
GPU-Hi:GPU RTL 平台实现及效率分析①
2022-07-26 06:05张立志赵士彭章隆兵
高技术通讯 2022年5期
张立志 赵士彭 章隆兵
(*计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
(**中国科学院计算技术研究所 北京 100190)
(***中国科学院大学 北京 100049)
0 引言
随着个人电脑与智能手机的普及[1],人们对细腻逼真的3D 图形绘制需求愈发强烈。图形处理器(graphics processing unit,GPU)作为处理3D 图形任务的专用芯片,其研究与发展对提升图形应用绘制效果有重要意义。
现有的典型GPU 架构有Fermi 架构[2]与graphics cone next (GCN)架构[3]。Fermi 架构是Nvidia公司于2008 年提出,该架构将顶点着色处理模块与像素着色处理模块合并为基于流处理器的统一渲染模块,统一渲染架构的流处理器与专用集成电路(application-specific integrated circuit,ASIC)实现的固定图形算法[4-7]处理电路共同实现整个图形处理流水线。GCN 架构由超威半导体公司于2012 年提出,该架构将原本使用的VLIW+SIMD 改进为SIMT架构。但因为商业原因,Nvidia 与AMD 公司并没有披露这两款架构的设计细节,导致研究者无法直接使用这些架构进行GPU 研究。
学术界对GPU 的研究主要集中在通用计算领域,例如gpgpu-sim[8]、gem5-gpu[9-10]、multi2sim[11]、MIAOW[12]、Accel-Sim[13],通用计算只涉及到GPU的流处理器模块,并不涉及ASIC 模块,这些研究对GPU 硬件与应用行为的分析更多地集中在流处理器与cache 模块,并没有对图形应用基础的图形算法模块进行研究分析。
学术界完整实现GPU 流处理器模块与ASIC 固定图形算法模块的典型GPU 架构有ATTILA[14]与Emerald[15]。ATTILA 是2006 年提出的一款GPU 架构,该架构使用高级语言模拟器实现了完整的周期精确模拟,但其很多设计已经不符合现代GPU 架构。Emerald 由英属哥伦比亚大学于2019 年提出,在gpgpu-sim 模拟器中增加了图形算法模块的实现。但Emerald 并没有对图形算法模块实现周期精确的模拟。ATTILA 与Emerald 的另一个不足是缺少RTL 实现,导致其分析结果不够准确。
统观学术界和工业界现有的GPU 平台,有的封锁实现方法,有的使用古老的GPU 架构,有的只使用高级语言模拟。GPU 研究领域缺少一款开放实现方法、使用现代GPU 架构并且进行寄存器传输级(register-transfer level,RTL)实现的GPU 研究平台。
本文主要贡献为实现了一个包含完整图形功能的RTL 级的GPU 研究平台GPU-Hi,解决了上述问题。并使用28 nm 工艺完成物理设计,该平台支持OpenGL 2.0 框架,使用ASIC 电路实现固定图形算法模块,使用SIMT 流处理器实现统一着色渲染模块。在实验模块本文基于该平台对glmark2[16]测试集进行了应用行为分析并对GPU 进行硬件效率分析。结果证明,图形应用程序在进行分辨率提升时,图形任务负载不会等比例增加;硬件光栅化模块的真实性能受到着色程序执行效率与访存效率的影响,单一提升GPU 部分模块硬件配置,GPU 整体性能并不会明显提升。这些结论对图形应用开发人员与GPU 结构设计人员有借鉴意义。
