
基于FPGA 的浮点可分离卷积神经网络加速方法①
2022-07-26 06:05张志超章隆兵肖俊华
高技术通讯 2022年5期
张志超 王 剑 章隆兵 肖俊华
(*计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
(**中国科学院计算技术研究所 北京 100190)
(***中国科学院大学 北京 100049)
(****中国电子科技集团公司第十五研究所 北京 100083)
0 引言
深度学习技术[1]不仅在图像处理应用中取得了较大的发展,在遥感影像目标图像识别中也取得了广泛的应用。目前,基于卷积神经网络的深度学习技术逐渐向轻量化模型[2]发展,使得轻量化模型能够在低处理能力的处理器上使用。在解决了轻量化模型的准确率问题后,还可以进一步采用硬件加速浮点卷积网络的方法进行加速。现有的卷积神经网络的加速研究包括参数量化方法[3-4]、轻量型网络结构设计、硬件卷积加速结构设计等方法。
轻量型网络结构设计方法主要采用分层卷积、分组卷积、点卷积和小卷积核等方式降低卷积的计算量,减少特征图跨通道提取特征的计算量。MobileNet[5]采用点卷积以及深度分离卷积结构降低模型的计算量。ShuffleNet[6]采用通道洗牌策略促进通道间特征融合,从而提升准确率。轻量型网络结合Yolo[7]检测算法也取得了高准确率与低处理时延[8-10]。轻量型网络结构设计从软件卷积结构层面降低模型复杂度,适合现场可编程门阵列(field programmable gate array,FPGA)定制硬件处理核直接加速浮点卷积模型获取加速能力。
硬件结构设计包括两种方法,一种是基于专用集成电路(application specific integrated circuit,ASIC)设计卷积计算单元和矩阵运算单元等方式获取加速能力[11-13]。另一种是基于FPGA 的加速浮点卷积计算方法,主要通过高层次综合(high-level synthesis,HLS)[14-15]或者开放运算语言(open computing language,OpenCL)[16-18]加速的方式,采用循环展开优化以及缓存设计方式提升处理能力。基于浮点的加速方式能够更好地去耦合软硬件协同开发。
本文针对星载飞机目标型号快速准确分类的需求,提出了一种基于FPGA 的浮点可分离卷积加速方法,达到了图像分类高准确率、高吞吐量、高效能计算的效果。本文的主要贡献如下。
(1)提出了一种基于FPGA 的浮点可分离卷积加速方法,结合轻量型卷积网络高准确率、低计算复杂度的特点,以及浮点可分离卷积网络加速技术,提供高吞吐量、高准确率的计算模式支撑。
(2)利用数据流调度技术以及浮点可分离卷积乘累加设计,解决了可分离卷积的浮点加速线速吞吐问题,同时也解耦合了软硬件协同开发。
(3)利用多核协同计算的方式,对多层卷积计算协同加速,避免过大的卷积核带来的超宽线宽问题造成的硬件时序收敛难题,进一步提升整个加速器的吞吐量。
1 卷积神经网络模型设计
针对遥感影像飞机目标型号分类任务快速低功耗处理的需求,需要在遥感影像机场区域中快速识别飞机目标的型号,对存在敏感的飞机目标型号的热点区域图像回传给数据中心后,进一步进行高精度目标处理分析。本文算法结合应用需求,一方面采用通用的轻量型网络MobileNet,从软件层面解决目标型号分类精度问题,同时降低卷积运算的复杂度;另一方面,从FPGA 加速浮点深度可分离卷积网络层面提升运算吞吐量。二者维持一个浮点卷积模型的编程接口,使得软硬件开发去耦合。
1.1 基于可分离卷积的飞机目标型号分类算法
