
基于语义融合的域内相似性分组行人重识别
2022-08-04 02:14:38寇旗旗黄绩程德强李云龙张剑英
通信学报 2022年7期
寇旗旗,黄绩,程德强,李云龙,张剑英
(1.中国矿业大学计算机科学与技术学院,江苏 徐州 221116;2.中国矿业大学信息与控制工程学院,江苏 徐州 221116)
0 引言
行人重识别[1-2]任务的目标是在同一区域内的多个摄像机视角中识别并匹配具有相同身份的人,它在智能监控系统中发挥着重要作用。该任务可以分为有监督和无监督2 种情况,近年来,有监督重识别任务所取得的优异成果给学术界留下了深刻印象,但由于训练数据集包含标签,不仅标注成本巨大,而且在实际测试时不具备实时获取目标域标签的能力,导致监督行人重识别难以满足实际应用的需求[3]。此时,无监督训练的优势便体现出来,利用有标签的源域数据集训练出具有较强泛化性的网络,应用于无行人标签的目标域,这类网络称为无监督跨域行人重识别网络。
在网络跨域训练过程中,为了解决标签问题,通常采用聚类的方式为行人分配伪标签,节省了人工标注的成本。深度卷积神经网络通过堆叠卷积层和池化层来学习判别特征,由于输入行人图片情况各异,如行人身体错位和区域比例不一致等,导致识别的准确率受影响。其中,身体错位一般有2 种情况:1) 人在行走时被相机抓拍导致姿态不同;2) 由于检测不完善,导致同一行人在不同图像中的身体部位出现区域比例不一致问题。在网络对特征向量进行聚类时,上述问题产生的噪声会直接影响聚类结果的准确性。
此外,在域自适应过程中不同数据域相机风格或背景风格等存在差异性,这种差异性对网络的泛化能力是一种巨大的考验。为了缩小这种差异,目前有2 种主流方法:1) 通过增强数据集或网络重新生成数据集的方式,加大训练样本的数量来提高网络识别性能[4-5];2) 基于生成对抗网络(GAN,generative adversarial network)将图像外观从源域转换到目标域,从而增加2 个域的相关性[6-7]。上述针对数据集操作的方法均是对源域和目标域之间相关性的考虑,目标域内训练样本中存在的相似性并未被进一步挖掘,且在网络学习过程中增加了额外计算成本。
针对图像身体错位等因素导致聚类结果不准确的问题,本文提出一种简洁高效的基于语义融合的域内相似性分组网络。本文的主要贡献如下。
1) 本文网络在Baseline 网络的基础上创新性地添加了两层语义融合层,实现对网络中间特征图的细化处理,增强卷积神经网络提取特征的辨识度,其中,本文提出的语义融合层包含空间语义融合(SSF,spatial semantic fusion)和通道语义融合(CSF,channel semantic fusion)2 个模块。
2) 在不增加额外计算成本的前提下,本文利用域内行人的细粒度相似性特征,将网络的输出特征图水平分割为两部分,通过聚类的方法根据全局和局部各自的域内相似性对行人进行分类,使同一行人被分配多个伪标签,构成新的数据集。被分配相同伪标签的不同行人图片具有许多相似性,通过新的数据集对预训练模型进行微调来迭代挖掘更精确的行人分类信息。
3) 与近年会议中提出的算法相比较,本文算法在DukeMTMC-ReID、Market1501和MSMT17这3 个公共数据集上的跨域识别率得到显著提升,算法的直接效果通过热图以及检索排序等方式进行展示。
1 相关工作
1.1 跨域行人重识别
最近,众多学者密切关注跨域行人重识别算法,利用在源域中训练的重识别模型以提高对未标记目标域行人的识别性能,跨域行人重识别也称作无监督域自适应行人重识别,它解决了不同域间差异性的挑战。但是,由于源域训练的模型对目标域中特征变化很敏感,在使用预训练模型适应目标域时必须考虑到图像的变化,当前无监督域自适应行人重识别的解决方案可以分为三类:图像风格迁移、中间特征对齐和基于聚类的方法[8]。
在图像风格迁移方法中使用基于生成对抗网络[9]是当下流行的方法。ECN(exemplar-cameraneighborhood)[10]利用迁移学习并使用示例记忆最小化目标不变性来学习不变特征;多视图生成网络CR-GAN(context rendering GAN)[6]着眼于背景风格,通过掩盖目标域图像中的行人以保留背景杂波,叠加源域中行人和目标域背景作为输入图像来训练模型。但是,GAN的训练过程复杂,而且会引入额外的计算成本,因此不适用于实际场景。
