
基于误差反馈的多尺度特征网络的CT图像超分辨率重建
2022-08-11 13:06林正春李思远姜允志罗庆星郑根让
广东技术师范大学学报 2022年3期
林正春,李思远*,姜允志*,王 静,罗庆星,郑根让
(1.广东技术师范大学 计算机科学学院,广东 广州 510665;2.中山职业技术学院 信息工程学院,广东 中山 528404)
0 引言
随着人工智能和卷积神经网络的快速发展,计算机视觉领域出现了许多优秀的应用,在各种视觉任务中拥有非常优异的表现.单图像超分辨率(Single-image super-resolution)使用一张低分辨率图像,通过计算恢复高频信息从而得到清晰的高分辨率图像.图像超分辨率作为一种图像恢复手段在各个领域如医学图像、辅助诊断、遥感监控等领域有着大量优秀的实际成果[1].CT、MRI及X射线是常见的医学影像,根据这些医学影像医生可以判断患者的病情情况,拥有更高分辨率的医学图像拥有更多的细节信息,能使医生更容易看到身体组织以及发现可能存在的病变症状,进一步提高医生判断的准确率.然而要想获得高分辨率的医学影像往往需要更加昂贵的医学成像设备,而通过增加扫描次数或者扫描时间获得高分辨率图像往往会出现运动伪影,对患者的身体也会造成更大的伤害[2].利用超分辨率重建来获得更高分辨率的医学影像是一种成本更低、风险更小的方法.
自这个问题被提出以来出现了许多超分辨率重建方法,这些超分辨率重建方法都取得了优秀的重建效果,而这些方法可以被分为三类[3]:基于插值、基于重建以及基于学习的方法.基于插值的方法主要通过某一位置周边的像素估算此位置的像素值.插值的方法实现简单,然而重建的图像高频信息丢失严重,存在严重的伪影与模糊,效果并不是十分理想.基于重建的方法是以低分辨率图像为约束条件,利用提取的先验信息来估计高分辨率图像.这种方法的重建效果强于插值方法,然而由于先验信息不足,重建图像往往也缺乏细节.早期的基于学习的方法需要手动选择图像特征和参数,要想建立低分辨率图像与高分辨率图像之间的映射关系需要人工的调整[4],这需要大量的人力且这些映射数量往往无法满足重建清晰高分辨率图像的要求.
Dong等人首先将卷积神经网络用于单图像超分辨率,提出了SRCNN[5].SRCNN由三个卷积层构成,首先,它将低分辨率图像通过卷积层来提取特征,同时建立映射关系,最后使用卷积层重建高分辨率图像.相比传统的超分辨率重建方法,基于卷积神经网络的SRCNN拥有明显更清晰的重建结果.随后,Dong等人将反卷积融入原始方法提出了FSRCNN[6],与SRCNN不同,FSRCNN的输入使用原始尺寸的低分辨率图像而不是插值后的图像,最后使用反卷积放大重建高分辨率图像,这种方法显著地提升了图像的重建速度.Shi等人提出了ESPCN[7],其引入了亚像素的概念,提出了一种不同于反卷积的放大方法.Kim提出了VDSR[8],提升了网络的深度,引入了全局残差,改善了梯度消失的问题.DBPN[9]将迭代反投影的方法引入图像超分辨率中,使用上投影和下投影模块反复交替来进行自我纠正,取得了优秀的重建效果.MSRN[10]是一种多尺度特征的图像超分辨率重建方法,它使用不同尺寸的卷积核改变感受野从而提取多尺度特征,相比单一尺度的图像超分辨率,它具有明显的优势.
