
基于深度学习的专利知识推荐服务研究
2022-08-09 05:44李振宇战洪飞余军合邓慧君
计算机工程与应用 2022年15期
李振宇,战洪飞,余军合,王 瑞,邓慧君
1.宁波大学 机械工程与力学学院,浙江 宁波 315211
2.宁波大学 信息科学与工程学院,浙江 宁波 315211
随着经济全球化的发展,市场环境动态多变,企业之间的竞争日益激烈。面对激烈的市场竞争,企业创新设计能力已成为决定企业竞争是否占优的关键,企业需要不断提高自己的创新能力来提升自身的核心竞争力。产品创新设计是一个创新密集型过程,需要大量的知识和设计经验[1]。在产品创新设计过程中,知识重用和重组已被证明是创新的主要来源[2],但如今的知识重用研究主要集中在同一应用领域设计知识的重用。然而其他应用领域的知识往往更好解决产品创新中的问题,从各种各样的领域汲取灵感进行创新设计正成为一种趋势。因此,研究如何利用多领域知识进行产品创新具有巨大的现实意义。
专利知识包含了各个应用领域最新的技术和研究成果,许多学者使用词频统计、机器学习、深度学习三种方法分析专利中的知识来辅助产品创新设计。其中基于词频统计和机器学习的研究有梁艳红等人[3]基于发明问题解决理论(TRIZ)提取专利中产品创新知识。Yoon等人[4]利用线性判别式分析算法提取专利主题,并根据协同过滤算法识别潜在竞争对手,以此辅助产品设计。陈忆群等人[5]利用支持向量机(SVM)算法将关键词抽取转化为分类问题提取关键词。林园园等人[6]构建功能-原理-结构模型,使用K均值聚类算法(K-means)对专利进行聚类,实现推荐相关的专利组合方案给产品设计者。Chen等人[7]提出了一种结构函数式知识抽取方法,识别包含结构和功能的潜在知识。刘龙繁等人[8]提出一种使用朴素贝叶斯算法(Naive Bayes),以功能基为分类标准的专利分类方法,为设计者提供相关专利知识。但基于统计词频以及共现的方法只能统计专利的显性信息,对产品创新提供帮助较小,机器学习方法抽取知识较为片面且精度不高、效率较低。而深度学习可以解决以上问题,可以抽取专利实现的功能效果,为产品创新设计提供类似的成功案例。例如董文斌等人[9]利用BERT-BiLSTM-CRF算法识别专利中的功能、原理、结构三类实体,并提取实体之间的关系,构建专利知识结构模型。Chen等人[10]预先定义实体类型和语义关系库,提出一种利用BiGRU-HAN算法的专利知识提取框架。张盘龙[11]利用实体识别算法构建专利知识图谱进行专利推荐。但现有的深度学习研究大多缺乏对专利知识应用情境和专利技术原理的深入分析,因而无法有效解决跨领域推荐专利的准确性。
除此之外,专利数量呈指数级上涨,并非所有专利都具有同等重要的创新意义[12],有必要为设计师评估检索到的专利。刘勤等人[13]采用熵权法对专利特征、发明人特征及权力人特征进行赋权,构建专利价值评估模型。Verhoeven等人[14]使用IPC分类号和引用信息来衡量技术的新颖性。李欣等人[15]选取专利技术、经济、法律和主体四大维度,运用机器学习方法对专利质量进行评估。但大多数研究仅用一个指标对专利进行评估,缺乏从多个角度评估专利创新价值。
基于以上问题,本文提出一种基于深度学习的专利知识推荐模型,从文本分类的角度提取专利的功能信息。其次,利用深度学习算法提取情境、技术属性,结合IPC分类号信息,生成专利知识空间。为满足设计者不同的知识需求,提出技术成熟性,新颖性和可扩展性三种评价指标,以向设计者推荐其他领域专利知识,激发设计者创造更多的创新设计理念。
1 基于深度学习的专利研究进展
目前,由于出色的表示学习能力,深度学习在自然语言处理领域取得了巨大的成功,许多学者致力于利用深度学习提取专利中的隐形知识,主要分为专利知识提取、专利知识推荐、专利评估及演化三个方向。文献[10]、[16]利用实体识别算法提取专利中的技术术语,构建了专利知识提取框架,方便使用者更快地理解专利。文献[9]、[11]、[17]在专利知识提取框架的基础上,提取专利的功能、技术等知识构建专利知识图谱,推荐合适的专利辅助产品创新。文献[18]、[19]利用深度学习构建专利相似性网络,根据技术进行专利聚类,判断专利技术的潜在价值,准确地预测新兴技术,为未来技术发展提供方向。
从现有研究成果来看,当前的专利知识研究主要集中在当前领域知识推荐的准确性,忽略了知识的多样性,即其他领域的专利知识。而其他领域的知识往往更好地解决当前的设计问题。因此本文对专利知识情境进行深入分析,解决产品创新设计的多样性知识需求,提高专利知识推送质量、增强企业创新能力和竞争能力。
2 基于深度学习的专利知识推荐模型框架
在产品设计中,设计者通过知识重用和重组来解决设计问题。专利作为包含大多数应用领域知识的重要知识资源,可以帮助设计者完成各种设计任务。其中产品是由功能和功能承载结构所组成的系统,功能分析贯穿产品设计的整个过程。将设计问题抽象解释为功能需求问题可以在任何领域中使用,但通过功能检索到的专利通常大量重复或者相似,设计者仍需要花费大量时间去寻找和理解检索到的所有专利,最终找到合适的专利。不同的知识具有不同的应用情境[20],在特定情境下其他领域知识才可以发挥效用。此外,不同的专利文本具有不同的技术成熟性和新颖性,这对不同的设计者有着不同的启发性影响。因此,本文提出一种基于深度学习的专利知识推荐模型,它可以推荐其他应用领域的专利知识,实现了跨领域的知识迁移。
跨领域专利知识推荐模型框架如图1所示。设计问题经过问题表征被描述为功能需求,并描述当前知识需求情境,对功能进行建模并分解为三层功能结构,根据功能基和需求情境将其解释为设计问题空间。由于专利文献为半结构化数据,阅读专利全文获取知识需要花费高昂的时间成本、人力成本等。于是本文提出一种TG-TCI(two granularity-three classifier integration)半监督文本分类算法从文本分类的角度提取专利的功能信息,分别从字符级(BERT)和词语级(Word2vec)对专利文本进行特征向量表示,可以有效解决专利文本中一词多义、歧义等现象。并集成支持向量机(SVM)、贝叶斯(Naive Bayes)、K近邻分类(KNN)三种不同基分类器的优点,提高专利功能分类的准确性。采用BERTBiLSTM-CRF实体识别算法从专利说明书中自动提取专利的知识应用情境、技术术语,实现使用计算机自动提取专利知识,降低人力成本和研发时间。结合IPC分类号信息分别代表专利的功能、情境、技术、领域属性,构成专利知识空间。其推荐过程如图1所示,首先根据功能基和知识情境实现设计问题空间到专利知识空间的映射,搜索相关专利。其次,检索后的专利通过技术术语将实现同一功能并技术手段相似的专利采用K-means算法进行聚类,形成专利技术集群,之后设计者根据设计需求选择相应的评估指标通过IPC信息对专利技术集群进行评估和排序。最后,向设计者推荐三层呈现的专利知识信息,以激发设计者的创新思维,进行新产品概念设计中的知识转移。必要的是,需要定时从专利网站中搜寻专利文本,通过上述知识抽取过程,将这些专利文本存储在本地专利数据库中,以便可以实时更新专利知识空间。
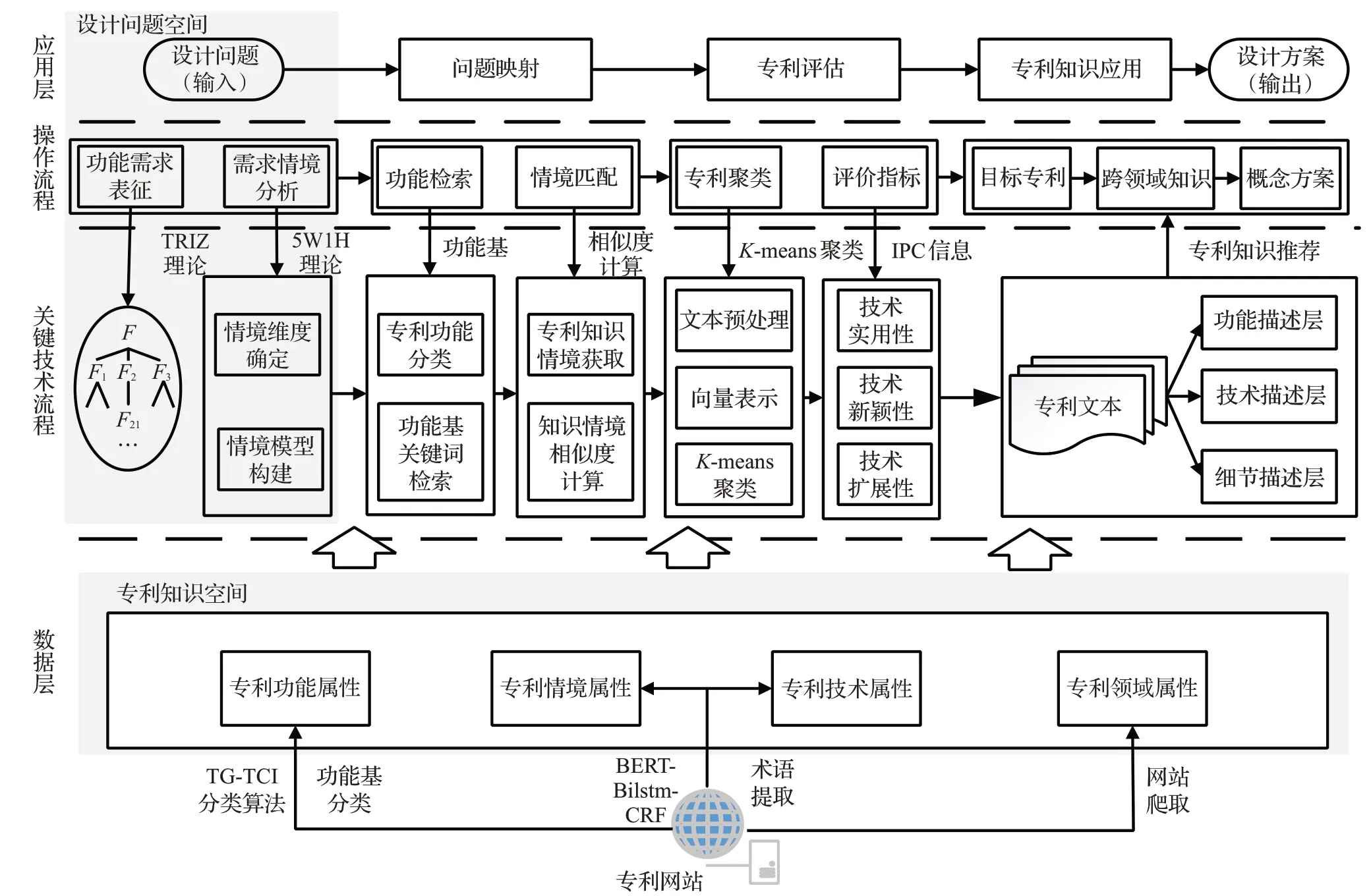
图1 基于深度学习的专利知识推荐模型框架Fig.1 Patent knowledge recommendation model framework based on deep learning
3 基于功能基和知识情境的专利知识推荐方法
3.1 研究思路
当前设计者搜寻专利由于受到自身知识经验和专利的分类体系(IPC)的约束,只能找到本专业或本领域的专利文献。从产品创新角度来说,其他领域知识往往更好激发设计者的创新思维,因为不同领域的产品设计问题,可能会采用相似的技术方案。因此,本文将功能基和知识情境引入产品设计流程中,来为设计者提供跨领域专利知识,辅助产品创新设计,其产品设计流程对比如图2所示。
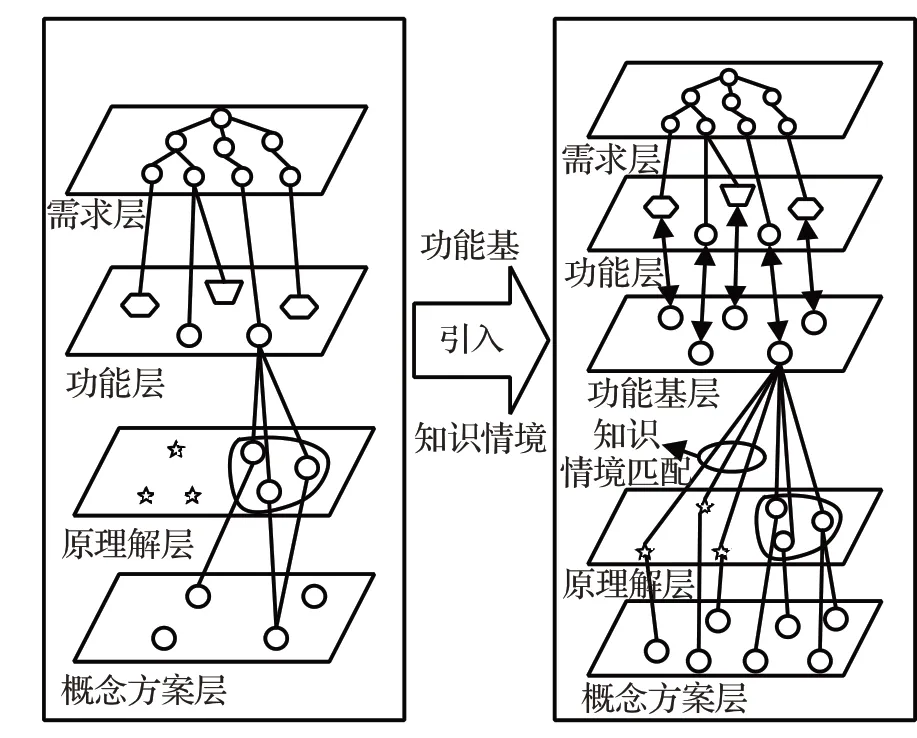
图2 产品设计流程对比图Fig.2 Product design process comparison chart
在引入功能基和知识情境之前,设计者由于自身知识的不足影响了功能层与原理解层的映射,从而限制了产品概念方案的生成。通过引入功能基和知识情境方便设计过程信息的表达,建立了统一的表达标准。由于功能基高度抽象,可以突破功能应用领域的限制,并根据知识应用情境的匹配程度对其他领域知识进行筛选,获得更多创新解决方案。
3.2 基于功能需求和知识需求情境的设计问题空间
产品创新设计是复杂的思维活动,设计问题求解可以理解为“发掘设计问题与已有知识之间的相关性,并进行知识的迁移和组合”的过程[21]。功能是产品的核心要素,而产品创新设计的核心是知识从一种情境转换到另一种情境[21]。通过对设计问题的功能需求和知识需求情境的问题表征,将设计问题进行标准化表达,可以得到产品的功能结构模型和知识情境模型,同时形成设计问题空间。设计者利用功能基和知识情境检索专利知识库中已有的解决方案和知识,并将其与当前的设计问题进行类比,以生成新的设计方案。
3.2.1 功能建模
产品设计的本质是设计具有特定功能、满足特定设计要求的产品。产品建模是产品设计的基础,功能建模是产品设计的首要任务。为了对功能进行统一的表达,Stone等人[22]提出了功能基(functional base)的概念,采用“元功能+流”的表示形式。Hirtz等人[23]整合并统一了元功能和流的分类,建立了功能基的标准词典。但该词典创建距今已经十多年时间,不能很好地适用于当前的设计活动。为此,本文根据TRIZ功能分析理论,提出一种采用“动作+对象”描述功能,如图3所示,“动作”描述了功能的作用方式,“对象”描述工作的对象。其中动作包括导向、聚集、转换、连接、感知、调节、分离、供应、支持九个一级功能类别,结合Hirtz对流的分析进一步细化为39个二级功能类别与234个三级功能类别。表1显示了一个功能基的实例,设计者可以选择合适的功能基来定义任何产品的功能。由于功能基高度抽象,使用功能基表示设计问题的功能需求可以在任何领域中使用。

