
分析师社交圈、 利益冲突与研究报告文本信息①
2022-08-08 06:25刘亚辉尹玉刚
管理科学学报 2022年3期
刘亚辉, 黄 凯, 尹玉刚, 汪 勇
(西南财经大学金融学院, 成都 611130)
0 引 言
证券分析师在抑制信息不对称、促进价格的信息发现过程中起到了不可忽视的作用[1-4].尤其近年来随着更多高学历、行业经验丰富甚至具有海外经历者的加入,证券分析师队伍不断成长和壮大. 但分析师是否有效发挥了信息中介作用?现有文献并未得出一致结论. 大部分研究认为研究报告(下文简称为“研报”)中存在普遍的乐观偏差,并将其归因于分析师所面临的利益冲突(1)对分析师的研究集中在受雇于券商的卖方分析师,券商与承销上市公司、 证券投资基金之间的利益关联很容易通过雇佣关系传导 给分析师,对分析师的独立性与客观性形成压力,形成利益冲突. 分析师面临的利益冲突主要有3种,一是来自所属券商的压力,不 能发表对客户(或投资者)不利的报告;二是分析师出于对自身职业生涯的考虑;三是分析师与被研究公司之间存在利益共谋.[5-9]. 也有学者认为分析师向市场提供了显著的增量信息,在抑制信息不对称、改善信息环境中发挥了不可替代的作用[10-13].
现有文献大多以盈余预测及荐股评级等量化指标来衡量研报的信息价值[14-16]. 然而,作为分析师基于公开及私有信息做出的结论性预测,这些量化指标无法涵盖所有信息,且不具有及时的可验证性. 更为重要的是从分析师解读信息到做出盈余预测和荐股评级的过程是个“黑匣子”,更容易受制于利益漩涡而失去客观性(2)在研报发布初投资者是无法验证这些量化指标的客观性的,只能在一段时间后通过市场表现或公司披露财报进行验证.[15]. 仅基于这些量化指标衡量研报信息价值可能有失偏颇. 作为研报更重要的组成部分,文字分析是分析师提供信息的重要载体,占据了研报的大部分篇幅(3)研报文字分析主要包括公司最近的业绩表现、发展战略、行业竞争力以及公司治理等方面的内容.. 相对于其他量化指标,它更多的是对客观事实的描述,并更受投资者关注(4)美国《机构投资者》对美国市场的调查显示,1998年以来投资者更注重研报的文本,例如在2010年~2011年, 受访者认为文本的重 要性排第5,而盈余预测排在第12位. 并且尽管很多金融数据库已经包含了研报中量化指标的数据,投资者每年花费在研报全文购 买上的资金仍高达数百万美元.. 但是囿于研报文本可得性、文本挖掘技术的发展等因素,分析师研报的相关文献却较少涉及文本信息[17].
中国是个关系型社会[18],在股市这个名利场更是如此. 无论研报的量化指标还是文字分析,都不可避免地受到分析师社交圈的影响. 在社会关系资本化的资本市场,“圈子”已然成为利益传输的重要桥梁[6, 9]. 对于分析师来说,“圈子”也是其获取私有信息的潜在途径[19, 20]. “圈子”在资本市场中的影响近年来不断受到学者们的关注. 现有对分析师社交圈的研究主要集中在商业关系上,例如券商与上市公司、证券投资基金之间的利益关联通过雇佣关系影响分析师的独立性[9]. 但是在错综复杂的人际关系中,同窗校友之情、共同调研之谊都是关系的重要内涵,与雇佣关系相比,这种私人关系对分析师来说更加平等,也具有更多的主动权和互动性[18].
因此,本文从增量文本信息和传统量化指标的双重视角较为全面地考察私人“圈子”对研报信息含量的影响. 以文本相似度代理研报所提供的增量信息,以量化指标的乐观偏差度量分析师对职业生涯的考量,进而较为全面地研究分析师在利益旋涡中的行为轨迹. 以文本相似度衡量增量信息的方法在财经新闻以及财务报告的文本分析中已被较多的学者采用[21-23],将该方法应用在研报中. 通过手工搜集研报全文内容,利用余弦相似度计算出每份研报与该公司前3个月所有研报文本相似度的均值作为该研报所提供的增量信息. 文本相似度越低,该研报信息含量越高(5)之所以用文本相似度度量分析师所提供的关于上市公司的特有信息,是因为除去文本相似度被广泛运用的科学性以外, 对于投资者来 说,研报有价值的部分在于研报文本中与其他分析师所提供的不一样的基本面等分析. 对于文本中与其他分析师所提供的一样的广为 人知的共同信息,不但私有信息含量很少,且这一共同信息可能正如董大勇等[50]所述那样, 仅仅是研报信息的“相互借鉴”, 并未提供 增量信息.. 同时,运用社会网络分析的方法,计算出分析师在基金经理中拥有的人脉资源(“圈子”). 将 “圈子”的范围限制在基金经理之内,是因为基金经理有《新财富》明星分析师的投票权,而入选《新财富》是分析师职业生涯的终极目标;并且基金经理通常拥有其所持股票的私有信息,分析师可以获取“圈子”内基金经理的私有信息而得到信息优势,进而体现在研报的文本内容中(6)基金经理的私有信息不一定是从上市公司获得的内幕信息,更多的是关于公司更为真实的基本面信息..
基于2006年~2016年的样本数据,发现“圈子”能够显著提高分析师研报的文本信息含量,其原因是作为获取私有信息的潜在途径,“圈子”增加了分析师的相对信息优势[19]. 进一步研究表明,这一优势主要体现在“圈子”内基金经理持股的研报上,证实了分析师通过“圈子”获取私有信息的推论. 作为利益冲突形成的土壤,广泛的社交圈在使分析师有获取信息的优势同时,也使其更容易陷入利益漩涡之中. 拥有较广社交圈的分析师总体上发布了更高的荐股评级,而这种系统的乐观性是由“圈子”内基金经理持股所致.
高荐股评级与分析师利益如何关联?作为重要的外部激励,入选《新财富》是分析师职业生涯的重大跨越[6]. “圈子”能显著提升入选概率,且这一提升作用主要通过分析师对“圈子”内基金经理持股发布更高的荐股评级实现. 对研报文本信息而言,虽然对当选概率没有显著影响,但信息含量高的研报能够引起投资者对该股票显著且持续的关注.
入选《新财富》,分析师在财富与声誉(投资者关注)均显著提升之后,分析师对二者的权衡会发生怎样的改变?结果表明,分析师当选后对“圈子”内外荐股评级的差异显著降低. 这是因为当选后随着地位提高,他们无需再以高评级取悦基金经理. 与“圈子”外相比,当选后“圈子”内股票的研报信息含量显著更高,这一方面是因为分析师更加注重自身声誉,倾向于提供更多的特质信息,另一方面是分析师在当选后获取私有信息的能力进一步增强.
本文的主要贡献体现在两个方面. 第一,不同于现有文献以盈余预测准确度、荐股评级等较为主观的量化指标衡量研报的信息价值,而以较为客观的研报文本为标的,运用文本挖掘中的相似度算法,为研报信息含量的评估提供新的方法;第二,“圈子”产生的利益冲突对分析师行为的影响仍是学术界较为前沿的话题,仅有的一些研究也局限在分析师通过券商而产生的外部利益关联上,通过研究分析师私人关系,为“圈子”与分析师利益冲突的研究提供了新的证据与补充.
1 文献综述与研究假设
1.1 研报文本分析回顾
在信息传递中扮演关键角色的分析师受到投资者和学术界的普遍关注[14,15]. 分析师一方面广泛搜集有价值的公开信息,另一方面通过实地调研等其他途径获得私有信息,并对这些信息进行专业解读,以研报的形式传递到市场[25-29]. 在我国资本市场处于新兴加转轨、信息环境有待改善且投资者以散户为主的背景下,分析师在抑制信息不对称、促进价格发现方面被寄予更高的期望. 作为分析师信息传递的重要载体,研报成为评价其表现的重要依据. 个股研报常常对公司近期的业绩表现、发展战略、行业竞争力以及公司治理等方面的信息进行初步分析,进而得出盈余预测、荐股评级和目标价位等量化指标. 囿于大量研报全文的不可得性及文本挖掘技术的发展,现有研究多局限于研报的量化指标,对文本内容较少涉及.
然而,正如Tsao[30]所言,“荐股评级和目标价位是分析师研报中无关痛痒的部分,真正有价值的是产生这些结论的逻辑分析与细节”(7)原文是“Stock ratings and price targets are just the skin and bones of analysts’ research. The meat of such reports is in the analysis, detail, and tone”..盈余预测、荐股评级和目标价位等量化指标是分析师基于基本面信息得出的结论性建议,但从信息到结论的推导是个“黑匣子”,难以避免地掺杂着分析师的主观倾向;而文字分析更多的是对客观事实的描述,包含了更多的增量信息. Asquith等[31]对1 126份研报全文手工构建情绪指标,发现在控制荐股评级后,这一指标对研报发布日未来5天收益率仍有显著解释力,但其样本量过小,回归中用到的观测数仅有193个,结论缺乏普适性. Twedt和Rees[32]通过词性标注对2 057份深度研报文本构建量化指标,也发现了研报文本对收益率的显著影响,而小样本导致的稳健性问题也削弱了这一研究的代表性. Huang等[17]首次在大样本范围内对研报文本进行分析,发现研报文本比盈余预测、荐股评级等包含了更多的信息,且文本信息对公司盈利有更长期的预测力. Huang等[33]进一步发现分析师在研报文字中对管理层电话会议内容进行了信息挖掘,而投资者对这部分挖掘的信息更为关注. 伊志宏等[34]利用文本分析技术,发现研报文本中的负面情感倾向能够降低股价暴跌风险. 马黎珺等[35]通过机器学习对分析师研报进行了文本分析,发现前瞻性语句的情感倾向与研报发布后的市场反应显著正相关. 本文虽然同样关注文本内容,但侧重的是研报信息的“增量”而非“倾向”,是对前述文献的补充与完善.
文本相似度被广泛应用在基于内容的推荐系统、信息检索及论文重复率检测等领域,在财经文本中的应用也初露端倪. 其原理是用文本之间的相似程度代理信息差异,相似度越高,则二者的信息差异越小. 利用这一思想,Hoberg和Philips[21]发现年报中产品描述章节文本相似度高的企业相互并购后获得了更好的协同效应. 类似的,以年报中产品描述章节的文本相似度为上市公司重新划分行业,Hoberg和Philips[22]发现这种新行业划分能更好地解释公司盈利能力和销售增长等个体特征,新的行业风险因子也具有更强的解释力. Bushman等[23]发现银行年报的文本相似度与其系统风险正相关,并且文本相似度高的银行之间的风险存在较高的联动性.
本文以每份研报与前3个月目标公司所有研报文本相似度的均值作为其信息含量的代理,这一方面为衡量分析师研报信息提供了新的角度,得以更全面地研究分析师信息中介角色的发挥,另一方面扩展了文本挖掘技术在财经文本领域的应用.
1.2 “圈子”与研报文本信息
“社会关系资本化,资本市场江湖化”[17],关系在资本市场的影响不容忽视. 研究的第一个问题是分析师在基金经理中的“圈子”对研报文本信息和荐股评级的影响. 将“圈子”的范围限制在基金经理之内是因为他们有《新财富》明星分析师的投票权,而入选《新财富》在很大程度上是分析师职业生涯成功的标志,并且基金经理通常拥有其所持股票的私有信息,分析师可以获取“圈子”内基金经理的私有信息而得到信息优势,进而体现在研报的文本内容中. “圈子”包括校友关系、调研关系和地域关系3个层次. 校友关系是形成社交网络的重要纽带,在资本市场中,校友间的利益共享、信息共享已被学者发现并证实[18]. 调研亦是分析师获取信息的重要渠道,有两层含义,一是调研者之间很可能已经具有紧密的联系;二是“交个朋友多条路”,调研时新建立的关系也很可能是新合作的开始. 而工作地点同城且同一个区,会由于地理的临近而为社交关系的形成提供很大的潜在可能,因此,将地域关系也纳入“圈子”的范畴. 借助社会网络分析方法,计算每个分析师在基金经理中“圈子”(Network)的大小.
