
WantWords:基于神经网络技术的反向词典
2022-07-20 01:54岂凡超刘知远孙茂松
辞书研究 2022年4期
岂凡超 张 磊 刘知远 孙茂松
一、反向词典及其价值
所谓“反向词典”,顾名思义,是和一般词典功能恰好相反的一种“词典”。(Sierra 2000)一般词典是帮助使用者了解一个词语的信息及用法,即以某个词语作为输入,以该词语的定义等信息作为输出。例如,输入“高峻”给一个汉语词典,该词典会告诉我们它表达的意思是“(山势、地势等)高而陡”。而反向词典则恰好相反,它以表达某种意思的语义描述作为输入,输出符合输入描述的词语。例如,输入“山非常高”,反向词典就会输出“高峻”“巍然”“嵯峨”等词语(详见图1)。
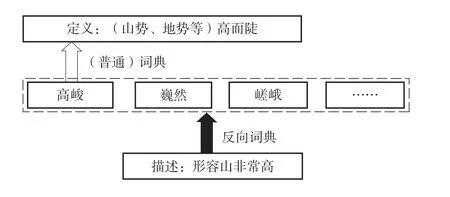
图1 反向词典示意图
反向词典有重要的实用价值,具体使用场景包括:
(1) 解决暂时性忘词的问题。词穷也被称为“舌尖现象”(tip-of-the-tongue phenomenon)(Brown & McNeill 1966),经历舌尖现象的人知道目标词语的意思,甚至能回忆起目标词语的某些特征,例如其中的一个字或一个音节,但是无法完整地想起目标词语。根据心理学相关研究,舌尖现象是一种十分普遍的语言产生失败现象,不同年龄、不同性别、不同受教育程度的人群在使用不同语言时均会遇到该问题。(郭桃梅,彭聃龄 2005)494-496而且舌尖现象的出现频率也较高,日记研究表明舌尖现象在年轻人中至少每星期发生一次,而老年人则增加到大概每天一次,对于需要频繁进行文字表达的人,例如作家、研究人员、学生,舌尖现象的发生频率则会增加若干倍。(姜敏敏,李虎 2011)反向词典是解决舌尖现象的最有效工具,使用者在忘词时只需输入对目标词语的描述,再利用若干筛选器(如字数、词性等),就可以迅速找到目标词语,免除久久不能想起词语的 烦恼。
(2) 缓解“网络失语症”问题。目前各种网络流行语充斥着人们——尤其是年轻人——的交流和表达,越来越多的人逐渐丧失了基本的语言表达能力,这种现象被称为“网络失语症”。2019年中国青年报社会调查中心对2002名受访者进行的一项调查显示,76.5%的受访者感觉自己的语言越来越贫乏。(常泽昱,任雾 2021)在社交媒体“豆瓣”上有一个名为“文字失语者互助联盟”的兴趣小组,[1]目前已有超过30万人在其中寻求包括网络流行语的替代用词在内的合适的文字表达方式。反向词典也可以有效地缓解“网络失语症”的问题,帮助用户找到符合想表达意思的合适的 词语。
