
基于Stacking模型融合的胎儿健康状态智能评估
2022-08-03 06:59郝婧宇陈奕吴水才
中国医疗设备 2022年7期
郝婧宇,陈奕,吴水才
1. 北京工业大学 环境与生命学部,北京 100124;2. 首都医科大学附属北京妇产医院 妇产科,北京 100124
引言
电子胎心监护(Electronic Fetal Monitoring,EFM)是临床上关注度最高的产检监测指标之一,是通过超声多普勒形成的脉冲向胎儿心脏传输信号,通过得到的胎心率(Fetal Heart Rate,FHR)变化来评估胎儿在子宫内的状况[1]。临床表明,FHR 曲线的变化有助于发现胎儿窘迫、宫内缺氧或酸中毒等异常病理状态[2]。然而,由于FHR 信号的复杂性与多样性,导致人工判读结果存在一定偏差。利用智能分类算法可以辅助医生诊断,对降低胎儿宫内缺氧、胎儿窘迫、新生儿窒息、缺血缺氧性脑病等不良妊娠结局具有重要意义。
近年来,国内外学者对胎儿心率参数定量研究,采用主成分分析、套索回归等方法从原始特征集中选择最优特征子集,随后运用机器学习算法对胎儿健康状态进行评估。2017 年,Georgoulas 等[3]运用曲线下面积对FHR 信号的54 个线性和非线性特征进行排序后,使用最小二乘支持向量机分类器来诊断胎儿类别。2018 年,Zhao 等[4]设计了统计检验、曲线下面积(Area Under Curve,AUC)和主成分分析等方法选择出多模态信号特征,运用决策树、支持向量机和自适应增强决策树(Adaptive Boosting,Adaboost)执行分类,最终分类准确率(Accuracy,ACC)为92%。Li 等[5]从胎心图中提取7 个特征参数,利用一维卷积神经网络对FHR 信号进行分类,ACC 为93%。2020 年,叶明珠等[6]采用盲分割、插值法对信号预处理后,得到FHR信号的瞬时频率特征图,提取特征子集后运用支持向量机对FHR 分类,ACC 为97%。
在胎儿状态的评估中,数据预处理至关重要,是获取高准确性的第一步。其次,在特征选择和模型构建时,一些机器学习模型的特征向量维数较低,并且过度依赖于时间特征。因此,本文将从数据处理、特征选择和模型构建等3 方面做出研究。首先,运用极端梯度提升树(Extreme Gradient Boosting,XGBoost)算法与HeatMap 对公开的胎心数据集进行分析,构建两个新特征作为最终模型的输入,提出一种两层Stacking 模型融合的新方法用于胎儿健康状态的分类,以辅助临床医师对宫内胎儿的健康状态进行诊断。
1 数据和方法
1.1 实验数据来源
本研究采用的数据集是波尔图大学在UCI(Machine Learning Repository,https://archive.ics.uci.edu/ml/index.php)中公开的葡萄牙孕妇29~42 周的真实胎心数据集[7],该数据集是研究胎儿心电分类算法的常用数据库之一,已被广泛用于算法的验证。
UCI 数据集中包含21 个临床特征和2 个类别属性,其临床特征是通过SisPorto 2.0[8]分析程序从胎心监护图中提取出来的,包含了致命心律的各种度量以及基于FIGO 指南的由产科专家分类的公共特征,包括临床实践中常见的形态学特征、时域特征、频域特征等,23 个属性的完整定义及说明如表1 所示。数据集共有2126 个样本,其中“正常、可疑、异常”3 类的病例数分别有1655、295 和176 个,本文的任务是用前22 个变量作为自变量预测胎儿的状态类别。

