
大学生就业决策的D数理论评估方法
2022-07-20 05:57:12莫泓铭
宜宾学院学报 2022年6期
莫泓铭
(四川民族学院图书馆,四川康定 626001)
就业是民生之本,事关全民幸福,是社会不断向前发展的主要推动力[1-2]. 近年来,社会用人制度、人才技能的需求等在不断发展与完善,就业环境、就业政策与社会大环境都发生了巨大的变化. 大学生的就业方式从计划经济时代的包分配过渡到了市场经济时代的自主择业、双向选择,为大学生就业提供了更为广阔的平台与更多的就业机会[3]. 然而,随着科技的发展,许多岗位都呈现了科技化、智能化的特点,岗位的需求人数在不断减少. 随着高校扩招,每年的大学毕业生规模逐年增大,再加上往年没有成功就业及再就业群体,大学生的就业前景不太乐观. 大学生就业不是孤立的个体事件,事关其背后的整个家庭,事关百姓民生[4]. 在严峻的就业形势下,大学生需要更新观念,正确认识并不断提升就业能力,运用科学的就业决策方法,做到既不好高骛远又实现自身能力与岗位最大化匹配.
纵观大学生的整个就业过程,其就业选择所涉及的因素也是众多的,除了直观的薪资待遇、工作稳定度、加班情况、社会认可度等客观因素外,还涉及到大学生自身的家庭背景、专业功底、个人爱好等主观潜在因素[5]. 这些主客观方面的因素共同左右着大学生的就业决策,因此,大学生的就业决策问题可视为多属性决策问题之一.
D 数理论是一种新的不确定信息表达与处理方法,它基于证据理论[6-7],但又克服了证据理论的诸多限制与不足. D 数理论近年来被广泛应用于多属性决策领域,如项目复杂性评估[8]、安全评估[9-10]、汽车性能评估[11]、施工方案优选[12]、投资决策[13-14]、交通可持续性评估[15],等等. 此外,D 数理论还和概率语言集[16]、模糊层次分析法[17-19]、SWOT 方法[20]等联合用于处理各类生活中实际问题.
尽管学者们提出了诸多的方法用于决策问题,但D理论由于其具有更为灵活、宽容度更高等特点,近年来被广泛应用于决策研究中. 特别是对于非完备信息,D 数理论能直接表示并处理,而不用强行补全. 大学生在就业决策过程中,对就业信息的搜集存在着不确定、不完全、不精确等情况,将D 数理论用于其就业决策过程,构建就业决策评估模型,选择合理的就业方案,从而帮助大学生实现就业能力与就业岗位的最大化匹配.
1 预备知识
D 数理论是邓勇教授于2012 年提出的一种用于表达和处理不确定信息的工具[21]. 证据理论在应用时需满足诸多限制,比如辨识框架必须完整、框架中的元素间必须两两互斥等约束条件,此外还具有“一票否决”制、计算时间复杂度高等不足.D数理论作为证据理论的扩展,更加贴近实际,元素之间不强行要求互斥;同一D 数内的各元素信任度之和允许小于1,即允许根据实际情况表达信息,而不需要强行将信息凑完整. D 数理论的聚集属性完美地解决了证据理论组合规则的指数级计算时间复杂度增长问题.D数理论的相关定义如下:
假设Ω为非空有限集合,D 数是一个映射,即D:Ω→[0,1]且满足条件:
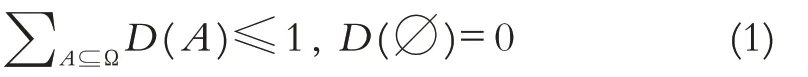
其中∅是空集,A是集合Ω的任意子集.
D数的定义存在两个特性:
①集合Ω 中的元素不要求两两互斥. 比如在语言评价中,“一般”“很好”和“好”这三个元素之间没有明显的间隙,很可能会存在一定的交叉,即不满足互斥条件,这在证据理论中是不允许的,但在D数理论中是允许的,使得决策者在表达自己的观点时,可以更好地结合自身情况作出评价.
②识别框架可以不完备,即同一D 数的所有映射之和可以小于等于1,而不必硬性要求等于1,这是与证据理论最大的不同.当∑A⊆ΩD(A)=1时,说明信息是完备的,否则是不完备的. 由于D 数这一灵活表达信息,特别是不确定信息的特点,专家们在决策时可以根据自身专业知识背景、偏好、经验等合理地表达其观点,而不用考虑其观点是否完备的问题.