中间特征对齐方法旨在减少域间特征和图像级别的差距,假设源域数据集和目标域数据集共享一个共同的中间特征空间,该共同中间特征可以用于跨域推断人员身份。D-MMD 损失(dissimilaritybased maximum mean discrepancy loss)[11]通过使用小批量来关闭成对距离,实现特征对齐;基于补丁的无监督学习(PAUL,patch-based unsupervised learning)[12]框架假设如果两幅图像相似,那么图像间存在相似的局部补丁;PAUL[12]并不学习图像全局级别特征,而是为行人识别提供局部细节级别特征。
基于聚类的方法通常根据聚类结果生成硬伪标签或软伪标签,然后根据带有伪标签的图像训练模型和交替迭代这2 个步骤使模型达到最优。深度软多标签参考学习模型MAR[13]根据特征相似性和分类概率之间的差异挖掘潜在的成对关系,然后使用对比损失加强挖掘的成对关系;UDAP(unsupervised domain adaptive person re-identification)[4]计算重排序的距离后对目标图像进行聚类,然后根据聚类结果生成伪标签;SAL(self-supervised agent learning)[14]算法通过利用一组代理作为桥梁来减少源域和目标域之间的差异。
上述3 种域自适应行人重识别方法在训练时通过缩小源域和目标域之间的差距从而提高模型的泛化能力,然而忽略了目标域内同一行人自身存在一定的相似性。利用这一特性,本文对目标域行人特征进行上下分块,聚焦于行人图像上下部分的非显著性特征,用聚类的方法将两部分特征进行聚类,为行人共分配3 种伪标签。
1.2 建模尺度变化
针对公共数据集内存在的图像尺寸和人物比例不一致的问题,近年已有研究增强对尺寸和比例变化的特征表示能力。传统方法一般采用尺寸不变的特征变换,如 SIFT(scale invariant feature transform)[15]和ORB(oriented FAST and rotated BRIEF)[16];对于卷积神经网络,通过图像对称、尺度变换和旋转等操作对数据进行转换。然而,此类方法采用固定尺寸的卷积核进行操作,导致其对于未知的转换任务存在局限性。此外,一些其他方法自适应地从数据域中学习空间转换:STN(spatial transformer network)[17]通过全局参数变换来扭曲特征图;DCN(deformable convolutional network)[18]用偏移量增加了卷积中的采样位置,并通过端到端的反向传播来学习偏移量。
上述方法均通过对网络进行大数据量的训练来得到图像变换参数,这对于数据量有限的行人识别任务来说并不合适。本文提出的空间语义融合模块计算空间语义相似度,对相同身体部位信息进行聚集,无须进行参数训练。而且,在语义融合层中的通道语义融合模块通过建模计算通道之间存在的相关性,显著增强了特征的表示能力。
2 基本原理
参照现有的大多数跨域识别网络在源域数据集上对模型进行预训练的方式,本文利用在ImageNet[19]上预训 练好的 ResNet50[20]作 为Baseline 网络。如图1 所示,在Baseline 网络layer2和layer3后分别添加语义融合层(虚线框内2 个深灰色层)作为主干网,为中间特征图融合更多语义信息。将原网络最后的全连接(FC,fully connected)层替换为两层维度分别为2 048和源域身份数的全连接层。将网络输出的特征图F水平切分为上下两块Fup和Fdn,由此可以获取更多的细粒度特征。分别对特征图F、Fup和Fdn进行全局平均池化(GAP,global average pooling)操作得到特征向量。然后将不同行人图像的特征向量分组并分配伪标签。通过最小化每组伪标签的三元组损失Ltri来迭代更新模型。

