
一种面向缺陷检测过程的警报自动确认方法
2022-08-03 02:40孔焦龙金大海宫云战
计算机测量与控制 2022年7期
孔焦龙,金大海, 宫云战
(北京邮电大学 网络与交换技术国家重点实验室,北京 100876)
0 引言
软件出现在现代生活的方方面面,从社交媒体到基础设施。由于软件正在变得越来越复杂,其不可避免的存在重大的缺陷,这些缺陷可能会给人类社会造成重大的损失[1]。然而,由于有限的预算以及紧张的日程安排,仅仅通过软件测试来找出缺陷是不切实际的,因为这通常需要大量的时间来运行各种各样的测试用例。静态分析(SA,static analysis)能很好的弥补这一点,不需要运行程序也能检验程序源码,并且可以考虑到所有可能的程序执行。但是,通过静态分析在程序中找到的相关缺陷通常是不可判定的,这一点限制了静态分析工具的实用性[2]。因此静态分析工具报告出的有关代码缺陷的警报信息中会存在一部分错误,本文称之为误报,人工确认潜在缺陷是一项费时费力的工作[3]。
为了减轻人工确认的负担,大量能使这一过程自动化的方法已经被提出[4-5]。其中有通过设计并提取一系列的手工特征来训练有效的分类模型,这些被提取的特征主要和源代码的统计特征有关,包括McCabe metrics[6], Halstead metrics[7], 和CK metrics[8],然而当前文献表明这些特征在表示源代码深层语义信息的时候缺乏准确性。另外,之前大部分方法主要针对工程内的任务,即训练集和测试集来自同一个工程。跨工程确认的一个主要的问题在于不同工程之间数据分布的差异性。因此,直接把基于源工程特征构建起来的模型应用到目标工程,大部分情况下无法达到令人满意的效果。
最近,越来越多静态分析和人工智能结合的研究成为了解决上述问题的重要手段。明确地说,基于深度学习的方法已被广泛应用于特征的自动生成[9-13]。它们的主要思路是将从源代码对应的语法树(AST,abstract syntax tree)上获取的符号序列表示为符合深度神经网络的输入形式,再利用神经网络学到的特征去训练更准确的分类模型。相关实验结果表明基于深度学习的方法能够更好的获取软件缺陷相关的语义特征,因此它们的表现会胜过仅使用手工特征的传统方法。
本文提出一种面向缺陷检测过程的自动确认方法,即基于缺陷模式状态机[14]的检测过程。通过搜集在检测过程中与缺陷模式状态机实例状态转换相关的指令集,提取指令集中所包含的细粒度的语法、语义信息并转换为结构化的序列,将这些序列集合映射到高维向量空间后作为神经网络的输入,训练出能有效自动确认警报的模型。该方法一定程度上可以抵消不同工程之间的特征分布差异,本文将其命名为State2Vec。
1 相关工作
1.1 缺陷模式状态机
缺陷模式描述了程序的某种属性,如果违反该属性则生成一条缺陷。例如:若某处申请的资源在使用完后未释放,则造成资源泄露缺陷(RL,resource leak);若对空指针解引用操作,会导致空指针引用缺陷(NPD,null pointer dereference)。

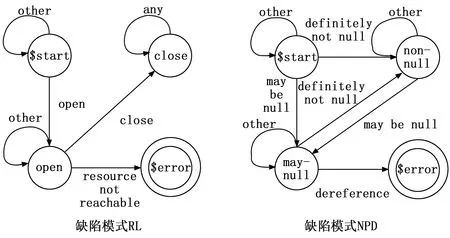
图1 RL和NPD缺陷模式状态机
缺陷模式状态机包含多种缺陷模式,是对所有缺陷的一种统称。若要对函数内部某些具体缺陷模式检测,需要根据其各自的状态机实例创建条件,创建相应实例。例如根据函数中每一处资源分配创建一个RL状态机实例;对每一处可能被解引用的变量创建一个NPD状态机实例。
1.2 基于缺陷模式状态机的测试方法