表1 数据集中23个属性的完整定义及说明
1.2 实验数据的临床获取
临床表明,当缺氧、酸血症和药物诱导等现象发生时,会在时域和频域内产生明显的FHR 值变化[9]。临床应用的胎心监护仪只显示以每分钟数表示的简单的形态学参数,而不提供用于胎心率变异性(Fetal Heart Rate Variability,FHRV)分析的时频域、非线性等其他参数,因此对胎心曲线的分析与解读来说,最重要的是如何准确获取上文所提数据集中包含的特征参数。
FHR 基线是指在没有加减速和显著变异的情况下,10 min 内胎心波动的平均值,一般可在胎心监护图中直接获得。FHR 加减速是指受到宫缩、胎动时,FHR 出现加快或减慢且与基线之差超过一定阈值,并持续十余秒的变化过程,可通过相位整序信号平均技术(Phase Rectified Signal Averaging,PRSA)计算加速(Acceleration Capacity,AC)与减速(Deceleration Capacity,DC)。
根据PRSA 计算AC 的公式如式(1)所示。

其中,X为心率加速点对应的心动周期的平均值,单位为ms,结果为负值。
根据PRSA 计算DC 的公式如(2)所示。

其中,X为心率减速点对应的心动周期的平均值,单位为ms,结果为正值[10-11]。
基线变异是指每分钟FHR 自波峰到波谷的振幅改变,分为长变异(Long-Term Variation,LTV)与短变异(Short-Term Variation,STV)。这种变异估测的是两次心脏收缩时间的间隔,在监护图上无法直接辨认,需要计算才可获得[11]。一些实用软件,例如,Matlab 中的峰值检测算法可以计算收缩峰值与持续时间,从而建立心率和心率变异信号之间的联系。除此之外,可以对FHR 变化序列进行经验模式分解,得到的若干个内蕴模式函数分量,然后进行希尔伯特-黄变换,得到希尔伯特谱及其边界谱,最后计算FHR 的希尔伯特边界谱在不同频带范围内的功率,建立一个定量测量的方法[10]。从而获得异常短期变异性的时间百分比(Abnormal Percentage of Time for Short-Term Variability,ASTV)、短期变异的平均值(Mean of Short-Term Variation,MSTV)、异常长期变异性的时间百分比(Abnormal Percentage of Time for Long-Term Variability,ALTV)、长期变异的平均值(Mean of Long-Term Variation,MLTV)等特征参数。
FHR 频率直方图的最小值(Min)、最大值(Max)、峰值(Nmax)、零点(Nzeros)、众数(Mode)、均值(Mean)、中值(Median)、方差(Variance)等可通过连续小波变换(Continuous Wavelet Transform,CWT)在频域和时域进行多分辨率分析。通常,小波被定义为母小波φ(t)和一组子小波φs(t),通过对φ(t)进行尺度变换得到φs(t),每个φs(t)的频率含量与一定的频带相关联,CWT 利用这一性质,将φs(t)与信号x(t)进行比较,FHR 信号中RR[n]的CWT 如式(3)所示。

