
个性化馆藏资源推荐技术在公共图书馆中的适用性分析
2022-08-01 13:27胡清
图书馆界 2022年3期
胡 清
(青岛市图书馆,山东 青岛 266000)
1 引 言
个性化馆藏资源推荐是指根据用户的行为习惯、个性特点以及特定需求,通过语义匹配、协同过滤等技术自动将馆藏资源推送给潜在读者用户的过程。个性化馆藏资源推荐是图书馆传统信息检索发展演化的新形式,是图书馆从被动服务向主动服务转型的标志性技术之一。早在1999年,美国图书馆信息技术协会(LITA)的10位著名的数字图书馆专家就把个性化定制服务列为数字图书馆技术发展的七大趋势之首。进入21世纪,大数据、云计算、物联网等新一代信息技术蓬勃发展,用户对信息的需求、传递、交流、获取发生本质变化,多元化、知识化、专业化、个性化成为信息需求新的主要特征。同时,资源过载、资源长尾现象、馆藏资源利用率低等问题更加突出,传统信息检索已无法满足用户对信息获取的迫切需求,这进一步加强了用户对馆藏资源个性化推荐的需求。根据郭婧婧等、李民等对个性化馆藏资源推荐的必要性与满意度调研结果显示,从需求角度来看,71%的高校图书馆认为开展个性化馆藏资源推荐具有必要性,而公共图书馆需求更高,有91%的参调人员认为个性化推荐具有必要性。从满意度来看,有61%的高校图书馆参调人员与23%的公共图书馆参调人员认为个性化馆藏资源推荐未达到用户预期(见表1)。
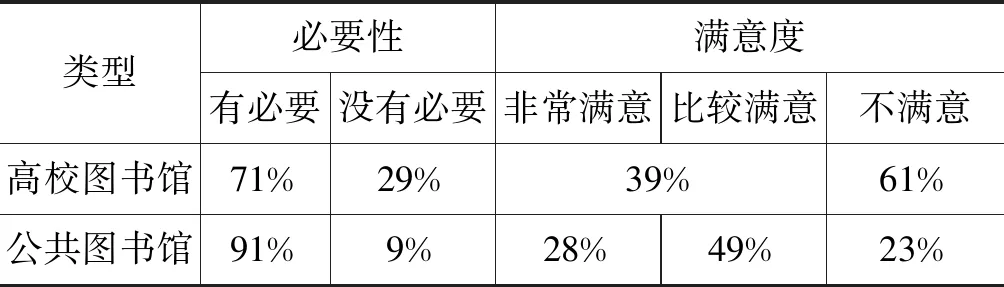
表1 个性化馆藏资源推荐的必要性与满意度分析
个性化馆藏资源推荐自提出后便受到了广泛的关注,学界围绕个性化馆藏资源推荐在图书馆应用的理论、技术以及实践等方面开展了丰富的研究,随着深度学习、机器学习、自然语言处理以及图理论等相关研究的深入,个性化馆藏资源推荐算法逐渐突破了基于内容、协同过滤等传统的算法思路,引入了本体、环境捕捉、位置感知等技术,大大提高了推荐的准确度、多样性、新鲜度等关键指标。然而,目前绝大多数研究聚焦于较少区分高校图书馆与公共图书馆在推荐需求方面的差异,而在算法的设计与技术指标的选择上并未充分考虑公共图书馆与高校图书馆在数据特征、读者特征方面的特殊性。
公共图书馆在数据基础、推荐受众、推荐内容以及推荐需求等方面与高校图书馆存在一定程度的客观差异,影响着推荐算法的选择。一方面,相较于高校图书馆,公共图书馆的服务对象较广泛,用户数量庞大,但受限于图书馆数字化水平与数据收集策略,用户建模的基础数据较少,冷启动和数据稀疏的问题更加突出;另一方面,公共图书馆与高校图书馆的社会功能定位不同,导致推荐的馆藏结构和内容等存在较大差异,如在藏书结构方面,公共图书馆注重馆藏资源的普适性,而高校图书馆则注重专业数字资源建设,在推荐算法的选择上要依据数据差异进行有针对性的选择。
