
基于改进Yolo v3 的弹载图像弱小目标检测算法*
2022-07-25 03:59田宗浩郭佳晖孙姗姗
火力与指挥控制 2022年4期
田宗浩,郭佳晖,孙姗姗,申 倩
(陆军炮兵防空兵学院高过载弹药制导控制与信息感知实验室,合肥 230031)
0 引言
新型作战条件下,战机稍纵即逝,如何快速、准确地确定战场打击目标是可见光图像制导弹的重要战术指标。由于弹载平台应用环境的特殊性,弹载摄像机成像与静态摄像机成像质量差别很大,空中运动成像导致目标在图像中尺度小、尺度多变,容易受周围景物和大小目标分布不均等干扰,并且图像存在扭曲、虚化等形变,导致目标检测效果不佳,大大降低检测精度,并且存在漏检、误检,严重影响智能弹药的自主决策能力。
弹载图像目标检测是一种自动目标识别技术(automatic target recognition,ATR),属于机器视觉领域,该领域从产生就一直受到学术界的高度重视。随着深度学习理论在机器视觉领域卓越的性能表现,基于深度学习的目标检测算法逐渐替代传统手工特征提取目标检测算法,其在不同应用场景下取得较好的识别检测效果,例如人脸识别、车道线检测等。大量的研究文献将基于深度学习的目标检测算法分为基于候选区域的目标检测(两阶段)和基于回归的端到端目标检测算法(单阶段),其中,单阶段目标检测算法直接在图像中多个位置上回归出这个位置的目标边框以及目标类别,在保证一定准确率的前提下,速度得到极大提升。文献[6]提出的Yolo(you only look once)算法通过对图像的直接检测确定目标的边界框和类别,检测速度提高到45FPS,但其对紧邻目标和小目标的检测效果不佳。随后,Yolo 系列算法通过BN 操作、残差网络特征融合等算法改进,使得模型检测精度和速度大幅度提升,并对小目标的适应性增强,如Yolo v2/v3、Tiny-Yolo、SlimYolo等。但是在高动态、强对抗的精确制导弹药领域,极少有人将人工智能技术应用到弹载平台,其根本原因在于弹载任务的特殊性对算法的检测准确率、实时性,以及特殊环境的适用性提出了较高的要求。为此,本文结合弹载图像目标特点和系统设计要求,选用当前检测速度和准确率较高的单阶段目标识别检测算法Yolo v3 为基线网络,丰富训练数据集,改进网络结构,提高弱小目标的检测精度。
1 弹载图像目标检测算法分析
1.1 弹载摄像机成像特点分析
图1 为图像制导弹工作过程,当弹丸在距离目标3 km~5 km 的位置时,弹载摄像机开始工作,通过在视场内搜索目标信息,引导弹丸命中目标。因弹载摄像机距离目标较远,且为高空成像,目标初入视场尺度非常小,目标在视场内比例变换如图2 所示。图2 为弹载摄像机高空成像下的视场范围,为简化计算难度,将弹载摄像机俯视视角转换为正面平视视角,不考虑弹丸落角造成的投影比例偏差。因此,弹载摄像机的视场范围可以分解为长宽方向。则摄像机视场范围和目标在图像中所占像素大小为:
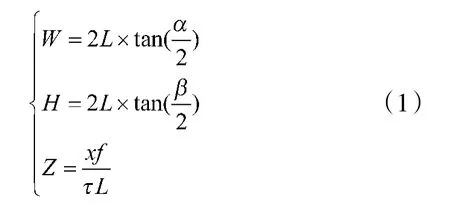
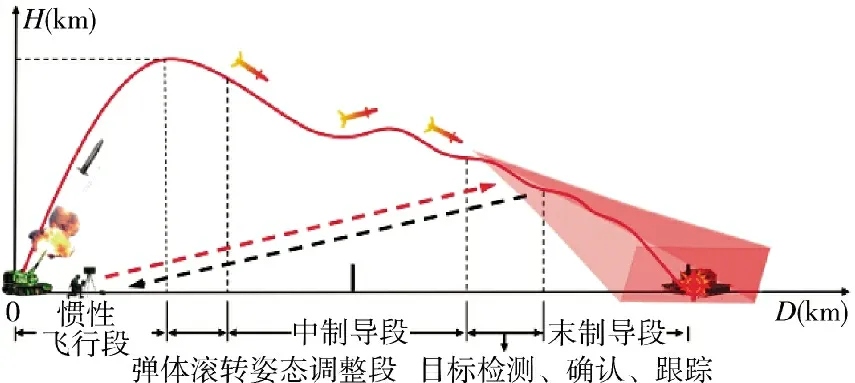
图1 图像制导弹工作过程