图1 整体网络结构
2.1 语义融合层
语义融合层依次对空间和通道信息进行融合。空间语义融合模块根据输入行人图像的姿态和尺度自适应地确定感受野。给定来自卷积神经网络的中间特征图,利用相似特征和相邻特征之间的高相关性特点,自适应地定位各种姿势和不同比例的身体部位,以此来更新特征图。将更新后的特征图经过批量归一化(CBN,batch normalization)层与原特征图构成残差结构,再将结果进行通道语义融合。通道语义融合模块是通道之间的相关语义融合,实现小规模视觉线索的保留。图2 为语义融合层的网络结构,残差结构可以使融合层保持良好的性能。
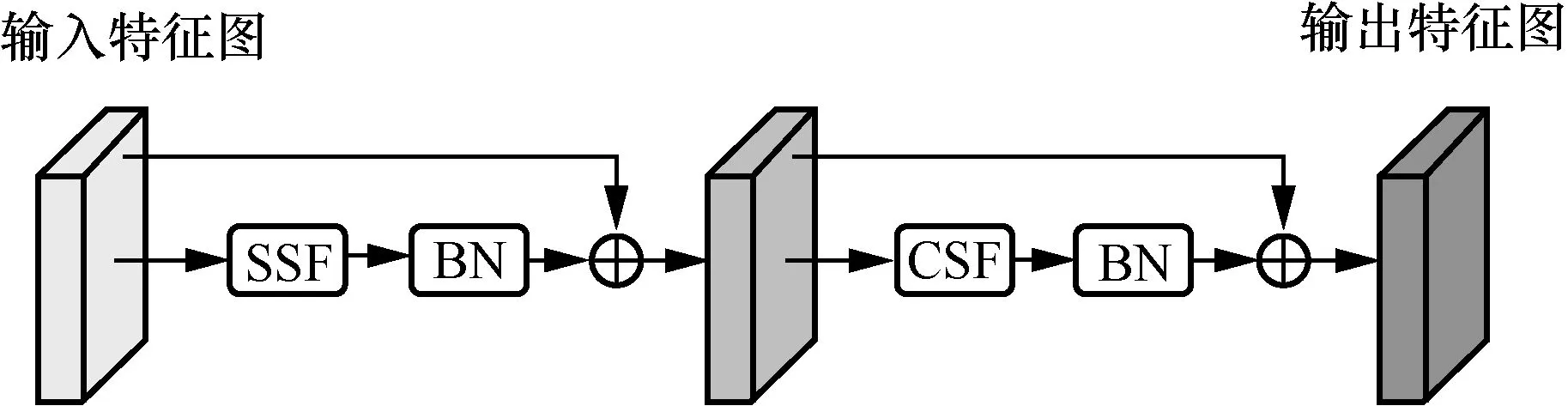
图2 语义融合层的网络结构
2.1.1 空间语义融合模块
受限于卷积神经网络的固定网络结构,卷积层在固定位置对特征图进行采样,池化层以固定比例降低空间分辨率。由于特征图感受野一般为矩形,导致感受野对行人不同姿态适应性较差。此外,固定大小的感受野对于不同尺寸的身体部位进行编码是不合适的。为了解决这个问题,本文对中间特征图进行空间语义融合,通过建模空间特征的相互依赖关系,自适应地确定每个特征的感受野,从而提高特征对身体姿势和比例变化的稳健性。
空间语义融合模块如图3 所示。假设给定一个特征图F∈RC×H×W,其中C、H和W分别表示通道数、特征图高度和宽度。首先,将F重塑为F∈RC×M,其中M为空间特征的数量(M=H×W);然后,从特征图的外观关系和位置关系两方面对空间特征进行依赖性建模,生成语义关系图S;最后,融合特征图F和语义关系图S,生成新的融合特征图。