定义2:检查点(IP,inspection point)。设P是待测程序,将缺陷模式S分成N类,类,S={S1,S2,…,Sn},每类分成K种,Si={Si1,Si2,…,SiK}, 从P中计算出和S相匹配的检查点的集合IP={IP1,IP2,…,IPm}。
定义3:警报点(AP,alarm point)。在IP集合中,每一条记录由一个三元组{S,P,J}表示:S为静态分析报告中一条记录对应的缺陷模式。P为一个六元组,用于描述IP前5个分别表示工程名,变量名、变量出现的位置、文件名、行号、IP所在方法名,若两个及以上相同变量出现在同一行代码中,Index表示变量出现的索引。J表示对此 IP 自动确认后的结果,未进行缺陷确认前,该值为 NULL,缺陷确认后,真实缺陷(True),误报(False Alarm)。
现对选定程序P缺陷检测,首先选定要检测的缺陷模式种类,根据各自条件创建相应的状态机实例,新创建的实例初始状态为$start,且实例之间互相独立。接着结合数据流分析,采用对控制流图进行迭代的方法,对当前节点各个实例可能的状态集合进行迭代。数据流分析中,数据流信息通过建立和解方程来收集方程联系程序不同点的信息。
基于缺陷模式状态机的检测过程如算法1所示,算法描述如下。
算法1:
输入:程序控制流图和缺陷模式描述状态机
输出:每个控制流节点的inStateSet[n]和outStateSet[n]
1:begin
2:for 每个控制流节点n do
3:inStateSet[n] ← Ø/*初始化*/
4:outStateSet[n] ← Ø
5:outStateSet[Entry] ← D{$start(Var[])} /*入口节点的初始状态集合*/
6:statechange ← true
7:while statechange do begin
8:statechange ← false
9:for 除 Entry的每个节点n do begin
10:nStateSet[n] ← Up∈pred[n]outStateSet[p]
11:oldout ← outStateSet[n]
12:outStateSet[n] ← genState[n] U(inStateSet[n]-kill[n])
13:if outStateSet[n] ≠ oldout
14:hen statechange ← true
15:end
16:end
end
算法1中,输入被测程序P的控制流图以及状态机描述文件,得到控制流各节点输入及输出的实例状态集合。其中inStateSet[n] 表示进入节点n之前的所有实例状态集合,outStateSet[n]表示通过节点n之后所有实例状态集合。genState[n]表示在节点n处新产生得到的所有实例状态集合,kill[n]表示在节点n处被注销的所有实例的状态集合。pred[n]表示节点n的入度节点集合,即n的前驱节点。
2 面向缺陷检测过程的警报自动确认
本文基于缺陷模式状态机的检测机理提取相关指令集,并设计了一种新的细粒度的特征提取方法,结合程序语言处理的相关技术,提升在跨工程场景下警报确认的效果。本文将该自动确认方法命名为State2Vec,共计三部分。
State2Vec可分为以下三部分:1)基于缺陷模式状态机的检测机理提取相关指令集,通过提取状态机实例沿着控制流计算过程中状态发生改变的节点集合,得到相应的代码段集合,称之为相关指令集。2)设计并利用一种新的细粒度的特征提取方法,提取相关指令集所包含的细粒度的语法、语义信息。3)利用词嵌入技术,将结构化的字符串序列映射到高维向量空间,作为神经网络的输入,并将合适的深度学习模型与之相结合,训练得到可以学习缺陷语义特征的深度神经网络。该方法整体流程如图2所示。
