
基于特征深度融合的Web 服务QoS 联合预测
2022-08-04 03:38:24刘建勋丁领航康国胜曹步清肖勇
通信学报 2022年7期
刘建勋,丁领航,康国胜,曹步清,肖勇
(1.湖南科技大学服务计算与软件新技术湖南省重点实验室,湖南 湘潭 411201;2.湖南科技大学计算机科学与工程学院,湖南 湘潭 411201)
0 引言
近年来,随着面向服务架构(SOA,software oriented architecture)、云计算、移动计算等技术的广泛应用,大量Web 服务被创建并发布在互联网上供人们调用,如何从大量的功能相似的Web 服务中快速、准确地找到高质量的服务是一个挑战性问题。服务质量(QoS,quality of service)描述了服务的非功能属性,是区分功能相似服务的重要参考依据,广泛用于QoS 感知的服务发现、服务推荐[1-2]、服务组合等服务管理任务中。常见的QoS 属性包括响应时间、吞吐量、带宽、丢包率、可靠性等。Web服务的QoS 同时依赖于用户和服务双方,且由于动态的网络条件,同一个Web 服务被不同用户调用的QoS 可能具有差异性。由于很多服务是收费的,通过调用及监测的方式获取所有用户−服务对的QoS是不现实的,因此准确和个性化的QoS 预测是一种可行的解决方案。
协同过滤(CF,collaborative filtering)技术目前已广泛应用于Web 服务的QoS 预测,大致可分为基于邻域的CF 方法、基于模型的CF 方法和混合的CF 方法。基于邻域的CF 方法的核心思想是依据历史QoS 数据计算用户或服务之间的相似度并生成相似邻居集,然后依据相似邻居的已有QoS 估算目标服务的QoS。基于邻域的CF 方法较简单,并且一定程度上利用了难以量化的潜在的用户特征或服务特征,但其预测性能受到数据稀疏性问题的影响较大,同时很难利用与目标节点相似度较低的节点所隐含的全局结构信息。基于模型的CF 方法的核心思想是预定义一个具有适当结构和参数的模型并使用已有的QoS 数据进行训练,训练后的模型具有较好的QoS 预测能力,且对整体结构有较好的估计。基于模型的CF 方法性能较高,在面对数据稀疏性问题时稳健性较强,但传统的基于模型的CF 方法如矩阵分解方法,难以学习用户和服务的深层特征和隐藏信息,可扩展性有限。
近年来,深度学习技术发展迅猛,并且在Web服务的QoS 预测任务上也得到了一些应用[3]。其中,图卷积神经网络(GCN,graph convolutional neural network)可以通过聚合相邻节点的信息获得目标节点的信息,能缓解数据稀疏性问题;同时,它可以通过神经网络的逐层融合获取图的结构信息和深层特征,能有效解决基于邻域的CF 方法和基于模型的CF 方法面临的问题,因而是目前基于深度学习的QoS 预测方法中性能较好的方法。
然而,现有的基于GCN的CF 方法只考虑用户与服务交互的显式信息,未考虑用户终端的环境特征信息和服务器的环境特征信息。环境特征是指客户端主机或服务器主机的特征,例如网络地址、子网、自治系统、地理位置等。这些因素可以通过不同的组合影响QoS,可以使用“偏好”来代表用户客户端主机和服务器主机对对方环境的适应程度,对对方环境特征适应程度更高的用户−服务组合可以获得更好的QoS,可以认为服务满足了用户的“偏好”,用户也满足了服务的“偏好”。因此,如果能够从用户−服务交互信息中挖掘出潜在的环境特征信息,就可以提供更全面和复杂的特征信息来提高QoS 预测精度。多组件图卷积协同过滤[4]方法是最近提出的一种基于GCN的CF 方法,它考虑了用户−项目的交互信息中潜在的用户对服务的偏好,并将抽象的偏好映射为具体的组件,具有挖掘用户或服务的潜在偏好的能力,因此本文前期工作采用该方法挖掘用户和服务的潜在偏好,并针对QoS 预测任务提出一种新的方法[5]。然而,该工作依然存在以下2 个可改进的地方。1) 现有的基于GCN的CF方法大多只应用于单类QoS 属性。在真实环境中,多类QoS 属性分别从不同的角度反映了用户特征或者服务特征,不同类别的QoS 属性之间存在潜在的共同特征,这些共同特征是单类QoS 属性的预测模型无法挖掘出来的。例如,一个拥有较优响应时间的用户−服务对可能保持了非常通畅的网络,也说明服务器此时可能负载较小,这些特征使该用户−服务对可能也有较优的吞吐量;同理,拥有较优吞吐量的用户−服务对也很可能具有较优的响应时间。如果能将多类QoS 属性用合适的方法映射到同一个空间,就能以此建模多类QoS 属性存在的共同特征及联系,提升QoS 预测模型的准确度。2) 预测模块应用DeepFM 对用户和服务的特征向量进行一阶特征、二阶和高阶特征的挖掘,但没有区分不同交互特征的重要性,也没有探究高阶交互特征对预测性能的影响。
基于以上的问题分析,本文提出一种多类QoS联合预测(JQSP,joint QoS prediction)方法。首先,引入一个包含多个卷积核的偏好提取模块来提取各单类QoS的用户−服务矩阵中隐含的用户偏好特征和服务偏好特征;然后,使用加权融合方法将多类QoS的特征提取向量映射到同一个向量空间;最后,使用引入自注意力的因子分解机挖掘融合嵌入向量中的一阶特征和各阶交互特征,并进行多类QoS的联合预测。本文的主要贡献总结如下。
1) 分析了提取多类QoS 数据的共同特征对QoS 预测精确度提升的有效性,应用偏好提取模块(MGCN 模块)实现了单类QoS的环境特征偏好提取,选择加权融合方法将多类QoS的提取向量映射到同一空间,实现了多类QoS 特征融合的目标。
2) 引入带自注意力的因子分解机(ANFM,attention neural factorization machine)对嵌入向量中的一阶特征、二阶交互特征和高阶交互特征进行深度融合,实现了特征深度融合,并为交互特征赋予注意力权重,提升特征提取的效果,最终实现QoS联合预测的目标。
3) 在真实数据集WS-DREAM 上进行了大量的实验分析,实验结果表明了JQSP 方法的有效性。
1 相关工作
协同过滤方法是应用最为广泛的QoS 预测方法,大致可分为基于邻域的CF 方法、基于模型的CF 方法和混合的CF 方法,本文主要介绍前两类方法的相关工作以及基于模型的CF 方法中发展迅速的基于深度学习的CF 方法的相关工作。