图3 空间语义融合模块
对于外观关系,通过测量输入特征图中任意两位置之间的外观相似性来生成外观关系映射图。Du等[21]提到在相邻空间位置的局部特征具有重叠的感受野,所以它们之间有较高的相关性。因此涉及相邻位置的感受野可以获得更精细的外观。假设fi,fj∈RC表示特征图F中第i个和第j个空间位置的特征,分别选取i和j位置周围大小为E×E的感受野,然后通过累加相应位置特征之间的点积,使用SoftMax 函数对F中的所有空间位置进行归一化处理得到外观相似性,计算式为

其中,pi,e和pj,e分别表示感受野大小为e的i和j位置上的特征,表示感受野大小为E对应的外观关系图。
根据式(2)融合不同尺寸E的感受野,得到对身体部位更稳健的关系图。SoftMax 函数可以抑制不同部位较小的相似度,通过式(2)可以得到外观关系图S1。
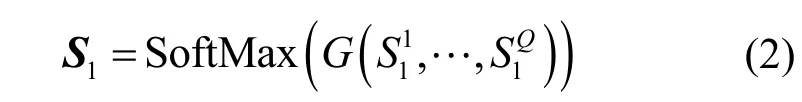
其中,G为具有元素乘积的融合函数,Q为不同尺度感受野的数量。
对于位置关系,行人图像对应于相同的身体部位特征在空间上相近,通过二维高斯函数可以计算空间特征fi和fj之间的位置关系,即
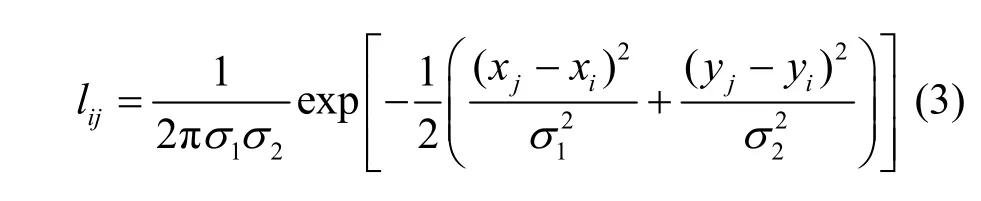
其中,(xi,yi)和(xj,yj)分别为fi和fj的位置坐标,(σ1,σ2)为二维高斯函数的标准差。通过式(4)规范化lij,使其关系值之和为1,记位置关系图为S2。

最后,根据式(5)将外观关系图和位置关系图进行融合,得到空间语义关系图S。
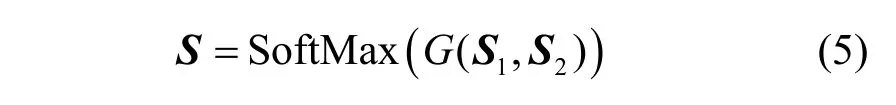
为了在原特征图内融入空间特征,通过两者相乘的方式得到融合特征图Fs,计算式为

