
基于U‐Net 的多尺度低照度图像增强网络
2022-08-12 02:30徐超越何鹏浩马玉辉
计算机工程 2022年8期
徐超越,余 映,何鹏浩,李 淼,马玉辉
(云南大学 信息学院,昆明 650091)
0 概述
低照度图像增强是计算机视觉中具有挑战性的任务之一,在各个领域得到广泛应用。在光线较暗的条件下,传感器获得的效果严重退化,产生的图像不但辨识性差、对比度低,而且还存在颜色失真、包含大量噪声等问题,这使得随后的计算机视觉任务变得困难,如视频监控、自动驾驶、目标检测等。为了提高低照度图像的实用性,需要采取低照度图像增强方法进行处理。
传统的低照度图像增强模型可以分为基于直方图均衡化、基于频域和基于Retinex 理论对光照区域增强的方法。根据计算中考虑的区域不同,基于直方图均衡化的方法可以分为全局直方图均衡化[1]、局部直方图均衡化[2]、自适应直方图均衡化[3]、限制对比度自适应直方图均衡化[4]等方法,但这些方法由于灰度合并可能会丢失图像细节信息。基于频域的方法主要 利用小 波变换[5]和傅里 叶变换[6]。在傅里叶变换域中,研究者采用高通滤波器增强高频反射分量,抑制低频照明分量来增强低照度图像。YANG 等[7]利用双树复小波变换来进行图像增强,但该方法需要大量计算,变换参数的选择往往需要人工干预。文献[8-10]提出基于Retinex 理论对光照区域增强的方法,利用颜色恒常知觉计算理论,通过获得反映物体固有属性的反射分量来实现图像增强处理,但此类方法在强烈的阴影过渡区域容易出现光晕、伪影。张聿等[11]利用Retinex 理论提出一种基于分区曝光融合的不均匀亮度视频增强方法。此外,DONG 等[12]采用去雾方法实现低照度图像增强;WANG 等[13]提出一种双对数变换和亮通滤波器,可以在图像细节和亮度之间取得平衡;YING 等[14]提出一种双曝光融合模型对低照度图像进行增强。
近年来,基于深度学习的增强方法逐渐发展,通过深度学习,网络经过训练生成一个处理器,不仅能产生更好的效果同时也能将训练好的网络应用到智能手机上。LORE 等[15]在训练低照度图像增强LLNet 的框架中采用堆叠稀疏去噪自编码器来实现图像增强,但增强后的图像细节模糊,存在噪声。江泽涛等[16]基于变分自编码器提出了一种多重构变分自编码器,从粗到细地生成高质量低照度增强图像。WEI 等[17]将Retinex 理论与深度学习相结合,但所得结果存在边缘轮廓模糊的现象。LÜ 等[18]提出一种新的网络MBLLEN,通过特征融合产生输出图像,但其在亮度增强上效果不够理想。LIU 等[19]提出一种基于最优加权多曝光融合机制的图像增强方法。马红强等[20]利用深度卷积神经网络(DCNN)对亮度分量进行增强。ZHANG 等[21]提出一个简单有效的KinD 网络处理低照度图像。随后,ZHANG 等[22]又在KinD 网络的基础上加入多尺度亮度注意力模块来增强处理低照度图像。LIU 等[23]基于生成对抗网络(Generative Adversarial Network,GAN)提出一种感知细节GAN(PD-GAN)来调整光照。