基于深度可分离卷积(depthwise separable convolution,DSC) 的MobileNet 算法,通过点卷积(pointwise convolution,PC)和深度分离卷积(depthwise convolution,DC)提取特征图,大幅降低了卷积过程的运算量,且在通用数据集图像分类任务上达到了较高的准确率。基于MobileNet 卷积网络模型在ImageNet 数据集图像分类任务TOP-1 准确率达到了70.6%[5],在CPU 平台上的处理时间为113 ms[1],相对于其他模型准确率较高且模型计算复杂度适中,适合将该网络模型通过迁移学习的方式解决机场区域内飞机目标的型号分类。
1.2 可分离卷积网络结构及复杂度分析
(1)基于MobileNet 的可分离卷积网络结构描述
MobileNet 网络中的可分离卷积与二维卷积的使用方式对比如图1 所示,图1 表示一个常规二维卷积运算需要一个深度分离卷积加一个点卷积协同运算。

图1 二维卷积与可分离卷积使用方式对比
MobileNet 飞机目标型号分类卷积网络的输入为128×128 像素的3 通道卫星影像,输出为1000个目标型号的类别信息,共28 个卷积层,1 个平均池化层,1 个全连接层,能够最多分类1000 个目标。具体的MobileNet 每层的卷积或池化参数配置如表1所示。

表1 MobileNet 卷积神经网络结构
(2)模型复杂度分析
通过卷积参数量计算以及卷积计算乘累加数计算,其中池化层没有参数,乘累加数不统计,该模型的权重数量为4.24×106,总大小为16.96 MB,总乘累加操作数为0.186 GMAC。由此可见,该分类模型为一个深层轻量化的目标分类网络,适于在FPGA 上实现全浮点精度的深度可分离卷积网络运算加速。
2 可分离卷积神经网络加速设计
为了降低软硬件协同加速MobileNet的开发耦合度,采用浮点原始模型参数的方式进行加速,保持了与原模型一致性的输出与分类准确率;采用基于数据流调度的浮点深度可分离卷积加速设计方案,利用多层卷积网络流水线协同的方式并行加速计算,提升最终的运算吞吐量。
2.1 基于数据流调度的MobileNet 加速总体架构
针对基于卷积神经网络的目标区域筛选算法,设计基于数据流计算的卷积神经网络加速器。Xilinx UltraScale+系列新品的内部物理结构分布为3个超级逻辑区(super logic region,SLR),每个逻辑区覆盖芯片内部的一个Die,整颗芯片由3 颗Die 通过基底层互联。
考虑逻辑分区问题,将整个数据流计算分为3大块,第1 块超级逻辑区(SLR0)覆盖卷积网络的前13 层卷积层计算,即从cnv0 到cnv6_2 的计算;第2块超级逻辑区(SLR1)覆盖中间10 层卷积层计算,即从cnv7_1 到cnv11_2 的计算;第3 块超级逻辑区(SLR2)覆盖后5 层卷积层计算,包括全连接计算,全连接计算可抽象为1×1 的卷积计算,即从cnv12_1 到fc 的计算。
超级逻辑区之间通过Xilinx 堆叠硅片互联(stacked silicon interconnect,SSI)技术互联,在超级逻辑区边缘有特定的专用寄存器进行跨逻辑区通信,基底层有超长线(super long line,SLL)来连接专用传输寄存器。超级逻辑区的内部访存和跨逻辑区通信需求均通过SLL 互联实现。具体的基于数据流计算的可分离卷积神经网络加速总体架构如图2所示。
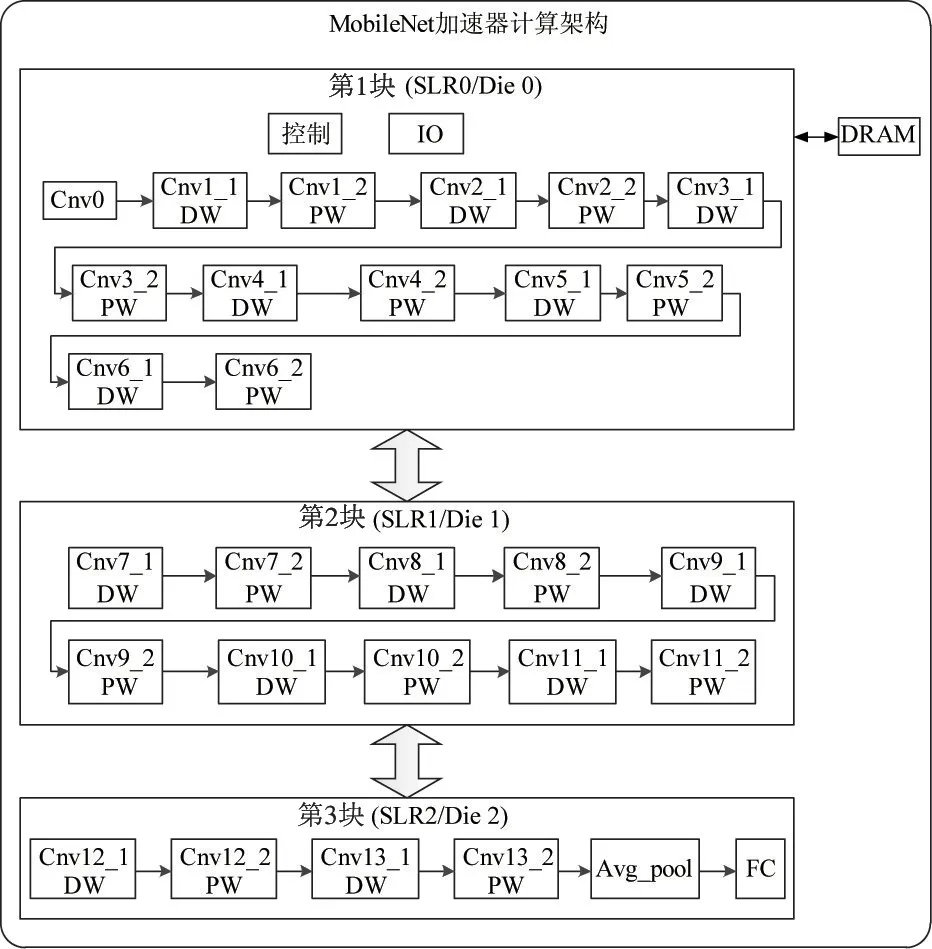
图2 基于数据流调度的MobileNet 加速总体架构
