
引入独立融合分支的双模态语义分割网络
2022-08-12 02:30田乐,王欢
计算机工程 2022年8期
田 乐,王 欢
(南京理工大学计算机科学与工程学院,南京 210094)
0 概述
在全天时条件下的语义分割任务中,恶劣光照、雨雪等天气条件会对可见光和热红外相机成像造成不同程度的干扰,因此,有很多研究人员联合可见光和红外热图像的信息[1-2]来设计双模态语义分割方法。可见光和热红外相机具有多种可以互补的优势,例如,在白天场景下,可见光相机分辨率高,成像清晰;在黑夜环境中,热红外不受低光照的影响,并且具有穿透雾霾等遮挡物的能力,在恶劣场景下依然能够观测到车辆、行人等与背景有温度差异的目标。通过互补这2 个传感器的信息,能够提升全天时的道路场景语义分割性能。但是,SUN 等[3]指出直接合并可见光、红外图像的所有通道信息作为网络模型的输入时效果并不好,有些甚至不如单模态网络,造成该现象的原因主要与双模态数据的差异性有关。
针对上述问题,主流方法大都采用2 支编码器来提取双模态图像的特征,然后对相同级别的特征图进行融合,以此来互补双模态信息。文献[4-5]中提出的多模态融合网络均是采用对应元素相加的方式组合每个模态的特征,但是这些研究并没有在双模态特征的选择上表现出倾向性,当遇到双模态图像包含的信息量严重失衡时,方法的效果将下降,例如,当相机视野内所有物体的温度差异很小时,热图像的信息量就很有限;在光照强烈或严重不足时,RGB 相机产生的图像会出现大面积白色或黑色等无效信息。文献[6]针对元素相加融合双模态信息的方法进行改进,在网络中加入模态加权融合层以加强对融合特征图的模态选择,该方法能够在夜间光照缺乏时检测出行人目标。根据双模态图像所包含信息量的多少来自适应地将更高的权重赋予信息量贡献更大的模态图像,有利于更好地完成分割任务。
为了有效融合可见光谱与红外谱段信息来实现图像语义分割,本文提出一种双模态深度神经网络。在双流网络架构的基础上,增加一支包含自适应图像融合模块的独立融合子网络,该子网络能够通过空间、通道注意力机制对双模态特征进行空间和通道上的显著性分析,以自适应地调整特征融合系数,从而完成双模态图像特征级和像素级的融合。
1 相关工作
1.1 图像语义分割
图像语义分割的目标是对图像的每一个像素点进行类别预测。为了精细化图像的分割结果,研究人员提出了众多应用于深度学习分割系统的网络结构和方法。BADRINARAYANAN 等[7]提出的SegNet 网络通过在池化层保留池化索引实现了非线性的上采样,其能够在解码阶段融入原始图像的空间信息。HE 等[8]提出深度残差学习的方法,该方法解决了梯度弥散问题,使深层网络的训练成为可能。Google 团队提出的GoogleNet 网络证明了CNN 可以有更多的排列方式,其提出的Xception 模块[9]不仅通过继承Inception v3 感知模块的功能获得了不同尺度的特征,还利用引入的可分离卷积提高了模型的运行速率。
此外,各种注意力机制也被应用于语义分割领域。MA 等[10]通过在卷积运算后加入自身平方项的注意力机制,增强了深层和浅层特征在解码器阶段的融合效果。HU 等[11]从像素预测和像素分组2 个独立的维度对语义分割重新进行考量,使用多头的压缩注意力模块增强像素间的密集预测。本文网络模型同样引入了注意力机制,包括空间、通道注意力机制,从而在不增加参数量的情况下使得网络能够选择更关键的信息。
1.2 多模态的语义分割
多模态图像能够提供具有不同成像机理的信息,因此,在医学领域得到广泛应用[12],多模态语义分割经常被用于分割病变区域,如ZHOU 等[13]利用多模态图像完成肿瘤的检测与分割任务。
多模态图像语义分割在机器人环境感知中也得到应用,常见的数据源有可见光图像、红外图像以及3D 点云图像。SUN 等[14]以DenseNet 作为编码器主干,提出两阶段的融合策略:第一阶段在RGB 编码器中分层添加红外特征;第二阶段将融合的特征图与对应层级的解码器特征图进行连接,以恢复密集下采样所造成的空间信息损失。HAZIRBAS 等[15]在FuseNet 网络中设计双支VGG-16 编码器同时提取RGB 和Depth 特征,通过密集和稀疏融合策略将深度特征融合到RGB 编码器中。LÜ 等[16]使用Resdiv模块完成融合特征的解码工作,其可以有效地融合颜色和红外特征。本文网络在编码阶段提出一种新的方法,在双流网络架构的基础上增加一个独立融合网络分支,其输入为可见光和红外图像,根据双模态图像信息量的贡献度自适应地调整融合系数以得到融合特征图。例如,当目标与环境温度相近时,红外图像在特征提取中提供的可用信息量较少,对于学习到的红外特征,融合网络在生成融合特征图时就会赋予其较低的权重。
1.3 图像融合
在传统的图像处理方法中,根据图像表征层次的不同,图像融合通常分为像素级融合、特征级融合和决策级融合这3 种层次[17]:像素级图像融合在输入数据层面进行融合,最大限度地保留了图像的细节信息;特征级融合对特征提取后的信息进行合并处理;决策级融合是在每个模态数据单独完成特征提取和分类后,根据每个决策的可信度做出的综合处理。此外,基于变换域的分解重构融合算法[18-19]也被用于可见光和红外图像的融合任务。
在深度学习网络中,多模态数据的融合策略有很多。本文以融合可见光、红外2 种模态数据为例进行介绍,这些策略也可以推广到更多的模态问题中。用vi、ir 表示可见光、红外2 种模态,和为它们在神经网络第l层的特征图,分别是第l层的变换函数和融合结果。3种融合策略具体如下:
1)Addition。在双模态特征融合上采用像素级累加的方式得到融合特征,即:

2)Concatenation。这种策略通常会在卷积层之前沿特征图的深度方向叠加2 种模态的数据,如式(2)所示:

其中:⊕表示张量的合并操作。
3)Mixture of Experts。混合专家网络[20]的策略能够通过多个专家网络隐式地学习每个模态的权重图,再和原始特征图加权以得到最终的融合特征图。VALADA 等[21]采用这种融合策略,根据场景条件自适应地加权专家网络得到的特征,从而完成全天时和跨季节的道路场景解析。本文以wvi、wir分别代表专家网络为可见光、红外模态预测的权重,则最终融合特征的数学表示为:

2 本文双模态语义分割网络
2.1 模型整体框架
图1 所示为本文模型的整体结构,其中,左图是网络的整体框架,右图是上采样块的详细结构,k和s分别表示卷积核的大小和步长,默认值分别为3 和1。鉴于Encoder-Decoder 是一种有效的语义分割网络框架[22],本文采用该框架来搭建所提模型的主干网络。与主流RGBT 网络的双编码器有所不同,本文在此基础上增加一支包含融合模块的编码器网络。3 个独立的编码网络分别从RGB 图像IV、热红外图像IT、融合“图像”(融合模块的输出)中提取特征。本文将所提网络命名为三支型网络,三支编码器分别命名为可见光编码子网络EV、红外编码子网络ET、融合编码子网络EF。EF的前端是一个融合模块,通过注意力机制自适应地在像素级别融合双模态的信息。EF子网络在下采样操作后添加可见光和红外单模态的编码分支网络的各级特征,以得到多模态特征。