图2 弹载摄像机成像目标像素计算示意图
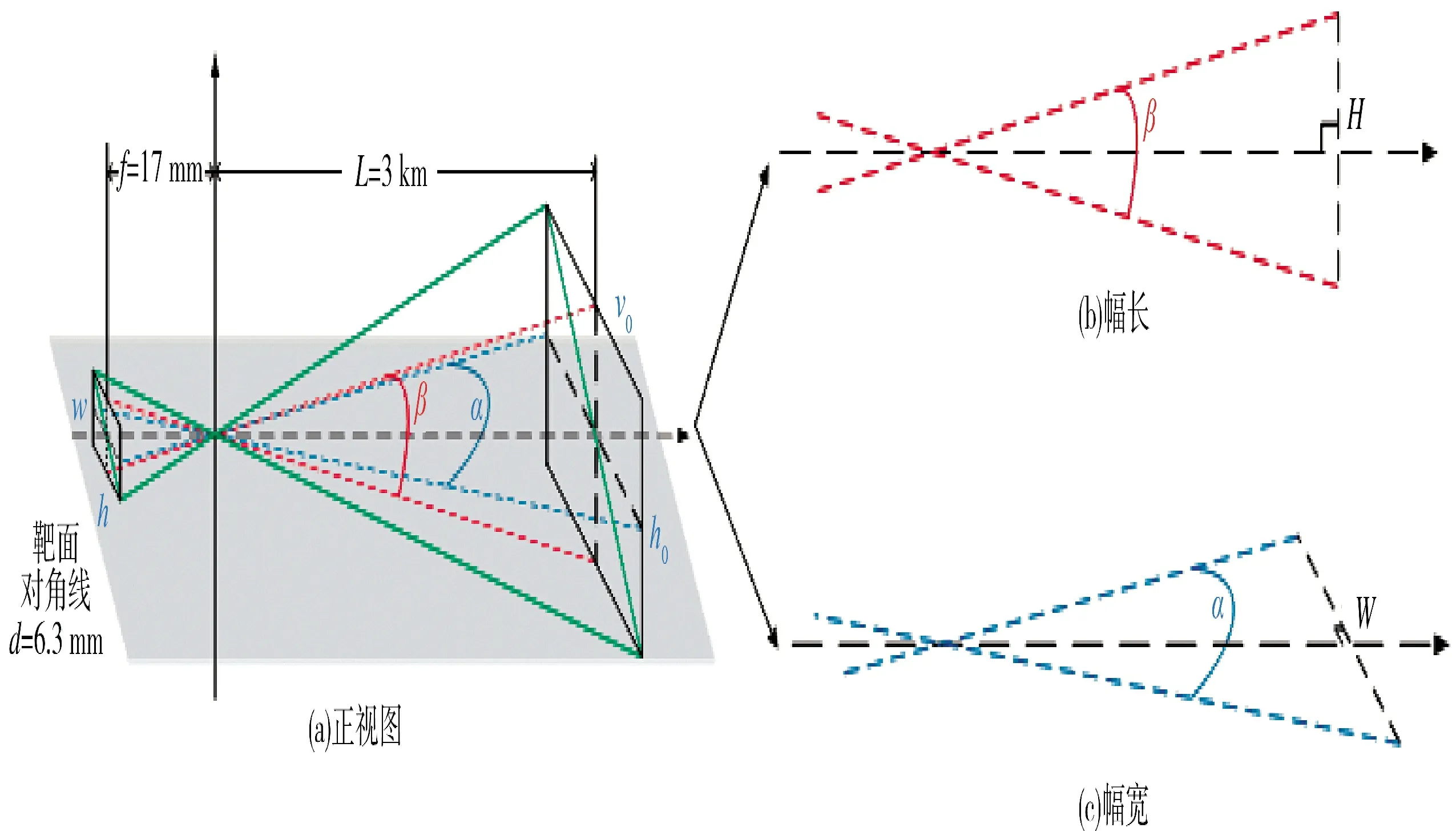
图3 视场幅长幅宽示意图
式中,W 和H 为弹载摄像机成像视场的幅宽和幅长,α 和β 为镜头在长宽方向的视场角,f 为焦距,为像元大小,x 为目标实际大小,Z 为占像素大小,L为弹目距离。假设目标的长宽分别为W和H,则目标在弹载摄像机视场内的比例大小为h和w:

用式(1)和式(2)计算不同装备在不同弹目距离时像素比例大小,假定摄像机的视场角α 和β 分别为20 °和18 °,像元大小为5.5 μm,则各装备在不同弹目距离下目标占视场比例和像素大小如表1 所示。

表1 不同装备在不同弹目距离条件下成像像素比例
目前,众多研究将弱小目标定义为像素值小于32×32 的物体,从表1 可以分析出,陆战场景下的武器装备因自身尺寸本身较小,导致目标在视场内所占比例较小,并且背景和目标分布不均,高度融合,这给识别检测算法带来较大的挑战,不同作战装备高空成像示意图如图4 所示。