为此,本研究在分析公共图书馆在数据基础、推荐受众、馆藏结构、推荐需求等方面特殊性的基础上,对个性化馆藏资源推荐技术在公共图书馆中的技术适用性进行分析讨论。首先总结图书馆开展个性化资源推荐现状研究,厘清主流的推荐技术以及其适用范围与优缺点;然后讨论公共图书馆资源推荐需求,着重分析公共图书馆与高校图书馆在数据基础、推荐受众、推荐内容以及推荐算法需求等方面的具体差异;最后分析个性化馆藏资源推荐技术的技术适用性,提出技术选择建议(见图1)。
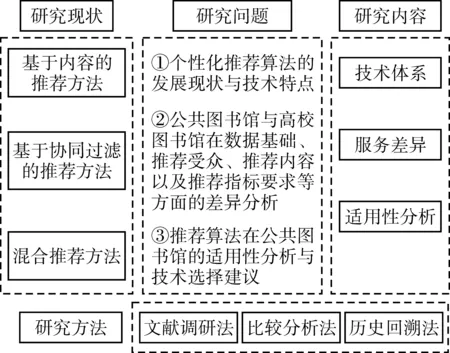
图1 研究思路图示
2 图书馆开展个性化馆藏资源推荐现状研究及典型算法特点分析
与传统资源推荐相似,图书馆馆藏资源推荐的研究主要集中在数据采集、馆藏资源与用户兴趣特征提取、推荐算法设计3个方面,拟解决的问题主要有冷启动、数据稀疏以及推荐结果相关性、权威度、新鲜度等关键指标计算等方面,技术手段主要有基于内容的推荐方法、协同过滤的推荐方法和混合推荐方法,具体研究进展如下。
2.1 基于内容的推荐方法
基于内容的推荐方法是指根据用户查阅过的馆藏资源,将其他相似的馆藏资源推荐给读者用户,最早提出并应用的基于规则的推荐算法便属于该类算法的一种。此类方法主要借鉴图书馆信息检索系统的理念,以读者兴趣与待推荐资源的相关性作为主要的推荐依据。例如,郑祥云等提出一种基于主题模型的个性化图书推荐算法,在主题模型LDA的基础上进行适应性改造,提出BR_LDA算法,依据读者的历史借阅记录与待推荐资源的语义相似度来获得推荐结果。高晟等提出一种基于关联规则与贝叶斯网络的高校图书馆个性化图书推荐方法,综合了学科、兴趣、需求等特征遴选馆藏资源。王刚提出一种融合用户行为分析和兴趣序列相似性的个性化推荐方法,融入时间特征、相关性以及兴趣序列等特征,综合多维度特征开展推荐工作。
2.2 基于协同过滤的推荐方法
基于协同过滤的推荐方法是从图书馆用户的角度出发,根据与该用户相似用户间兴趣偏好来定义被推荐对象的用户偏好。例如,程秀峰对传统协同过滤的推荐算法进行改造,提出一种融入朴素贝叶斯算法与情景的协同推荐算法,使推荐准确率有一定的提升。盛先锋提出一种基于聚类优化的数字图书馆协同过滤个性化推荐方法,在协同过滤前利用聚类算法初步数据填充与经验积累,在一定程度上缓解了数据稀疏的问题,提高了协同过滤的准确性。田磊提出一种基于聚类优化的协同过滤个性化图书推荐方法,利用改进的K-means算法对用户偏好进行提前分析,然后通过用户借阅偏好性矩阵实现基于协同过滤的推荐。基于协同过滤的推荐方法可以在一定程度上解决数据稀疏、冷启动的问题。