本文包含以下几个部分。第1 节介绍了3D 图形应用背景与GPU 架构背景;第2 节描述了GPUHi 的RTL 实现方法;第3 节分析了图形应用计算特性;第4 节展示了GPU-Hi 的RTL 实现的参数,并使用glmark2 测试集进行图形应用行为分析与GPU 硬件效率分析;第5 节提出未来研究工作并对本文进行总结。
1 背景介绍
1.1 3D 图形应用背景
目前主流3D 图形应用程序主要使用Open-GL[17]与DirectX[18-19]2 个图形库进行实现。OpenGL图形库是一个面向2D 与3D 计算机图形学的跨平台语言的应用程序库,1991 年由SGI 公司提出,后来由Khronos 组织进行版本更新与维护。DirectX 图形库由微软公司提出,实现内容与OpenGL 图形库类似。
这2 个图形库都为3D 图形程序定义了一条图形处理流水线,这2 条流水线处理流程基本相同。图形处理流水线将处理流程分为顶点着色阶段、光栅化阶段、像素着色阶段、后片段处理阶段。顶点着色阶段以顶点数据为处理对象,对每一个顶点数据使用顶点着色程序进行顶点的位置计算与属性计算。光栅化阶段将经过计算的顶点数据组织成以三角形为代表的基本图元,并以这些基本图元为处理对象,将图元转换生成屏幕像素点。像素着色阶段以像素点为基本处理单元,对每一个像素点使用像素着色程序进行像素点的颜色计算。OpenGL 图形库使用高级着色器语言(high-level shading language,HLSL)[20]实现顶点着色器程序与像素点着色器程序,DirectX 图形库则使用GLSL 语言[21]进行实现。后片段处理阶段将经过着色的像素点数据进行深度剔除或透明混合操作,处理过后的像素点最终组成在屏幕中显示的图像。
1.2 GPU 架构背景
GPU 是针对3D 图形应用程序而设计的应用加速芯片。依据OpenGL 与DirectX 图形库所定义的图形处理流水线,同时为增强自身处理能力,GPU将自身架构设计为统一渲染架构。因为顶点着色阶段与片段着色阶段都使用着色程序进行计算,所以统一渲染架构使用同一块流处理器实现这两阶段的处理。基于这两个阶段所具有的并行特性,流处理器使用单指令多线程(single instruction multiple threads,SIMT)架构。根据光栅化单元与后片段处理阶段的流式数据处理特性,使用ASIC 电路对其进行实现。
2 GPU-Hi 的RTL 实现方法
2.1 GPU-Hi 简介
GPU-Hi 使用本文作者所设计的一款GPU 架构进行RTL 实现,该GPU 架构已经通过高级语言模拟器[22-23]完成了正确性验证。GPU-Hi 支持Open-GL 2.0 渲染框架,流处理器实现为统一渲染架构,各个处理单元支持灵活扩展。本文介绍了GPU-Hi的RTL 实现方法,并使用GPU-Hi 进行图形应用行为分析与GPU 硬件性能分析。
