
改进的PP-YOLO 网络遥感图像目标检测①
2022-07-26 06:05朱福珍
高技术通讯 2022年5期
朱福珍 王 帅 巫 红
(*黑龙江大学电子工程学院 哈尔滨 150080)
(**中南大学物理与电子学院 长沙 410006)
0 引言
遥感图像具有数据量大、数据复杂、目标分布广泛等特点,如何克服遥感图像目标繁多、种类密集、背景信息复杂等难点,快速精准地识别定位遥感图像中的目标,是当下遥感图像目标检测领域研究的热点和难点。遥感图像目标检测在遥感图像语义检索、智慧城市建设、资源调査、环境监测等领域具有重要意义[1]。本文对现阶段自然图像目标检测表现突出的PP-YOLO 网络进行改进,并将该网络进行迁移,更好地用于遥感图像目标检测。
传统的遥感图像目标检测算法主要是基于人工提取特征的方法,对专家经验依赖程度很高,且工作量巨大。随着深度学习技术的成功应用,全球重要赛事和实际应用已证明了其在目标检测中的强大实力。深度学习领域的重大转折始于2012 年的计算机视觉竞赛中由Krizhevsky 等人[2]改进设计的AlexNet,该网络设计获得了卷积神经网络模型图像分类最高的准确率。随着硬件技术的快速发展,大规模的深度学习网络架构呈现井喷式发布。例如,2014 年,Girshick 等人[3]提出区域卷积神经网络(region convolutional neural network,R-CNN)算法,该算法将目标检测任务分割成了目标分类和定位两个任务,实现了检测精度的重大突破,但是选择性搜索算法产生了大量的冗余候选框,候选区域特征提取过程中存在大量重复运算,这些都限制了模型的速度和性能。随后,基于其改进的Fast R-CNN[4]、Faster R-CNN 算法[5]以及Mask R-CNN[6]都在深度学习发展史上留下了浓墨重彩的一笔。