图3 功能基的结构Fig.3 Functional base structure

表1 功能基的实例Table 1 Functional base instance
3.2.2 知识情境建模
基于功能基向设计者推荐其他领域专利知识时,大量跨领域专利满足当前功能需求,检索结果冗余度高,无法满足知识推荐的准确性。然而知识的产生和应用都具有特定的背景和环境[20],知识情境可以视为知识应用的限定条件,是知识共享和知识重用的重要基础,能够有效解决基于功能基检索后的专利知识过载问题[24]。通过对设计问题和知识主体之间的情境匹配度计算将极大地提高设计者知识检索的效率,进而缩短产品创新设计的开发周期,提高创新质量。为此,本文建立一个可扩展的知识情境模型,用以判断其他领域知识解决当前设计问题的可行性。
在产品设计过程中,根据5W1H分析法可得知识情境就是描述当前的设计者的5W1H信息(Who、What、Where、When、Why、How),即设计者在某一时间某一地点用某种方法从事当前的设计活动。但仅这六个维度可能造成设计需求识别不完整,降低工作效率。因此,本文以设计过程为线索,结合5W1H分析法将知识情境维度进行提炼,构建知识情境模型,形式化表达为:知识情境={问题、任务、设计过程、设计执行者、设计活动、设计对象、知识资源、地点、时间},其中设计执行的时间和地理位置和在设计活动中没有实际意义,本文将产品的业务周期作为时间维度,产品工作时的应用地点作为地点维度。具体维度释义如表2所示。