GPU-Hi 包括5 个部分,即命令处理器(command processor,CP)、全局任务调度器(global task scheduler,GTS)、图形处理集群(graphics processing cluster,GPC)、二级缓存(level 2 cache,L2 Cache)和内存控制器(memory controller,MC)。其中图形处理集群包括6 个模块,即计算处理引擎(compute engine,CE)、几何处理引擎(geometry engine,GE)、图元处理引擎(primitive engine,PE)、局部任务调度器(local task scheduler,LTS)、流处理器集群(stream processor cluster,SPC) 和输出合并单元(output merge unit,OMU)。
GPU-Hi 结构如图1 所示。
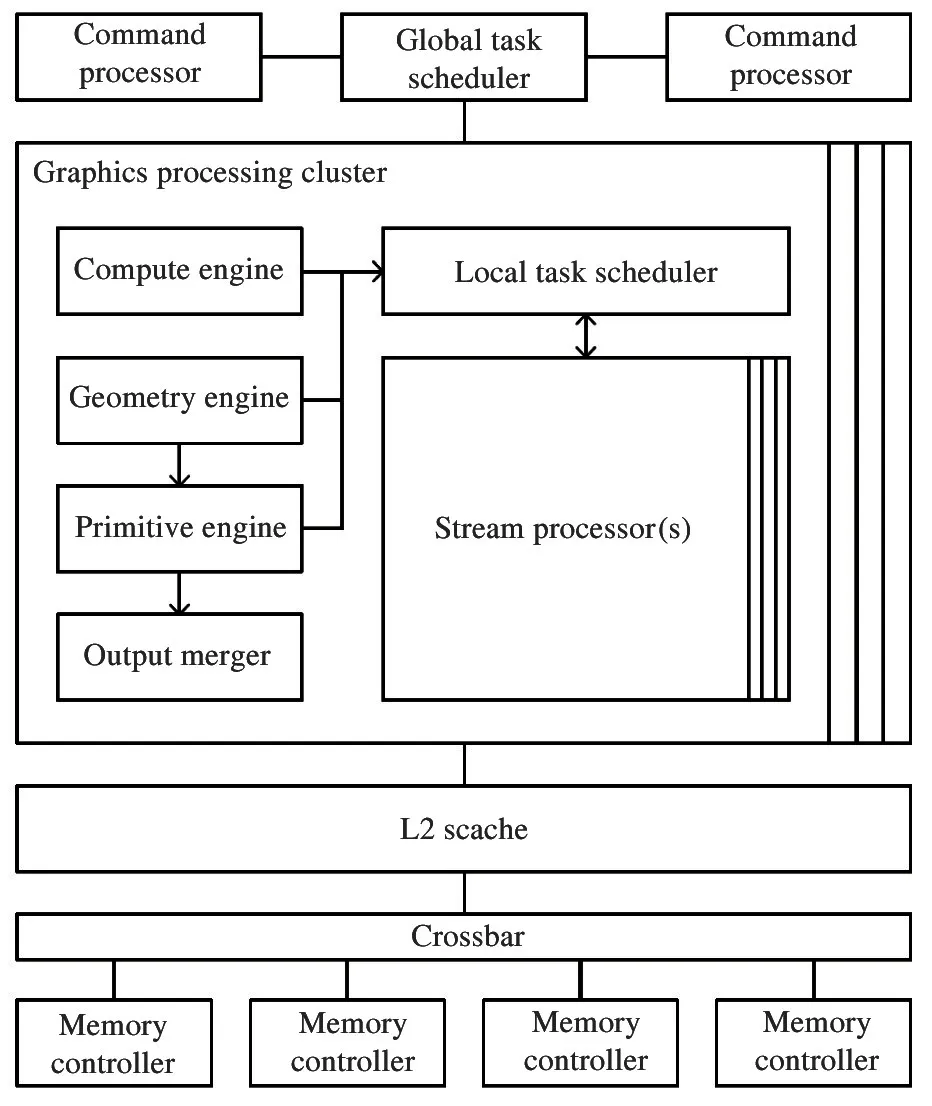
图1 GPU-Hi 架构图
本节后续部分介绍各模块的具体实现方法。
2.2 命令处理器
命令处理器是GPU 的整体控制模块,本平台通过在命令处理器模块嵌入一个GS132 处理器核进行实现。该处理器核解析来自主机中央处理器(central processing unit,CPU)的图形绘制命令与绘制任务参数,针对不同的绘制命令与任务参数配置全局任务调度器和图形处理集群。在GPU 流水线完成任务的绘制后,命令处理器把绘制结束信息通知给显示输出模块,最终由显示输出模块将结果数据输出在显示器屏幕上。
2.3 全局任务调度器
全局任务调度器从命令处理器接受绘制命令,并根据调度算法将绘制命令分配到对应的图形处理集群中。
2.4 图形处理集群
图形处理集群是GPU-Hi 的核心处理模块。包括几何处理引擎、图元处理引擎、流处理器集群、局部任务调度器、输出合并单元。
几何处理引擎主要包括顶点索引数据拆分模块与顶点着色任务重定序队列。顶点索引拆分模块使用硬件电路实现,解析命令处理发送来的命令参数,获得顶点数据索引,将顶点数据索引组织为顶点着色任务,并将着色任务发送至局部任务调度器。着色任务包括着色程序的指令地址、数据地址、寄存器信息。顶点着色任务重定序队列由随机存取存储器(random access memory,RAM)实现,保存着色器任务的结果数据,并按照着色器任务生成顺序将结果数据发送到图元处理引擎。
图元处理引擎主要包括固定的光栅化算法模块、像素着色任务生成模块和像素着色任务重定序模块。固定光栅化算法模块实现了3D 图形光栅化算法。区别于通用CPU 对数值处理的定点、单精度、双精度数值格式,该模块使用大量定制的运算单元提高运算效率与数值精度。这些定制的运算单元包括单精度数据处理、可变精度数据处理、定点数据处理、多数据融合运算处理等。像素着色器任务生成模块将固定光栅化算法模块生成的像素数据组织为像素着色任务,并为像素着色任务提供指令地址与预赋值的寄存器数据。像素着色任务重定序队列由RAM 实现,保存顶点着色任务的结果数据,并且按照像素着色任务生成顺序将像素着色任务结果数据发送给输出合并单元。