陈榆琅等[24]提出一种基于生成对抗网络的空间卫星低照度图像增强方法。ZHU 等[25]采用零样本学习(zero-shot)方案增强图像。此类方法将低照度图像增强制定为曲线估计任务,但图像整体亮度仍偏暗。XU 等[26]提出一种用于低照度图像增强的多尺度融合框架。基于深度学习的方法是当前图像处理研究发展的主要趋势,但其对不同尺度图像特征的表达能力不足,使得网络很难从极暗的图像中复原细节信息,且增强后的图像容易出现色彩畸变、噪声被放大、边缘轮廓模糊的现象。
针对上述问题,本文提出一种基于U-Net 的多尺度低照度图像增强网络(MSU-LIIEN),旨在增强图像亮度,消除噪声并使图像细节内容清晰可见。利用特征金字塔网络对原始低照度图像进行处理,以便让网络模型在初期即可获得融合深、浅层特征信息的特征图,使得所有不同尺度的特征图都含有丰富的高级语义信息。MSU-LIIEN 中每个网络分支都采用U-Net 网络,可以使模型在捕捉图像特征信息的长期依赖方面更有效。在此基础上,将多尺度和U-Net 互相结合,设计MSU-Net 模块,以获得丰富的细节信息,有效增强低照度图像的亮度。由于融合不同尺度的特征图是提高网络性能的一个重要手段,因此还设计一种扩张的结构细节残差融合块(Structural Detail Residual Fusion Block,SDRFB)嵌入到U-Net 骨干网中。该模块通过扩大感受野的方式,能够获得更为全面、语义层次更高的特征图,提高网络表达图像特征信息的能力。
1 MSU-LIIEN 模型
1.1 网络结构
为了解决低照度图像亮度增强、图像细节恢复和噪声去除的问题,本文提出一种基于U-Net 的多尺度低照度图像增强网络(MSU-LIIEN)。MSU-LIIEN 通过融合不同尺度的特征图来对低照度图像进行增强,采用特征金字塔(FPN)和U-Net 结合的方法使网络模型获得丰富的低照度图像特征信息,并将所得到的特征图沿着网络模型逐渐融合。由于图像细节是高频信息,因此低照度图像增强后会不可避免地导致图像细节模糊或产生噪声,且现有的特征提取块[27]很难完全从低照度图像中获得纹理细节特征,所以,MSU-LIIEN以特征金字塔为基本结构,用于把低照度图像转换为特征映射,将特征金字塔网络提取到的多级特征融合为基本特征。然后将其输入到MSU-Net 模块中,经过多层卷积消除噪声,并获得丰富的图像特征信息。最后将3 个分支输出的特征图逐层进行融合,用于恢复出最终的结果图。在MSU-Net模块中的3 个分支中都采用U-Net 结构作为骨干网,对提取到的图像特征进行编码与解码操作,并在所有分支上都进行相同的卷积和结构细节残差融合操作,以加强主干网络对特征信息的传递,获得表达能力更强的特征图。本文网络整体结构框架如图1 所示,原始低照度图像首先通过特征金字塔提取浅层特征信息,然后将特征图输入到3 个U-Net 分支中,其中U1、U2 和U3 分别是输入特征图的尺寸为H×W,H/2×W/2 和H/4×W/4 的3 个U-Net分支。