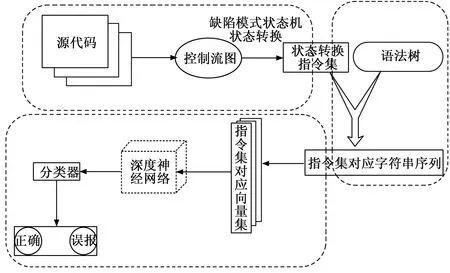
图2 State2Vec工作流程
2.1 基于缺陷模式状态机的指令集提取方法
目前大部分缺陷语义相关的指令集提取技术都存在以下问题——关于程序特征的指令集序列通过人工建模的方式提取,这类方法的缺陷在于人工提取的指令集较为粗糙,无法准确获取代码深层次的语义信息。
本文采用面向缺陷检测过程的指令集提取技术——将空指针引用、资源泄露等具体的程序缺陷抽象为一种缺陷模型, 通过缺陷模式状态机的创建条件及程序语义确定是否创建该缺陷的状态机实例,并通过在为源代码构建的分析底层框架(控制流图等)上迭代状态引发状态间的转换检测出程序中的潜在缺陷,在此缺陷检测过程中,收集并提取导致状态发生改变的控制流节点集合,这些节点对应的源代码片段即为相关指令集。基于该原理的指令集提取过程如算法2所示。
算法2:
输入 程序控制流图和缺陷模式描述状态机
输出 缺陷模式状态机实例状态转换对应的控制流节点集合
1:for n in G(N, E, Entry, Exit) do
2:inStateSet[n] ← Ø
3:outStateSet[n] ← Ø /*初始化*/
4:end
5:changeList ← List() /*声明changeList用来存放状态改变的控制流节点*/
6:outStateSet[Entry]←D{$start(Var[])}/*入口节点的初始状态集合*/
7:statechange ← true
8:while statechange do
9:statechange ← false
10:for 除 Entry的每个节点n do
11:inStateSet[n] ←
12:Up∈pred[n]outStateSet[p]13:oldout ← outStateSet[n]outStateSet[n] ← gen[n]
14:U (inStateSet[n]-kill[n])if outStateSet[n] ≠oldout then /*满足该条件时状态发生改变*/
15:statechange ← true
16:changeList.add(n) /*将状态改变的控制流节点放入list*/
17:end
18: end
19:end
20: return changeList
以bad函数的源码为例,相关指令集提取的具体细节如图3所示。bad函数共有5个控制流节点,在节点Entry处,状态机实例处于start状态;在节点n1处,结构体指针twoInts初始化为NULL,此时发生状态转换START->MAYNULL;在节点n2处,twoInts在位操作符&后发生解引用,此时状态转换MAYNULL->ERROR。因此,bad函数中与NPD警报相关的指令集为控制流节点n1、n2对应的代码段。
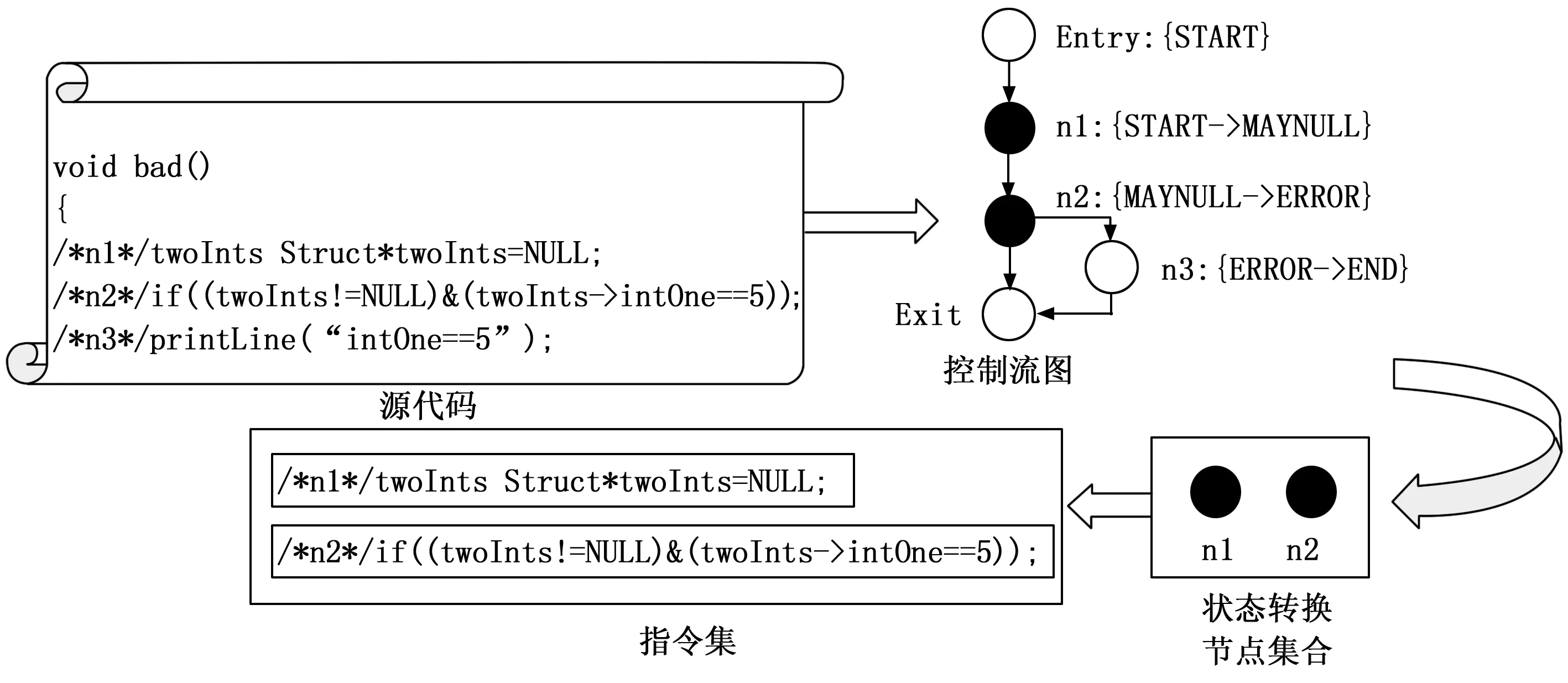
图3 bad函数相关指令集提取
2.2 基于指令集的细粒度特征提取方法
源代码语句中细粒度结构信息在之前的方法中往往会被忽视。为了做一个简单的解释,本文引入两个C语言函数为例,如图4所示。两个函数都有类型声明type declaration 语句,if语句,以及函数调用function invocation语句。两者唯一的区别在于if语句中操作符不同,使用单一的&操作符会使表达式的两侧均被计算,从而导致NPD缺陷,正如bad函数展示的那样。但是在good函数中,使用&&操作符可以避免NPD缺陷,当表达式左侧不满足条件时,右侧将不会被计算。现有的基于深度学习的方法大多只是根据上下文信息将代码片段映射为字符串序列,这样无法区别条件谓词表达式中细微的区别。因此两个函数的字符串序列表示也是一样的,可以用序列[TYPE_DECLARATION, IF_STATEMENT, FUNCTION_INVOCATION]表示,但是它们的确认结果是完全相反的。