2017 年,提出的YOLO 系列算法成功地开创了单目标检测算法的时代[7-9],不再使用特定算法来产生候选框,而是巧妙地将回归问题与目标边框定位问题进行类比推理,极大地提升了目标检测器的速度和精度。同年,Lin 等人[10]在特征金字塔网络(feature pyramid network,FPN)算法中提出了bottom-up 与top-down 的结构,利用深层特征图的高语义特征与浅层的高分辨率信息融合后的特征层独立预测,提升了目标检测算法对小目标检测的效果。2019 年,CornerNet 算法[11]的提出,开创了无锚框算法的时代,成功解决了基于锚框的算法依赖手动设计、训练和预测过程低效及正负样本不均衡的问题,并取得了与基于锚框的算法相媲美的精度。
PP-YOLO 网络是基于百度编写的深度学习框架PaddlePaddle 上编写的,在目标检测方面体现了非常好的性能,将YOLOv3 模型的平均精度均值(mean average precision,mAP)在COCO 数据集对象检测任务上从38.9%提升到44.6%,并将推理速度(FPS)从58 增加到73。可见,与其他目标检测器相比PP-YOLO 模型检测性能有了很大的提升。与YOLO 系列算法不同,PP-YOLO 网络并没有探索不同的骨干网络和数据增强算法,也没有使用神经结构搜索(neural architecture search,NAS)超参数,而是采用一种改进的ResNet50-vd-dcn 骨干网络[12]替换掉了原YOLOv3 网络的骨干网络,并对现有的一些几乎不影响效率的有效技巧进行修改并叠加到原有网络中,以提高网络性能,做到有效性和效率之间的平衡。本文对PP-YOLO[12]网络在训练策略和网络结构两方面进行了改进优化,使其能够更好地适应遥感图像小目标任务的检测。
1 改进的PP-YOLO 网络遥感目标检测
PP-YOLO 网络是一种典型的单阶段目标检测算法,通常由骨干网络、检测颈(通常是一个特征金字塔网络)和检测头(物体分类和定位部分)组成[13]。本文在检测颈、数据增强策略和训练策略方面进行改进,用于提高遥感图像目标检测。
1.1 检测颈的改进