社会关系对分析师具有双重影响. 一方面它是资本市场信息扩散的重要渠道之一,分析师可以籍此取得信息优势. Horton和Serafeim[20]用社会网络分析法对10 508名分析师和42 376名公司高管构建校友关系网络,发现网络中心度高的分析师盈余预测更准确,并且失业率更低. Cohen等[19]发现校友关系是分析师获取私有信息的重要渠道,与上市公司高管有校友关系的分析师取得了显著更高的荐股超额收益. 程博和潘飞[36]也发现分析师与CEO之间的校友关系增加了分析师的信息获取优势. Cohen等[37]对校友网络的进一步研究发现,基金经理的持仓集中于与高管有校友关系的上市公司股票,且有关系的持仓组合收益比无关系的持仓组合收益率每年高出7.8%,这部分超额收益主要来自于上市公司重大事项公布前后,间接证实了基金经理通过校友关系获得了信息优势.
本文则用文本相似度度量研报信息含量,研究“圈子”的影响,并提出如下假设:
H1a“圈子”越广,分析师研报文本信息含量越高.
H1b分析师对“圈子”内基金经理持股的研报文本信息含量较“圈子”外研报更高.
另一方面,“圈子”在赋予分析师信息优势的同时,也影响着研报的独立性与客观性. “圈子”内私有信息的获取不是无偿的,分析师向基金经理付出的成本是更乐观的荐股评级. Tan等[8]发现对于基金经理重仓的股票,分析师公开发布的研报乐观偏差较大,但未公开的研报不存在乐观偏差,间接证明了分析师与基金经理之间可能存在的利益共谋. 李志生等[38]研究发现证券分析师在媒体上发布的荐股行为中存在内幕交易和利益输送,使得财富向机构投资者转移. Yin[9]通过将受雇于基金公司控股股东或发起人的分析师与这些基金公司进行配对,直接研究了分析师与关联基金经理之间的利益互动,发现分析师倾向于对关联基金公司持有的股票发布较高的荐股评级,而基金经理则在乐观评级发布后显著减少了持股数量. 上述研究集中在雇佣引起的商业关系上,证实了分析师对与其具有商业关联的股票发布了较高的荐股评级,这一逻辑同样适用于私人关系,即分析师与基金经理的“圈子”. 基金经理对其持股的信息优势和《新财富》明星分析师投票权,有足够的诱惑力吸引分析师用较高的荐股评级与基金经理达成协议. 据此本文提出如下假设:
H2a“圈子”越广,分析师荐股评级越高.
H2b分析师对“圈子”内基金经理持股的荐股评级较“圈子”外高.
入选《新财富》能极大促进分析师职业生涯的发展及个人财富的积累,因此竞争异常激烈. 基金经理投票的评选机制是“圈子”效应发挥作用的温床. Emery和Li[39]把竞选明星分析师称为“人气竞赛”,他们发现市场认可度是当选最重要的因素. 吴偎立等[40]对我国《新财富》明星分析师评选进行研究,发现获奖前明星分析师与普通分析师的研报信息含量无显著差异,影响获奖概率的不是提供信息的多寡而是其曝光率及所属券商的市场地位. 这些研究都表明能否当选更重要的是基金经理对分析师的认可度. 在同等条件下,分析师更容易获得“圈子”内基金经理的选票,“圈子”越广的分析师越容易当选. 然而,分析师获得基金经理的选票和私有信息不是无偿的,他们需要为“圈子”内基金经理持股提供更高的荐股评级. 同时,校友关系、调研关系和地域关系只是名义上的,实质利益同盟的形成离不开对“圈子”的维护. 只有当分析师确实为基金经理提供了较高的荐股评级时,才能得到基金经理的投票回报. 从分析师对“圈子”内、外基金经理持股的荐股评级差异和跟踪偏好两个方面衡量分析师对“圈子”的维护. 因此,本文提出假设:
H3“圈子”会提升分析师入选《新财富》的概率,这种提升效应形成的途径是分析师对“圈子”内、外基金经理持股的荐股评级差异和跟踪偏好.
在普遍认识到研报量化指标存在乐观偏差的情况下,投资者更关注文本信息. 在我国股票市场也存在类似的情况,一是Wind、东方财富、国泰安和中国研究数据服务平台等金融数据库投入大量资金从券商研究所购买卖方分析师的研报全文,并将其以收费的方式向用户限量提供;二是虽然中美股市在投资者结构、市场交易制度安排方面有明显差异,但投资者对信息获取的诉求是一致的,在分析师研报的量化指标存在普遍乐观偏差的环境下,投资者更看重研报的文本信息. 在与中国的机构投资者和中小投资者的交流中,他们也表达了对研报文本信息的重视. 据此本文提出假设:
H4研报文本信息含量越高,投资者对目标公司的关注度越高.
当选明星分析师后,其利益和地位得到了极大提高[6],分析师与“圈子”内基金经理的交流也随之改变. 一方面,分析师当选后无须再一味地以高评级取悦基金经理;另一方面,明星分析师获取信息的能力增强,且更注重文本信息含量对自身声誉的影响. 因此,分析师当选后对利益与自身声誉的动态权衡必然发生改变(8)高质量的研报文字能够提高投资者对分析师的认可度,进而影响到对研报量化指标的置信程度,并且无论是从分析师职业操守的角度,还是从监 管层对研报信息的质量要求,分析师都有动力提供较高质量的文字分析.. 据此提出假设:
H5明星分析师当选后对“圈子”内、外股票的荐股评级差异降低,“圈子”内股票研报信息含量提高.
2 研究设计
2.1 研究样本与数据来源
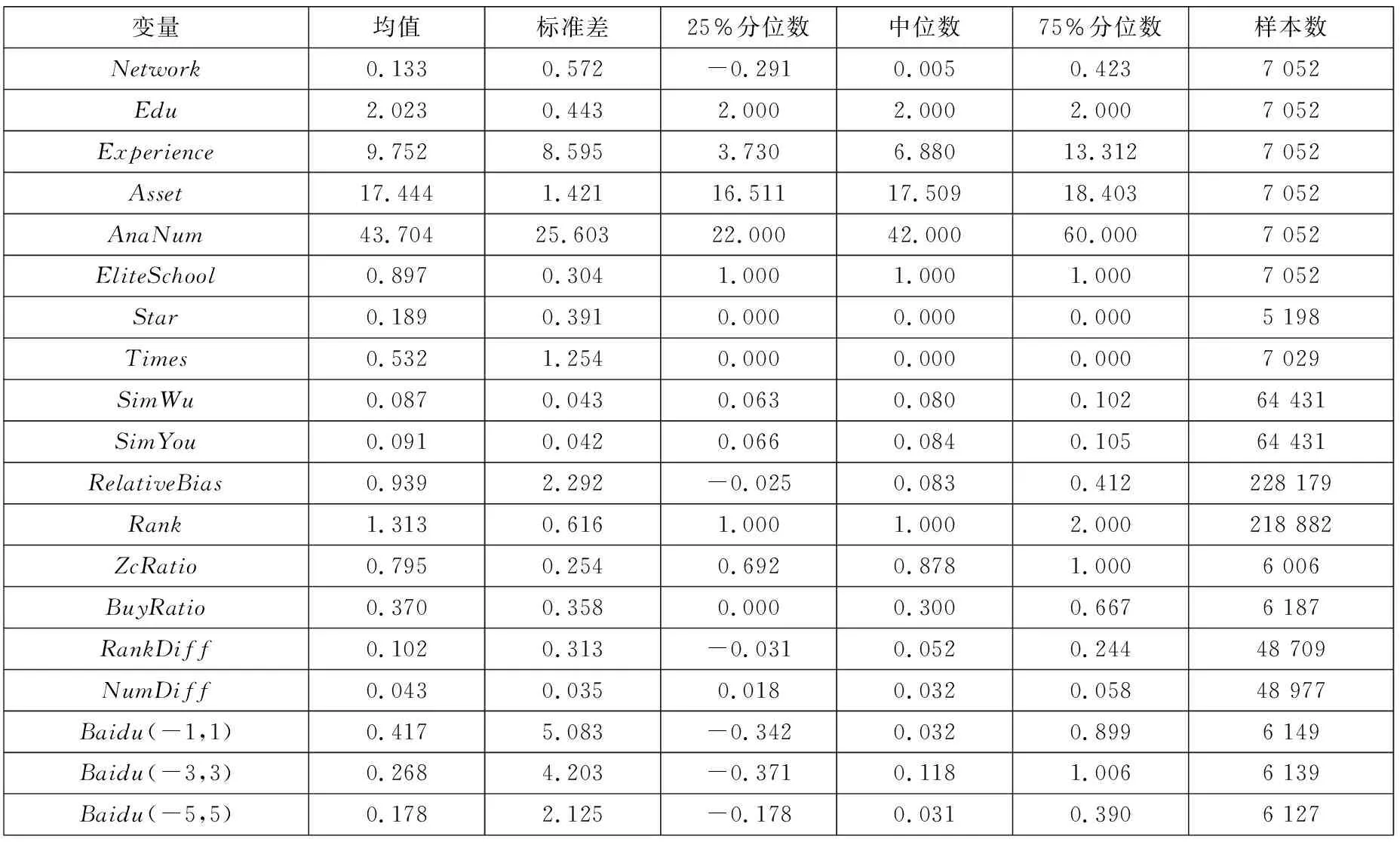
数据有3个来源. 在构建分析师社交圈时,分析师和基金经理的学历、毕业院校、所属券商等个人特质数据从中国研究数据服务平台(CNRDS)获得,由于样本期内(2006年~2016年)部分院校出现更名、合并等现象,统一将院校名称改为现用名称,并以此构建校友圈;分析师和基金经理调研数据亦来自CNRDS. 分析师所属券商的办公地址从全国企业信用信息公示系统手动搜集,并以此构建地域圈. 研报全文数据来自和讯财经,时间跨度为2006-01~2016-12,共168 184份原始研报;当研报为团队撰写时,将该研报视为每一团队成员的单独成果,分离后共有193 097个分析师—研报数据, 将这些研报按标的公司、分析师姓名、所属券商和发布日期与国泰安数据库(CSMAR)中的研报量化指标匹配后, 最终得到64 431个研究样本. 其他控制变量数据来自CSMAR数据库.
2.2 关键指标构建
分析师社交圈为分析师在基金经理中拥有的人脉资源. 与申宇等[18]不同,对社交圈从深度和广度两个层面进行了扩展,在深度上除了考虑直接关系,还加入了间接关系;在广度上把“圈子”的范畴在校友圈之外加入了调研圈和地域圈.
“圈子”的计算依赖于社会网络分析技术[41],连接矩阵(adjacent matrix)是其常用的数据形式(见表1).