2.2 基于数据流调度的点卷积层设计
本节阐述基于数据流的点卷积层计算,主要包括卷积层权重输入、权重缓存、卷积输入数据流宽度变换、卷积计算阵列、批归一化处理、非线性响应等部分。具体的基于数据流的卷积层初始化与计算流程如图3 所示,其中权重初始化只在权重缓存初始化的时候运行一次,后续的卷积计算不再需要从动态随机存取存储器(dynamic random access memory,DRAM)中调度缓存数据,降低存储带宽的开销,避免卷积计算阵列需要等待权重数据。
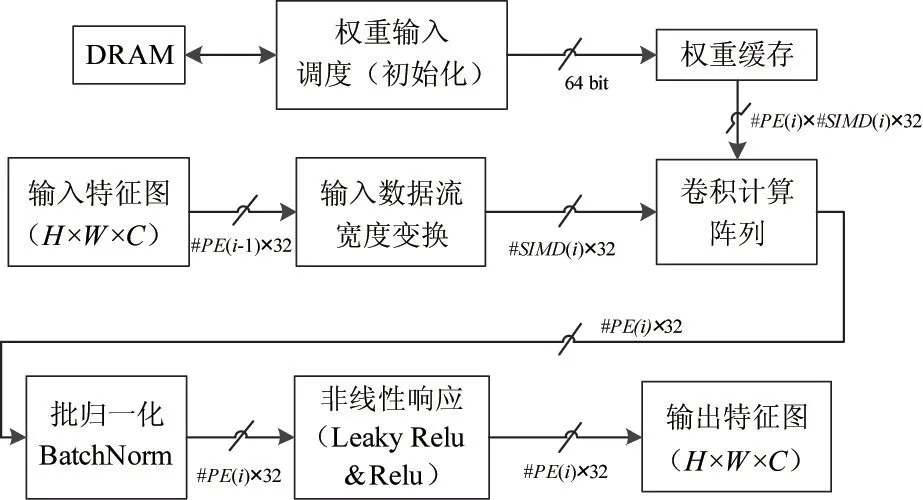
图3 点卷积层初始化与计算流程
与常规卷积层计算流程相比,点卷积不需要进行输入数据流调度,只需要将输入宽度为处理单元(process element,PE)个数的浮点数据流转换为输入宽度为单指令多数据(single instruction multiple data,SIMD)个数的浮点数据流,因为点卷积进行的卷积运算核为1 ×1,通常的特征图维持的H×W×C即可满足1×1 卷积的计算需求,不需要在特征图上跨行调度数据,因此简化了输入数据流调度为输入数据流宽度变换。卷积计算阵列依然采用基于前向累加链的卷积计算阵列设计,批归一化操作与非线性响应操作均无变化。
2.3 基于数据流调度的深度分离卷积层设计
本部分阐述基于数据流的深度分离卷积层计算,主要包括卷积层权重输入、深度分离卷积层权重缓存、深度分离卷积输入数据调度、深度分离卷积计算阵列、批归一化处理、非线性响应等部分。具体的基于数据流的深度分离卷积层初始化与计算流程如图4 所示,其中权重初始化只在权重缓存初始化的时候运行一次,后续的深度分离卷积计算不再需要从DRAM 中调度缓存数据,降低存储带宽的开销,避免深度分离卷积计算阵列需要等待权重数据。
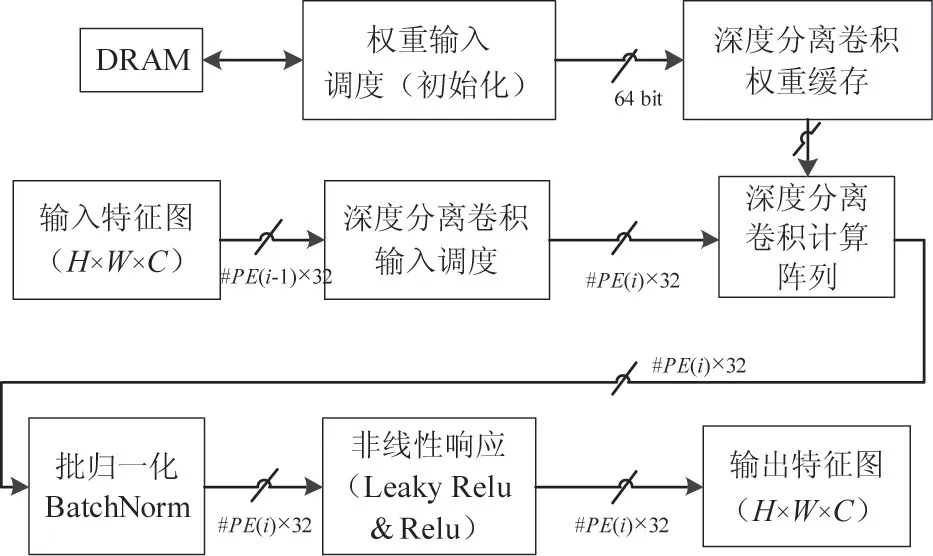
图4 深度分离卷积层初始化与计算流程
与常规卷积层计算流程相比,深度分离卷积的批归一化操作与非线性响应操作均无变化。
(1)深度分离卷积层数据流调度
基于数据流的深度分离卷积计算要求输入数据以及权重都能够达到线速吞吐,这样深度分离卷积计算单元的流水周期不会出现空转,计算效率达到最高。基于线速吞吐的数据流调度要求,设计多端口的权重缓存,能够提供PE组权重,每组权重有1个权重32 位浮点数;设计多端口深度分离卷积输入缓存,能够提供1 个32 位浮点数特征图输入;同时引入与深度分离卷积s行同等大小的输入先入先出队列(first input first output,FIFO),与深度分离卷积输入缓存构成异构“乒乓”缓存,去耦合上个阶段的计算输出调度和本阶段的深度分离卷积计算输入调度。输入特征图的输入宽度为上一层PE个数量的32 位浮点数,通过输入FIFO 转换宽度为1 个32 位浮点数据。卷积计算单元的输出为PE个32 位浮点数据计算输出。具体的卷积层数据流调度如图5所示,实现了一组数据计算多个深度分离卷积输出,利用了输入数据的局部性。
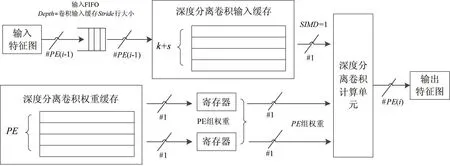
图5 深度分离卷积层数据流调度
(2)深度分离卷积层输入缓存设计
深度分离卷积层输入缓存的Stride行(Stride为深度分离卷积滑窗步进)大小与输入FIFO 的大小一致、结构不同,卷积层输入缓存将H×W×C的输入特征图转换为卷积核所需的k×k的输入,通过在多组寄存器滑窗,为深度分离卷积计算阵列提供计算深度分离卷积所需的线性输入。具体的深度分离卷积输入缓存设计如图6 所示。