图4 不同作战装备高空成像示意图
图4 中红色方框为小目标装备,特别对于第1幅图像,目标像素大小不超过10×10 个像素,包含的特征信息较少,很难判别装备类型。虽然Yolo v3网络结构在传统模型上有了很大改进,对小目标等难点问题有了一定的改善,但是对于复杂战场条件下的目标检测仍存在目标漏检和误检情况,特别是对于大小目标分布不均匀的情况。
1.2 Yolo v3 基础框架
Yolo 系列算法是基于回归的单阶段卷积神经网络目标检测算法,直接对图像中的目标类别、位置等信息进行检测,节省特征提取过程中候选区域生成过程,其识别检测速度得到质的提升。随着Yolo 系列算法网络架构不断改进,其检测速度、识别精度以及对不同场景的适应性不断提升,尤其Yolo v3 模型在应对多尺度变化、弱小目标识别场景下体现出优越的性能,使其在工程应用中被大量使用,如无人机目标检测、自动驾驶等。
Yolo v3 模型由Darknet53 骨架网络、特征融合网络(neck)和预测网络(prediction)组成,其识别检测过程如图5 所示。

图5 Yolo v3 识别检测过程示意图
其中,骨架网络Darknet53 在不同图像粒度基础上提取目标特征,通过特征融合网络将提取的特征进行结合,提高对不同尺度目标的适应能力,预测网络则利用融合特征进行分类、回归,确定目标的类别信息和位置。结合Yolo v3 官方代码及模型可视化工具Netron 对模型计算架构的可视化处理,总结分析Yolo v3 的网络架构如图6 所示。

图6 Yolo v3 网络结构
Yolo v3 是在Yolo v1/v2 的框架基础上演变而来,它将Yolo v1 架构中的池化层取消,通过卷积核的移动步长达到缩小特征尺度的目的(图6 中红色方框),并且利用K-means 聚类算法对Yolov2 模型先验框(anchor boxes)最优数量进行优化设计,提升模型的预测精度。另外,Yolo v3 采用更多的残差单元加深网络特征提取器(图6 绿色单元),并采用多尺度特征图(feature pyramid networks,FPN)结构提取3 个尺度的图像特征信息,通过多尺度检测提升弱小目标的检测精度,获得鲁棒性更强的图像特征,增强模型对不同尺度目标的适应性。
1.2.1 先验框(Anchor Boxes)
Yolo v3 预测过程借鉴Faster R-CNN 中Anchor Boxes 的设计理念,每个cell 预先设计多个与数据集中目标对象宽度和高度类似的不同形状和大小的先验框,并在训练过程中修正与ground truth 相匹配的anchor 位置偏移,通过非极大值抑制(non-maximum suppression,NMS)获得目标的检测框,大大提升了目标的定位精度,如图7 所示。
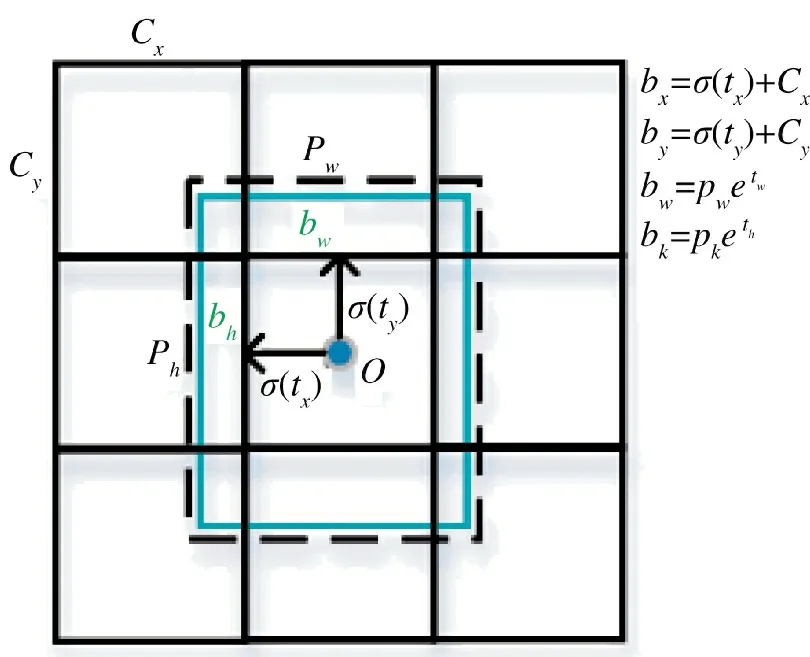
图7 anchor box 位置预测