以上基于深度学习的方法在自然景色图像上取得了不错的效果,然而在应用于CT图像上的方法数量较少而且仍然存在许多的问题.医学影像纹理复杂而且需要有更加准确的还原度.大多数图像超分辨率重建方法都使用了单一尺度特征进行还原,而且输入特征尺寸单一,如SRCNN、VDSR使用插值后的低分辨率图像,FSRCNN、DBPN和MSRN使用了原始尺寸的低分辨率图像.MSRN使用了不同的卷积核提取多尺度特征,然而大尺寸的卷积核参数巨大,导致运行速度较慢,且只利用了单个尺寸的特征图.以往的方法在最后重建时使用最后的提取的特征或者融合之前提取的所有特征,使用最后提取特征重建效果往往不佳,而使用级联的方法将所有特征串联并压缩这种方法时,往往包含大量低频信息,无法有效使用高频信息还原图像细节.
针对以上问题我们提出一种基于误差反馈的多尺度特征网络用于CT图像的超分辨率重建,我们使用堆叠的小尺寸卷积核代替大尺寸的卷积核来提取多尺度特征,同时利用两种尺寸的特征图完成重建工作.设计了使用误差反馈的融合方法来融合提取的多尺度特征,并使用全局反馈逐步细化特征提取高频信息,最后设计了一个基于误差反馈的高分辨率图像重建模块来重建CT图像.
总的来说,本文的主要贡献如下:
(1)改进了多尺度特征的提取,同时利用了不同尺寸的特征图,并且使用多个级联的小尺寸卷积核的卷积层替换单个大尺寸卷积核卷积层来提取多尺度特征,有效提升了重建质量,同时减少了计算时间.
(2)设计了一种基于误差反馈的特征融合方法以及图像重建方法,提升了特征融合效果,有效利用高频信息重建CT图像.
(3)构造了一个拥有全局反馈连接的基于误差反馈的多尺度特征网络,提出的网络用于重建高质量CT图像,模型的规模可以任意调节.对比结果显示,我们提出的方法有着良好的重建效果.
1 相关工作
1.1 多尺度特征
使用多尺度特征可以有效提升各种视觉任务的最终效果,有许多基于多尺度特征的经典网络,如GoogLeNet[11]以及后续的Inceptionv2[12].此外,多尺度特征在目标检测、图像分割有广泛的应用,并且取得了优秀的效果,如YOLOv3[13]以 及U-Net3+[14].多尺度特征形式可以分为两类,一种是使用尺寸不同的卷积核提取多尺度特征,由于卷积核尺寸不同,感受野不同,提取的特征尺度也不相同.另一种是使用上采样或者下采样生成尺寸不同的特征图来实现多尺度特征的构造.GoogLeNet使用了感受野不同的卷积核提取多尺度特征,而FPN特征金字塔[15]使用尺寸不同的多尺度特征图.在图像超分辨率中,MSRN使用了拥有不同尺寸卷积核的卷积层提取多尺度特征,而LapSRN[16]使用了一种阶梯式的方法逐步放大图像,使用了多个尺寸不同的特征图重建SR图像.
1.2 反馈网络
反馈是指系统输出返回到输入端来影响全局系统的方法,其在各个领域如心理学、控制理论以及物理学都是一种强有力的预测方法.在深度学习中可以使用循环结构实现这种操作,如Feedback Networks[17]是一种利用了反馈的深度学习模型,它采用反馈的方式代替前馈的方式,实现了大类到小类的逐步判断,证明了反馈学习在深度神经网络中的有效性.在图像的超分辨率中,DRCN[18]以及DRRN[19]使用循环结构实现参数共享与特征的反馈.SRFBN[20]将输出的SR反馈到低分辨率图像上,然后一起作为输入重新提取特征.在DBPN中提出了一种误差反馈,其无需循环结构来实现反馈操作,使用前馈操作即可将反馈信息融合至原始特征.
1.3 医学影像超分辨率
除了直接将用于自然图像的超分辨率重建用于CT图像,过去已经提出了许多针对医学影像的超分辨率算法,如吴磊等[21]提出一种基于多尺度残差网络的CT图像超分辨率重建算法,其使用尺寸不同的卷积核提取多尺度特征.刘可文等[22]提出的方法将通道注意力机制加入残差网络结构中重建CT图像.章伟帆等[23]提出的方法可以实现CT图像放大任意比例.