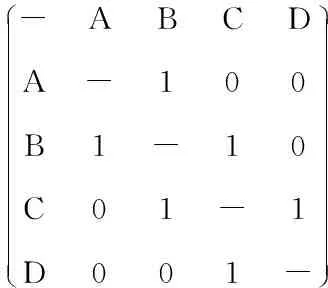
表1 一个连接矩阵Table 1 An adjacent matrix
如果A和B曾经是校友,则赋值为1,否则为0. 如果A和B在同一时间调研了同一家上市公司,则认为二者之间存在调研关系;如果A和B所属券商的办公地在同一个城市的同一个区,则二者存在地域临近关系(9)部分券商存在双总部或多总部的情形,这可能导致基于注册地计算的地域圈不精确,在稳健性检验中详细考察并排除了这种可能性对本文结论的影响.. 这样就构建了3个仅由0和1组成的对称矩阵,三者加总,得到初始矩阵(有权).
“朋友的朋友亦是朋友”. 间接关系也属于“圈子”的范畴,并且与直接关系相比,其强度势必减弱. 为将间接关系和直接关系强度统一加总计算,采用Yin和Liu[42]提出的指数衰减法对间接关系进行处理. 具体来说,假设A和B没有直接关系(仅考虑直接关系时二者的权重为0),但A和B同时与C有直接关系,即A和B通过C建立了间接关系,C是A和B的中介(10)分析师和基金经理的本科、硕士、博士阶段可能不在同一学校,因此存在这种交叉校友的现象.. 将A和B的间接关系进行指数衰减(具体算法见附录A).
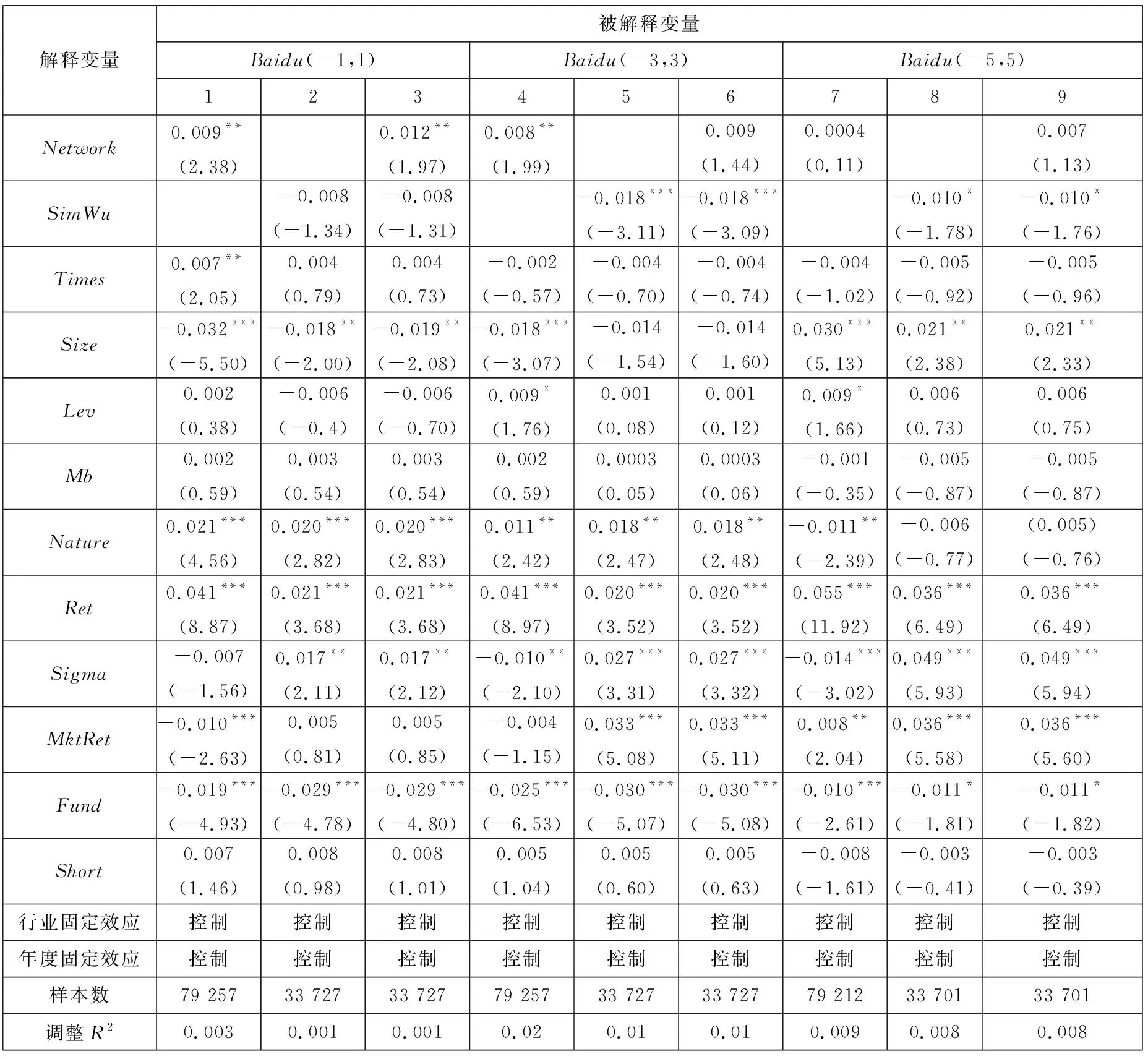
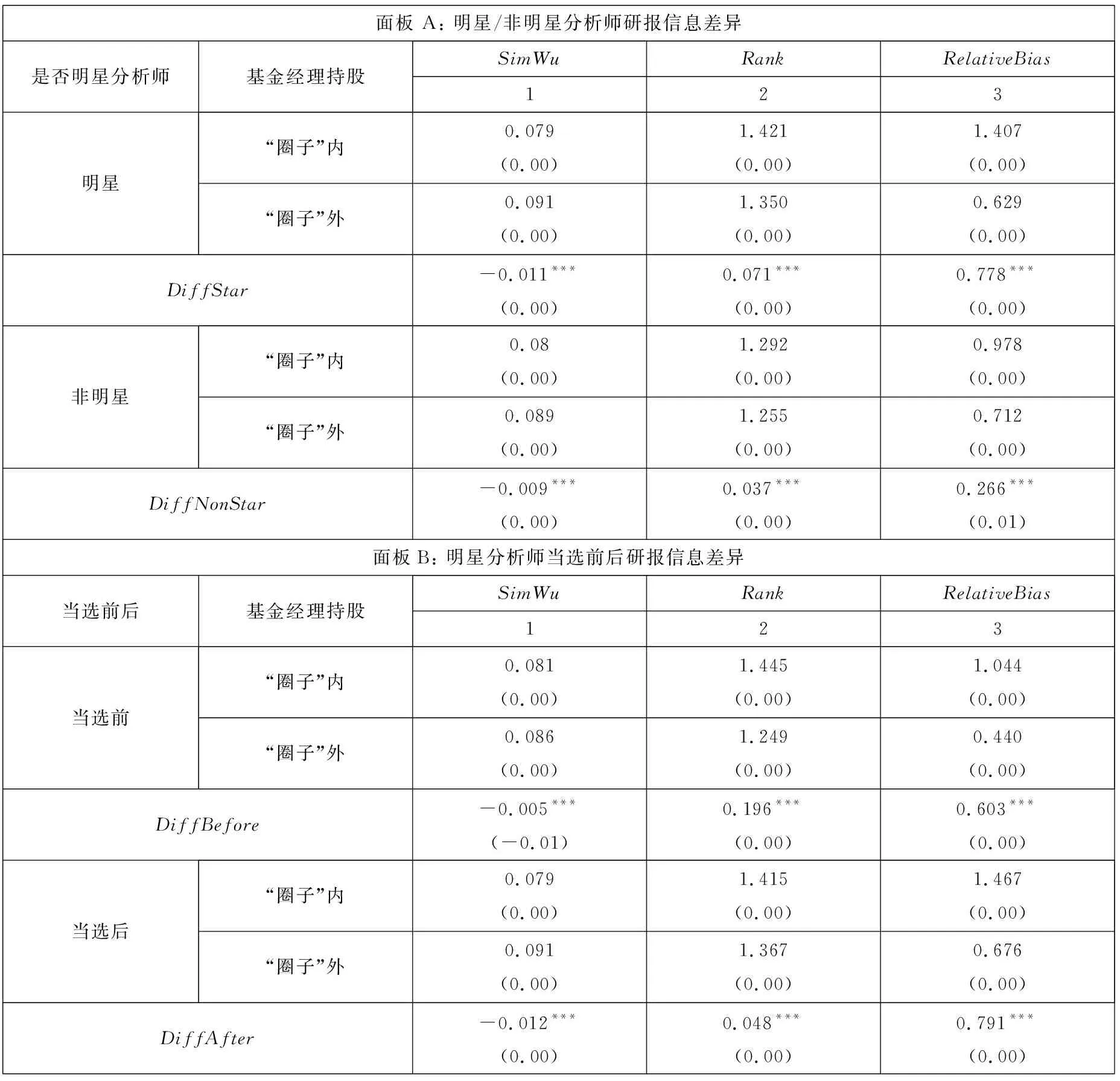
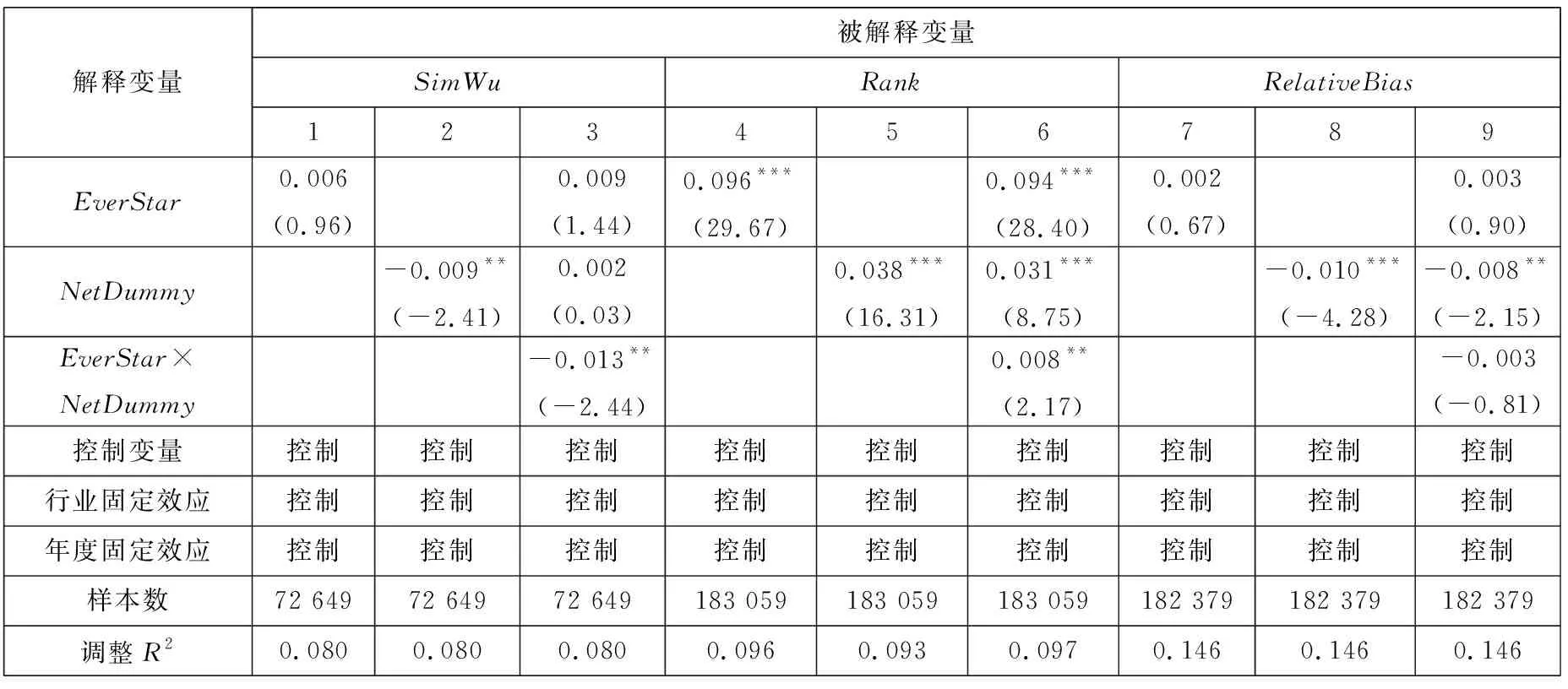
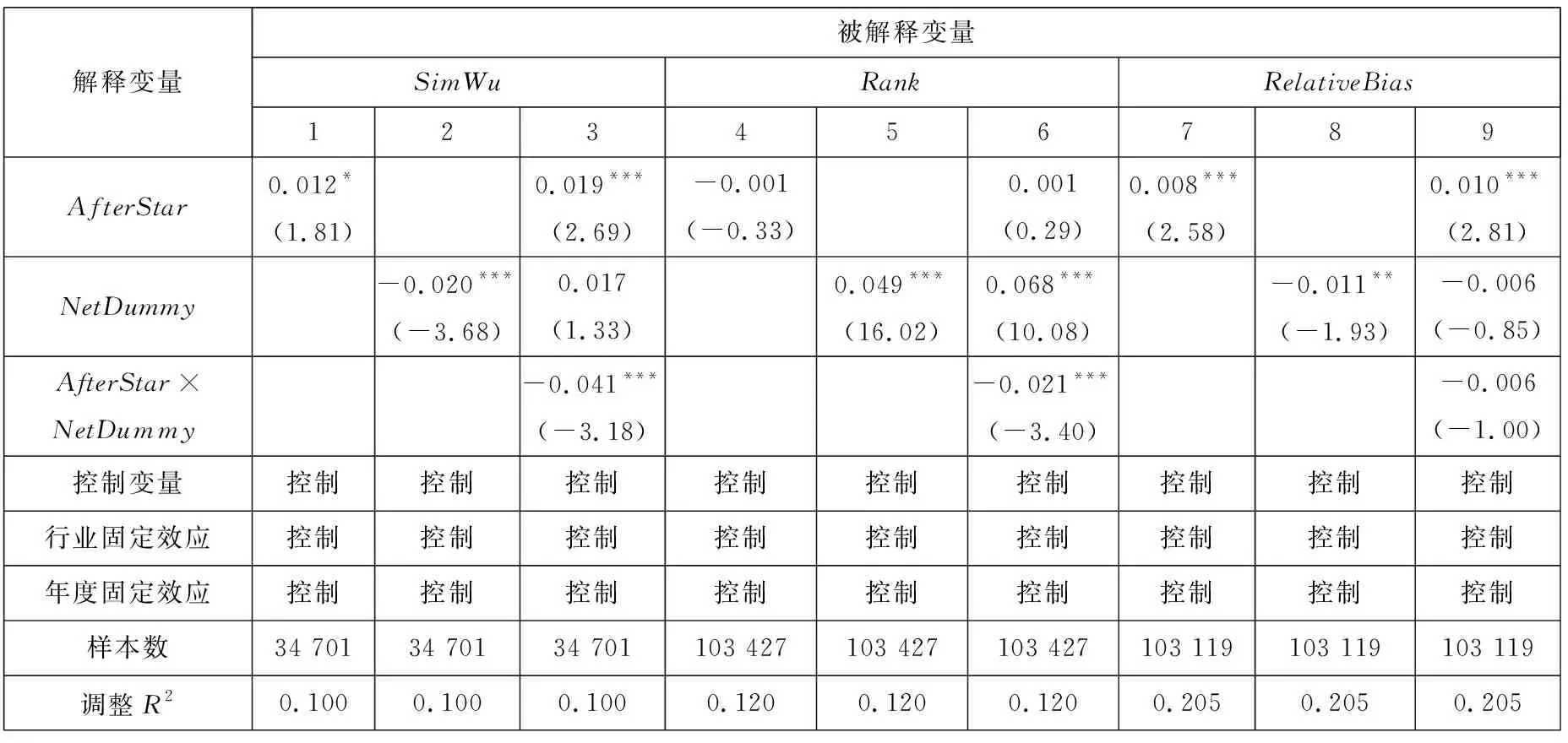
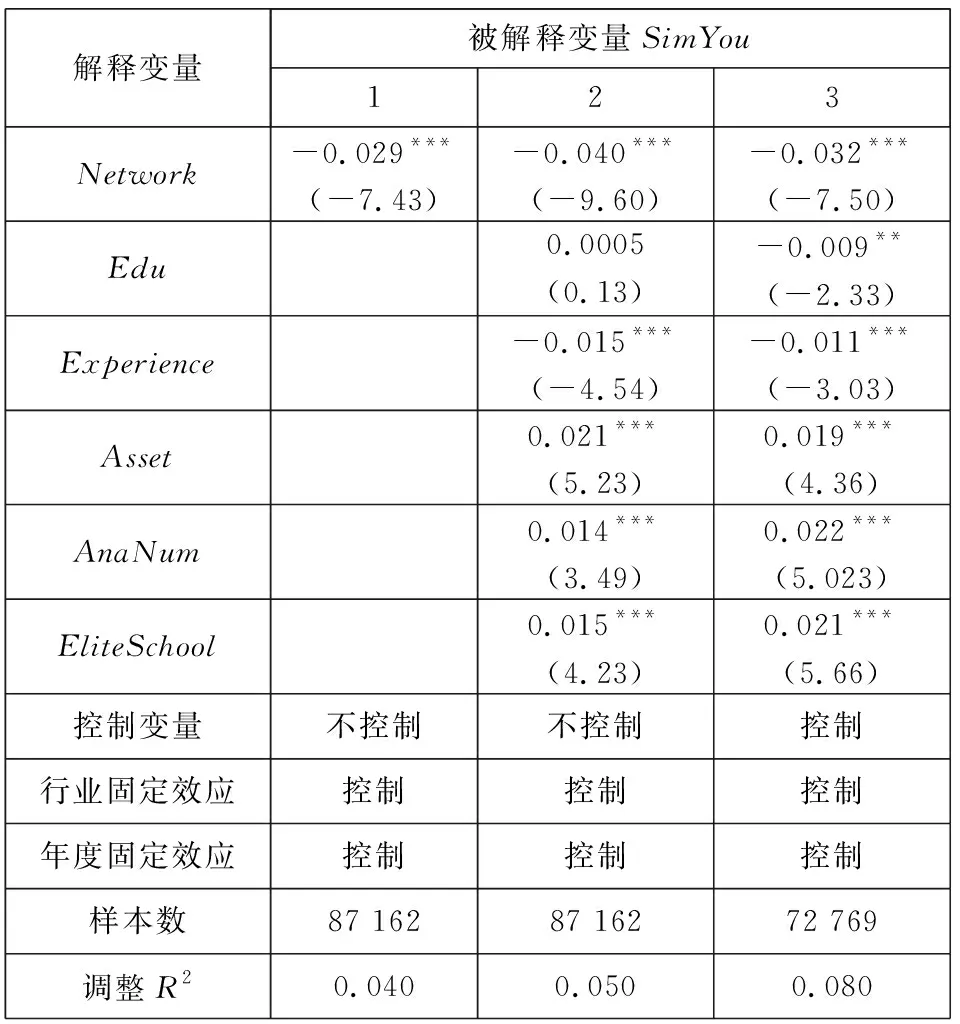
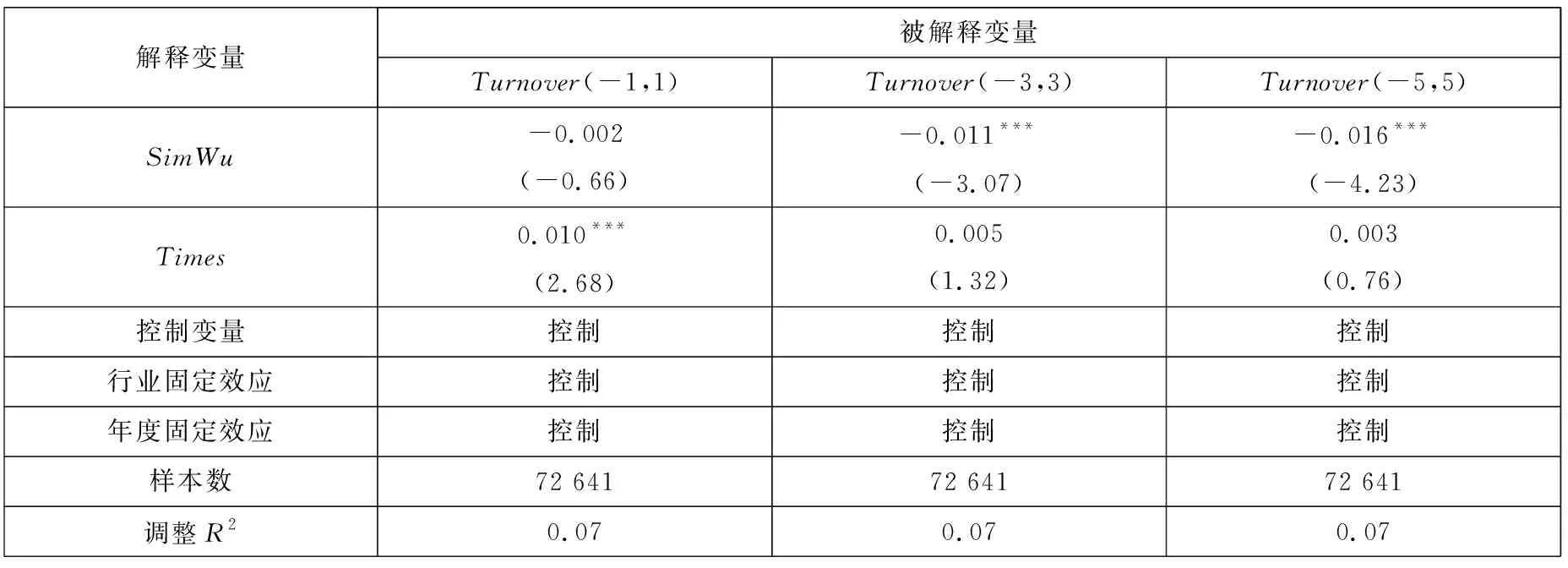
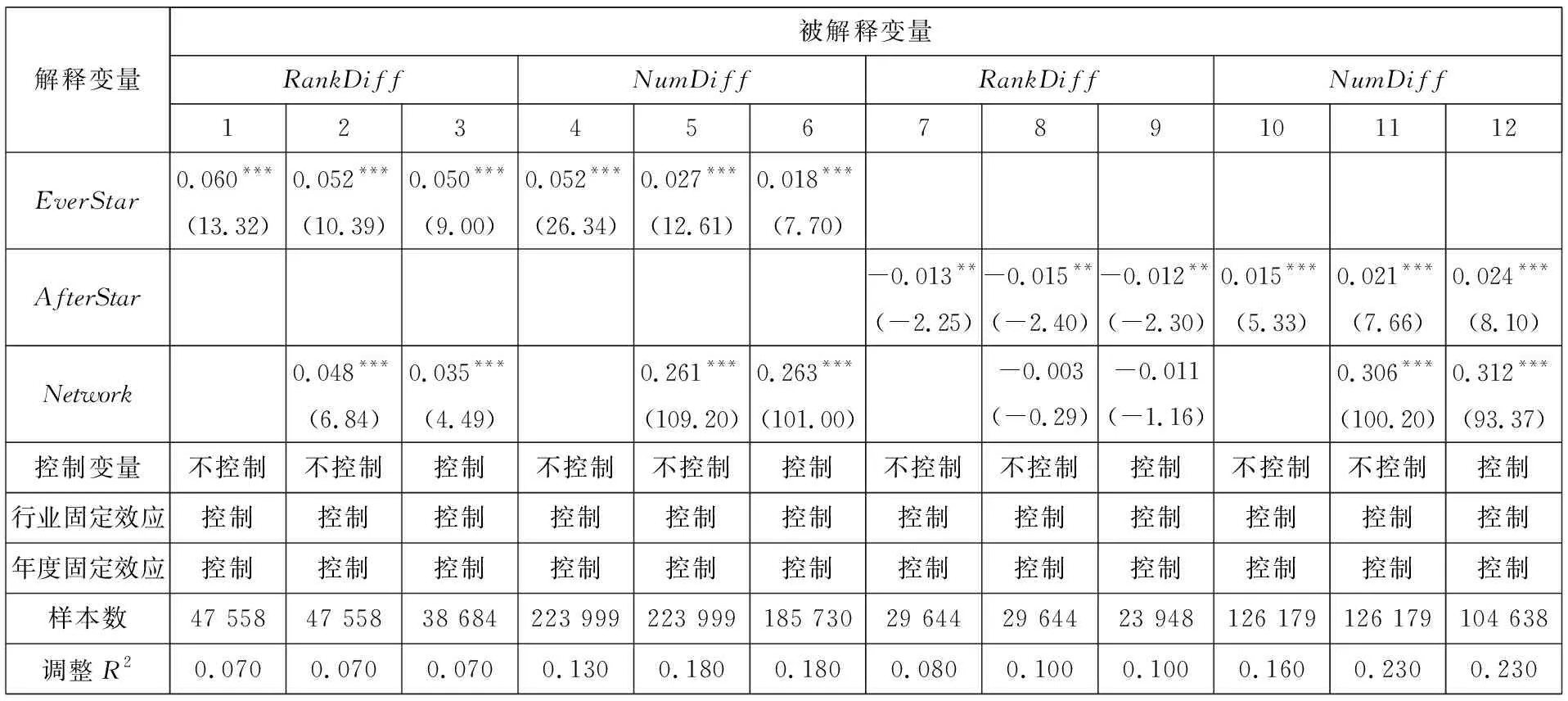
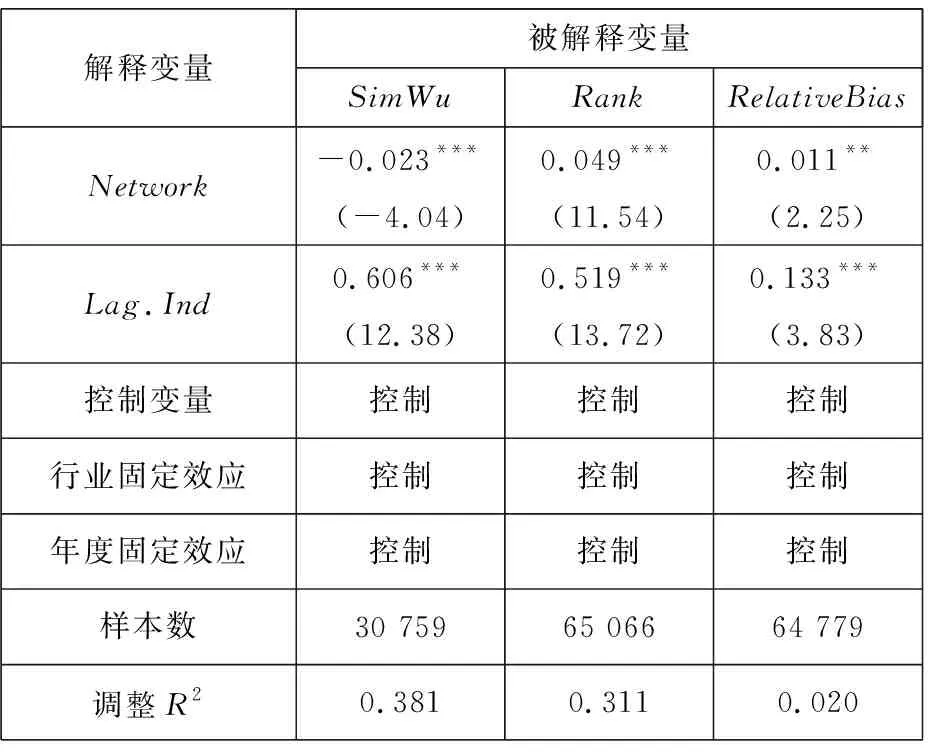
连接矩阵中包括分析师和基金经理两类节点,而《新财富》明星分析师评选时只有基金经理才有投票权,二者不能等同而论,因此对传统的社会网络分析方法进行改进. 具体方法是对所有的节点按照类型进行排序,例如矩阵共有n=n1+n2个节点,n1个节点为分析师,n2个节点为基金经理. 这样排序之后可以根据每个连线的坐标确定其关系类型,例如某个点的坐标为(x,y),x>n1,y 基于综合考虑了直接和间接关系的连接矩阵,用社会网络分析中的点度中心性来衡量分析师“圈子”的大小. 在对矩阵根据分析师和基金经理进行排序后,分析师i(i (1) 式中E(i,j)为分析师i和基金经理j的关系值,即排序后连接矩阵中元素(i,j)的值.Networki越大,表示该分析师在基金经理中拥有越广的人脉. 尽管分析师的校友关系、地域关系在不同年份保持稳定,但其调研圈会有较大波动,同时每年均有离职和新进的分析师和基金经理,这将导致分析师的“圈子”大小有较大的年度差异. 因此在样本期内的每一年度,都按照上述方法计算分析师“圈子”的大小. 文本相似度为研报文本余弦相似度. 两个文本之间的余弦相似度计算主要分为分词、构建词向量、计算余弦夹角3个步骤. 分词是把研报文本拆分成词语,以进行更深入的分析. 相比英文分词,中文的分词更加复杂(11)英文以空格作为分词标记即可,但是中文分词需要完善的词汇库,词汇库应该尽可能的包含目标文本中所有的词汇.. Jieba是中文分词中最常用的工具,其自带的通用词汇库已较为完善(12)Jieba分词是国内团队开发的主要针对中文分词的开源项目,是目前最为流行的分词组件之一. Jieba可跨语言调用,本文用到的是 其R语言版本,该项目托管在github上,网址https://github.com/qinwf/jiebaR.. 考虑到研报属于财经文本,有较多的财经专业术语,将搜狗输入法官方推荐的“财经金融词汇大全”和“财务会计词汇大全”导入Jieba中,以进一步提高分词的准确性. 分词中另一个重要问题是对停用词的处理. 如果将停用词认为是噪音,则在分词时剔除之;如果认为停用词也是种信息,则保留之(13)停用词是指“的”、“了”、“吗”等没有实际意义的结构助词或语气词以及特殊符号,本文用到的是哈工大停用词表,网址为https:// github.com/chdd/weibo/blob/master/stopwords/哈工大停用词表.txt.. 考虑到过多的停用词意味着研报没有提供太多有价值的信息,所以将保留了停用词的文本相似度作为稳健性检验. 研报文本分词后要将每份研报向量化(14)基础文库是计算IDF必须用到的概念. 对某个词语,IDF指这个词语在该研报所属特定领域内的通用程度,基础文库就是这个“特 定领域”内所有研报的集合. 本文中研报的基础文库是研报目标公司所属行业的所有研报集合.. 向量化的核心问题是每个词语对应的数值应该是多少? 采用最常用的TF-IDF方法,其中TF(text frequency)指某一词语在这份研报中出现的次数,IDF指基础文库中包含该词语的文档数(15)在附录B中,从两个方面验证了以文本相似度代理增量信息的有效性. 一是根据已有研究,给出负面荐股评级的研报中包含了更多 的新信息. 与此一致,本文发现卖空或减持评级的研报文本相似度显著更低. 二是现有文献发现,当股票收益率出现跳跃时,说明股 票受到了价值相关的新信息冲击. 以月度收益率向下跳跃代理负面信息冲击,发现与同一年度其他月份的均值相比,当月研报的文 本相似度显著更低;而盈余预测准确度无显著差异;荐股评级反而更高. 