其中,φ*为小波的复共轭,计算某一尺度下每个时刻的功率如式(4)所示。

其中,Cg为可采性常数,通过计算Ps[τ]的平均值并对该频段内的尺度积分,可以计算出某一频段内的频率,进 而 计 算 出Min、Max、Nmax、Nzeros、Mode、Mean、Median 等特征参数[12]。
1.3 类不平衡问题
类不平衡是指训练分类器所使用的训练集类别分布不均。在医疗领域中,数据集通常是不平衡的,多数类样本数量与少数类样本数量之比高达106[13],在临床胎心监护案例中,异常类也极为稀少,若以不平衡数据建模,占据多数的正常类会被过度学习,使得分类算法倾向于忽略少数类样本。例如,本文使用的数据集包含2126 个样本,其中有471 个被评估为负类,正类和负类之比达9 ∶2,即任何分类算法的准确度均可达9/(9+2)×100%=82%,这是不合理的。面对不平衡的数据集,Jyothi 等[14]提出利用3 种不同的加权,同时利用合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)与决策树相结合的方法解决类别不平衡的问题。张扬等[15]也采用SMOTE,利用线性插值,解决类不平衡的问题。
在本文中,采用SMOTE 与k-最近邻相结合的方法对少数类样本进行填充。该方法利用k-最近邻的思想,在相距较近的两个少数类样本间插入新样本,形成规模更大的训练集。
采用SMOTE 技术后,数据集由2126 例变为3310 例,其中负类为1655 个,样本数趋于平衡。其中原始数据集中的正常类、可疑类、异常类分别有1655、295 和176 个,受杨蔓丽等[7]研究的启发,本文将数据集中的可疑类、异常类两类数据进行合并,归为“负类”,当某个样本被判断为“负类”时,需及时进行就医,更加符合临床实际意义。
1.4 特征工程
选择合适的特征子集是机器学习算法中的关键步骤。在绝大多数分类问题中,某些特征往往包含重叠信息,相关性较高,甚至无法达到预期的信息量。因此,在应用分类算法之前,需进行特征选择,减少一部分特征或构建一部分新的特征。选择出最优特征子集作为分类器的数据输入,不仅能提高计算效率,还能增强分类器的泛化能力[16-17]。
该数据集中包含23 维特征,其中“CLASS”标签列不考虑在内,将该标签列去除,最终用于特征选择的特征列为22 维。本文采用XGBoost 算法来选择最优特征子集,XGBoost 算法训练速度极快,可以计算每个特征的重要性,在特征筛选、模型可解释性等方面都有显著的优势。
XGBoost 算法选择最优特征子集的原理如下:在单个决策树中通过每个属性分裂点改进性能度量的量来计算属性重要性,由节点负责加权和记录次数,一个属性对分裂点改进性能度量越大,权值越大,属性越重要[18]。最后将属性在所有提升树中的结果进行加权求和并平均,得到重要性得分。本实验中,由XGBoost 算法计算得到的每个特征的重要性得分如图1 所示。
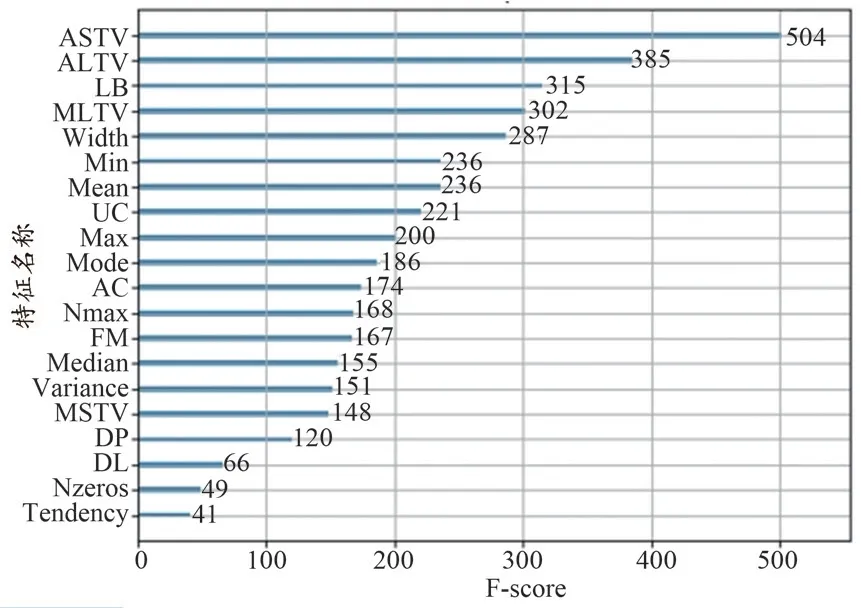
图1 基于XGBoost算法的各个特征重要性得分
从特征重要性分析图中可看出,ASTV 特征重要性最高,这与杨蔓丽等[7]的研究结果类似,考虑到短期变异的时间与短期变异的数值大小有相关性,因而将ASTV 与MSTV 这两个特征相乘与相除得到两个新特征,分别记为“ASTV_x_MSTV”与“ASTV_div_MSTV”。随后运用HeatMap 对24 个特征进行相关性的分析,特征相关性高往往包含重叠信息,影响模型的解释性和稳定性,因此我们需要删除高度相关的特征。通过HeatMap 可以简单地聚合大量数据,直观地展现数据相关性程度或频率高低,最终效果优于离散点的直接显示,HeatMap 如图2 所示,蓝色代表相关性高,红色则相反。