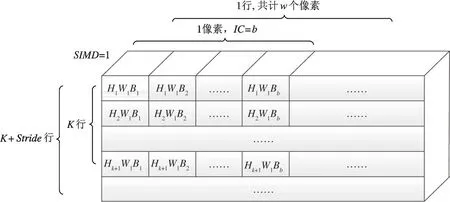
图6 卷积层输入缓存设计
深度分离卷积层输入缓存包括k×Stride行寄存器组,其中k为深度分离卷积核大小,Stride为深度分离卷积滑窗的步进大小。每行寄存器缓存输入特征图多个通道一行的数据,即W×C个数据,W为输入特征图的宽度,IC为输入特征图的通道数。每个寄存器行都可以按照SIMD=1 个浮点数的宽度输出数据,一个像素的多个通道数据按照SIMD的宽度分为b个Block,每个Block 按照顺序放在寄存器行里。由于深度分离卷积的空间访存特性,需要从多个寄存器行里顺序读取数据,按照卷积核行列计算的要求顺序输出SIMD宽度的输入特征图数据流。
多个寄存器组分开存放,可以将深度分离卷积输入特征图的输出调度和输入调度分开,除了初始化读入k行输入特征图像素,后续可以按照Stride行补充输入特征图数据。虽然访问的同一个深度分离卷积输入缓存,利用多行深度分离卷积输入缓存寄存器,由此可以将输入数据与输出数据调取去耦合,避免数据依赖和数据污染,实现无锁的数据输入输出同时调度,满足深度分离卷积计算单元SIMD个浮点数据的输出线速调度要求。
(3)深度分离卷积层权重缓存设计
针对在片上缓存该层深度分离卷积计算所需的全部卷积,并且权重缓存的输出能按照深度分离卷积计算阵列PE×1 的计算模式输出面向多个处理单元PE输出每组1 个浮点权重数据等要求,设计深度分离卷积层权重缓存。
深度分离卷积层参数按照式(1)维度顺序进行存放,其中PE为深度分离卷积计算单元的处理单元个数,每个深度分离卷积处理单元输入数据的宽度SIMD为1,每个数据均为32 位浮点数据。

深度分离卷积权重缓存T的计算如式(2)所示,其中OC为深度分离卷积核输出通道数量,k为深度分离卷积核大小。

深度分离卷积层权重缓存具有PE组独立的缓存行,每个行的输出宽度为1 个浮点数,由于卷积计算阵列的多个PE输出为输出特征图的一个像素的连续属性,故需要在权重缓存里将深度分离卷积权重按照多个PE行寄存器交叉存储,保证输出的PE组权重通过深度分离卷积计算阵列得到的是连续的输出特征图一个像素内部的连续属性值。具体的存放顺序如图7 所示。
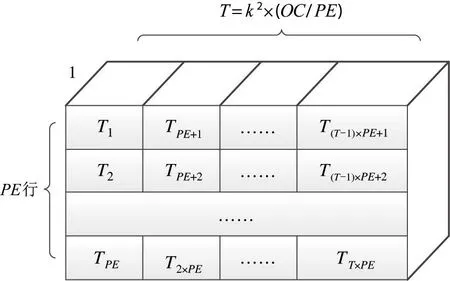
图7 深度分离卷积层权重缓存设计
(4)深度分离卷积阵列计算单元设计
针对深度分离卷积计算高吞吐量的计算需求,设计深度分离卷积计算阵列。每个时钟周期能够处理PE个乘累加计算,其中PE为深度分离卷积阵列的行数,深度分离卷积输入特征图数据的个数为1,输出为PE个深度分离卷积计算输出,PE个浮点数据属于同一个输出特征图像素的连续属性值。
考虑浮点累加器调度延迟问题,主要在与累加器输出要反馈到累加器输入上,这个延迟决定了累加器的吞吐速率,如果能够打破累加器的后向反馈,则可以使累加器性能达到线速,进而深度分离卷积计算阵列达到线速。
卷积的累加次数是固定的,且累加次数随着每个深度分离卷积层参数的变化而变化。基于数据流的卷积计算阵列支持面向不同的深度分离卷积层分别配置深度分离卷积计算参数,主要是深度分离卷积阵列大小,为此本文设计了一个基于前向累加链的深度分离卷积累加器,深度分离卷积计算单元的每个PE输出1 个数据,通过加法树1 和2 分别汇聚k个数累加。基于前向加法链的深度分离卷积累加器共需N个加法器,计算如式(3)所示。通过前向加速树的方式避免了卷积累加计算的负反馈过程,使得累加成为一个开环的设计,既完成了累加计算,又能够达到线速吞吐的目的。具体的基于前向加法树的深度分离卷积累加器设计如图8 所示。