PP-YOLO 网络构建具有横向连接的特征金字塔,具体结构如图1 所示。为了简洁起见,图中省略了激活层。与传统的特征金字塔不同的是,PP-YOLO 加入了许多不影响精度的方法提升FPN 结构的性能,本文对检测颈的重要改进之一是对特征金字塔引入新的方法进行调整。在图2 中使用不同颜色的圆角框和连接线进行了标注,其中棕色圆角框表示该卷积层加入CoordConv 方法[14],紫色圆角框表示在该位置加入DropBlock 方法[15],红色连接线表示加入空间金字塔池化[16]方法。骨干网络的最后3 层的特征映射(C3,C4,C5)输入到FPN 网络中,在此定义l层特征金字塔输出的特征映射为Pl,本文实验时l=3,4,5。当输入图像尺寸为W×H时,输出特征映射Pl为
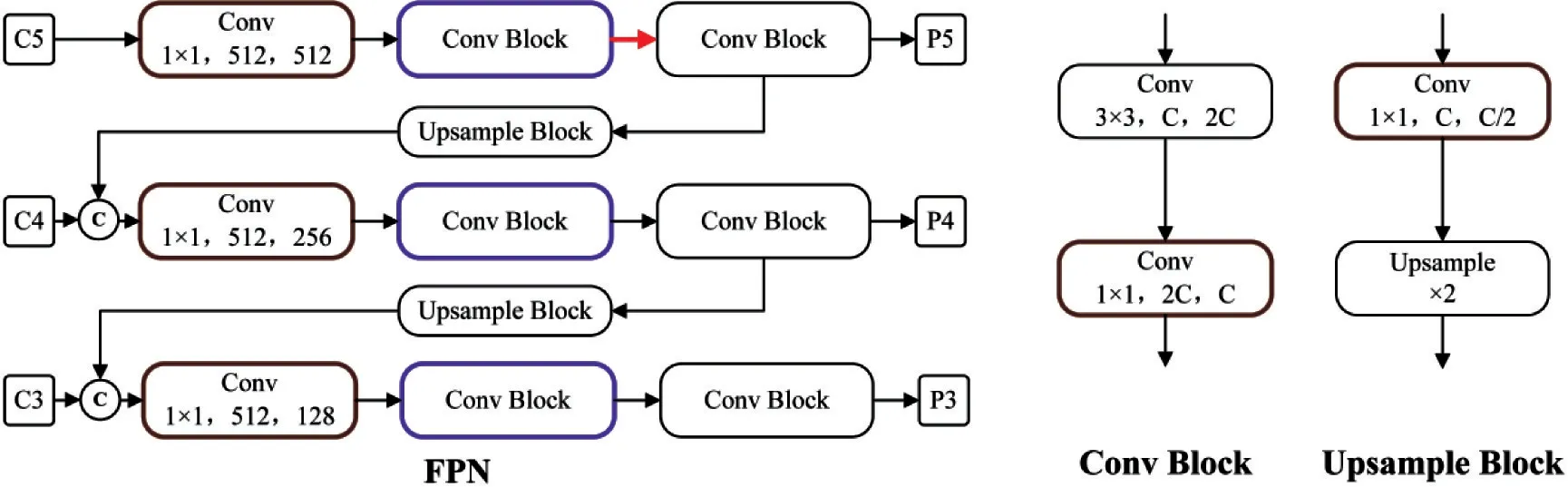
图1 特征金字塔具体结构
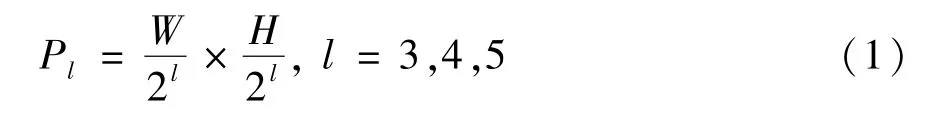
本文在检测颈部分的另一处改进是加入了由低层网络向高层网络传达的通路,如图2 所示。之所以做出这样的改进,是由于原PP-YOLO 网络的检测颈只能实现低层网络学习到高层网络的语义信息,但是高层网络却没有办法学习低层网络丰富的空间特征信息。因此,本文在改进的检测颈结构中,保留了原网络的基本框架,即每一层的处理过程不变,在第4 和第5 层加入了低层网络语义信息传达通路,该通路通过名为Downsample Block 的模块实现,DownsampleBlock 模块的具体信息在图3 中给出。经实验验证,改进后的检测颈设计在遥感图像目标识别过程中显示出了一定的优势,对提升检测精度很有帮助。
图2 检测颈优化策略框图
1.2 检测头
PP-YOLO 网络的检测头部分采用3×3 卷积层和1×1 卷积层进行最终预测,每个输出通道最终的输出是3×(K+5),其中K是预测目标实例总类别。每一张输入图片的最终预测结果都会与3 个锚框进行关联。每个锚框的输出结果都是由K个不同类别的预测概率加上4 个预测锚框的位置坐标以及为某个类别的分数预测组成。针对分类和定位,分别采用了cross entropy 损失和L1 损失函数。检测头的结构以及损失函数的搭配使用如图3 所示。
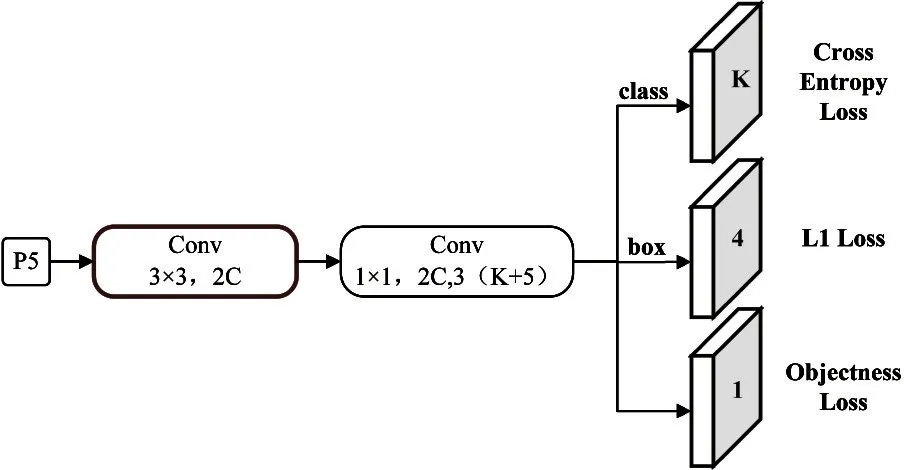
图3 检测头的结构以及损失函数的搭配