进一步地,在以文本相似度为被解释变量的回归中,代理收 益率是否出现向下跳跃的哑变量系数显著为负; 而以盈余预测准确度和荐股评级为被解释变量时, 哑变量的系数并不显著 (或为 正). 表明本文的研报文本相似度能够更好地捕捉这一信息冲击.. TF越大,说明该词语在这份研报中越重要;IDF越大,说明在基础文库中,该词语是个较为通用的词语,没有特质信息含量,因此权重越小. 对于一篇研报中的某个词语,其TF-IDF最终的计算公式为 (2) 式中ft,d是该词语在研报d中出现的频率;nd是该研报包含的词语总数;N是基础文库包含的研报份数;nt是基础文库中包含该词语的研报份数,较低的nt表明包含词语t研报份数较少,意味着该词代表了较高的特质信息. 向量化后的研报可以计算两两之间的相似度,即余弦夹角,计算公式为 (3) 式中A,B分别表示向量化之后的研报;cos(θ)表示A,B的余弦夹角;Ak表示向量A的第k个元素;Bk表示向量B的第k个元素;n为向量A,B的维度. 研报的余弦值越大,说明二者的夹角越小,两篇文档的相似度越高. 在计算出研报之间两两相似度之后,计算每一份研报与对应目标公司前3个月所有研报的相似度的均值,作为这篇研报的文本相似度. 如果在分词时剔除了停用词,变量为SimWu,如果保留了停用词,变量为SimYou. 文本相似度越高,则该研报提供的新信息越少. 市场关注度采用百度指数作为度量[43-45]. 百度是国内占有量最大的搜索引擎,自2010年3月谷歌宣布退出中国大陆市场后,2010年~2016年间百度占搜索引擎市场份额的70.17%,而即使在谷歌退出前的2009年~2010年也达到59.51%. 因此,选取百度搜索指数作为市场关注的代理具有较好的代表性. 百度指数值越大,说明该股票受到投资者的关注度越高. 其他变量构造见变量定义表2. 表2 主要变量定义Table 2 Definition of main variables 社交圈对分析师研报信息含量具有如下影响:一方面“圈子”(Network)拓展了私有信息的获取途径,分析师籍此能够向市场提供更多的增量文本信息(SimWu);另一方面“圈子”使分析师更容易陷入其独立性与职业发展追求的利益旋涡,降低其研报量化指标的客观性. 因此,以Network为核心解释变量,并综合现有文献中研报信息的其他相关因素,利用模型(4)来检验“圈子”对研报文本信息、盈余预测偏差以及荐股评级的影响 Qualityi,j,t=β0+β1Networki,t+β2Lag.Indi,j,t+β3Edui,t+β4Experiencei,t+β5Asseti,t+ (4) 国内外学者对当选明星分析师的影响因素进行了较为深入的研究[39,40]. 但是尚未有文献将“圈子”纳入模型,本文将Network作为核心解释变量引入如下logistic模型 (5) 建立如下模型 Xβi,t=β0+β1Networki,t+β2SimWui,t+β3RelativeBiasi,t+β4Ranki,t+β5Timesi,t+β6ZcRatioi,t+ β7BuyRatioi,t+β8Edui,t+β9Experiencei,t+β10Asseti,t+β11AnaNumi,t+β12EliteSchooli,t+εi,t (6) 利用模型(6)检验“圈子”以及文本相似度、荐股评级对当选明星分析师概率的影响. 除核心变量Network和研报质量(SimWu、RelativeBias、Rank)之外,参考吴偎立等[43],同时控制如下变量:评选前分析师累计获奖次数(Times);跟踪机构重仓股比例(ZcRatio)、买入评级占比(BuyRatio)、分析师学历(Edu)和是否名校毕业(EliteSchool)、从业时间(Experience)、所属券商规模(Asset)以及券商所属分析师数量 (AnaNum). 上述变量的计算方法见表 2. 建立如下模型 Xβi,t=β0+β1Networki,t+β2RankDiffi,t+β3NumDiffi,t+β4Ranki,t+β5Timesi,t+β6ZcRatioi,t+ β7BuyRatioi,t+β8Edui,t+β9Experiencei,t+β10Asseti,t+β11AnaNumi,t+β12EliteSchooli,t+εi,t (7) 利用模型(7)检验“圈子”以及荐股评级差异(RankDiff)、跟踪偏好差异(NumDiff)对当选概率的影响,之所以将RankDiff和NumDiff加入模型是因为Network仅是分析师潜在的关系,其在评选中作用的发挥依赖于分析师对该关系的维护,而“圈子”内外荐股评级差异和跟踪偏好差异是维护关系的重要手段. 其他控制变量的选取与模型(6)一致. 在分析师荐股评级等量化指标存在普遍乐观偏差的先验认知下,投资者更关注研报文本信息. 尹玉刚[46]发现投资者更关注明星分析师,而对分析师教育背景、经验、努力程度等影响研报质量的分析师特质信息关注度较低. 在控制上述已有文献中的变量后,Network、SimWu对投资者关注度是否有显著影响?采用和模型(4)一样的控制变量,用如下模型进行考察 (8) 式中Baidui,j,t是分析师i跟踪的上市公司j在研报发布窗口期内的搜索热度指标[42-44]. 同时,以异常换手率(Turnover)作为稳健性检验. 曾当选明星分析师和从未当选明星分析师对不同分析师而言是质的区别,一朝当选,名气与利益随之而来. 他们的研究报告信息有何不同?用如下模型来检验这一差异 Qualityi,j,t=β0+β1EverStari,t+β2NetDummyi,j,t+β3EverStari,t×NetDummyi,j,t+β4Timesi,t+β5Edui,t+ (9) 式中EverStari,t为在年度t之前分析师i是否曾当选明星分析师的虚拟变量,其他变量选取与模型(4)相同. 