
基于深度学习多源数据融合的生菜表型参数估算方法
2022-08-06 05:10朱逢乐何梦竹郑增威
农业工程学报 2022年9期
朱逢乐,严 霜,孙 霖,何梦竹,郑增威,乔 欣
(1.浙大城市学院计算机与计算科学学院,杭州 310015; 2.浙江工业大学机械工程学院,杭州 310023; 3.智能植物工厂浙江省工程实验室,杭州 310015; 4.浙江大学计算机科学与技术学院,杭州 310027)
0 引 言
生菜,为菊科莴苣属一年或两年生草本植物,在世界范围内广泛种植,是大众喜爱的主要蔬菜之一。生菜的干质量、湿质量、株高、直径和叶面积等外部表型参数与生菜生长势和产量直接相关,对生菜的生长监测和产量预估意义重大,有助于实现设施蔬菜栽培的数字化、自动化、智能化。传统的生菜表型参数定量测量方式耗费人力,效率低下;更严重的是,在干湿质量测量中,若对土培或基质培生菜采用传统的破坏式称量方法,会使得生菜生长无法继续,无法对特定植株生长过程中的干湿质量进行连续测量。因此,发展快速无损的表型检测方法势在必行。
可见光图像易于获取,包含丰富的作物表型信息,基于可见光的机器视觉和图像处理技术是表型参数无损估算的研究热点。大多数研究基于二维RGB图像开展。李晓斌等采集了生菜整个生命周期俯视及侧视两类序列图像数据,并同步人工测量生菜生长势的动态参数数据,对图像进行背景分割后从图像中手动提取生菜投影面积、株高、群体覆盖指数3项指标,并通过回归分析证实了提取的特征在表征生菜生长势方面具有可行性。Du等提出了一种目标检测-语义分割-表型分析方法,设计多种几何特征和颜色特征,实现了对每个生菜植株的静态、动态特征的提取,发现静态特征的积累率准确地反映了生菜植株的生长状况,并人工测定冠层宽度参数,通过回归分析验证了所提取图像特征的有效性。Reyes-Yanes等采集多株生菜的俯视图和侧视图,进行图像实例分割后对单株生菜样本手动提取多种几何特征,基于叶面积特征计算生长速率参数,基于多种几何特征构建湿质量线性回归模型,实现了生菜生长速率和湿质量的实时测量。刘林等对日光温室环境下基质培生菜采集俯视图和侧视图,对其进行背景分割后设计并提取几何特征、颜色特征和纹理特征,并与生长环境特征进行融合后作为机器学习模型的输入,构建湿质量回归模型,用于个体和群体的湿质量无损估算,相对误差平均值达11.50%。Valle等在RGB图像的基础上,增加近红外图像的采集实现生菜等作物叶面积和叶片生长速率的计算,对叶面积估算的决定系数达0.997。另外,有少数研究采集生菜的三维信息以获得更精准的外部表型参数估算。Mortensen等对大田种植生菜采集彩色3D点云,提出了一种在3D点云中分割生菜并估计湿质量的方法,从分割的生菜点云中手动提取体积、表面积、叶覆盖面积和高度特征,将其与实际测量的湿质量构建回归模型,结果表明,基于点云数据计算得到的表面积特征能够精准地预测湿质量,对两种生菜品种的湿质量估算平均绝对百分比误差分别达到40%和62%。上述研究均证明了机器视觉和图像处理技术在生菜表型参数估算方面的可行性,但仅针对一种或两种表型参数进行建模,不利于对作物进行全面的生长状况评估;更重要的是,这些研究均基于人工设计或选取的图像特征,且特征提取方法均为手动提取,对数据信息的挖掘不充分,估算精度不足,过分依赖于专家经验的多寡,受制于采集环境的变化。