图2 新特征子集的HeatMap图
从HeatMap 图 可 看 出,FHR 直方图Mode、FHR 直方图Median 与FHR 直方图Mean 三者之间相关性极高,高达95%,则考虑在这三个特征中进行选择,结合上文XGBoost 算法对特征重要性的排名,最终保留“Mean”特征集。通过特征工程这一步骤后,最终确定的特征子集共有22 维特征,包含构建的两个新特征与剔除的两个旧特征,特征选择的效果在后文中得到评估。
1.5 模型构建
1.5.1 XGBoost分类器
XGBoost 分类器是数据挖掘和机器学习中最常用的算法之一,与传统的梯度提升算法相比,XGBoost 集成算法更快,分类效果更准确,被认为是在分类和回归上都拥有超高性能的先进评估器。
XGBoost 将回归树作为基分类器不断生成新的回归树,每生成一棵树即是在学习一个新的函数,去拟合上次预测的残差,运用梯度下降的方法,将上一步生成的树作为基础,逐渐最小化目标函数。当预测样本时,根据样本特征,在每棵树中寻找对应的叶子节点,每个叶子节点对应一个分数,最后只需将每棵树对应的分数相加即得到该样本的预测值[19]。
建树过程如下:确定初始树为f0(xi),那么建立第t棵树时的预测模型如公式(6)所示。

其中,xi表示第i个样本,fk表示第k棵树,yi表示样本xi的预测结果。
在建立模型过程中不断优化目标损失函数,使其最小,见公式(7)。

目标函数由两部分构成,第一部分用来衡量预测分数和真实分数的差距,第二部分则是正则化项,正则化项表示每棵树的复杂度[20]。XGBoost 通过将Objt使用二阶泰勒公式展开得式(8)。

其中,gi、hi分别表示在第i 个样本下泰勒展开式的一阶导数、二阶导数,通过公式(8)可得到关于wj的一元二次方程,因此能够找到使Objt取值最小的wj。
通过以上步骤完成第t棵树的建立[21]。
本研究基础模型选择树形结构,模型调参采取GridSearch CV 方法,其中GridSearch 为网络搜索,CV 为交叉验证。网络搜索为在指定的参数范围内,依据其步长,不断调整参数,从所有的参数中选择出使测试集精度较高的参数,XGBoost 模型的几个重要参数与解释说明如表2 所示。

表2 XGBoost模型的几个重要参数
1.5.2 Stacking模型融合
Stacking 是一种模型融合算法,又叫作模型堆叠,基本思路是先从初始的训练集训练出若干模型,然后将单模型的输出结果作为样本特征进行整合,并将原始样本标记作为新数据样本标记,生成新的训练集[22]。再根据新训练集训练一个新的模型,最后用新的模型对样本进行预测,其优点是降低单模型的泛化误差。
本研究的设计步骤如下:
(1)首先将选择的最优特征子集切分为5 份,每份包括662 例样本数据。
(2)Stacking 的第一层模型可理解成一个超强的特征转换层,第一层基模型选择了5 个强模型,分别为:随机森林(RandomForest,RF)、极端随机树(Extremely Randomized Trees,ET)、 梯 度 提 升 决 策 树(Gradient Boosting Decision Tree,GBDT)、 自 适 应 增 强 决 策 树(Adaptive Boosting,Adaboost)、XGBoost,这5 个树模型均属于强模型,均是在决策树的基础上进行优化与提升。将第一步切分好的5 部分数据分别作为这5 个模型的输入进行训练。
(3)第一层的5 个模型均运用六折交叉验证的方法做训练。六折交叉验证的思想是:将数据划分为6 部分,对其中的5 部分数据做训练,每一份数据都会被作为一次验证集,然后将得到的6 个结果取平均。通过第一层的训练后,将5 个模型的5 个预测结果组成新的特征,作为第二层模型的输入做训练。第二层的基模型选用了一个简单的Logistics 回归分类器,可以避免过拟合现象的发生。具体的Stacking 模型融合步骤如图3 所示。