图4 两个C语言函数
本文提出一种新的细粒度的特征提取方法,可以准确地反映条件谓词表达式中各操作符与操作数之间的细微区别。该方法从以下5种类型的语法树节点中提取特征:1)Assignment Expression Node;2)Declaration Node;3)Function Invocation Node;4)SelectionStatement Node(例如 if、switch语句);5)IterationStatement Node(例如for、while语句);6)JumpStatement Node(例如return、break语句)。通过从这些节点及其子节点中提取操作符及操作数,再按照表达式从左到右的顺序将他们排序,最后以该顺序映射为定义好的字符串序列。
图5列出了本文中使用的所有选定节点类型和原子指令,使用每个节点的名称类型和原子指令作为标识符。考虑到函数和变量的名称通常是特定于工程的,不同工程中具有相同名称的函数可能实现不同的功能,为了保证跨工程确认的可行性,本文使用两种类型名称,表示库函数和用户定义函数分别标记函数调用节点而不是使用特定名称,字符串LIBRARY_FUNCTION_INVOCATION和USER_DEFINE_FUNCTION_INVOCATION分别表示库函数和用户自定义函数调用。对于IP(Inspection Point)变量——在检查点与缺陷直接相关的变量,本文用VAR_IP表示,其他变量用VAR_OTHER表示。
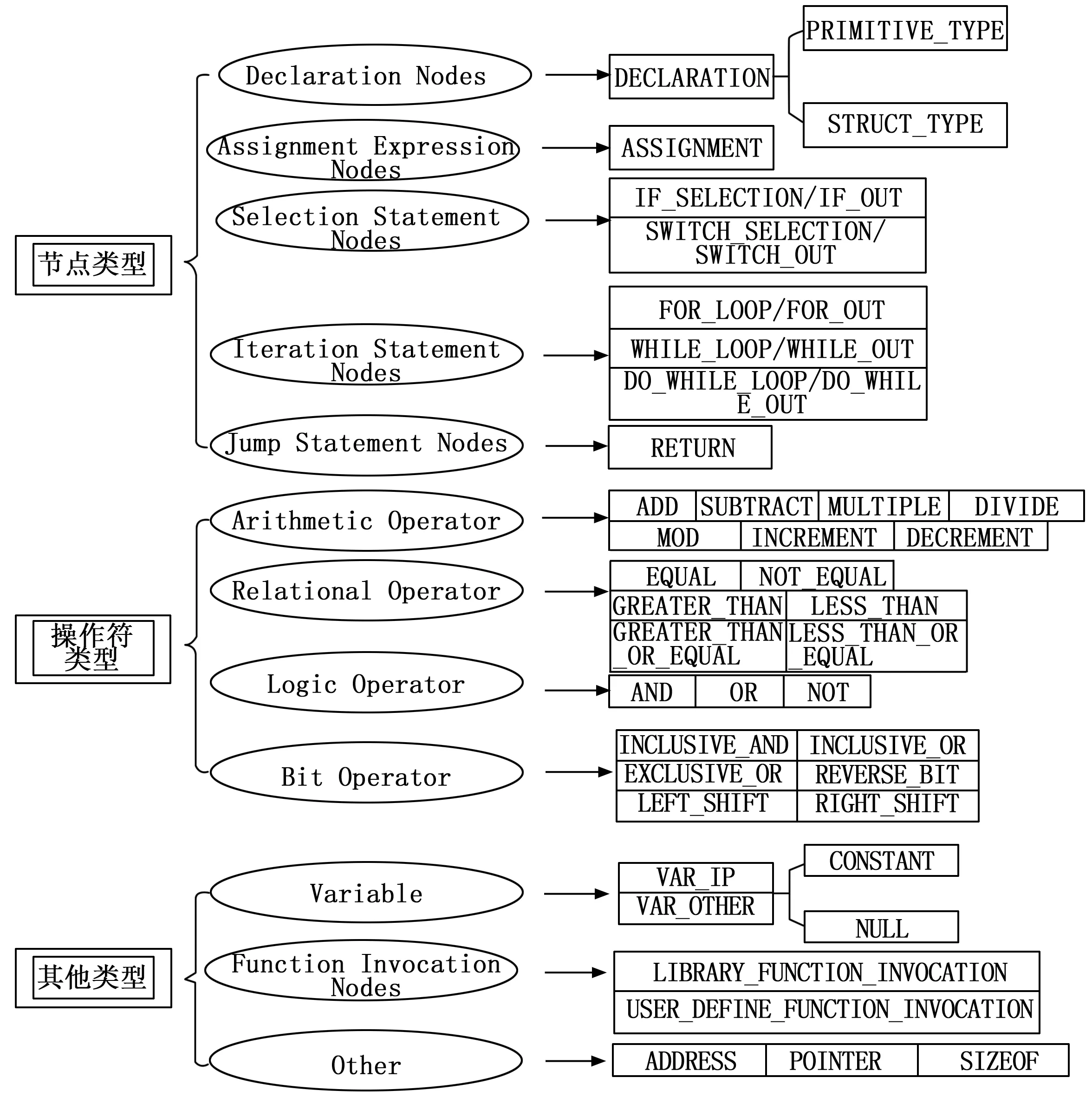
图5 各节点类型和原子指令对应字符
以bad函数警报相关的指令集为例,将其映射为上下文相关的字符串序列,特征提取的详细过程及结果如图6所示。在该函数中,有一条NPD警报生成,在控制流节点n1和n2处缺陷模式状态机实例发生状态转换,n1处状态转换为START->NULL,n2处状态转换为NULL->ERROR。
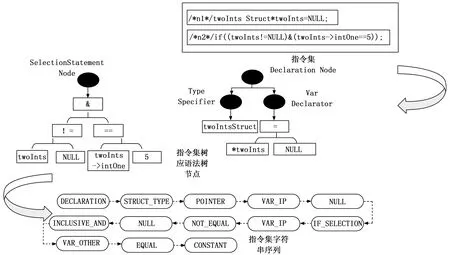
图6 相关指令集特征提取
节点n1对应代码行是声明语句,对应语法树节点Declaration Node类型,twoIntsStruct是结构体类型,twoInts是一个结构体指针,twoInts是IP变量,且初始化为NULL,因此节点n1相关指令可以映射为字符串序列{DECLARATION,STRUCT_TYPE,POINTER,VAR_IP,NULL}。
节点n2对应代码行是选择语句,对应语法树节点SelectionStatement Node类型, twoInts->intOne是其他变量,“!=”和“#”是比较操作符,“&”是位操作符,“5”是常数,因此节点n2相关指令可以映射为字符串序列{IF_SELECTION,VAR_IP,NOT_EQUAL,NULL,INCLUSIVE_AND,VAR_OTHER,EQUAL,CONSTANT}。
2.3 字符串编码以及深度神经网络的构建和训练
2.3.1 字符串向量编码
因为字符串序列无法直接作为神经网络的输入,需要通过词嵌入技术将其转换为数值向量。本文首先统计字符串的总类,将每一种字符串都对应一个正整数索引,从1开始。由于低维的整数无法有效描述字符串序列中的结构及上下文信息,本文将其映射到高维的向量空间,并且有着相似上下文的字符串在高维向量空间中的分布会更加接近。
