
基于正样本对比与掩蔽重建的自监督语音表示学习
2022-08-04 03:38:16张文林刘雪鹏牛铜陈琦屈丹
通信学报 2022年7期
张文林,刘雪鹏,牛铜,陈琦,屈丹
(信息工程大学信息系统工程学院,河南 郑州 450001)
0 引言
语音表示学习是指利用机器学习的方法自动提取语音信号的高层特征表示,该高层特征表示含有音素、说话人、语种等丰富的信息[1],可用于连续语音识别、说话人识别、语种识别等多种下游任务[2]。自监督语音表示学习利用大量无标注数据学习语音表示,可大大降低下游任务对标注数据的依赖。对于大部分的人类语言,标注数据的获取是十分困难的,一些语言甚至没有书面文字,而无标注语音的获取相对容易得多,因此自监督语音表示学习具有重要的研究意义和应用前景。
目前,常用的自监督语音表示学习方法主要有3 种[3-4]:基于对比预测的方法、基于掩蔽重建的方法和基于多任务学习的方法。基于对比预测的方法采用区分性模型,以对比预测为辅助任务,通过最小化某种分类损失来得到语音的表示;基于掩蔽重建的方法采用生成式模型,以语音重建为辅助任务,通过最小化某种重建损失来得到语音的表示;基于多任务学习的方法将对比预测任务和语音重建任务相结合,以期达到更好的语音表示效果。从实验结果来看[4],基于对比预测的方法通常优于基于掩蔽重建的方法,是目前研究语音表示学习最热门的方法。
基于对比预测的方法需要解决的主要问题是模型坍塌问题,即模型所有的表示输出都为一个常数。为了解决这一问题,现有方法往往需要精心设计某种随机采样机制以构造大量的负样本,将其与正样本进行对比,从而避免所有样本的输出都相同。目前,基于对比预测的自监督语音表示学习方法中[5-8],由于没有语音标注,通常使用相邻的语音帧作为正样本,对来自同一批次的数据进行随机采样以构造负样本。这种正负样本的选择方法没有经过很好的设计,不能保证采样得到的负样本质量,可能会出现错误的正负样本对,导致训练不稳定。具体实现中往往需要通过增大批次大小来保证训练的收敛性和模型的性能,因此,这类方法在训练过程中需要耗费大量的存储和计算资源,计算成本很高。
近年来,众多自监督图像对比表示学习的研究表明[9]负样本并不是训练所必需的,特别是Chen等[10]提出的SimSiam(simple siamese)模型使用简单的孪生网络进行自监督训练,只需要正样本进行对比学习,通过梯度停止技术有效避免了模型坍塌,在ImageNet 上训练100 个epoch 即可达到很好的学习效果。
在语音表示学习领域,目前还没有使用正样本对比学习方法的相关研究。本文将正样本对比学习技术应用于语音表示,并提出了一种结合正样本对比和掩蔽重建的自监督语音表示学习方法。SimSiam 模型[10]采用残差网络(ResNet,residual network)[11]作为表示学习的主干网络;与图像不同,语音信号是一种连续的变长序列,因此本文方法采用Transformer[12]作为语音表示学习的主干网络。本文所提语音表示学习方法仅需正样本进行对比学习,有效避免了大量负样本带来的模型训练困难问题,结合掩蔽重建任务,在低训练成本下得到了较好的语音表示。本文基于Librispeech 语料库[13]进行自监督表示学习,并在音素分类、说话人分类等下游任务上进行了测试验证,结果表明与现有模型相比,本文方法得到的模型在所有下游任务中的性能均达到或者超过了现有模型的性能。
1 相关工作
1.1 自监督语音表示学习
目前,自监督语音表示学习的主要方法有基于对比预测的方法、基于掩蔽重建的方法和基于多任务学习的方法3 种。