流处理器集群由多个流处理器模块构成。流处理器模块使用顺序流水线的单指令多线程(SIMT)架构,每周期可以发射一条指令,这条指令可以同时驱动多个线程进行数据的读写与运算。流处理器模块包括融合乘加运算单元、超越函数单元、纹理单元、便笺式存储单元、L1 Cache 单元和寄存器单元。融合乘加单元可以执行融合乘加运算;超越函数单元可以执行正弦、倒数、指数、开平方等运算;纹理单元通过纹理指令来获取纹理数据的地址,并通过L1 Cache 读取纹理数据,并且对读取得到的纹理数据进行滤波操作;便笺式存储单元可以通过独立寻址的方式为各个运算单元提供数据,减小片外访存压力;L1 Cache 为模块内各运算单元提供数据。寄存器单元是各运算模块最基础的数据存储单元,流处理器设计为所有运算单元无法直接从内存进行数据读写,读取数据时必须先将数据从内存load 进寄存器,写入数据时必须先将数据写入寄存器。流处理器分别从几何处理引擎与图元处理引擎接收顶点着色任务与像素着色任务,并将处理结果分别返回给几何处理引擎与图元处理引擎。
局部任务调度器用于保存流处理器模块的资源分配与占用情况,并根据资源占用情况将接收到的顶点着色任务与像素着色任务分配调度至流处理器模块。
输出合并模块主要包括深度测试与透明混合模块。这两个模块使用定制的乘加运算单元实现,将从图元处理引擎接收的像素点数据直接进行计算处理,并输出至片外帧缓冲区,供显示输出模块使用。
2.5 二级缓存模块
片上二级缓存使用一个静态RAM(static RAM,SRAM)实现,用于处理流处理器集群中的L1 Cache的访存请求,使用最近最少使用替换策略,在发生访存地址缺失后,通过一个crossbar 将缺失的访存请求发送至内存控制器进行处理。
2.6 内存控制器
内存控制器负责与片外显存交互,将L2 Cache的Miss 的访存请求通过总线协议(advanced extensible interface,AXI)发送到片外显存进行数据读写访问。
3 图形应用计算特性分析
如1.1 节所述,图形处理流水线的各个阶段分别使用不同的数据对象作为最小处理单元,这便导致流水线各部分极易产生工作负载不均衡的问题。在早期GPU 中,顶点着色阶段与像素着色阶段分别由不同的GPU 硬件模块进行处理,但因为顶点着色任务与像素着色任务的工作任务负载并不相同,很容易出现顶点着色任务过多或者像素着色任务过多的问题,这种负载不均衡问题严重影响了GPU 的工作效率。现代GPU 通过统一渲染架构来解决这种问题,即使用统一的流处理器架构同时处理顶点着色任务与像素着色任务。但统一渲染架构只能解决着色器任务的负载不均衡,无法解决光栅化阶段与着色器任务的负载不均衡问题。本节将对这一问题进行分析。
图形处理工作分为需要顺序执行的3 个阶段,即顶点着色阶段、光栅化阶段和像素点着色阶段。
顶点着色阶段对当前任务中所有顶点数据执行顶点着色程序,顶点着色任务的工作负载与当前任务中顶点数目与顶点着色程序复杂度呈正相关。
光栅化阶段分为以下几个步骤。步骤1 将顶点数据组织成为图元数据;步骤2 将图元数据生成以4×4 pixel 组成的frag(如图2);步骤3 逐个处理frag 数据,确定该frag 是否存在覆盖图元的quad 数据,并计算这些quad 与pixel 的属性数据。步骤1以顶点数据为对象,每周期读取一个顶点数据,其工作负载由顶点着色阶段传递来的顶点数目决定;步骤2 与步骤3 以frag数据为处理对象,每周期处理一个frag 数据,其工作负载由多个因素影响,包括每个顶点的位置信息、绘制任务所配置的屏幕分辨率信息。