假如Ω= {d1,d2…di…dn},则可表现为一种特殊形式的D 数:D(d1)=v1,…D(di)=vi,…D(dn)=vn. 它也可以被简化为:
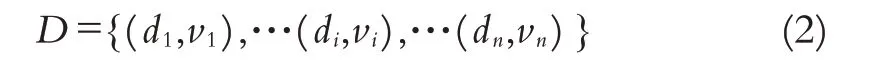
与证据理论类似,D数也具有相应的属性.
属性1(交换不变性):假设在同一框架上有2个 D 数D1={(d1,v1),…(di,vi),…(dn,vn)} 和D2={(dn,vn),…(di,vi),…(d1,v1)},那么D1和D2和被认为是完全相同的,即它们只是元素的位置不同.

例3:假设一个D 数D={(2,0.1),(4,0.3),(5,0.3),(7,0.3)},那 么I(D)=2×0.1+4×0.3+5×0.3+7×0.3=0.2+1.2+1.5+2.1=5.
例4:假设一个D 数D={(7,0.2),(8,0.3)},那么I(D)=7×0.2+8×0.3=3.5.
D 数的聚集属性仅适用于特殊的离散型D 数.在决策评估中,合理利用D 数的聚集属性将会简化及加快决策评估过程.
2 就业决策评估模型
基于D数的大学生就业决策评估过程步骤如下:
①信息收集,包括候选用人单位涉及到的相关指标因素:工资福利、录用率高低、工作环境、休假情况、通勤成本、管理情况等.
②信息整理,指对用人单位的相关指标条件整理,有的指标有可能是定量的,有的指标有可能是定性的,有的指标有可能是积极的,有的指标有可能是消极的. 如在①中提到的,工资福利和录用率通常用定量数据表示,而用定性数据表示工作环境、通勤成本则更为方便. 工资福利等指标通常而言应该是越高越好,是正向的积极指标,而通勤成本情况等指标却是消极的,即指标值越低越好. 因而需要把定性指标和定量指标、积极指标与消极指标等转化为同一类型的指标. 为了保持与思维习惯一致性,易于理解,通常会把定性指标转换为定量指标,把消极指标转换为积极指标.
③各指标权重确定,在就业时,大学生对各指标的关注点和偏好程度是不一样的,通常而言,录用率、工资福利待遇等指标占较大的比重.
④数据归一化处理,对不同候选用人单位的同一指标的数据进行归一化处理,从单个指标的层面来体现各用人单位的具体情况,以便后续信息融合、整理.
⑤D 数引入,引入D 数工具,对各候选用人单位的相关指标数据进行D数表示.
⑥D 数集成,运用D 数聚集属性对各候选用人单位的相关指标进行融合. 需要说明的是,在D 数聚集属性中是没有考虑权重因素的,若实际应用中需要涉及到权重因素,因而需要对D 数聚集属性进行一定的修改,使其从无权重聚集工具变为加权聚集工具.
⑦排序,根据集成结果对各候选用人单位进行排序,并将排序结果呈现给大学生,供其就业参考.
构建的就业决策评估模型如图1所示.
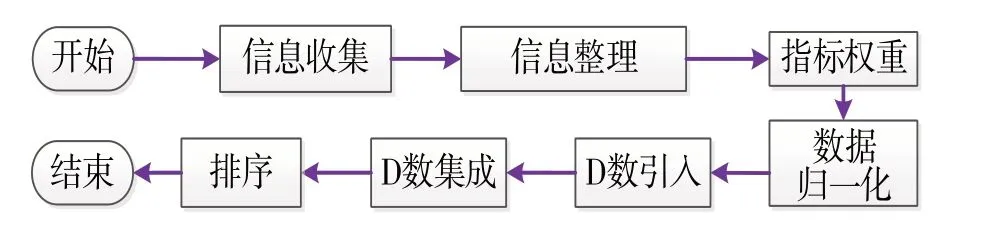
图1 就业决策评估模型
3 实例应用与讨论
大学生在就业前,通常会对自己的能力与水平进行大致的评估,再结合自己的偏好,把与自己能力大致相匹配的用人单位纳入候选清单,才能提高就业成功率,而不是随机地、盲目地选择用人单位. 调研发现,大学生在选择用人单位时,较为关心的指标有录用率、工资福利、假期天数、工作环境、通勤成本等[22]. 例如,张某是某大学的应届毕业生,他目前收到5家用人单位的录用通知,通过进一步搜集这5家用人单位的相关指标信息,发现这5 家单位的相关指标各不相同,录用率最高的却工资最低,假期天数多的工作环境和交通满意度却一般. 张某倍感困惑,特向学校招生就业处的老师请教,如何从这5 家用人单位中选择性价比最高的. 对此,将上述指标视为多属性决策问题中的候选目标的属性,以运用D数理论的决策评估模型来解决张某的困惑.