Yolo v3 利用K-means 聚类算法对3 个预测分支的anchor 的尺寸进行聚类分析,每个预测分支确定3 个anchor,其大尺度特征图使用尺寸小的anchor,用来提高对图像中小目标特征的提取能力。小尺度特征图使用尺寸大的anchor,提高对大目标特征提取能力,使Yolo v3 网络具有更强的多尺度特征提取能力。
1.3 FPN+多尺度预测
对于图像特征而言,高层特征语义丰富,但分辨率较低,对纹理细节特征的感知性能较差;低层特征分辨率较高,更多的位置和细节信息包含在内,但是语义表达能力较差,容易受噪声影响。Yolo v3 网络通过5 次降采样操作提取不同尺度的图像特征,并在后3 次降采样后对目标进行预测,输出3种尺度的特征图13×13、26×26 和52×52。其中,3种尺度的特征提取对应大、中、小3 种不同的感受野,以此预测不同尺度的目标。另外,通过对第4 和第5 次降采样得到的特征图进行上采样,分别与各自前一层的图像特征进行融合,使得对小目标位置的特征描述更加丰富,大大提升了对不同尺度目标的适应能力,如下页图8 所示。
从图8 可以看出,图8A ~图8C 分别为第3、4和5 次降采样后提取的特征图,图8E、图8F 分别为两次上采样后图像特征融合结果。从中可以看出,经过FPN 特征融合后,图像包含的高层和底层图像特征更加丰富,对弱小目标的特征提取更加明显。

图8 Yolo v3 特征图提取结果分析
2 改进算法
上文对弹载摄像机的成像特点进行了分析,弹载图像中的目标尺度信息随弹丸运动变化较大,并且由于弹载摄像机视场和目标本身尺度较小,目标在图像中的比例较小。当弹目距离1 km 时,10 m×3 m 的目标也即31×10 个像素,受限于弹丸的制导能力(距离目标1 km 时,弹丸约3 s~4 s 落地),很难在短时间内针对识别的类别信息有选择性地确定打击目标,改变弹丸的运动姿态。通过对大量装备的目标特征分析发现,当弹载摄像机距离3 km成像条件下,目标特征信息较少,对于不同的装备,存在很大程度上的相似信息,如图9 所示。

图9 多目标远距离成像
从图9 可以看出,当目标特征较少时,不同装备的纹理细节非常少,只有基本的轮廓信息。同时,结合图像制导弹的作战使用流程以及弹丸的毁伤效能特性,精确制导弹药要能在视场中快速定位目标位置,而对尺度特征相对较小的打击目标类别区分度要求不高,即坦克、装甲车等目标的重要性相同,能大概率命中目标即可。因此,对于复杂作战环境下的弱小目标识别问题,可以将不易分辨类别的目标归结为一类,而对于易于辨别的目标正常识别,提高弹载图像中目标快速检测能力,其检测过程如图10 所示。

图10 弹载图像小目标检测步骤
图10 中,当弹目距离较远时,快速定位到图像中的目标位置,为指挥员提供预判时间,随着弹目距离不断缩小,判断图像类别,评估战场目标分布和毁伤效果。
为此,本节针对弹载图像目标特性对Yolo v3网络结构和参数进行优化,提升对战场弱小目标的检测准确率,调整方案为:1)数据扩充及标注;2)调整anchor 大小;3)上采样转换为双线性插值上采样;4)空间注意力模块。
2.1 数据扩充及标注
文献[10]对弱小目标检测算法的难点问题进行了研究分析,目标尺度小、特征信息少以及样本数量不足是制约小目标检测算法性能的关键因素。对于弹载图像中的目标,因其尺度小,包含目标的anchor 相应较少,平均最大的IoU 也相对较低,为此可以提高弱小目标在图像中出现的频率,以此增加更多的anchor 与之匹配,如下页图11 所示。
从图11 可以分析出,对于大目标,图11(a)中有多个anchor 与目标匹配(紫色anchor),而图11(b)中的小目标仅有3 个anchor 与之匹配,并且IoU的值也非常小(红色anchor)。通过目标在图像中复制,小目标在图像中出现的频率变高,与其匹配的anchor 也大幅度增加,提高了对弱小目标的搜索能力,被检测出的概率也大幅度提升。

图11 不同尺度目标anchor 分布
上节对弹载摄像机采集的目标特征进行了分析,其成像初期目标在图像中的像素占比非常低,不易于辨别图像类别特征。结合图像制导弹的机动能力以及目标在弹载图像中的特征统计分析结果,本文将像素低于15×15 的目标标注为一类,而其他像素比例的目标按照其自身特征进行正常标注,例如像素低于15×15 的坦克、远程火箭炮、步战车等等,统一标注为“target”类;而像素高于15×15 的坦克、远程火箭炮、步战车等分别标注为各自类别名称。
2.2 网络结构优化
2.2.1 双线性插值上采样
Yolo v3 算法中通过FPN 结构实现不同尺度特征的提取,并通过上采样实现不同尺度特征的融合和预测,提高模型对不同尺度目标的适应性(图6黄色方框)。上采样操作可以提高图像的分辨率,常用的方法一般为上池化(unpooling)、上采样(upsampling)和双线性插值(bilinear upsample)。传统Yolo v3 通过两次上采样提高特征图的分辨率,分别与上层特征图进行特征融合,其最大值池化和上采样过程特征图变化如图12 所示。