(3) 帮助语言学习者学习、回忆、巩固词汇。首先,某种语言的初学者(无论是母语初学者还是第二语言初学者)对于词语的记忆往往并不牢固,出现“舌尖现象”的频率也大大增加,(Kreiner & Degani 2015;戎玲等 2018)273-274反向词典可以帮助他们回忆、巩固学过的词语。其次,反向词典可以输出大量符合输入描述的词语,帮忙语言初学者了解、学习一些新的词汇,尤其是在写作时提供帮助。支持跨语言查询的反向词典对于第二语言学习者的辅助作用更加巨大,他们可以使用自己更为熟悉的母语来检索遗忘的第二语言的词语。
(4) 帮助选词性失语症(word selection anomia,又称“选词性命名不能”)患者。这种症状由脑部损伤引起,患者可以识别并描述某个物体但是无法记起该物体的名称。(Benson 1979)据统计,每100万人中至少有一人罹患选词性失语症。(Rohreret al. 2008)该症患者的生活质量以及人际沟通受到严重影响,而反向词典可以在很大程度上帮助这些患者,提升他们的生活质量。
二、现有的反向词典及实现方法
反向词典可以看作一种特殊的搜索引擎,目前国外有一些支持英语词语检索的反向词典,例如OneLook[2]、ReverseDictionary[3]。但是除了本文介绍的WantWords之外,还没有支持中文词语检索的反向词典。
反向词典背后的技术属于自然语言处理(Natural Language Processing)的范畴,这是一门让计算机能够理解并说出人类语言的学科,也被称作“计算语言学”。
自然语言处理相关研究中,反向词典的算法主要有两类。第一类方法基于句子匹配,(Zock & Bilac 2004;Méndezet al.2013;Shawet al. 2013),该方法的主要思想是在数据库中检索与输入查询文本最相似的词语定义并且返回对应的词。尽管这种方法在一些情况下比较有效,但是实际情况中用户的输入描述往往非常多变,而且和词典编纂者撰写的词语定义有较大差别,因此在很多情况下这种方法效果不佳。