2.1.2 通道语义融合模块
通常,卷积神经网络经过下采样处理后会丢失很多细节信息,然而这些细粒度信息对于行人的区分往往起到重要的作用,比如在困难样本对中,通过利用衣服纹理或背包等细节信息,可以区分2 个不同的身份。根据Zhang 等[22]提到的大多数高级特征的通道图对特定部分会表现出不同反应,融合不同通道中的相似特征,也可以增强行人独有的特征。
通道语义融合模块如图4 所示。同空间语义融合一样,重塑特征图为F∈RC×M,将得到的F和自身转置矩阵FT相乘,并将结果进行归一化处理得到通道关系图C∈RC×C,计算式为
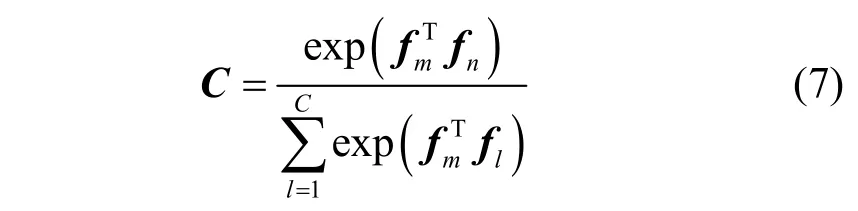

图4 通道语义融合模块
其中,fm和fn分别表示F的第m和第n通道中的特征。通过式(8)将通道关系图和原特征图进行融合得到新的融合特征图Fc。

2.2 细粒度信息的密度聚类
受到Wang 等[23]提出的监督训练分割方法的启发,即从细粒度中可以提取出更多有用的信息。考虑到目标数据集中行人特征从全局到局部存在潜在的相似性,本文利用密度聚类方法[24]对全局和局部特征进行聚类,结合这两部分信息能够获得更稳健和有辨识度的行人特征表示。网络中语义融合层很大程度降低了可能因数据集产生的聚类噪音。

对于式(9)中的每组特征向量,利用密度聚类算法得到相应的伪标签组,即每个身份根据它所属的组分配一个伪标签。经过主干网后,每张图像xi对应3 个伪标签,分别表示为因此,可以基于3 个特征向量分组结果组成一个有标签的数据集X,如式(10)所示。此外,如图1 所示,特征向量fi通过一个维度为2 048的全连接层,旨在获取一个全局嵌入向量其伪标签与特征向量fi共享。

2.3 损失函数
为了学习到更具判别力的特征,本文在预训练网络损失函数上联合使用难样本挖掘的三元组损失和SoftMax 交叉熵损失。为每个小批量随机采样P个身份和K个实例,以满足难样本三元组损失的要求。三元组损失函数为

对于Baseline 网络的训练,利用SoftMax 交叉熵损失提高网络判别学习能力,其计算式为

其中,ya,i为第i个身份的K张图像中第a张图像的真实标签,H为身份的数量。通过式(13)将2 种损失函数进行组合,从而实现对预训练网络的更新。

对于域迁移网络的训练,目标域图片输入网络后,将聚类生成的伪标签作为监督信息,使用三元组损失对预训练模型进行跨域自适应微调。损失函数包含全局、上分块、下分块、全局嵌入4 个部分,计算式为