基于对比预测的方法主要基于对比预测编码(CPC,contrastive predictive coding)[5]的思想对模型进行自监督学习,利用编码器将语音映射到隐藏的表示空间,要求在表示空间可以对正负样本进行预测分类。这类方法的典型代表是Facebook的研究人员提出的wav2vec 系列模型[6-8]及其相关改进模 型[14-15],其中wav2vec 2.0 模型[8]已经在连续语音识别等多个下游任务上得到广泛使用,性能达到甚至超过了有监督学习的方法。HuBERT(hidden-unit bidirectional encoder representation from transformers)[14]在wav2vec 2.0 模型的基础上,通过K-means 聚类迭代生成离散的伪标签,把预测标签的任务用于模型的训练,该方法可视为对比预测编码的一种改进方法,即通过聚类得到数量固定的负样本进行对比学习。WavLM[15]沿用了HuBERT的思想,采用了更灵活的位置编码策略,引入更复杂的加噪和重叠语音数据扩展方法,增大了无标注训练数据的规模,使语音表示模型在13 个语音相关下游任务中达到最佳性能。上述方法的一个共同缺点是需要采用较大批次进行训练,训练过程中计算复杂度高,容易发生不稳定现象。
基于掩蔽重建的方法主要使用自回归预测编码(APC,autoregressive predictive coding)[16]或BERT(bidirectional encoder representation from transformer)掩蔽重构任务[17]等对表示模型进行自监督训练。例如,APC和矢量量化自回归预测编码(VQAPC,vector-quantized autoregressive predictive coding)[18]采用自回归模型,基于过去语音帧的编码信息来重建未来的语音帧;Mockingjay[19]、TERA(transformer encoder representation from alteration)[20]等模型通过对语音帧进行掩蔽重建来进行模型训练;pMPC(phoneme-based masked predictive coding)[21]在音素级进行掩蔽重构,以期模型学习到的表示能够包含更多的音素类别信息。
基于多任务学习的方法将上述2 种自监督学习任务进行结合,通过多任务训练的方式得到更有效的语音表示模型。典型代表有Speech SimCLR[22],它借鉴了图像自监督表示学习中SimCLR 模型[23]的对比训练任务,并将其与TERA 掩蔽重建任务相结合,证明了对比学习任务和掩蔽重建任务相结合的有效性。Zaiem 等[24]探索了多种自监督学习任务相互组合的方法。上述模型在对比学习任务中需要构建大量的负样本对进行对比学习,因此仍需要较大的训练批次,训练复杂度较高。
1.2 基于孪生网络的表示学习
在图像表示学习中,基于孪生网络的表示学习是目前研究的热门方向。孪生网络[25]通过对输入进行2 种不同增强,以最大化2 个分支输出的相似性进行训练。然而,如果只是拉近相似样本之间的距离,模型很容易得到一个退化解,即对于所有的样本输出都相同,这就是著名的模型坍塌问题。解决这一问题的一个自然想法是不仅要拉近相似输入之间的距离,也要使不同输入之间的距离变大,换句话说就是不仅要有正样本对,也要有负样本对。这种方法确实解决了模型崩塌的问题,但是也带来了一个新的问题,那就是对负样本对的数量要求较大,只有这样才能训练出足够强的特征表示能力。例如,MoCo(momentum contrast)[26]通过一个记忆库来存储所有样本的特征,从而维护了一个庞大的负样本队列。SimCLR[23]通过9 000 以上的批次大小来保证有足够数量的负样本供对比学习。