将通过MSU-Net 模块得到的所有尺度特征图进行逐层融合,再通过两层卷积和SDRFB 模块得到最终增强后的正常光照图像,该过程表示为:

其中:i表示输入的原始低照度图像;o为最终增强的正常光照图像;Conv 表示大小为3×3、步长为1 的卷积操作;SDRFB 表示结构细节残差融合块;Cat 表示对图像进行连接操作;U1、U2、U3 表示3 个分支,这里是对3 个分支输出的特征图进行Cat 操作。
1.2 MSU-Net 模块
每经过一层卷积噪声的等级就会减小,但相应的图像细节内容也会丢失,因此,本文设计了MSU-Net模块。该模块将多尺度结构和U-Net 互相结合,在达到良好去噪效果的同时较好地保留了图像细节纹理信息。采用多尺度结构可以在不同尺度的特征图上捕获更全面的特征信息,增强网络对不同尺度特征的感知能力。U-Net 网络能够将编码器中的低级特征与解码器中的深层语义特征相结合,充分利用上下纹理信息。与标准的U-Net 架构相比,MSU-Net 的不同主要在于采用多分支多尺度的方式融合了多个不同感受野大小的卷积序列产生的特征图,在模块中通过对多个不同感受野的特征图进行信息提取,能够让网络获得更多的细节和语义信息,从而增强网络对多尺度特征信息的提取和表达能力。MSU-Net 分支结构如图2所示。

图2 MSU-Net 分支结构Fig.2 MSU-NET branch structure
值得注意的是,每个分支采用的U-Net 网络的结构和深度都一致,其每个分支都采用3×3 大小、步长为1 的卷积,下采样执行2×2 最大池化操作,上采样执行2×2 转置卷积操作。编码器由两个卷积层、两个结构细节残差融合块组成,解码器也是同样结构。当来自编码器网络的高分辨率特征图与解码器网络含有丰富语义的特征图逐渐融合时,能够让网络更有效地捕获图像的细节和语义信息。在MSU-Net模块中,下采样用来逐渐展现环境信息,上采样用来进行信息的传递。由于模块具有对称性,因此可以在提高网络模型精度的同时减小计算量。每个分支的计算过程可以表示为:

其中:Fin为输入的特征图;F1、F2、F3分别为经过卷积、池化等操作产生的特征图;Fout为MSU-Net 模块每个分支输出的特征图;SDRFB 表示结构细节残差融合操作;Conv 表示卷积操作;Max_Pooling 表示下采样最大池化操作;up_sampling 表示上采样转置卷积操作。
1.3 结构细节残差融合块
为了更好地挖掘图像的深层次特征信息,提高网络表达特征信息的能力,本文将SDRFB 嵌入到UNet 中,它不仅可以结合不同尺度的图像特征信息,同时也有助于梯度的反向传播,加快网络模型的训练速度,解决网络层数较深情况下梯度消散的问题。图3 所示为本文设计的结构细节残差融合块结构,其对输入的特征图进行最大池化下采样操作,以保留显著的图像特征信息并减少网络训练参数。
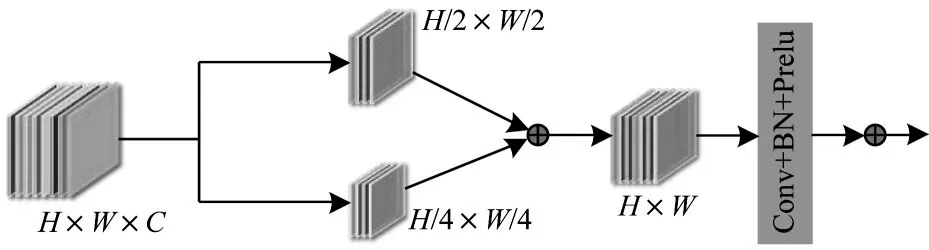
图3 结构细节残差融合块Fig.3 Structure details residual block