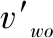
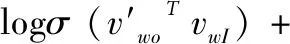
(1)
因为Word2vec本质上也是训练神经网络,本文采用随机梯度下降(SGD,stochastic gradient descent)进行优化。最终每一个字符串都被表示成了一个n维向量Rn,n的大小可以自己设置,本文将n设置为150,负采样样本大小k设置为100。
由于字符串序列的长度存在差异,而神经网络的输入要求每一个样本的长度相同,本文需要对长度较短的序列进行填充(padding),将多个padding字符串填充在较短的序列末尾,使其长度和样本中最长的字符串序列相同,padding字符串用n维零向量表示。
2.3.2 训练模型及警报自动确认
循环神经网络(RNN,recurrent neural networks)是一个在时间上传递的神经网络,网络的深度就是时间的长度。该神经网络是专门用来处理时间序列问题的,能够提取时间序列的信息。如果是前向神经网络,每一层的神经元信号只能够向下一层传播,样本的处理在时刻上是独立的。对于循环神经网络而言,神经元在这个时刻的输出可以直接影响下一个时间点的输入,该神经网络能够处理时间序列方面的问题。因此,RNN对具有序列特性的数据非常有效,它能挖掘时序信息以及语义信息,利用这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题有所突破。同样,RNN网络也可以应用到程序语言处理(PLP,program language process)问题中。
因为模型的输入是存在上下文依赖关系的向量序列,本文选择RNN作为基本模型,通过调整RNN的种类,具体表现为长短期记忆网络(LSTM,long-short term memory)与门控循环单元网络(GRU,gated recurrent unit)。 RNN的层数为两层,RNN的方向为双向,并与逻辑回归(LR,logistic regression)分类器结合。首先把5个开源工程中所有的警报人工确认好,按照State2Vec的前两步映射为对应的字符串序列,接着按照第三步将每种出现的字符串训练为词向量,将每一条字符串序列转换为向量集合,并在它们末尾以零向量填充,数据集构建完成。开始进行工程内的自动确认实验,将5个工程的数据集依次分为训练集和测试集,再分别用5个工程的训练集训练,调整RNN的类型搭配,分别训练出LSTM和GRU类型的RNN模型,再分析不同的模型在不同工程测试集内的自动确认情况。挑选出效果最好的模型,进行跨工程的实验。因为在同一工程内,训练集和测试集样本的分布可以认为在同一向量空间,本文提出的细粒度的特征提取方法也是尽可能缩小不同工程间样本在向量空间中分布的差异性。因此,在使用此特征提取方法的前提下,工程内确认效果更好的模型理论上在跨工程确认场景中也会取得更好的效果。跨工程实验的训练集是某4个工程全部样本的集合,测试集是另一个工程的全部样本,实验过程中依次将每个工程的全部样本作为测试集。
3 实验
3.1 实验构建
针对模型的构建和训练,本文使用Pytorch框架进行实验,版本为1.7.1,python版本为3.8.5,实验在服务器上运行,服务器环境如下:Ubuntu 18.04.5 LTS,Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10 GHz,160 GB RAM,GPU TITAN Xp (12 GB memory)。