受到Inceptionv2的启发,我们提出使用多个小尺寸卷积核叠加实现多尺度特征的提取.同时,与以往的方法不同,我们同时利用两个尺寸不同的低分辨率图像产生多尺度特征.将DBPN的误差反馈改进用于融合多尺度特征,并且设计了一个逐步融合提取的特征来重建SR图像的重建结构.
2 基于误差反馈的多尺度特征网络
2.1 整体结构
我们的模型由三个主要模块:构成初步特征提取模块,多尺度特征提取模块和图像重建模块.低分辨率图像首先经过初步的特征提取后传入级联的多尺度特征提取模块,每个模块提取出的多尺度特征使用密集残差的方式传递给下一个多尺度特征提取模块,在级联多尺度特征提取模块的最后,提取的特征反向传入第一个多尺度特征提取模块,实现多尺度特征的全局反馈连接.在循环数次后,将每次循环提取的特征传入图像重建模块,由重建模块重建高分辨率图像.整个模型的结构如图1所示.
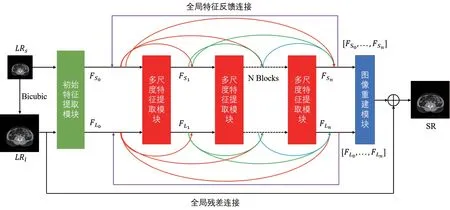
图1 提出的网络的整体结构
2.2 初步特征提取模块
首先,要提取低分辨率图像的初步的单尺度特征.其中传入的低分辨率图像有两种,一种是原始尺寸的低分辨率图像,另一种是插值放大后的图像,两者分别通过两层卷积层提取初步的特征,提取的特征将输入后续的多尺度特征提取模块进一步提取多尺度特征.这个过程可以用以下公式进行表示:

其中C3×3是卷积核为3×3的卷积层,FS0为输出的原始尺寸的特征图,FL0为输出的大尺寸特征图.
2.3 多尺度特征提取模块
多尺度特征提取模块的输入有两种,一个为初始特征提取模块的输出特征,或者是前一个多尺度特征提取模块的输出.多尺度特征提取模块的输出将与之前提取的多尺度特征以密集残差的方式传入下一个模块.
多尺度特征提取模块由多个并列的不同的卷积层组成,其中一路采用单个3×3卷积核的卷积层,另一路采用两个3×3卷积核的卷积层串联连接.与以往的一些方法不同,我们使用两个叠加的3×3尺寸的卷积核代替单个5×5的卷积核,在Inceptionv2中证明叠加两层3×3卷积核的卷积层与单个有5×5卷积核的卷积层在提取特征时具有相同的感受野,但参数数量更少.而且两个卷积层之间的激活函数还进一步增加了模型的非线性.
对传入的特征图首先进行降维操作,使用瓶颈层将特征压缩至较小的维度以减少计算量.瓶颈层使用一个卷积核为1×1的卷积层,整个过程可以有以下公式表示:
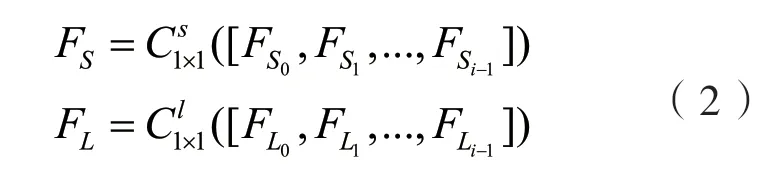
C1×1是卷积核为1×1的卷积层,[FS0,FS1,...,...,FSi−1]为特征的级联.