当选明星分析师后,其收入、地位以及人脉资源均得到巨大提升[6],此时分析师对利益与声誉的权衡有何不同?用如下模型来研究这一动态变化 Qualityi,j,t=β0+β1AfterStari,t+β2NetDummyi,j,t+β3AfterStari,t×NetDummyi,j,t+β4Timesi,t+β5Edui,t+ (10) 式中AfterStari,t为分析师i当选明星分析师前/后的虚拟变量,其他变量选取与模型(4)相同. 表3列示了主要变量的描述统计结果,从表中可以看出,在剔除个人信息(学历、经验等)缺失的数据后共有7 052个有效的分析师数据,其Network均值为0.133,标准差为0.572,中位数为0.005,说明分析师在基金经理中的人脉资源差异较大. 剔除研报作者信息缺失的数据后共有64 431个文本相似度的有效观测值,其中SimWu均值为0.087,标准差为0.043,中位数为0.080,离散程度和偏度较小.Rank的特征与前人研究一致,体现出较高的乐观偏差(均值为1.313),在75%分位数仍为买入评级,且标准差较小(0.616);BuyRatio均值达到0.370,呈左偏态(中位数0.300). 从跟踪上市公司的基金持股特征来看,ZcRatio均值为0.795,且分布离散程度低(标准差为0.254),中位数为0.878,呈现右偏态,说明分析师倾向于对基金重仓股发布研报.RankDiff的均值为0.102,说明分析师对“圈子”内持股普遍发布了较高的荐股评级. 表3 主要变量描述统计Table 3 Descriptive statistics of main variables 表4利用模型(4)分析了社交圈对分析师研报文本信息含量、相对预测偏差以及荐股评级的影响,其中Edui,t、EliteSchooli,t、Experiencei,t、Asseti,t以及AnaNumi,t等分析师特征的频率为年度,其他控制变量则在每次研报发布日进行更新. 注意到模型中解释变量之间的量纲不同,以原始数据直接回归将导致系数对量纲过于敏感,且不便于不同变量系数之间的对比. 为消除量纲差异以及系数的可比,常用的做法是Greenland等[47]提出的标准化回归方法. 其思路是先将被解释变量和所有自变量进行标准化,用标准化后的数据进行多元回归. 其回归的系数βi代表变量i变动1个标准差,被解释变量变动βi个标准差. 需要注意的是,虽然在模型中加入了前人发现的控制变量,仍无法穷尽被解释变量的所有影响因素,但可以合理地推断这些因素中相当的一部分不会随着时间推移而迅速消失. 因此,通过将被解释变量的一阶滞后项加入模型,能够从一定程度上更全面地控制这些因素对被解释变量的影响. 下文所有固定效应模型的实证分析均遵循此范式. 表4 分析师社交圈与研报信息含量关系分析Table 4 Analysis on the relationship between analysts’ social ties and information content in research reports 分析师的信息来源有两部分,上市公司披露的公开信息和分析师获得的私有信息[26]. 私有信息包括厂房设备维护、日常运营状况、公司管理水平等无须依法披露但与公司价值息息相关的信息. Cheng等[28]发现分析师通过调研活动获取了有价值的私有信息,并有更好的盈余预测及荐股表现,这一现象在重资产的行业(如传统制造业)中更为明显. 分析师获得私有信息的另一重要渠道为其“圈子”,即本文定义的社交圈. “圈子”广的分析师能够获得更多的私有信息,因此,其文本信息含量更高,体现为更低的文本相似度(表4第3列Network系数为-0.020,t值为-5.79),验证了上文提出的H1a. 分析师一方面通过“圈子”获得了更多的私有信息,另一方面也需要发布更乐观的荐股评级作为补偿. 表4第6列和第9列表明,“圈子”显著增加了分析师研报的荐股评级(Network系数为0.050,t值为20.74)和盈余预测乐观偏差(Network系数为0.005,t值为1.98),这与H2a一致. 表4整体上看,在控制了年度和行业固定效应后,无论是仅以“圈子”作为独立解释变量的单变量分析,还是逐渐加入其他控制变量后的多元回归分析,“圈子”对研报信息含量、盈余预测偏差和荐股评级的系数都符合前文假设. 表5和表6展示了logistic模型(模型(5))的实证结果. 出于自身职业生涯的考虑,分析师具有发布乐观荐股评级的倾向. Emery和Li[39]和吴偎立等[40]的研究都表明,高荐股评级能够帮助分析师当选. 与前人研究一致,表5第4列说明较高的荐股评级能够增加当选为明星分析师的概率(Rank系数为0.928,z值为3.71). 但是分析师研报的文本信息含量和盈余预测准确度对当选概率无显著影响(第2列SimWu系数为0.096;第3列RelativeBias系数为-0.039,均不显著). 表5 分析师社交圈、荐股评级与当选明星分析师概率Table 5 Analysts’ social ties, stock recommendations and probability of being a star analyst 分析师社交圈能够显著增加其当选为明星分析师的概率. “圈子”文化在中国由来已久,其在金融领域的作用逐渐受到学者的广泛关注[18-20]. 在基金经理投票的评选机制下,明星分析师评选更成了“圈子”发挥作用的温床:分析师更容易获得“圈子”内基金经理的选票,并为基金经理的持股发布高荐股评级. 