基于邻域的CF 方法基本思想是借助相似用户或服务的历史QoS 来预测目标服务的QoS。Shao 等[6]首先提出一种基于用户的CF 方法,该方法利用Pearson 相关系数(PCC,Pearson correlation coefficient)计算用户−服务QoS矩阵中所有用户的相似性,然后对目标用户的前k个相似用户的历史QoS 值进行融合,得到预测结果。其后的相关工作大多致力于改进相似性度量办法来增加衡量用户或服务相关性的准确度。例如,Chen 等[7]使用A-余弦来计算服务之间的余弦相似性,然后减去服务的平均QoS 向量,以此消除不同QoS的尺度影响,有利于相似性计算;任丽芳等[8]在移动边缘计算环境中通过K-means 聚类确定相似用户和边缘服务器。此外,在CF 方法中加入用户或服务的时间信息或位置信息也有利于QoS 预测。例如,Wang 等[9]提出一种基于距离的增强型Top-K 选择策略,在移动边缘计算任务中利用纬度和经度坐标选择相似边缘服务集;邓璇等[10]引入网络嵌入式学习,提出一种基于信誉感知的QoS预测方法,充分挖掘高阶隐式关系。基于邻域的CF方法易于实现、效果较好,但它们面临数据稀疏、冷启动等问题,可扩展性也较差。此外,基于邻域的CF 方法主要利用历史QoS 值和上下文信息,该特点很好地利用了局部信息,但可能忽略了全局结构。
基于模型的CF 方法的基本思想是使用历史QoS 值来训练预定义模型,使模型趋向于真实QoS值的分布。最经典的模型是矩阵分解(MF,matrix factorization)模型[11],其主要思想是将用户−项矩阵分解为用户和项的2 个潜在因素矩阵的乘积,这2 个矩阵提取了部分用户或项的特征。大多数基于MF的模型采用梯度下降或随机梯度下降方法来寻找目标函数的局部最小值,Luo 等[12]将交替方向法的原理引入基于交替最小二乘法的训练过程中,加速了模型收敛;鲁城华等[13]提出一种基于用户和服务区域信息的QoS 预测方法,将全局的服务质量信息和局部的区域信息相结合构建预测模型。在改进方法上,Chen 等[14]将用户ID、服务ID、服务位置和用户位置信息嵌入向量中,为MF 模型引入了更多信息;Tang 等[15]通过合并服务用户的位置,改进了经典的因子分解机模型,提升了模型预测的精确度;夏会等[16]分析用户−服务QoS 矩阵的时空特征,提出一种基于全局和局部结构相似度的稀疏矩阵分解模型;陈蕾等[17]通过将Web 服务QoS 预测问题建模为L2,1 范数正则化矩阵补全问题,提出了一类基于结构化噪声矩阵补全的Web 服务QoS 预测方法,有效缓解了QoS 信息受结构化噪声污染的问题。在引入时间信息时,Luo 等[18]提出了一种有偏的非负张量潜在因子分解模型,有效缓解了QoS数据随时间波动的问题。基于模型的CF 方法使用用户−服务矩阵中的所有QoS 值来构建全局模型,有效利用了全局信息,因而可以很好地估计整体结构,但传统的基于模型的CF 方法在挖掘关联性较强的用户组或服务组的局部信息时表现较差,且难以提取高阶特征。
随着神经网络研究的深入,作为基于模型的CF方法的一个分支,基于神经网络的CF 方法得到了较多研究。Kang 等[19]提出一种结合神经网络和注意力的因子分解机模型,能有效捕获非线性特征交互并赋予不同的重要性;Gao 等[20]提出一种能够对上下文信息进行聚类的模糊聚类算法和一种新的组合相似度计算方法,并提出一个新的神经协同过滤(NCF,neural collaborative filtering)模型,可以利用本地和全局特性为预测提供信息;王安迪[21]提出基于自组织映射神经网络与K-means 两阶段聚类的QoS 预测方法,对用户和服务分别进行聚类,将基于相似用户的预测值和基于相似服务的预测值结合进行混合预测;Chen 等[22]提出了一种由多个LSTM 层组成的递归神经网络模型,并使用了多种正则化技术来提升预测性能。在GCN 相关方法中,Elif 等[23]针对Wi-Fi6的QoS 预测,采用GCN 对数据进行时间分析,提升了预测的效果。本文的前期工作[5]将用户−服务的历史QoS 值建模为二部图,采用GCN 提取和聚合节点的邻居信息,并采用ANFM 模块挖掘低、高阶交互特征并赋予权值,为预测提供了更多有价值的信息。基于神经网络的CF方法能有效提取历史QoS 值中的高维信息,有能力拟合任何非线性QoS 分布,但在提取特征的方法上还有较大的改进空间,如果能够从用户−服务交互信息中挖掘出潜在的环境特征信息,就可以提供更全面和复杂的特征信息来提高QoS 预测精度。
2 方法介绍
本节将详细介绍JQSP 方法。图1 展示了JQSP方法的工作流程。JQSP 主要由多组件图卷积神经网络(MGCN,multi-component graph convolutional neural network)和ANFM 这2 个模块组成。JQSP方法使用MGCN 模块提取各单类QoS的多维偏好特征,并将多类QoS的特征嵌入映射到同一个空间,然后通过ANFM 模块将拼接的多类QoS 偏好特征进行深度融合,并实现多类QoS的联合预测。作为一个端到端模型,JQSP 以数据预处理后的多个用户−服务QoS 矩阵作为输入,每个矩阵代表一类QoS。在整个JQSP 方法框架中,MGCN 模块包含3 个子模块。1) 具有节点级注意力的分解器,该子模块可以从服务的特征信息和用户的特征信息中识别和捕获用户−服务交互关系的潜在偏好,并将其映射为具体的组件;2) 具有组件级注意力的组合器,该子模块可以获得上述组件的权重系数,然后通过聚合组件与对应的权重系数得到用户嵌入向量和服务嵌入向量;3) 加权融合器,该子模块负责将多类QoS的用户嵌入向量和服务嵌入向量采用加权融合的方式构成融合嵌入向量。ANFM 模块使用线性部分挖掘融合嵌入向量的一阶特征,使用交互部分挖掘其二阶交互特征,使用全连接层部分挖掘其高阶交互特征并应用自注意力层为交互特征分配权重,最后将多个部分的结果相加得到最终的多类QoS 预测结果。JQSP 方法框架如图2 所示,考虑两类QoS的联合预测情形,其中对每类QoS分别为用户和服务提取其偏好特征。