在SDRFB 模块内生成两个不同尺度的特征图,大小分别为H/2×W/2 和H/4×W/4,然后将特征图进行融合获得含有丰富信息的特征图。受残差网络的影响,考虑到非线性因素的初始化方法适用于研究更深更大的网络结构,因此该模块借鉴了残差网络的结构,引入跳跃连接进行特征融合。与普通残差块的主要区别是,SDRFB 模块可以在同一尺度内充分利用多尺度信息。该模块因为具有更大的感受野,所以可以获得更多的上下文信息,有助于网络找回丢失的图像细节信息。此外,它还是一个独立的模块,可以灵活地嵌入到各种网络模型训练中。
SDRFB 模块首先对输入的特征图进行卷积操作,然后再对输入的特征图进行池化操作以获得不同尺度特征图,该过程可以表示为:

其中:x表示输入的特征图;Conv 表示大小为3×3、步长为1 的卷积操作;Max_Pooling 表示大小2×2、步长为2的池化操作;y1、y2分别表示通过卷积和池化操作得到的输出特征图,大小分别为H/2×W/2、H/4×W/4。
最后,将所有尺度的特征图融合在一起,通过带有BN 和PReLU 操作的卷积层,再和输入特征图x相加。该过程可以表示为:
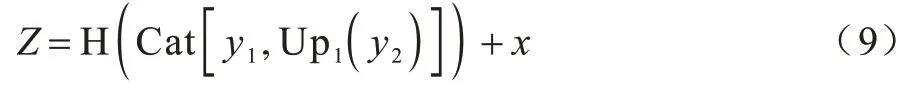
其中:Up1表示一次上采样操作;Cat 表示对特征图进行拼接,融合不同尺度的特征信息;Z为通过结构细节残差融合块(SDRFB)输出的特征图;H 表示包含Conv、Batch Norm 和PReLU 操作组成的运算,可以加速网络训练,加强特征的传播、减少模型参数,解决了深层网络的梯度消散和减少小样本的过拟合的问题。
1.4 损失函数
为定性和定量地提高图像质量,考虑图像的结构信息、感知信息和区域差异,本文将均方误差(Mean Square Error,MSE)、结构性相似度(Structural Similarity Index,SSIM)和梯度损失(Grad Loss,GL)结合起来作为图像增强模型的联合训练损失函数,其计算公式如下:

MSE 是网络训练时常用的回归损失函数,在训练过程中具有较好的收敛性,其计算公式为:
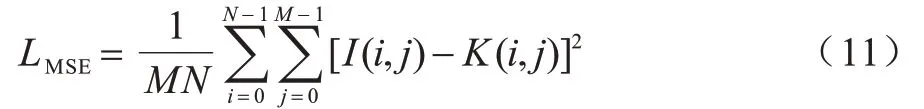
其中:I表示原始正常图像,大小为M×N;K表示经过网络框架增强后的图像。
为弥补普通的均方误差无法衡量图片结构相似性的缺陷,本文加入了SSIM 损失函数,其计算公式为:
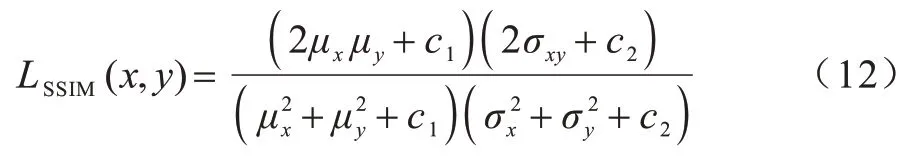
其中:μx和μy分别为图像x和y的均值分别是图像x和y的方差;σxy表示图像x和y的协方 差;c1和c2为默认调节参数。
为了避免网络在训练过程中陷入局部最优,在联合训练损失函数中加入梯度损失函数,计算公式为:
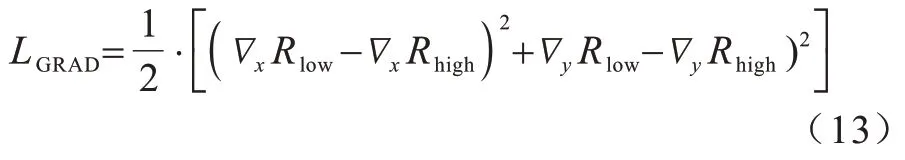
其中:∇是梯度算子,包含图像x和y两个维度方向;∇x和∇y分别表示水平和垂直方向的梯度。
2 实验与结果分析