图1 本文模型的整体结构Fig.1 The overall structure of the proposed model
2.2 模型细节
模型编码(Encoder)部分由3 支包含ResNet 结构的编码子网络组成。3 种模态原始图像的通道数分别为1、3、4,而3 支编码器EV、ET、EF的输入数据要求通道数均为64。因此,本文设计了In Conv 卷积层来统一多模态数据的深度(即设置该卷积层输出通道数均为64),之后采用L个stage 的残差卷积层(本文中L=4)来进行不同尺度特征的提取。数据流经过每一个stage,宽度和高度各减小1/2,通道数会增加一倍。表1 所示为编码器子网络的具体结构,包括每个残差卷积块使用的残差卷积层数量。

表1 编码器子网络结构Table 1 Structure of encoder sub network
残差卷积层主要分为2 种设计方式,如图2 所示。本文选择3 层残差卷积结构,其将2 个3×3 的卷积层替换为1×1、3×3、1×1 的结构,从而有效降低参数量。例如,在一个卷积单元中,2 层的残差结构参数量为18C2,而3 层残差结构中第一个1×1 的卷积将通道数降为原始通道数的1/4,然后通过后置的1×1卷积再将通道数恢复,整体上的参数量为比2 层的残差结构降低了94.1%。

图2 残差卷积的2 种结构Fig.2 Two structures of residual convolution
整个编码器网络通过像素级别的融合编码子网络实现双模态图像的特征融合,且该子网络通过Concat方式添加对应层级的可见光和红外特征图,通过该方式使得到的特征图通道数变为原先的3 倍。为了减轻网络负载,本文使用一个1×1 的卷积来降低通道数,因此,融合编码子网络最终的输出特征图为:

Decoder 部分包含4 个上采样块,由卷积层、BN层、激活层、反卷积层组成。每个上采样块的残差连接部分首先采用1×1 卷积核的卷积层作为bottleneck层进行通道数降维,以减少训练的参数量,然后使用核为3 的卷积层和同尺寸的反卷积层来恢复特征图的尺寸。上采样块的短连接部分只做反卷积操作,得到与残差部分相同尺寸的特征图。把上述2 个部分的输出通过像素级对应的方式进行组合,得到新的特征图并通过ReLU 激活函数层获得当前块的输出,将其作为下一层的输入。整个模型使用多分类的交叉熵损失函数来训练,通过计算预测数据与真实标签的差距来反向传播梯度从而优化模型。
2.3 像素级特征融合模块
多数融合策略采用加权平均算子的方式生成加权映射以融合特征,如ASPP 空洞空间金字塔池化模块使用多个空洞卷积层来提取不同感受野下的特征,从而得到融合特征,然而,这些策略并不适合本文的双模态特征融合,因为本文的目标是既保留红外图像中所提取的辐射特征,也要保留可见光图像中所提取的细节特征。融合注意力机制能够解决不能针对性地提取不同模态特征的问题。
本文基于空间和通道注意力机制的融合策略,可以实现像素级的特征融合。空间注意力机制以特征图的每个像素点作为单位,对每个像素点都分配一个权重值,这个权重值可看作一个矩阵,尺寸与当前特征图一致;通道注意力以特征图的每个通道作为单位,得到的权重值是一个向量,其与当前特征图的深度一致。如图3 所示,本文像素级特征融合模块分为3 个阶段:下采样阶段分别对可见光、红外图像进行特征提取;融合阶段对相同层级的双模态特征图(虚线部分)采用空间、通道2 种注意力融合(Spatial and Channel Fusion,SCF)机制;上采样阶段在每个层级上添加前一层的特征图,再通过上采样操作获得当前层的融合特征。

图3 特征融合模块结构及SCF 机制流程Fig.3 Feature fusion module structure and SCF mechanism procedure