3 实验及结果分析
3.1 实验数据集
实验主要在3 个行人数据集上对网络进行评估,包括Market1501[25]、DukeMTMC-ReID[26]和MSMT17[27]。
Market1501[25]数据集图像由6 台相机捕捉,共包含身份1501 个,总图像数量达到32 668 张。其中,训练集身份有751 个,图像有12 936 张;query 图像共有3 368 张,身份有750 个;gallery 图像共有15 913张;身份有751 个。
DukeMTMC-ReID[26]数据集是由8 台相机捕捉的包含1 812 个不同行人的重识别公开数据集,其中有1 404 个身份同时出现在2 台及以上的相机中,其余408 个身份用作干扰项。数据集包含训练集图像共有16 522 张,身份有702 个;query 图像共有2 228 张,身份有702 个;gallery 图像共有17 661 张,身份有1 110 个。
MSMT17[27]数据集是一个接近真实场景的大型数据集,由15 个相机捕捉图像共有126 441 张,身份有4 101 个。其中训练集图像有30 248 张,身份有1 041 个;query 图像有11 659 张,身份3 060 个;gallery 图像共有82 161 张,身份有3 060 个。
3.2 实验细节和评估指标
如第1 节所述,首先对Baseline 用源域数据集进行训练,采用Zhong 等[32]使用的方法进行训练。将输入图片的大小调整为256×128,采用随机裁剪、翻转和随机擦除对数据进行增强;为满足难样本三元组损失的要求,将每个mini-batch 用随机选择的P=16个身份进行采样,并从训练集中为每个身份随机采样K=8张图片,得到mini-batch 为128 张,将三元组损失的边缘参数α设置为0.5。空间语义融合模块中感受野的数量Q设置为3(如式(2))。由于ResNet[20]不同阶段特征图空间大小不同,因此本文采用不同的标准差(如式(3)),添加到layer2后的语义融合层σ1和σ2设置为10和20,添加到layer3后的语义融合层σ1和σ2设置为5和10。在训练中使用权重衰减为0.000 5的Adam[33]优化器来优化70个epoch的参数。初始学习率设置为 6 × 10−5,在7个epoch 后将学习率调整为 1.8 × 10−5,再经过7 个epoch 学习率调整为 1.8 × 10−6,一直训练到结束。
3.3 与先进算法的比较
在3 个公共数据集上,将本文算法与近年顶级会议文章所提出的算法进行比较。将行人重识别任务通用的累积匹配特性中的Rank 识别准确率(R-1、R-5、R-10)和均值平均精度(mAP,mean average precision)作为评价指标,评价模型在数据集上的性能。比较结果如表1和表2 所示,所有数据均不经过重排序处理。

表1 不同算法在DukeMTMC-ReID和Market1501的实验结果

表2 不同算法在MSMT17的实验结果
不同算法在MSMT17的实验结果如表1 所示,包括8 种通过聚类形成伪标签的算法UDAP[4]、MAR[13]、ECN[10]、CDS[29]、UCDA[5]、SAL[14]、DCJ[31]和NSSA[30];2 种通过域风格迁移的算法CR-GAN[6]和PDA-Net[7];3种特征对齐算法ARN[28]、D-MMD[11]和PAUL[12]。其中,CR-GAN[6]在DukeMTMC-ReID泛化到Market1501的mAP和R-1 表现最好,本文算法在网络复杂度上远低于CR-GAN[6],而且mAP提高2.3%,R-1 提高0.9%。在数据集Market1501泛化到DukeMTMC-ReID的结果中,本文算法表现更好,和上述算法中表现最好的DCJ[31]相比mAP 提高了1.5%,R-1 提高了3.4%。
表2为DukeMTMC-ReID和Market1501 分别泛化到MSMT17的实验结果。MSMT17 数据集包含的身份更多且摄像头视角更多,数据集包含较多存在身体错位和遮挡等问题的图片,更接近现实场景,难度较大。与表2 中性能最优的MMCL[35]算法相比,本文算法在DukeMTMC→MSMT17 上mAP提高 1.2%,R-1 提高 1.7%;在 Market1501→MSMT17 上mAP 提高0.8%,R-1 提高1.4%。
3.4 消融实验
本节首先将模型在DukeMTMC-ReID 数据集上进行预训练,然后在Market1501 数据集上进行消融研究,最后通过实验分别验证语义融合层中各部分和特征细粒度分块的有效性。
在添加的语义融合层内,空间语义融合模块中感受野尺寸E(如式(1))的选择对识别准确率有较大影响。如表3 所示,不同尺寸E的感受野较Baseline 识别准确率均有所提高,但当E进一步增大到5 时,准确率开始下降。感受野的不断增大会忽略一些关键身份信息。本文在式(2)中对不同感受野对应的关系图进行融合时,选取感受野数量Q=3得到最优的实验结果。

表3 不同感受野尺寸E的感受野对实验结果的影响
对于融合函数G的选取,本文实验将逐元素求最大值、累加以及相乘3 种函数作比较,实验数据如表4 所示。在Q=3的情况下,融合函数对经过尺度分别为1、2、3的感受野所获得的外观相似图进行融合,从表4 中可知,对应位置逐元素求最大值、累加和相乘的融合函数较Baseline 网络的识别准确率均有所提升,其中逐元素相乘的融合函数对结果提升最为显著。