Cross entropy 损失函数定义如式(2)所示,计算输入和标签之间的交叉熵,可用于训练分类器。如果提供权重参数,它是一个1-D 的张量,每个值对应每个类别的权重,损失函数为式(2);如果不提供权重参数,该损失函数为式(3)。
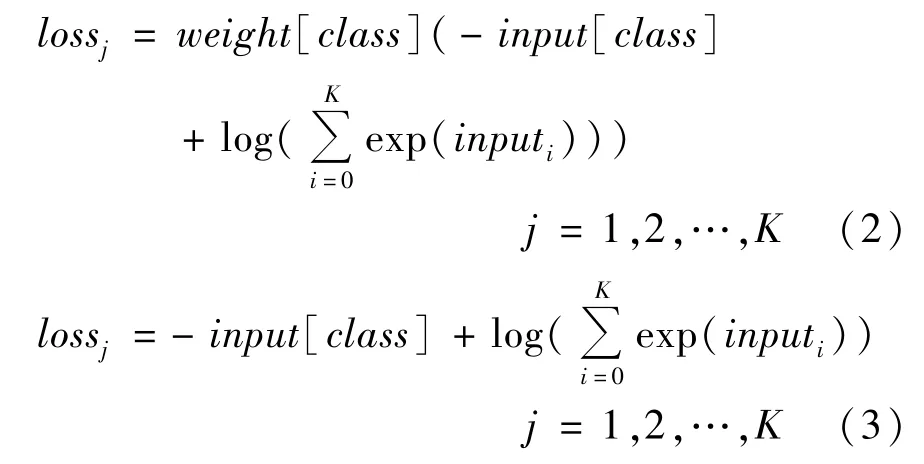
其中,weight为指定每个类别的权重,input为指定类别的输入。
L1 损失函数用于计算输入和标签之间的损失,根据指定应用于输出结果的计算方式L1 损失函数有绝对值、均值和求和3 种表达,本文中采用求和L1 损失,如式(4)所示。
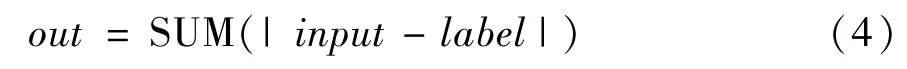
其中,input为指定类别的输入,label为与input在维度和类别上相同的标签。
1.3 数据增强优化策略的改进
数据增强的目的是扩充原训练数据集,产生与原图像相似但又不完全相同的样本,防止网络过拟合,以提升模型的泛化能力。PP-YOLO 首先使用Image Mixup(服从Beta(1.5,1.5)分布)训练,使训练的前250 轮每幅图像都是任意2 张图像混合,最后20 轮不做混合,这样做的优点是提高了网络对空间扰动的泛化能力。但Mixup 数据增强算法会存在图像混合不自然的情况,从而出现非信息像素,降低训练效率。因此,本文对数据增强策略进行改进,改进策略框图如图4 所示,以更优的CutMix 数据增强算法[17]替换掉原有的Mixup 数据增强算法。这种CutMix 数据增强算法采用裁剪区域然后以补丁的方式混合图像,不存在以上问题,同时训练和推理代价不变。
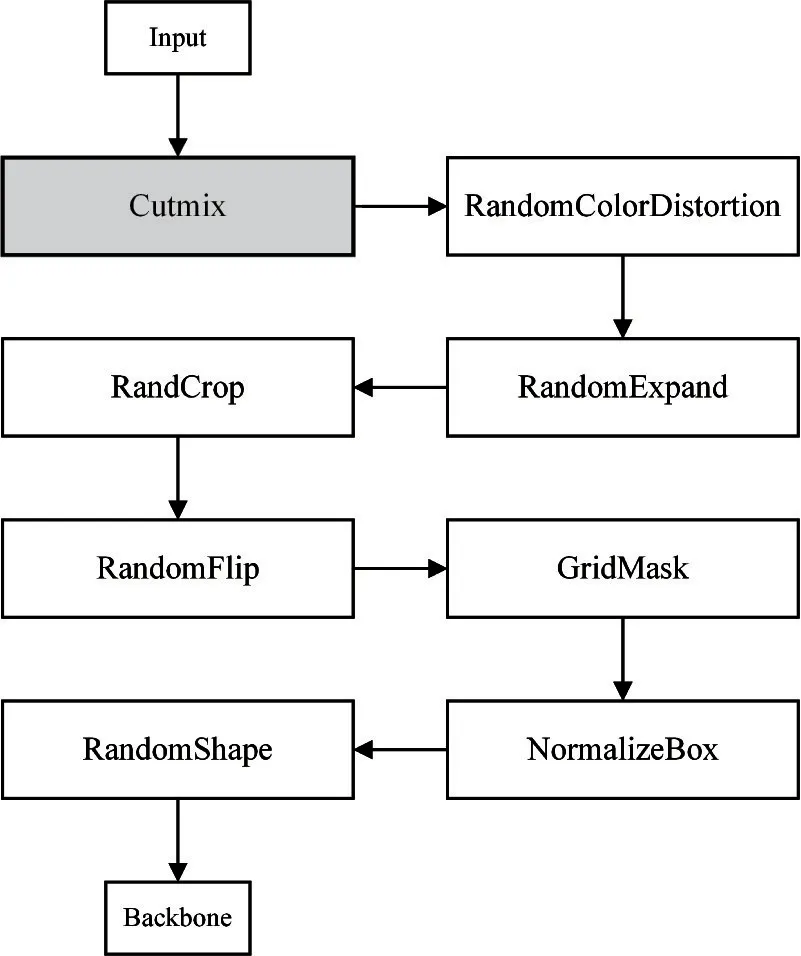
图4 改进的数据增强策略框图
1.4 训练策略的优化
本文实验数据集为公开的DIOR 和DOTA 遥感图像目标检测数据集,这类数据集目标总数分布不均匀(车辆的图片高达6000 张,而包含烟囱的图片却不到1000 张)、类别总数分布不均匀(船只总数高出了车辆总数的1/3,是火车站数量的60 倍)。在模型训练过程中,这会导致模型的差别学习或偏向性学习,使得相同识别难度下某些在数据集中分布更广泛的类别识别精度远高于相同识别难度的其他类别。