2.3 混合推荐方法
混合推荐方法是一种组合式的推荐方法,旨在对待推荐文献与用户兴趣的多维特征进行深度探析。该类方法能克服上述两种推荐方法的弱点,同时综合了效用、知识、动态特征、环境特征等维度开展资源推荐。例如,刘晓艳提出一种融合情境感知的移动图书馆个性化推荐技术方法,假设用户所处的位置不同所需要的资源也不同,从而依据情境环境来预测读者偏好信息。黄涛提出一种地方志资源的混合推荐模型,基于协同过滤技术,改进TopN和关联规则算法,解决了数据稀疏、内容特征提取难度大、新用户推荐冷启动等问题。钟克吟提出一种基于混合推荐的学术资源推荐系统,可以从浏览行为、关联数据、搜索习惯等多维度进行特征提取,采用基于内容、规则的方法构建用户需求库。
2.4 小结
随着各研究学者对技术的深耕,研究重点由理论研究转向技术研究,特别是深度学习、机器学习、自然语言处理以及图理论的进一步丰富,个性化馆藏资源推荐算法逐渐突破了基于内容、协同过滤等传统的算法思路,引入了本体、环境捕捉、位置感知等技术,大大提高了推荐的准确度、多样性、新鲜度等关键指标。目前,常见个性化馆藏资源推荐的主流技术的优缺点如表2所示。但目前相关研究主要存在以下问题:1)绝大多数研究聚焦于未区分公共图书馆与高校图书馆的区别,在算法的设计与技术指标的选择上未充分考虑公共图书馆的在数据特征、读者特征方面的特殊性。2)技术维度较单一,仍然局限于对单个技术的应用,未考虑公共图书馆数据源复杂,系统异构、数据交叉等基础性问题,影响用户兴趣的建模与推荐质量。
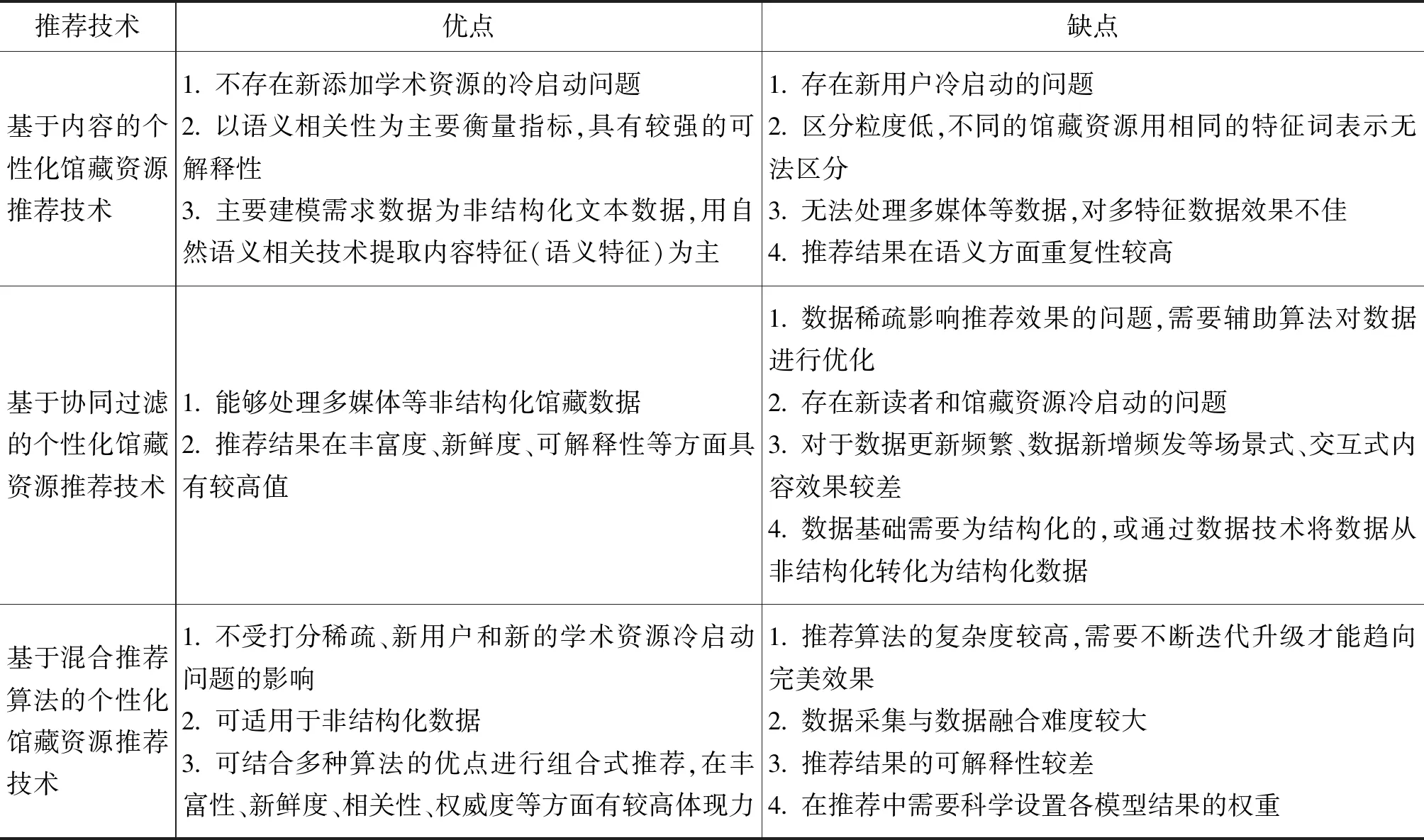
表2 常见个性化馆藏资源推荐技术的优缺点分析
3 公共图书馆与高校图书馆在个性化馆藏资源推荐方面的差异分析
公共图书馆与高校图书馆在功能定位上存在客观差异,个性化馆藏资源推荐技术的选择需要根据各自的特点而有所不同。高校图书馆主要为在校大学生学习专业知识以及教师开展教学科研提供资源服务,而公共图书馆主要为社会公众提供免费服务,承担大众服务、文化引导的责任,故二者在馆藏资源、服务对象、服务目标、功能定位以及推荐需求等方面存在一些差别。高校图书馆与公共图书馆的差别主要体现在以下方面。
3.1 数据基础不同