近年来,深度学习在各个领域得到成功应用,在农业领域渗透到植物表型研究的方方面面,也取得了不错的成绩。综合利用机器视觉和深度学习技术对植物的重要表型参数进行采集和分析是生菜生产过程管理的一种重要技术手段。Zhang等针对以往研究严重依赖于手动设计特征、易受环境噪声影响等问题,提出了一种基于二维RGB图像和卷积神经网络(Convolutional Neural Network,CNN)监测温室生菜生长相关表型参数的方法,训练CNN模型建立生菜图像与相应表型参数之间的关系,可估算的参数包括叶湿质量、叶干质量和叶面积,估算决定系数分别为0.893 8、0.891 0和0.915 6,均一化均方根误差分别为26.00%、22.07%和19.94%。Bauer等针对大面积航拍归一化植被差异指数(Normalised Difference Vegetation Index,NDVI)图像,结合CNN模型实现生菜的计数和尺寸估计,计数决定系数达到0.97。Chang等基于预训练的深度分割神经网络提取生菜的叶面积,进行生菜生长分析。上述研究证明了深度学习在生菜表型参数估算方面的潜力,但是在图像数据源方面,仅依赖于二维俯视图,未考虑植株三维立体形态对表型参数估算的影响,模型性能还有待提升。
为此,本文针对多品种基质培生菜,基于深度学习技术,设计实现了一种融合二维RGB图像和深度图像的多源数据生菜表型参数估算方法,在包含4个生菜品种、涵盖生菜生长全过程的多源图像数据集上进行5种表型参数(干质量、湿质量、株高、直径、叶面积)的高精度、快速估算;分别仅使用RGB图像和深度图像开展消融试验,探究本文融合方法的有效性;引入传统的特征提取和回归方法开展对比试验,验证本文所提方法在生菜表型参数估算中的优势;分别在生菜不同品种和不同生长阶段上进行估算对比试验,评估模型对不同数据子集的估算性能,以期验证方法估算精度,为基质培环境下生菜表型参数估算提供参考。
1 材料与方法
1.1 图像采集与数据集构建
本研究开展于2021年5-6月,在设施环境因子高度可控的植物工厂环境下,基质栽培4种生菜,在不同的生长时间点采集多源图像,并随即测定5种表型参数。
试验地点为浙大城市学院智能植物工厂实验室,试验材料为市场上较为常见的4种生菜,包括Aphylion(L.cv.)、Lugano(L.cv.)、Salanova(L.cv.)、Satine(L.cv.),其中Aphylion和Lugano为绿叶生菜,Salanova(Oakleaf叶形)和Satine为红叶生菜,如图1a所示。将生菜种子放入穴盘中在培养箱环境下培育,待幼苗生长到“五叶一心”时,定植到16 cm×16 cm×25 cm基质盆中,置于植物工厂多层种植架上。整个生长过程中保持环境参数可控,温度为27/22 ℃(昼/夜),相对湿度为50%~60%,人工LED光强为(200±5)mol/(m·s)、光周期为16 h/d、红蓝光质比为3:1,营养液每日10:00滴灌一次。Aphylion、Lugano、Salanova、Satine分别栽培92、96、102、98盆,每盆栽种1株,共388株生菜样本。
从栽种后第10天开始,每隔5 d取55株生菜样本进行图像采集和表型参数测量,第50天取最后的58株样本进行数据采集,如图1b所示。由于表型参数测量为有损方式,故数据采集后植株不再继续栽培。

图1 生菜表型参数估算图像数据集示意图 Fig.1 Schematic diagram of lettuce image dataset for phenotypic parameters estimation
本文使用低成本的RealSense D415 RGBD相机进行生菜表型参数的图像数据采集,RGBD相机是一种可以同时测量像素点颜色和深度信息的相机,输出可见光图像(下称RGB图像)和深度图图像(下称Depth图像)。RGB图像包含肉眼可见的一些基本特征,如叶片大小、颜色、形状等,能够提供较为基本的植物特征信息。深度图像能够记录所拍摄物体与相机镜头的距离信息,可以反映植株的三维立体特征,为植物表型参数估算提供空间深度信息。在图像采集平台上,将RGBD相机以俯视生菜的视角进行安装,悬挂在生菜正上方约0.90 m处,如图2所示。采集的图像格式为PNG格式,图像原始分辨率为1 920×1 080像素。计算机驱动RGBD相机进行图像采集,记录从定植到收获各个生长阶段的生菜RGBD俯视图像,如图1b所示。每株生菜样本对应一组RGBD图像,共388张RGB图像和Depth图像。