图12 Unsampling 示意图
从图12 可以看出,upsampling 操作相对简单,通过复制操作完成特征图扩张,对特征位置信息带来误差,特别对弱小目标,特征图上采样中容易将其特征丢失。
上池化(unpooling)保留了特征图中的位置信息,其余位置用0 补充,如图13 所示。

图13 unpooling 示意图
上池化过程仅是对特征图的扩增,没有充分利用特征图保存的信息,虽然unpooling 保留了特征的位置信息,但是补0 操作容易丢失部分弱小目标信息。
双线性插值(bilinear upsample,BU)充分利用低分辨率图像中特征图的位置和像素信息,提高定位精度,减少特征信息损失,其过程如下所示:
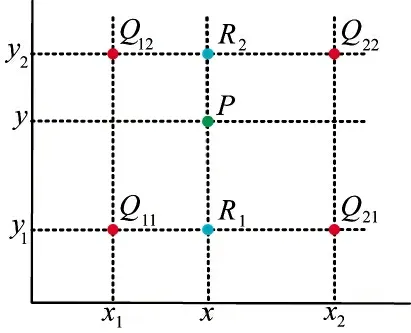
图14 BU 示意图

2.2.2 卷积注意力模块
在人类的视觉感知模型中,更加关注图像中特征显著的目标区域,即人的注意力机制。在作战环境下,指挥员对目标区域的目标特征更感兴趣,而弱小目标的特征较少,容易在下采样中被忽视。为此,本节算法在不同尺度特征融合的基础上引入卷积注意力模块(convolutional block attention module),提高对弱小目标的特征的表达能力。
CBAM 包含通道注意力(channel attention modul,CAM)和空间注意力(spatial attention module,SAM),其整体结构如下页图15 所示。

图15 CBAM 结构示意图

其中,CAM 提取特征图通道之间的联系,注意力集中在辨别目标类别,使用最大池化和平均池化实现信息整合,用Softmax 函数激活特征信息,其结构如图16 所示。

图16 CAM 模块结构示意图
利用图16 中通道注意力模块,得到通道注意力最后的结果为:

其中,MLP 为共享多层感知器,σ 为Softmax 函数。
CAM 提高了对特征中目标类别的注意力,并将输出的结果送入SAM 对特征图中信息的空间相关性进行分析,其SAM 的结构如图17 所示。

图17 SAM 模块结构示意图
SAM 用来提高对目标位置信息的注意力,通过maxpool 和avgpool 来对通道维度信息进行整合,利用标准的卷积操作对两个不同特征图信息进行特征提取,以此产生二维空间注意力图,式(6)所示:

2.2.3 Anchor Boxes 设计
Yolo v3 采用Anchor 的思想对目标位置进行定位,解决直接预测目标位置确定边界框难以回归问题,通过直接预测与Anchor 的偏移距离加快模型收敛和提高定位精度。Yolo v3 算法通过K-means 聚类对数据集上的目标先验框尺度进行分析,解决Anchor 尺度不合理对定位精度带来的负面影响,特别是对于小型目标和大小尺度不均衡目标,Anchor的长宽比例对模型检测精度至关重要。针对自己的样本集对网络中每种尺度特征图的Anchor 重新初始化,提高模型的训练效果,其参数如表2 所示。