压缩后的原始尺寸特征分别进入单层3×3卷积层和连续两层3×3的卷积层,由于两路有着不同的感受野,所以提取的特征为多尺度特征.这个过程可以表示为:
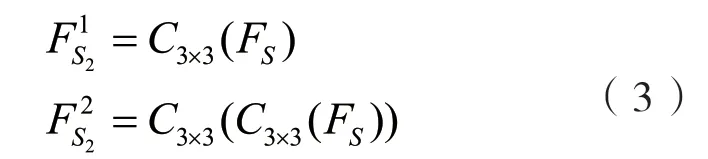
两个提取后的多尺度特征分别与之前多尺度特征模块提取的特征进行一次融合,使用误差反馈融合特征.误差反馈是指将两个特征图相减,然后通过卷积层提取误差信息,并将其加到原始特征图中完成融合.这个过程可以由以下公式表示:
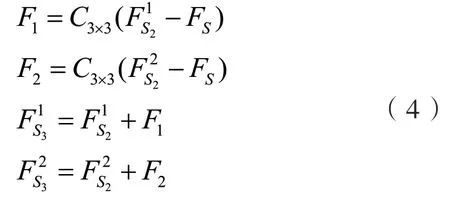
此步骤类似局部残差连接,但与残差连接不同,不是简单的将特征相加而是使用误差反馈进行特征融合.
融合后的两个多尺度特征使用误差反馈进行一次融合.与之前的融合类似,不同尺度的特征相减,使用卷积层提取误差信息,将误差信息返还原始特征.这个过程可以表示为:
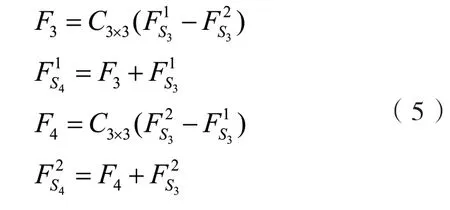
进行第二次特征提取,将提取的特征通过上采样放大.
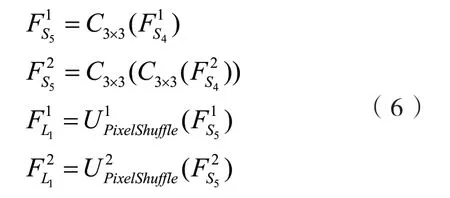
生成的大尺寸特征图的尺寸与需要生成的SR图像一致,将两个特征与输入多尺度特征提取模块的FL融合,同样采用误差反馈的融合方式.其可表示为:
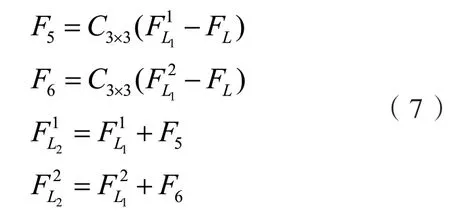
将两个大尺寸的特征融合.通过误差反馈的方式将其中一个的特征信息转移到另一个特征中,用公式可以表示为:
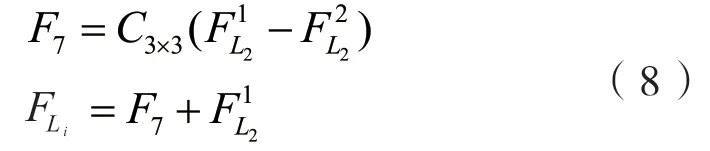
其中FLi为输出的大尺寸特征,用于最后SR图像的生成.
直接处理大尺寸的特征需要大量的计算量,将其通过跨步卷积进行下采样为原始尺寸特征图进行多尺度特征的提取.这个过程可以表示为:
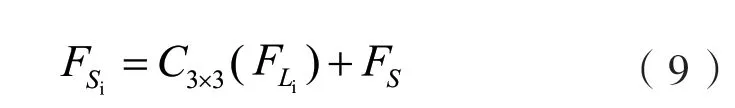
其中,此处的C33×是卷积核大小为3×3的跨步卷积,其步长等于缩放比例,起到下采样的作用.