表5第1列从实证上支持了这一推论,控制其他控制变量后,“圈子”对分析师当选的影响系数为0.182,并且在10%的置信水平上显著. 在控制了文本相似度、盈余预测偏差以及荐股评级后(第5列),“圈子”的系数增加到0.353,z统计量增加到2.30,并且荐股评级在加入“圈子”后不再显著,这说明相对于荐股评级,“圈子”是影响分析师当选更重要的因素. “圈子”为分析师与基金经理的利益交换提供了潜在途径,但其发挥作用还依赖于分析师对关系的维护. 从两个角度衡量分析师对“圈子”内基金经理关系的维护,一是分析师在某一年度对“圈子”内基金经理持股荐股评级的均值减去对“圈子”外基金经理持股荐股评级的均值(RankDiff),二是分析师在某一年度对“圈子”内基金经理持股发布的研报数量占该年度该分析师发布研报的总量,即跟踪偏好(NumDiff). Gu等[48]发现分析师倾向于跟踪与其有校友关系的基金经理持有的股票. 从表6看出,RankDiff(表6第1列系数为0.249,z值为2.43)和NumDiff(第2列系数为0.242,z值为2.49)对分析师当选都有显著影响,同时加入这两个变量后各自依然显著(第3列RankDiff系数为0.193,z值为1.84;NumDiff系数为0.197,z值为1.95). 并且加入这两个变量中的任何一个后“圈子”不再显著(第1列、第2列和第3列Network的系数分别为0.137、0.122和0.122;z值分别为1.29、1.16和1.15). 从第3列进一步发现荐股评级差异(系数0.193)和跟踪偏好(系数0.197)对当选的影响大于“圈子”(系数为0.122). 这说明“圈子”效应的发挥依赖于分析师对基金经理的利益输送。表5与表6共同验证了H3. 尽管更高的荐股评级有助于分析师当选,进而实现其利益,但文本信息含量却可能影响分析师的市场影响力和公信力. 表6 分析师跟踪偏好、乐观偏差与当选明星分析师概率Table 6 Following preference, optimistic bias and the probability of being stars 利用模型(8)检验了文本信息含量对市场关注度的影响,结果见表7.实证发现,研报发布后的第1天(Baidu(-1,1))投资者更关注分析师自身的“圈子”(表7第3列的系数为0.012,t值为1.97)以及当选次数(表7第1列系数为0.007,t值为2.05;而在第3列加入SimWu后Times不显著,t值为0.733). 但第3天(Baidu(-3,3))和第5天(Baidu(-5,5))投资者更关注研报的信息含量,第6列和第9列SimWu系数分别为-0.018和-0.010,t值分别为-3.09和-1.76,而分析师的“圈子”和当选次数对市场关注没有显著影响. 验证了H4. 尹玉刚[46]将投资者关注明星分析师而忽视分析师特质的现象称为认知偏差,因为这些分析师特质更能影响研报质量. 值得注意的是,从表7看出投资者对新发布的研报在第1天(Baidu(-1,1))出现了关注偏差,但是随着时间推移,这种偏差在研报发布后第3天和第5天(Baidu(-3,3) 和Baidu(-5,5))消失,市场关注重新回归富含文本信息的研报. 表7 分析师“圈子”与市场关注(百度指数)Table 7 Analysts’ social ties and market attention (Baidu Index) 等[47]的标准化回归方法,其常数项为0,故未列示. 上文研究为分析师社交圈与研报文本信息含量和荐股评级的关系提供了直接证据,并证明了荐股评级及其在“圈子”内外的差异对分析师职业生涯的重要影响,以及研报文本信息含量对市场关注的作用. 下面则进一步研究不同分析师群体对其“圈子”内/外基金经理持股研报的差异,以及明星分析师在当选前后研报各指标(文本信息含量和量化指标)的变化,从而考察“圈子”导致的利益冲突在分析师当选前后的动态过程,结果如表8所示. 表8表明,从研报文本增量信息的角度,曾当选的明星分析师从“圈子”内获取信息的能力更强,在面板 A中体现为DiffStar的绝对值(0.011)大于DiffNonStar的绝对值(0.009);从动态变化看,明星分析师当选后从“圈子”内获取信息的能力进一步增强,DiffAfter的绝对值(0.012)大于当选前的DiffBefore的绝对值(0.005). 表8 不同分组下”圈子”内外研报信息差异Table 8 Difference of research report information between inside and outside social ties under different groups 这一证据与上文的分析一致,分析师当选后从“圈子”内获取信息的能力增强. 其次,在前文论述中,将荐股评级作为分析师获取信息的成本,那么这一成本的动态变化有什么特征? 从明星分析师与非明星分析师的静态对比看,明星分析师整体上对“圈子”内基金经理的持股给予了更高的荐股评级(面板A第2列中DiffStar的值为0.071,而DiffNonStar的值为0.037),这也是明星分析师能获取更多增量信息的原因. 尤其是明星分析师当选前,对“圈子”内基金经理持股的荐股评级显著更高(面板 BDiffBefore的值为0.196). 有趣的是,在当选明星分析师后随着分析师自身财富和市场地位的迅速提高,他们出于对声誉的考量,给出了相对较低的荐股评级(DiffAfter的值为0.048). 最后,曾当选明星的分析师对“圈子”内基金经理持股给予了更乐观的盈余预测(面板 ADiffStar的值为0.778),且“圈子”内外的乐观程度差异更大(面板ADiffNonStar的值为0.226). 