表2 Anchor Boxes 参数
原Yolo v3 网络利用FPN 和多尺度预测相结合的方式来提高对多尺度目标的适应性,对图像制导弹来说,其面向的目标尺度相对较小。因此,本节算法将预测大目标的特征结构改进为中等目标和小目标的融合特征,并增加CBAM 提高对显著特征的注意力,提高对弱小目标特征信息的提取能力,改进后的Yolo v3 网络结构如下页图18 所示。
从图18 可以看出,改进Yolo v3 网络将中尺度和小尺度特征通过降采样实现空间特征融合(红色虚线方框),并且在融合特征的基础上通过卷积注意力模块CBAM(蓝色方框)提高对特征图中显著特征的注意力,提高对弱小目标特征的提取能力。另外,FPN 中的上采样过程通过双线性插值提高特征图的分辨率,充分利用特征图中的目标特征和位置信息,进一步提高对弱小目标特征的提取能力。
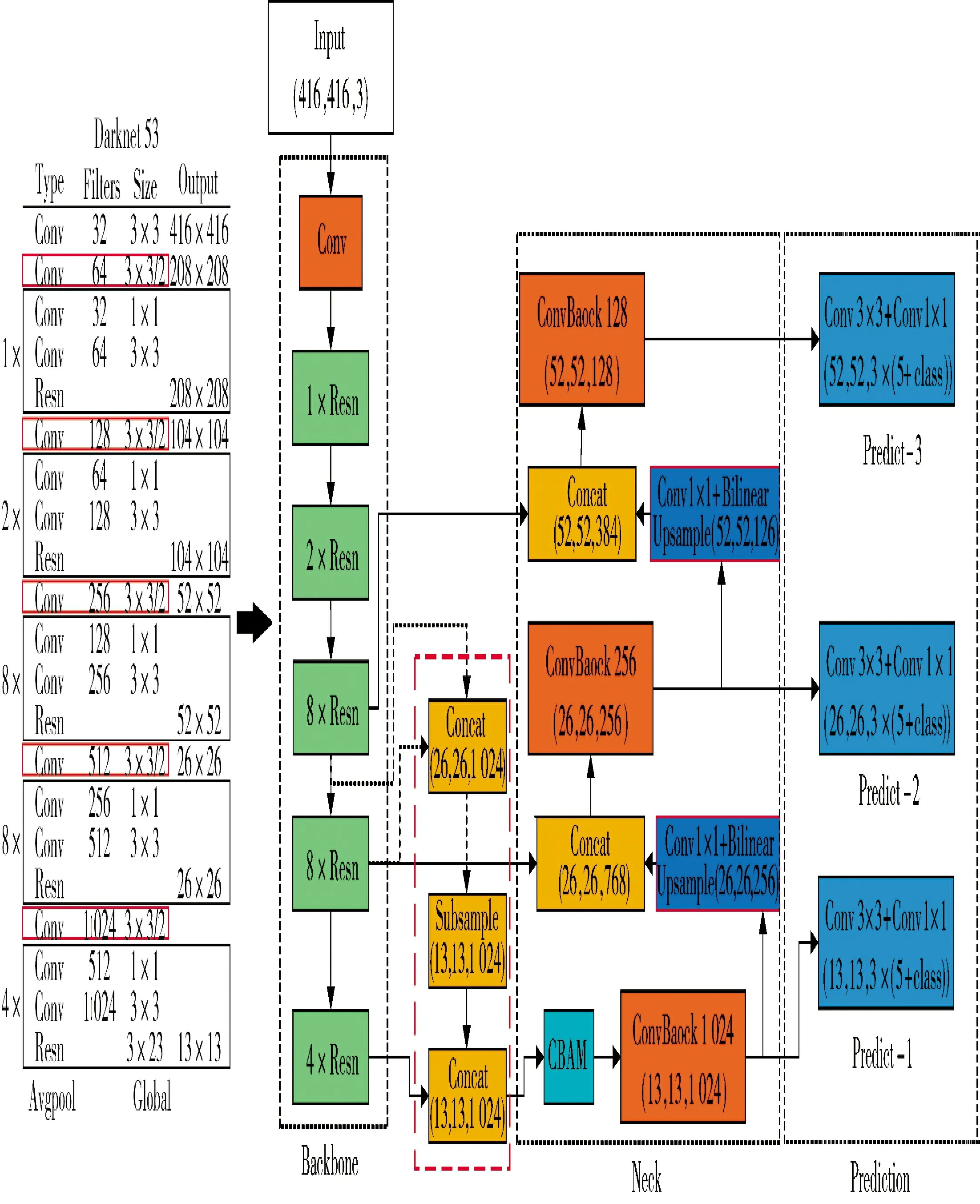
图18 改进Yolo v3 网络结构
3 实验结果
模型训练硬件配置:CPU:Intel(R)Corei7-7700HQ @2.8 Hz 八核,GPU:NVIDIA GeForce GTX 1070,RAM:16 GB。
软件配置:操作系统为64 位Microsoft Windows 10,深度学习框架:tensorflow,编程语言Python。
模型训练参数设置:训练样本为弹载摄像机高空成像仿真图像和无人机搭载弹载摄像机模拟弹丸飞行高度航拍图像,筛选出符合弹载摄像机成像特点的图像,其中,涵盖坦克、步战车、远程火箭炮、直升机、战斗机、火炮、桥梁以及碉堡等8 类目标,共8 000 张图片,每类目标不低于10%,并且不同弹目距离目标图像按照3 km,2 km,1 km 和0.5 km 为4∶3∶2∶1 比例配置,保证远距离目标样本数量,训练集、测试集和验证集按照7∶2∶1 的比例配置。