第二类方法是使用一个神经网络语言模型(一种深度学习模型)对输入的描述编码成一个向量,然后将其映射到词语的向量(词向量,word embedding)表示空间之中,最后返回向量空间中与输入描述距离最近的词语。(Hillet al. 2016;Morinaga & Yamaguchi 2018;Kartsakliset al. 2018;Hedderichet al. 2019;Pilehvar 2019)这类方法的效果很大程度上依赖于词向量的质量,然而,由于大部分词语都是低频词,其词向量质量较差。因此,这类方法对于低频词的反向查词效果较差。
为了解决上述问题,我们此前提出了一种名为“多通道反向词典”的方法。(Zhenget al. 2020)这一方法受到人根据描述猜测词语过程的启发,会首先根据语义描述预测词语的特征,具体包括词性、词素、词语类别和义原。[4]通过预测这些特征,模型就能更好地排除低质量词向量的干扰,更准确地找到正确的词语。例如,“平凡”和“凡人”的意思有很大的相关性,词向量通常比较接近,但是它们的词性不同,前者为形容词,后者为名词,当输入的描述为“平常人”时,模型能够猜到目标词语是名词,进而将“平凡”排除在外,将“凡人”“ 凡夫”等正确的词语保留。
根据多个评测数据集上的实验结果,我们提出的“多通道反向词典”方法是当前效果最好的反向词典方法。
三、WantWords反向词典
(一) WantWords介绍
基于上述“多通道反向词典”方法,我们研发了WantWords反向词典,(Qiet al. 2020)目前有网页版(访问地址为https://wantwords.net)和微信小程序两个版本。
该词典主要功能包括汉语和英语单语的反向查词,以及汉英和英汉跨语言反向查 词。
图2为反向词典系统的查询结果界面示例(以汉语单语查询为例)。用户在输入框输入对目标词语的描述(图中示例为“山非常高”)后点击按钮,即会在输入框下方显示工具栏以及100个最可能符合输入描述的词语。
工具栏由4个筛选器构成。筛选器具体包括:(1) 词性筛选器,包含名词、动词、形容词、副词等;(2) 字数筛选器;(3) 韵脚筛选器,基于《中华通韵》的韵脚集合;(4) 词形筛选器,如输入“高”可以匹配所有包含“高”字的词。