这也表明明星分析师群体给出的盈余预测整体上比非明星分析师更乐观. 仅从明星分析师群体看,当选后他们对“圈子”内的乐观程度更高(面板BDiffBefore的值为0.603,而DiffAfter的值为0.791). 结合荐股评级的动态变化,可以看出明星分析师当选后虽然给予了更客观的荐股评级,但盈余预测中的乐观偏差却在增加. 在加入控制变量后,用模型(9)更细致地研究了明星/非明星分析师研报信息的差异,结果见表9. 表9第1列表明明星分析师和非明星分析师的文本相似度整体上没有差异(EverStar系数为0.006,t值为0.96),但他们呈现出共同特征——对“圈子”内股票研报的文本相似度都更低(表9第2列中NetDummy的系数为-0.009,且在5%水平上显著). 然而在第3列中加入NetDummy和EverStar的交叉项后发现其系数为-0.013,且在5%水平上显著,这说明明星分析师对”圈子内外文本相似度的差异要显著大于非明星分析师,即明星分析师更能获得“圈子”内基金经理的私有信息,并体现在文本信息中,也验证了H1b. 高的荐股评级(第6列EverStar系数为0.094,t值为28.40);无论是明星还是非明星分析师,都会对“圈子”内的股票给出更高的荐股评级(第5列NetDummy系数为0.038,t值为16.31);与表9结论相对应,发现明星分析师更注重给“圈子”内基金经理持股发布较高的荐股评级(第6列交叉项EverStar×NetDummy系数为0.008,t值为2.17),验证了H2b. 对于盈余预测偏差,第9列EverStar系数为0.003,t值为0.90,这是由于盈余预测偏差的来源有两个:一是分析师的乐观偏差,曾当选的分析师面临更严重的利益冲突;其次,盈余预测偏差也包含了信息,明星分析师有更广泛的的信息搜集和处理能力,预测更准确. 两个相反的效应相互抵消,导致其系数不显著. 同样的,交叉项也没有显著的解释力(第9列EverStar×NetDummy系数为-0.003,t值为-0.81). 首次当选后分析师的知名度大大提高,同时也获得极大经济利益. 这对分析师有两方面的重要影响,一是其更加注重自己的市场影响力及公信力;二是随着其地位的提高,他们通过“圈子”内基金经理获取私有信息的能力也得到增强. 表9 明星/非明星分析师研报信息差异Table 9 Difference of information content between star and non-star analysts 利用模型(10)动态研究了分析师入选《新财富》后对“圈子”内外评级差异的动态变化,结果见表10. 从第1列可以看出,尽管当选后明星分析师研报的文本相似度整体上有所上升(AfterStar系数为0.012,t值为1.81),但是他们当选后对“圈子”内股票研报的文本相似度显著降低(第3列AfterStar×NetDummy系数为-0.041,t值为-3.18),这一方面是因为他们更容易获取“圈子”内基金经理的私有信息,另一方面是因为他们更注重自身的市场号召力,有动机提供更有信息的研报. 前文提到分析师当选后市场知名度及地位会有显著提高,这很可能会影响其与“圈子”内基金经理的“议价”能力:他们一方面能够更容易获得“圈子”内基金经理所拥有的私有信息,另一方面无需一味地以高荐股评级取悦基金经理. 第6列验证了这一推论,明星分析师当选后对“圈子”内股票的荐股评级依然显著(AfterStar×NetDummy系数为-0.021,t值为-3.40). 与表9的结论类似,盈余预测偏差则在明星分析师当选前后没有显著差异(第9列第3行系数不显著). 表10的实证结果验证了H5. 表10 明星分析师当选前后研报信息差异Table 10 Difference of information content between before and after being star analysts 实证分析中,用剔除了停用词的文本相似度度量研报增量文本信息,然而作为没有实际意义的结构助词或语气助词以及特殊符号,停用词从某种程度上代表了特殊的“信息”——无用信息. 为保证结论的可靠性,使用保留了停用词的文本相似度(SimYou)进行稳健性检验,结果见表11. 表11第3列加入所有控制变量后,结论不变(Network系数为-0.032,t值为-7.50). 表11 保留停用词的稳健性检验Table 11 Robustness test of remaining stop words 尽管以百度指数作为市场对股票的关注度是学者常用的做法[43-45],但也有采用换手率作为市场关注度的度量[49,50]. 研报文本相似度对市场关注度的影响在替换市场关注度指标后是否依然存在?本文构建异常换手率(Turnover)指标来检验结果的稳健性. 异常换手率是研报发布后i日与发布前i日换手率的均值差异(i分别取值1,3,5). 检验结果展示在表12中. 从中看出研报文本相似度对股票换手率的影响与百度指数具有同样的模式,结论稳健. 表12 分析师“圈子”与市场关注度(异常换手率)Table 12 Analysts’ social ties and market attention (Turnover) 在前文中,用模型(10)研究了分析师当选明星后股票研报质量(SimWu和Rank)的变化,发现明星分析师更加注重研报的文本信息含量,而降低了“圈子”内股票荐股评级. 为验证这一结论的可靠性,直接以RankDiff及NumDiff为被解释变量,采用如下模型检验分析师当选明星后的动态变化 (11) 式中Diffi,t代表RankDiff和NumDiff,控制变量的选取与模型(4)相同,回归结果展示在表13中. 