
融合结构数据和语义的专利技术主题识别研究
——以非小细胞肺癌治疗领域为例
2022-08-05 11:07沈漫竹于慧娴袁红梅
科技管理研究 2022年13期
沈漫竹,于慧娴,李 倩,袁红梅
(沈阳药科大学工商管理学院,辽宁沈阳 110016)
专利技术主题是对专利技术内容的高度凝练和概括[1],它代表了某一研究领域的技术核心。精准高效地对技术主题进行识别和挖掘可以帮助研究人员全面深入地了解领域研究概况和趋势,掌握技术发展机会,进而为研究人员的技术创新研发决策提供科学支持。近年来,随着科学技术的迅猛发展,生物技术、信息技术等领域新兴技术大量涌现[2],相关专利的申请数量也迅速增长,对于分析技术发展的专业人员来说,显然已经不能通过主观判断对该领域技术进行准确、快速的分析。因此,研究自动化处理大量专利文本数据以识别和挖掘专利技术主题的有效方法具有重要意义。
1 相关研究现状评述
在过去十几年中,研究人员广泛探索将专利文献计量和文本数据转化为深刻、有价值的文本挖掘方法,目前也有较多利用文本挖掘识别技术主题的研究成果,其中主题模型和词嵌入这两种方法最为常用。
作为最著名的主题建模方法之一,潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)根据词汇出现在文档中的概率以及词汇之间的共现频率对文档集进行建模[3],通过概率生成模型从而识别潜在主题。随着LDA 模型在专利主题分析中的研究越来越深入,LDA 模型的改进和拓展逐渐成为研究重点[4]。部分学者根据特定的问题设置和数据改进LDA,例如相关主题模型(correlated topic model,CTM),层次主题模型(Hierachical LDA,HLDA)和拓展生成分布假设的结构主题模型(structural topic modeling,STM)[5-6]。部分学者为了达到研究目的,依据结构信息添加时间、作者等维度改进LDA,例如狄利克雷多项式回归 (Dirichlet-multinomial regression,DMR) 明确提到以作者和引用时间作为结构数据[7];发明人-专利权人主题模型(inventorcompany-topic,ICT)融入发明人和专利权人数据[8];动态主题模型(dynamic topic model,DTM)增加时间动态性[9];连续时间模型(Topics over Time,TOT)对共现词和文档时间戳共同建模[10];作者主题模型(author model,AT)和作者主题模型(author-topic model ,ATM)融入作者数据[11];WI-LDA 模型融入IPC 和单词结合成二元组等[12]。还有部分学者为了增强主题建模语义,使用SAO(subject-action-objec)三元组作为单位词汇[13]。可见,主题建模及其拓展依旧是技术主题分析研究的流行方法。
从主题识别的角度来看,单词嵌入在过去两年中也引起了科学文本挖掘研究人员的极大兴趣。针对专利短文本的高维稀疏特点和语法结构特点,word2vec 模型则可以很好地提取专利文本的语义信息。word2vec 模型是专门用来检测词之间关系的强大工具,在语义分析中经常被采用[14],该方法在映射向量空间中的术语和概念以及发现潜在语义相关性方面显示出了强大的能力。例如,Zhang 等[15]人提出了一种新的核心k 均值聚类方法,通过结合词嵌入,有效地从文献计量学数据中提取主题;Greiner-Petter 等[16]人应用词嵌入的方法从科学文章中检索数学信息;Lee 等[17]人将词嵌入与词网络结合并学习,进行语义相关性和相似性测量。一般来说,词嵌入的目的是将词汇表中的单词映射成数字向量,基本假设是上下文相似的单词具有相似的含义。
虽然目前已有很多文本挖掘和主题识别的研究方法,但是仍然存在一个根本且明显的问题没有解决,也就是提取的主题混乱、界定模糊、不易解释,原因在于,就专利数据自身的独特性来说,无论是LDA 主题模型、LDA 拓展模型还是神经网络word2vec 模型,在对专利文本进行技术主题识别时都各自存在一定缺陷,其缺陷总结如下:
(1)LDA 主题模型及其拓展模型缺乏语境和语义。LDA 和大部分LDA 拓展模型以“词袋”假设,采用无监督学习为每个主题生成离散的单词分布,并为每个文档生成主题分布,该方法只根据术语和单词共现频率提取主题,然而专利文本的高维稀疏特点影响了主题提取的准确性,而且这些模型的训练语料都是独立、分离的词/词组,是uni-gram 形式,而单个单纯的词/词组所包含的语境和语义信息有限,导致主题不易解释[12]。尽管部分模型使用SAO 三元组作为单位词汇来增强语义,但由于专利为法律文本,语言晦涩难懂,其句法结构也限制了提取效率,增强语义的效果不佳。
(2)word2vec 模型缺乏全局信息。尽管近几年许多研究广泛使用基于上下文语义的word2vec 模型,但相较于LDA 对文本全局信息的描述,word2vec 模型虽包含序列词汇的语义关联,其挖掘范围也只是邻近词汇的语义关系,缺乏全局信息[18],不能描述不同文章的主题。如何在识别技术主题时将全局信息和上下文语义有效结合是值得研究的。
(3)忽略专家对于专利分类的意见,专利结构数据结合程度低。无论是主题模型还是word2vec 模型都是根据词汇的各种规律对专利进行绝对客观的分类提取,忽略了专家对于专利的主观分类判断。一项专利往往包含多个技术,一个技术又可能应用于多个领域,仅仅依据词汇而忽略专家意见将会使提取的主题出现偏差、难以解释界定等问题。尽管WI-LDA 等相关模型使用了代表专家意见的IPC 结构数据,但该模型依然存在构建空间巨大、忽略细粒度数据等问题[19],对专利结构数据的结合程度低。
综上所述,技术主题识别工具已成为技术分析及技术创新的重要手段,但是随着该方法的广泛运用,其存在的弊端也日益凸显,致使研发人员无法真正了解领域技术核心内容,阻碍研究人员快速掌握受限技术领域的当前专利格局。因此,需要开发一种方法来一并解决上述所提到的缺乏语境、语义、忽略专家主观分类等具有挑战性的问题,进而提高文本挖掘工具的精确度和高效性。本研究旨在探索更高效优质的主题识别方法,以期帮助研究人员清晰、快捷、全面地了解技术发展,为研发策略提供支持,避免社会资源的浪费。
2 研究设计和方法
2.1 研究框架
本研究旨在克服上述问题,提出了一种精准、高效的技术主题识别方法。首先,从Incopat 数据库中检索所需专利数据并进行预处理,提取专利结构数据IPC 分类号信息,使用bi-gram 添加双词组作为词库;其次,为了结合专家意见、提高专利结构数据结合程度、增强语境解释,本研究将完整的IPC信息引入LDA 主题模型,为了实现科学引入,我们参考作者主题模型(ATM),结合专利独有的结构信息IPC 分类号,将作者概念替换为IPC,形成由IPC 和专家分类意见为指导的IPC-LDA 主题模型。同时,采用word2vec 模型获取基于文本语义的词向量;最后将主题词向量进行权值归一化计算,并对文本语义词向量进行余弦相似计算,再将二者进行向量集成拼接,实现主题建模全局信息和上下文语义相结合,得到最终包含语境、语义和专家分类建议的主题词矩阵。本研究提出的方法细粒度地利用了专利结构数据,平衡了统计评估和人工解释,而且发现了主题建模和word2vec 各自的缺点和互补点,将二者完美结合以解决主题识别方法缺少语义语境和忽略全局信息的不足,使获取的主题词更加精准、完整。本研究的框架如图1 所示。

图1 研究框架
2.2 研究方法
2.2.1 IPC-LDA 主题模型提取主题-词矩阵
本步骤以LDA 的拓展模型作者主题模型ATM为依据,用IPC 替换作者概念,形成IPC-LDA 主题模型。作者主题模型 (ATM)是一种概率模型[20],它以单词作为分析单位,采用四级结构对语料库进行建模,以文档的原始文本和作者(分类属性)为输入,输出每个文档的主要主题和每个作者关注的主要主题。该模型在探讨不同作者研究倾向时表现极好,但在主题识别过程中,由于一个作者可能涵盖多个主题,因此存在多余主题分布干扰[21],而IPC 符号通常只驱动文本语言,IPC 分类号可以直接映射到单个主题,即IPC-LDA 主题模型的主题不直接分配给文档,而是产生一个主题到 IPC 的映射,通过主题到 IPC 和 IPC 到文档的分配,实现主题到文档的分配,主题和 IPC 符号之间通过一个矩阵建模链接,该矩阵分配每个IPC 属于每个主题的可能性概率,扩展了 LDA 使用词频合并标签的方法,也解决了干扰主题识别的问题。同时,IPC 是一个独立于语言的符号分层系统,它代表了发明专利的功能和应用,是专家根据不同的技术领域对专利进行分类的标准,通过引入完整的IPC,可以利用IPC 自身语境和专家分类判断来指导LDA 提取主题的过程。