将本文提出的基于U-Net 的多尺度低照度图像增强网络MSU-LIIEN 与现有经典方法进行对比评估,并对网络模型进行消融实验。
2.1 训练数据集
本文使用LOL-datasets 和Brighting Train 数据集作为训练数据集。LOL-datasets包括500 个低/正常光图像对,有485对低光/正常光训练图像,15张低照度测试图像。Brighting Train数据集包含1 000对低照度和正常光照图像。实验平台配置Intel Xeon W-2102 2.90 GHz CPU、8 GB RAM 和Nvidia 2080 GPU,实验程序在Tensorflow 1.15 框架上运行,联合损失函数的权重参数设置为α=β=γ=1,利用学习率设置为1e-4 的Adam 优化模型对网络进行优化,整个网络训练次数为2 000 次。
2.2 定量分析
基于LOL数据集,本文将MSU-LIIEN网络模型与9种经典低照度图像增强模型进行比较,传统模型为MSRCR[8]、DONG[12]、NPE[13]、SRIE[9]、MF[10]、BIMEF[14],深度学习模型为MBLLEN[18]、KinD[21]、RRDNet[25]。图4~图6 分别是从LOL 数据集中选取的3 张测试图像的实验结果对比图,其中细节部分用方框标出。可以看出:SRIE、BIMEF 和RRDNet模型计算得到的图像在亮度和清晰度上均不理想;DONG、BIMEF、MF、NPE、MSRCR 和SRIE 方法都产生了大量噪声,导致主观效果欠佳;MSRCR 模型使增强后的图像存在过曝的现象且伴有大量噪声;BIMEF、MBLLEN 和KinD 模型在其增强后的图像物体边缘会出现模糊现象,细节丢失严重;相比之下,本文提出的MSU-LIIEN 模型不但能更好地提升增强图像的整体亮度,而且增强后的图像保持了丰富的物体细节信息和清晰的边缘轮廓,同时还能有效抑制噪声的产生。

图4 Wardrobe 图像实验结果对比Fig.4 Experimental results comparison of Wardrobe image

图5 Natatorium 图像实验结果对比Fig.5 Experimental results comparison of Nataorium image

图6 Doll 图像实验结果对比Fig.6 Experimental results comparison of Doll image
基于Brighting Train 数据集,本文模型与3 种基于深度学习的低照度图像增强模型进行对比,对比模型包括Retinex-Net[16]、KinD[21]、TBEFN[28]模型。图7~图9分别是从Brighting Train 数据集中选取的3 张测试图像的实验结果对比图,其细节部分用方框标出。