图1 JQSP 方法的工作流程
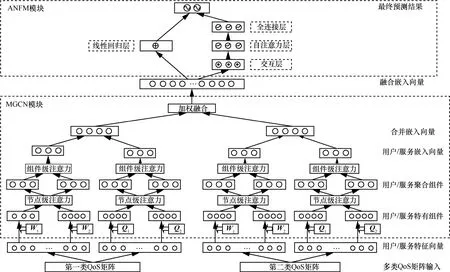
图2 JQSP 方法框架
2.1 数据预处理
数据预处理的目的是将QoS 矩阵转换为模型可以识别的标准格式。在QoS 预测的背景下,可将用户−服务的历史QoS 值建模为用户GCN服务二部图G={U,S,R,E},其中U和S分别为用户Nu和服务Ns的集合,R为QoS 集合,E为边集合,其元素边e=(u,s,r)∈E表示存在用户u调用服务s的QoS 值r。
为便于处理,将QoS 矩阵分别从用户和服务视角来建模,即用户特征矩阵和服务特征矩阵,其中,Lu和Ls分别为用户特征和服务特征的维度,Nu和Ns分别为用户和服务的数量。
2.2 MGCN 模块
本文将编码器称为MGCN 模块,它由多个结构相同、参数独立的Single-MGCN 模块构成。Single-MGCN 模块在本文的前期工作[5]中已经得到实现,其思想主要借鉴文献[4],可以细分为分解器和组合器2 个部分,目的是将QoS 矩阵表征为嵌入向量。Single-MGCN 模块的输入为单类QoS的用户特征矩阵和服务特征矩阵,输出为该类QoS的用户嵌入向量和服务嵌入向量。
2.2.1 分解器
本文构建分解器从特征信息中识别和捕获交互中的潜在偏好,并将其映射为组件。分解器的输入为用户特征矩阵和服务特征矩阵,输出为用户聚合组件和服务聚合组件。
1) 多组件提取。假定用户−服务二部图G受M个潜在偏好影响,本文分别为用户和服务设计M个独立的转换矩阵作为卷积核,对二部图进行卷积操作:用户转换矩阵组和服务转换矩阵组第m个转换矩阵捕获第m个用户−服务交互潜在偏好。对于服务i,其第m个服务特有组件可以按式(1)提取;对于用户j,其第m个用户特有组件可以按式(2)提取。这两组组件包含了QoS 二部图中环境偏好特征对用户和服务的分量。
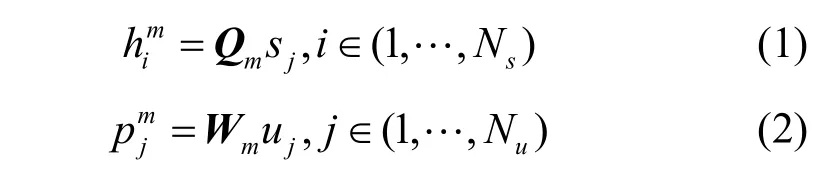
2)节点级注意力应用。在用户−服务二部图中,每个节点都有若干可用于获取邻域信息的邻居节点。对节点应用节点级注意力,可以学习该节点的各邻居节点的重要性,区分邻居节点之间的差别并为其分配不同的权重,以提升特征提取的效率。
经过多组件提取步骤,用户j得到M个用户特有组件服务i得到M个服务特有组件。考虑到用户与不同服务的交互对描述各组件影响不同,分解器应用节点级注意力来凸显对描述组件影响较大的服务。
具体来说,考虑到第m个组件对用户j调用服务i的QoS 值的影响同时表现在用户特有组件和服务特有组件中,则其影响因子可以由注意力计算式(3)学习得到,其中,attnode表示执行节点级注意力的神经网络,Watt,m表示第m个组件的节点级注意力参数矩阵,σ表示激活函数,||表示拼接运算。在获得影响因子后,将其按softmax 函数式(4)进行标准化,以获得其权重系数该权重系数表示该服务特有组件的节点级注意力权重。