表2 知识情境维度含义及说明Table 2 Knowledge situation dimension meaning and explain
知识情境各维度之间存在着紧密的联系,知识情境交互关系模型如图4所示。问题维度、任务维度、知识执行者维度以及设计活动维度之间存在相互传递转换关系:设计问题分解成多个任务目标;任务目标由设计活动实现;设计活动由相关部门和组织组成的设计执行者全权负责;并且在设计活动维度中,时间和地点两个维度是设计活动执行的条件限制,设计活动使用相应的知识资源驱动设计过程的执行。在知识执行者维度中,知识员工存在于各个业务执行组织,在特定的设计活动中具备一定的求解技能、求解经验以及对应的执行职位。需要说明的一点是,本文列出了知识情境的主要维度,企业在实际应用时需根据自身的业务特点和业务数据进行维度的扩展和细化。
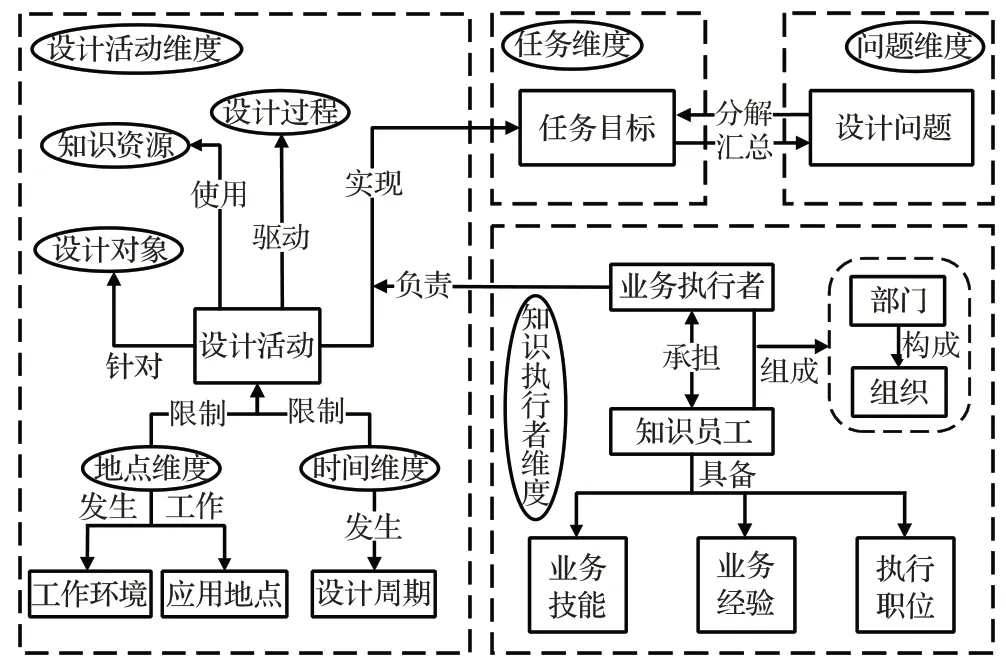
图4 知识情境多维度交互关系模型Fig.4 Knowledge situation multi-dimensional interaction model
3.3 专利知识空间的知识表示
专利知识是创新的重要资源,有效地整合产品创新所需的专利知识资源方便企业创新人员对相关专利知识的检索和利用[25]。密阮建驰等人[26]提出知识应与情境相结合,以方便设计者更全面地理解知识,促进知识之间的共享和重用。为此,本文将情境化设计引入FBS模型,构建功能描述层、技术描述层、详细描述层三层知识表示结构,形成专利知识空间,如图5所示。功能描述层体现了专利发明人的主观意愿,是产品的最终目的。技术描述层包括情境属性、技术属性、领域属性,分别由专利应用情境、技术术词、IPC分类号信息组成,方便设计者更快速理解专利的应用场景和所使用的技术。详细描述层包含专利中的具体实施方式和专利显性信息。该专利知识空间模型从左到右的知识抽象程度逐渐减少,较高抽象的知识更容易进行知识转移,利于设计者从多个角度理解专利知识。
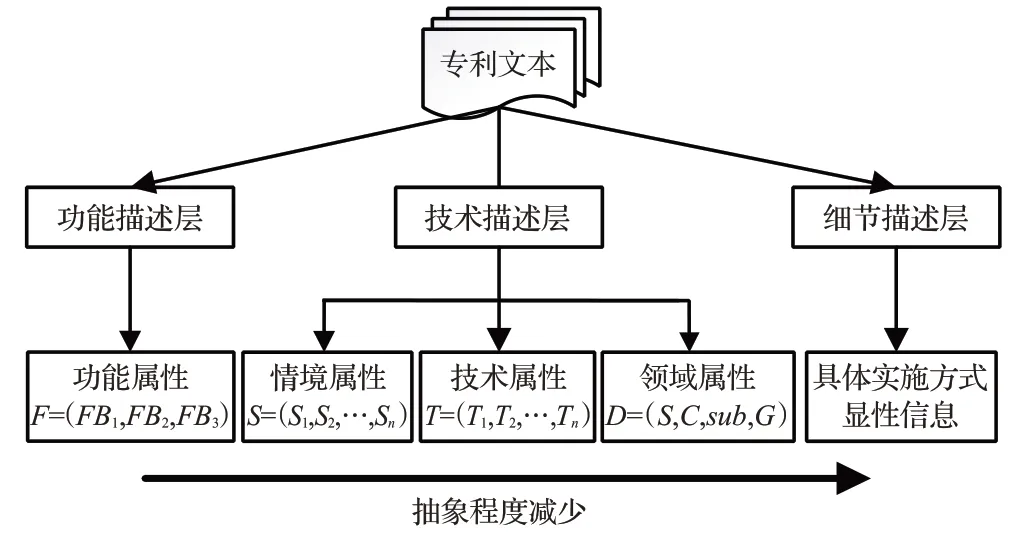
图5 专利知识表示模型Fig.5 Patent knowledge representation model
3.3.1 功能描述层
定义1功能描述层是指利用功能基的层次结构表示专利的功能信息。