图3 Stacking模型融合流程图
2 实验与分析
2.1 评估方法
采用混淆矩阵评估分类模型的性能。首先,对于测试数据的正负类别是已知的,要判断的是通过模型预测出来的结果是否符合测试数据的真实结果。已知的测试数据分为正类和负类,预测出的结果分为阳性和阴性[23]。本文中,胎儿“正常”表示正类,胎儿“可疑”和“异常”表示负类,则真正类(True Positive,TP)为正常胎儿被正确分类为正常;假负类(False Negative,FN)为正常胎儿被错误分类为异常;假正类(False Positive,FP)为异常胎儿被错误分类为正常;真负类(True Negative,TN)为异常胎儿被正确分类为异常,TP、FP、FN、TN 分类矩阵如表3 所示。

表3 TP、FP、FN、TN分类方法
为能直观反映分类性能,本文采用ACC、精确率(Precision)、召回率(Recall)以及F-score 值来衡量分类结果。ACC 是一个很好很直观的评价指标,其计算公式如(9)所示。

其 中,TP+TN表 示 分 类 正 确 的 样 本 数,TP+FP+FN+TN表示所有的样本数,ACC 为两者的比值,ACC 越高,说明分类效果越好。
Precision 表示的是当前划分为阳性的类别中,被分对的比例,其计算公式如(10)所示。

Recall 度量的是有多少个正例被分为正例,其计算公式如(11)所示。

F-score 值同时兼顾了分类模型的ACC 和Recall,它是分类模型ACC 和Recall 的一种加权平均,分数越高说明分类效果越好。
除此之外,本文还采用皮尔逊相关系数(Pearson Correlation Coefficient,PCCs)以及AUC 来衡量训练模型的效果。PCCs 定义为两个变量之间的协方差和标准差的商,它是一种统计指标,可以查看特征之间相关关系的密切程度。AUC 被定义为受试者特征曲线下与坐标轴围成的面积,它的取值范围通常为0.5~1,AUC 值越接近1 说明分类器的ACC 越高。
2.2 结果分析
本文的结果分析可分为两部分。第一部分是运用XGBoost 算法与HeatMap 所选择的最优特征子集的评估,运用这两种方法确定出最终的22 个特征应用于模型的训练。第二部分是模型分类结果的评估,将数据集划分为训练集和测试集,随机选取1968 个数据作为训练集,662 个数据作为测试集。
2.2.1 特征选择
综合XGBoost 算法和HeatMap 对特征的重要程度与相关性评估的结果,选出22 维特征作为最优特征子集进行模型的训练。首先,通过XGBoost 算法进行模型训练,运用GridSearch CV 方法选出XGBoost 算法的最优参数,最优参数如表4 所示。其中学习率为0.1,最大深度为9,模型数量为10。
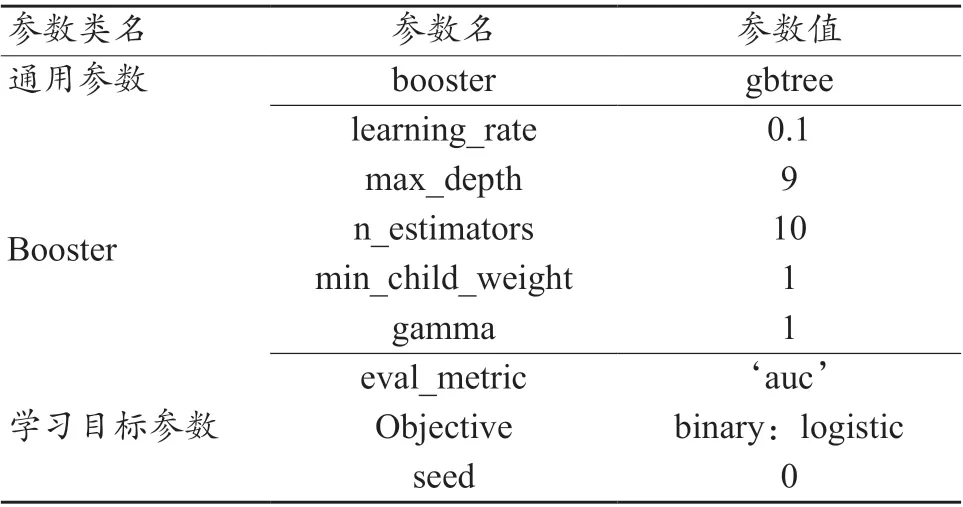
表4 XGBoost模型最优特征参数
随后,运用PCCs 评估所得的预测结果与真实结果的差异性,结果表明,PCCs 由未选特征前的0.873 提高到0.885。
除此之外,运用ACC、Precision、Recall 以及F-score值所得评价结果如表5 所示。从表中可看出,运用最优特征子集所训练的模型分类性能更好,ACC、Precision、Recall、F-score 值均有所提高。