第一步,信息收集.张某收集5家用人单位的录用率、工资福利、假期、工作环境和通勤成本5 个指标信息,如表1所示.
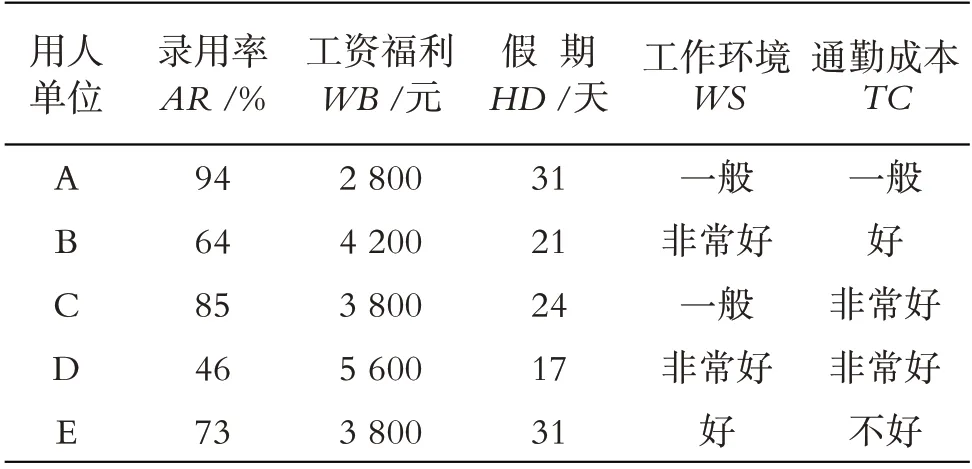
表1 用人单位基本信息(原始)
第二步,信息整理. 由表1 可知,各项指标的相关数据都是积极的,因而无需在积极与消极数据间相互转换. 但存在定量与定性数据,为方便后期数据处理,需要把定性数据转换为定量数据. 结合表2中的定性信息效用值,表1 中的数据指标进一步统一后得到表3.

表2 定性信息效用值
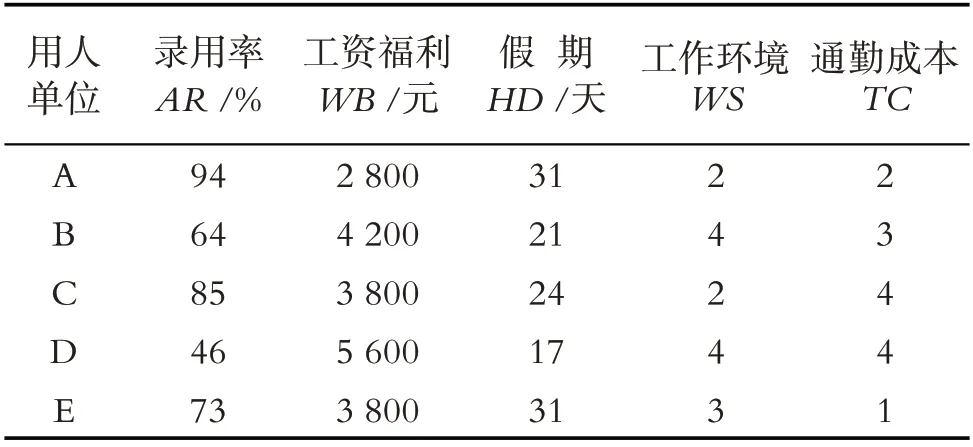
表3 用人单位基本信息(数据整理)
第三步,权重指标确定. 通过调研,大学生在就业时虽然比较看中工资福利,但与是否最后签约录用,即用人单位的录用成功率相比,却更看重后者.此外,假期情况、工作环境和通勤成本等对大学生的就业也有一定的影响. 再结合张某的个人主观侧重和偏好,就业过程中的各指标权重分配为:
(ω1,ω2,ω3,ω4,ω5)=(0.4,0.25,0.1,0.15,0.1)(4)
其中,ω1 代表录用率AR的权重,ω2 代表工资福利WB的权重,ω3代表假期HD的权重,ω4代表工作环境WS的权重,ω5代表通勤成本TC的权重.