对于用户j的调用服务集Pu中的所有服务,通过式(5)聚合其服务特有组件与对应的权重系数,可以得到用户j特有的第m个服务聚合组件它描述了用户j的客户端主机受第m个偏好影响的程度。经过分解器的处理,所有用户都获得了M个服务聚合组件所有服务也获得了M个用户聚合组件

2.2.2 组合器
本文构建组合器学习潜在组件的权重系数并聚合它们,得到嵌入向量。组合器的输入为用户聚合组件和服务聚合组件,输出为用户嵌入向量和服务嵌入向量。
1) 组件级注意力应用。客户端主机对服务环境的偏好可以通过服务聚合组件反映,而服务器对用户环境的偏好可以通过用户聚合组件反映。考虑到不同组件对学习用户嵌入向量或服务嵌入向量有不同的贡献,组合器应用组件级注意力来凸显对学习嵌入向量影响较大的组件。
具体来说,考虑到第m个服务聚合组件的权重系数同时受到原始的用户特征信息和节点级注意力加权的用户特征信息的影响,本文通过拼接服务聚合组件和用户特有组件并通过全连接层,按式(6)得到用户联合向量其中Cm是参数矩阵,bm是偏置向量。然后,按式(7)学习得到第m个服务聚合组件的影响因子wm,其中attcom是执行组件级注意力的神经网络,q是组件级注意力参数矩阵,b是偏置值,q和b由所有用户聚合组件和服务聚合组件共享,因为这2 个参数表示客户端主机对不同服务环境和服务器对不同用户环境的共同偏好倾向。然后,将影响因子wm按soft max函数式(8)进行标准化,获得第m个服务聚合组件的权重系数,该权重系数表示了该服务聚合组件的组件级注意力权重。
2) 权重聚合。按式(9)聚合服务聚合组件与其对应的权重系数,获得用户j的嵌入向量zj。类似地,可以获得服务i的嵌入向量vi。用户嵌入向量zj和服务嵌入向量vi不仅捕获了低维的用户相似关系和服务相似关系,也捕获了高维的用户−服务交互中隐含的客户端主机对服务环境、服务器对用户环境的偏好信息。

2.2.3 加权融合器
获得用户嵌入向量zj和服务嵌入向量vi后,将它们按式(10)进行拼接,得到合并嵌入向量所有合并嵌入向量组合获得合并嵌入矩阵emerge。

值得注意的是,合并嵌入矩阵emerge是Single-MGCN 模块处理单个QoS 矩阵所获得的单类QoS 合并嵌入矩阵,仅包含单类QoS的用户特征和服务特征。对于多个Single-MGCN 获得的多类QoS 合并嵌入矩阵emerge,k,在对齐用户标识和服务标识后,本文采用加权融合的方式进行特征深度融合,按式(11)获得融合嵌入矩阵zunion作为解码器的输入,其中,λi是可训练的权重系数,且融合嵌入矩阵zunion中的每个融合嵌入向量zij都包含了用户j和服务i在多类QoS 上的特征。

2.3 ANFM 模块
本文将解码器称为ANFM 模块,它主要借鉴ANFM 模型[24]。ANFM 模块的输入为融合嵌入向量,输出为多类QoS 预测值。与传统因子分解机相似,ANFM 使用线性部分提取嵌入向量中的一阶特征;而在挖掘嵌入向量交互特征上,ANFM 进一步应用自注意力挖掘交互特征的注意力权重,然后使用深度神经网络挖掘高阶交互特征,这些工作使ANFM模块拥有比传统因子分解机FM 更优的性能。
2.3.1 ANFM 介绍及线性部分计算
ANFM的核心计算式如式(12)所示,其中,w0表示全局偏置,W1表示一阶特征提取的参数向量,h(x)表示可变的高阶特征提取函数。由此,对于输入的混合嵌入向量zij,首先可以获得线性部分
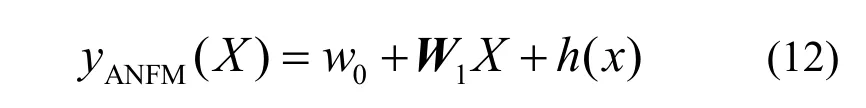
传统FM的h(x)为该项为二阶因式分解交互项,可以有效提取输入向量中的二阶交互特征,但在处理复杂的现实数据时表达受限[25]。考虑到各组交互对最终预测的贡献不同,本文应用注意力来凸显贡献更大的交互项。文献[24]证明在该任务中,自注意力机制[26]可以减少注意力特征提取对外部信息的依赖,有效捕捉特征的内部相关性,相比其他注意力机制有更优的表现,所以本文应用自注意力来强化高阶特征提取。图3 展示了适用于本文模型JQSP的式(12)中的ANFM 模块中高阶特征提取函数h(x)的框架。