图2 frag 结构示意
像素点着色阶段需要将所有输入来的quad(如图2)数据进行像素点着色程序处理。则像素点着色阶段的工作负载依赖于像素着色程序的指令复杂度,同时依赖于光珊化阶段第3 步生成的quad 数据数目。
通过对图形处理工作各阶段任务的分析,可以得出结论,图形处理工作在各个阶段,甚至是同一阶段的不同步骤,都有着不同的任务复杂度。同时由于顶点着色阶段、光珊化阶段和像素着色阶段需要顺序执行,任务复杂度不同会导致图形处理负载不均衡。例如,当顶点着色任务负载过重,则会出现光栅化阶段输入数据供给过慢的问题;当像素着色阶段处理过重,则会出现光栅化阶段结果数据输出被堵塞的问题。各个阶段的任务负载又依赖于顶点位置与屏幕分辨率等应用行为,而硬件芯片在设计完成后各模块的处理能力又无法变化,所以各模块的处理效率将极大地受到图形处理各阶段的工作负载影响,即硬件模块的执行效率受到图形应用行为的影响。
4 平台实现及实验分析
本节首先介绍GPU-Hi 平台的硬件实现情况,而后基于本平台进行了2 组实验分析。
两组实验分别为:实验1 为图形应用程序在配置为不同分辨率时,图形应用工作负载的变化;实验2为流处理器与内存控制器配置为不同规模时,GPU 光栅化模块的性能变化。GPU 作为3D 图形应用加速器,图形应用的工作负载直接影响GPU 各硬件模块的计算效率。
4.1 GPU-Hi 物理设计结果
本文使用28 nm 工艺对该平台进行物理设计,在目标主频为500 MHz 的情况下,芯片总面积为7.90 μm2,主要模块实际面积开销如表1 所示。
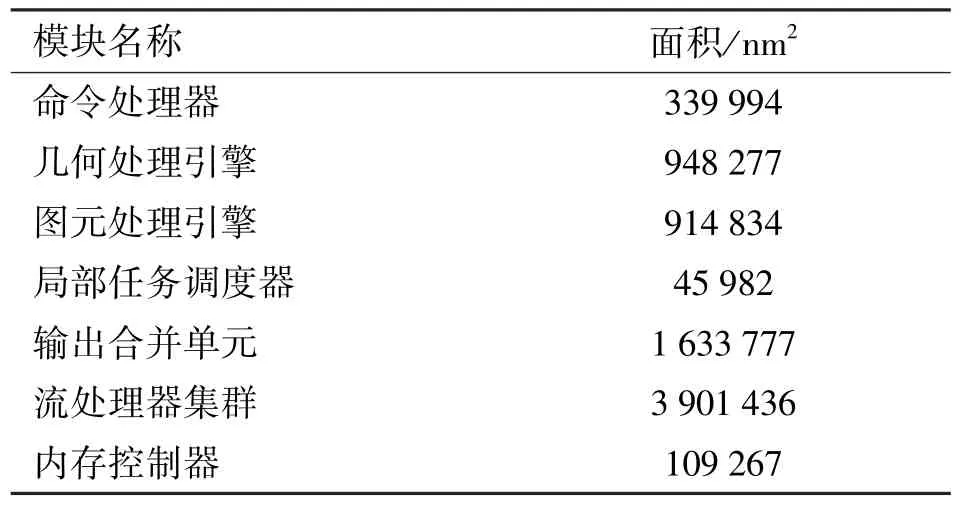
表1 GPU-Hi 在28 nm 下面积开销
4.2 分辨率对图形任务负载影响
本文选取glmark2 测试集中build-horse 进行实验分析。glmark2 是一款OpenGL 应用程序接口(application programming interface,API)程序测试集。build 测试是一个在顶点着色阶段进行光照渲染的图形程序。
首先通过将分辨率配置为400×300、600×450、800×600、1000×750、1200×900,来展示分辨率对图形应用行为的影响。
由于顶点数目属于图形任务固有属性,不随分辨率变化,所以顶点着色阶段的任务负载不随分辨率变化。但图元数据所生成的frag 数目属于图形任务动态属性,与分辨率相关,即光珊化任务负载会随分辨率变化。
图3 展示了build-horse 程序在不同分辨率下光珊化阶段中frag 数量与frag_visi 数量的统计信息。其中frag 数量是指需要进行像素点遍历处理的frag数据数目,代表了光栅化阶段的工作负载情况;frag_visi 数量是指经过像素点遍历处理后,被标记为可见的frag 数目,代表了有效的frag 数据;光珊化有效率是frag_visi 数量与frag 数量的比值。从图中可知,虽然frag 数量与frag_visi 数量均随分辨率提高而提高,但两数量的比值,即光栅化有效率最终也随分辨率提高而提高。