第四步,数据归一化处理.表3中的数据虽然已是统一的定量数据,但仍然不能被D 数理论直接进行处理,需要对其进行归一化操作. 数据的归一化机制采用当前值与最大值的比例的方式来进行. 以录用率AR为例,用人单位A 的得分为94/max(94,64,85,46,73)=1.0000,而用人单位B 的得分为64/max(94,64,85,46,73)=0.6809. 同理可得其他用人单位其他指标的得分(表4).
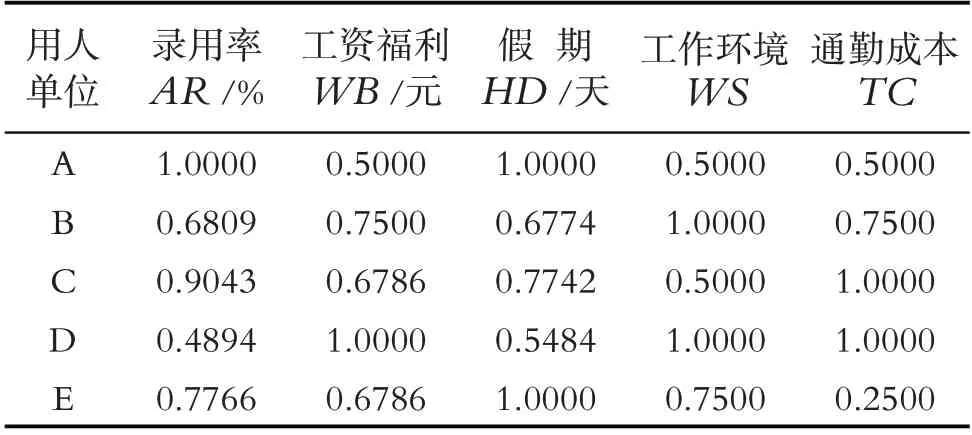
表4 用人单位基本信息(归一化)
第五步,D数引入.运用D数理论对就业信息进行表示. 以用人单位A 为例,其各项指标的D 数信息表示为
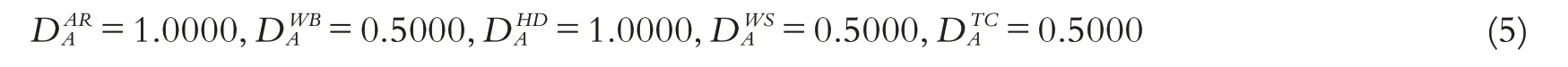


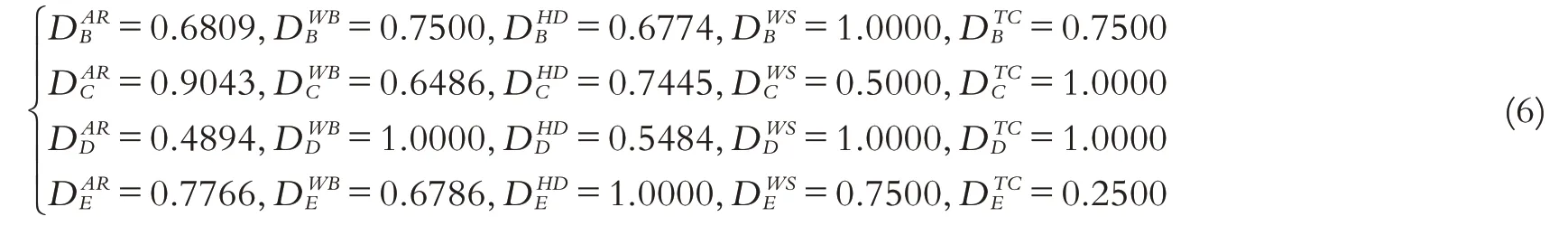
第六步,D 数集成. 运用D 数的聚集属性,如式(3)所示,对各用人单位的D 数信息进行集成. 需要说明的是,在该案例中,并没有明确的等级打分,不能直接运用式(3),但可以将各指标的权重信息视为对各指标的等级打分情况. 以用人单位A 为例,结合式(3)-(5),其最终得分为:
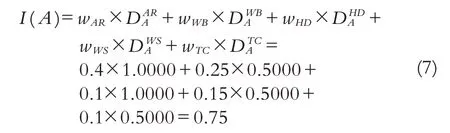
同理,可得用人单位B、C、D的最终得分为:
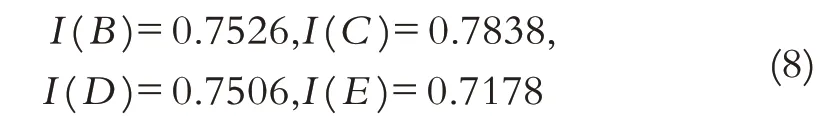
第七步,排序. 用人单位的指标信息都是采用的积极指标,因而最终的聚集结果应该采用正向排列,即值越大越好. 结合式(7)-(8),五家用人单位的最终得分情况如图2所示,其排序结果如式(9)所示.