然而,最新的研究结果表明,为了保证图像表示模型不发生坍塌,负样本并不是必需的。例如,BYOL(bootstrap your own latent)[9]基于孪生网络构造了在线网络和目标网络2 个子网络,2 个子网络分别通过反向传播和动量编码器更新参数,利用在线网络的输出预测目标网络的输出,从而在不使用负样本的情况下避免了模型坍塌。SimSiam[10]进一步去除了动量编码器,将2 个子网络进行权值共享,对目标网络使用梯度停止策略,从而仅依靠正样本使模型学习到有意义的表示。SimSiam 方法的模型构造和训练过程更简单,只需要小的训练批次即可进行表示学习,本文的自监督语音表示学习中的对比学习任务即受其启发而来。
2 所提模型
2.1 模型结构
基于正样本对比与掩蔽重建的自监督语音表示学习模型如图1 所示。模型采用孪生网络结构,由2 个分支组成,其中右分支包含一个用于对输入的语音信号进行编码表示的编码器(Enc)、一个用于根据编码表示对原始语音进行重建的预测器(Pre);左分支除了编码器和预测器外,还包含一个映射器(Proj)。在模型训练过程中,首先对输入的语音帧x进行两路增强得到正样本对x1和x2,将其分别送入孪生网络的2 个分支中。左分支对x1进行编码得到特征表示z1,右分支对x2进行编码得到特征表示z2。将z1、z2分别送入左、右分支的预测器,得到重建的语音帧分别计算重建损失函数。对于语音表示z1,还将其送入左分支的映射器得到输出来对右分支的语音表示z2进行预测,映射器的输出p1的维度与语音表示z1、z2相同,计算p1与z2之间的余弦距离作为对比预测损失函数,并对其进行最小化以使两路输出更相似。将z1、z2的重建损失函数及对比预测损失函数进行求和作为最终的损失函数,采用梯度下降法对其进行优化,从而实现语音表示的多任务学习。
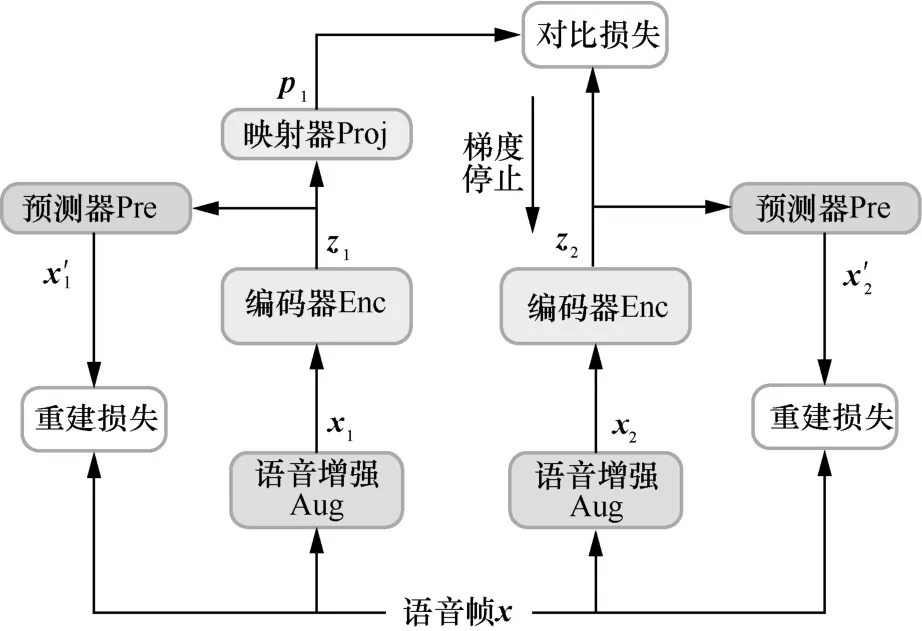
图1 基于正样本对比与掩蔽重建的自监督语音表示学习模型
在图像的正样本表示学习中,采用ResNet[11]作为编码器。与图像不同,语音信号是一个连续的变长序列,具有长时相关性,因此在本文方法中左右分支的编码器均采用多层Transformer 编码器[12]的堆叠实现。其中每一个编码器层由一个多头自注意力层和一个前向层组成,将编码器的最后一层输出视为最终的语音表示。模型中的预测器和映射器均采用两层前向网络,仅在语音表示学习(即预训练)阶段使用,表示学习结束后仅保留编码器,将得到的语音表示作为下游任务的输入特征。
2.2 数据增强
针对语音数据,本文采用加入高斯噪声、时间掩蔽、频率掩蔽3 种方式对输入的语音进行随机扰动获得增强后的语音数据,以得到孪生网络2 个分支的输入数据。考虑到在测试阶段并不会对输入模型的语音数据进行增强,为了减少训练与测试的不一致,对左右2 个分支均以概率pa进行随机增强。
具体地,对于一条输入语音帧x,根据[0,1]上的均匀分布进行采样得到p∈[0,1],当p≥pa时进行语音增强,否则不进行语音增强。增强后的语音数据为

其中,Aug(x)表示对输入语音x进行随机扰动,实验中通过Specaugment 工具箱[27]实现。