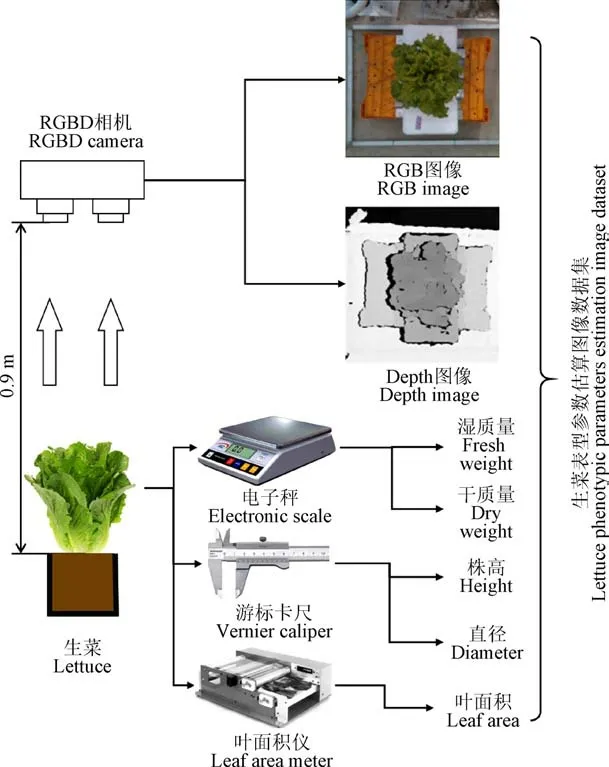
图2 生菜表型参数估算图像数据集获取示意图 Fig.2 Schematic diagram of image dataset acquisition for lettuce phenotypic parameters estimation
每株生菜样本图像采集之后随即人工测量其表型参数,包括湿质量、干质量、株高、直径和叶面积,如图3所示。采用游标卡尺测量株高和冠层最大直径,其中株高为冠层叶片最高点至基质直线距离,冠层最大直径为冠层叶尖最大直线距离;采用叶面积仪(LI-3100 Area Meter, LI-COR Inc., Lincoln, USA)测量冠层叶面积;采用电子天平(精度0.1g)测量去除根部后的样本湿质量;再将样本置于纸质信封中90 ℃烘干48 h,采用电子天平测得其干质量。图3展示了不同品种和各个表型参数的直方图数据分布。从品种上看,样本分布比较均衡;从湿质量、干质量、株高和叶面积来看,生长阶段早期的样本数较多,后期的样本数偏少;从直径来看,直径处于中等大小的样本数较多,小直径和大直径的样本数偏少。
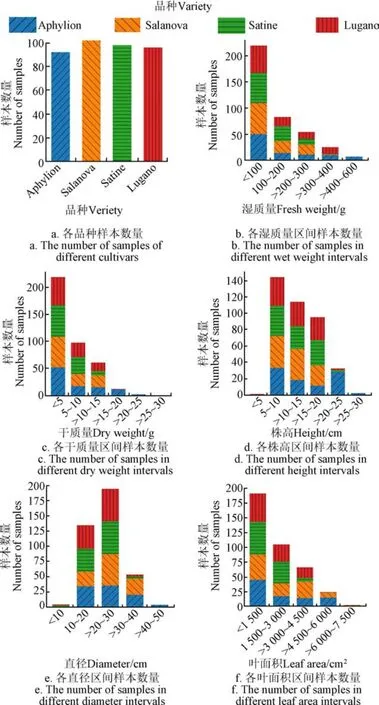
图3 不同品种生菜图像数据集表型参数的 样本分布直方图 Fig.3 Sample distribution histogram of lettuce image dataset according to different varieties and phenotypic parameters
本文基于构建的数据集开展生菜表型参数估算研究,对采集的RGBD图像进行背景分割和数据归一化,输入深度学习多源数据融合算法建立5种表型参数同步估算模型。
1.2 生菜图像分割
为减少杂乱背景的干扰,提高算法的可靠性,本研究对生菜表型参数图像数据集进行了图像背景分割。根据Rother等对图像分割问题建模,图像分割可以转换为图论中的最小割问题,在其研究中,前景和背景的标记选取依赖于手动的框选,不利于大规模数据集和生产应用中的图像分割。为此,本文构建了生菜图像自动前景标记和图像分割的方法。
对每一品种,预先取一个标准图像样本,如图4a所示,在分割如图4b、图4c所示的生菜图像时,将图像划分为若干个15×15像素的区域,再对每个区域求归一化颜色直方图,计算其与标准图像样本的归一化颜色直方图之间的相似性。采用KL散度(Kullback-Leibler divergence)衡量直方图的相似性,如式(1)所示:
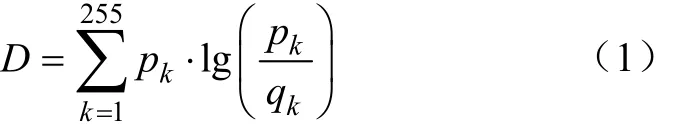
式中为图像的KL散度,为像素值。
KL散度不允许输入包含零元素,所以将归一化后的结果加上0.01再进行计算。根据试验结果,设定阈值=0.7,KL散度低于阈值的区域可以被认为是包含生菜像素的区域。处于生菜轮廓边缘,但包含部分背景的区域也和标准图像样本具有很高的相似度,若直接将整个区域标记,则会导致处于边缘处的背景被标记为前景,进而影响分割结果。因此,仅标记每个15×15像素 区域正中间的5×5个像素,这样可以有效减少处于生菜轮廓边缘处的背景被标记为前景的情况,优化分割效果。标记结果如图4d所示,小方块即为标记结果。

图4 生菜图像分割过程示意图 Fig.4 Schematics of image segmentation procedure of lettuce
至此,已标记好前景T,背景T,通过运行GrabCut算法计算得到分割掩膜,如图4e所示。将原始RGB和Depth图像与分割掩膜进行运算,得到分割结果,如图4f、图4g所示。图5展示了分割完毕的生菜图像示例(与图1中的样本一一对应)。