权重图ω由空间注意力模块(Spatial-AttentionModule,SAM)的AVG 层和Softmax 操作得到。其中,AVG为通道平均层,能够在特征图所有的空间位置(x,y)上对所有通道的值取平均,得到尺寸为h×w×1 的特征图,再利用Softmax 层计算得到权重图ω,如式(5)、式(6)所示:
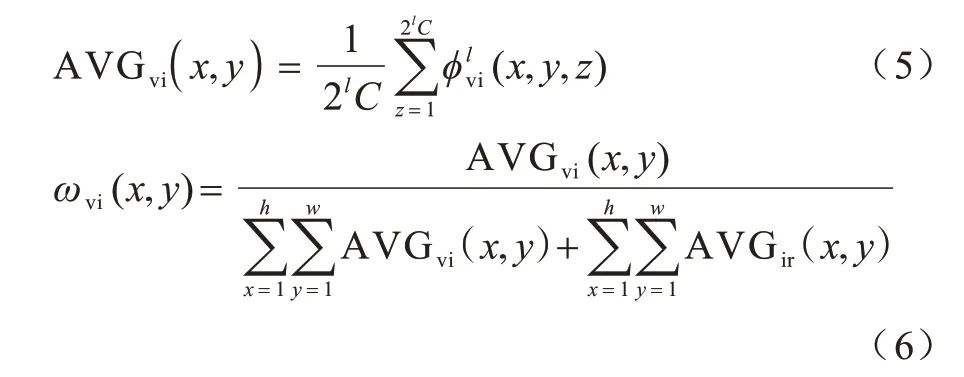
权重向量ν由通道注意力模块(Channel-Attention Module,CAM)的GAP层和Softmax 操作得到。GAP为全局池化层,在特征图每个通道上对所有位置上的值取平均,得到c维的特征向量,再通过Softmax 计算得到权重向量v,如式(7)、式(8)所示:



3 实验结果与分析
3.1 数据集与评价指标
MF 是较早用于城市场景双模态语义分割的数据集,其包括1 569 个有像素级标注的可见光、红外图像对。本文对MF 数据集进行划分,使训练集、验证集、测试集的比例为4∶1∶1,且每部分的白天、夜晚数据比例为1∶1。
FR-T 数据集包含多个白天和夜晚的可见光、红外图像序列,并对13 个语义类别进行了标注,但是该数据集没有提供夜间场景的图像标注信息,因此,本文仅使用部分白天拍摄的图像序列,共12 170 个可见光、红外图像对。
在语义分割领域,一般利用均交并比(mean Intersection over Union,mIoU)作为度量标准,其计算公式为:

其中:k+1 是所有语义类别的个数(包含未标记的类);pxy表示真实值为x而被预测为y的像素数量;pii代表真正例(True Positive,TP);pij、pji分别代表假正例(False Positive,FP)和假负例(False Negative,FN)。
在消融实验部分,本文还引入精确率Precision指标来衡量模型的查准率,该指标表示在所有正样本中正确目标所占的比例,计算公式如下:

3.2 实验环境与参数设置
本文实验平台为基于Linux18.04 系统的深度学习服务器,包括4 张Nvidia 3090 显卡,并使用Pytorch 1.7 深度学习框架。分别在MF 和FR-T 数据集上训练模型,初始学习率设置为0.03,学习率每次迭代下降2%,训练批大小为4。使用SGD 和Adam优化器的组合策略共训练200 个Epoch,通过最小化交叉熵损失函数来优化模型参数。
6.3.3 抽奖规则。抽奖是从已关注了XX图书馆官方微信并参与了现场网上荐购的读者的微信号中抽取。其中,微信荐书抽奖共分3轮,第一轮抽取三等奖20个,第二轮抽取二等奖10个,第三轮抽取一等奖5个,抽奖只针对微信网上荐购渠道,门户、APP等渠道,不参与抽奖。
3.3 与主流模型的对比实验
将本文所提模型与MFNet[1]、PSTNet[4]、HeatNet[23]、RTFNet-50[3]模型进行对比实验,此外,还设置一组RTFNet-50+NestFuse[24]的组合模型,以验证 本文像素级融合策略在语义分割任务中的性能优势。NestFuse[24]是RGB、红外图 像的融 合网络,其 在RTFNet 的基础上增加一支编码网络,输入为通过NestFuse 输出的红外、可见光融合图像。NestFuse 模型直接采用原始论文中提供的参数。
表2 所示为MF 数据集上的对比实验结果(mIoU),其中,“—”表示原文实验未提供,加粗字体表示每列中的最好结果。从表2 可以看出,在8 个语义类别中,本文模型在其中的6 个类别上都达到了最优,另外,在第5、第6 组实验中,Guardrail 类别的检测率有大幅提升,而这2 组实验与其他网络模型的主要区别是增加了一支融合编码网络,这表明在双模态网络中增加第三支融合编码器的策略具有有效性。另外,由于第5 组实验中网络的融合模块是NestFuse,即本文提出的像素级融合模块在可见光、红外的双模态数据融合中更具优势。