根据候选词语语言的不同,筛选器也略有不同,例如对于英语候选词就没有字数和韵脚筛选器。
这些筛选器可以帮助用户更快地找到目标词语,例如图2中如果用户想找的是形容“山非常高”的词语,可以利用词性筛选器去除形容词之外其他词性的词语,进而更快地找到满足需求的词语。
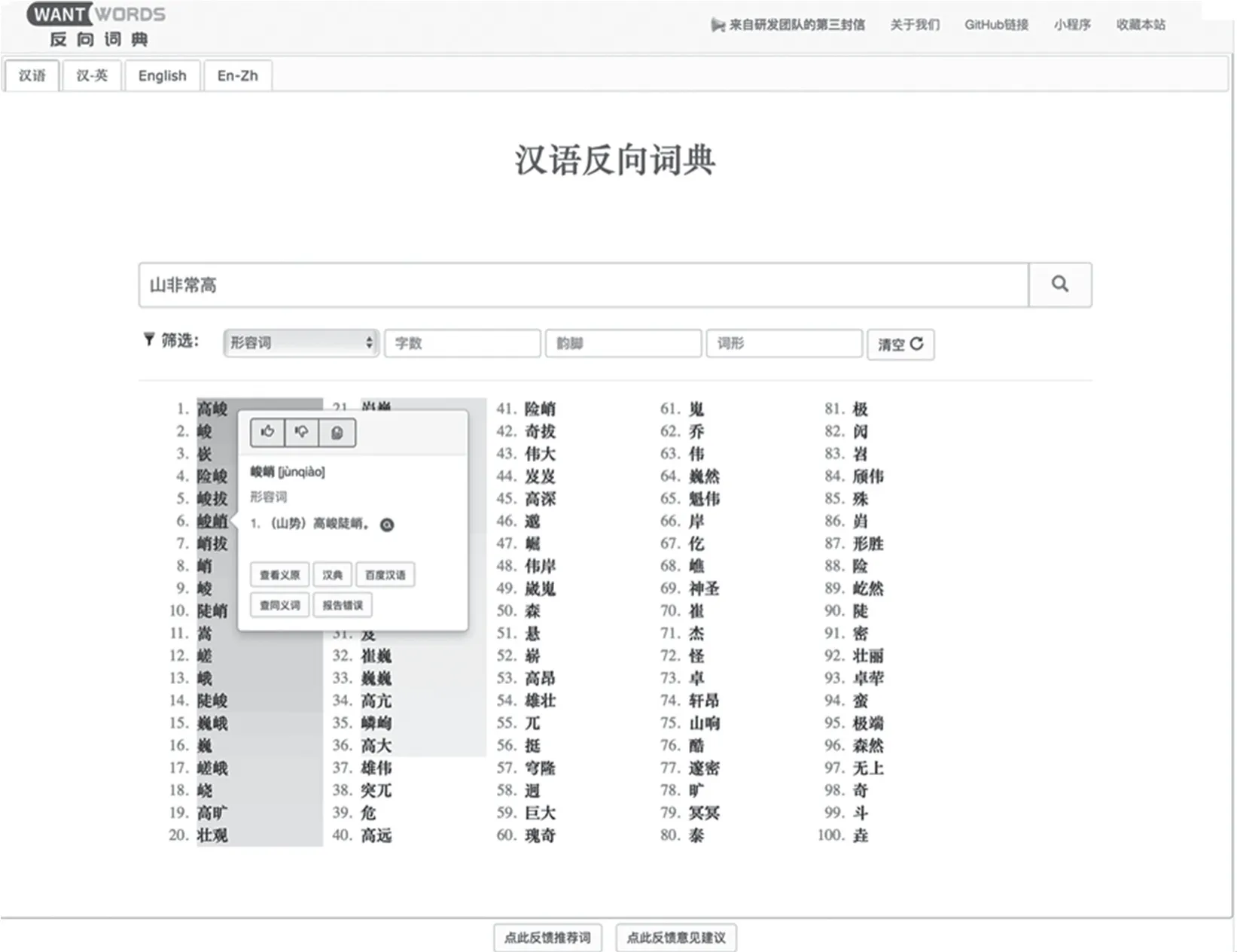
图2 反向词典系统查词结果界面
对于所有展示出的候选词,系统为相关性较高的词语添加了深浅不同的背景色,相关性越高颜色越深。此外,用户点击某个候选词,系统会弹出一个浮动窗口,该窗口会显示该候选词的拼音、词典定义等基本信息,以帮助不熟悉该词的用户学习、了解该词,同时判断该词是否为自己所需。浮动窗口中还提供了该词在百度汉语或维基词典等其他在线词典中的链接,方便用户跳转到相应的查询结果页面以进一步了解该词语。
本系统还设计了一套完善的用户反馈系统。在每个词语的浮动窗口中,用户可以通过点击或来向系统反馈该词是否符合输入的描述。在页面的最下方,用户还可以直接反馈自己认为的符合输入描述的词语,或者提出其他的意见和建议。这些反馈将会保存在数据库中,帮助后续提升系统的性能。
(二) WantWords基本工作流程
图3展示了WantWords反向词典的系统运行流程。
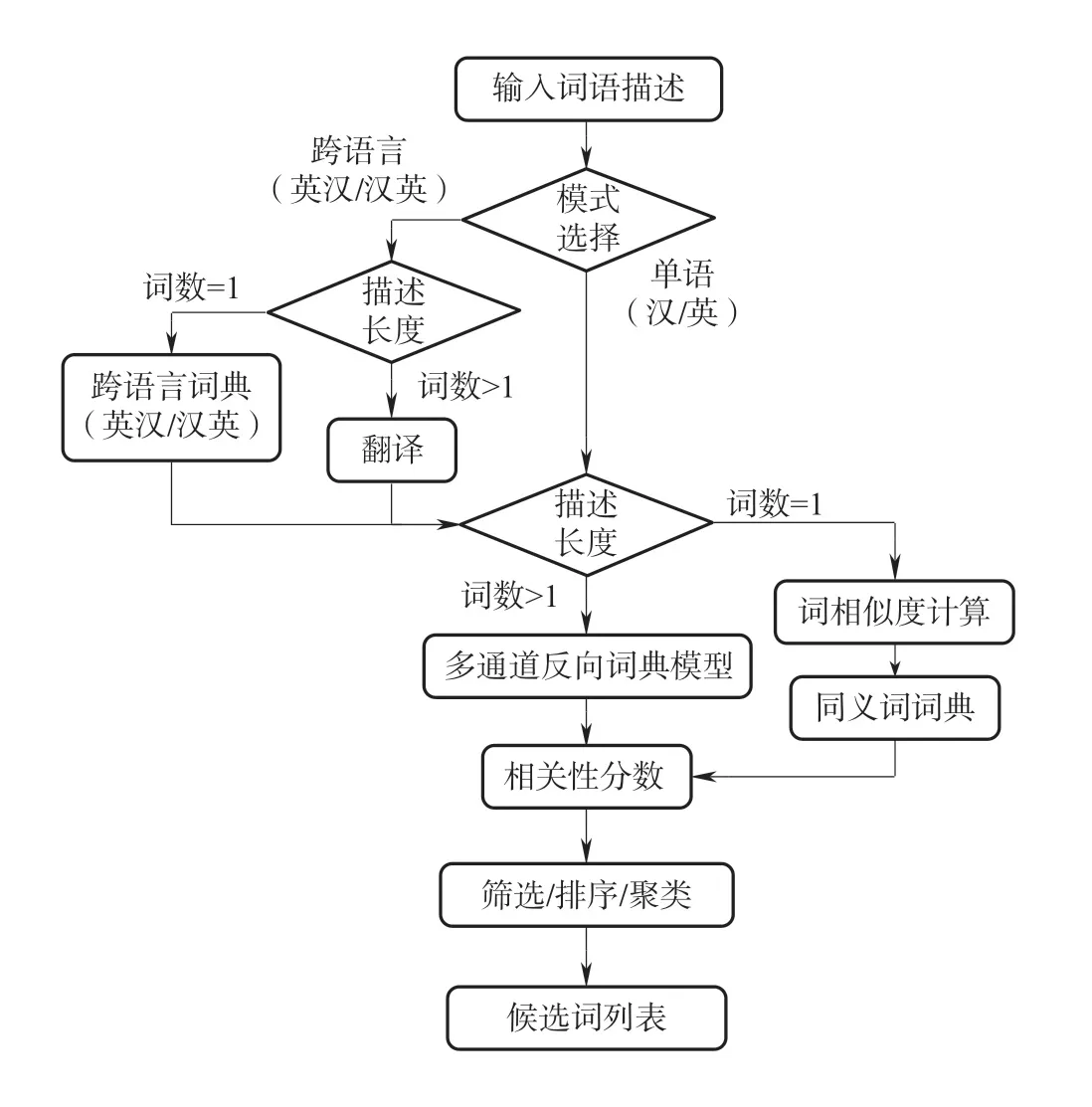
图3 WantWords的运行流程
在用户输入词语的描述后,首先从“汉语、英语、英汉、汉英”四种模式中选择一种。在前两种模式(单语模式)中,如果用户的输入不是一个词,那么该输入会被送到多通道反向词典模型中,然后为词表中的每个候选词计算出一个相关性分数;如果用户的输入是一个词,那么候选词的相关性分数主要由输入描述词和候选词的词向量的相似度计算得到。
在后两种模式(跨语言模式)中,我们定义输入描述的语言为源语言,想查找的词语的语言为目标语言。如果输入描述的不是一个词,我们会调用翻译引擎将其翻译成目标语言,然后进入目标语言单语模式的处理流程;如果输入的是一个词,我们会借助跨语言词典获得输入词语的目标语言定义,然后再进入目标语言的单语模式处理流程。
在获得相关性分数后,所有的候选词将会根据相关性分数从高到低排列,作为输出结果。不同的筛选器可以对输出结果进行调整。