2.3 正样本对比损失函数计算及模型训练方法
在模型训练过程中,左右2 个分支的编码器和预测器共享相同的权值。最终总的损失函数由重建损失和预测损失两部分组成。其中,重建损失为使用左右2个分支编码输出z1和z2对原始语音帧x进行重建的误差。借鉴TERA 模型[20]中的做法,本文使用L1 距离来衡量语音帧的重建误差,总重建损失为

其中,l1为L1 距离分别为左右2 个分支的重建语音帧。
预测损失由左右2 个分支的语音特征表示z1、z2进行相互预测计算得到。由于z1、z2分别对应同一个输入语音帧x的不同增强x1和x2,可视为正样本对,因此在训练预测任务时只需要最大化预测值与预测目标之间的余弦相似度即可。
为防止模型坍塌,在反向传播过程中,对右分支执行梯度停止操作,不对其模型参数进行梯度计算。图像自监督学习方法SimSiam[10]从实验验证和理论证明2个角度证明了梯度停止在仅采用正样本进行对比学习中的重要性。从理论上看,梯度停止操作相当于将语音表示视为隐藏变量,引入除模型参数之外的第二组参数,采用EM(expactation maximization)算法,通过两组参数的迭代更新得到表示模型参数的近似最优估计。
综上所述,采用梯度停止技术后,根据z1对z2进行预测的损失函数为

其中,stopgrad(⋅)表示梯度停止操作;Proj(z1)表示z1经过预测器后的输出;cos(⋅)表示矢量间的余弦距离,其计算式为

实际中由于左右2 个分支的编码器参数完全相同,为了更高效地利用训练样本,可同时计算根据z2对z1进行预测的损失函数,得到对称的总预测损失函数为

结合式(2)和式(5),最终训练总损失函数为

TERA 模型[20]中,将重建损失函数和对比预测损失函数的权重均设置为1。采用上述损失函数进行梯度下降训练,最终将学习到的编码器Enc 作为语音表示模型。
3 实验
3.1 实验设置
实验中使用公开数据集Librispeech[13]训练语音表示模型。为了验证不同数据量下模型的性能,分别使用其中的100 h 无标注数据(train-clean-100)和960 h 无标注数据(包括train-clean-100、train-clean-360、train-other-500)进行自监督训练。编码器为3 层Transformer 编码器,隐含层维度为768,注意力头为12 个,前向层维度为3 072,dropout 概率为0.1。预测头和投影头均由2 个线性层构成,隐含层维度为768。编码器的输入为80 维美尔谱,帧长为25 ms,帧移为10 ms。
将最后一层编码器的输出作为最终的语音表示,后接一个任务相关的分类器或预测器用于下游任务。在下游任务训练中,语音表示模型有2 种使用方式:一种是将编码器参数冻结,仅作为特征提取器使用;另一种是将编码器参数与下游任务相关的模型参数共同在下游任务的标注数据上进行微调训练。预训练模型经过微调后更适应具体下游任务的需要,因此在测试中具有更好的效果。
实验中测试了音素分类、说话人分类及连续语音识别等下游任务的性能。其中,音素分类任务遵循CPC[5]的实验设置,使用CPC 给出的数据集划分方式将train-clean-100 划分为训练集和测试集,分别比较了使用单层线性层的分类器和含一个隐含层的分类器的识别性能,下文中将上述2 种分类器的实验结果分别记为lib-plin和lib-phid;同时实验中也测试了在TIMIT(Texas Instruments/Massachusetts Institute of Technology)数据集[28]上使用单层线性层作为分类器的实验结果,记为timit-plin。训练过程中预训练模型参数被冻结。