图5 生菜图像分割结果示意图 Fig.5 Schematics of image segmentation results of lettuce
1.3 生菜图像数据归一化
由于数据分布、数据尺度等原因,图像数据集的原始图像数据并不适合于直接输入到神经网络中进行训练,因此需要对生菜图像进行数据归一化。
数据归一化可以提高分类器的预测能力,不同的数据归一化方法中,Z-Score方法使用均值和标准差的方法比其他方法更有效。本文使用Z-Score对图像进行数据归一化。将裁切后的图像中第个通道的第个像素点pixel(= 0,1,2,=0,1,2...,369 664)通过Z-Score归一化转化为pixel′,如式(2)所示:
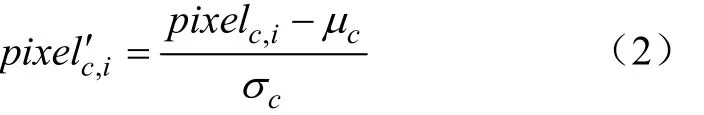
式中μ为通道图像像素值的均值,σ为通道图像像素值的标准差,pixel代表通道的第个像素点。RGB图像有3个通道,Depth图像仅有1个通道。
1.4 生菜表型参数估算模型
本文生菜表型参数估算深度学习多源数据融合模型如图6所示,由特征提取部分、多源特征融合部分和回归网络部分构成。深度学习模型的输入为背景分割和归一化后的图像数据,输出为湿质量、干质量、株高、直径和叶面积5个参数。
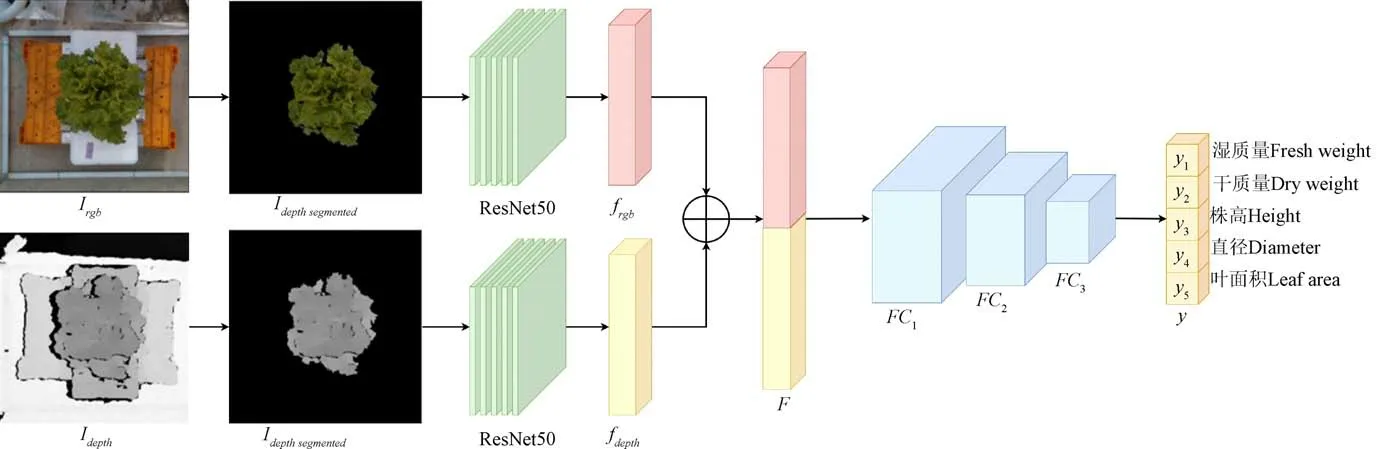
图6 生菜表型参数估算深度学习多源数据融合模型示意图 Fig.6 Schematic of the deep learning multi-source data fusion model for estimating phenotypic parameters of lettuce
特征提取部分采用残差神经网络(Residual neural network, ResNet)分别对RGB图像和Depth图像自动学习和提取生菜的有效特征,用于后续生菜表型参数估算。ResNet是一种用于解决传统CNN深度学习中退化问题的网络结构,是目前计算机视觉领域最常用的深度学习模型之一,在植物表型领域也得到广泛的应用。ResNet由若干个残差块构成,残差块中的shortcut连接将残差块提取的特征和残差块的输入直接相加作为输出,实现跨层的前向传播和反向传播,这种残差学习的思想使得ResNet可以解决深度学习中的退化问题,构建更深的深度模型。残差块结构如图7所示,由三层卷积层和一条shortcut连接组成。
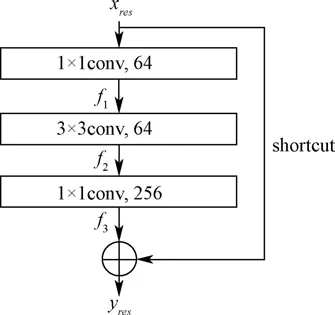
图7 ResNet残差块结构示意图 Fig.7 Schematic of the residual block structure of ResNet
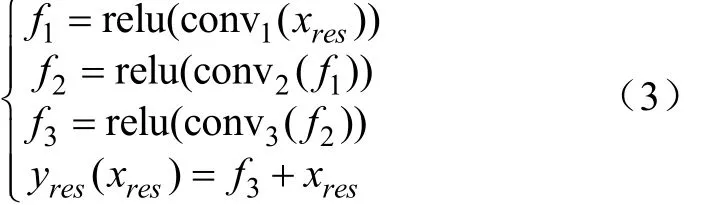
残差块计算如式(3)所示: 式中,,分别为残差块第1,2,3层的输出特征,x和y分别表示残差块的输入和输出。
常用的ResNet框架有ResNet18(18的含义为网络总共包含18层,下同)、ResNet34、ResNet50、ResNet101和ResNet152。本文使用ResNet50的预训练模型作为生菜表型参数估算模型的特征提取网络。模型经过预先在ImageNet上的训练,达到了较好的特征提取性能。相对于其他参数初始化方法,这样的初始值更容易迁移到生菜表型参数估算中,训练时可以在小型数据集上快速收敛。ResNet50的网络结构如图8所示。 ResNet50特征提取的结果是长度为2 048的特征向量。分别将RGB图像I和Depth图像I输入到两个ResNet50中进行特征提取,得到两个长度为2 048的特征向量f和f,如式(4):
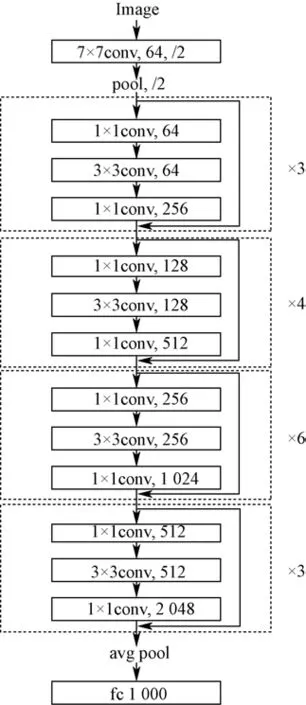
图8 ResNet50结构示意图 Fig.8 Schematic of ResNet50 structure