每个多尺度特征提取模块最后都会输出两个尺寸不同的特征图.与之前模块输出的特征级联,以密集残差的方式输入下一个模块.由于存在全局反馈,所以多尺度特征提取模块的参数在每次反馈之中是共享的,这样也有利于减小模型整体的参数数量.
2.4 图像重建模块
每次循环提取的特征在最后的循环结束后输入图像重建模块,大尺寸的特征图通过误差反馈逐步融合,每次循环的特征信息将反方向传递到之前的特征图中,丰富所有特征图中的高频信息,从而获得更好的重建效果.用公式表示如下:
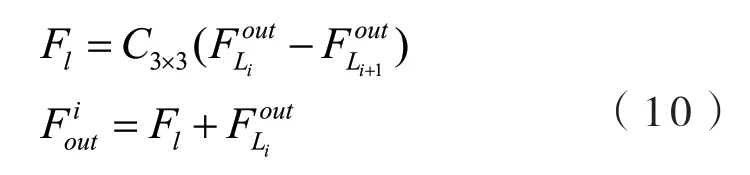
融合后的每组特征单独重建为高分辨率图像,用公式表示为:
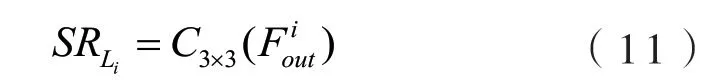
这里的卷积层将特征转换为3通道RGB图像.模型有几次全局反馈,就会生成几个初步的3通道图像.
在利用大尺寸特征的同时,我们也会使用小尺寸的特征图,对于输入重建模块的原始小尺寸特征,将其通过瓶颈层压缩后使用反卷积放大,放大后单独重建为SR图像,这个过程可以表示为:
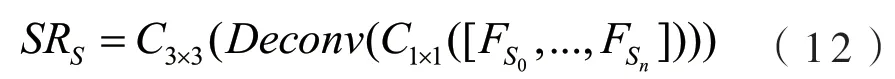
其中[FS0,FS1,...,FSi,...,FSn]是每次循环输出的原始尺寸特征图的级联,Deconv是反卷积层,起到上采样的作用,反卷积的跨步数等于放大的比例数.
最后将以上的SR图像求和取平均得到最后的SR图像.
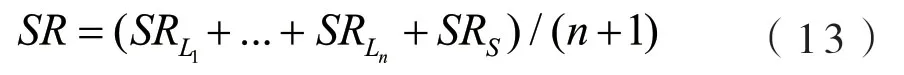
重建的SR图像融合了原始图像的低频信息以及提取的高频信息,拥有更加丰富细节纹理.
3 实验与分析
3.1 数据集与指标
我们在癌症影像档案(The Cancer Imaging Archive, TCIA)中收集CT图像,该网站拥有大量公开的CT图像.我们使用了其中的TCGACODA、TGGA-STAD和TCGA-ESCA的CT图像数据集.其中,TCGA-CODA为结肠腺癌CT图像,TGGA-STAD为胃腺癌CT图像,TCGAESCA为食道癌的CT图像.我们从这几个数据集中选取600张CT图像作为训练集,其中,以上每个数据集的CT图像占整体训练数据集的三分之一.再从三个数据集中分别选取20张图像混合重排后生成3个测试集,每个测试集包含20张CT图像.