表2 各模型在MF 数据集上的测试结果Table 2 Test results of each model on the MF dataset %
图4 所示为MF 数据集上定性实验的部分样例可视化结果(彩色效果见《计算机工程》官网HTML版),第1 列、第2~第4 列分别显示白天、夜晚场景下的结果,第2~第4 列代表夜间的照明条件,部分区域甚至完全黑暗。从图4 可以看出,与其他网络模型相比,本文网络模型提取的目标更完整,比如在第3、第4 列中,只有本文模型识别出了完整的车辆、自行车类别的目标。

图4 MF 数据集上的分割结果可视化效果Fig.4 Visualization of segmentation results on MF dataset
从表3 可以看出,在FR-T 数据集的12 种语义类别中,本文模型在其中的8 种类别上mIoU 达到了最优,总体平均值比RTFNet高0.6个百分点。图5所示为FR-T数据集上的部分样例可视化结果(彩色效果见《计算机工程》官网HTML 版),从中可以看出,本文模型对目标的识别更为准确,分割的结果也更为精细。

表3 各模型在FR-T 数据集上的测试结果Table 3 Test results of each model on the FR-T dataset %

图5 FR-T 数据集上的分割结果可视化效果Fig.5 Visualization of segmentation results on FR-T dataset
为了测试各模型在白天、夜晚不同场景下的稳定性,在MF 测试集的白天、夜间图像上分别进行评估,表4 所示为白天和夜间场景中模型预测结果的定量比较(mIoU),实验结果表明,本文模型在2 种场景下均能达到最佳效果,其精确率较2 种场景中次优的模型分别高出4.5 和4.0 个百分点。

表4 白天和夜晚场景下的模型分割结果比较Table 4 Comparison of model segmentation results in day and night scenes %
3.4 消融实验
3.4.1 网络参数分析
编码子网络中残差卷积块的堆叠数量L直接影响网络的深度,为了探究其对模型学习效果的影响,设置L分别为3、4、5 并进行实验,结果如表5 所示,从中可以看出,在MF 数据集上使模型效果最优的L值为4,L过大会使模型的参数量增加,训练难度提高,L过小会导致模型的学习结果欠拟合。

表5 残差卷积块数量对模型性能的影响Table 5 Influence of the number of residual convolution blocks on the performance of the model
本文在编解码器中使用1×1 卷积的bottleneck 层,目的是降低特征图的通道数。通过实验分析bottleneck层的使用与否对网络参数量、实时性、准确性产生影响。表6 结果表明,使用1×1 卷积的bottleneck 层策略,不仅能让整个模型的参数量降低8%,而且在准确率和平均交并比指标上均有略微提升。