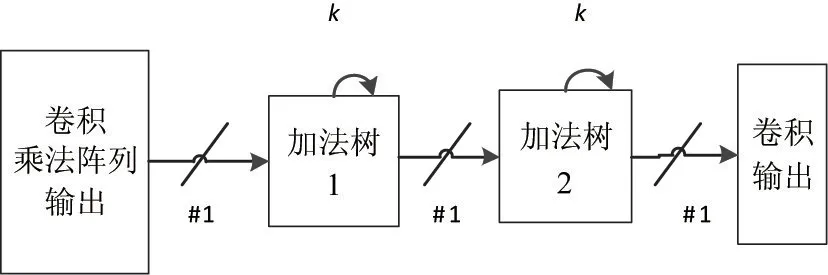
图8 基于前向加法树的深度分离卷积累加器设计
基于乘法矩阵与前向加法树的卷积计算阵列包含两部分,一是乘法矩阵,完成PE个数的乘法运算;二是加法树矩阵,将多个周期的k×k个数汇聚成一个数,完成同一个深度分离卷积计算的累加功能。基于前向加法树的卷积阵列设计,打破了浮点数累加的后向反馈,不依赖于加法器的具体延迟,通过延长流水线的方式达到了深度分离卷积计算的线速累加和输出。具体的基于乘法矩阵以及前向加法链的深度分离卷积计算阵列如图9 所示。
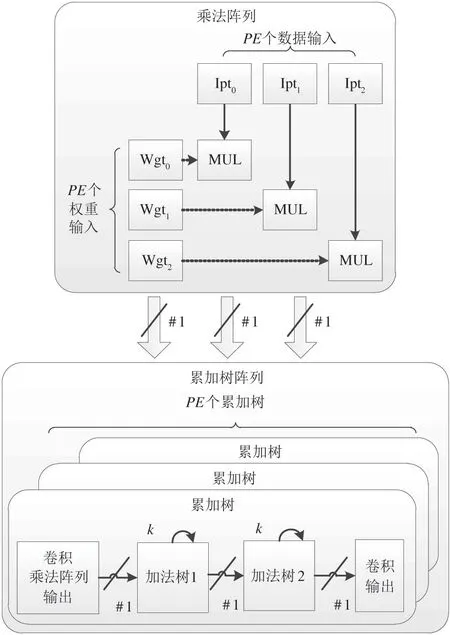
图9 基于乘法矩阵与前向加法树的深度分离卷积计算阵列
3 实验结果和分析
3.1 加速器性能设计与分析
基于流式的卷积网络加速器可以配置不同的PE、SIMD参数,设计分析模型,可以获得不同的加速器性能。本节通过分析模型计算硬件预估性能,结合HLS 高级综合资源占用分析,选取性能最高的MobileNet 加速器进行分阶段设计,以适应VU9P FPGA 芯片的分超级逻辑区放置资源。由于MobileNet 模型可以调节不同的模型神经元通道深度α值来配置不同通道数的模型网络,但是对于硬件设计单元来讲,可以针对不同的神经元通道深度α值来设计MobileNet 加速器,对应的模型计算复杂度以及加速器处理吞吐量则随之有增减。
(1)MobileNet 卷积网络加速器配置
针对MobileNet 模型α值为1,结合硬件加速器各层PE、SIMD配置进行设计。MobileNet_α_1卷积网络加速器配置如表2 所示,处理速度达到了725.64 FPS,硬件卷积处理资源性能达到了308.588 GFLOPS,相关吞吐量数据在214 MHz主频下得到。MobileNet_α_0.75 加速器和MobileNet_α_0.5 加速器的配置与MobileNet_α_1 加速器大致相同,不同的地方在于MobileNet_α_0.75 加速器cnv1_2 层的SIMD参数设置为12,MobileNet 各α值的硬件计算吞吐量大致相同,由于不同的模型神经元深度,吞吐量则按比例缩放。
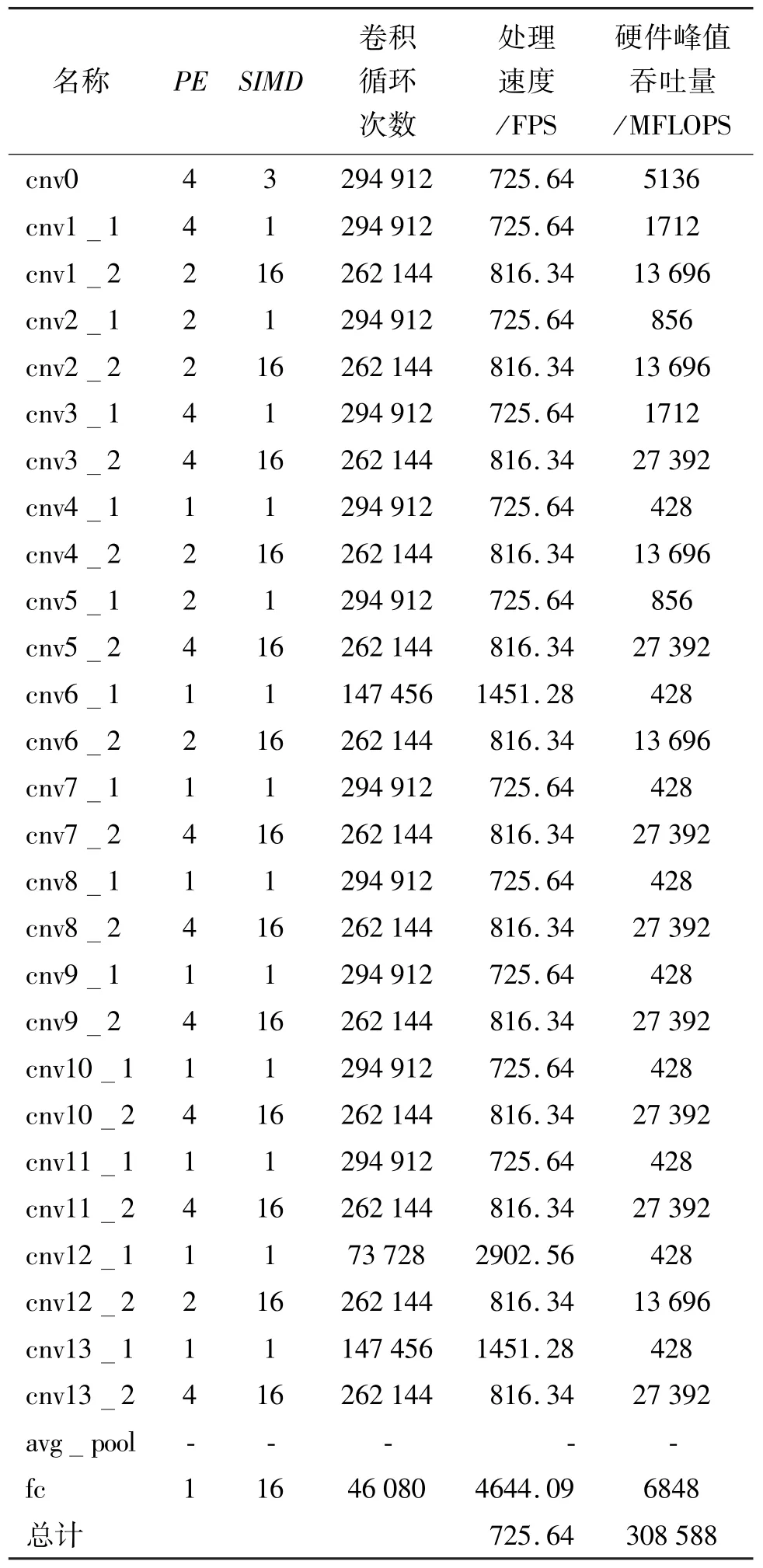
表2 MobileNet_α_1 卷积网络加速器配置
(2)基于分析模型的MobileNet 加速器性能分析
对不同神经元深度α 值的MobileNet 加速器分析模型进行对比分析,具体如表3 所示,相关吞吐量数据在214 MHz 主频下得到。MobileNet_α_0.5加速器处理速率最高,达到了1451.28 FPS,性能是MobileNet_α_1 的1 倍,各加速器的硬件计算吞吐量大致相同。
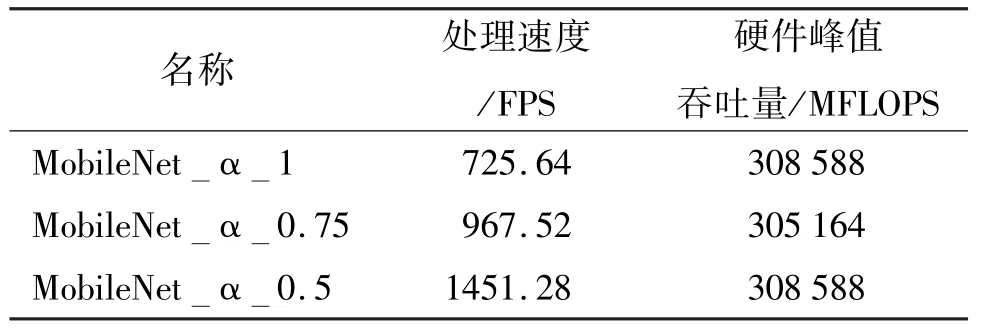
表3 基于分析模型的MobileNet 加速器性能对比分析
3.2 基于Vivado_HLS 高级综合工具的加速器资源占用分析
(1)MobileNet 卷积网络加速器资源占用分析
基于Vivado_HLS 高级综合工具的MobileNet卷积网络加速器资源占用分析如表4 所示,其中BRAM 为块随机存储器,DSP 为数字信号处理器,FF为触发器,LUT 为查找表,URAM 为超级随机存储器。从SLR 资源用量占比来看,不同α值的MobileNet 加速器所需资源占用超出单个SLR 的资源总量,该配置中URAM 资源占用率最高,达到了SLR 资源用量占比的184%,影像后续的综合实现过程,需要分割成多个阶段进行配置。从片上资源用量占比来看,各个α值的MobileNet 加速器所需各类资源大致相同,虽然各个加速器的PE、SIMD配置大致相同,但输入输出的调度、加法链的长度以及加法树大小不同,导致了资源占比略有不同,但都未超过片上资源总量的62%,表明基于分析模型的MobileNet 加速器参数设置合理,适合在片上进行综合仿真。
