
本文提出一种改进型RetinaNet算法,在特征提取模块的深度残差网络[9]中引入多光谱通道注意力(Multispectral Channel Attention,MCA)模块[10],该模块在ImageNet 数据集[11]上可达到最佳水平,能够提取不同阶段特征的丰富信息。此外,在特征提取模块后添加多尺度特征融合(Multi-scale Feature Fusion,MFF)模块,该模块包括1 个具有自底向上路径的路径聚合模块[12]和1 个特征融合操作[13],通过使用不同深度集成的特征来增强多层特征融合。将RetinaNet 算法中的边界框回归损失函数替换为完全交并比(Complete Intersection over Union,CIoU)损失函数[14],提高边界框在回归过程中的收敛速度。最后,在MS COCO 数据 集[15]和PASCAL VOC 数据集[16]上验证 改进型RetinaNet 算法的检测性能。
1 改进型RetinaNet 算法
改进型RetinaNet 算法的整体架构如图1 所示,首先输入一张图片,在加入MCA 模块的ResNet-FPN 特征提取模块中提取图像特征,通过MFF 模块来融合多阶段特征,输出5 层多尺度特征图,并在每层特征上设置锚框,其对应输入图像按固定长度进行平移。然后,生成的全部锚框覆盖了相对于输入图像的尺度范围,并设置交并比(Intersection over Union,IoU)阈值对锚框进行筛选。最后将其送入分类与边界框回归模块,分类分支和回归分支都是全卷积网络,分类分支预测了每个锚框上K个类别的概率,回归分支预测了锚框和目标框之间的相对偏移。

图1 改进型RetinaNet 算法的整体架构Fig.1 Overall architecture of improved RetinaNet algorithm
1.1 基于多光谱通道注意力的特征提取模块
如图1 的左侧部分所示是基于多光谱通道注意力的ResNet-FPN 特征提取模块。ResNet-FPN 作为RetinaNet 算法的特征提取模块,使用ResNet 每个残差阶段中的最后一个残差块输出的特征图,即C2、C3、C4和C5这4 层特征构成自底向上路径。而P2、P3、P4和P5这4 层特征是经过横向连接和2 倍上采样得到的。为了减少计算量,不使用高分辨率特征图P2。P7、P6是经过步幅为2 的3×3 卷积得到的,最后P7、P6、P5、P4和P3这5 层特征构成了自顶向下路径。由于ResNet-FPN 特征提取模块存在不能充分提取图片特征信息的问题,因此,本文算法加入了多光谱通道注意力(Multi-spectral Channel Attention,MCA)模块[10]来帮助有效地提取丰富的特征信息。
本文将MCA 模块插入在深度残差网络的多个残差块中,以ResNet-50 网络为例,该网络主要有5 个阶段,第1 个阶段包括7×7 卷积和3×3 最大池化层,后4 个阶段分别包括3、4、6、3 个残差块,每个残差块又包括1×1、3×3 和1×1 共3 个卷积层,ResNet-50 网络结构如表1 所示,其中64、256、128、512、1 024、2 048 等数字代表通道数。

表1 ResNet-50 网络结构Table 1 Network structure of ResNet-50
以ResNet-50 网络为例,在该网络的每个残差块中均插入一个注意力模块,具体操作如图2 所示,总共插入了16 个注意力模块。

图2 插入多光谱通道注意力模块的残差块Fig.2 Residual block inserted in the multi-spectral channel attention module
多光谱通道注意力模块是基于离散余弦变换(Discrete Cosine Transform,DCT)[17]提出的,二 维DCT 可定义为:


因此,二维离散余弦逆变换可定义为式(2)所示:

为简单起见,使用B表示频率分量,即二维DCT的权重分量,B的元素定义如式(3)所示:

根据式(3),可以将二维DCT 的逆变换重写为式(4):

由式(4)可知,图像特征可表示为不同频率分量的组合。为了使用频谱表征所有特征信息,引入了MCA 模块。
多光谱通道注意力模块的整体流程如图3 所示。

图3 多光谱通道注意力模块的整体流程Fig.3 Overall procedure of multi-spectral channel attention module
从图3 可以看出,将输入X沿着通道维度划分为n部 分,用[X0,X1,…,Xn-1]表 示n个部分,其 中:,n必须能被通道数C整除。对于每个部分,分配相应的二维DCT 频率分量,其结果可作为通道注意力的预处理结果,即:

其中:Freqi∊是预处理后的C′维向量;[u,v]是对应于Xi的频率分量指数。实验中,选定Top-k个性能最佳的频率分量后,通过u=rH/7可得出u的值,r为选定频率分量中的一个值,计算v值同理。
最后,将各部分的预处理向量合并起来:

其中:cat 表示向量级联;Freq∊RC是获得的多光谱向量。
整个MCA 模块可以定义为:

对于尺寸为H×W的特征,利用2 维DCT 将其分解为H×W个频率分量,得到总的频率分量为C×H×W。由于测试所有组合的计算成本很高,因此通过2 步准则来选择MCA 模块中的频率分量。其主要思想是先逐个计算每个频率分量的结果,然后再根据所得结果筛选出Top-k个性能最佳的频率分量。
由于MCA 模块可以将包含不同信息的频率分量合并到注意力处理中,从而提取出更多的特征信息,因此有效缓解了RetinaNet 算法中存在的难以充分提取不同阶段特征的问题。
1.2 多尺度特征融合模块
MFF 模块是受路径聚合网络[12]和平衡特征金字塔[13]的启发而构建的,其包含1 个具有自底向上路径的路径聚合模块和1 个特征融合操作。
1.2.1 路径聚合模块
图4 为多尺度特征融合模块的结构。如图4 路径聚合模块所示,在ResNet-FPN 特征提取模块的后面连接具有自底向上路径的路径聚合模块。P3、P6、P7层特征图不经过任何操作,直接作为N3、N6、N7层特征图。以P4层的特征图为例,P4与经过2 倍下采样的N3特征图根据元素相加,得到的特征图再经过3×3 卷积后生成特征图N4,以此类推,生成特征图N5,最后生成5 层通道数均为256 的特征。N3、N4、N5、N6和N7则构成了具有自底向上路径的路径聚合模块。该模块通过扩充自底向上路径,在较低特征层上用精确的定位信号增强了整个特征金字塔的信息流。

图4 多尺度特征融合模块的结构Fig.4 Structure of multi-scale feature fusion module
1.2.2 特征融合操作
特征融合操作主要分为缩放整合、优化、加强特征这3个步骤,如图4特征融合模块所示。具体操作如下:
步骤1调整特征图尺寸并平均融合后的特征。现有{N3,N4,N5,N6,N7}5 层特征,由于低层特征分辨率高,一般只能学习到细节特征,高层特征分辨率低,学习到的是语义特征。因此,要先把这5 层特征的尺寸调整到中间层次N4特征图的尺寸,并进行融合。采取的操作是,将N3特征图下采样,将N5、N6、N7特征图进行上采样,对N4特征图不进行其他操作,最后再做简单的相加取平均操作,如式(8)所示:

其中:L表示特征层的层数;Nl表示第l层特征。
步骤2将平均后的特征图进一步优化,使特征图具有更强的辨别力,使用embedded Gaussian nonlocal 模块[18]进行优化操作,该操作的定义如下:

其中:M和N是尺寸相同的特征图;i是特征图的一个像素位置;j是所有可能位置的索引;g是一元输入函数,一般采用1×1 卷积,目的是进行信息变换;f是配对计算函数,计算第i个位置和其他所有位置的相关性;θ和ϕ都是1×1 卷积操作,T设置为1;C(N)是归一化函数,能够保证变换前后整体信息不变。
步骤3将优化后的特征分散成多层特征{M3,M4,M5,M6,M7},并与N3~N7特征相加融合,其中:M3特征是通过将优化后的特征进行上采样得到的;M4特征是直接输出得到的;M5、M6和M7特征是通过将优化后的特征进行下采样得到的。
上述过程是特征融合的3 个步骤。通过添加路径聚合模块和特征融合操作,有效缓解了RetinaNet算法难以充分融合不同阶段特征的问题。
1.3 边界框回归和分类模块
本文算法的边界框回归网络与分类网络使用的是RetinaNet 算法的回归与分类网络。其中,边界框回归网络是附加在输出特征每一层的全卷积网络[19]。该网络使用4 层通道数为256 的3×3 卷积,每层卷积接一个ReLU 激活层,然后接1 个通道数为36的3×3 卷积层,最后的输出预测了锚框和目标框之间的相对偏移。
得到预测值和目标值后,便可以计算边界框回归损失,但RetinaNet 算法的边界框回归损失函数存在2 个问题:
1)如果目标框和预测框没有重叠,那么损失函数将不起作用;
2)如果两对预测框和目标框的大小均相同,而且这2 对框的相交值也相同,那就不能确定这2 对框是如何相交的。
针对上述问题,本文算法使用CIoU 损失函数[14]替换了RetinaNet 算法的边界框回归损失函数。CIoU 损失函数根据边界框回归中的重叠面积、中心点距离和长宽比这3 个因素,直接最小化预测框和目标框之间的归一化距离,以达到更快的收敛速度。同时,当预测框与目标框没有重叠,或者预测框与目标框有重叠甚至有包含关系时,该损失函数能使边界框回归更加准确。
交并比(Intersection over Union,IoU)的定义如式(11)所示:

其中:Bgt=(xgt,ygt,wgt,hgt)是目标框;B=(x,y,w,h)是预测框;x、y、w、h分别是框的中心点坐标和宽高;|B∩Bgt|表示目标框与预测框重叠部分的面积;|B∪Bgt|表示目标框与预测框2 个框包围的总面积,如图5 所示。

图5 IoU 的定义Fig.5 Definition of IOU
因此,CIoU 损失函数的定义如下:

其中:b和bgt分别表示预测框B和目标框Bgt的中心点;ρ(∙)是2 个中心点的欧几里得距离;c是同时包含预测框和目标框的最小封闭框对角线长度;α、ν是影响因子,α是用来平衡长宽比的系数,ν是用来衡量预测框和目标框之间的长宽比一致性。α和ν的定义如下:

参数c和d的示意图如图6 所示。

图6 参数c 和d 的示意图Fig.6 Schematic diagram of parameters c and d
2 实验结果与分析
2.1 数据集和评价指标
选用MS COCO[15]和PASCAL VOC[16]两大公共数据集。其中MS COCO 数据集包含80 个类别,其中用于训练的图片有118 287张,用于验证的图片有5 000张,用于测试的图片有20 000 张。令本文算法在test-dev 2017 数据集上进行实验,并与最新的目标检测算法相比较,然后使用val 2017 数据集进行消融实验。实验结果使用平均精度(Average Precision,AP)指标进行表征,AP 表示IoU 从0.5 开始,每隔0.05 作为阈值,直到取到0.95 得到的平均精度再进行平均的结果。例如AP50表示IoU 阈值为0.5 时的平均精度,AP75表示IoU 阈值为0.75 时的平均精度,其它同理。APS、APM、APL分别表示小、中、大目标的平均精度。PASCAL VOC 数据集包含20 个类别,其中训练图片来自trainval 2007 数据集和trainval 2012 数据集,共22 136 张;测试图片来自test 2007 数据集,共4 952 张,实验结果遵循VOC 数据集的最终评价指标,即平均精度均值(mean Average Precision,mAP),其中类别精度表示该类别在IoU 阈值为0.5 时的平均精度。
2.2 实验参数设置
在COCO 数据集中,先将输入图像的短边调整为800 像素,然后使用随机梯度下降(Stochastic Gradient Descent,SGD)优化所有算法,权重衰减为1×10−4,batch size为4(2个GPU,每个GPU 每训练一次选取2 张图像)。学习率被初始化为0.002 5,共训练12 个epoch,并分别在第8 和第11 个epoch 时将学习率降低10 倍。在VOC 数据集中,将输入图像的短边调整为600 像素,在第9 个epoch 时将学习率降低10倍,其他设置与COCO 数据集相同。
本文实验在PyTorch 1.7 深度学习框架[20]下进行,操作系统为Ubuntu 18.04,使用2 个NVIDIA GeForce RTX GPU 训练,显卡内存为11 GB。本文的基线算法Baseline 即为RetinaNet 算法,在超参数(如权重衰减、batch size、学习率、epoch 等)设置均相同的情况下,对RetinaNet 算法进行了重新实验,实验结果优于提出该算法的原始论文中的结果,本文的RetinaNet 算法的实验结果与原始论文结果相比提高了超过1 个百分点。
2.3 结果分析
2.3.1 对比实验与结果可视化
本文在COCO test-dev 2017 数据集和PASCAL VOC 测试集上评估了本文所提改进型RetinaNet 算法的性能。在COCO test-dev 2017数据集上,实验主要分为2个部分,将主干网络为ResNet-50和ResNet-101的改进型RetinaNet 算法分别与其他主干网络为ResNet-50 或ResNet-101 的最新一阶段、两阶段目标检测算法进行比较,实验结果如表2 所示。由表2 可知,主干网络为ResNet-101 的改进型RetinaNet 算法的AP 值为40.9%,与RetinaNet 算法相比性能得到显著提高。在主干网络相同的条件下,改进型RetinaNet 算法与表2 中的其他目标检测算法相比均达到了最佳结果。