由图7 可以看出:TBEFN 的模型无法增强出其图像本身的色彩,增强后的图像整体呈现灰色黯淡的情况;拱门上面的奖杯出现灰度分布不均匀的现象,雕像侧边凹进去的墙壁边缘模糊;Retinex-Net 模型在图像整体色彩恢复上较差,拱门上面的奖杯存在色彩失真的现象,侧边凹进去的墙壁边缘轮廓模糊不清;KinD 模型可以把奖杯的色彩均匀的恢复出来,但图像的整体细节信息还是存在模糊的问题;本文提出的MSU-LIIEN 模型可以较好地恢复出建筑物本身的色彩,且拱门上面的奖杯和侧边凹进去的墙面边界都能清晰地增强出来。由图8可以看出:TBEFN 模型仍旧没有把建筑物本身的色彩增强出来;Retinex-Net模型存在颜色失真、图像模糊的现象,屋顶建筑物的轮廓和屋檐与墙壁之间的分界处由于噪声的存在,导致图像模糊,且天空中的乌云分布不自然合理;KinD 模型有伪影的现象发生,屋檐与天空的分界不明显,屋顶建筑物的轮廓也不清晰;本文的MSU-LIIEN 模型能够使天空中的乌云的分布恢复得更自然一些,屋顶及屋顶建筑物的轮廓增强得较为清晰,且细节更加丰富,颜色丰富度较其他模型有明显的提高。由图9 可以看出:TBEFN 模型使草地的颜色明显发生了明显退化,有很多小草的颜色没有恢复出来;Retinex-Net 模型出现了大量的噪声,且两只鸟的色彩恢复较为单一;KinD 模型存在细节模糊的现象,两只鸟的边缘轮廓模糊;相比之下,本文提出的MSU-LIIEN模型可以使两只鸟的边缘轮廓更加清晰,草地的颜色更加合理自然,且有效地抑制了噪声的产生。总体而言,本文模型取得了较好的效果。

图7 Building1 图像实验结果对比Fig.7 Experimental results comparison of Building1 image

图8 Building2 图像实验结果对比Fig.8 Experimental results comparison of Building2 image

图9 Bird 图像实验结果对比Fig.9 Experimental results comparison of Bird image
2.3 客观评价指标
本节实验采用图像质量客观评价指标来评估本文提出的MSU-LIIEN 网络模型。选用的评价指标包括峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似性(Structual Similarity,SSIM)、噪声质量评价(Noise Quality Measure,NQM)、信噪比(Signal-to-Noise Ratio,SNR)、视觉信息保真度(Visual Information Fidelity,VIF)以及信息保真度准则(Information Fidelity Criterion,IFC)来评价。PSNR 值越大,表明图像的质量越好,失真越少;SSIM 值越大,表明图像的质量越好,更符合人眼的评判标准;VIF、NQM 和IFC 越大,表明图像细节保留得越好。