表5 原特征与最优特征子集的结果比较
2.2.2分类结果
对原始特征集和最优特征子集使用Stacking 模型堆叠,在第一层基模型中,运用5 个强模型:RF、ET、GBDT、AdaBoost、XGBoost。每个模型运用六折交叉验证进行训练,将5 个模型的预测结果组成新的特征,作为第二层模型的特征输入,第二层的基模型运用了简单的Logistics 回归模型。在第一层的模型训练中,以AUC 为指标,对比了5 个基模型的得分情况,见表6。

表6 五个基模型的AUC得分情况
从表6 中可看出,XGBoost 分类器相较于其他4 个机器学习单模型有较好的分类能力。采用ACC、Precision、Recall、F-score 值对第一层最强的基模型XGBoost、第二层Logistics 回归模型以及第一层分别使用4 个和5 个基模型融合的分类结果进行比较,见表7。

表7 ACC、Precision、Recall、F-score值评估结果
从表7 中可看出,RF+ET+GBDT+Adaboost+XGBoost 5 个模型融合的分类能力最优,ACC、Precision、Recall、F-score、AUC 分 别 达 到0.950、0.923、1、0.960、0.980,具有较好的分类性能。
除此之外,对第一层中最强的基模性XGBoost 与第二层基模性Logistics 回归的性能采用混淆矩阵来评估,见图4。结果显示,在随机选取的662 例测试集样本中,运用XGBoost 模型,分类正确的有294 例(实际为正类,预测为正类)+330 例(实际为负类,预测为负类)=624 例,而运用Logistics 回归模型分类结果不如XGBoost 模型,有269 例(实际为正类,预测为正类)+299 例(实际为负类,预测为负类)=568 例分类正确。
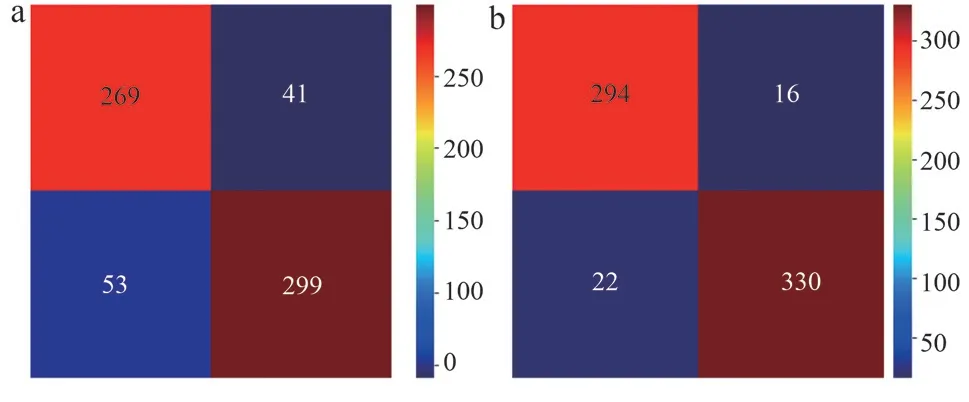
图4 模型分类混淆矩阵
3 讨论
本文提出一种基于公开数据集的胎儿宫内健康状态智能评估新方法。针对正类和负类数据集不平衡问题,采用SMOTE 方法进行少数样本集的填充。运用XGBoost 算法与HeatMap 对原始数据集分析,构建两个新特征作为最佳特征子集用于模型的特征输入,最后构建了一种两层Stacking 模型融合的新方法用于胎儿分类。实验结果表明,使用最佳特征子集的分类性能优于原始特征集,并且运用五层Stacking模型融合的方法达到性能最优,ACC 为0.950,Precision为0.923,Recall 为1,F-score 为0.960,AUC 为0.980。