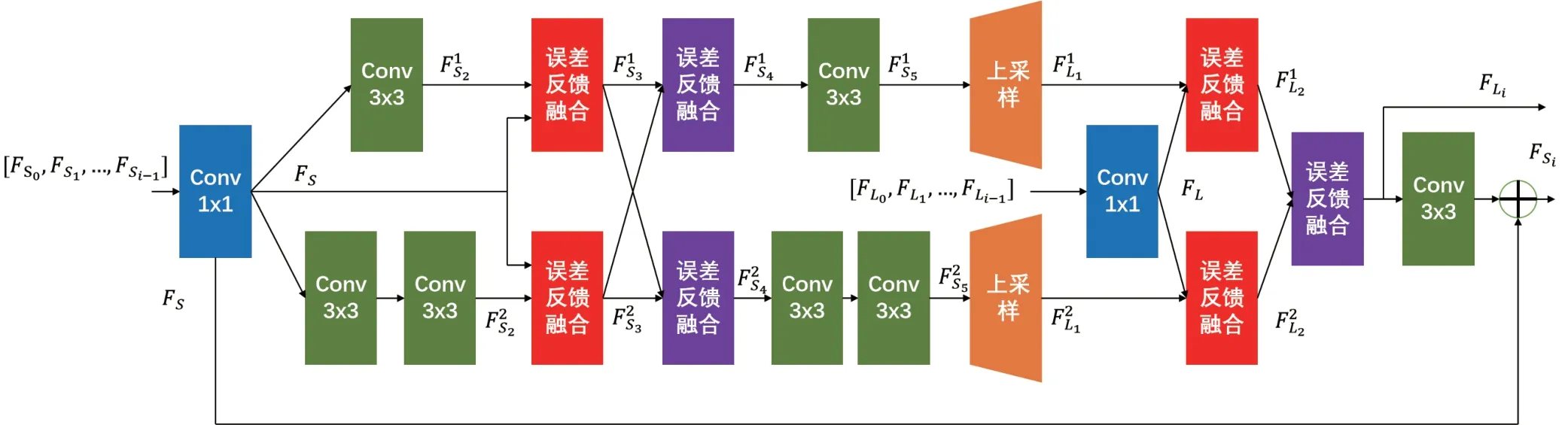
图2 多尺度特征提取模块的结构
所有的图像尺寸为512×512,我们使用Bicubic对训练集做下采样处理,下采样后的CT图像作为网络的输入.我们将训练集的CT图像缩小了2倍、4倍以及8倍,以测试我们的网络在放大2倍、4倍和8倍时的性能.在评价重建指标时,我们采用了峰值信噪比(Peak Signal to Noise Ratio, PSNR)以及结构相似度(Structural Similarity, SSIM).两者都在YCbCr空间上的Y通道计算的.
3.2 实验环境与设置
我们的实验平台为Ubuntu20.04,GPU采用NVIDIA GeForce RTX3090,32G内存,使用PyTorch框架,CPU为AMD Ryzen 9 3900x,所有的训练与测试都在以上环境下进行.我们使用Adam[24]优化器进行优化,其中它的参数β1设置为0.9,β2设置为0.999,ε设置为10-8.设定网络迭代300次,开始的学习率设置为0.0001,第200次迭代学习率后减半为0.00005,训练时的batch size设置为2.模型中的卷积通道数设置为64,采用L1损失函数,激活函数采用PRelu.L1损失函数可以表示为:

其中Ytrue为原始图像,Ypredicted为模型预测图像.
3.3 实验结果
我们将我们方法与其他方法进行比较,使用构造的测试集分别测试各个模型.除了我们的方法外,还有Bicubic、SRCNN、FSRCNN、VDSR、DBPN.我们比较了放大2倍、4倍和8倍的情况下CT图像的重建质量,使用客观评价标准PSNR和SSIM进行比较.这里我们采用7层多尺度特征提取模块和2次循环的结构,这两个参数设置是可以自由选择的.对比结果见表1,其中,最佳结果加粗表示,可以看到相比Bicubic这种传统的方法,深度学习方法具有极大的优势,而我们提出的方法与其他深度学习方法相比也具有明显的优势.除了客观指标外,我们还展示了使用我们提出的方法重建的CT图像,这样可以更加直观的进行对比,我们展示了放大4倍和8倍的结果.对比的结果见图3.可以看到,与其他方法相比,我们提出的方法重建的CT图像拥有更丰富的细节表现.