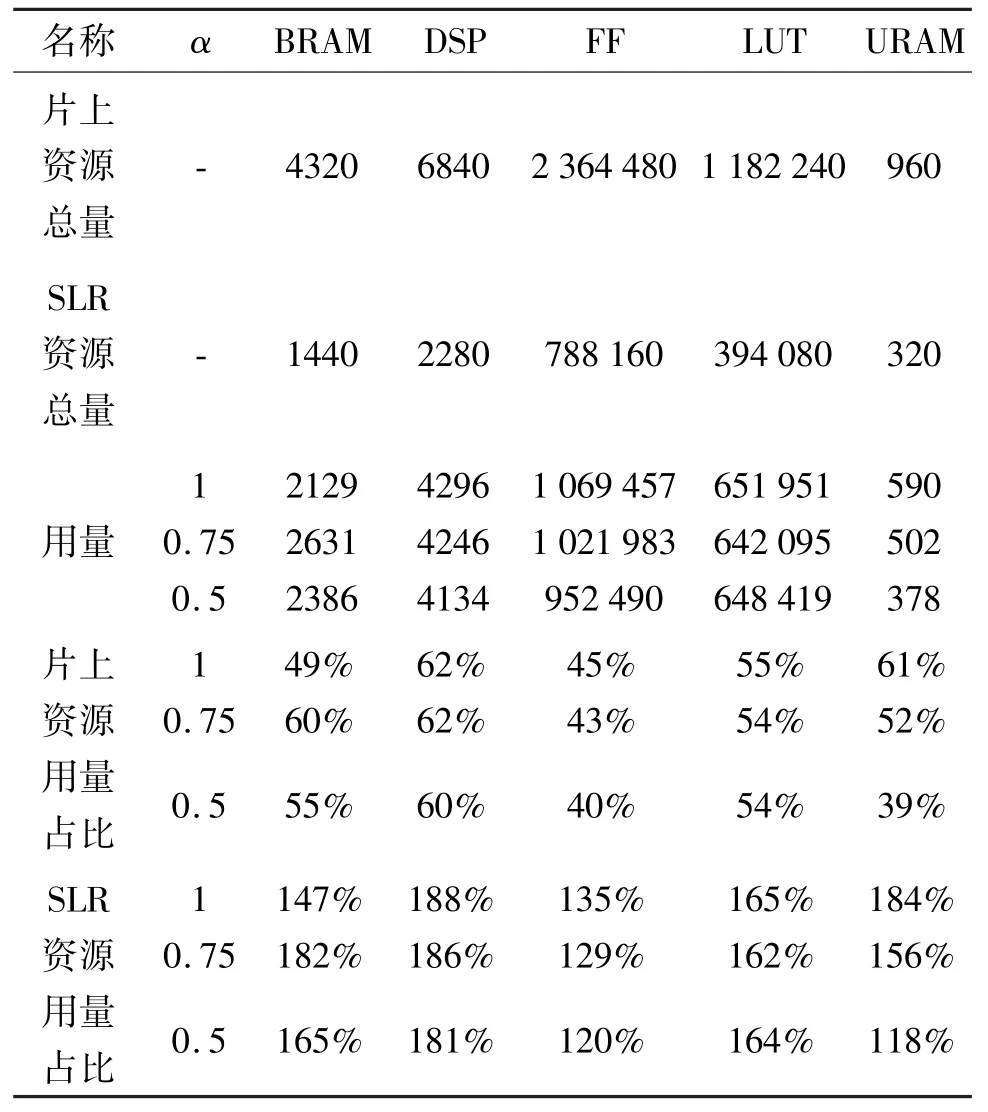
表4 MobileNet 卷积网络加速器资源占用
基于高级综合工具的MobileNet 卷积网络加速器资源占用对比分析如图10 所示。MobileNet_α_1加速器的资源占用最高的为DSP 资源,达到了片上可用资源占比的62%,使得加速器规模不能进一步扩大规模,同时也预留了资源给其他应用处理模块。各类资源的用量均已超出单个SLR 资源的总量,如不对MobileNet 各α值的加速器按照3 个SLR 进行切分设计加速器核,则不能满足Vivado 综合的时序收敛要求。
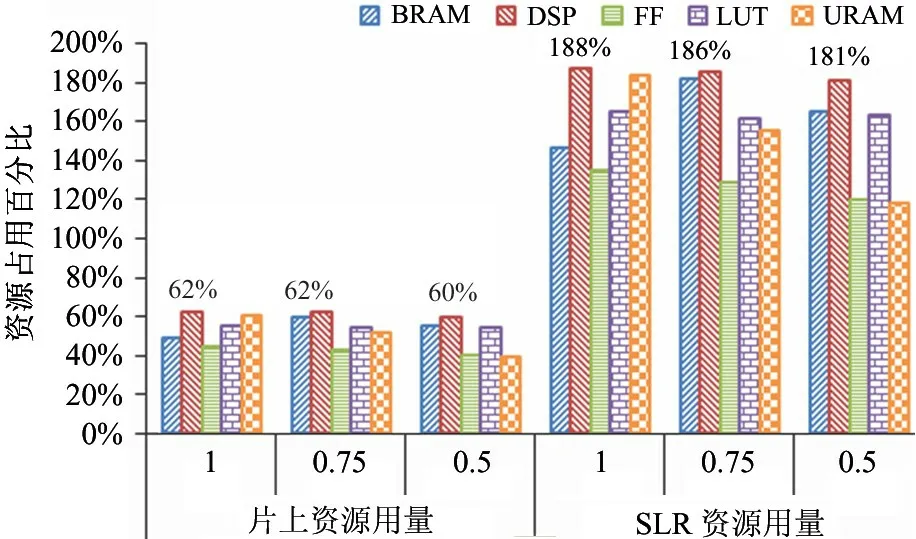
图10 MobileNet 卷积网络加速器资源占用对比
(2)分阶段设计加速器资源占用对比分析
由于VU9PFPGA芯片内含3个逻辑分区,整体的MobileNet 加速器占用的资源超过了一个逻辑分区,同时该设计需要一个较高的主频设计以期获得较高的吞吐能力,需要将MobileNet 加速器切割为3个加速器核,分别进行仿真设计。具体的MobileNet分阶段设计加速器资源占用对比如图11 所示,MobileNet_α_0.5 加速器各项资源占用均值在24%~71%之间,MobileNet_α_0.75 加速器各项资源占用均值在47%~82%之间,MobileNet_α_1 加速器各项资源占用均值在30%~100%之间,均能充分利用片上资源进行综合,同时又避免对布线资源过度使用造成拥塞,避免了高频时钟加速器设计的综合实现时序不收敛的问题。
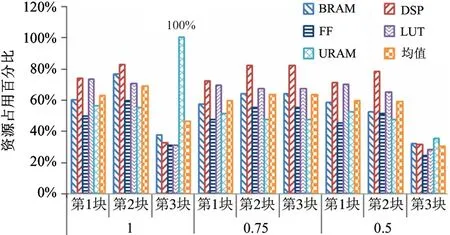
图11 分阶段设计加速器资源占用对比
3.3 基于Vivado 的加速器资源占用与功耗分析
可分离卷积网络加速器使用高级语言综合形成处理核以及Vivado 板卡仿真结合的方式获得最终可执行的比特流,Vivado_HLS 版本为2019.1,Vivado 版本为2019.1,基于Vivado 综合工具的MobileNet 可分离卷积网络加速器资源占用分析如图12所示。其中,LUTRAM 为基于查找表的随机存储器,IO 为输入输出,GT 为千兆位收发器,BUFG 为一般时钟缓存,MMCM 为混合模式时钟管理器,PLL为锁相环。通过分析,基于Vivado 的资源占用与基于HLS 的资源占用大致相当,不同α值的MobileNet加速器设计在IO、GT、BUFG、MMCM 以及PLL 资源占用情况一致,在LUT、LUTRAM、FF、BRAM、URAM以及DSP 资源占用情况略有差别,符合设计的要求。最大的资源占用率为URAM,约为70%,其他的资源占用均低于70%,使得加速器能够在有限的布线资源约束下时序收敛。
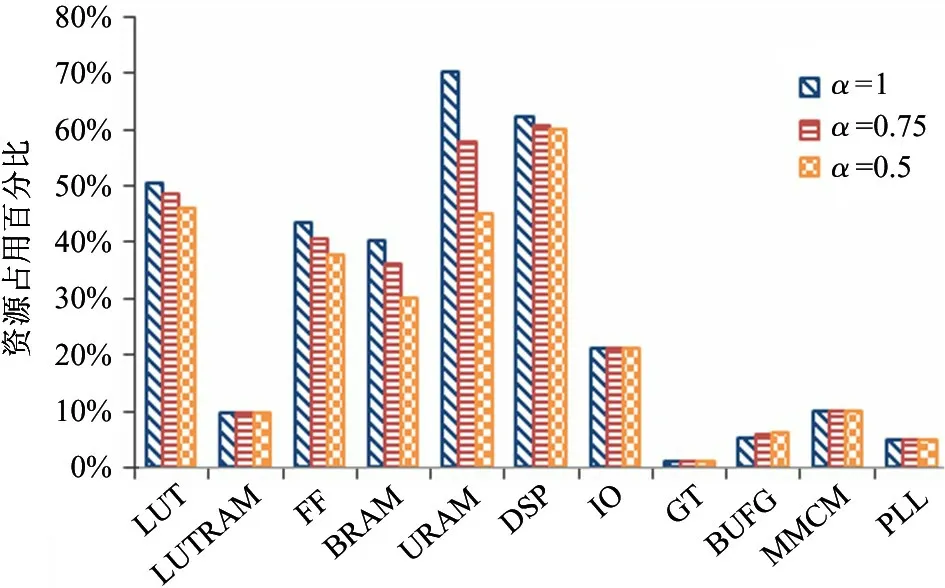
图12 加速器综合实现后资源占用对比
基于Vivado 仿真工具的MobileNet 卷积网络加速器功耗分析如表5 所示,MobileNet_α_1 加速器片上功耗为22.226 W,基于板卡测得处理速度为633.69 FPS;MobileNet_α_0.75 加速器片上功耗为23.144 W,基于板卡测得处理速度为855.12 FPS;MobileNet_α_0.5 加速器片上功耗为20.974 W,基于板卡测得处理速度为1283.90 FPS。不同α值的加速器功耗大致相当,由于设计的片上计算吞吐量大致相同,不同α值按比例缩减了模型的计算复杂度,其在板卡处理速度上按比例增加。