此外,对比前人的研究工作,进一步证明了本文算法的性能。张扬等[15]对FHR 信号进行研究,提取出形态学、时域、频域等多模态特征后,运用k-最近邻遗传算法选择最优特征子集,最小二乘支持向量机法对其分类,ACC 为0.91,AUC 为0.92。Ocak[24]使用支持向量机和遗传算法相结合的分类技术,使用回归模型和粒子群优化方法来训练,最后应用二叉决策树进行数据分类,ACC 为91.6%,此方法中二叉树算法很容易在训练数据中生成复杂的树结构,造成过拟合。本文中Stacking 模型融合第二层采用简单的Logistics 回归分类器,可以很好地避免过拟合问题,并且本文所提的算法准确度有所提升。
本文方法亦存在不足,今后在以下几个方面还有待深入探究:
(1)临床实践的验证。对于胎心信号图的分析和解读来说,最重要的是如何准确识别所有特征参数,因而,后期需在医生的指导下,进行胎心信号的数据采集和参数提取,尽可能获得本文所用数据集的所有参数,以便验证本文所提出模型的性能。
(2) 提高算法精度。虽然该算法的ACC 有所提升,但对于要求更高的临床诊断来说还有所欠缺。因此,后期将不断改变算法结构,进一步提升分类性能。
(3)应用深度学习算法。应用深度学习算法对胎心监护图研究,运用卷积降维,用低维的卷积核区代替高维的卷积核,并配置与优化网络层数,减少运算量和参数量,设计出更加轻量级的网络模型。
(4)构建完整的胎心监护辅助诊断系统。一个好的模型是辅助诊断的第一步,后续还需结合智能分类算法,将科研成果落地,将其部署到服务器软件中,构建一个完整的胎心监护诊断系统。
4 结论
近年来,由于胎心监护图中参数定义的不严谨性以及临床医师个体主观认知的不同,对胎心图像误判导致剖宫产率不断上升[25],利用智能分类算法可以辅助医生对胎儿健康状态做出诊断。本文提出的基于Stacking 模型融合的方法经过测试集的测试,最终的ACC 为0.950,AUC 为0.980,可作为医护人员诊断胎儿健康状态的参考依据。另外,XGBoost 等模型速度快、准确率高,可分布式部署,能集成到当前流行的Hadoop、Apache Storm 等数据处理框架之中,使得本方法可移植到服务器软件平台,实现诊断监护一体化。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
中国典型病例大全(2022年10期)2022-05-10
中学生数理化·高一版(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
成都信息工程大学学报(2021年4期)2021-11-22
健康体检与管理(2021年10期)2021-01-03
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国生殖健康(2020年6期)2020-02-01
母子健康(2016年2期)2016-05-18
为了孩子(孕0~3岁)(2016年3期)2016-03-11