图3 高阶特征提取函数h(x)框架
2.3.2 交互层计算
为提取特征之间的交互,对于给定的d维输入特征向量zij={z1,z2,…,zd},首先为其每个特征元素zi构建交互嵌入向量ei,按式(13)得到元素嵌入向量所有交互嵌入向量构成交互嵌入矩阵E,它由所有输入特征向量共享。然后,按式(14)得到二阶交互向量zpair,其中◦表示哈达玛积。
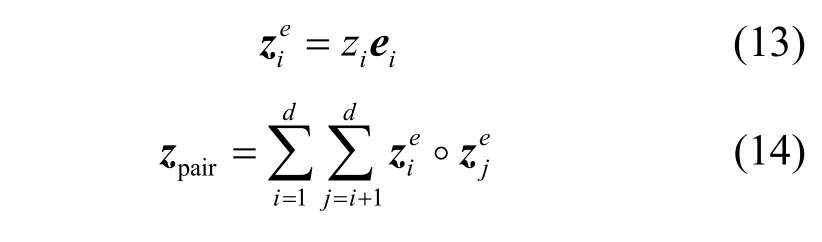
2.3.3 自注意力应用
自注意力机制是注意力机制的变体,它依据输入向量的内部元素相关性计算各元素的自注意力值,减少了对外部信息的依赖,与传统注意力机制相比更加灵活。对二阶交互向量的自注意力机制实现过程如下。对于e维二阶交互向量zpair={z1,z2,…,ze},首先为每个交互特征元素zj构建注意力嵌入向量attj,按式(15)得到元素注意力嵌入向量zajtt。然后构建3 个由全部元素嵌入向量共享的自注意力参数矩阵WQ、WK、WV,按式(16)~式(18)分别计算得到查询向量Qj、键向量Kj和值向量Vj。接着将Qj与Kj按式(19)相乘得到的注意力分数值scorej,其中⊙表示点乘。

对于多个交互特征元素zj,将它们的注意力分数值按式(20)进行softmax 归一化,得到对应的权重值weightj,该权重值能判断Qj和Kj的相似程度,也决定了Vj的重要程度。最后,将weightj和Vj按式(21)进行加权求和,得到带自注意力的二阶交互特征向量zij,att。区别于显式注意力,应用自注意力的二阶交互特征向量可以调整向量内部的元素值,使向量表征更加灵活、准确。
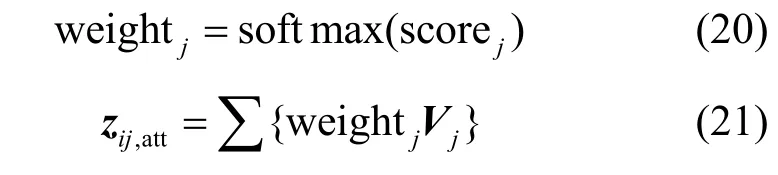
2.3.4 QoS 联合预测
在获得带自注意力的二阶交互特征向量后,为提取高阶交互特征,本文将zij,att传入一组全连接层,按式(22)~式(25)计算高阶特征提取向量h(zij)。

其中,Wi和bi表示第i层神经网络的权重矩阵和偏置值,σ表示激活函数,q表示预测层权重矩阵。
至此,已获得了适用于本文模型JQSP的式(12)中的高阶特征提取函数h(x)。注意,式(25)中q表示的是一个权重矩阵而非列向量,其列数等于MGCN 模块输入的QoS 矩阵的个数,因此h(zij)的输出为一个多维向量,其维度等于QoS的类别数。
综合以上结果,按式(26)获得A个最终预测结果,其中表示用户j调用服务i在第a类QoS 上的预测结果表示高阶特征提取向量由的第a个分量,线性回归部分ylinear,ij所有类的QoS 预测结果共享。

2.4 优化
本文方法采用均方误差作为损失函数,具体计算如式(27)所示,其中,O是已知QoS的集合,|O|是O的元素数量是用户j对服务i的第m类预测QoS 值是用户j对服务i的第m类真实QoS 值,A是QoS的类别数量。此处假定了如果一个用户−服务对获得一类真实QoS 值,那么就能获得所有类的真实QoS 值,因此获得的真实QoS 值的数量为A|O|。

为缓解过度参数化和过拟合问题,本文对损失函数进行L0正则化,对多组件提取矩阵W和Q进行稀疏化,过滤无关自由度。最终的目标函数为式(28),其中θ={W,Q},λ表示用于平衡损失和系数正则化的超参数。