表2 不同目标检测算法在COCO test-dev 2017 数据集上的实验结果对比Tabel 2 Comparison of experimental results of different object detection algorithms on COCO test-dev 2017 data set %
在PASCAL VOC 测试集上,将改进型RetinaNet算法(主干网络为ResNet-50)的各个类别的精度与RetinaNet算法进行对比,结果如图7所示。由图7可知,RetinaNet 算法的mPA 为78.3%,改进型RetinaNet 算法的mPA 为79.4%,且改进型RetinaNet 算法在大多数类别上的精度高于RetinaNet算法,只在少部分类别如bird、boat、bus、sofa 上的类别精度较低于RetinaNet算法。其原因在于VOC 训练集图片数量较少,随着网络层数的加深及参数量的增加,算法的训练效果稍低,且测试集中含有的小目标或重叠目标的图片不易被检测。

图7 不同算法在PASCAL VOC test 2007 数据集上的结果对比Fig.7 Comparison of results of different algorithms on PASCAL VOC test 2007 data set
从MS COCO 数据集中随机选取一些图片进行可视化,本文选取2 对具有代表性的检测结果进行对比,结果如图8 所示。图8(a)为RetinaNet 算法的可视化结果,图8(b)为改进型RetinaNet 算法(主干网络为ResNet-50)的可视化结果,由图8 可知,改进型RetinaNet 算法的检测结果具有更高的准确率,检测的边框更加准确。

图8 改进前后的RetinaNet 算法在COCO 数据集上的可视化结果对比Fig.8 Comparison of visualization results of RetinaNet algorithm before and after improvement on the COCO data set
2.3.2 消融实验
本文所有消融实验均在COCO val 2017 数据集上进行。实验结果均与基线算法Baseline 进行对比,Baseline 是主干网络为ResNet-50 的RetinaNet 算法。
1)MCA 模块中频率分量数量的性能分析
分析不同数量的频率分量对RetinaNet 算法的影响,也就是说在Baseline 算法上加入具有不同频率分量的MCA 模块。本文选择了性能最高的前k个频率分量,k分别为4、8、16、32。
由表3 可知,具有多光谱通道注意力的RetinaNet算法与基线算法相比,实验结果均存在明显差距,这验证了在通道注意力中使用多个频率分量的正确性。此外,由表3 还可以发现当频率分量的数量为8 时,RetinaNet 算法的AP 值最大。

表3 不同数量的频率分量对RetinaNet 算法的影响Table 3 Influence of different number of frequency components on RetinaNet algorithm
2)MFF 模块中组成部分的性能分析
表4 是在RetinaNet 算法上加入特征融合模块各个部分的对比结果,由表4 可知,路径聚合模块及特征融合操作分别验证了较低层特征的信息有用性、融合多层特征的有效性,将路径聚合模块与特征融合操作相结合可获得最佳性能。

表4 在RetinaNet 算法上加入特征融合模块各个部分的对比结果Table 4 The comparison results of each part of the feature fusion module added to the RetinaNet algorithm
3)CIoU 损失函数不同损失权重的性能分析
在Baseline上加入具有不同损失权重值的CIoU 损失函数,分析不同的损失权重对RetinaNet算法的影响。损失权重值分别设置为1、2、3,实验结果如表5 所示。由表5 可知,CIoU 损失函数有效改善了RetinaNet算法中存在的边界框回归问题。当CIoU 的损失权重值设置为2 时,网络可获得最佳性能。