(三) WantWords的主要创新点
WantWords反向词典的创新点主要有以下三点。
1. WantWords是世界首个汉语反向词典,填补了没有汉语反向词典的空白。这一系统将帮助广大汉语学习者和使用者缓解“舌尖现象”“网络失语症”等问题,同时也将对提高中国的选词性失语症患者的生活质量做出贡献。
2. WantWords也是世界上首个支持跨语言查询的反向词典,能够大大提高第二语言学习者的学习效率,帮忙他们回忆、巩固初学的词汇,学习、了解新的词汇,同时在他们写作时也能起到重要的辅助作用。
3. 依赖于我们提出的多通道反向词典模型,WantWords反向词典的英语反向查词性能也超过了现有的其他英语反向词典。
四、WantWords反向词典的现状及未来
目前WantWords的累计查询量已经超过1400万次,每天的查询量超过20万次,受到了众多文字表达者的喜爱。
WantWords的第二版正在研发过程中,将有以下几点主要更新:
1. 支持更多类型词语的查询,包括古汉语词、专业术语、网络流行语等;
2. 支持更多的筛选器,包括褒贬性、书面语/口语、常用度;
3. 支持更丰富的查词模式,包括根据词语的字形、音调特征来查词,以及更强大的近反义词查询功能。
此外,我们也在研发WantWords的姐妹产品,可以根据用户的现代汉语描述来查找表达相同意思的古诗文、名言名句、歇后语等。
附注
[1] https://www.douban.com/group/715666/。
[2] https://onelook.com/thesaurus/。
[3] https://reversedictionary.org/。
[4] 义原在语言学中被定义为最小的语义单位,(Bloomfield 1926)一个词语的语义可以由其被标注的义原所表示。
猜你喜欢
飞天(2022年5期)2022-05-18
心潮诗词评论(2019年12期)2019-05-30
文理导航(2017年25期)2017-09-07
成都中医药大学学报(教育科学版)(2016年2期)2016-01-22
华南师范大学学报(社会科学版)(2013年1期)2013-12-02
疯狂英语·中学版(2013年7期)2013-08-01
小小说月刊(2010年5期)2010-05-14