表4 融合函数G 对实验结果的影响
对于网络的整体结构,本节分别对语义融合层中空间语义融合和通道语义融合模块进行消融实验,实验结果如表5 所示。通过分析,Baseline 网络分别添加空间语义融合和通道语义融合模块对识别准确率均有所提升。将二者按先空间后通道的方式串联到一起,组合成语义融合层添加到Baseline 网络中,对识别准确率的提升最大:mAP 提高4%,R-1 提高3.1%。由此可见,添加语义融合层可以获取更多有效的行人特征信息,从而提高识别准确率。

表5 不同语义模块对实验结果的影响
对于网络输出特征图,本节在水平分块的数目上进行了消融实验。通过表6 可知,将网络输出特征图分为上下两部分能得到最佳识别准确率。通过分析可知,当不进行分块时,特征图丢失了有用的细粒度信息;当分块较多时,由于数据集图像内存在一些身体错位和被遮挡的图像,导致在经过密度聚类时会产生较多噪声信息和较差的相似性挖掘以及匹配。因此,本文对网络结构的设计时将分块数确定为2。

表6 不同分块数对实验结果的影响
3.5 可视化分析
为了更直观地体现网络在Baseline 上的改进,本节使用DukeMTMC-ReID 数据集进行预训练,使用Market1501 数据集进行训练和测试,使用热图[36]和检索排序对实验结果进行可视化分析。
热图共有4 组图片,如图5 所示。每组图中,第一张图像为Market1501 数据集行人图片,第二张为经过Baseline 网络的热图,第三张为经过本文网络的热图。从图5 中可以看出,Baseline 网络由于固定感受野,所以只关注行人的局部信息,当图像整体色调相近时(如图5(a)所示),Baseline 网络对行人的关注会被背景所干扰,本文方法将不同尺寸的感受野进行融合,实现了更关注行人主体的效果;当背景较为复杂时(如图5(d)所示),Baseline网络的关注完全偏离了人物,而本文的改进网络表现依旧稳定。