首先,我们使用bi-gram 添加双词组,实现与命名实体识别相同的目标,即查找具有某些特定意义的相邻单词作为词库。其次,采用IPC-LDA 主题模型。不同于WI-LDA 模型只使用主分类号的小类,IPC-LDA 模型使用每个专利的所有完整分类号,得到更加准确、细粒度的提取结果。IPC-LDA 主题模型如图2 所示,图2 中符号θ为IPC,α为作者超参数(影响作者的主题混合),ad为给定文档的实际IPC,x为对给定词负责的IPC,z为词主题分配,w为观察词本身,φ为主题,β 为主题超参数(影响一个主题的词混合),N、D、T、A分别为单词数、文档数、主题数和IPC 数。IPC-LDA 主题模型由 Gensim 工具包实现[22]。
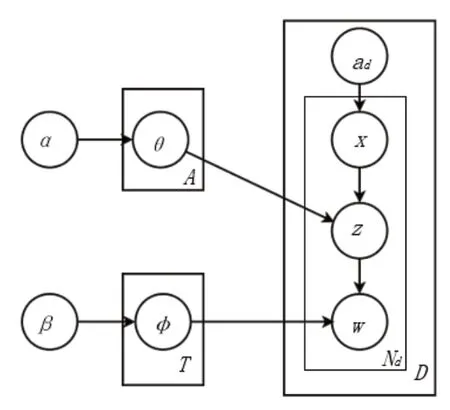
图2 IPC-LDA 主题模型
IPC-LDA 主题模型使用 Gibbs 抽样,提供了一种在 Dirichlet 先验下获得参数估计的简单方法,我们有两组潜在变量:z和x。我们将每一对(zi、xi)作为一个组,条件是所有其他变量如下:
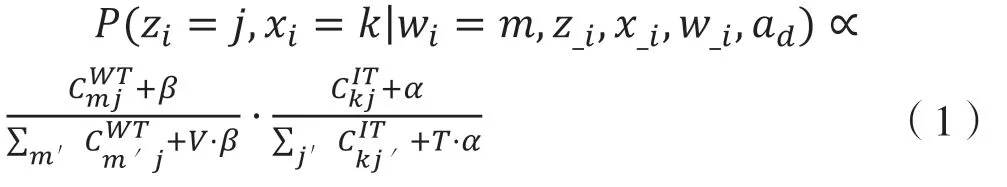

2.2.2 Word2vec 获取语义词向量
为了解决基于概率的统计主题建模技术缺少语义表示的局限性,本研究采用基于神经网络的词嵌入算法Word2vec,实现单词表示从uni-gram向 n-gram 的转变[23]。Word2vec 将语料库中的单词表示为具有上下文理解的向量。在向量空间中,两个向量之间的距离越近,两个词的相似度越高。Word2vec 的结果取决于定义的参数:向量表示m的维度(即大小),以及句子中单词与单词周围单词之间的最大距离(即窗口)δ。Word2vec 有两种配置方式:skip-gram 和连续词袋(CBOW)。本文选择的训练skip-gram 模型如图3 所示。

图3 word2vec 的skip-gram 模型
skip-gram 预测了给定一个目标词周围的上下文。wt被定义为目标词,wt+c、wt+2、wt+1、wt-1、wt-2和wt-c指的是wt的上下文。根据对wt的上下文(如wt+c,wt+2,…,wt-c)的分析,可以得到wt的概率分布,因此,可以定量评估任意两个词之间的语义关系[19]。
2.2.3 向量拼接
IPC-LDA 主题模型和word2vec 模型对专利文本向量化时,有各自的侧重点: IPC-LDA 虽描述了文本全局信息,但缺乏对深层语义的挖掘;word2vec模型包含序列词汇的语义关联,但缺乏全局信息[24]。由此看出,二者信息互为补充,因此本研究提出向量拼接,在IPC-LDA 主题模型提取的主题词表示的基础上挖掘遗漏的单词表示。
(1) IPC-LDA 主题词向量权值归一化。本研究认为,对于每个主题,概率值最高的前h个单词被认为是对该主题贡献最大的(以下简称“贡献词”),代表了本主题的主要内容。我们计算了每个贡献词的所有向量的加权平均值,以获得该主题的唯一向量表示。将权值向量设置为IPC-LDA 输出的归一化词比例b。获得的主题-词矩阵中将前h个单词以外的向量均设置为0。该步骤作为与word2vec 向量拼接的前提准备。加权平均值公式如下:

(2) Word2vec 词 向 量 余 弦 相 似 聚 类。Word2vec 将语料库中的每个词向量化为m维词向量vt∈Rm。采用余弦相似度进行词聚类,为每个单词{w1,w2,w3,…,wt}分配其最接近的单词并得出相似度值,得到单词-单词余弦相似值矩阵,保留矩阵中数值最大的前j个单词值,其余均设置为0。