表6 bottleneck 层对模型性能的影响Table 6 Influence of the bottleneck layer on model performance
3.4.2 各编码器分支对网络的影响测试
为了分析三支型网络中各编码器分支的作用,本文尝试了各分支的其他组合形式:同时去掉红外和可见光2 支编码器子网络(w/o RGBT 实验组);单独去掉融合编码器子网络(w/o Fusion 实验组)。实验结果如表7 所示,从中可以看出,当去除红外和可见光编码器分支时,模型的预测准确率下降8.9%,仅缺少融合编码器子网络时下降7.6%。因此,通过红外、可见光编码器网络补充的特征级信息以及融合编码器自身的像素级融合特征,都能使模型性能得到提升。

表7 编码器分支的组合实验Table 7 Combined experiment of encoder branch %
3.4.3 像素级融合模块中注意力机制的有效性测试
表8 所示为融合模块中采用不同注意力机制的效果,以不采用注意力机制的网络模型1 为基准,将其分别与采用空间注意力机制SAM(模型2)、通道注意力机制CAM(模型3)以及空间通道注意力机制SCAM(模型4)进行比较。从表8 可以看出:模型1因为没有使用注意力机制,其平均交并比和预测精确率均为最低;与通道注意力机制(模型3)相比,空间注意力机制(模型2)对网络分割效果的提升更明显,表示空间注意力机制更有效;本文模型在2 个指标上均为最优,说明采用空间和通道注意力机制相结合的方式最有效。
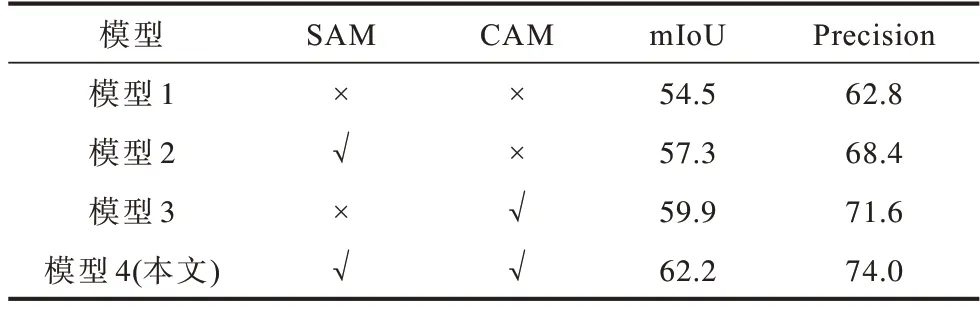
表8 注意力机制的消融实验结果Table 8 Ablation experimental results of attention mechanism %
3.4.4 融合策略的影响
为了验证不同融合策略对模型效果的影响,设计早期融合和晚期融合2 种策略进行对比实验[25]。如图6 所示,上图是采用早期融合策略的网络模型,其以可见光、红外以及像素级融合模块的融合结果作为输入,将3 种图像逐通道拼接作为新的输入,然后训练分割网络,整个模型从第一层到最后一层都可以利用不同模态的特征信息。早期融合策略可以表示为:

图6 中的下图是采用晚期融合策略的网络模型,每个模态图像是对应分支网络的唯一输入,仅在决策阶段才综合各分支网络的信息,且以预测概率最大的类别作为最终的分割结果。使用该融合策略的模型旨在从不同模式中独立学习互补信息。晚期融合策略可以表示为:


图6 2 种融合策略的模型结构Fig.6 Model structure of two fusion strategies
表9 中的前2 行数据分别对应早期融合、晚期融合策略的网络模型。本文调整3 组实验的编码器、解码器结构,均减少一个下采样层和对应的上采样层以及相关的卷积层。一方面,由于迟融合网络分别含有3 支编码器、解码器网络,如果采用和第2 节相同的下采样数量,迟融合模型的参数量会过大从而导致难以训练;另一方面,对所有组实验均采用相同的策略能排除模型结构对实验数据的影响。