3 实验评估及分析
本节进行若干对比实验和JQSP的消融实验,以期回答以下问题。
问题1JQSP 方法是否比其他基线方法表现更优?
问题2JQSP 方法模型的各子模块是否产生了预期的作用?具体来说,用于提取环境偏好特征的MGCN 模块是否对QoS 预测的准确度有优化作用?引入自注意力的ANFM 模块是否能更有效地利用特征交互信息来提升QoS 预测准确度?将多类QoS 数据的特征映射到同一空间是否能更有效地挖掘隐含特征信息?联合预测是否能提升预测性能?
问题3各类超参数是如何影响模型性能?
本文使用如下配置的计算机进行实验。CPU 为Intel(R)Xeon(R)Silver 4210 CPU @ 2.20 GHz,内存为64 GB,GPU 为2 块GeForce RTX 2080ti。
3.1 数据集描述及处理
为评估模型性能,本文使用公开数据集WS-DREAM 数据集。该数据集包含了339 个用户与5 825 个Web 服务交互的1 974 675 个真实QoS结果,包括响应时间和吞吐量两类重要QoS。
为去除无效数据,本文对响应时间数据集进行如下预处理。首先,舍弃响应时间为0(代表用户未调用该Web 服务)和响应时间超过20 s(代表响应时间过长,用户可能放弃调用该服务,所以该响应时间数据没有意义)的元素;然后,为保证联合预测时多类QoS的数据在同一个尺度,将响应时间数据集进行min-max 归一化,使其数据尺度为(0,1)。吞吐量数据集中的元素均为有效数据,故仅进行min-max 归一化。
现实中,用户通常只会调用少量的服务,从而导致QoS 数据的用户服务矩阵稀疏。考虑到预处理后的吞吐量矩阵和响应时间矩阵为稠密矩阵,为了在实验中模拟真实情况,本文在训练模型时使用训练集密度(DoT,density of training set)较低的QoS矩阵。例如,DoT=5%表示随机选择5%的QoS 作为训练集,剩余95%的QoS 作为测试集。
3.2 评估标准
为了评价模型的效果,本文采用以下2 种广泛使用的评价参数:均方根误差(RMSE,root mean square error)和平均绝对误差(MAE,mean absolute error)。
1) 均方根误差。RMSE 表示预测值与真实值偏差的平方与观测次数比值的平方根,反映了样本的分散程度。RMSE的计算方法为

2) 平均绝对误差。MAE 表示预测值和观测值之间绝对误差的平均值,其所有差值的权重相等。MAE的计算方法为

其中,ypred,i表示第i个预测QoS 值,ytrue,i表示第i个真实QoS 值。RMSE和MAE的值越小,表示模型预测的准确性越高,结果越好。
3.3 对比方法与消融实验
本文将JQSP 方法与基于邻域、基于因子分解模型和基于神经网络的CF 方法以及JQSP 方法的消融实验进行比较,以证明JQSP 方法的性能。
1) UIPCC[27]。UIPCC 结合了基于用户和基于项目的协作预测方法,采用PCC 来度量节点之间的相似度,并使用相似用户和相似服务进行QoS 预测。它属于基于邻域的CF 方法。
2) PMF(positive matrix factorization)[28]。PMF采用概率矩阵分解方法对用户−服务QoS 矩阵进行因子分解来提取隐藏特征,在面对大型稀疏数据集时具有良好的预测效果。它属于基于因子分解模型的CF 方法。
3) 深度神经模型(DNM,deep neural model)[29]。DNM 是一种基于上下文的QoS 预测模型,具有较好的预测精度,在面对挖掘异构上下文特征的任务时具有较好的稳健性和可扩展性。它属于基于神经网络的CF 方法,因其在所有对比方法中表现最优,本文选用该方法作为基准方法。
4) MLP-ANFM(multilayer perceptron-attention neural factorization machine)。MLP-ANFM 使用MLP 替代MGCN 模块作为编码器,和ANFM 模块一起组成完整的端到端模型。该方法的实验结果可论证MGCN 模块是否对QoS 预测的准确度有影响。
5) MGCN-MLP(multi-component graph convolutional network multilayer perceptron)。MGCNMLP 使用MLP 替代ANFM 模块作为解码器,和MGCN 模型一起组成完整的端到端模型。该方法的实验结果可以论证ANFM 模块是否能有效地利用特征交互信息来提升QoS 预测准确度。
6) Single-MGCN。Single-MGCN 使用单个MGCN 模块,同时去掉了加权融合层,使整个模型只训练和预测单类QoS。该方法的实验结果可以论证联合预测是否比单独预测更精确。
3.4 参数设置
考虑数据稀疏性的影响,本文将QoS 数据集按如下比例随机分成训练集和测试集:DoT={5%,10%,15%,20%,25%,30%},共6 个实验组,注意随机拆分时对齐多类QoS的用户标识和服务标识。然后,本文对所有方法在所有DoT 数据集上各进行5 次实验并取平均值,以评价QoS 预测性能并进行对比分析。
参考文献[4,30],JQSP 方法及其消融实验的参数设置如表1 所示。对于其他对比方法,本文分别按照其参考文献内的最佳参数进行设置。
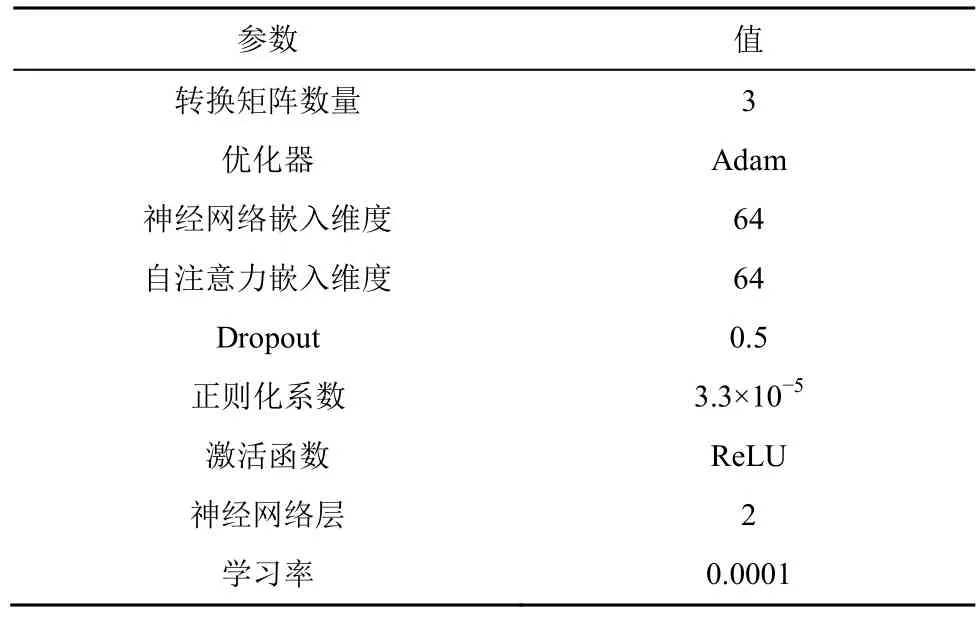
表1 参数设置
3.5 实验结果与分析
表2给出了基于响应时间数据集的所有QoS 预测评价结果,表3 给出了基于吞吐量数据集的所有QoS 预测评价结果,并对每个DoT 训练集的最优数据进行加粗表示。表2和表3 中Gains 计算方式如式(31)所示,代表了JQSP 方法与基准方法DNM 相比性能提升的程度。