其中,p代表专利,FB1、FB2、FB3分别代表专利功能的第一类别、第二类别、第三类别。
专利中的摘要可分为目的、方法、结论三个部分,目的和结论体现了专利的主要目标,可以表示专利主要实现的功能。本文使用专利摘要数据,根据功能基对专利进行分类和标注,将专利分为三层功能类别。但人工标注费时费力,于是本文从文本分类的角度实现计算机自动提取专利的功能信息。目前文本分类主要分为半监督学习和有监督学习。有监督学习需要大量人工标注数据,专利数据专业性强,进行人工标注需要消耗大量的时间成本。传统的半监督算法可以利用少量的标注数据和大量的未标注数据进行文本分类,但专利术语专业性强,存在一词多义现象,使用未标注数据会影响分类器性能,影响准确率。
为此,本文提出一种TG-TCI(two granularity-three classifier integration)半监督文本分类算法,同时引入基于分歧思想(disagreement-based methods,DBM)和集成学习(co-training)两个方向同时对半监督文本分类方法进行改进,采用BERT和Word2vec构建双通道语言模型,加大专利样本之间的分歧,并对KNN、SVM、Naive Bayes三种分类器进行集成,既可以发挥数据集多空间特征的优势,又可以集成各分类器的优点,提高专利功能分类的准确性。分类过程主要包括专利数据集准备、专利特征抽取、训练,其功能信息提取流程图如图6所示。
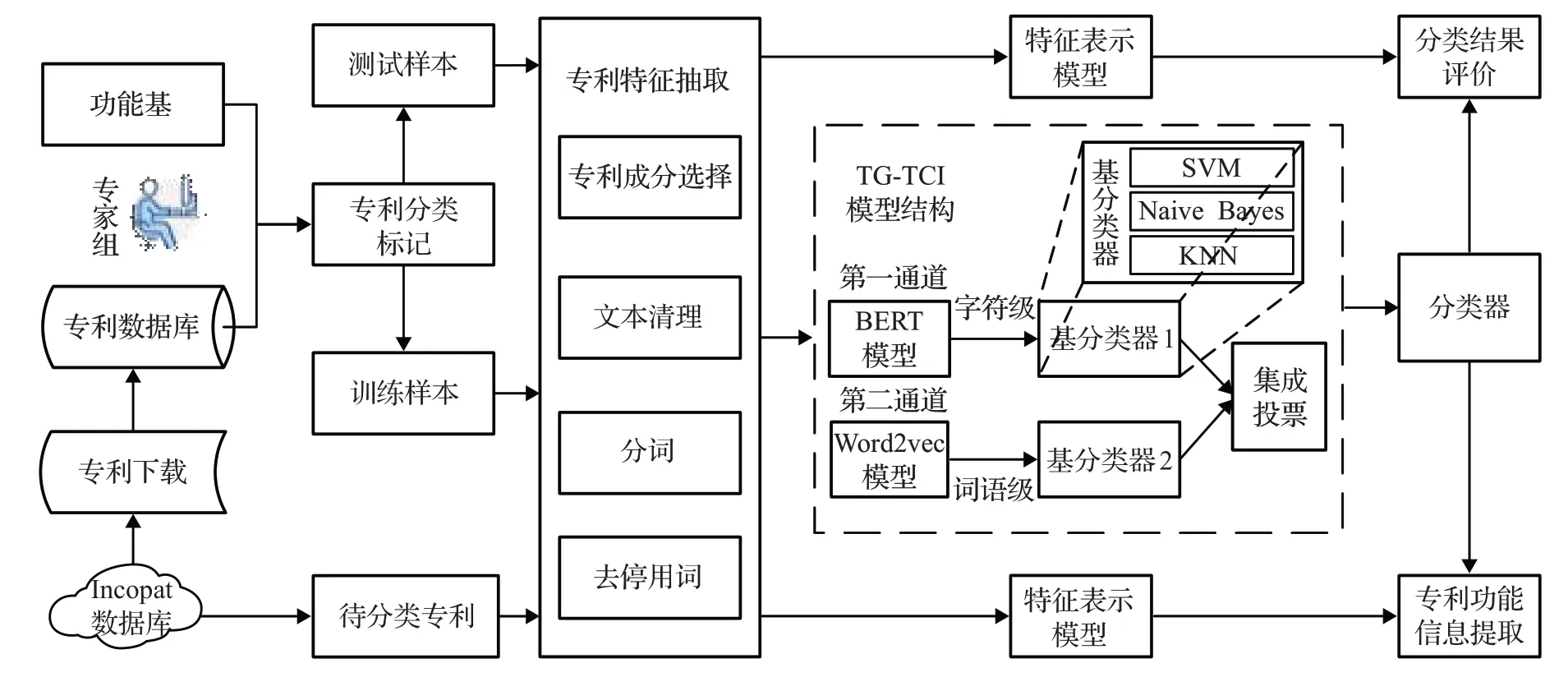
图6 功能信息提取流程图Fig.6 Function information extraction flowchart
3.3.1.1 专利数据集准备
本文从商业专利数据网站(incopat)获取有效发明专利文献,选择“标题+摘要”作为专利信息的代表进行实验,专家组根据功能基对专利文本进行人工标注和分类,将专利文献分为测试样本、训练样本和待分类样本三个部分,以进行专利功能提取。
3.3.1.2 专利特征抽取
采用jieba分词对专利原始文本进行预处理。对专利进行文本清理、分词、去停用词,形成计算机可理解的结构化形式,提高专利功能分类的效率和质量。
由于在中文文本中,字和词是最主要的两个粒度,所以TG-TCI模型利用BERT构建字符级的专利文本特征,利用Word2vec构建词语级的专利文本特征。Word2vec模型有CBOW和Skip-gram两种训练模式,由于本实验使用的数据集较小,Skip-gram模式一个中心词可以预测多个周围词,在小数据集也能取得较好的效果,于是选择Skip-gram模型构建词语级特征训练。将双通道的向量作为基分类器的输入,如公式(2)所示:

yi为专利功能类别,f为分类函数,x1、x2分别为BERT和Word2vec两种模式训练下的特征向量。这样的文本特征向量表示可以让模型学习到不同粒度上的特征,使TG-TCI模型比传统半监督分类模型学习更多的信息。
3.3.1.3 基分类器训练
(1)基分类器的选择
目前机器学习领域有多种分类器。其中SVM在二分类问题效果显著,可以有效解决数据分布不均的问题,但在多分类问题和高维度情况下效果不佳,求解较慢。KNN算法准确率高,对异常点不敏感,但在小样本集中易出现误分类情况。Naive Bayes可以处理多分类问题,并且过程简单速度快,在小样本集中有着很好的效果,为了保证TG-TCI算法的分类速度、多分类情况的准确性、不同样本维度和不同规模样本集的适应性,因此本文选择SVM、Naive Bayes、KNN3个基分类器,将这三种分类器集成,发挥各分类器的分类优势。
其中SVM算法是一种在一个多维数据空间中通过寻找最优分离超平面,将数据映射到高维空间,将数据分成两类,实现文本的高效分类的算法。其中核函数可以有效避免“维数灾难”,得到最优的分离超平面。目前常用的核函数有线性核、多项式核、高斯核等,根据数据集的规模选择合适的核函数可以有效地提高分类精度。本文专利文本数据集规模较小,且向量维度适中,因此选择高斯核作为SVM的核函数。超平面的定义如下所示:

其中,ω、b为需要训练的参数、φ(x)为核函数。
构造待有约束条件的优化问题,公式如下:
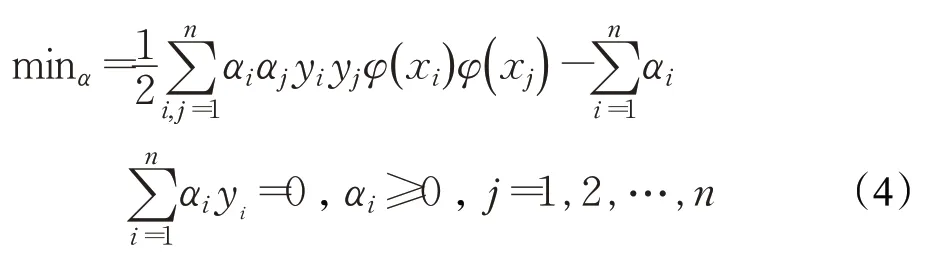
朴素贝叶斯算法是一种基于统计的分类器。核心思想是当不能准确知悉一个事物的本质时,可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率[23]。该算法假定属性之间相互独立,没有某个属性变量对于决策结果有较大的比重。朴素贝叶斯算法极为简单,对于未分类的文本d i,所选特征向量为d i=(ω1,ω2,…,ωn),文本d i属于特定类别(Fb)的概率为p={F=Fb|d i=(ω1,ω2,…,ωn)},当等式表示的后验概率达到最大值时,该文本属于该类功能。
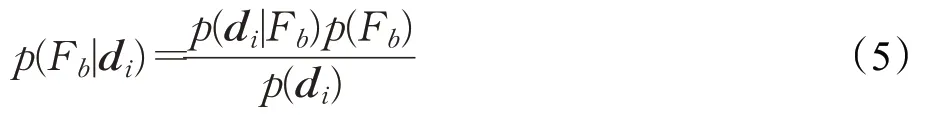
KNN算法是一种简单、有效的分类器。核心思想是每个待分类文本根据在特征空间中与它最接近的K个邻近值的类别进行分类,是一种非参、惰性的算法模型。无需对数据做出假设,无需对数据进行提前训练,对多分类任务有着较好的效果。KNN算法计算公式为:
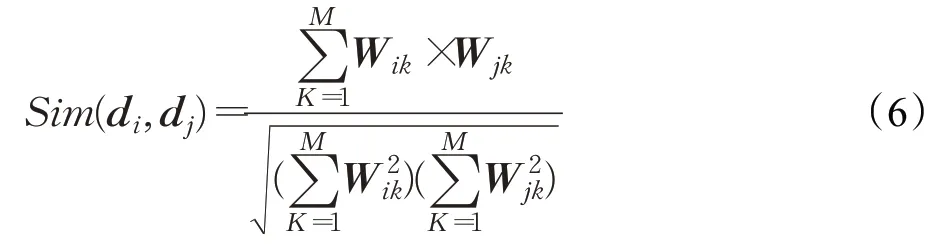
其中,Sim(d i,d j)表示文本中d i与d j之间的相似度,W ik代表文本d i中第k个词语的权重。
(2)基分类器的集成
目前基分类器有多种集成方式,为了提高分类器的泛化能力和降低数据集对分类器的影响,本文将Bagging、Stacking结合对基分类器进行集成。基分类器集成结构如图7所示。
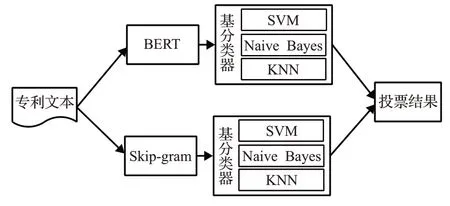
图7 基分类器集成结构Fig.7 Base classifier integration structure
首先TG-TCI模型将字、词两种专利本文特征向量输入到两个由SVM、Naive Bayes、KNN构成的基分类器组。在每个基分类器组中,使用Stacking方式对3个基分类器进行集成,让3个分类器学习相同样本的特征,获取3个分类器之间的分歧,整合3个基分类器的优点。其次,使用Bagging方式对两组基分类器组进行集成,让分类器学习同一样本在两种粒度的特征向量,得到同一样本在不同空间特征的信息。最后,集成结果采用投票的方式产生,投票公式如式(7)所示:
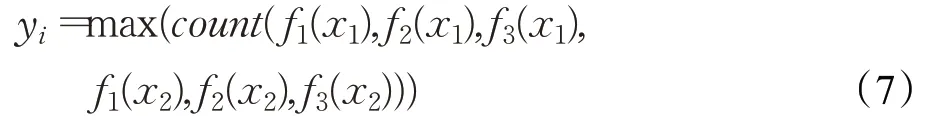
f1,f2,f3分别为3个基分类器的分类函数,count为计数函数。
其中考虑算法的复杂度,Stacking方式选择三折交叉验证,该方法使TG-TCI模型获得样本和分类器的两种差异,从分歧设计的角度上对传统半监督分类算法进行改进,提高分类算法的准确率。
(3)算法流程
TG-TCI专利功能分类算法流程如图8所示。
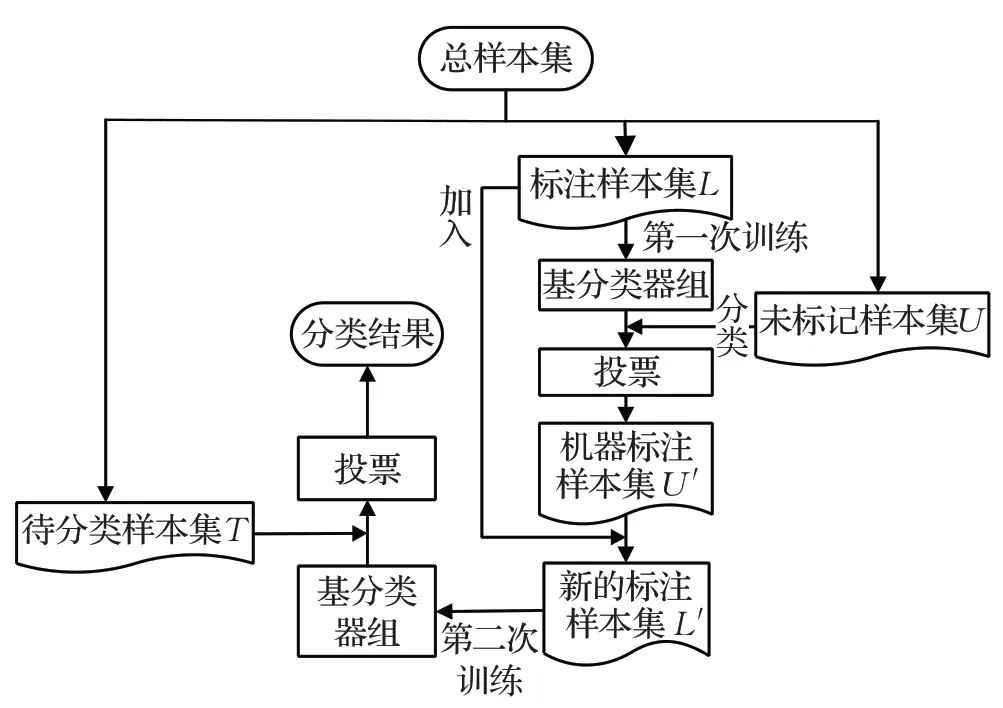
图8 TG-TCI算法流程图Fig.8 TG-TCI algorithm flowchart
输入:标记样本集L、未标记样本集U、待分类样本集T。
输出:专利功能分类结果。
步骤1对标记样本集L、未标记样本集U、待分类样本集T分别采用BERT和Skip-gram进行特征向量表示,得到字符级向量L1、U1、T1,词语级向量L2、U2、T2。
步骤2将L1、L2分别输入两组基分类器中,进行基分类器第一次训练。
步骤3将U1、U2分别输入经过第一轮训练的六个基分类器中,得到同一样本的六个预测结果。根据投票选择相对准确的预测结果和标记样本L结合形成新的标记样本集L′,进行第二次训练基分类器。
步骤4将T1、T2分别输入两组训练好的基分类器,得到同一样本的六个预测结果,通过投票的方式得到最终的分类结果。
3.3.2 技术描述层
定义2技术描述层由情境属性、技术属性、领域属性组成。其中情境属性和技术属性通过BERT-BiLSTM结合CRF的命名实体识别方法提取,领域属性(IPC分类号)从专利网站获得。
实体识别方法是一种从非结构化文本中提取特定类型词的方法,如人名、地名等。该方法通过BIO序列标注对专利文本进行逐字标注,以B和I分别标注需要类型词的首字和非首字,以O标注其他无关的词。将标记好的文本通过BERT映射为词向量并作为BiLSTM的输入,通过神经网络的不断训练自动提取句子特征,最后以CRF层为预测结果添加约束,保证预测的精度。
(1)定义3专利的情境属性是由专利知识的应用情境术语组成。根据专利数据对知识情境描述的情境要素进行适当调整,选择问题、任务、知识资源、设计对象、地点五个主要素。专利中背景技术介绍了当前的技术空白和技术现状,发明内容包含了专利技术功效、实现目标和应用的物理环境。权力要求介绍了所需的机器设备、生产资料和产品装置。因此,问题维度可以映射到专利的背景技术,任务和地点维度可以映射到专利的发明内容,知识资源和设计对象映射到专利的权力要求中。其专利知识情境模型如表3所示。从专利中提取知识应用场景,表示为:

表3 专利知识情境模型及位置Table 3 Patent knowledge situation model and location

S1,S2,…,S n代表专利中知识情境术语。
(2)定义4专利摘要中包含了所使用的技术原理,从专利摘要中提取专利技术术语以表示专利的技术属性,例如太阳能、激光切割、高能脉冲等。技术术语体现专利实现功能的技术原理,表示为:

T1,T2,…,T n代表专利中的技术术语。
(3)定义5领域属性是规范引入的国际专利分类(IPC)信息。IPC是基于专利的不同应用领域的层次分类系统,分为部、大类、小类、组四个层次。每个层次都有其相应的域名描述信息。表示为:

其中,S代表部,C代表大类,subC代表小类,G代表组。
3.3.3 详细描述层
定义5详细描述层包含专利的显性信息和说明书中的实施方式。这些信息可以直接从专利搜索网站直接获取。设计者可以详细查看该专利的法律状态,产品的实例应用等,帮助设计者更具体地理解专利。
3.4 设计问题空间到专利知识空间的相似度匹配
匹配过程如图9所示,在产品概念设计中,根据需求系统工程师确定系统的不同功能,对于每个功能,都定义一个功能子系统,结合当前设计者的知识情境将设计问题抽象表征为设计问题空间。例如,存在一个“设计道路桥梁除雪机”的设计问题,其中一个子功能为清除道路上的积雪。积雪根据功能特性可以表示为固体,通过分析采用“清除固体”作为该设计问题的功能基,并给出当前设计问题的知识情境。其中功能基之间的映射为关键词检索,知识情境相似度是通过之前神经网络训练将情境术语表示为词向量,利用余弦相似度公式计算设计问题空间和专利知识空间情境术语的相似度,计算公式如式(11)所示:
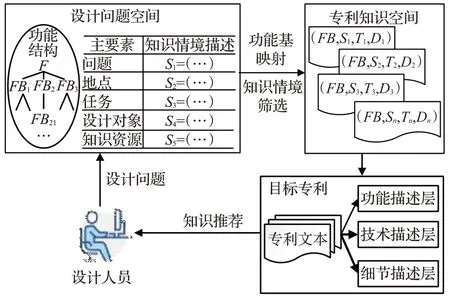
图9 需求-专利空间映射过程Fig.9 Demand-patent space mapping process
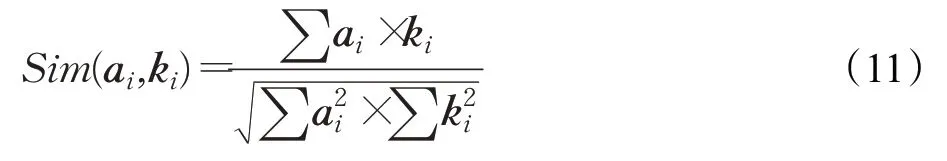
其中,a i、k i分别为设计问题空间和专利知识空间的情境术语词向量。Sim(a i,k i)代表相似度。当相似度大于阈值认为该专利可以解决当前设计问题,阈值需根据实际情况进行确定。
通过知识情境和功能基检索专利知识空间的专利,搜索到“一种多功能清淤机(CN201821880967.3)”。实现利用功能基和知识情境实现从设计问题空间到专利知识空间的匹配。
3.5 专利文本的聚类与评估
通过功能基和知识情境可以在专利数据库中搜索大量的相关专利,但是从各个应用领域中选择合适的专利将浪费大量的时间和精力。因此,需要对检索的相关专利进行进一步的评估,以推荐适当的专利给设计者。
首先将检索后的结果根据专利的技术属性将技术相似的专利采用K-means进行聚类,每个类别形成一个专利集群,其中包含的技术是相似的,设计者只需要阅读每个专利集群的技术术词即可了解整个集群。集群内的专利根据情境相似度进行排序,将检索到的具有相似技术属性的专利分组推荐给设计人员。然后根据领域属性的IPC信息引入成熟性、新颖性、可扩展性对专利集群进行评估和排序,如图10所示。
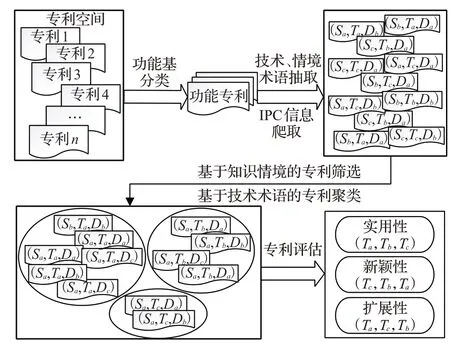
图10 专利聚类和评估过程Fig.10 Patent clustering and evaluation process
在专利集群评估中Verhoeven等人[14]使用IPC分类号和引用信息来衡量技术的新颖性。在产品设计和开发中,不仅要考虑技术的创新性还要考虑市场应用的前景。当前发明或实用新型专利的申请需具备新颖性、创造性、实用性,本文参考上述专利申请条件提出成熟性、新颖性、可扩展性三种评价指标,方便设计者针对不同设计问题选择相应的评估指标对专利技术进行评价。为了减弱聚类数K的选择对评价指标的影响,对所有结果进行归一化处理。
定义6成熟性是指技术越成熟,越有可能应用于其他领域。成熟度指数应该与集群内专利应用域数量和专利数量成正比,它成熟性计算公式为:

定义7新颖性是指该技术越特殊,对该技术应用的专利就越少。越是新颖性高的技术,其申请专利的数量和应用域数量就越少,新颖性计算公式为:

定义8可扩展性是为了探索其潜在的应用领域和发展方向。更好的技术可扩展性表明该技术涉及多个领域。一项扩展性好的技术往往应用在多个领域,但可能该技术的专利申请可能不容易找到,可扩展性计算公式为:

其中,d k是第k个专利技术集群包含的专利应用域的数量。n k是第k个专利技术集群中专利数量。D是所有集群中专利应用域的总数。N是所有专利技术集群中的专利总数。d k D表示第k个技术的应用域比重。n k N表示第k个技术的申请数量比重。式(12)中的M k越高,技术成熟性越高,同样式(13)、(14)中的S k、E k越高,技术的新颖性和可扩展性越高。
针对不同的设计问题,设计者用不同的指标对专利集群进行评价。为了调整或更新现有的结构以满足最终功能的要求,选择成熟性较高的专利进行产品设计。如果设计任务是在特定领域改进结构的某个组成部分,则可以选择新颖性作为评价标准。在设计新产品时,选择扩展性来评估专利集群,扩展潜在的应用领域。
4 实例验证
为了验证本文提出的专利知识推荐模型的可行性,以桥梁冰雪清除装置设计进行实例验证。通过将传统的基于关键词检索和本文提出的方法进行对比,并根据专利技术集群生成四种清除积雪的设计方案,验证本文提出的专利知识推荐模型在跨应用领域推荐专利知识方面的有效性和可行性。
4.1 专利数据获取及处理
本文在专利商业网站(incopat)中下载50 000条发明专利数据。本文使用的专利数据包括标题、摘要、说明书和权力要求等,采用jieba分词对专利数据进行分词,去除停用词,以便进行更深入的信息分析。
4.2 设计问题空间的构建
在寒冷地区,大雪和低气温的情况比较普遍。积雪在道路桥梁上会造成堆积和结冰影响行车安全的问题。目前除冰方式主要是人工洒融雪剂或借助机械设备完成。但由于人工清理有被车撞到的危险,且融雪剂会污染环境、清雪车的清雪结构简单清雪不彻底,对于冰面和已经压实的雪清理效果不好。因此,有必要设计一种有效、安全的除冰设备。
通过分析“如何去除道路桥梁的冰雪”设计问题,其功能基的主要类别是“分离”,第二类别是“除去材料”,第三类别是“清除固体”,其知识情境如表4所示。通过以上分析构建设计问题空间。

表4 设计知识情境描述Table 4 Design knowledge situation description
4.3 专利知识空间构建
4.3.1 功能描述层
(1)数据准备
本文选择两个数据集对TG-TCI算法进行验证。数据1为专利“标题+摘要”数据,共50 000条。根据功能基对2 000篇专利文本进行人工标注和分类,按照9∶1的比例分为训练集、测试集,选取其他没有贴上标签的18 000项专利作为未标记样本集对分类器进行二次训练。其他30 000条专利根据训练好的分类器对进行功能基标记,文本数据集标注分布情况如表5所示。在本文中,仅基于功能结构的一级分类为例进行开发,此外,该方法可以通过全面的分类器轻松扩展到所有功能基础级别。数据2为THUCNews新闻数据集种的10万条新闻标题,文本长度在20~30之间,一共10个类别,每个类别10 000条。

表5 数据集分布Table 5 Data set distribution
(2)评价指标
将标记的专利文本语料集通过TG-TCI半监督文本分类方法训练基分类器,将专利根据功能基分类。在这项研究中,准确性是检索结果中相关专利的部分,而召回率是实际检索到的相关专利总量的部分。专利数量如此之多,以至于设计者不需要查看所有专利,在这个模型中只考虑准确率的影响。准确率是指预测为该类别且正确的样本数TP与预测为该类别的样本总数TP+FP的比值,公式如下:

(3)算法有效性分析
为了验证本文提出TG-TCI模型的有效性,本文首先使用数据1对比单通道和双通道分类模型的分类效果,再使用数据2与当前基于分歧的半监督文本分类方法的重要成果做对比,说明本文模型的有效性。
单通道模型采用BERT对文本进行特征建模,使用标记样本集对KNN、SVM、Naive Bayes构成的基分类组进行训练,训练好之后对未标记样本集进行标注,将投票一致的样本补入标记样本集对基分类器组二次训练,最后对待分类样本集进行标注。另一个单通道模型采用Word2vec对文本进行特征建模,其余与上述相同。其中按照数据集的5%、10%、20%、30%分别作为标记数据集,比较三组模型的效果,实验进行5次取平均值,效果如图11所示。
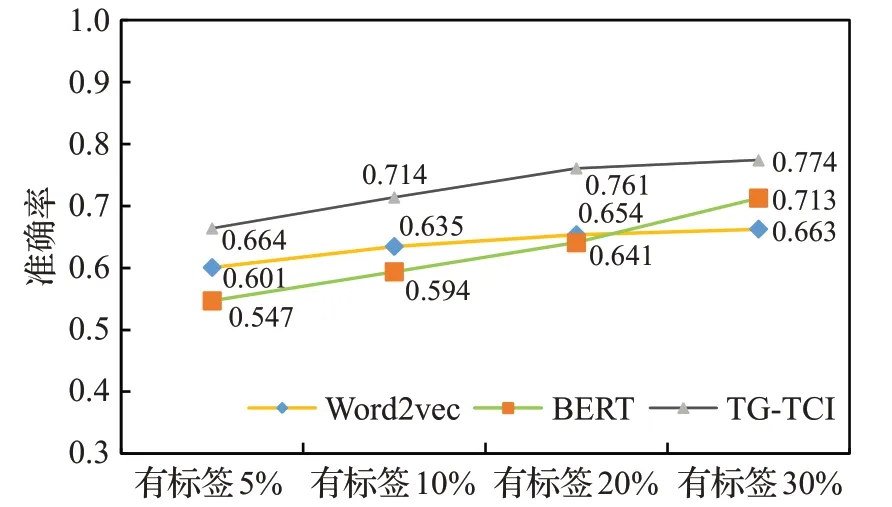
图11 单通道与双通道算法分类准确率对比Fig.11 Single-channel and dual-channel accuracy comparison
由图11可知,单独使用Word2vec和BERT的单通道模型在标记数据集占比5%情况下准确率均低于本文提出的TG-TCI算法,随着标记数据占比的增加,各模型准确率逐渐增加,但单通道模型始终不如TG-TCI算法,验证了使用Word2vec和BERT两种方法结合的方式能够有效地学习同一文本的不同信息,形成样本之间的分歧,对算法准确率有积极的影响,并验证自然语言技术实现专利功能知识的自动提取具有可行性。
本文进一步地将TG-TCI算法与传统的基于分歧的算法进行对比,对比的算法有Co-training[27]、Tri-training[28]、改进Tri-training[29]三种模型。本文引用文献[30]提出的精度差值(precision difference,PD)作为新的评价指标,将半监督分类模型的分类精度与对应的有监督分类模型分类精度的差值的绝对值大小评估算法的有效性,如公式(16)所示:accuracy(SC)为有监督的准确率;accuracy(SSC)为半监督分类的准确率。其中半监督模型在标记数据集占比20%的条件下进行。每组实验分别进行5次取平均值,各模型准确率和PD值如图12所示。
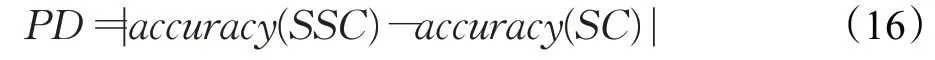
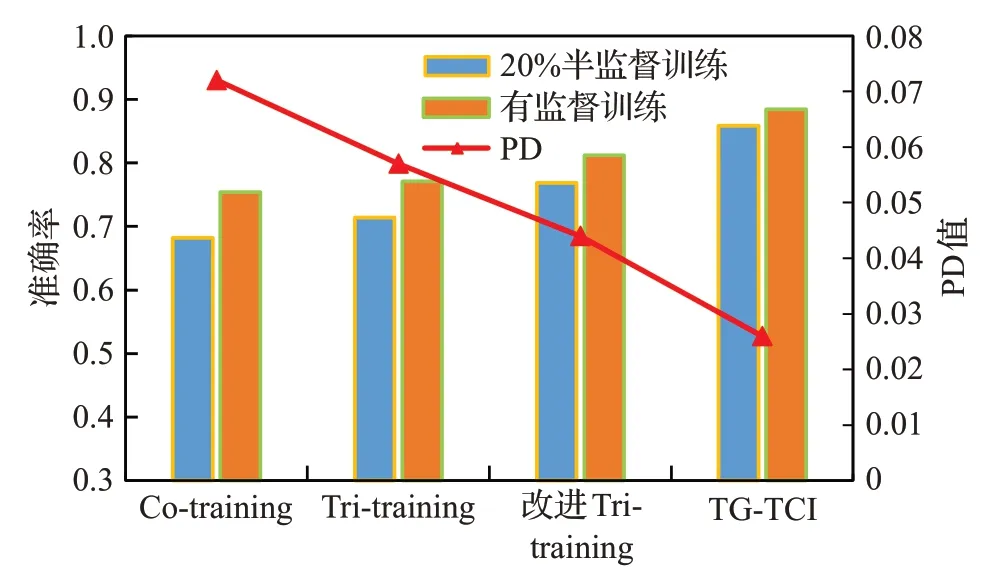
图12 算法准确率对比Fig.12 Algorithm accuracy comparison
可以看出本文提出的TG-TCI半监督算法在半监督和有监督两种方式中分类准确率均优于其他半监督分类算法,且PD值也小于其他算法,说明本文提出TGTCI模型更接近半监督学习的最优效果,有效地证明了TG-TCI算法可以更好地应用到标记样本少或人工标记难度大的半监督文本分类任务中。
(4)算法复杂度分析
算法有效性和算法复杂度是评价算法的两个重要指标。因此,在数据经过预处理后,本文对比TG-TCI模型与传统分歧半监督模型的训练时间,对算法时间复杂度进行分析,训练时间如表6所示。
训练时间实验在单机下进行,实验平台为Windows 10 64位操作系统,CPU为Intel®Core™i7-8150H,显卡为GTX1660S,物理内存为16 GB。由表6得知TG-TCI算法效率略低于改进Tri-training算法,这是因为本文算法采用了stacking集成方式,对每个基分类器需进行三折交叉验证。但其他算法需要对参数花费大量时间进行验证,TG-TCI算法无需花费过多时间对参数进行调整也有很好的效果,相比于传统的基于分歧的半监督算法更适用于标记样本少或人工标记难度大的半监督文本分类任务中。
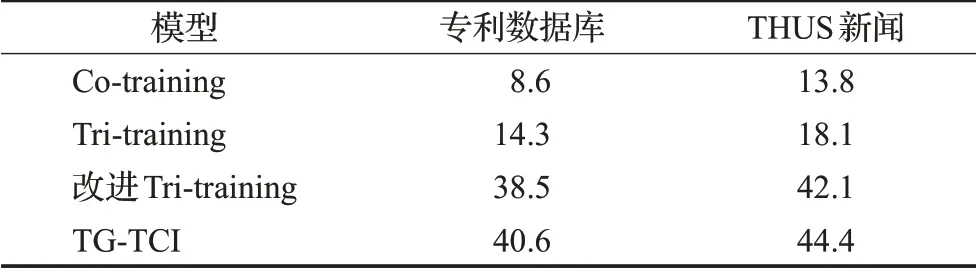
表6 各模型算法训练时长Table 6 Training duration of each model algorithm min
(5)重要参数的影响分析
本文提出的TG-TCI半监督文本分类算法中主要参数包含基分类器SVM中的惩罚参数C和KNN中的K值。本文使用数据1和数据2对这些参数进行进一步的实验,研究其对于分类结果的影响。
首先固定KNN中的K值,对C值进行调整,分析C对算法精度的影响,K值的实验分析过程与上述相同,实验图如图13所示。
由图13可知,C值和K值过大或过小会影响算法的准确性,在C值在400~600之间,K的个数在6的时候,最终TG-TCI算法的预测结果可以取得最高的精度,保证了最佳的整体分类性能。
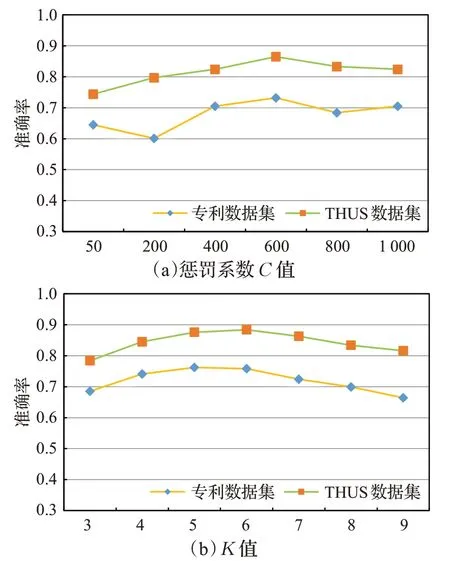
图13 C值、K值对分类结果的影响Fig.13 Influence of C and K on classification results
4.3.2 技术描述层
对专利中的情境术语和技术术语进行BIO标注,将标记好的专利样本集通过BERT-BiLSTM-CRF的方法训练出一个判断模型,利用该模型从专利文本中抽取情境属性和技术属性,领域属性(IPC)直接从网站中提取,为之后对专利的聚类和评估做准备。结合功能描述层和详细描述层,专利知识空间表示如图14所示。
图14 专利知识空间表示实例Fig.14 Patent knowledge space representation example
4.4 设计问题空间到专利知识空间的相似度匹配
根据上述分析对设计问题空间的构建,利用功能基和知识需求情境在专利知识空间中检索专利,检索流程如图15所示。并且为了验证文本提出的专利知识推荐模型可以有效地推荐跨应用领域的专利知识,使用“清除固体”作为关键词在专利网站(incopat)进行检索。图16显示并比较了前10名、前50名、前100名检索到专利应用域的数量。
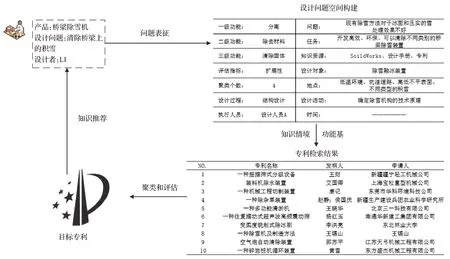
图15 专利知识推荐过程Fig.15 Patent knowledge recommendation process
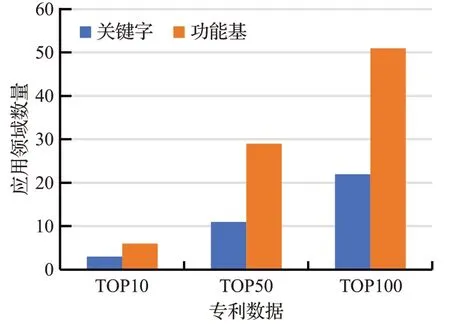
图16 两种检索方法的专利应用领域数量Fig.16 Two search methods patent domain quantity
对于前10名,关键词检索的结果包括三个应用域(B01D33、B08B9、E02B15),功能基检索包括6个应用域(E01H5、G05B19、A23L1、F16K1、C02F1、B61K9)。前50名和前100名,本文提出的检索方法明显优于传统关键字检索方法。因此,在本文的专利知识推荐模型之后,跨领域专利检索效率显著提高。
4.5 专利聚类和评估
检索后的专利需要进一步地聚类和评估。首先基于专利的技术术语对专利文本进行聚类,设计人员可以主动选择专利集群的个数。本文选择专利集群数量为4,聚类图如图17所示,专利被分为四个集群,每个专利集群呈现不同的技术,如表7所示。设计者只需要阅读每个集群的术语列表就可以快速理解专利集群的技术信息,减轻设计者的认知负担。之后设计者可以根据设计需求从各类专利技术集群中选择合适的专利进行产品创新设计。通过分析可以得到如图18的四种设计方案。
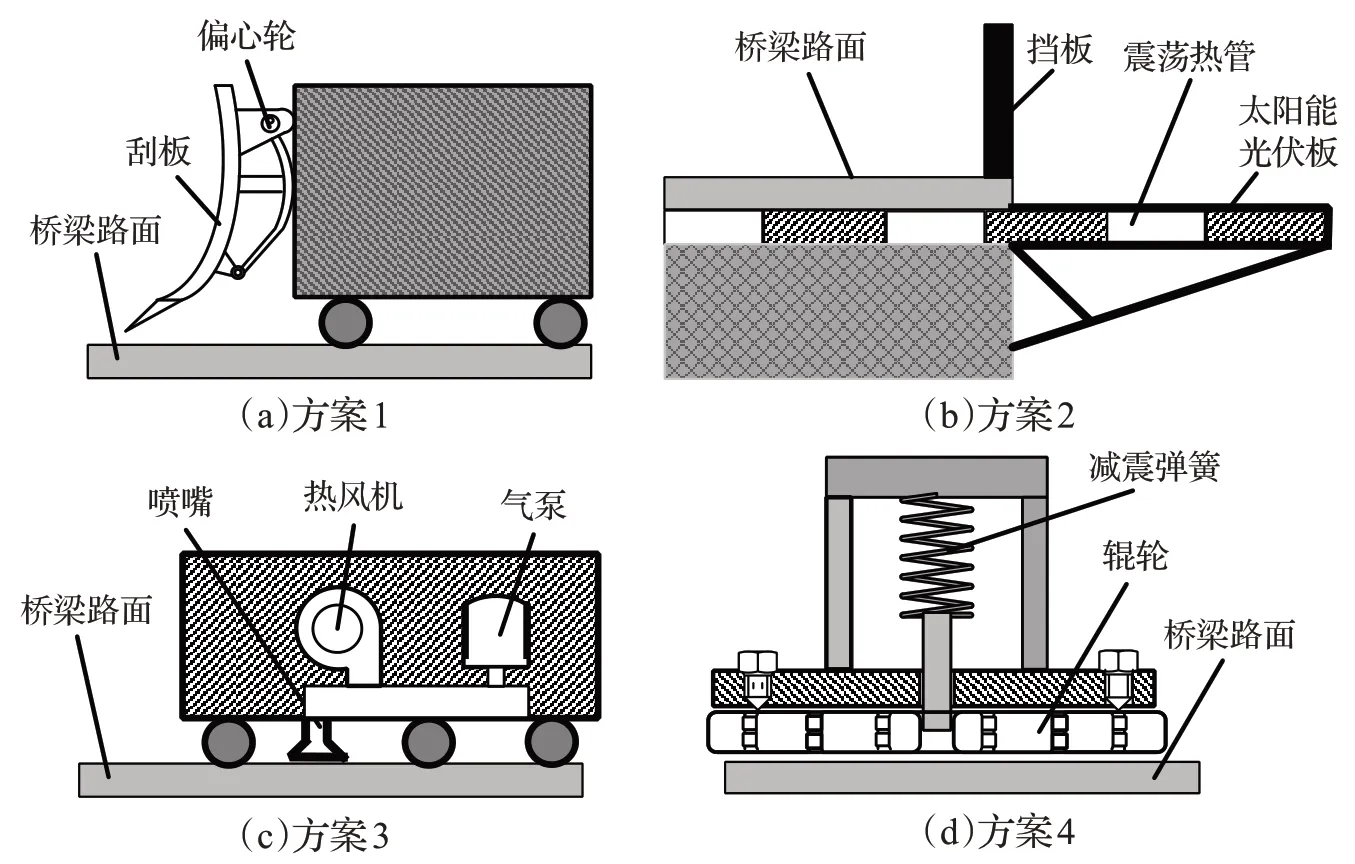
图18 设计方案概念图Fig.18 Design plan conceptual drawing