图书馆收集的数据是用户真实需求和兴趣建模的基础,是后续算法设计的保障与依据。相较于高校图书馆,公共图书馆用户数据量大,且更新相对频繁,但用户关键属性数据较少,存在数据稀疏与冷启动的问题。主要表现在以下方面:1)从用户个体数据来看,高校图书馆凭借校园卡以及学号使用图书馆资源服务,校园卡与学号通常会关联较为丰富的个体关键属性数据,如学院、专业、性别、年龄、年级、发表论文等,为用户兴趣的建模提供了必要的数据源,能在一定程度上解决推荐冷启动的问题,而公共图书馆较难掌握例如专业、论文发表等数据。2)从用户规模上来看,高校图书馆服务对象为在校大学生以及教职员工,用户数量较少且较为稳定,用户数据更新慢。而公共图书馆尤其是省市级公共图书馆面对的读者数量众多,部分大城市公共图书馆用户量达到百万级甚至千万级,且用户数据更新频繁。3)从用户参与度角度来看,高校图书馆是获取学术资源的主要途径,在校师生对其依赖性强,访问比较频繁,由于用户参与较多,高校图书馆获取用户痕迹数据较容易。而用户去公共图书馆借阅的频次较少,参与程度较低,公共图书馆很难依靠访问痕迹与浏览记录真正了解、掌握和预测他们在阅读方面的真实需求。
3.2 推荐受众不同
推荐受众是推荐算法服务的主要对象,分析推荐受众的分布特点、文化层次以及关注点有助于推荐算法参数、特征的选择。高校图书馆主要为在校师生提供科研、教学的基础资源服务,而公共图书馆的服务对象比较广泛,涉及各类职业、各种文化层次的读者。在推荐受众上,主要有两点差异影响推荐算法的选择。1)职业不同。推荐人群的职业不同,所关注的推荐点也不同。高校图书馆面向人群主要为在校大学生与教职员工,成分比较单一,专业较为具体,兴趣需求易于掌握与分析。而公共图书馆面向人群更多样,既有学术研究的需求,又存在爱好阅读、休闲欣赏的需求,需求具多样性、复杂性,较难捕捉与分析。2)知识层次不同。高校图书馆服务人群一般有教师、研究生、本科生等,而公共图书馆面向人群知识层次差异较大,关注点也不统一,对馆藏文献的需求也存在差别。
3.3 推荐内容不同
推荐资源内容结构直接决定其语义建模与特征提取方式。因公共图书馆与高校图书馆两者在功能定位、服务受众等方面存在客观差异,故二者在馆藏结构与馆藏内容上也存在一些区别。公共图书馆藏资源更注重资源的普适性,以科普类、休闲娱乐类、专业文文献为主,部分区域级公共图书馆在传统资源建设的基础上,馆藏资源更强调本地特色,如典藏地方古籍文献等;高校图书馆是学术性机构,主要为高校教学、学术研究提供服务,在满足在校大学生与教职员工公共阅读需求的同时,更加强调馆藏资源的专业性。因此,在待推荐文献的语义提取、主题挖掘方面有不一样的选择。
3.4 推荐算法要求指标不同