3.1.1 数据准备
本文用5个开源C工程(如表1所示)中人工标签好的警报作为数据集,从近期的研究方法[16-18]中挑选了4个工程,它们的警报由SA工具测出,已通过人工确认打上标签。最后,本文制作了基于android-4.0 C 语言源码的漏洞数据库,通过SA工具DTS[19]对其C源码分析得到警报,再人工确认并打上标签。这些工程代码行数从1 991到325 164 1不等,警报数量从74到5 235不等,警报中阳性比例(确认结果为True)最小占50.0%,最大占87.3%。
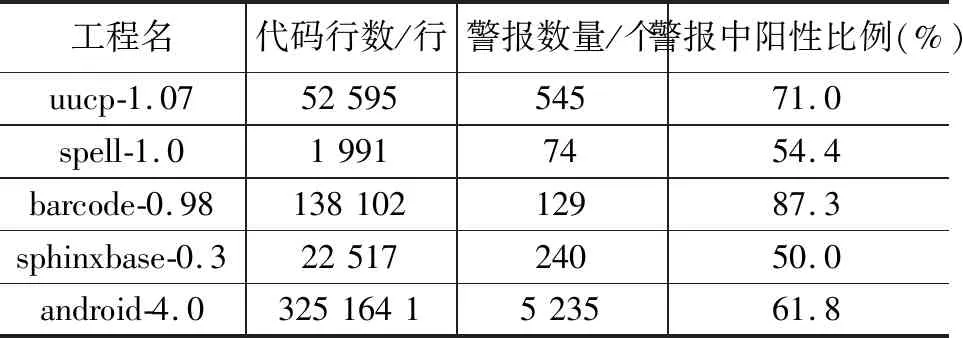
表1 5个开源C工程基本信息
3.1.2 实验表现度量元
过去的研究[20-21]表明,当数据集中正负样本比例不平衡时,用精准率(precision)和召回率(recall)来衡量实验的表现是存在问题的,因为它们对正负样本的分布比较敏感。同时,LR阈值(threshold)的设置也会对它们产生影响。因此,本文采用曲线下面积(AUC,area under curve)来度量模型自动确认的表现。
在二分类实验中,本文一般关注4个指标:1)真阳性(TP,true positive):数据集中本身既是缺陷也被模型预测为缺陷的警报的数量;2)假阳性(FP,false positive):数据集中本身不是缺陷却被模型预测为缺陷的警报的数量;3)真阴性(TN,true negative):数据集中本身既不是缺陷也被模型预测为非缺陷的警报的数量;4)假阴性(FN,false negative):数据集中本身是缺陷却被模型预测为非缺陷的警报的数量。AUC表示受试者工作特征(ROC,receiver operating characteristic)曲线下的面积,ROC曲线是基于样本的真实类别和预测概率来画的。具体来说,ROC曲线的x轴是假阳性率(FPR,false positive rate),y轴是真阳性率(TPR,true positive rate),FPR和TPR的计算见示(2)和式(3)。
FPR=FP/(FP+TN)
(2)
TPR=TP/(TP+FN)
(3)
AUC的值在区间[0,1]内,值越接近1,说明模型的表现越好。若接近0.5,说明分类器近似于随机分类。若小于0.5,这种情况说明分类器趋向把正样本分类为负样本,负样本分类为正样本。AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器做出合理的评价。
3.1.3 实验参数设置
1)词向量训练相关参数:词典大小是63,即一共有63种字符串。通过词嵌入映射成的高维向量维度设置为150,学习率( LR,Learning Rate)设置为0.1,训练时每一批数据数量为128,优化器选择SGD,迭代次数Epoch为5次。
2)RNN相关参数:工程内确认实验时,对比双层双向LSTM和双层双向GRU,隐层神经元均设置为100个。训练时每一批数据数量为64,LR=0.01,优化器选择SGD,迭代次数Epoch为200次。跨工程确认实验时,选择工程内确认实验效果较好的模型,其他参数设置不变。
3.1.4 实验过程
本文先分别用5个工程进行工程内的缺陷确认实验。采用十折交叉验证的方法,先将每个工程的数据集均分为十份,轮流将其中九份作为训练集,剩下一份作为测试集,共实验十次,并取十次结果的平均值。在跨工程实验中,训练集是某4个工程全部样本的集合,测试集是另一个工程的全部样本,并依次将每个工程的全部样本作为测试集。再训练之前工程内实验效果更好的一组RNN模型,计算在不同工程下的AUC值。同时,基于这些工程引入对比试验。