同时,具有类间相似性的不同类别还存在相互抑制性,在分布差距较大的情况下,可能会导致对某一类目标的过度学习,抑制具有类间相似性的其他类别的学习。这都给目标检测算法带来了巨大的挑战。即使采取了适当的数据增强策略,距离满足网络训练的需求还有一定差距,因此,实验中对DOTA 数据集进行了分析,取该数据集与DIOR 数据集中相同且难以识别的类别,修改其数据标注文件为VOC 数据集标注格式,然后将该部分数据混合入DIOR 数据集的训练集中完成扩充。由于DIOR数据集中包含类别众多,类间相似性明显,训练过程中难免会出现部分类别训练不充分的问题。为了解决该问题,本文提出了训练策略的优化并编写了相应的程序来实现该功能。
具体过程是将公开的DIOR 和DOTA 遥感图像目标检测数据集经特定的筛选规则组成混合训练集,当模型训练达到某个瓶颈,总体平均mAP 值在取得最优值的10 个批次内不再提升时,停止训练并测试输出每一个类别的AP 值;将单一类别的AP 值与总体平均mAP 值进行对比;根据统计出的各单一类别的平均像素大小,取所有包含低于总体平均mAP 值且像素点在平均像素以下类别的图片;根据单一类别AP 值升序排列,分别在混合数据集中取原训练集大小的9.75%依次递减0.5%的数量(小数部分按四舍五入处理),然后再扩充2 倍写入新的训练集。这样做的目的是为了使网络能对那些难以识别的图片进行学习,并且尽可能地保证不会因为引入更多的某一类图片而导致具有类间相似性类别的识别精度降低。
2 实验结果与分析
具体实验中,选择开源DIOR 和DOTA 数据集,确定训练集图像5861 张,测试集图像11 738 张,共20 类目标。为了表述方便,分别用H1~H20 依次表示飞机、飞机场、棒球场、篮球场、桥、烟囱、大坝、高速公路服务区、高速公路收费站、高尔夫球场、地面田径场、港口、立交桥、船、体育场、储存罐、网球场、火车站、车辆和风车。实验的环境为GPU:Tesla V100,Video Mem:16 GB;CPU:2 Cores,RAM:16 GB;Disk:100 GB。