表7 专利聚类结果Table 7 Patent clustering results
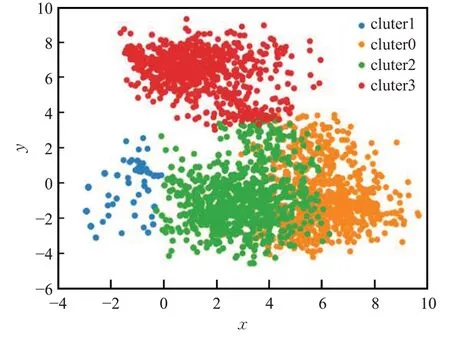
图17 聚类效果展示Fig.17 Clustering effect display
方案1该集群技术术语为偏心轮、振动、高能脉冲、刮板等。找到名为“帮助从铸件上除去砂型”的专利。该专利通过高能脉冲激励铸膜,使铸膜破碎。于是可以得到方案1,利用偏心轮产生振动震碎道路桥梁上的结冰,并通过刮板进行除雪。
方案2该集群技术术语为太阳能、震荡热管、热利用等。找到名为“一种太阳能与中深层地热能复合融雪化冰系统”的专利。该专利采用太阳能供热系统提供热水,融化地面的冰。得到方案2利用太阳能为震荡热管提供热能,对道路进行加热,以达到除雪目的。
方案3该集群技术术语为压缩空气、热风机、气泵、喷嘴等。找到名为“铸件清砂修用气铲”的专利,该专利通过压缩空气去除铸件上的砂膜。于是方案3为通过压缩空气释放强力气流,剥离吹除冰层,在道路上形成干燥空气循环的局部环境,以进行道路除雪。
方案4该集群技术术语为辊轮、研磨、滚压、减震弹簧等。找到名为“新型钢管外壁除锈机”的专利,该专利通过辊轮滚动对钢管外壁进行除锈。得到方案4为通过电机使辊轮滚动,对结冰路面进行研磨,并与减震弹簧连接,对弧形、高低不平路面进行除雪。
最后根据领域属性评价了每个专利集群的成熟性、新颖性和扩展性,评估结果如表8所示,结果表明聚类1成熟度最高,聚类3新颖性最高,聚类4可扩展性最高,设计者可以根据设计问题选择不同的评价指标对技术进行评估,其映射结果如图15所示。在设计者寻求实现某一功能的技术时,突破了不同应用领域的局限性。
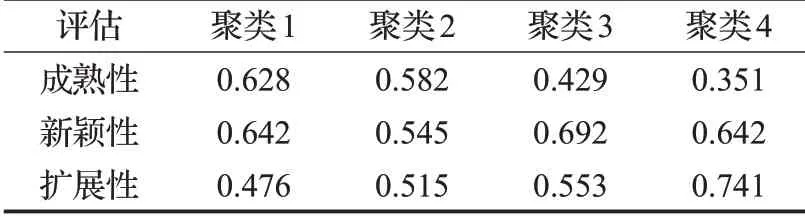
表8 专利聚类结果Table 8 Patent cluster evaluation results
4.6 模型有效性的定性分析
从道路桥梁清雪机的概念设计可以看出,通过对设计问题进行归一化表达,设计者可以得到更多具有相同功能基和相似知识情境的跨领域专利文本。同时本文构建的三层专利知识空间结构既包含了专利的功能信息也包含了其技术信息和详细信息。便于帮助设计者突破本领域的限制,丰富设计者的知识空间,从而产生更多具有创新性的概念解决方案。
5 结束语
为了更好地满足设计者知识多样性的需求,本文提出了一种基于深度学习的专利知识推荐模型框架。主要贡献总结为三点:(1)基于功能基和知识情境的设计问题表征。本文对产品功能和知识情境分别建模,在产品设计流程中引入功能基和知识情境对设计问题进行标准化表达,对比实验证明本文方法可以在更大范围找到更多的解决方案。(2)自动提取专利知识并构建表示模型。本文提出TG-TCI算法根据功能基从本文分类角度提取专利功能信息,利用实体识别方法提取专利情境、技术术词构建专利知识空间,便于设计者快速理解当前专利。(3)多指标专利评估方法。本文利用K-means算法对相似专利进行聚类,并提出成熟性、新颖性、扩展性三种指标对专利聚类进行评价,方便设计者选择合适的评价指标满足自己的设计需求,提高设计知识重用率。
但仍存在一些问题需要解决。首先本文的领域属性是根据专利的IPC分类来定义,具有局限性。其次,本文仅对专利一级功能进行分类提取,之后需要根据二级类别、三级类别进行进一步分类。最后专利知识表示需要行更深入的分析,专业技术术语和知识情境专业性较强,需要更高的知识背景。今后将进一步深入研究领域之间的知识转移,完善功能词典,改善专利功能分类的准确性,并且进一步完善专利内容研究,需要更深入地开发专利知识,更全面地发现潜在的领域知识,进而更智能化地实现设计者的知识需求。
猜你喜欢
水运工程(2022年7期)2022-07-29
计算机系统应用(2021年2期)2021-02-23
山东工艺美术学院学报(2020年2期)2020-06-13
电子技术与软件工程(2019年18期)2019-11-18
山东工艺美术学院学报(2019年2期)2019-05-16
商周刊(2018年22期)2018-11-02
电子技术与软件工程(2017年14期)2017-09-08
电脑知识与技术(2016年33期)2017-03-21
航天返回与遥感(2014年5期)2014-07-31
中国发明与专利(2007年7期)2007-08-09