在说话人分类任务中,同样遵循CPC[5]的实验设置,使用CPC 给出的数据集划分方式将train-clean-100 划分为训练集和测试集,使用单层线性网络作为分类器,测试模型的帧级说话人分类准确率,记为spk-fr。训练过程中预训练模型参数被冻结。
在连续语音识别任务中,将语音表示作为特征输入,以 Conformer 模型[29]为声学模型,以Transformer 解码器为语言模型构建连续语音识别系统,分别使用Librispeech的100 h和960 h的有标注数据作为训练集对模型进行训练,测试系统在test-clean 子集上的词错误率(WER,word error rate)。训练过程中预训练模型参数与语音识别系统一起微调训练。
3.2 100 h 无标注数据实验结果
本节使用train-clean-100 对表示模型进行预训练,测试其在音素分类和说话人分类任务上的性能。同时采用加入高斯噪声、时间掩蔽和频率掩蔽3 种数据增强方式,对图1 中左右2 个分支的输入均以概率pa进行随机增强。模型训练过程中使用4 个1080Ti GPU,总的训练批次大小为8(约12 s 语音数据),训练总步数为200 000 步。在训练下游任务时,语音表示模型的参数被冻结,仅作为特征提取器使用。
首先,对不同的数据增强概率pa进行了对比实验,分别测试了pa=0.5、pa=0.8、pa=1.0 时的模型性能。不同数据增强概率时模型在下游任务中的实验结果如表1 所示。表1 中还给出了仅对左分支输入进行增强(单路增强)的效果。

表1 不同数据增强概率时模型在下游任务中的实验结果
从表1 可知,在音素分类任务上,pa= 0.5时模型性能最佳;在说话人分类任务中,单路增强的模型结果最佳,pa= 0.5时模型准确率与之接近,仅相差0.04。因此,在后面的实验中,取pa= 0.5进行增强。
进一步地,分别测试了本文模型在仅使用重建损失、仅使用正样本对比损失及使用多任务学习时的性能,同时还对比测试了使用相同训练数据的Mockingjay、TERA 模型的性能。100 h 无标注数据下的实验结果如表2 所示。
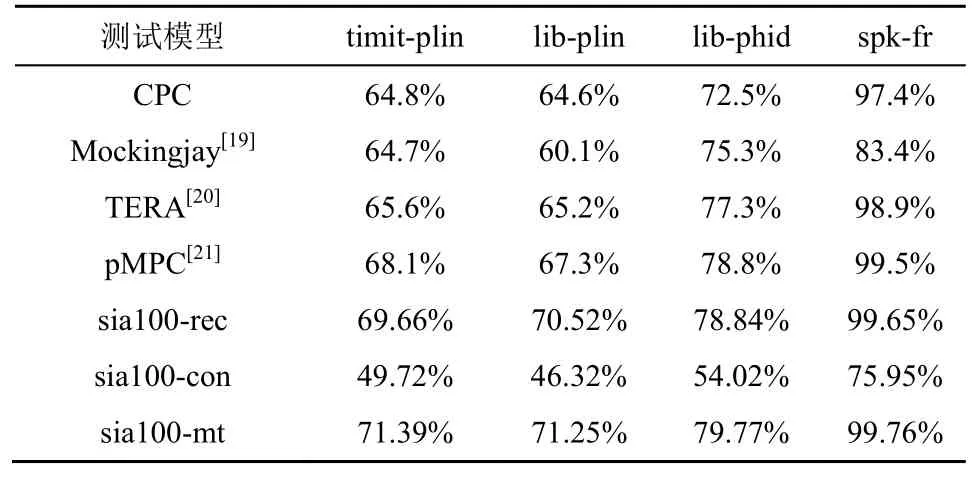
表2 100 h 无标注数据下的实验结果
表2中,sia 表示本文模型,100 表示训练数据为100 h,rec、con和mt 分别表示仅使用重建损失、仅使用正样本对比损失和使用多任务学习时的实验结果。例如,sia100-rec 表示本文模型在100 h 训练数据、仅使用重建损失时的实验结果。
仅使用重建损失的模型(sia100-rec)可以看作对TERA 模型进行了数据增强,从表2 可知,其在各下游任务中的性能均优于TERA 模型。仅使用正样本对比损失的模型(sia100-con)能够学习到一定的信息,但是性能相对较差,本文推测这是由于模型在训练过程中仅对单个语音帧进行对比,可供利用的信息较少,导致模型无法得到充分训练。使用正样本对比和重建损失进行多任务学习的模型(sia100-mt)在所有下游任务的测试中性能均达到最佳,验证了本文模型的有效性。
3.3 960 h 训练数据实验结果
本节进一步在960 h 无标注数据上对模型进行训练,参数设置与3.2 节实验基本相同。总的训练批次大小设置为8(约12 s 语音数据),训练总步数为1000 000。实验结果如表3 所示。