实验过程主要步骤可概括为:首先设定训练模型路径和评估模型路径,模型分类数设定为20,依次设定模型的backbone、检测颈、检测头,损失函数、学习率设定为0.0003;然后训练数据增广和优化;最后设置预测模型参数。整个网络训练约30 h收敛。详细参数设置及具体实现过程已开源,开源网址为https://aistudio.baidu.com/aistudio/projectdetail/1480790。
实验采取平均精度均值(mAP)作为评判指标,mAP 是n个不同类别平均精度(average precision,AP)的平均值,其定义为

式中,AP 是对数据集中的一个类别的精度进行平均,其定义为
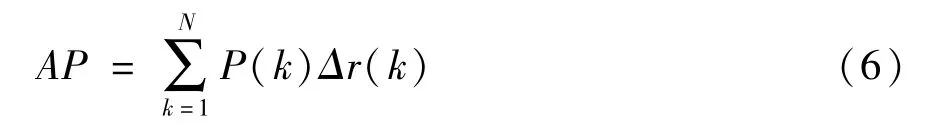
式中,P和Δr为查准率-查全率(precision-recall,P-R)曲线中的查准率和查全率[13,18]。
为了验证本文改进网络的有效性,并在实验过程中提供具有参考意义的对照组,本文提出的每一个改进点,均是在单独的实验环境中进行测试,以保证不引入非修改因素对实验结果造成影响。为了便于描述,本文将ResNet101-vd-dcn 骨干网络的整体网络架构实验称为方法1,将训练策略优化的方法在ResNet50-vd-dcn 以及ResNet101-vd-dcn 骨干网络的实验,分别称为方法2 和方法3。将优化的检测颈结构在ResNet50-vd-dcn 骨干网络的实验称为方法4。实验结果如图5 所示。
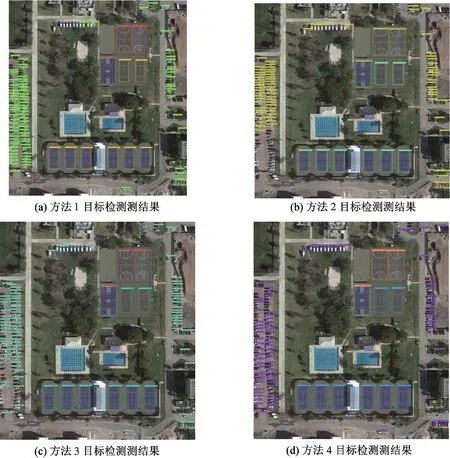
图5 各方法预测检测效果对比图
根据表1 和表2 的统计结果,可以看出使用优化训练策略后网络各类别预测AP 值均有显著的提升,充分训练后的网络其mAP 值高达89.3%。通过对比方法4 和方法1,可以看到优化后的检测颈结构对网络的精度提升是有效的,相比于使用更大骨干网络的方法1,方法4 仍取得了2.5%的mAP值提升。故整体考虑,该修改结构引入的参数增多是可以忽略的。即使造成了推理速度的降低,但精度的提升弥补了该缺陷。通过检测效果图5,可以看到优化的训练策略存在一些矛盾,由于DIOR 数据集中汽车等目标存在为数众多的特小目标,中等以上目标较少,而网络更多地对小目标以及特小目标的特征进行了学习,反而对中等以上的目标特征学习造成了影响。