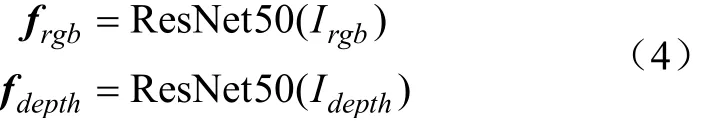
多源特征融合部分将RGB图像特征向量f和Depth图像特征向量f进行拼接,得到一个长度为4 096的生菜表型参数特征向量,如式(5)所示:

将融合后的生菜特征向量输入到回归网络部分进行表型参数回归拟合。回归网络由多层全连接(Fully Connected, FC)和激活函数构成,通过调整隐层数量和隐层中神经元数量,可以优化回归模型。最终得到的模型中,FC层数为三层(包含一层输入层,一层隐层和一层输出层),第一层FC含有1 024个神经元,第二层FC含有512个神经元,第三层FC含有5个神经元。为防止出现梯度弥散和神经元死亡等问题,本文激活函数为LeakyReLU,其计算如式(6)所示,回归网络的计算公式如式(7)所示:
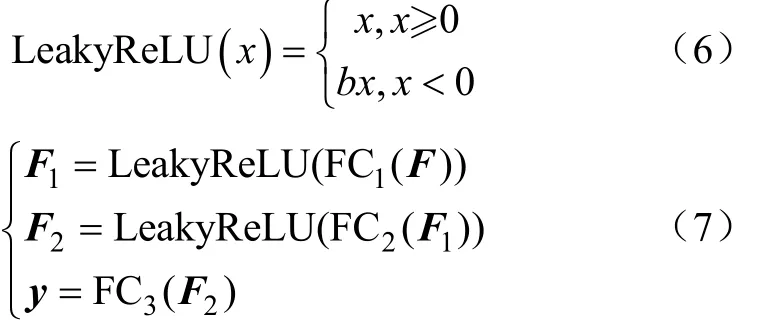
式中为激活函数的输入,系数取0.01,FC(=1,2,3)为分别是回归网络全连接层的第1,2,3层,F,F分别为FC和FC的输出
生菜表型参数估算模型的输出为一个长度为5的向量,、、、、分别表示湿质量、干质量、株高、直径、叶面积。
本文的生菜表型参数估算属于回归问题,采用归一化均方误差(Normalized Mean Square Error, NMSE)作为误差函数,其计算如式(8)所示:
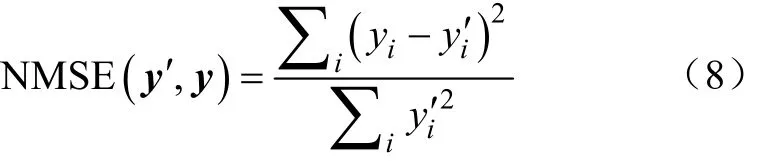
式中′表示人工测量的真实值向量,′′、′′′分别表示人工测量的真实湿质量、干质量、株高、直径、叶面积,表示估算结果向量,、、、、分别表示估算的湿质量、干质量、株高、直径、叶面积。
1.5 参数设定与模型评估
模型训练使用交叉验证的方法,将数据集平均划分为4个子集、、、,每个子集有97条样本。以作为测试集,、、作为训练集进行训练,得到模型I,在上进行估算试验,得到的估算结果,以此类推得到4个子集的估算结果,将它们合并起来作为最终的估算结果。本文所有估算试验结果均采用此结果。
本文深度学习多源数据融合模型基于Pytorch 1.9.0编程实现,软件环境为Ubuntu 20.04.3 LTS,硬件环境为Intel Core i9-10900K CPU 3.70GHz,内存为64GB,GPU为NVIDIA GeForce RTX 3090。模型训练使用Adam优化器;为了抑制训练过程中的过拟合现象,模型中的FC层使用相同的丢弃率0.2,训练300轮次,批处理大小为16。初始化时,FC层的学习率设为1×10,对ResNet50预训练模型进行微调,学习率设为2×10;训练50轮之后,降低学习率,FC层的学习率为2×10,ResNet50预训练模型微调学习率为4×10。
为评价回归模型性能,采用决定系数(Coefficient of Determination,)和平均绝对百分比误差(Mean Absolute Percentage Error, MAPE, %)作为评价指标,其计算分别如式(9)和式(10)所示:

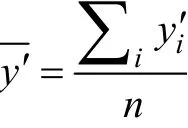

1.6 对比方法
采用传统机器学习模型进行性能对比,包括随机森林(Random Forest, RF)和支持向量回归(Support Vector Regression, SVR)两种。与本文提出的深度网络方法中直接以图像作为模型输入不同,在使用传统的RF和SVR进行回归拟合时,需要人为进行特征提取。本文参考刘林等的研究,选取了生菜轮廓周长、生菜投影面积、Depth图像众数作为形状特征,RGB图像的分量众数、分量众数作为颜色特征,RGB图像的分量熵值、分量熵值作为纹理特征。其中,熵值E的计算如式(11)所示:
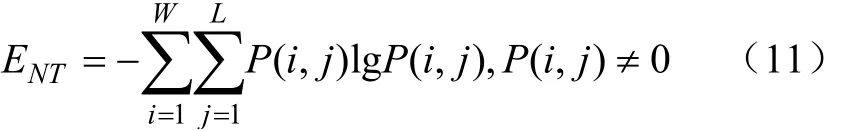
式中(,)表示图像在,处的像素值,,分别为图像的宽和高。
采用相同的交叉验证方法和数据集划分,基于提取的形状、颜色和纹理特征分别构建RF和SVR模型对生菜表型参数进行估算试验,对比方法中模型的实现均基于scikit-learn机器学习库。
2 结果与分析
2.1 生菜各表型参数估算结果
按上文所述方法进行深度学习多源数据融合模型训练与评估,即得到对所有品种的全部样本的各表型参数的估算结果,训练过程损失函数曲线如图9所示,随着迭代次数增加,损失函数损失值逐渐减小并趋于稳定,对一个样本的平均估算耗时约为37.067 ms。估算结果误差和相关性分析如图10所示。可以看出,本文表型参数估算方法对生菜的湿质量、干质量、株高、直径和叶面积估算均表现优异,均高于0.94。对比相关研究来看,本文湿质量估算达到了0.982 1,高于文献[6]的0.949 3、文献[11]的0.94和文献[15]的0.898 3;本文干质量估算达到了0.984 4,高于文献[15]的0.891 0;本文直径估算达到了0.941 1,高于文献[8]的0.88;本文叶面积估算达到了0.962 3,高于文献[15]的0.915 6。上述结果对比表明,相比于以往研究,本文方法的估算结果与真实值有更好的相关性;另一方面,本文的MAPE指标均小于8%,表明所提出的表型参数估算方法具有潜在的应用价值。

图9 训练过程损失函数曲线 Fig.9 Loss function curve during model training
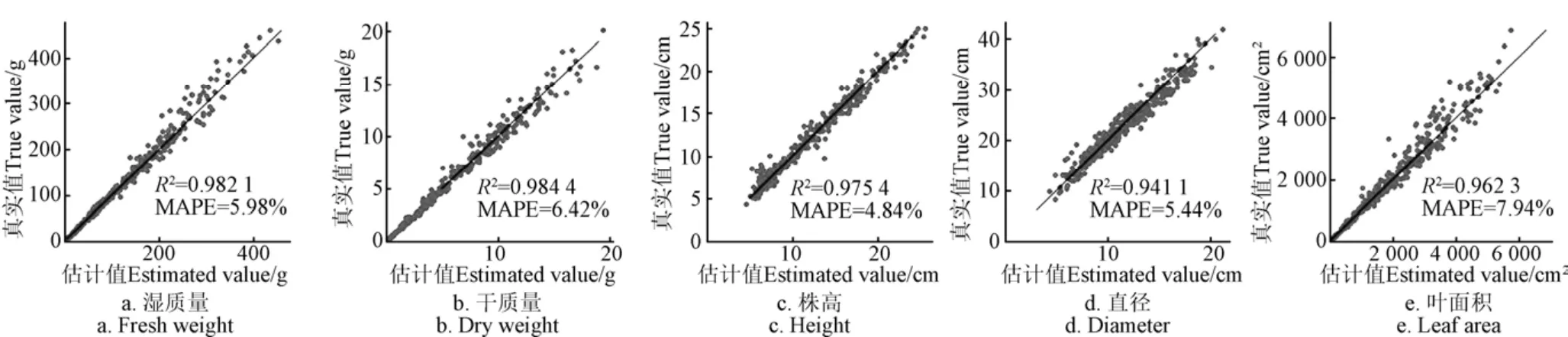
图10 基于深度学习多源数据融合模型的生菜各表型参数估算结果 Fig.10 Estimation results of different phenotypic parameters of lettuce based on deep learning multi-source data fusion model
2.2 消融试验结果
为验证本文提出的融合RGB图像和Depth图像进行生菜表型参数估算的有效性,开展了消融试验,分别仅使用RGB图像、Depth图像作为数据源进行对比,得到对所有品种的全部样本的各表型参数的估算结果,结果如表1所示。
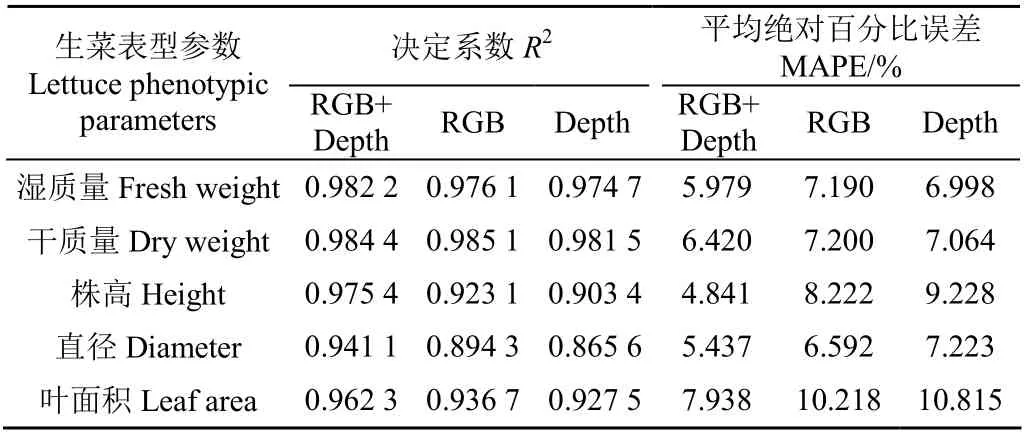
表1 生菜表型参数估算深度学习模型消融试验结果 Table 1 Results of ablation experiment on the deep learning model for phenotypic parameters estimation of lettuce
消融试验结果表明:仅使用单源图像数据(RGB或Depth图像)的估算模型在各项指标上有不错的表现,其中仅使用RGB图像的模型在湿质量、干质量和叶面积的估算中,分别达到了0.976 1、0.985 1和0.936 7,高于仅采用RGB单源图像数据的同类研究结果,其原因在于相较于手动提取特征或仅使用5层卷积网络提取特征的方法,本文使用的ResNet50网络能够自动学习并充分挖掘图像中含有的表型参数相关特征,拥有更强的特征提取能力,更有利于回归拟合和估算。
将RGB图像和Depth图像进行特征融合后,估算性能得到了进一步提升,尤其在株高、直径和叶面积3种表型参数上,株高的相对于RGB和Depth图像分别约提升了0.052 3和0.072,MAPE分别降低了3.381和4.387个百分点;直径的相对于RGB和Depth图像分别约提升了0.046 8和0.075 5,MAPE分别降低了1.155和1.786个百分点;叶面积的相对于RGB和Depth图像分别约提升了0.025 6和0.034 8,MAPE分别降低了2.280和2.877个百分点。