表5 不同损失权重值对RetinaNet 算法的影响Table 5 Influence of different loss weight values on RetinaNet algorithm
4)3 个改进部分不同组合方式的比较
对MCA 模 块、MFF 模块、CIoU 损失函 数3 个 改进部分以不同的方式进行组合,结果如表6 所示,其中“✕”代表不添加,“√”表示添加。由表6 可知,在基线算法上单独加入1 个模块,或者加入其中2 个模块都不能达到最佳性能效果,因为每个模块的作用各不相同。对于目标检测算法整体而言,特征提取、特征融合和边界框回归都是很重要的部分,因此在改进目标检测算法时,不能只着眼于部分网络,而要分析整体网络所存在的问题,再针对这些问题进行解决和改进。因此,这3 个改进部分的结合不仅改善了难以充分提取和融合多层特征的缺陷,而且缓解了边界框回归不准确问题,验证了该改进算法的有效性。如表6 所示,改进型RetinaNet 算法在COCO val 2017 数据集上的AP 值比RetinaNet 算法高出了2.4 个百分点,性能得到显著提高。
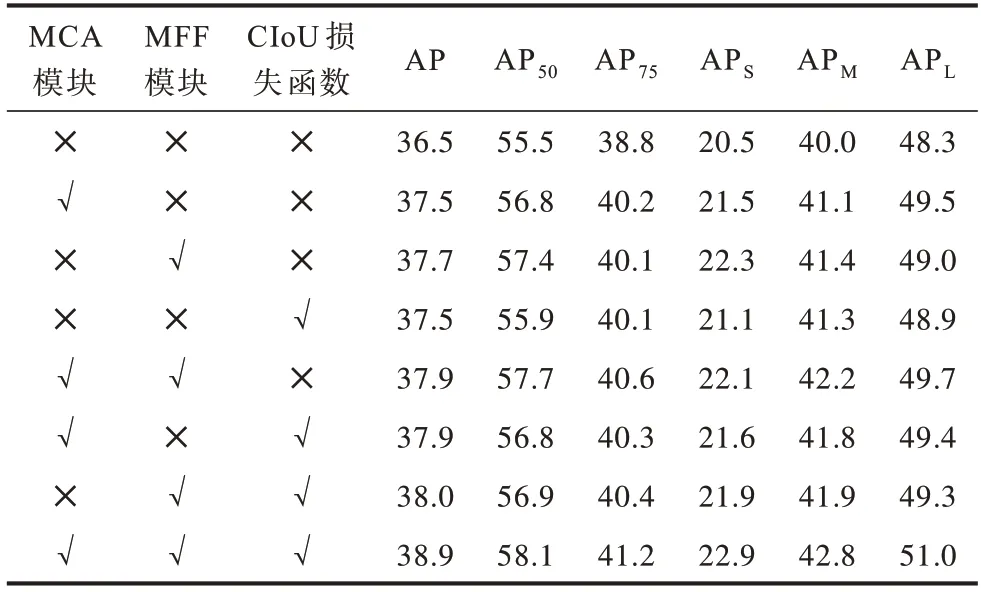
表6 3 个改进部分不同组合方式的对比实验结果Table 6 Comparative experimental results of different combinations of three improved parts %
3 结束语
本文针对RetinaNet 算法难以充分提取及融合不同阶段特征、边界框回归不准确等问题,提出一种改进型RetinaNet 算法。在特征提取模块中引入多光谱通道注意力模块,将路径聚合模块与特征融合操作相结合以构成多尺度特征融合模块,并在边界框回归过程中引入CIoU 损失函数。在MS COCO 和PASCAL VOC 两大公共数据集上的实验结果表明,与RetinaNet 算法相比,改进型RetinaNet 算法的检测性能得到了显著提高。但目前所提算法尚未应用到两阶段目标检测中,下一步将通过调整该算法的网络结构或具体参数,将本文算法应用到两阶段目标检测中的特征提取与融合部分、边界框回归部分,使两阶段目标检测算法在提高检测精度的同时保持检测速度,提高本文算法的适用性。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
现代装饰(2020年4期)2020-05-20
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
当代陕西(2019年10期)2019-06-03
英美文学研究论丛(2018年1期)2018-08-16