表1~表3 分别给出了对应LOL 数据集中3 幅测试图像的各种对比模型所得到的客观评价指标,其中,加粗数据为最优数据,下同。可以看出:在表1中除了SSIM 指标略低于KinD 方法外,本文模型在其他评价指标上明显优于其他对比模型。在表2 中除了SSIM、VIF 指标外,其他评价指标都是最优的,而且在PSNR、NQM、IFC、SNR 指标上和图像处理速度上明显优于其他对比模型。在表3 中本文模型在所有评价指标上均明显优于其他对比模型。此外,在表3 中还给出了LOL 数据集中全部15 幅测试图像所对应各种模型的平均峰值信噪比(Average Peak Signal-to-Noise Ratio,AVG_PSNR)指标,可以看出,本文模型在该指标上也明显优于其他所有对比模型。由此看见,本文模型对低照度图像增强的效果在客观评价指标上明显优于其他9 种对比模型,且图像的处理时间也为最短。
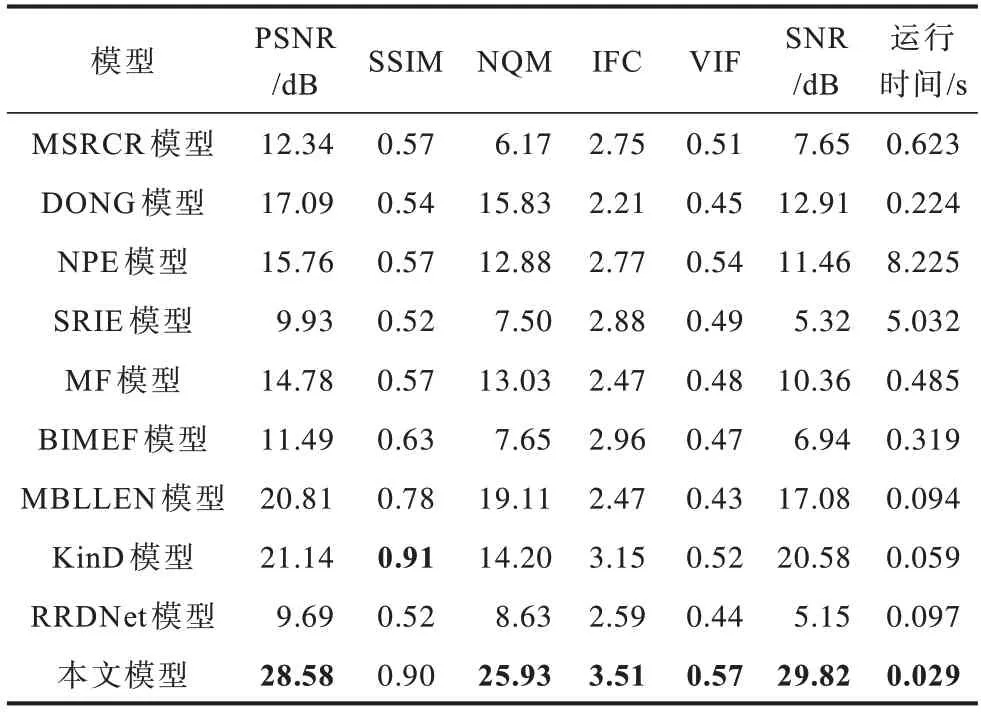
表1 Cabinet 图像评价指标Table 1 Evaluation index of Cabinet image
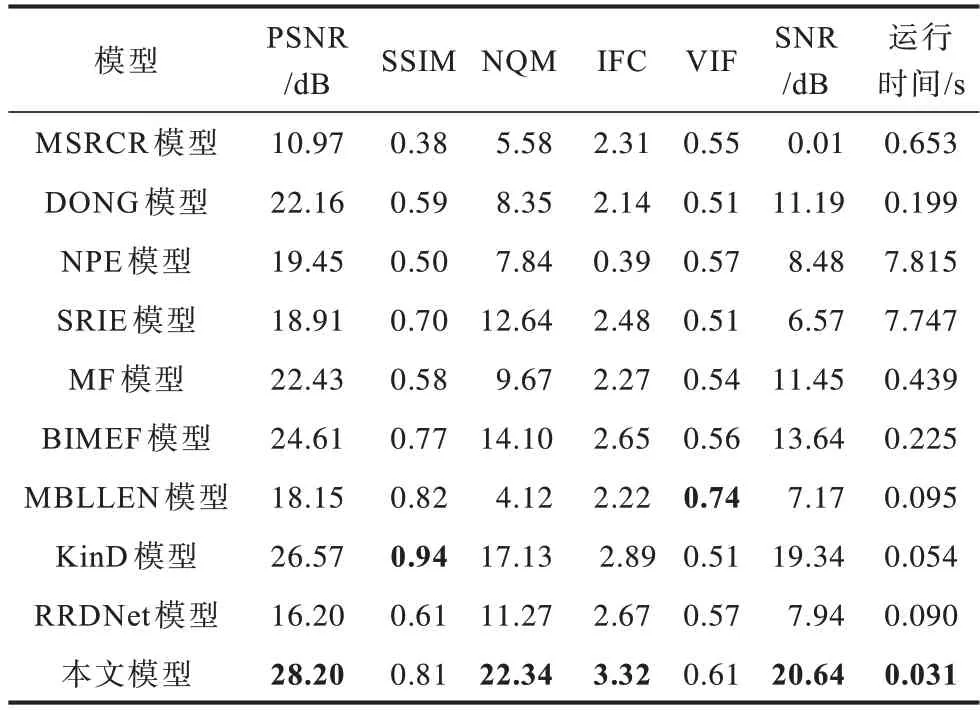
表2 Natatorium 图像评价指标Table 2 Evaluation index of Natatorium image

表3 Doll 图像评价指标Table 3 Evaluation index of Doll image
表4~表6 分别给出了对应Brighting Train 数据集中3 幅测试图像的各种对比模型所得到的客观评价指标。可以看出,在表4~表6 中除了图像的运行时间外,其他评价指标均是本文模型最优,且在PSNR、SSIM、NQM、IFC、VIF和SNR指标上明显优于其他对比模型。此外,在表6 中还给出了Brighting Train 数据集中全部测试图像所对应各种模型的平均峰值信噪比(AVG_PSNR)指标。可以看出,本文模型在该指标上也明显优于其他所有对比模型。由此看见,无论是在像素层面、结构层面还是在感知层面,本文网络模型的图像增强质量均优于其他所有对比模型。
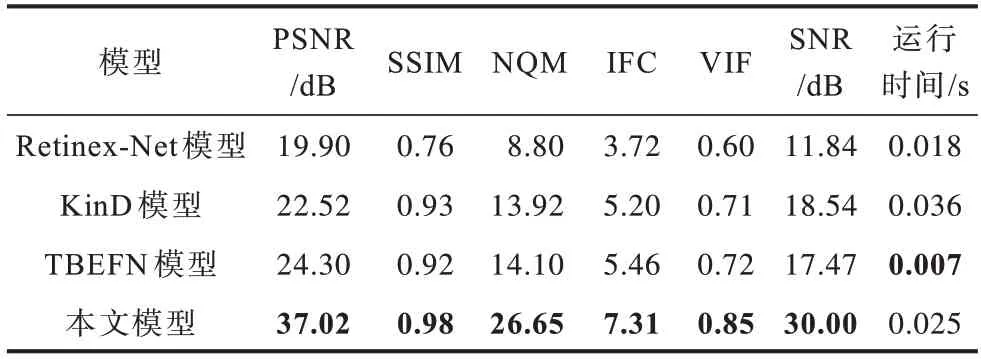
表4 Building1 图像评价指标Table 4 Evaluation index of Building1 image
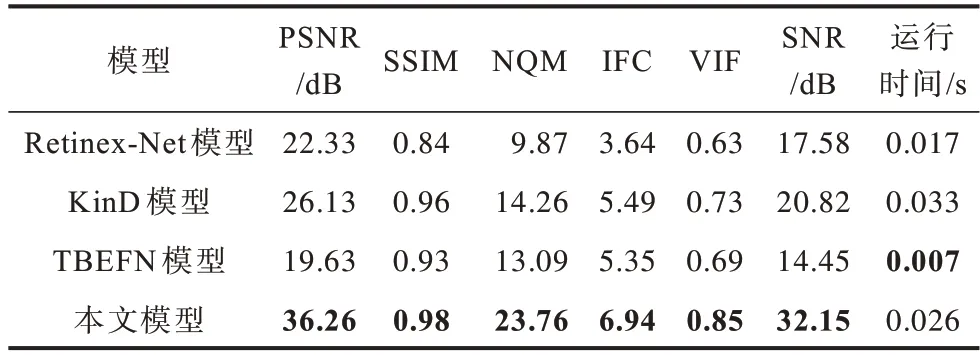
表5 Builling2 图像评价指标Table 5 Evaluation index of Building2 image

表6 Bird 图像评价指标Table 6 Evaluation index of Bird image
2.4 消融实验
对MSU-LIIEN 网络模型中各个网络模块进行消融实验,本实验采用LOL 数据集。为公平比较,实验均在相同设置下进行训练。为了验证本文引入的结构细节残差融合块(SDRFB)和特征金字塔网络(FPN)的有效性,每次训练分别移除其中一个网络模块来进行消融实验。
图10 所示为从LOL_datasets 选出的3 张测试图像。可以看出,去掉SDRFB 模块的网络模型在颜色丰富度上没有基础模型好,去掉FPN 的网络模型在细节恢复上不够理想,物体的边缘轮廓较为模糊。