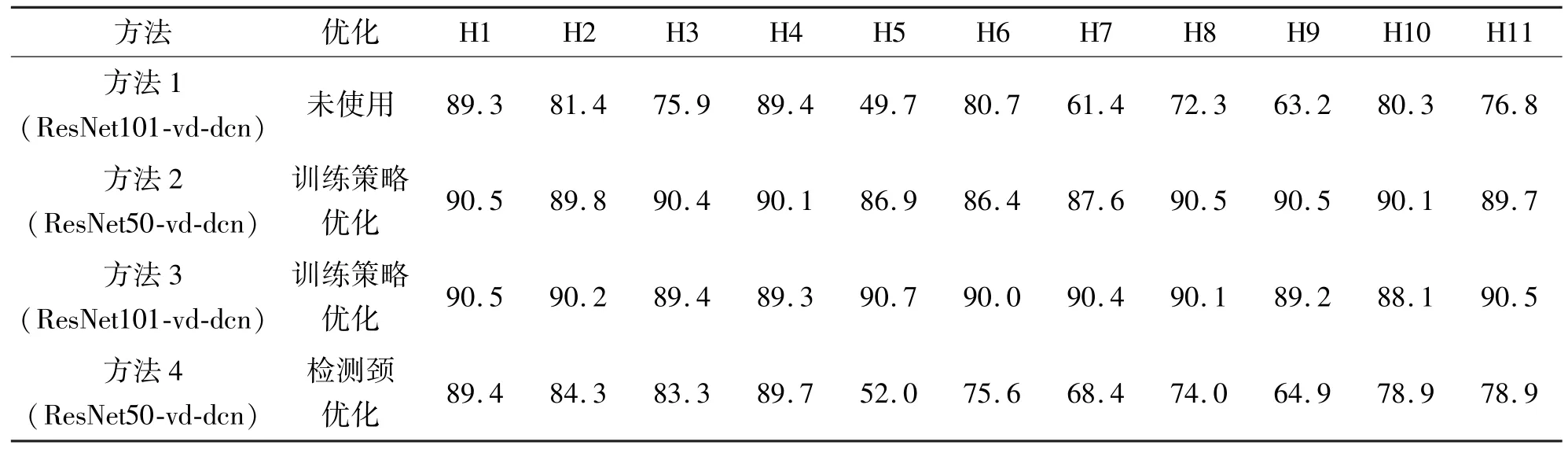
表1 不同方法在DIOR 数据集上取得的AP 对比表
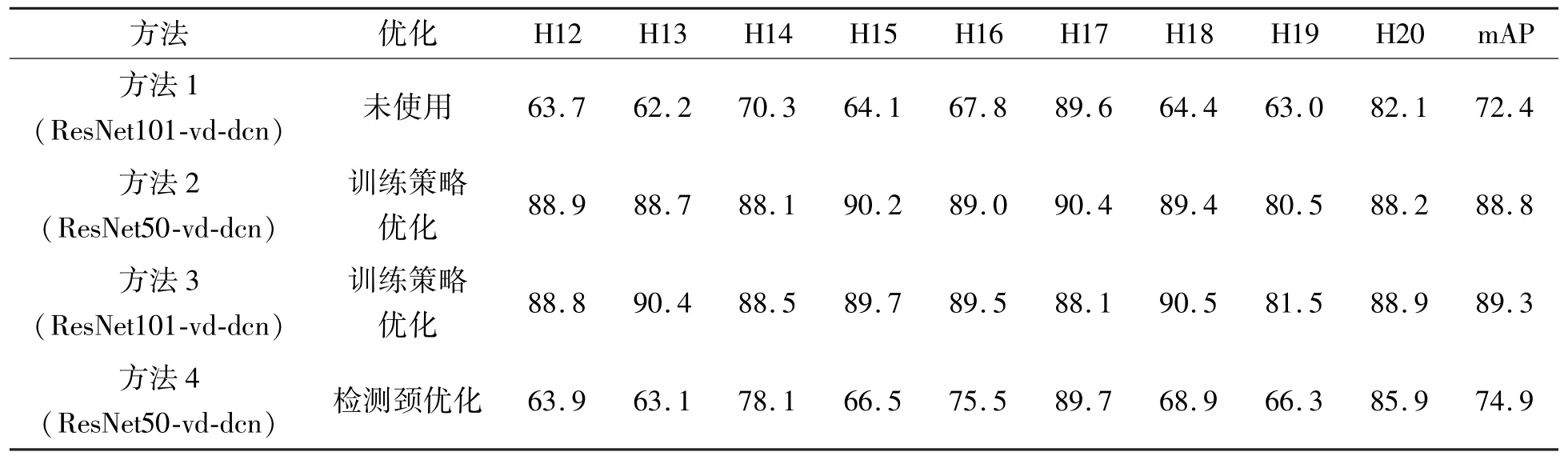
表2 不同方法在DIOR 数据集上取得的AP 对比表续
3 结论
本文提出一种改进的PP-YOLO 网络遥感图像目标检测方法,分别进行了训练策略的优化和检测颈的优化。优化训练方法基于遥感数据集特点,使用更优的CutMix 数据增强算法替换掉原有的Mixup数据增强算法,加入增强网络特征学习的GridMask算法,生成增广数据集对模型进行训练,充分且均衡地学习每一类目标的特征。训练优化策略均能有效地提高每一类目标实例的精度,解决了遥感图像目标实例尺寸变化大、类间相识性和类内相似性大,从而造成不同目标实例精度差距较大、部分目标精度不高的问题,最高取得了89.3%的mAP。
对PP-YOLO 网络的检测颈部分进行了改进优化,保留了原基本框架,在第4 和第5 层加入了由低层网络向高层网络传达的通路,不仅使网络低层部分可以学习到高层部分的特征信息,同时加强高层网络学习到的特征信息。检测颈优化方法提高了检测精度,保证了极佳的泛化能力,即使是在识别完全不同的数据集时,仍然可以取得优异的检测效果,其mAP 比未改进优化同骨干网络的PP-YOLO 网络提高了4.4%。
猜你喜欢
一重技术(2021年5期)2022-01-18
陶瓷学报(2021年4期)2021-10-14
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
少儿画王(3-6岁)(2020年4期)2020-09-13
作文小学中年级(2020年6期)2020-07-24
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
意林(2011年10期)2011-05-14