3.5.1 不同模型预测性能比较(问题1)
由表2和表3 可以得出,对于RMSE和MAE两项评价指标,PMF 显著优于UIPCC,在训练集占比低的情况下更加明显,这说明了矩阵分解方法在缓解数据稀疏性问题上比基于邻域的方法表现更优。DNM 一定程度上优于PMF,在少数训练集占比上持平,这说明神经网络方法有比矩阵分解方法更优的建模能力。本文提出的JQSP 方法及其消融实验(即 MLP-ANFM、MGCN-MLP、Single-MGCN)在RMSE和MAE 上始终优于对比方法,并且在吞吐量数据集、DoT=30%的RMSE评价指标上相比基准方法DNM 有28.94%的提升率,这说明本文所提方法JQSP 相比其他基线方法有更优的表现。
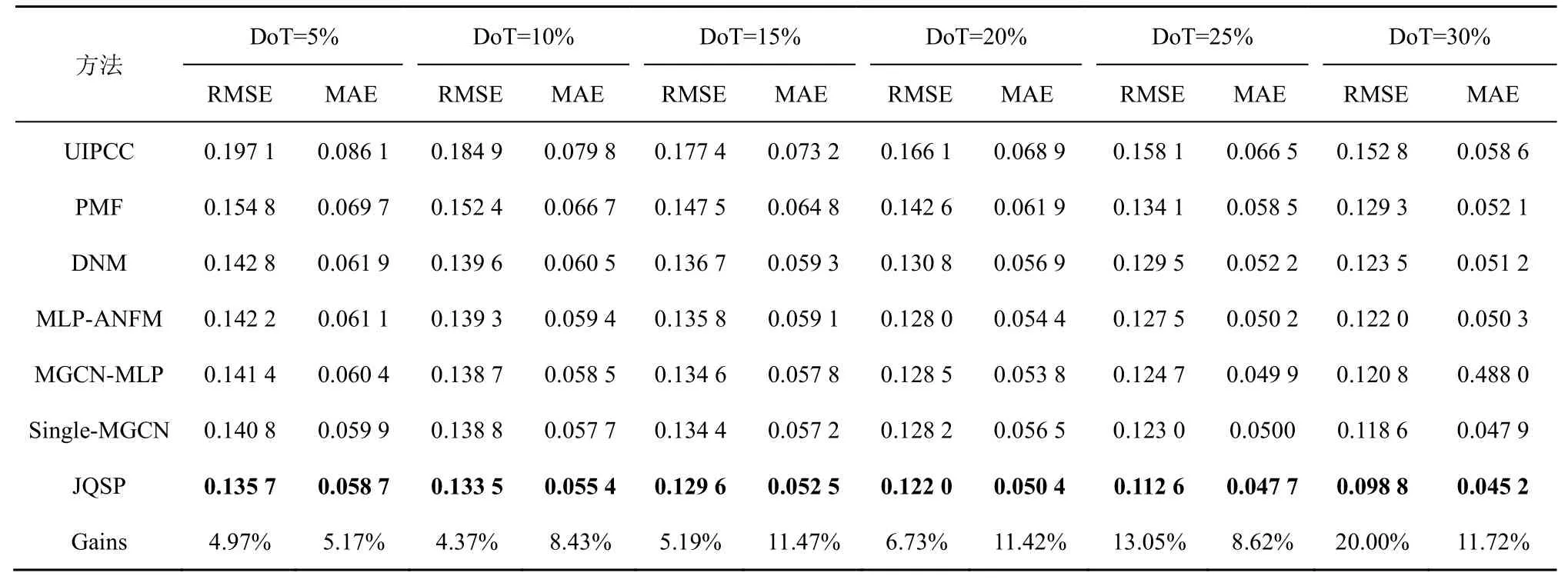
表2 基于响应时间数据集的所有QoS 预测评价结果