其中,在对株高的估算中,由于不同植株基质厚度对株高手工测量的影响和RealSense D415中深度相机本身的误差(在2 m左右有2%以内的误差),导致Depth图像的估算结果稍差于RGB图像,但是将二者融合后株高的估算精度有明显提升,说明深度信息补充了RGB图像中缺少的特征,有利于株高的估算;在对干质量的估算中,尽管融合多源数据和仅使用单源数据的模型相差不大,但从MAPE指标上看,融合多源数据的模型明显比仅使用单源数据的模型误差更低。消融试验发现,相较于仅使用单源数据的方法,本文所提的融合多源数据的表型参数估算方法在各个表型参数上均有不同程度的性能提升,说明Depth图像提供的植株三维立体形态信息有助于模型对表型参数作出更精准的估算。
2.3 传统估算方法对比试验结果
为验证本文表型参数估算方法的有效性,采用上文所述的传统估算方法进行定量对比试验,得到对所有品种的全部样本的各表型参数的估算结果,结果如表2所示。
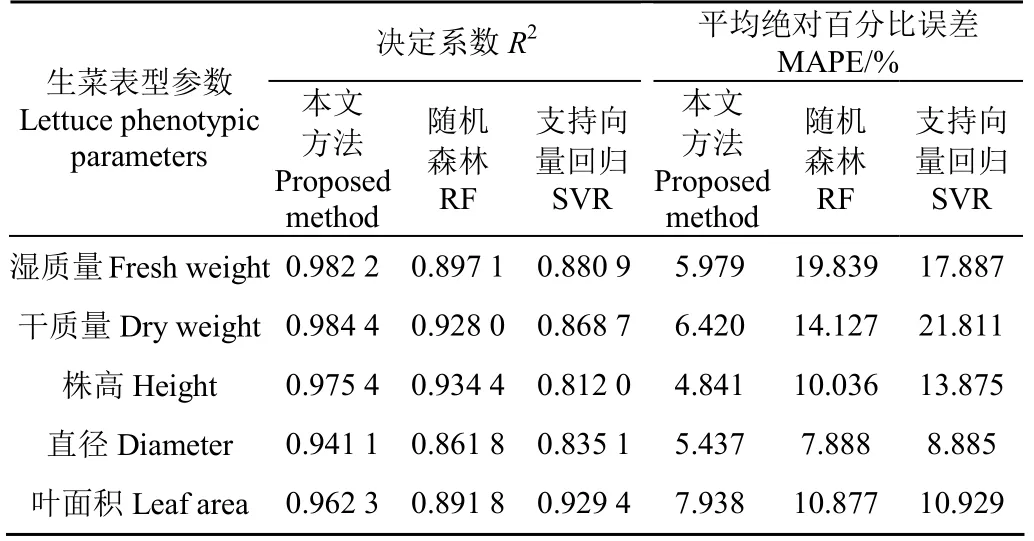
表2 生菜表型参数估算不同方法结果对比 Table 2 Results comparison between different methods for phenotypic parameters estimation of lettuce
对比试验结果表明:RF模型对生菜的株高、直径、叶面积的估算结果和SVR模型对直径、叶面积的估算结果尚可接受,MAPE均在10%左右或更低,均高于0.81,具有一定的实用意义。但RF对湿质量、干质量的估算结果和SVR对湿质量、干质量、株高的估算结果误差很大,MAPE均在13%以上,无法投入实际应用。其原因为传统的手动特征提取方法受制于人工经验,无法充分挖掘图像中的有效表型信息,而且特征提取过程与回归拟合过程的分离显著降低了数据处理流程的自动化程度。相比之下,本文基于深度学习多源数据融合算法构建的生菜表型参数估算模型具有强大的有效特征自动学习能力和非线性数据拟合能力,且端到端的训练方式大大提升了生菜表型参数估算的自动化程度,显著优于传统的估算方法。
2.4 不同生菜品种的估算结果
为验证本文的表型参数估算方法对不同生菜品种的适应性,分别对数据集中4个品种的生菜进行估算试验,结果如图11所示。可以看出,所有品种的各项参数估算的MAPE均低于10%,且总体上表型参数估算结果无明显的品种倾向性,说明本研究的生菜表型参数估算方法适用于不同颜色、形状的生菜品种,具有一定的跨品种适应性。
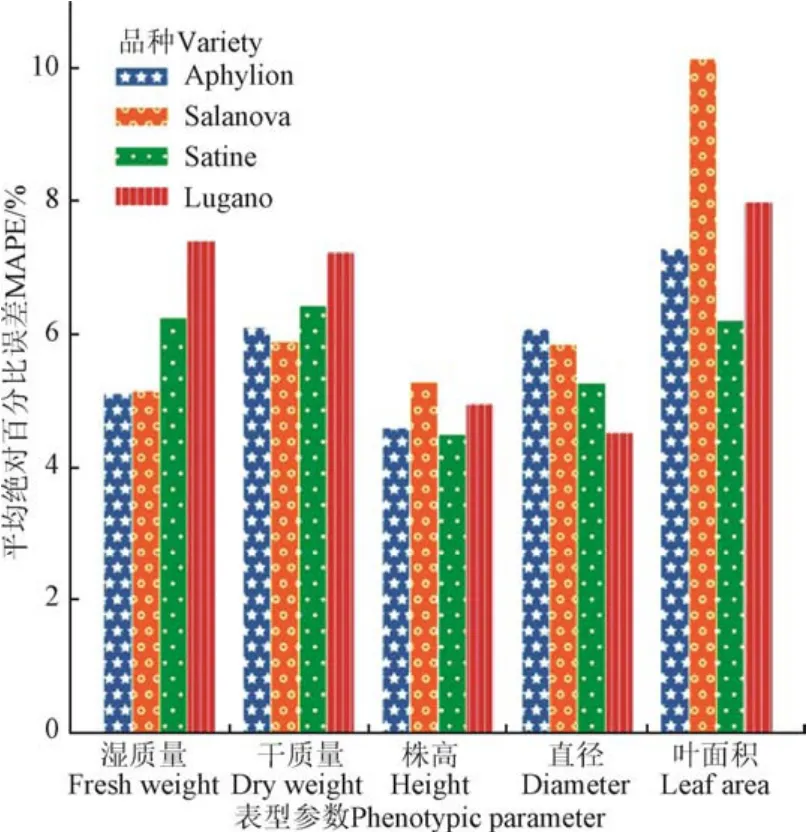
图11 不同生菜品种的表型参数估算结果MAPE对比 Fig.11 MAPE comparison on the estimation of phenotypic parameters between different varieties of lettuce
2.5 不同生菜生长阶段的的估算结果
为验证本文的表型参数估算方法对生菜不同生长阶段的适应性,对数据集样本按实测湿质量进行分组,按湿质量从小到大排序,均分为3个阶段。其中,实测湿质量介于(0, 33.1 g]的样本共132条,称为生长前期样本;实测湿质量介于(33.1 g, 149.0 g]的样本共129条,称为生长中期样本;实测湿质量介于(149.0 g, 459.7g]的样本共127条,称为生长后期样本。对3个生长阶段的表型参数估算MAPE结果如图12所示。可以看出,湿质量、叶面积两项参数的估算误差随着生菜的生长逐渐增大,这是因为幼苗期的生菜叶片更加舒展,图像可以更加完整地体现出冠层所有叶片的性状;随着植株生长,叶片逐渐出现重叠,生长后期的冠层叶片尤为紧凑,被遮挡部分的表型信息无法通过RGBD相机直接采集到,增大模型估算误差。相反,直径的估算误差随着生菜的生长逐渐降低,是因为生长早期的生菜冠层轮廓形状不规则,难以提炼出直径参数的规律,而随着植株的生长,冠层轮廓形状逐渐接近圆形,更利于直径参数的估算。类似的,株高的估算误差也随生菜的生长逐渐降低,则是因为生长前期生菜株高增大较快,且样本间株高差异较大,而生长中后期株高趋于稳定,样本间差异减小,更利于株高的估算。