图4 展示了build-horse 程序在不同分辨率下光栅化阶段中quad 数量与pixel 数量的统计信息。其中quad 数量是指存在可见像素点的quad 数据数目,代表了像素着色阶段的工作负载;pixel 数量表示真正可见像素点的数量,代表了图形应用真正需要计算的像素数目。由图2 可知,1 个quad 数据对应4 个pixel 数据,所以像素着色有效率是pixel 数量与4 倍quad 数量的比值。从图中可知,quad 数量与pixel 数量均随分辨率提高而提高,同时像素着色有效率也随分辨率提高而提高。
由图3 和图4 可知,随着分辨率的提高,光栅化有效率与像素着色有效率都随之提高,这是因为在提升分辨率以后,相同屏幕面积下,每一个像素点所占屏幕面积更小,图形应用的3D 模型建模更加细腻,每一个三角形覆盖的误差区域也就更小。
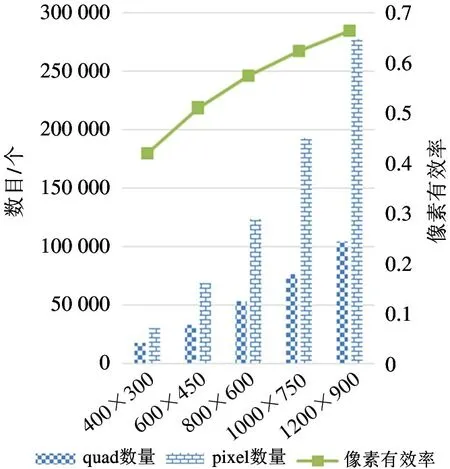
图4 quad 与pixel 数据变化
图5 展示了在分辨率增大后,以400×300 分辨率为基准,各项数据的比例情况,其中代表pixel 的线与代表像素的线完全重合。图中像素表示当前分辨率下屏幕中的像素数目,例如400×300 分辨率中像素数目为120 000。frag、quad、pixel 数据意义与图3、图4 相同。可以看出,在分辨率增大后,所有数据量都随之增大,但各个数据增大的比例并不相同。代表光栅化任务负载的frag 数据小于代表像素着色任务负载的quad 数据变化趋势,同时两者变化趋势均明显小于像素个数的变化趋势。
对图3~图5 的分析可以得出以下结论:(1)在图形任务分辨率提升时,分辨率模块与像素着色模块的工作有效率均有明显提升;(2)在对图像分辨率进行提高时,即提升画质时,各项工作负载并不会随分辨率的变化而等比例变化;(3)在图形任务分辨率提升时,GPU 各处理模块的任务负载变化比例并不相同,即GPU 各处理模块会产生负载不均衡问题。
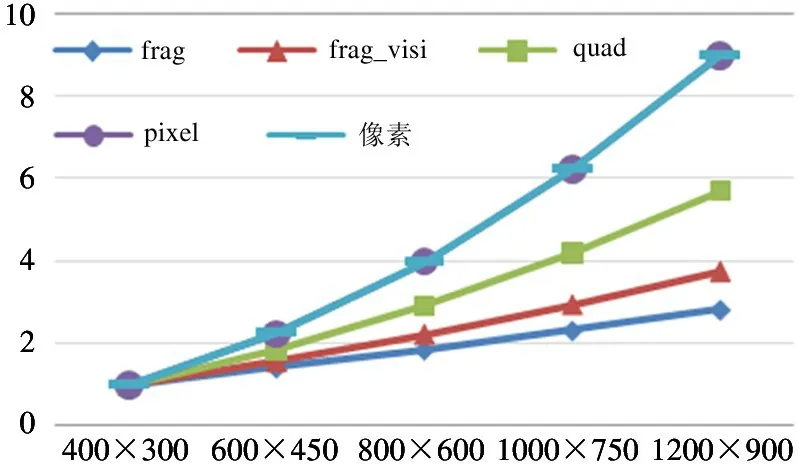
图5 光栅化各项数据变化比例
4.3 硬件配置对光珊化模块利用率影响
如第2 节对GPU 硬件结构描述,光栅化模块负责将图元数据生成为像素点数据,它并不执行着色器指令,也不进行显存的读写操作,指令执行能力与显存读写能力不会直接影响光栅化的效率。但是GPU 硬件使用顺序的硬件流水线实现图形处理算法,所以在执行图形任务时,GPU 各个硬件模块的执行时间是相同的,即光栅化模块的处理效率会受到流处理器能力与访存能力的间接影响。这里对这一问题进行实验分析。
表2 展示了应用程序在配置为不同分辨率时,光栅化模块的处理效率变化情况。total_time列表示GPU-Hi 的光栅化模块执行当前任务所执行的总周期数,frag_num表示对应分辨率下光栅化执行的frag 数据数目,ra_rate表示光栅化模块处理frag的速率,例如第一行表示分辨率为400×300 时,GPU-Hi 的光栅化模块执行了56 239 周期,处理了23 395 个frag 数据,平均每周期处理0.415 个frag数据。根据表2 可以看出,在分辨率与光栅化工作负载发生变化时,光栅化速率并没有发生显著改变,并且光栅化效率均不高,距离理想状态下的每周期处理1 个frag 数据的差距很大。这表示光栅化模块并不是GPU-Hi 的性能瓶颈,处理速率过低的原因可能是因为流处理器集群的处理能力不足,例如顶点着色阶段处理顶点数据的速度过慢,导致光栅化模块接收输入数据的速率太慢;像素着色阶段处理像素点数据过慢,导致光栅化模块生成的frag 数据无法向后级流水线传递。