通过这两部分的计算,降低了后续向量拼接的计算强度。
(3)进行向量拼接。为了将主题映射到向量上,本文将上述两个步骤得到的结果进行拼接,最终得到精确主题词向量。向量拼接过程如图4 所示。

图4 矩阵向量拼接
3 实证分析——以非小细胞肺癌治疗领域为例
肺癌占所有恶性肿瘤的11.6%,是全球最常见的恶性肿瘤,也是癌症相关死亡的最常见原因,其中非小细胞肺癌(NSCLC)最为常见,且死亡率最高[25]。随着生物疗法和基因疗法的迅速发展,新药物、新疗法、新检测诊断方法不断被研发出世,大大提高了非小细胞肺癌的治疗效率[26]。在患病率持续增加的情况下,非小细胞肺癌治疗已成为肿瘤领域的热点和重要的研究课题。因此,对该领域进行技术主题识别至关重要,所以本研究选择非小细胞肺癌治疗领域进行实证研究。
3.1 数据收集与预处理
本研究专利数据来自incopat 专利信息数据库,经过阅读文献和咨询专家意见,确定检索式为TIAB=( 非小细胞肺癌)OR TIAB=(non-small cell lung cancer) OR TIAB=(NSCLC),检索时间截止到2021 年12 月31 日,专利类型选取发明专利,共检索到9 353 条专利,识别并剔除不相关专利以及IPC分类号不完整专利,确定8 960 条专利作为最终实证数据。
由于技术主题识别主要以专利标题和摘要作为依据,因此,本研究使用python 对数据集文件夹进行爬网,读取专利标题、摘要,并对文本进行预处理,包括删除标点符号和数字、删除非索引字、删除停用词、将所有空格换位单个空格、标记化文本、词形还原以及删除频繁词和罕见词,以保证结果的客观科学性,此步骤由spacy 工具包实现。
3.2 专利IPC 提取
IPC-LDA 主题模型还需要专利IPC 分类号数据集。本研究将各专利文本文档编号,随后采用爬网提取每个专利的所有IPC 分类号,进而构造从IPC到文档编号的映射,以txt 形式保存为数据集。本研究选择提取每个专利的所有IPC 分类号,而不是主分类号,因为一项专利被分配的多个专利号代表了这项专利所涉及的完整技术范围。为了进行更加细粒度的分析,最终选择提取到IPC 分类号的小组层级。本步骤获得1 848 个IPC 分类号。
3.3 IPC-LDA 主题模型和word2vec 模型
对于IPC-LDA 主题模型,本研究首先使用N-gram 语言模型添加双词组bi-gram,预测单词的联合概率,生成文档的向量化表示,为下面主题模型的使用做准备。
为了使IPC-LDA 主题模型获得的结果可解释,我们通过Gensim 对IPC-LDA 主题模型进行训练,使用top_topics 方法评估模型的主题一致性,并选择主题一致性最高的模型。通过阅读文献,结合专家意见和训练结果,以平衡统计评估和可解释性为目的,将主题数量num_topics 设置为10,遵循现有研究中超参数α和β的通用设置,设置α=0.5 和β=0.01,应用2000 吉布斯抽样迭代来推断潜在的变量和分布。
对于word2vec 模型,本研究通过Genism 工具包在专利语料库上训练单词向量。由此,我们构造了一个统一的向量空间。考虑本研究的数据量和唯一单词量,参考以往研究中使用的参数值,我们将窗口大小设置为10,向量维数设置为150。
3.4 向量拼接
将IPC-LDA 主题模型的结果进行权值归一化计算作为向量拼接过程中的权重,并将word2vec 模型的词向量输出做余弦相似度计算,最后进行向量拼接,获取更精准、更易解释的主题词向量。根据拼接结果,本研究选择每个主题下概率值最高的前10个单词作为对每个主题的解释,获取的技术主题分布如表1 所示。

表1 非小细胞肺癌治疗领域主题分布
技术主题1 中概率值排名靠前的单词有“monoclonal(单克隆)”“antibody(抗体)”“hybridoma(杂交瘤)”等,可以清晰地确定技术主题1 为单克隆抗体。在非小细胞肺癌领域,单克隆抗体被广泛应用于放射免疫显像、肺癌类型识别检测、靶向治疗和免疫治疗中。新型单克隆抗体、包含新型单克隆抗体的药物制剂、治疗试剂和诊断试剂等是该领域的热点研发技术,尤其是对具有高亲和力、高特异性、毒副作用小的人源化和全人源抗体药物的研发。