一般来说,考核推荐系统的主要指标有相关性、权威度、新颖度、启发性、长尾资源挖掘能力、主题多样性等。其中,相关性是主要的考核指标,一般指推荐资源与用户兴趣的直接匹配度,是考核推荐算法最基本的指标,公共图书馆与高校图书馆均对此要求较高。权威度是指推荐结果的知名度与影响力,高校图书馆以推荐文献资源为主,且用户较为专业,故对推荐资源的权威度与启发性要求较高。公共图书馆资源结构以科普文献、休闲娱乐文献、专业文献、地方特色文献为主,普及性、普适性、区域特色性较强,且用户层次较为广泛,故在保证资源准确性的基础上,对推荐结果的权威度要较低,对新颖性、主题多样性以及部分长尾资源挖掘能力要求较高(见表3)。
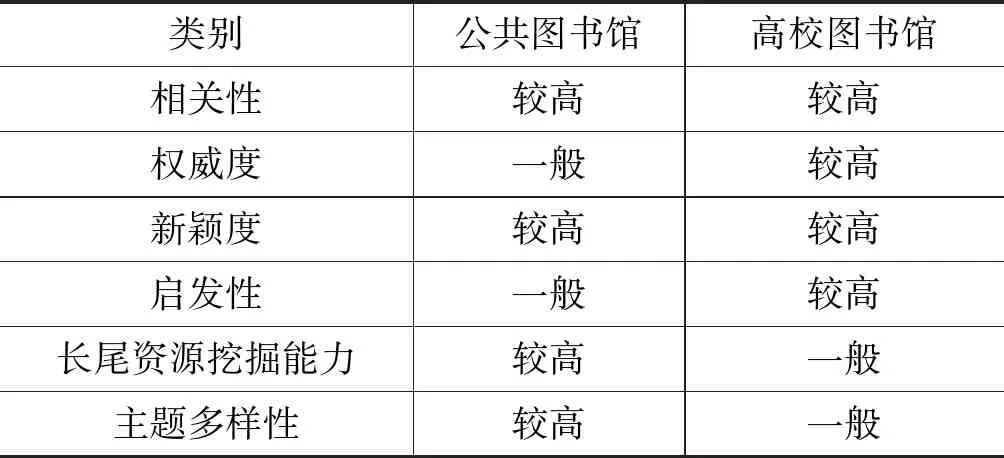
表3 公共图书馆与高校图书馆推荐算法要求指标的差异
4 公共图书馆个性化馆藏资源推荐技术适用性分析与应用建议
结合公共图书馆在数据基础、推荐受众、资源结构等方面的特点,本研究从数据采集与预处理、特征提取、算法设计3个方面讨论个性化馆藏资源推荐技术的适用性。
4.1 数据采集与预处理
源数据是读者用户兴趣和需求建模的基础。受限于数字化水平、服务机制、用户参与度,公共图书馆存在不同程度的用户数据单一、数据稀疏、数据零散、数据痕迹单薄等问题,导致冷启动、长尾资源等现象较为普遍,但公共图书馆用户规模数据大,存在数据的规模优势。
在数据采集与数据预处理算法的选择方面,公共图书馆应注重对数据融合算法、聚类算法(预测算法)的应用,解决冷启动与数据稀疏的问题。主要有:1)数据融合。公共图书馆仅仅依赖于静态资源只能开展一般性的推荐,如利用点击量进行热门数字资源的推荐;依靠访问痕迹进行同类资源的推荐,导致在个性化、长尾资源挖掘、推荐结果新鲜度等方面表现较弱。因此,在资源推荐过程中,公共图书馆应利用外部环境数据,对用户兴趣进行预测,主要包括外部热门数据、馆外阅读热点、场景数据等,同时与其他单位如高校图书馆、学术资源数据库等开放接口对接,主动分析读者的需求与兴趣的变化,并作为前置经验嵌入模型中。此外,还应加强对质量数据的挖掘,利用爬虫程序爬取相关图书的评论数据,对馆藏图书资源进行评价,利用内外部评论数据、访问量数据对资源进行客观评价,用于矫正推荐结果。2)聚类算法。对大城市公共图书馆来说用户通常为百万级甚至千万级的,用户量大,且用户数据更新频繁。公共图书馆应加强K-means、基于密度的聚类方法、凝聚层次聚类等算法,对部分稀疏的数据进行必要字段的填充与预测,丰富建模的基础数据,避免空数据。
4.2 特征提取