为了评价在跨工程任务上的表现,本文挑选了两组基准,与它们的实验结果对比。
1)LR:一种传统的方法,基于28种通用的度量元特征,这些特征的完整定义在[22]中有详细介绍。
2)FRM-TL:一种基于路径变量特征(PVC,path-variable characteristic)等级匹配的跨工程缺陷确认模型[16]。
3.2 实验结果及分析
3.2.1 工程内缺陷确认实验结果及分析
工程内缺陷确认(WPDI,within project defect identification)反映了当数据集和验证集在向量空间同一区域分布时,State2Vec方法的检测结果,基于各个工程得到的AUC值如表2所示。
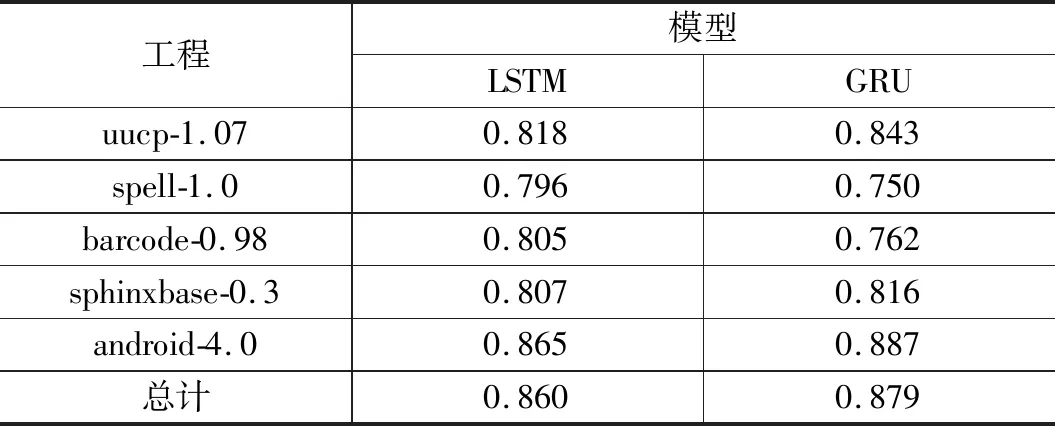
表2 工程内缺陷确认实验结果
可以发现,在uucp,sphinxbase和android这3个工程中,GRU组的确认效果会更好一些,而在spell和barcode这两个工程中,LSTM组的效果更好。具体来看,spell和barcode数据集中警报数量分别为74和129,是5个数据集中最少的。样本数量的不充足,导致模型一定程度上欠拟合,在GRU组中,spell和barcode的AUC值分别为0.750和0.762,低于LSTM组的0.796和0.805。在uucp,sphinxbase和android数据集中,警报的数量分别为545,240和5235,此时LSTM组的AUC值分别为0.818,0.807和0.865,均低于GRU组的0.843,0.816和0.887。根据该发现可以得出,当数据集中警报数量足够多时,选择GRU作为神经网络的基本单元,可以更有效地学习特征,达到更好的分类效果。在后续跨工程缺陷确认的实验中,训练集和验证集的警报数量都会大幅度提升,选择GRU作为基本单元更加符合实验场景。
3.2.2 跨工程缺陷确认实验结果及分析
跨工程缺陷确认(CPDI,cross project defect identification)反映了当训练集和验证集在向量空间不同区域分布时,State2Vec方法的检测结果。将该方法与LR和FRM-TL两组基准对比,各方法在各个工程上所得ROC曲线如图7~11所示,并将各方法实验结果的AUC值记录在表3中。在表3中,若State2Vec的实验结果好于基准FRM-TL,则将State2Vec列的数据加粗,若好于基准LR,则加入下划线。
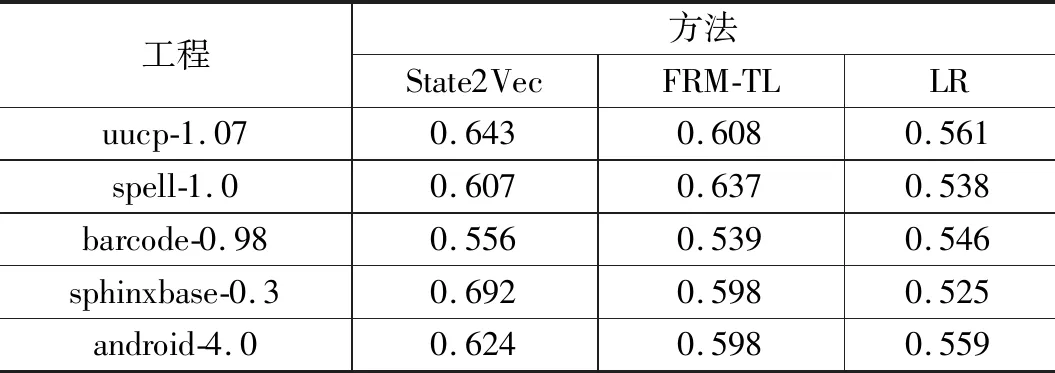
表3 跨工程缺陷确认实验结果
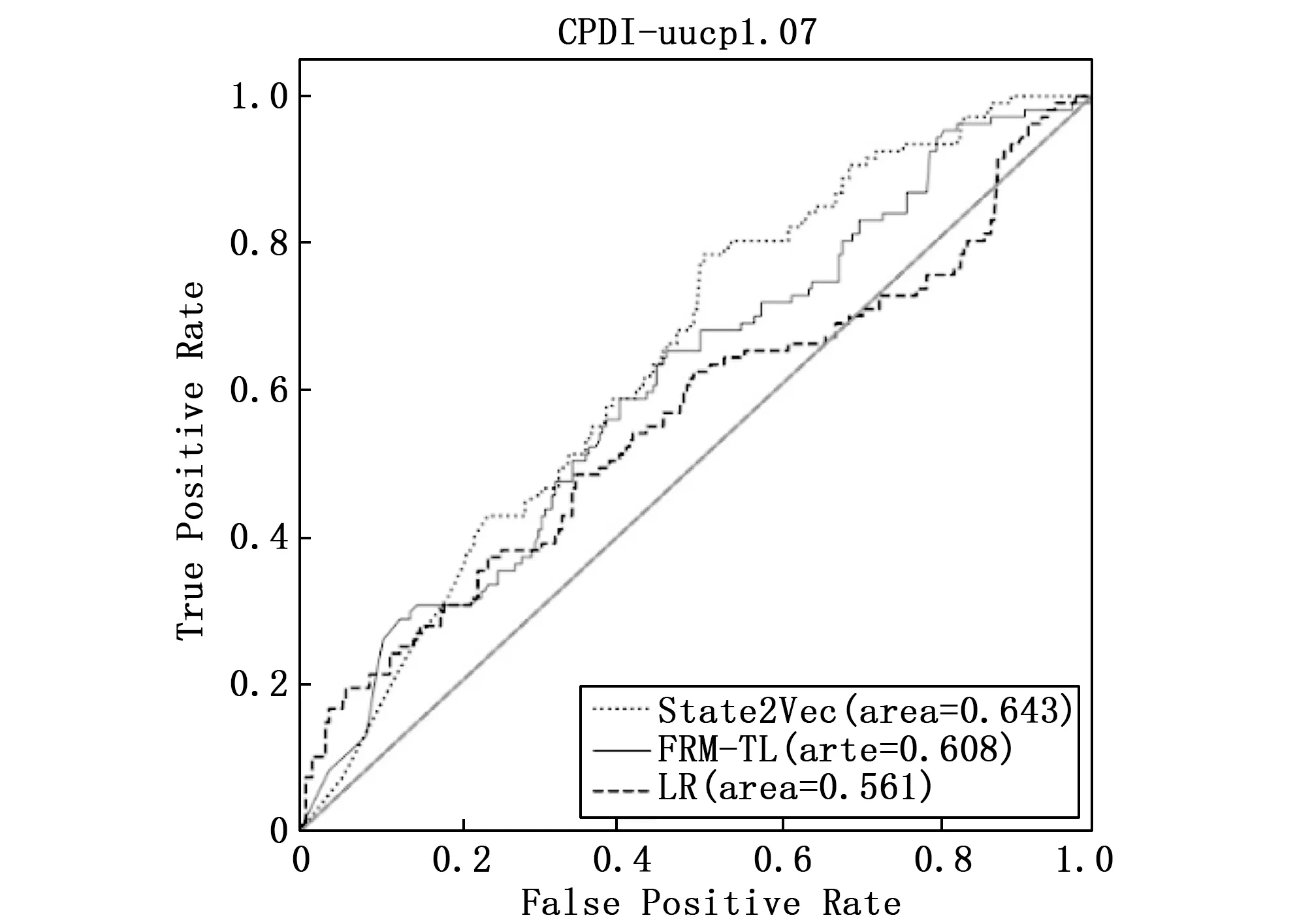
图7 uucp数据集上各方法跨工程缺陷确认ROC曲线
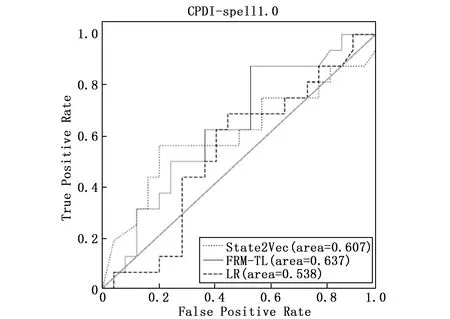
图8 spell数据集上各方法跨工程缺陷确认ROC曲线
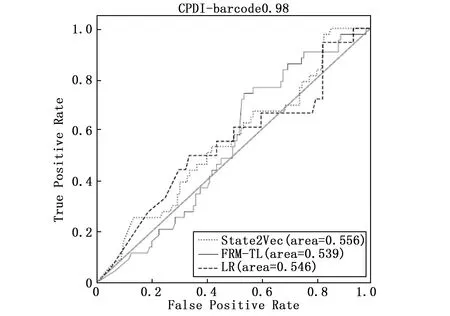
图9 barcode数据集上各方法跨工程缺陷确认ROC曲线
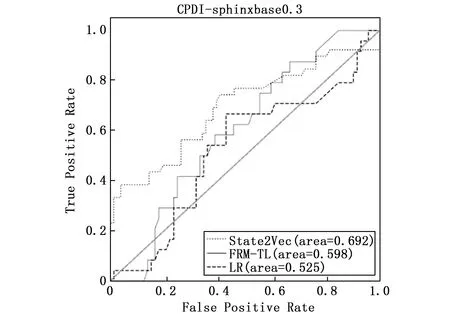
图10 sphinxbase数据集上各方法跨工程缺陷确认ROC曲线
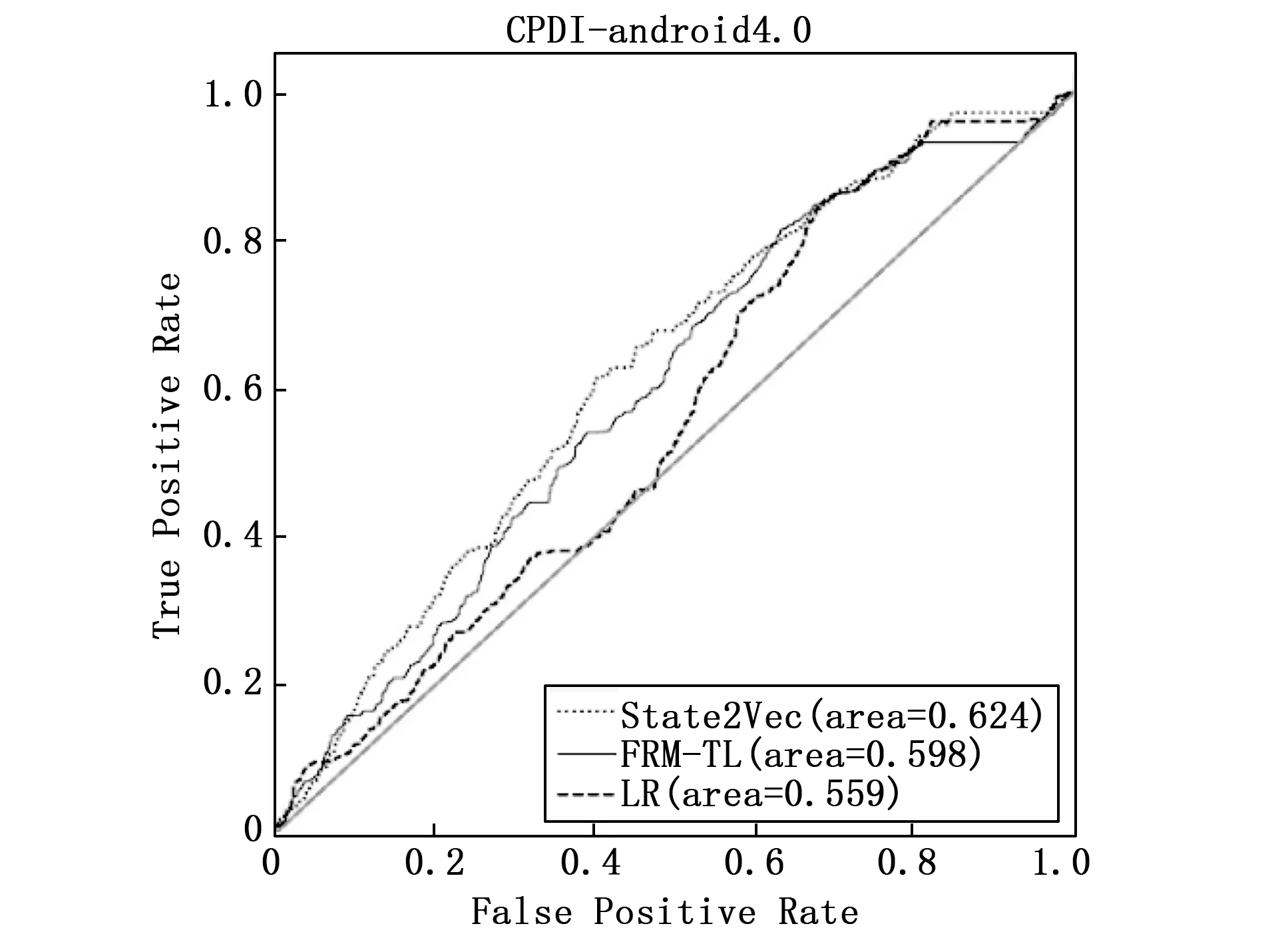
图11 android数据集上各方法跨工程缺陷确认ROC曲线