表3 基于吞吐量数据集的所有QoS 预测评价结果
3.5.2 JQSP方法与各消融实验预测性能比较(问题2)
对比表2和表3 中的MLP-ANFM 方法和JQSP方法可以看到,JQSP 方法性能全面领先MLP-ANFM 方法,这证明了用于提取环境偏好特征的MGCN 模块实现了以环境偏好特征为主要目标的细粒度潜在特征的挖掘,对QoS 预测准确度的提升有帮助。
对比表2和表3 中的MGCN-MLP 方法和JQSP方法可以看到,JQSP 方法依然有较优的表现,这证明ANFM 模块因为有效提取了输入向量的二阶及高阶交互特征而提升了预测的准确性,实现了特征深度融合。同时注意到 MGCN-MLP 方法和MLP-ANFM 方法的性能差距较小,说明MGCN和ANFM 这2 个模块对模型预测性能的影响是接近的,单独增加2 个模块中的任一个对整个模型性能的提升相差不大。
对比表2和表3 中的Single-MGCN 方法和JQSP 方法可以看到,JQSP 方法依然有着较大的领先优势,这证明了与提取单类QoS 特征相比,将多类相关的QoS 数据的特征映射到同一空间进行特征提取有更优的表现,QoS 联合预测实现了对多类QoS 潜在的共同特征的挖掘。同时注意到Single-MGCN 方法与MGCN-MLP和MLP-ANFM方法相比更接近JQSP 方法的表现,这说明与MGCN和ANFM 这2 个模块相比,单独应用联合预测框架对模型的预测精确度的提升较少,这可能是因为相比于MGCN 模块挖掘的QoS 矩阵中的环境偏好特征信息和ANFM 模块挖掘的二阶和高阶交互信息,Single-MGCN 所挖掘的多类QoS 潜在的共同特征信息的信息量更少,重要性更低,对模型性能提升的帮助更有限。
综上所述,本文提出的JQSP 方法中3 个主要子模块均产生了预期的作用,单独添加任一子模块都能有效提升模型的预测性能。
3.5.3 超参数影响分析(问题3)
本文针对以下超参数在DoT=30%的数据集上进行单一变量实验,以探究它们各自对JQSP 模型性能的影响:转换矩阵数m∈ {1,2,3,4,5},神经网络嵌入维度,自注意力嵌入维度。简便起见,本文仅列出响应时间数据集上的结果。
1) 转换矩阵数。转换矩阵数m代表模型捕获潜在环境偏好的数量,增加m可以提高模型的捕获能力,但过高的m可能超过了真实数据中的潜在环境偏好数,增加了模型复杂度的同时无法提升模型性能。从图4的实验结果可以得出,随着m的增加,模型性能有所提升,m=3时模型获得了最优的性能,后续进一步增加m无法获得明显性能提升,同时还会大幅增加模型训练的时间。

图4 转换矩阵数对模型性能的影响
2) 神经网络嵌入维度。嵌入维度表示神经网络层使用多少维度来表达特征,维度越高,表达特征越细腻,但过高的维度会引入过多的参数,可能造成过拟合和难以收敛的问题,大幅增加模型训练时间。从图5的实验结果可以得出,随着dneu增加,模型性能明显提高,dneu=64时模型获得最优表达能力,继续增加dneu反而导致性能下降。
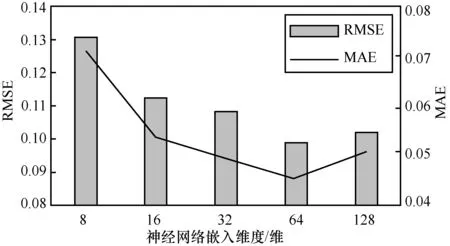
图5 神经网络嵌入维度对模型性能的影响
3) 自注意力嵌入维度。自注意力嵌入维度表示自注意力参数矩阵使用多少维度来表达自注意力特征。从图6的实验结果可以得出,从8 开始增加datt有效提升了模型的性能,datt=32时模型获得了最优的表达能力,继续增加datt降低了模型的性能。

图6 自注意力嵌入维度对模型性能的影响
4 结束语
本文提出了一种JQSP 方法用于多类QoS 联合预测,与现有的QoS 预测方法相比,所提方法具有以下优点:1) 所提方法能有效识别和挖掘用户偏好信息和服务偏好信息,从而为特征提取提供了更丰富的信息;2) 所提方法将多类相关QoS的特征映射到同一个空间进行特征提取,这能获取到处理单类QoS 无法获取的多类QoS 相关性特征;3) 所提方法引入带自注意力的因子分解机来挖掘特征提取向量中的一阶特征、二阶和高阶交互特征,并为交互特征赋予注意力权重,有效提升了特征提取的效果,该效果优于传统因子分解机和MLP。在未来的工作中,将考虑引入更丰富的异构信息来提升模型预测的精确度,同时考虑合理地简化模型结构,降低模型的训练时间,增加其可用性和稳健性。
猜你喜欢
能源工程(2022年2期)2022-05-23 13:51:50
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
重型机械(2020年2期)2020-07-24 08:16:16
装备制造技术(2019年12期)2019-12-25 03:07:36
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