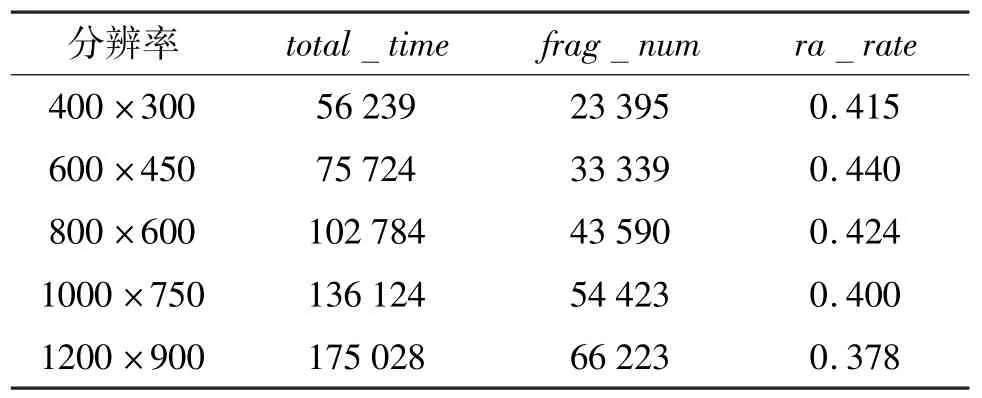
表2 分辨率与光栅化速率统计
为分析光栅化速率过慢的原因,本文对GPU 硬件中流处理器集群与ram 的配置进行更改。流处理器集群配置包括1 sp 和2 sp,其中1 sp 表示GPU-Hi中原本的流处理器集群架构,即整个GPU-Hi 只有一个流处理器模块,所有的顶点着色任务与像素着色任务均使用这一组流处理器进行处理;2 sp 作为对照组,表示使用2 组流处理器模块来完成顶点着色任务与像素着色任务,可大幅提高着色任务处理能力。ram 配置包括small ram 和super ram,其中small ram 表示GPU-Hi 中原本的ram 架构,即整个GPU-Hi 只有一个ram 进行显存读写处理,所有需要显存操作的模块均共享该模块;super ram 架构作为对照组,表示为GPU-Hi 中所有需要进行显存读写的模块均配备独立的访存处理单元,可以大幅提升整个GPU-Hi 的访存能力。
在实验中,对每个分辨率进行4 组对照实验:实验组1 为1 sp、small ram;对照组2 为1 sp、super ram;对照组3 为2 sp、small ram;对照组4 为2 sp、super ram。4 组对照实验的结果如图6 和图7 所示。
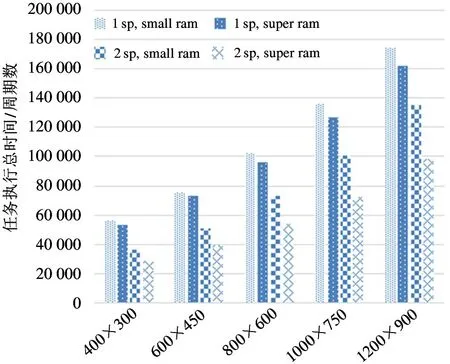
图6 任务执行总时间随硬件配置变化图
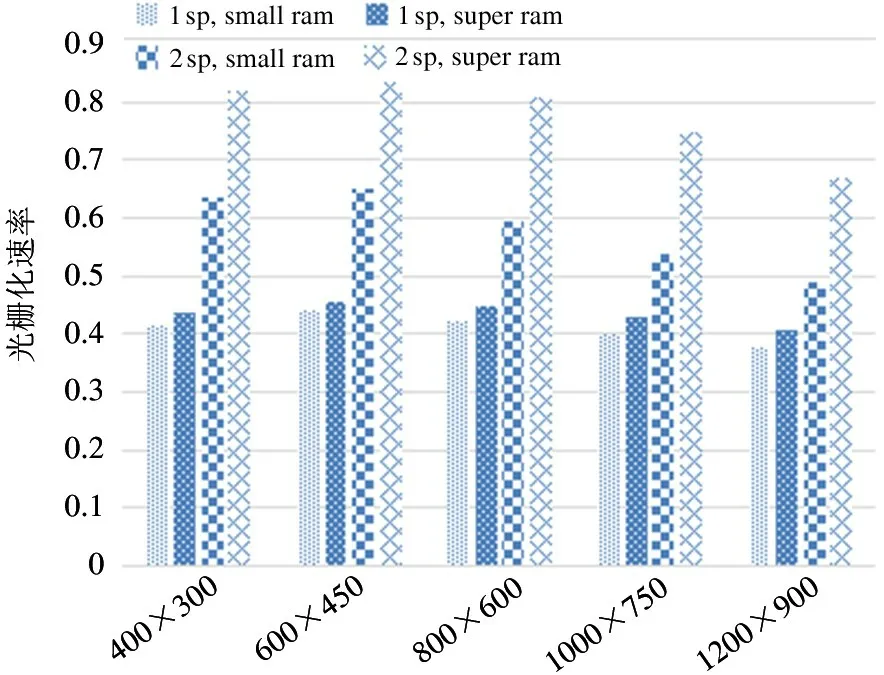
图7 光栅化速率随硬件配置变化图
由图可知,在5 种分辨率下,1 sp 与small ram均表现出最慢的光栅化速率。
在不更改ram 而单纯将1 sp 更改为2 sp 后,所有分辨率下frag 处理能力都发生了明显提升,每周期处理数目分别提升了0.22、0.21、0.17、0.14、0.11,提升比例分别为53.4%、48.3%、40.4%、35.1%、29.1%。这说明1sp 与small ram 的配置下,流处理器集群的工作负载过重,其计算能力极大限制了流水线整体的处理效率,并且在分辨率越低的情况下,流处理器集群的计算能力对光栅化的限制越明显,流处理器集群与光栅化模块的负载不均衡问题也越明显。但此时流处理器集群的理论计算能力增加了100%,光栅化能力虽然有提升,却没有进行等比例增加,最高提升比例仅有53%,最低提升比例仅仅为29%,这说明在2 sp 与small ram 的配置下,GPU的瓶颈可能是ram 的访存能力,而不是流处理器集群的计算能力,下文将增加ram 配置的对比实验。
在不更改流处理器集群配置而单纯将small ram 更改为super ram 后,可以看出frag 的计算能力并没有明显的提升,5 种分辨率下光栅化每周期性能提升比例仅为5.1%、3.7%、6.3%、7.1%、7.8%,这说明在1 sp 的配置下,small ram 的处理能力已经完全达到了工作负载的需求。