从表3 可知,本文模型(sia960-mt)在所有下游任务中性能均优于TERA 模型。在说话人分类任务(spk-fr)和TIMIT 数据集上的音素分类任务(timit-plin)中,本文模型(sia960-mt)的准确率超过了wav2vec 2.0-Base 模型;在librispeech的音素分类任务(lib-plin和lib-phid)中,性能略低于wav2vec 2.0-Base 模型。出现这一结果的原因在于,本文模型参数量较少,学习的语音表示复杂性相对大模型来说较低,具有更好的线性可分性,因此音素分类任务在单层线性分类器上表现更优,而在使用多层线性层作为分类器时,测试的准确率相比wav2vec 2.0-Base 模型略低。

表3 960 h 无标注数据的测试结果
本文进一步增大了模型训练的批次大小,将总的训练批次增大到32,训练总步数为1 000 000 步,表示为sia960-mt-bs32。从实验结果看,增大训练批次能进一步提高语音表示模型的性能,在所有下游任务测试中均取得了更好的结果。
由于本文模型参数数量仅为wav2vec 2.0-Base模型的且仅使用正样本进行对比学习,因此可以在仅使用4 个2080Ti GPU、总的训练批次大小为32(相当于48 s 语音数据)时即取得较好的训练效果,模型训练所需时间约为9.5 天。与之相比,相同训练数据量条件下,wav2vec 2.0-Base 模型在训练过程中使用了64 个V100 GPU,总的训练批次大小为1.6 h。如表4 所示,在不考虑不同GPU 性能的情况下,本文模型的预训练时间相当于使用单个GPU 预训练38 天,wav2vec 2.0-Base 模型则相当于使用单个GPU 预训练102 天。因此,本文方法训练更高效,所需计算资源更少,实际中更有利于模型的推广应用。表4 中,下游任务训练速度和推理速度为归一化结果。在推理时间上,使用单层线性层进行音素分类任务的测试时,wav2vec 2.0-Base 模型在测试集上的推理时间为3.8 min,本文模型仅需要1.7 min,推理速度是wav2vec 2.0-Base 模型的2.2 倍。

表4 本文模型与wav2vec 2.0-Base 模型参数量、训练资源比较
3.4 语音识别
连续语音识别任务使用ESPnet 工具箱[30]实现,使用960 h 无标注数据对表示模型进行预训练,本节分别在100 h和960 h 有标注数据条件下对连续语音识别模型进行微调,以分别模拟低资源和高资源训练条件,分别测试模型在test-clean 子集上的WER,测试结果如表5 所示。声学模型采用Conformer 模型,Trans 表示语言模型采用Transformer 解码器结构,4-gram 表示采用四元文法语言模型。
从表5的实验结果可知,在使用100 h 有标注数据进行微调时,与相同规模参数量的模型相比,sia960-mt 与Speech SimCLR的WER 最低,为5.7%;进一步将训练批次大小增加至32 后,sia960-mtbs32的WER 进一步降低,为5.5%。这一实验结果与相同训练数据量(100 h 有标注数据)下的wav2vec 2.0-Base和HuBERT-Base 相比还有一定的差距。使用960 h 有标注数据进行微调后,sia960-mt与wav2vec 2.0-Base和HuBERT-Base 模型相比,WER 仅差0.3%和0.2%,而参数量仅约为它们的增大训练批次大小后,sia960-mt-bs32 模型的性能进一步提高,WER 降低到2.3%。