图5 热图
图6 分别展示了Baseline 网络和本文网络在Market1501 数据集上识别实例的检索排序结果。每张行人图像上方的“√”和“×”分别表示查询结果的正确与否。可以看到经过本文网络的实验结果在R-1、R-5 上的识别准确率都较高且稳定。其中,第二组行人的衣着相似难以辨认,Baseline 网络在第二位置识别错误的行人图像在本文网络的识别结果排序中排第八位,且本文网络未出现其他识别错误图像。由此可见,在面对特征相似的行人图像时,本文网络依旧可以得到很好的识别效果。
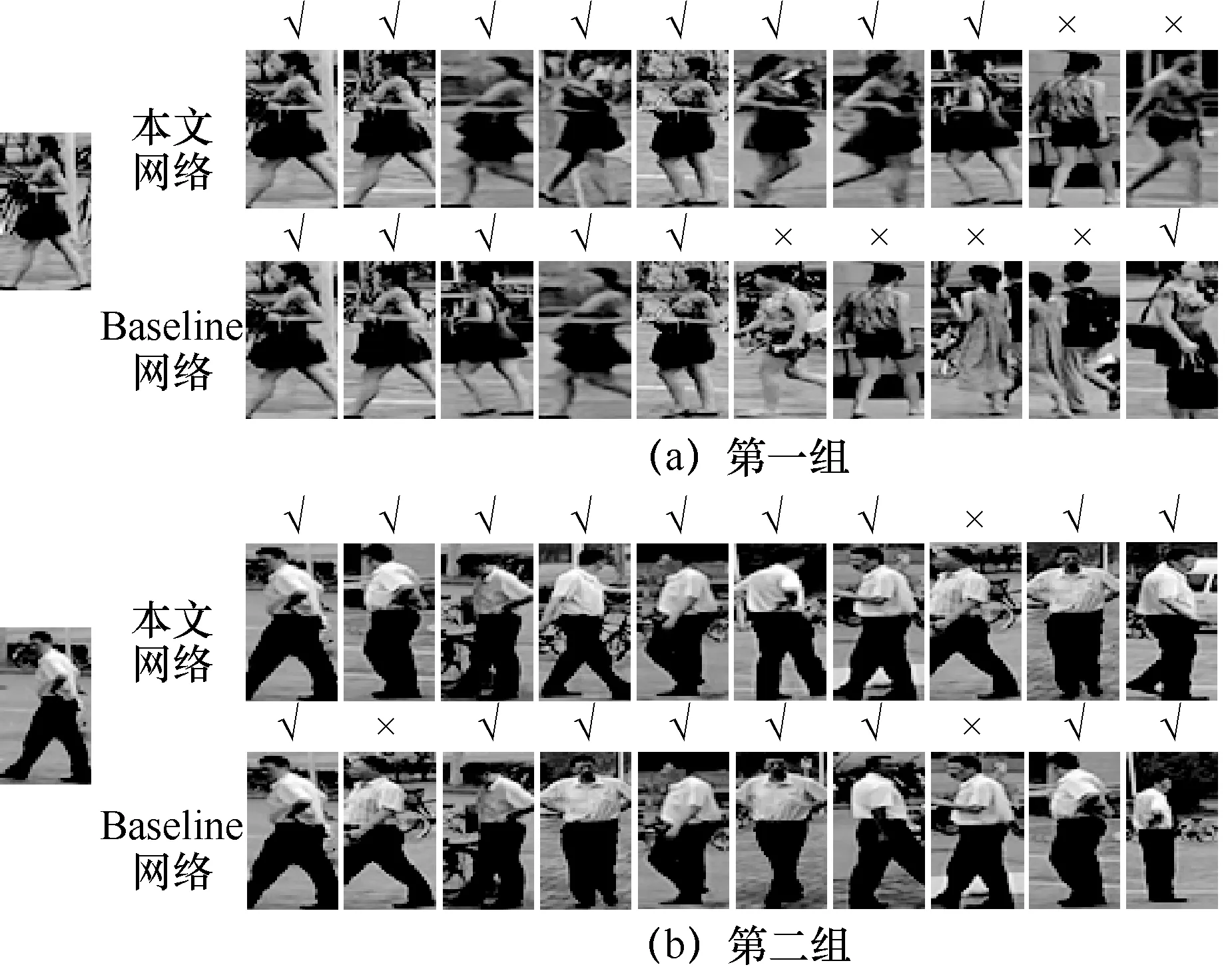
图6 检索排序结果
4 结束语
本文提出了一种基于语义融合的域内相似性分组网络。语义融合层对于行人图片自适应生成不同尺度的感受野,增强了空间特征之间的相互依赖关系,通过融合通道信息进一步提高了网络的表示能力。实验结果表明,相比于未添加语义融合层前的网络,本文网络的mAP 提高4.0%。此外,本文提出的网络采用分块的方式对目标域内细粒度相似性信息进行挖掘,得到更精确的行人分类信息。实验数据表明,分块聚类相比于未进行分块处理的网络mAP 提高5.0%。为了进一步增强网络在现实环境中的泛化性,在后续的工作中本文将采用不同光照和尘雾环境的数据集对网络进行训练。对于行人被遮挡的情况,本文会为网络添加行人遮挡模块使网络具备一定的抗遮挡能力。
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
开放教育研究(2020年2期)2020-03-31 01:54:14
扬子江(2019年1期)2019-03-08 02:52:34
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
现代语文(2016年21期)2016-05-25 13:13:44
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
大连民族大学学报(2015年2期)2015-02-27 08:28:11