图12 不同生菜生长阶段的表型参数估算结果MAPE对比 Fig.12 MAPE comparison on the estimation of phenotypic parameters between different growth stages of lettuce
尽管各参数的估算误差随着生菜生长阶段不同而有所差异,但各生长阶段的各项表型参数估算的MAPE均低于10%,表明本模型亦对不同生长阶段、不同植株大小的生菜具有一定的适应性。
3 结 论
本文针对基质培生菜,使用深度学习技术,设计实现了一种融合二维RGB图像和深度图像的生菜表型参数估算方法,在包含4个生菜品种、涵盖生菜生长全过程的图像数据集上进行干质量、湿质量、株高、直径、叶面积的高精度估算,主要结论如下:
1)提出了一种基于深度学习多源数据融合的生菜表型参数估算模型,以预处理后的生菜RGB和深度图像作为输入,对生菜5种表型参数的估算决定系数均高于0.94,优于以往的研究结果。
2)消融试验结果表明:仅使用单源图像数据(RGB或深度图像)的估算模型在各项指标上依然有不错的表现,而将两者进行信息融合后,估算性能得到进一步的提升,尤其在株高、直径和叶面积3种表型参数上,株高的相对于RGB和深度图像分别约提升了0.052 3和0.072,MAPE分别降低了3.381和4.387个百分点;直径的相对于RGB和Depth图像分别约提升了0.046 8和0.075 5,MAPE分别降低了1.155和1.786个百分点;叶面积的相对于RGB和Depth图像分别约提升了0.025 6和0.034 8,MAPE分别降低了2.280和2.877个百分点,证明了本文所提出的多源图像数据融合方法的有效性。
3)与传统估算方法的对比结果表明:随机森林(Random Forest, RF)和支持向量回归(Support Vector Regression, SVR)在某些表型参数的估算上误差很大,RF对湿质量、干质量的估算结果和SVR对湿质量、干质量、株高的估算结果MAPE均在13%以上,应用价值不高;相比之下,本文的估算方法在各个表型参数上都具有良好的估算性能,优于传统方法。
4)对不同生菜品种的估算结果表明:本研究的生菜表型参数估算方法适用于不同颜色、形状的生菜品种,具有一定的跨品种适应性;对不同生菜生长阶段的估算结果表明:尽管各参数估算误差随着生菜生长阶段不同而有所差异,但各生长阶段的各项表型参数估算的平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)均低于10%,表明本模型亦对不同生长阶段、不同植株大小的生菜具有一定的适应性。
因此,本研究提出的融合RGB和深度图像的深度学习模型可以有效对生菜的多种表型参数进行无损、高精度估算,对设施蔬菜快速生长监测和产量预估有重要的应用价值。后续研究会采集更多品种的生菜以增强模型的鲁棒性。
猜你喜欢
中国现代医生(2022年21期)2022-08-22
环球时报(2022-06-08)2022-06-08
瞭望东方周刊(2021年6期)2021-03-30
瞭望东方周刊(2021年6期)2021-03-30
小星星·阅读100分(低年级)(2020年8期)2020-10-26
三农资讯半月报(2020年2期)2020-03-09
食品与健康(2017年3期)2017-03-15
农业与技术(2016年21期)2017-03-06
美食堂(2017年2期)2017-02-14
中国科技纵横(2016年21期)2017-02-13