在将1 sp 更改为2 sp 同时将small ram 更改为super ram 后,相较于2 sp 与small ram 的配置,光栅化每周期性能提升比例分别为28%、28%、35%、38%、37%,可以看出此前2 sp 在配置small ram 时,流处理器集群的计算能力的确已经满足工作负载,但ram 的访存能力无法满足工作负载需求。对比1 sp与small ram 的配置,性能提升比例分别达到了97%、90%、90%、87%、77%。光栅化模块的frag处理速度在600×450 分辨率时达到了最高的0.83 个/s frag 数据,已经接近1 个/s frag 的理论峰值。
根据以上分析可知,GPU 作为图形应用加速器,其内部各个模块分别使用ASIC 与SIMT 等不同架构实现,具有极强的异构架构特性。光栅化模块作为流水线一部分,虽然不直接执行着色器程序,也不进行访存操作,但工作时的实时处理能力受到流处理器处理能力与访存能力的影响。
5 结论
工业界因为商业问题无法提出一套完整的寄存器传输级GPU 研究平台;学术界所使用的GPU 研究平台中,MIAOW RTL 平台没有实现完整的图形算法,而其他研究平台如ATTILA、Emerald、Teapot,没有通过RTL 实现。
在这一情况下,本文提出RTL 级的GPU-Hi 研究平台,并描述了该平台的硬件实现的方法。使用GS132 处理器核实现命令控制器,完成CPU 发送来的任务解析与整条流水线的调度配置;使用ASIC电路实现图元处理引擎,完成复杂的3D 图形光栅化算法;使用SIMT 架构的流处理器实现流处理器集群,完成顶点着色程序与像素着色程序的执行。
基于前述寄存器传输级GPU 研究平台通过glmark2 测试集对3D 图形应用行为分析及GPU 硬件负载进行分析,得到以下结论。(1)图形应用的分析表明3D 图形应用的分辨率变化与分辨率所带来的工作负载变化并不是等比例相关,并且光栅化任务负载与着色器任务负载存在明显的负载不均衡问题;(2)对GPU 硬件负载的分析表明,虽然光栅化模块并不执行着色器程序指令,也不直接进行显存的读写操作,但其工作效率极大地受到流处理器与访存能力的影响。
随着人工智能的飞速发展,学术界越来越多的关注点投入到了GPU 在通用计算领域的研究,本文现有平台的实现集中于GPU 在图形渲染领域的研究,尚未实现通用计算功能。下一步的研究工作需要增加通用计算如OpenCL 的支持,同时需要进一步完善实验平台的工具链与调试环境,尽快将GPUHi 平台开放给研究人员使用。
猜你喜欢
中国交通信息化(2022年5期)2022-07-23
今日农业(2021年9期)2021-11-26
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
今日农业(2020年16期)2020-12-14
电子制作(2019年24期)2019-02-23
电影(2018年10期)2018-10-26
北方交通(2016年12期)2017-01-15
湖南大学学报·自然科学版(2014年3期)2014-12-30
中学生数理化·高一版(2009年6期)2009-08-31