为使本节搭建模型能更快、更稳定地获得更好的训练效果,Learning_rate 取值0.001,momentum 为0.9,decay 为0.000 5,batch 为16、32、64 等(根据训练过程自行调整),训练迭代最大次数50 000。
为对比分析本节改进模型与原Yolo v3 模型性能优劣,分别采用相同的训练参数配置训练模型,其性能分析结果如图19 所示。
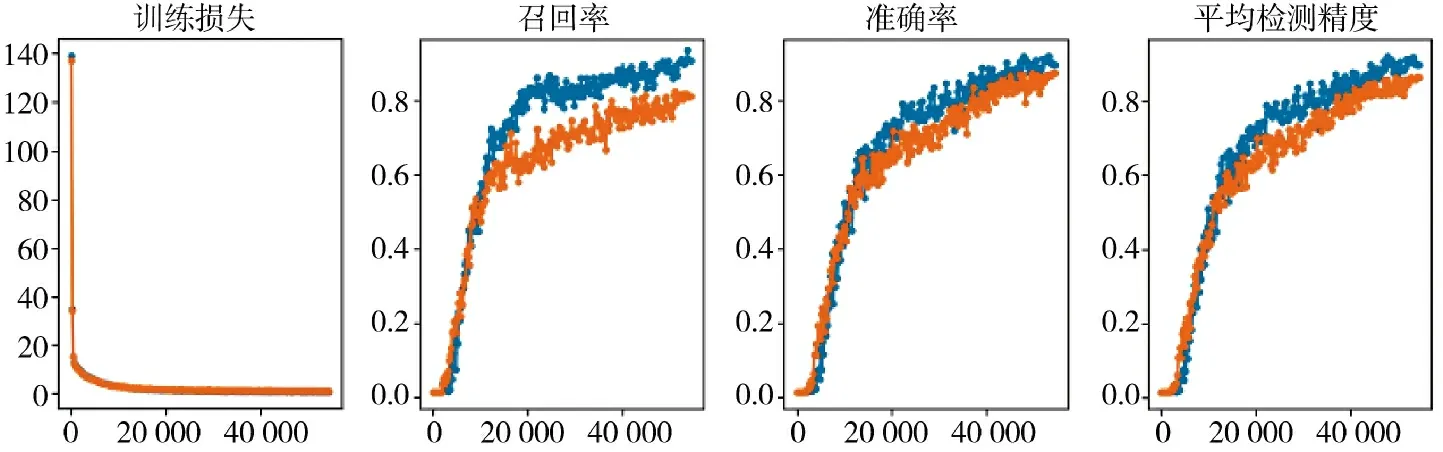
图19 本节模型与Yolo v3 性能指标变化情况
图中橙色散点为Yolo v3 算法指标,蓝色散点为本节改进模型参数指标,通过对各自训练损失、召回率、准确率以及平均检测精度分析可知,本节模型训练损失能快速降至较低水平,并且在迭代12 000 次左右损失值低于Yolo v3 水平,模型的各评价标准也在迭代12 000 次左右超过原始Yolo v3模型,验证了本节改进模型的有效性和高性能。
利用数据集中的测试集对上述训练模型结果进行测试,其结果如图20 所示。
图20 为不同弹目距离时不同目标的检测结果示意图,从中可以分析出,对于远距离弹载摄像机成像,战场中目标特征信息较少,坦克、远程火箭炮等尺度较小的目标被统一识别为“target”类别,检测准确率最高达92%。随着弹目距离的不断缩小,各装备在图像中的特征信息不断增多,被准确识别类别的概率也不断增大,当弹目距离为1 km 左右时,已基本可以准确分辨类别信息。