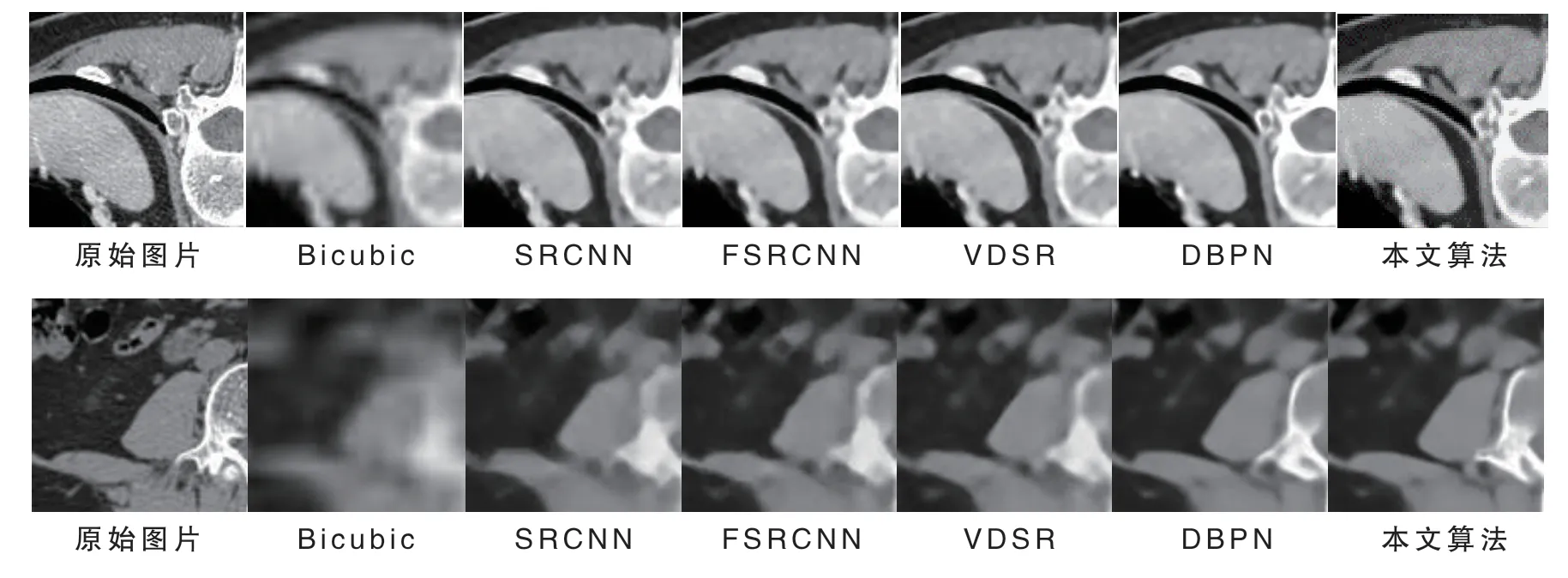
图3 各个超分辨率重建方法的主观比较,其中第一行为放大4倍,第二行为放大8倍
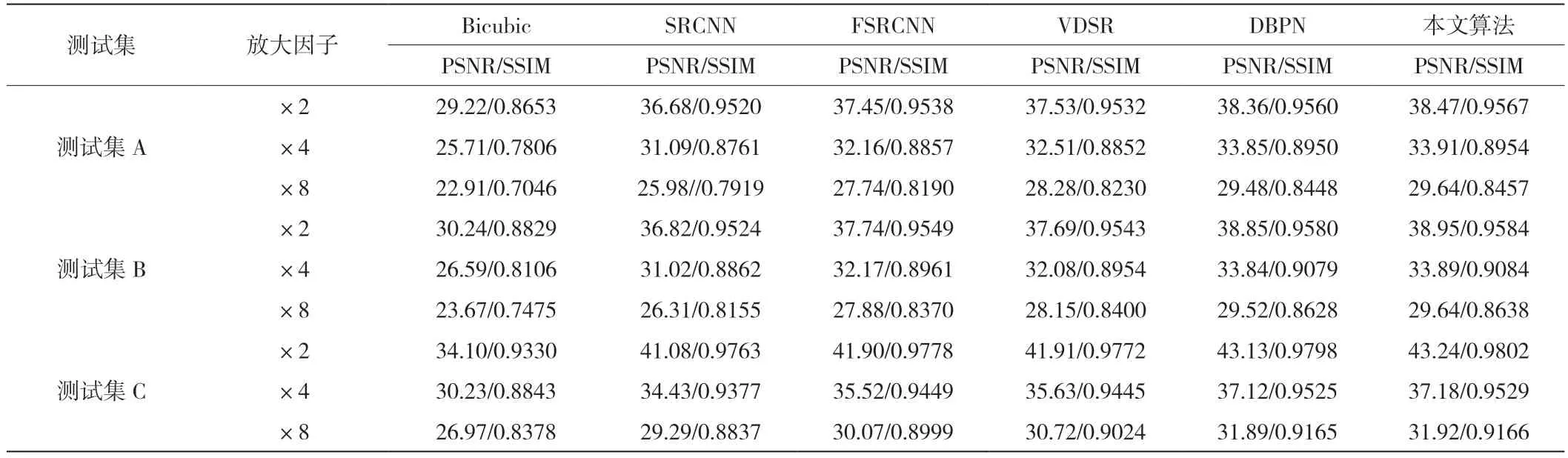
表1 各个超分辨率算法在不同放大因子下的客观比较
3.4 消融实验
我们将我们提出的融合方法和SR图像重建方法与传统的级联融合以及重建方法进行了比较.我们设置了4个不同的网络:第一个结构没有误差反馈融合,使用传统的重建方法;第二种使用误差反馈融合,并使用我们提出的重建方法;第三种不使用误差反馈,使用我们提出的重建方法;最后一种使用误差反馈融合以及我们提出的SR图像重建方法.每个网络都是2层多尺度特征提取模块,循环2次,放大8倍,使用测试集A对比.对比结果见表2,由表2可以看出,没有使用误差反馈融合与重建的效果最差,使用其中之一会有更好的效果,全部使用拥有最佳效果,证明我们的融合与重建方法相比,传统的级联融合方法可以得到更好的重建效果.

表2 使用不同融合方式与重建方式的消融实验
4 结论
本文提出了一种基于误差反馈的多尺度特征网络用于CT图像的超分辨率重建,解决了基于多尺度特征卷积神经网络的医学影像超分辨率重建中高频信息丢失导致纹理不清晰、含有伪影模糊的问题.我们将误差反馈用于多尺度特征融合与超分辨率图像的重建,并同时利用两种尺寸不同的低分辨率图像.我们构造了多尺度特征提取模块,在多尺度特征提取模块中使用并行的卷积层提取多尺度特征.并引入全局反馈进一步细化提取的特征,最后使用我们设计的重建模块生成高质量的CT图像.由实验结果可以看到,我们的方法在客观指标PSNR以及SSIM上取得了良好的效果.从主观上来看,我们重建的CT图像可以清晰地看到组织细节,可以使医生更加准确地做出诊断.未来我们将尝试减小模型的规模,降低其对计算机资源的要求,使其更加容易部署在真实的工作环境中.
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年15期)2019-08-27
数学物理学报(2019年3期)2019-07-23
电子制作(2018年19期)2018-11-14
家庭影院技术(2018年9期)2018-11-02
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
太空探索(2016年5期)2016-07-12
噪声与振动控制(2015年4期)2015-01-01