可以发现,在uucp,barcode,sphinxbase和android这4个工程中,使用State2Vec方法确认结果,AUC值分别为0.643,0.556,0.692,0.618,确认效果均好于基准FRM-TL的0.608,0.539,0.598,0.598,以及基准LR的0.561,0.546,0.525,0.559。但在工程spell中,State2Vec的AUC值为0.607,低于FRM-TL的0.637,高于LR的0.546。
由此得出,当警报训练集和验证集分布在向量空间的不同区域时,State2Vec的确认效果会受到一定程度的限制。与WPDI的结果相比,CPDI的AUC值在5个工程中分别下降了23.72%,5.93%,27.03%,15.20%和30.32%。 但是与FRM-TL的CPDI表现相比,State2Vec方法在工程uucp,barcode以及android上确认效果均有小幅度提升,提升幅度依次为5.76%,3.15%和3.34%;在工程sphinxbase上有较大的提升,提升幅度为15.72%;但是在工程spell中,AUC值下降了4.70%,这是因为工程spell的警报数据集中仅含NPD和MLF两种缺陷模式,而由其他4个工程构成的警报训练集中包含多种缺陷模式,因此通过学习含有多种缺陷模式的警报数据集中的语义信息,无法准确地将所学知识迁移到目标域,导致指标AUC在工程spell的警报验证集上下降。与LR相比,该方法在工程uucp,spell,sphinxbase,android上确认效果均有较大幅度的提升,AUC指标提升幅度依次为14.62%,12.83%,31.81%,10.55%;在工程barcode上有轻微的提升,提升幅度为1.83%。
4 结束语
本文提出State2Vec方法,该方法面向缺陷模式状态机的检测过程,先收集导致缺陷模式状态机状态发生改变的指令集,再通过特征提取将指令集转换成设计好的字符串序列,最后通过词嵌入技术将字符串映射到高维向量空间。实验证明,State2Vec方法可以较为有效的提取不同工程中的状态指令集,通过定义并构建结构化的可以表示指令集语法及语义信息的字符串序列,加以词嵌入技术将字符串集合映射到高维向量空间,并以此训练神经网络模型,使得模型能有效学习指令集中的特征,一定程度上提升了在CPDI任务场景中的泛化能力。
在日常的开发过程中构建某新的软件项目的警报数据库时,通常缺少足够的历史数据,或者能够用于训练模型的警报数据较为稀疏,导致无法基于同项目警报自动确认技术构建警报数据库,此时可以采用State2Vec方法,利用历史项目的警报数据库构建该新项目的警报数据库。
在接下来的工作中,会在更多实际的工程上构建缺陷数据库,用新的数据集检验本文方法的可行性,以及该方法在新的数据集上是否依旧存在较好的泛化能力。因为大多数的程序语言都有语法树和控制流图,也会将该方法拓展到其他程序语言上。另外,未来也考虑构建结构更复杂的神经网络模型,比如将循环神经网络与卷积神经网络(CNN,convolutional neural network)结合,使模型能够更好的学习代码中的语义特征,从而达到更好的分类效果。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
卫星应用(2022年3期)2022-05-23
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
科普童话·百科探秘(2019年8期)2019-09-18
少儿科学周刊·少年版(2018年12期)2018-01-26
软件(2017年6期)2017-09-23
Coco薇(2017年8期)2017-08-03
数字技术与应用(2017年3期)2017-05-17
科教导刊·电子版(2016年30期)2016-12-26