表5 语音识别任务测试结果
3.5 SUPERB 基准测试
SUPERB[4]是一个语音处理通用性能基准排行榜,旨在为语音社区提供一个标准和全面的测试平台,用于评估预训练模型在涵盖语音所有方面的各种任务上的可推广性,通过10 多个任务来测试语音表示对语音内容、说话人、语义和副语言4 个方面的表达能力。
本节主要在SUPERB的6 个任务上对本文模型进行测试,具体如下。
音素识别(PR,phoneme recognition)任务。使用LibriSpeech 数据集的train-clean-100、dev-clean、test-clean 子集分别作为训练集、验证集、测试集,测试的评价指标为音素错误率(PER,phone error rate)。
关键词识别(KS,keyword spotting)任务。使用Speech Commands v1.0 数据集,包含10 种关键词、静音和未知,评价指标为准确率(ACC,accuracy)。
意图分类(IC,Intent classification)任务。在话语级对说话人的意图进行分类,使用Fluent Speech Commands 数据集[31],评价指标为ACC。
说话人辨认(SID,speaker identification)任务。在话语级进行分类,使用VoxCeleb1 数据集[32]进行训练和测试,评价指标为ACC。
实例查询口语术语检测(QbE,query by example spoken term detection)任务。采用QUESST 2014[33]挑战赛中的英语子集,评估指标是最大项加权值(MTWV,maximum term weighted value),能更好地平衡漏检和虚警。
说话人确认(SV,speaker verification)任务。使用VoxCeleb1 数据集,采用x-vecter[34]作为下游模型,评价指标为等错误率(EER,equal error rate)。
实验中采用SUPERB 默认的测试方法对上述6 个任务进行测试,其中预训练模型仅作为前端的特征提取器,参数保持冻结。
表6中展示了多种自监督预训练模型在SUPERB 基准上的测试结果。从表6 中可以看出,当使用本文自监督语音表示模型学习的表示作为下游任务的输入时,在绝大多数任务上相比log-Mel谱均有明显提升。本文模型与参数量相近的模型相比,在所有任务上性能都达到最佳;与参数量大得多的wav2vec 2.0-Base和HuBERT-Base 模型相比,在多数任务上也有相当的表现,特别是在SID 任务上,性能甚至超过了wav2vec 2.0-Base和HuBERT-Base模型。

表6 多种自监督预训练模型在SUPERB 基准上的测试结果
4 结束语
本文提出了一种新的自监督语音表示学习方法,该方法基于孪生网络结构,将仅使用正样本的对比学习任务和掩蔽重建任务相结合,以多任务学习的方式实现自监督语言表示学习。与现有方法相比,本文方法仅使用了正样本进行对比学习,通过梯度停止策略防止模型坍塌,仅需要较小的批次大小即可进行训练。在音素分类、说话人分类和连续语音识别等下游任务中的实验测试表明,与TERA等同等参数量下的其他模型相比,本文方法具有更好的性能;同时,与wav2vec2.0-Base 等参数量大得多的表示学习方法相比,本文方法在大大降低模型训练的存储和计算开销的同时达到甚至超过了其性能,具有良好的应用推广价值。