表7给出了采用LOL数据集中“Doll”图像和“Room”图像来进行消融实验所得到的客观评价指标。其中,AVG_PSNR 和 AVG_SSIM(Average Structural Similarity,AVG_SSIM)是采用LOL数据集中所有15幅测试图像所得到的平均峰值信噪比和平均结构相似度。从表7中可以看出,本文引入SDRFB模块和FPN能够有效提升低照度图像的增强效果,AVG_PSNR 和AVG_SSIM指标有明显提升。加入FPN后,AVG_PSNR指标提升了4.95%,AVG_SSIM 指标提升了1.19%;而加入SDRFB 模块后,AVG_PSNR 指标提升了23.02%,AVG_SSIM 指标提升了3.66%。

表7 消融实验指标对比Table 7 Indexes comparison of ablation experiment
图11(a)和图11(b)分别为各消融实验每隔200次迭代所得到的平均PSNR 值和平均SSIM 值的变化情况。可以看出,在每200 次迭代中,均值PSNR 及均值SSIM 指标均是本文模型最好,因此,本文的基础模型能够取得最好的结果。
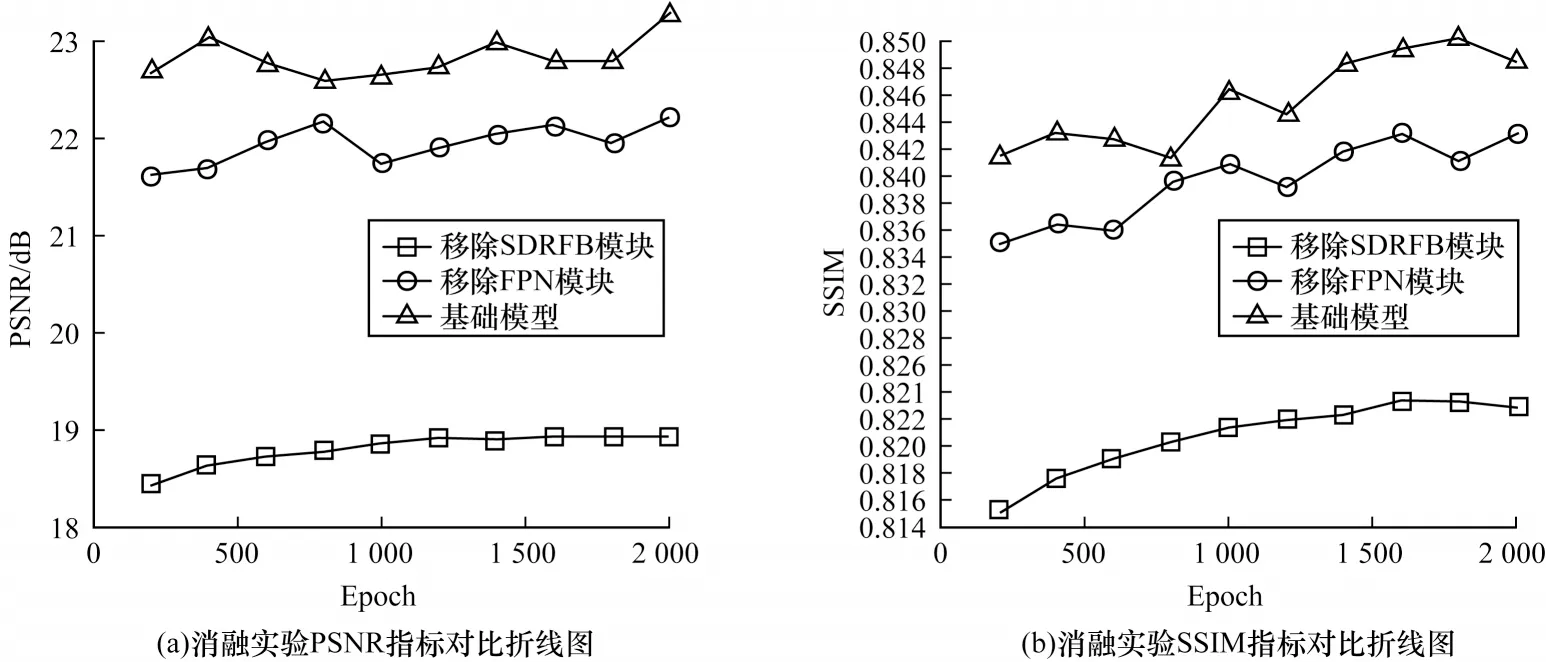
图11 消融实验PSNR、SSIM 指标对比折线图Fig.11 Line chart of comparison of PSNR and SSIM in ablation experiment
3 结束语
本文提出一种基于U-Net 的多尺度低照度图像增强网络(MSU-LIIEN),在网络训练过程中采用融合的策略对网络进行端对端的有监督学习,以促进网络模型融合更多的图像特征信息。由于网络中3 个分支都采用U-Net 作为骨干网,因此MSU-LIIEN能够充分捕捉相隔较远图像区域间的特征信息,提取更丰富的语义信息,从而有利于恢复图像的整体结构,增强图像亮度。此外,MSU-LIIEN 模型中嵌入的SDRFB 模块能够更好地聚合上下纹理信息,捕获更详细的图像特征信息,提高网络模型精度。实验结果表明,与KinD、MSRCR、NPE、MBLLEN 等模型相比,本文模型在增强图像亮度的同时能保持更多的图像结构和纹理信息,而且可以有效抑制噪声的产生。MSU-LIIEN 模型只适用于静态低照度图像处理,下一步拟将其应用范围扩展到低照度视频增强领域。
猜你喜欢
航天返回与遥感(2022年2期)2022-05-12
燃气涡轮试验与研究(2021年6期)2021-08-01
辽东学院学报(自然科学版)(2021年1期)2021-03-12
海洋信息技术与应用(2020年4期)2021-01-18
家庭影院技术(2020年10期)2020-12-14
应用心理学(2019年4期)2019-12-05
小学生优秀作文(低年级)(2018年10期)2018-10-13
北京航空航天大学学报(2017年3期)2017-11-23
Coco薇(2016年10期)2016-11-29