图20 检测结果示意图
进一步分析本节模型与原Yolo v3 的算法性能,统计测试集中不同目标的检测精度,如图21 所示。

图21 各类别检测精度对比结果
图21 中,“target”为弹目距离较远不能分辨目标类别标注的泛化“目标类”,mAP 为目标的均值平均精度。通过测试集各目标检测精度的统计分析发现,本节改进模型在同等训练条件下比传统Yolo v3能获得更高的检测精度,特别是对弹载图像中不易区分目标类别的小目标装备,模型检测精度可以达88.7%,为指挥员战场决策提供更充分的时间。
为进一步验证改进模型中各改进策略的有效性,通过相同的参数训练条件调节模型训练过程,其测试结果如表3 所示。
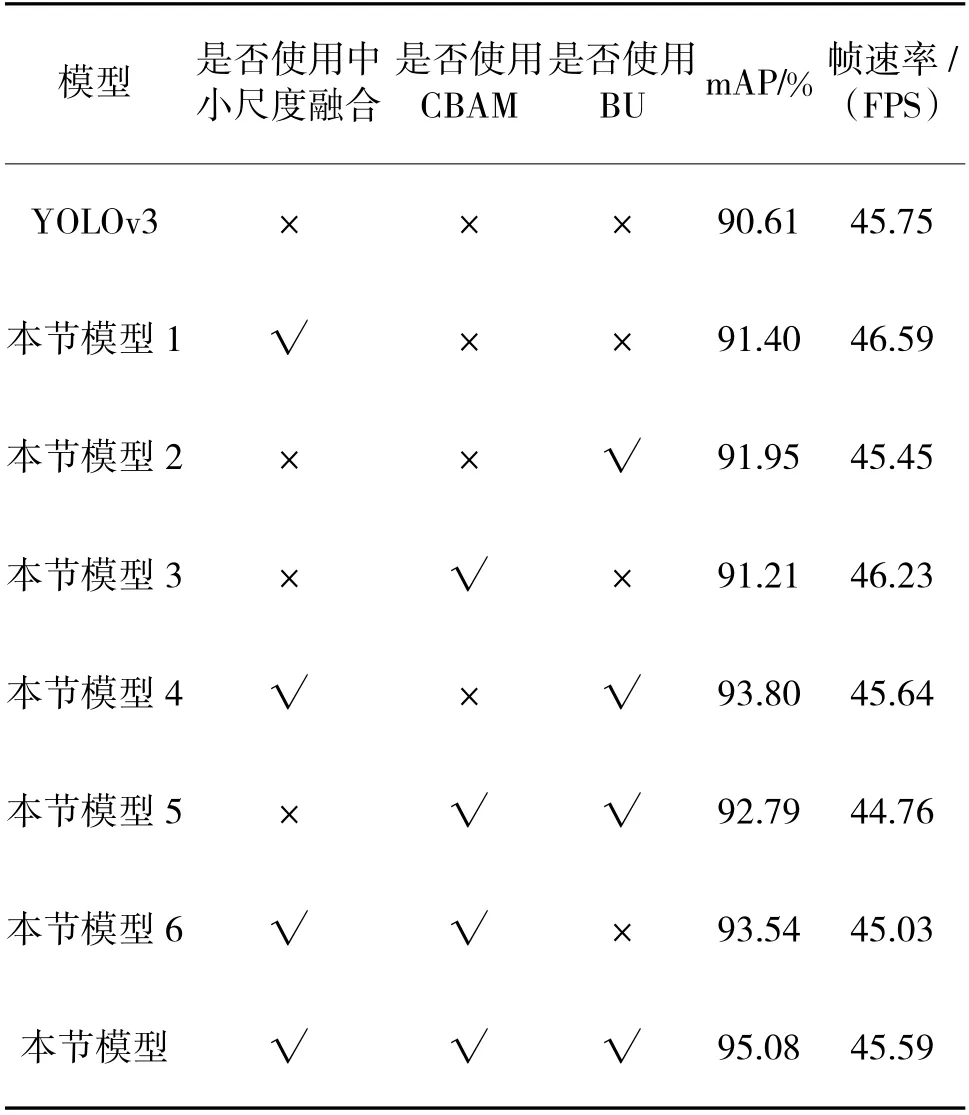
表3 模型改进策略对算法影响
通过表3 分析可知,改进算法中各策略均会在一定程度上提高模型的预测精度,并且当各策略均被应用到网络改进中时,模型的均值平均精度比传统模型提高了4.47%。此外,上述改进策略对模型的目标检测速度影响不大,均保持在45 FPS 左右,满足弹载图像地面站目标检测实时性的要求。
4 结论
本文对弹载图像目标检测中存在的问题进行分析,以Yolo v3 为基线网络,建立对弱小目标的改进模型。在数据增强和目标分类层面对小目标样本集进行处理,将像素小于15×15、不易区分类别的目标统称为“target”类,提升小目标占比,大大降低了弱小目标的误判概率。随后,优化Yolo v3 网络结构,在Yolo v3 多尺度特征提取中将小尺度和中尺度特征融合替换大尺度特征,并引入卷积注意力模块,提高对目标显著特征的表达能力。利用双线性插值实现多尺度特征上采样,充分利用目标特征的位置和像素信息,提高定位精度,减少特征信息损失。实验结果表明,改进后的Yolo v3 模型可以大幅提升小目标的检测准确率,mAP 高达95.08%,检测速度在GPU 平台下为45 FPS,满足实时性要求,为弹载异构平台部署提供了高性能算法。
猜你喜欢
雪豆月读·高年级(2020年2期)2020-09-10
飞天(2018年8期)2018-10-29
奇闻怪事(2018年9期)2018-09-28
同学少年·作文(2017年1期)2017-06-05
红领巾·萌芽(2015年1期)2015-04-10
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
小哥白尼·野生动物画报(2009年4期)2009-05-11
数码(2009年3期)2009-03-16
数码影像时代(2009年1期)2009-02-12