技 术 主 题2 中 的 单 词 有“inhibitor( 抑 制剂)”“inhibit(抑制)”“EGFR(表皮生长因子受体)”“ALK(间变性淋巴瘤激酶)”“salt(盐)”等,可以确定技术主题2 为靶向抑制剂。靶向抑制剂属于对非小细胞肺癌的靶向治疗,其作用原理为发现并攻击非小细胞肺癌癌细胞中的特定物质、区域,或者检测、阻止癌细胞内发送的细胞生长信息。为了延长非小细胞肺癌患者的生存期,解决靶向抑制剂耐药等问题,不断对EGFR 抑制剂等靶向抑制剂的盐、晶型、制备方法以及应用等方面进行研发,目前已研发出第四代靶向抑制剂药物[27]。因此,靶向抑制剂一直是非小细胞肺癌领域上的重要技术主题。
技术主题3 中的概率值排名靠前的单词有“antibody(抗体)”“peptide(肽)”“vaccine(疫苗)”“tumor(肿瘤)”等,可以确定技术主题3为非小细胞肺癌疫苗。非小细胞肺癌疫苗是一种新型免疫治疗方法,通过调动免疫系统抑制、攻击非小细胞肺癌癌细胞,可延长患者生存期[28]。目前非小细胞肺癌疫苗的研发涉及用于免疫治疗方法的肽、蛋白质、核酸、细胞,特异于Kras G12V 或HER2-ITD 新抗原的结合蛋白和高亲和力重组T 细胞受体(TCR),活性(免疫刺激性)组合物等等,并将上述成果用于制备疫苗。目前已有治疗性疫苗获批或进行临床试验,对疫苗的研究和开发也是非小细胞肺癌治疗领域中的重要技术主题。
技术主题4 中包括“detection(检测)”“kit(试剂盒)”“gene(基因)”“biomarker(生物标记物)”“marker(标记)”等词,可以确定技术主题4 为检测及试剂盒。对非小细胞肺癌患者进行检测是治疗的基础,领域专业人员意在获得检测谱广、准确度高、灵敏度高、成本低,的方法,目前该技术包括使用基因标志、生物标志物、生物标志物组合等多种方法进行检测,还提供了用于检测非小细胞肺癌标志物的探针组合,试剂盒和生物芯片等技术。
同理即可得到技术主题5 ~10 分别是“药物组合物”“融合蛋白质”“免疫治疗的肽”“RET(激酶)抑制剂”“治疗药物制备技术”“非小细胞肺癌诊断”。
由于非小细胞肺癌治疗属于癌症治疗和肺癌治疗的分支,各种治疗技术都有着较大的关联性,因此在主题提取和解释方面存在较大的困难,但从本研究获得的主题结果可以看出,可以很轻松地对各个主题作出解释和总结,各个主题之间界限较为清晰,而且得出结果较为精准细致,可以进行细粒度解读。经过阅读大量文献以及咨询专家意见,上述的主题本符合非小细胞肺癌领域的研究现状,反映了该领域的热点技术主题,可以帮助研究人员对热点研究技术进行判定。
4 结论
本研究针对目前技术主题识别方法存在的主题可解释性差、界定模糊问题,提出了一种有效的技术主题识别方法,采用IPC-LDA 模型结合专利独有的结构数据,将IPC 分类号引入主题模型指导技术主题识别,同时使用word2vec 模型得到包含上下文语义的词向量,最后进行二者的向量拼接,获得精确的主题词表示,并以非小细胞肺癌治疗领域作为实证案例证明方法的有效性。本研究提出的技术主题识别框架一次性解决了现有主题挖掘方法缺乏语境、语义、忽略专家分类意见等的缺陷,降低了主题界定和解释的难度,提高了技术主题识别的准确度和精确度,为领域研究人员掌握技术发展现状提供帮助,为未来研发方向决策提供科学依据。
本研究的技术主题识别方法也存在局限和不足。首先,在word2vec 得出的结果中使用余弦相似度性确定相似词,没有考虑词汇对主题的贡献度,后续将对word2vec 词向量结果做加权处理;其次,本研究只提供了技术主题识别方法,在未来研究中考虑将本方法用于相对领域新兴主题或专利组合进行预测。
猜你喜欢
水运工程(2022年7期)2022-07-29
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
中国洗涤用品工业(2019年4期)2019-05-11
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