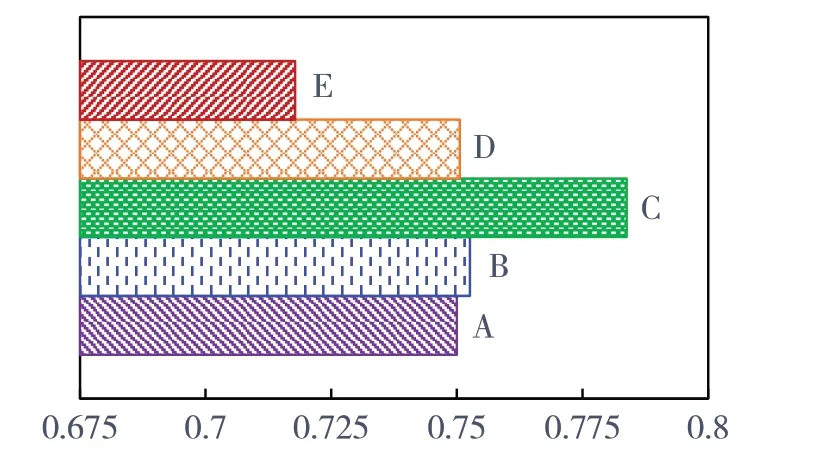
图2 用人单位最终得分情况
I(C)≻I(B)≻I(D)≻I(A)≻I(E)(9)
由上可知,张某应将用人单位C 作为首选. 用人单位C 虽然在各项指标方面都不是最突出的,但从各指标的权重分布来看,不仅保证了就业的成功率,同时也最大限度地平衡了其余指标. 从决策结果来看,本文基于D 数的决策模型与基于证据理论的模型[22]结果是一致的,不同的是文献[22]采用的是信任期间决策方法,得到的值为区间值,两两进行比较,再进行推导,间接得到最终结果,没有直观地体现用人单位之间的具体差异,而本文所采用的则是直观的确定数值,全部直接比较,能直观地呈现不同用人单位之间的差距. 从另一方面来说,由于证据理论的融合规则的计算时间复杂度较高,特别是随着证据数量的增加时,其时间复杂度呈指数增长,如若候选用人单位数量或用人单位的指标不断增加时,其计算时间将大幅增加,而D数的聚集属性则没有这方面的缺陷.
4 结语
本文基于D 数理论构建了就业决策评估模型,将复杂的就业决策问题,逐步分解,从信息收集、信息整理、指标权重、数据归一化、D 数表示及D 数决策等方面进行了详细表述. 在原始信息收集与整理部分,允许较为宽松地信息表达模式,即允许定量与定性信息共存和允许积极与消极指标共存,有助于收集到更加贴切、真实的信息,进而提高决策有效率. 实例验证表明,本文建立的就业决策评估模型是可行、有效的,具有流程直观、运算简便等特点.本文建立的决策评估模型不仅可用于就业决策领域,同时可以推广到其他的决策场合,具有普适性与推广意义.
猜你喜欢
工会博览(2023年1期)2023-02-11 11:57:24
反歧视评论(2021年0期)2021-03-08 09:13:16
当代陕西(2020年17期)2020-10-28 08:18:18
今日农业(2019年11期)2019-08-15 00:56:32
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
红土地(2016年3期)2017-01-15 13:45:22
幼儿智力世界(2016年6期)2016-05-14 13:50:51
发明与创新(2016年33期)2016-04-16 16:32:25
小雪花·初中高分作文(2015年10期)2015-10-24 04:01:58