表9 不同融合策略的实验结果Table 9 Experimental results of different fusion strategies
综合3 组实验模型的参数量、预测结果的平均交并比以及分割精确率可以看出,虽然采用迟融合策略的网络取得了最佳表现,但是将融合阶段置于网络的后端,需要更多地参数来执行前置的卷积以及其他操作。本文模型采用的融合策略在准确率和参数量上取得了较好的平衡。
3.4.5 图像降质和失效情况下的网络测试
本次实验测试输入图像质量降低甚至失效时对模型性能的影响程度。通过对输入的可见光、红外热图像附加额外操作来模拟图像的降质和失效情况,如图7 所示。对于图像降质,本文通过改变RGB图像的亮度和对比度,以模拟可见光相机在过曝、欠曝场景下得到的降质图像;通过给红外图像附加高斯滤波操作,以模拟红外图像的降质。对于图像失效,本文在图像的每个通道上都增加一个全局平均池化操作。

图7 降质、失效图像的合成与实验结果Fig.7 Synthesis and experimental results of degraded and invalid images
为了定量地说明网络在上述情况下受影响的程度,本文将处理后的图像分别输入RTFNet 网络和三支型网络中进行对比。表10 所示为测试网络在双模态图像质量降低或单一模态图像失效时的性能表现,其中,下降率表示模态失效时模型指标较正常状态的下降幅度。对输入图像的降质操作具体为:将可见光图像的整体亮度调整为原来的0.2 倍;在红外图像上增加一个核尺寸为21 的高斯滤波操作;对双模态输入图像同时采取上述2 种操作。从表10 可以看出:当可见光、红外图像单独降质时,本文模型准确率分别下降3.7%和3.9%,RTFNet 模型准确率分别下降5%和4.3%;当双模态图像均降质时,2 种模型准确率分别降低11.1%、12.1%。对于单一模态输入图像失效的情况,参与实验的模型都受到了较大程度的影响,在可见光、红外图像分别单独失效时,RTFNet 模型的测试指标分别下降16.9%、36.5%,本文模型则分别下降22.2%、24.5%。

表10 图像降质和失效情况下的测试结果Table 10 Test results in case of image degradation and invalidation %
在输入图像失效的极端场景中,由于本文模型使用三支编码子网络分别进行特征提取,因此能够保证有正常输入的一支子网络能够继续工作,此外,像素级特征融合模块在这种情况下虽然丢失了双模态特征的选择功能,但仍然能对正常输入模态图像进行特征提取和增强,这也是在任一模态图像失效时本文模型能得到一个稳定的分割结果且模型指标下降程度较低的原因。
4 结束语
为对城市场景图像进行语义分割,本文提出一种双模态深度神经网络。该网络通过RGB-T、像素级数据融合模块以及注意力机制,完成双模态图像的特征级和像素级融合。实验结果表明,在加入独立融合分支网络后,模型性能得到一定提升,在公开数据集上,与已有网络MFNet、PSTNet 等相比,本文所提网络能取得最优的分割效果。此外,本文还研究了输入模态图像降质和失效情况下模型的性能表现,结果表明,无论是单个模态图像降质还是双模态图像均降质甚至单个模态图像完全失效,本文模型受影响程度均较低,表明其鲁棒性较高。
本文所提网络仍然存在若干问题需要解决:目前整个模型参数量达到亿的数量级,推理速度无法满足实时处理的需求,今后尝试利用参数剪枝的方法加快网络的运行速度;模型在白天和夜晚2 种情景下的分割效果存在一定差距,本文认为这和双模态图像很难在像素上一一对应有关,可以通过调整深层特征图映射的感受野大小来尝试解决该问题;虽然本文网络中融合了细粒度的特征信息和粗粒度的抽象信息,但是各个类别的上下文信息也同样值得探究,利用这些信息在物体边界上获取更好的分割效果也是下一步的研究方向。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
网络安全与数据管理(2022年1期)2022-08-29
环球时报(2022-05-23)2022-05-23
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
金桥(2021年4期)2021-05-21
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