表13 明星/非明星分析师研报差异稳健性检验Table 13 Robustness test of difference of information content between star and non-star analysts 回归方法,其常数项为0,故未列示;为节约篇幅,其他控制变量也未在表中显示. 与表9和表10的结论吻合,发现相对于非明星分析师,明星分析师对“圈子”内股票的荐股评级更高,也更倾向于对“圈子”内的股票发布研报. 另外,我国部分券商存在双总部或多总部的情况,这可能会导致正文中基于注册地计算的分析师“地域圈”有偏差. 实际上,虽然很多券商存在双总部或多总部的情况,但大部分分析师主要在注册地的研究所办公,其它总部的研究所主要是为在当地开展业务的分析师设置的临时办公场所. 但是依然检验了双总部或多总部情形对分析师“地域圈”构建造成的可能影响。从各地方证监局网站统计了各自辖区内券商的情况,得到每家券商的总部数量与所在地,发现样本所包含的133家券商中,有72家券商只有1家总部,双总部或多总部的有61家. 对于多总部或双总部的券商,无法确切地知道某个分析师所属的确切总部进而计算“地域圈”,因此表14基于72家单总部券商旗下的分析师样本重复了表4的实证模型. 与表4相比,表14中主要解释变量的系数与显著性保持一致. 同样的,社交圈对分析师预测偏差的影响也保持稳健,这些结论进一步表明多总部券商的情况并不影响本文主要结论. 表14 基于单总部券商的子样本分析Table 14 Subsample analysis based on single-headquarter brokerage 研究报告是分析师向市场传递信息的重要载体,以往研究多以盈余预测偏差和荐股评级等量化指标评价研报的信息价值,但这些量化指标本质上是分析师基于其公共信息和私有信息的结论性预测,而非信息本身. 分析师从解读信息到作出预测的过程是个“黑匣子”,具有较强的主观性且易受到外部利益冲突的干扰,从投资者角度来说这些指标也不具有及时的可验证性,以其作为评价分析师信息中介功能的依据可能片面且不客观. 因此,本文创新性地以文本相似度衡量研报信息含量,并通过量化分析师社交圈的大小,研究“圈子”对分析师独立性的影响及其在研报信息含量中的体现,运用逻辑演绎并实证得出一些有价值的发现. “圈子”是分析师获取私有信息的重要途径,人脉广泛的分析师凭借信息优势能够向市场提供具有显著增量信息的研究报告. 实证发现“圈子”广的分析师研报文本信息含量更高,这一现象在“圈子”内基金经理持股的研报中更为显著. 同时,在“社会关系资本化,资本市场江湖化”的股票市场,“圈子”增加了分析师陷入利益漩涡的概率,分析师可能以高评级的研报谋求私人利益. 对该问题的实证分析证实了这一推论,“圈子”广的分析师整体上荐股评级更高,并且其对“圈子”内基金经理持股的荐股评级显著高于“圈子”外. 本文进一步分析“圈子”效应在分析师研报中发挥作用的机制. 作为重要的外部激励,当选明星分析师是分析师职业生涯的终极追求,而基金经理手握明星分析师评选的投票权. 实证发现对“圈子”内基金经理持股发布高评级能显著增加分析师入选《新财富》的概率,从某种程度上讲,高荐股评级是分析师获取基金经理选票的筹码. 尽管文本信息含量对当选概率没有显著影响,但是高信息含量的研报文本能够引起更大的市场反应,标的股票获得了更广泛的市场关注. 作为分析师职业发展的重要节点,入选《新财富》后分析师的声誉与利益发生了显著改变,此时“圈子”效应发生了何种变化?对这一动态问题的研究发现当选明星后分析师更注重文本信息含量,而对“圈子”内股票的荐股评级有所下降. 其原因是分析师的职业生涯利益得到实现后更注重声誉,并且明星分析师获取私有信息的途径更加多元化,而以高评级获取选票的动机减弱. 本文的研究价值主要体现在两方面. 一是为全面评价分析师研报信息含量提供了新的方法. 不同于以往局限于研报量化指标的研究,本文将其范围拓展到了更为客观和重要的的研报文本,并且相对于量化指标,投资者更关注研报的文本信息. 二是为“圈子”在资本市场的作用提供了新的补充,发现“圈子”对分析师具有双重影响:一方面为分析师发现私有信息提供了便利,有利于其信息中介作用的发挥;另一方面影响分析师的独立性,提高了荐股评级的乐观偏差. 这为投资者如何充分利用研报信息以及规范分析师行为提供了新的思考与启示.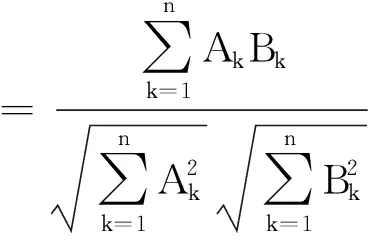
2.3 实证模型

3 实证结果及分析
3.1 描述统计分析
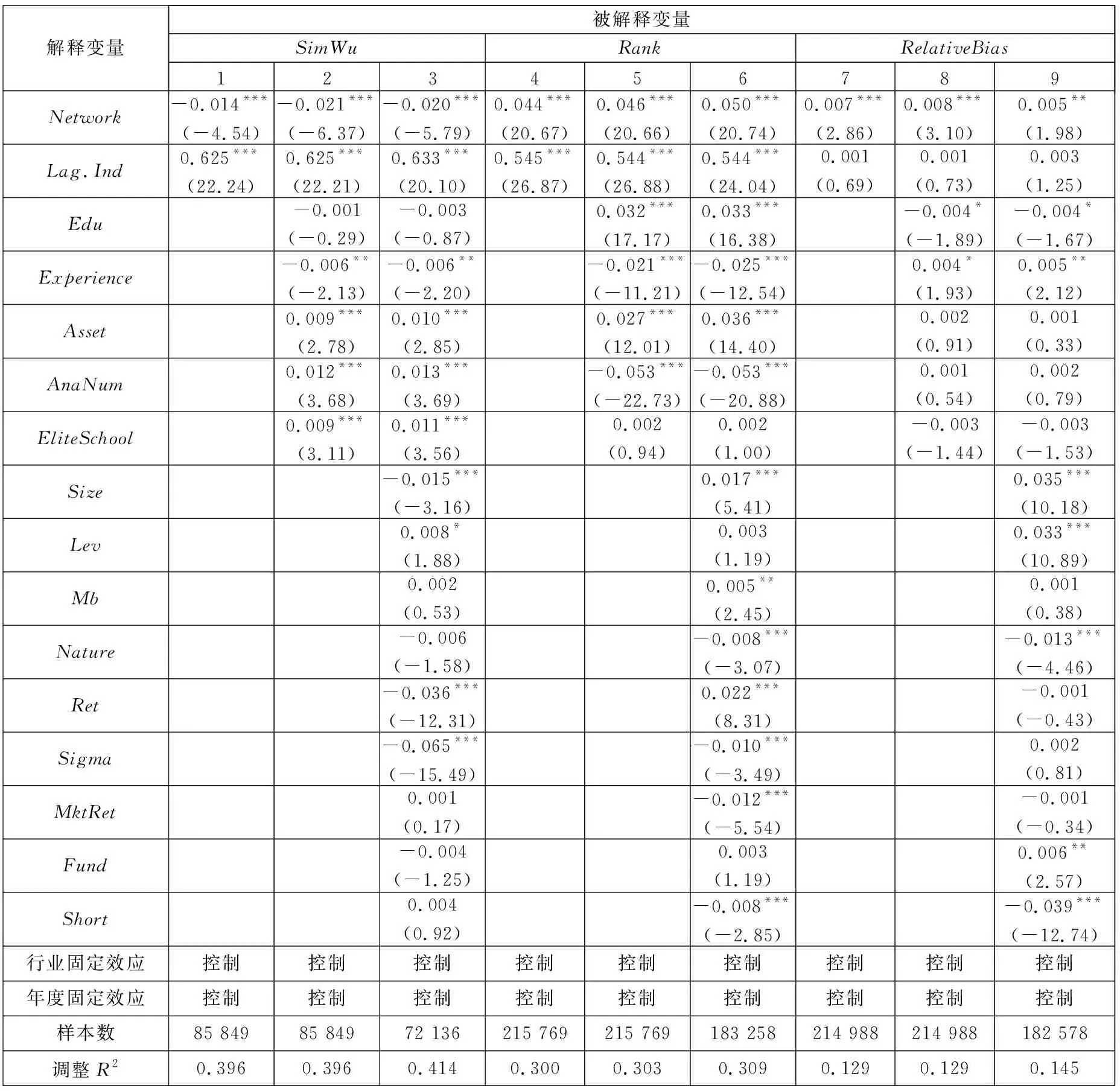
3.2 分析师社交圈、利益冲突与研报信息
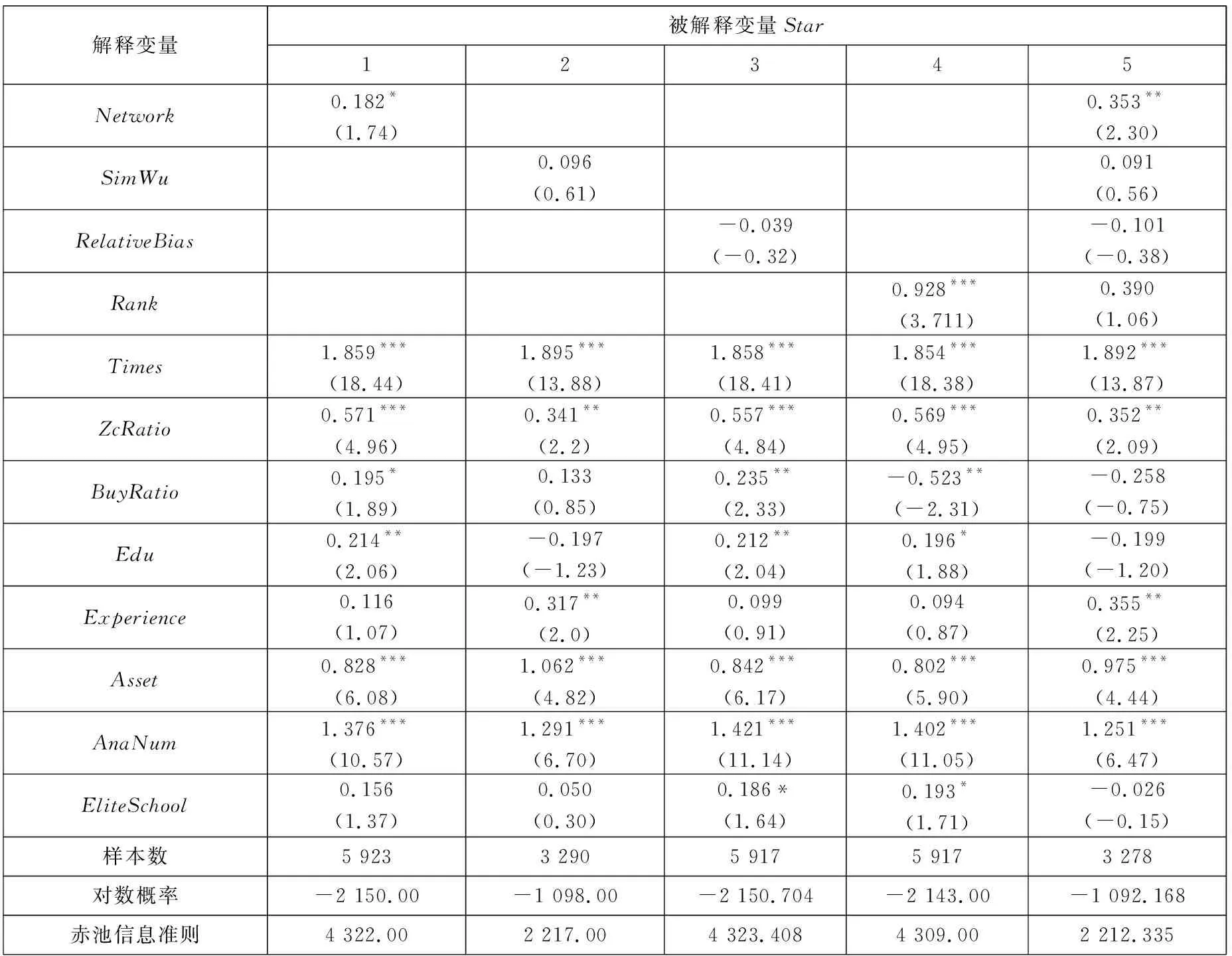
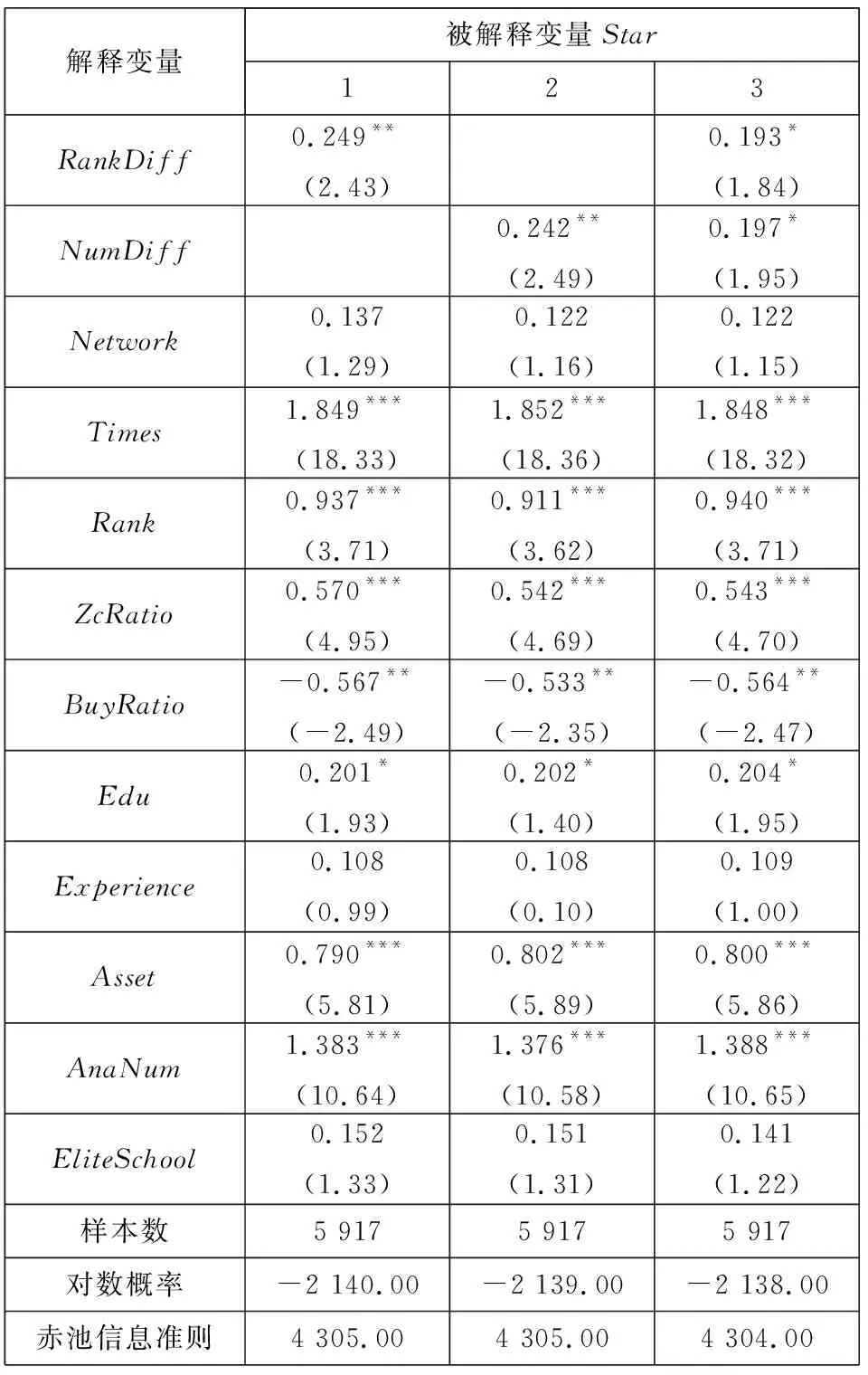
3.3 进一步研究
3.4 稳健性检验

4 结束语
猜你喜欢
证券市场红周刊(2018年38期)2018-05-14证券市场红周刊(2018年33期)2018-05-14证券市场红周刊(2018年10期)2018-05-14证券市场红周刊(2018年5期)2018-05-14股市动态分析(2016年22期)2016-12-27现代苏州(2016年24期)2016-02-04意林(2011年24期)2011-02-11幸福·悦读(2015年3期)2010-11-18投资与理财(2009年8期)2009-11-16流行色(2009年9期)2009-10-21