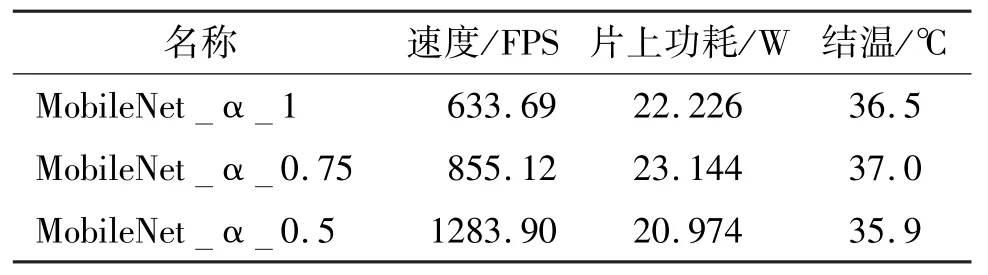
表5 基于Vivado 的MobileNet 卷积网络加速器功耗对比
3.4 模型准确率与性能测试
基于开源Google Earth 卫星遥感影像数据,本文采样了多时相的0.5 m 分辨率的全球多个机场影像数据,并标注了30 类具体的飞机型号分类数据作为模型训练数据。具体的飞机型号标注样本数据集如图13 所示,包括30 类常见飞机型号类型,共计7882 张图片,每个类别的数量从76 到820 张不等。本文将该部分数据集做成2 个训练数据集,并在MobileNet 分类模型上进行训练得出相应的模型准确率。从数据量的降序排列的前15 类别抽取数据,构成15 类飞机型号分类数据集,称为Plane15 数据集,共计6017 张数据,采用该数据集训练出的模型称为Plane15 模型;全部30 类别数据构成30 类飞机型号分类数据集,称为Plane30 数据集,采用该数据集训练出的模型称为Plane30 模型。
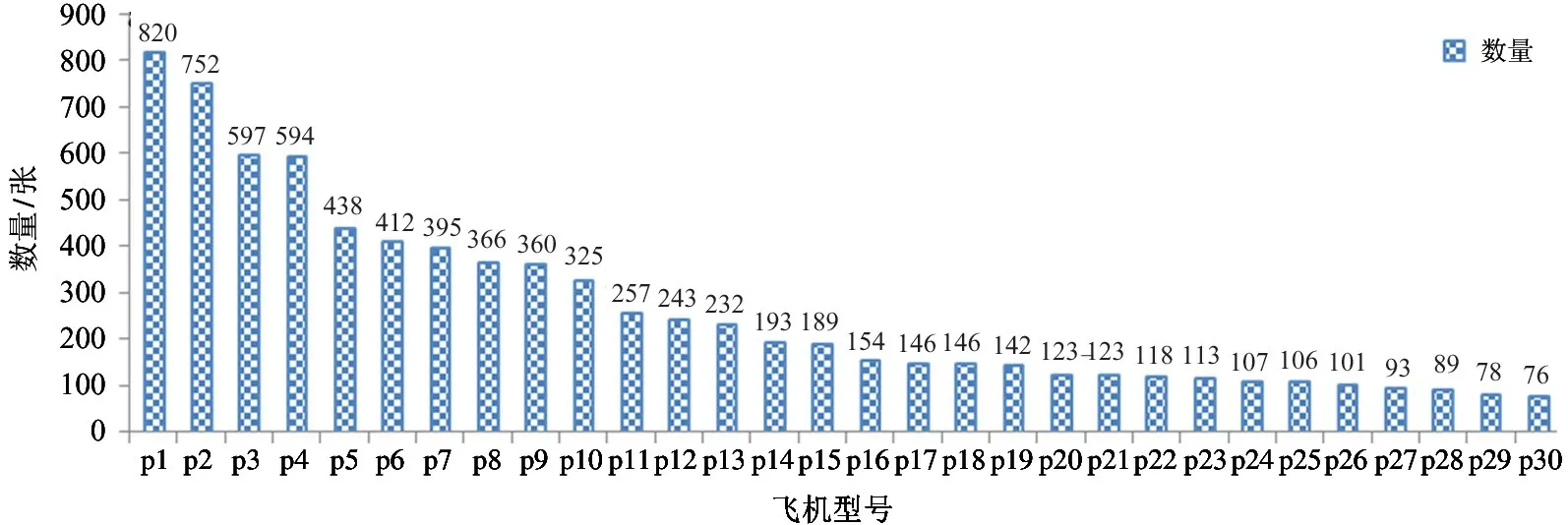
图13 飞机型号标注样本数据集
训练参数的设置包括批处理大小为16,最大迭代次数为200 000 次,优化器选择Adam 优化器,初始学习速率为0.0001。训练平台采用Titan Xp 进行训练,软件框架采用TensorFlow 1.5.0。训练时对数据进行4 倍扩充,包括旋转0 °和90 °,饱和度增强0 倍和1 倍,训练、验证、测试数据集比例按照8∶1∶1划分。
分别用Plane15 数据集和Plane30 数据集训练MobileNet 模型Plane15 模型,训练过程如图14 所示,经过30 000 次迭代后模型基本收敛,在70 000次迭代时的损失与准确率曲线基本稳定。在20 万次迭代中,选择各个数据集不同α值网络的最优模型进行准确率测试。Plane15_α_1 模型经过200 000批次迭代训练后验证准确率为98.9%,测试Top-1 准确率为98.9%;Plane15_α_0.75 模型经过200 000 批次迭代训练后验证准确率为98.2%,测试Top-1 准确率为97.8%;Plane15_α_0.5 模型经过200 000 批次迭代训练后验证准确率为98.3%,测试Top-1 准确率为98.5%;Plane30_α_1 模型经过200 000 批次迭代训练后验证准确率为96.9%,测试Top-1 准确率为97.2%;Plane30_α_0.75 模型经过200 000 批次迭代训练后验证准确率为97.2%,测试Top-1 准确率为97.3%;Plane30_α_0.5 模型经过200 000 批次迭代训练后验证准确率为96.3%,测试Top-1 准确率为96.1%。Plane30 相关数据集模型在验证集和测试集上的准确率比Plane15 数据集相关模型稍低一些,但也表现了相当高的准确率,这证明谷歌的MobileNet 模型在其他应用上也有很好的学习与泛化能力,具体的测试结果如表6 所示。
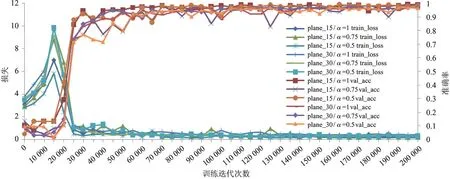
图14 MobileNet 模型训练过程
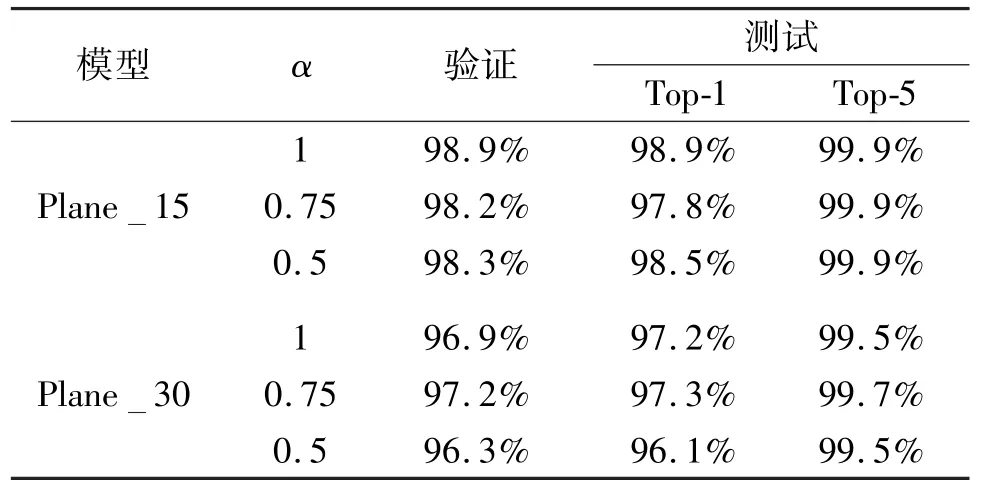
表6 模型准确率实验结果