特征提取分为馆藏资源的特征提取与读者兴趣的特征提取。公共图书馆个性化馆藏资源推荐存在受众广、推荐内容多样、读者层次差异大等问题。公共图书馆在馆藏结构方面更注重资源的普及性与普适性,在推荐结果方面更注重推荐主题多样性,在算法的选择上应注重对文献资源主题的提取,且注重多维度主题的挖掘。一是主题提取应利用多维主题挖掘模型——LDA,该模型可深度挖掘文献潜在的多个研究主题并计算出其中与用户需求相近的主题,实现对用户兴趣的延展。二是质量特征可利用内网外网两个来源的评论数据与情感倾向数据,对馆藏资源的质量进行评级,推荐质量高的馆藏资源。
4.3 算法设计
基于内容的推荐方法依靠文献资源与用户兴趣的语义相关性进行推荐,推荐结果具有较强的可解释性,推荐结果比较直观,不需要先验知识,但存在冷启动、数据稀疏的问题,对新用户的推荐效果不太理想。采用热门资源推荐可解决冷启动问题,但其弊端是过于普适性和大众化,缺乏个性化与针对性,无法达到理想的效果。同时,图书馆用户和馆藏资源通常具有多个属性,对于复杂属性的情况而言,基于内容的推荐方法效果不佳。相较于基于内容的推荐方法来看,基于协同过滤的推荐方法其推荐结果具有新鲜感,主题分散且多样,不需要先验知识来对算法进行提前干预,较适用于馆藏资源这样的结构化数据,但该算法的推荐质量过于依赖历史数据,推荐结果的质量需要不断依赖反馈修正才能达到预期效果。混合推荐方法因集成了基于内容与基于协同过滤两种推荐方法的优缺点,并融入了地理位置、上下文等情景因素,故该类算法能够很好地克服其他推荐算法的缺点,但不足是通常需要较大的计算能力作支撑。同时,该方法因融合了多种特征与因素,推荐计算时间较长,推荐结果较难解释。
基于对数据的采集与预处理,结合对馆藏资源与用户兴趣的特征提取,综合利用基于内容的推荐方法、基于协同过滤的推荐方法、基于混合推荐方法的思想,采用加权的方式,整合相关性、多样性、新鲜度、文献质量等特征,筛选出符合用户需求的馆藏资源。同时,根据用户对推荐资源的点击量、阅读时长等指标进行数据反馈,逐步调整各模型的权重,实现最优的推荐结果。
猜你喜欢
学校教育研究(2022年11期)2022-06-08
新班主任(2022年4期)2022-04-27
江苏科技报·E教中国(2022年3期)2022-04-19
世纪(2022年1期)2022-02-12
阅读与作文(英语初中版)(2019年8期)2019-08-27
民生周刊(2017年19期)2017-10-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
档案管理(2015年3期)2015-04-20