经过Vivado 综合工具综合后,在VCU 1525 板卡对MobileNet 模型进行了吞吐量测试,并将其结果与GPU 模型进行性能对比,具体的模型性能对比如表7 所示。GPU 的速度测试从batch 为1、2、4、8、16中挑出最高的性能进行对比,batch 为8 时,MobileNet 模型的GPU 性能最高。Plane15 与Plane30模型都是基于MobileNet 的GPU 分类实例,测试吞吐量大致相当,功耗较高。基于FPGA 实现的MobileNet_α_0.5 模型达到了最高的吞吐量,为1283.90 FPS,是GPU 模型的2.61、2.27 倍,功耗远低于GPU 平台,计算效能是GPU 的18.66、16.24倍。MobileNet 加速器相对于GPU 的加速比为1.10~2.61 倍,能效比为7.44~18.66 倍,具体的加速比与能效比结果如图15 所示。
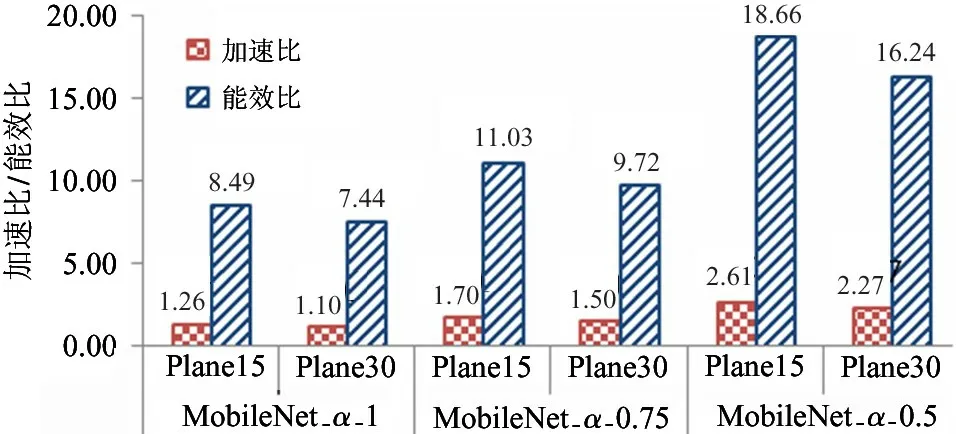
图15 MobileNet 加速器与GPU 加速比与能效比
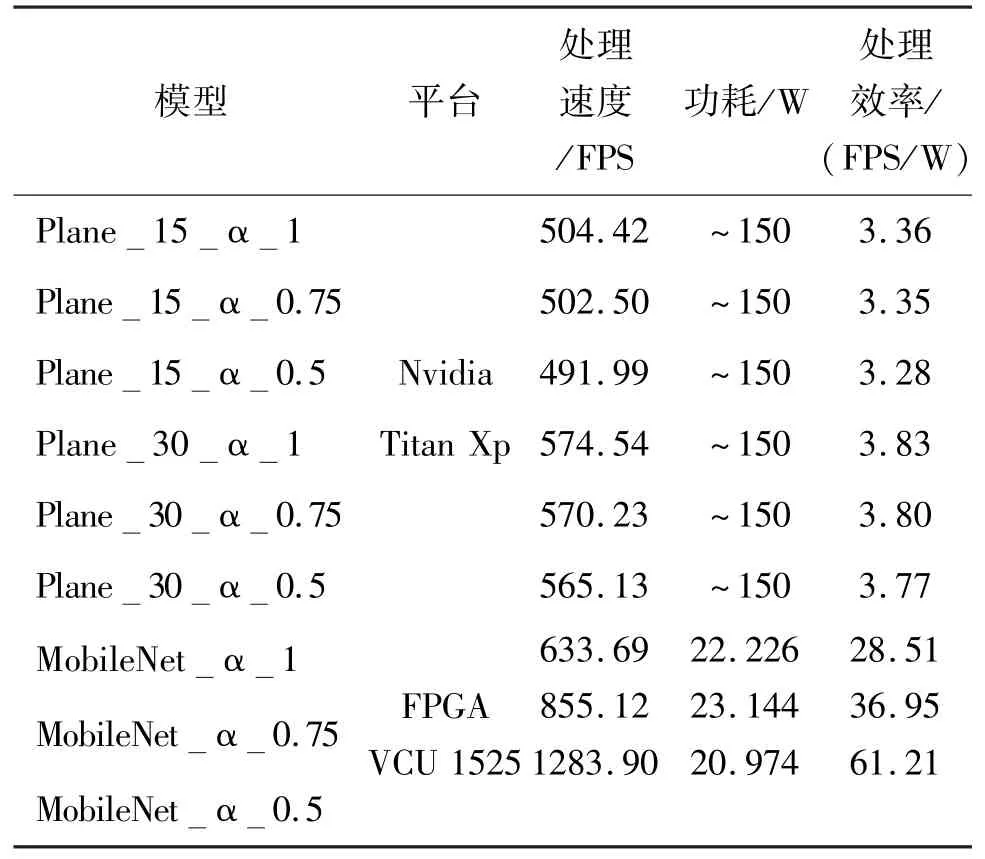
表7 加速器性能对比
3.5 与通用FPGA 加速卷积计算模型对比
将MobileNet_FPS 725 的性能与其他工作对比,如表8 所示,文献[16,18]的工作采用了基于硬核浮点DSP 的Intel Arria 10 器件,吞吐量较高,除了采用浮点硬核加速的相关工作,本文算法的运算吞吐量达到了最高值,为236.04 GFLOPS;运算效能也达到了最高值,为10.62 GFLOPS/W,GOPS/DSP 指标也取得了较好结果。实验结果表明,基于乘法矩阵与前向加法树的深度分离卷积计算阵列设计有效地解决了浮点可分离卷积计算的线速吞吐瓶颈,提高了DSP 资源的利用率,进一步提升了加速器的吞吐量与效率。
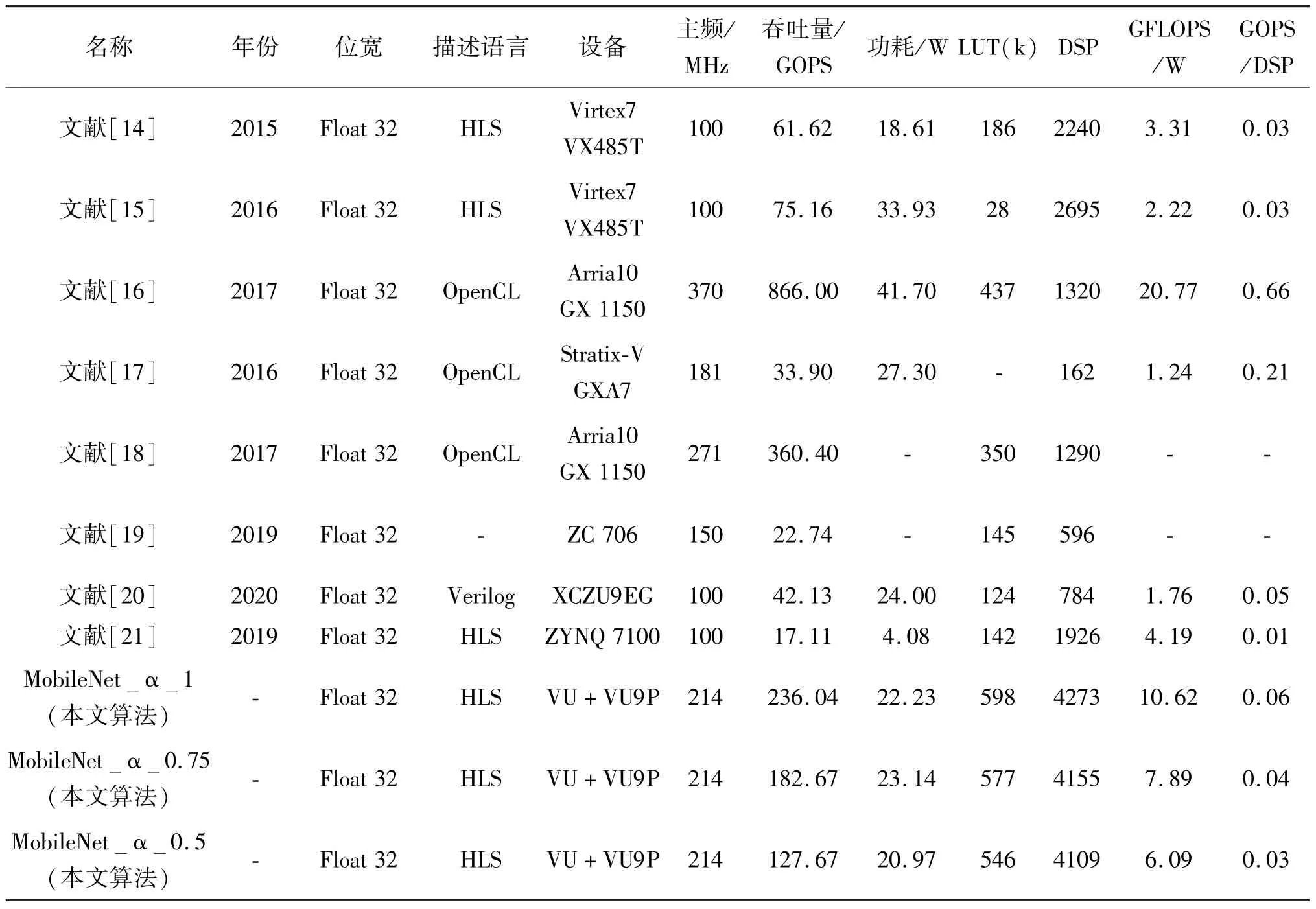
表8 与其他浮点加速卷积网络工作对比
4 结论
本文面向遥感影像飞机型号分类应用,采用轻量型网络MobileNet 构建型号分类模型,并通过基于FPGA 的数据流调度与浮点模型进行加速,突破了浮点加速可分离卷积的线速吞吐问题,达到了加速模型与原始模型准确率一致性的要求,使得软硬件协同开发去耦合,软件算法人员专注于训练模型以及模型认知不确定性研究。通过在Xilinx VCU1525开发板上构建浮点可分离卷积图像分类网络加速器,运算性能最高为236.04 GFLOPS,型号分类处理速度为633 FPS,功耗为22.226 W。实验结果表明,本文方法计算速度达到了Titan X GPU 的1.10~2.61倍,计算效能是Titan X GPU 的7.44~18.66倍。通过与同类的FPGA 加速浮点卷积网络方案对比,本文方法计算吞吐量以及计算能效比达到了最优。后续可就基于轻量型网络的多尺度目标检测加速进一步开展研究。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
导航定位学报(2022年2期)2022-04-11
数据与计算发展前沿(2021年5期)2021-11-30
少先队活动(2021年6期)2021-07-22
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
汽车实用技术(2019年4期)2019-10-21
计算机技术与发展(2018年1期)2018-01-23
雷达科学与技术(2015年3期)2015-01-22
